深度学习(DL)(四) — 探析
自注意力
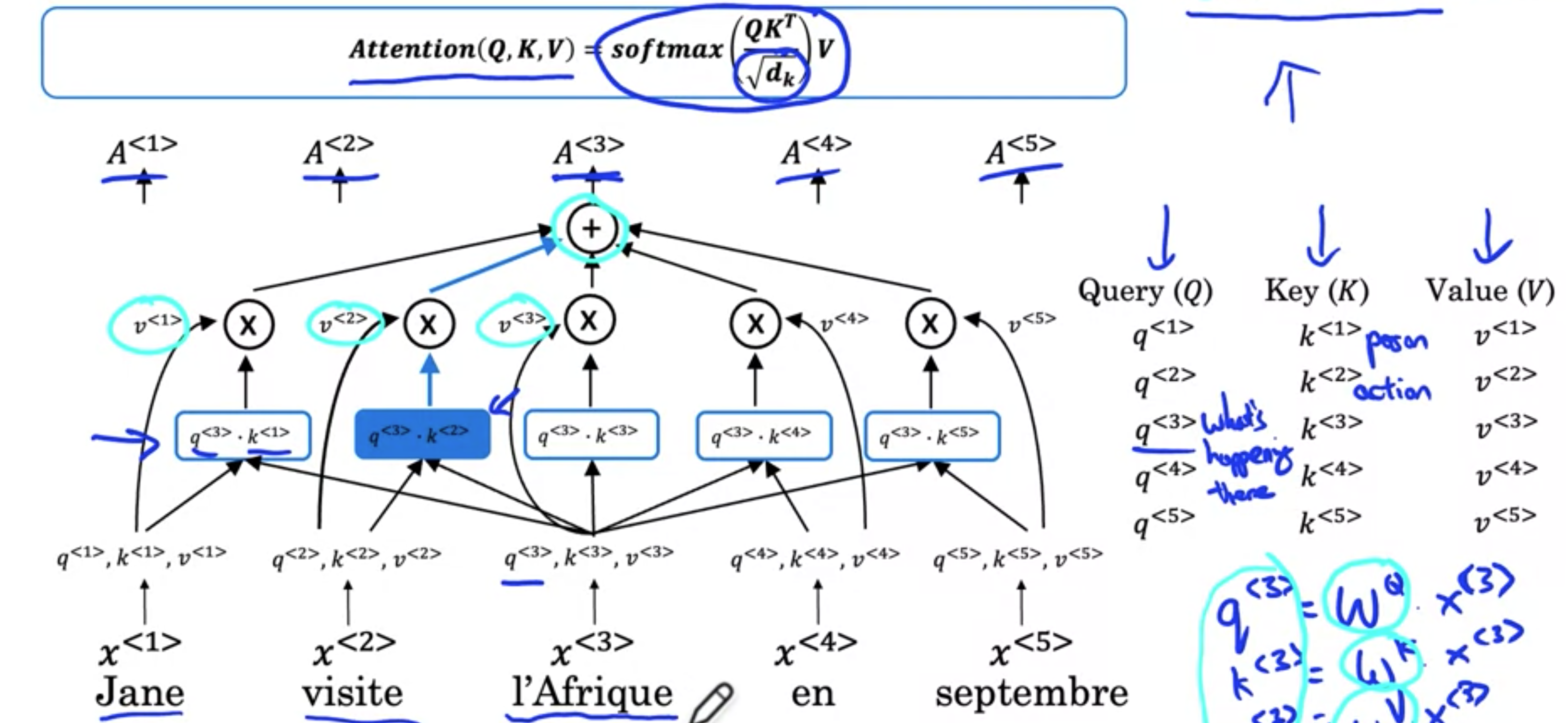
要将自注意力与CNN一起使用,需要计算自注意力,即为输入句子中的每个单词创建基于注意力的表示。示例Jane, visite, l'Afrique, en, septembre,我们的目标是为每个单词计算一个基于注意力的表示。最终会得到五个,因为句子有五个单词。即l'Afrique的一种方法是查找l'Afrique的词嵌入。根据对l'Afrique的理解,可以选择不同的方式来表示它(RNN上下文中看到的注意力机制没有太大区别,只是并行计算句子中所有单词的表示。
在RNN之上构建注意力时,使用了以下方程Transformer的自注意力机制,方程将如下所示softmax。但主要的区别在于,比如l'Afrique,有三个值,称为Query、Key和Value。这些向量是计算每个单词的注意力值的关键输入。让我们逐步完成从单词l'Afrique到自注意力表示l'Afrique的单词嵌入,则计算1时问题的答案有多好。1时问题的答案有多好,此操作的目的是提取信息,并计算出此处最有用的表示Jane是一个人,而visite是一个 action,那么会发现softmax。visite具有最大值。