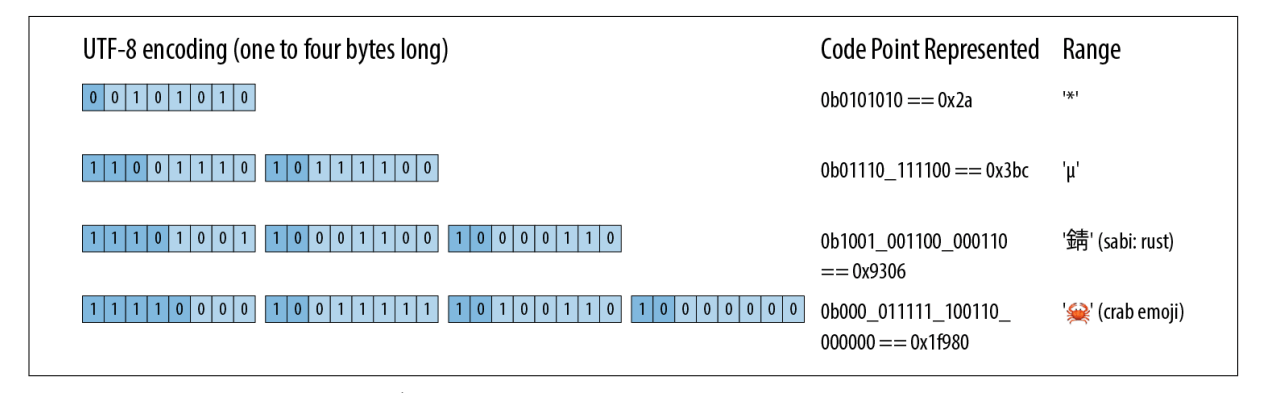
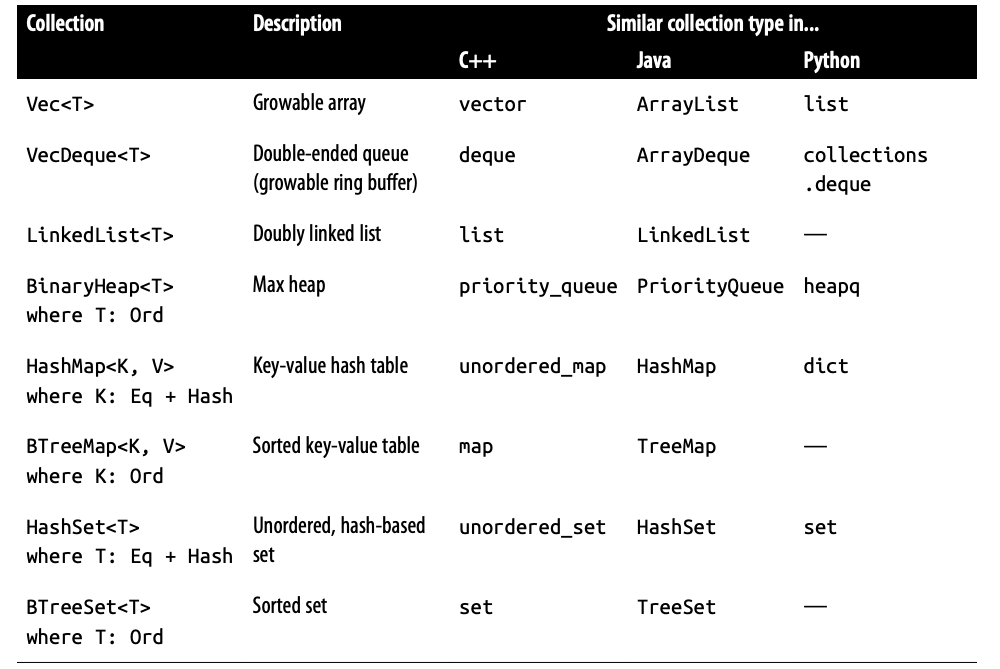
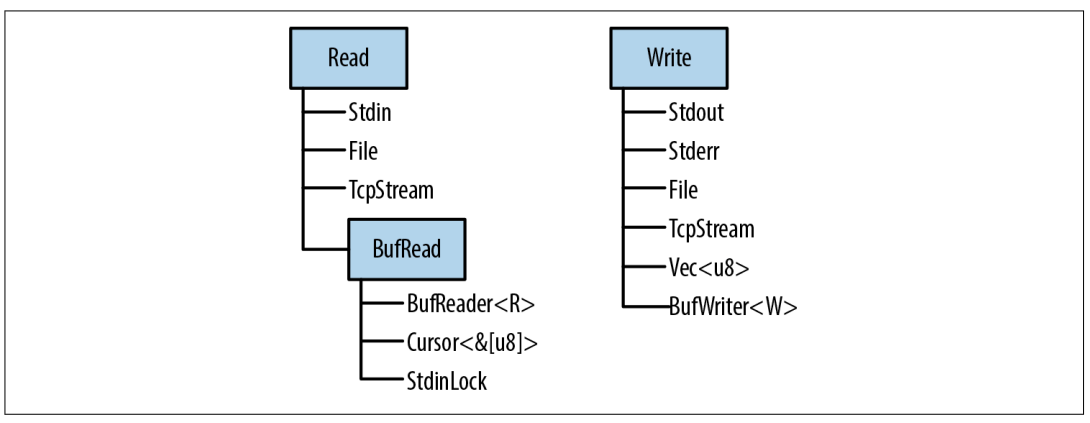
面向对象
几年前在面试的时候,还经常被面试官问 OOP 的四个特征是什么以及他们背后代表的意思,几年过去了,除了不支持面向对象的语言之外,面向对象编程思想已经深入到了每个开发者的灵魂,只是做的好与不好罢了。
面向对象编程中有两个非常基础的概念,类和对象,面向对象编程是一种编程范式或者说编程风格,它以类或者对象作为组织代码的基本单元,并将封装,继承,抽象,多态作为代码设计和实现的基石,不像面向过程编程语言,以函数为程序中的基本单元。
面向对象编程只是一种编程思想,可以用不同的语言进行实现,即使我们用面向对象语言,也完全可以写出面向过程风格的代码。至于什么是面向对象编程语言,并没有严格的定义,只要它能实现 OOP 的四大特性,那它就是面向对象编程语言,例如:Rust,C++,GO,Java,Python 以及 PHP 等,
面向对象编程的前提是面向对象分析(OOA)和面向对象设计(OOD),这样才能进行面向对象编程(OOP),具备完整的面向对象编程的思维。面向对象分析和设计两个阶段的产物应该是类的设计,包括应用程序应该被分为哪些类,每个类该有哪些属性和方法,类与类之间如何交互等等,它们比较贴近代码,非常具体,容易落地实现。
在 OOA 和 OOD 的过程中,我们会经常用到 UML(Unified Model Language) 工具辅助我们进行工作。UML 是一种比较复杂的工具,除了包括我们常见的类图,还有用例图,顺序图,活动图,状态图,组件图等,即使是类图,类之间的关系就有泛化,实现,关联,聚合,组合以及依赖等,熟练掌握难度比较大,即便你掌握了,你同事不一定掌握,沟通成本依然很高,大多时候,我们会用草图实现我们的设计过程。