将这些softmax值与l'Afrique这个词不是某种固定的词嵌入。相反,它让自注意力机制意识到l'Afrique是访问的目的地,从而为这个词计算出更丰富、更有用的表示。如果将这五个计算放在一起,文献中使用的表示法如下所示,其中
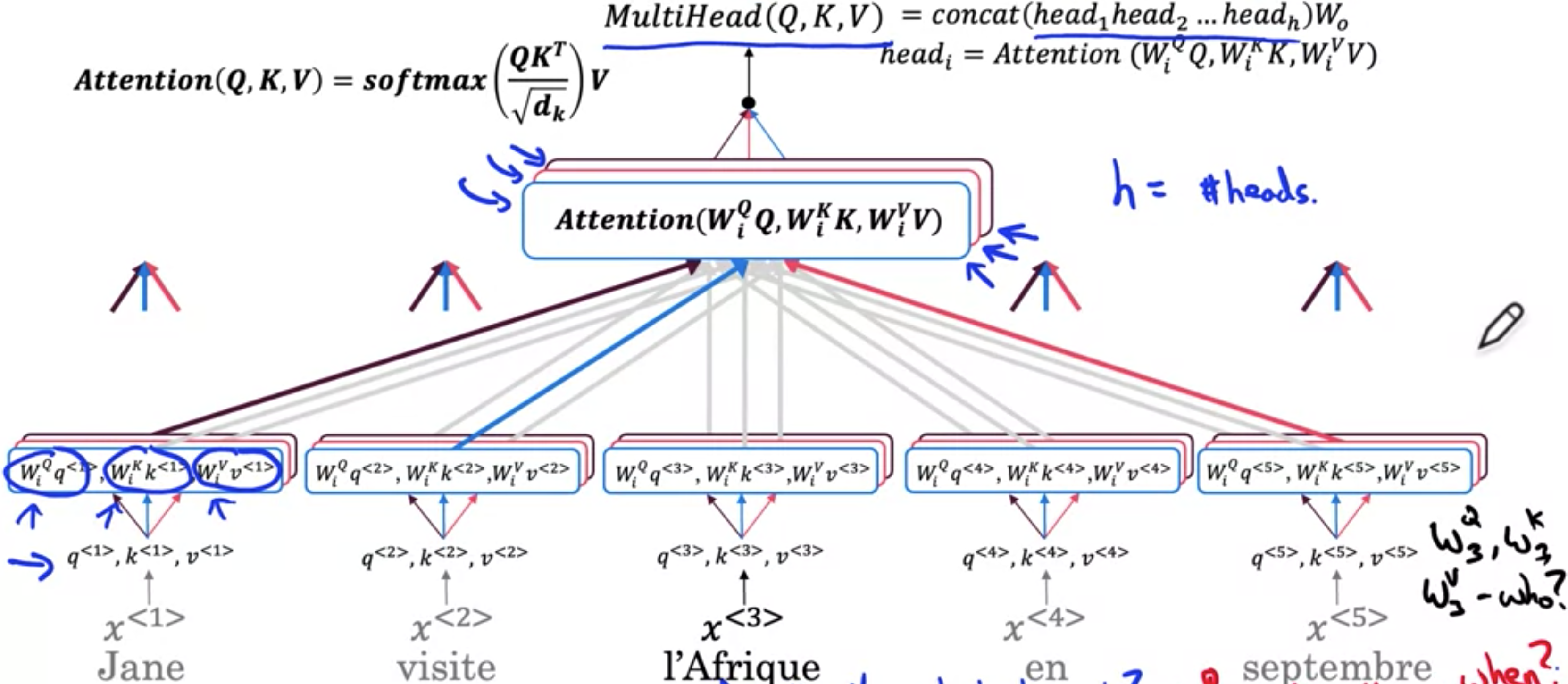
多头注意力
每次计算序列的自注意力时,称为头部。通过将每个输入项乘以这几个矩阵WQ,WK和WV,获得了向量QK和V。使用多头注意力,将同一组查询键和值向量作为输入。visite给出了最佳答案,表示l'Afrique的键与visite的查询之间的内积具有最高值。这就是获得l'Afrique的表示,对Jane、visite和其他单词en septembre做同样的操作。最终得到五个向量来表示序列中的五个单词。这是对多头注意力机制中的第一个头进行的计算。对l'Afrique和其他单词进行的完全相同的计算,并最终得到注意力值。现在执行不止一次,而是多次。到目前为止,用第一个头计算了注意力的数量。让我们用第二个头进行计算。有一组新的矩阵。september键和l'Afrique查询之间的内积最高。也许我们现在要问的第三个问题,由Jane的键向量和l'Afrique查询向量之间的内积将最高。Jane的值将在此表示中具有最大的权重,将其堆叠在后面。在文献中,头部的数量通常用
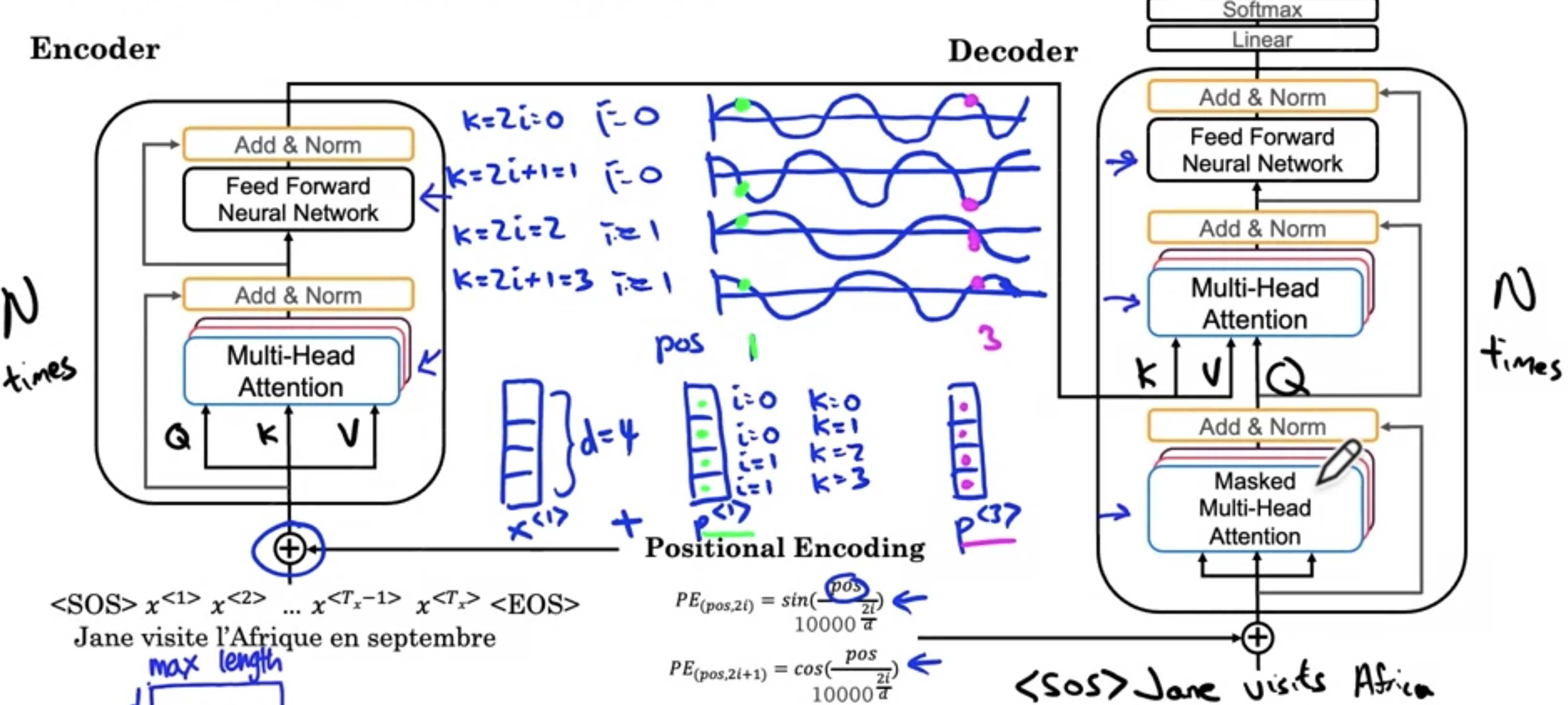
Transformer
再次从句子“Jane visite L'Afrique en septembre”及其对应的嵌入开始。如何将句子从法语翻译成英语。这里添加了句子开头和句子结尾的标记。为了简单起见,只讨论了句子中单词的嵌入,但在许多序列到序列的翻译任务中,添加句子开头(SOS)和句子结尾(EOS)标记会很有用,Transformer的第一步是,这些嵌入被输入到具有多头注意力层的编码器块中。根据嵌入和权重矩阵Transformer论文中,这个编码块重复了n次,n的默认值是6。大约经过六次这个块之后,将编码器的输出输入到解码器块中。接下来开始构建解码器块。解码器块的工作是输出英文翻译。第一个输出将是句子开头的标记。在每一步,解码器块都会输入前几个单词,无论生成了什么翻译。刚开始时,唯一知道以句子开头的标记开始。句子开头标记被输入到这个多头注意力块中,仅使用这个标记(SOS)来计算多头注意力块的6次,将输出反馈给输入,并让它重复。神经网络的工作是预测句子中单词。希望确定英语翻译中的第一个单词是Jane。然后还要将Jane提供给输入。下一个查询来自SOS和Jane,给定Jane,最合适的下一个单词是什么?找到正确的键和值,然后生成最合适的下一个单词,希望会生成visite。然后再次运行这个神经网络生成Africa。然后我们将Africa反馈给输入。希望它生成in然后是September,有了这个输入,希望它能生成句子结尾的标记,然后就完成了。输入的位置编码。没有任何东西可以指示单词的位置。这个词是句子中的第一个词,还是句子中的中间词,还是句子中的最后一个词?句子中的位置对于翻译来说非常重要。对输入中元素位置进行编码的方式是使用正弦和余弦方程的组合。例如,假设您的词嵌入是一个具有四个值的向量。在这种情况下,词嵌入的维度Jane的位置嵌入。在下面的等式中,位置(pos)表示单词的数字位置。对于单词Jane,pos是单词的位置,l'Afrique的位置进行编码的向量Jane的代码位置中使用的四个值。Transformer网络还使用与批量规范非常相似的层。它们的目的是将位置信息传递到位置编码中。Transformer还使用了一个批量规范层。最后,对于解码器块的输出,实际上还有一个线性层和一个softmax层,用于一次一个单词地预测下一个单词。您可能还会听到一种称为掩码多头注意力。掩码多头注意力仅在训练过程中很重要,在该过程中,您将使用正确的法语到英语翻译的数据集来训练Transformer。