机器学习(ML)(十九) — 强化学习探析
介绍
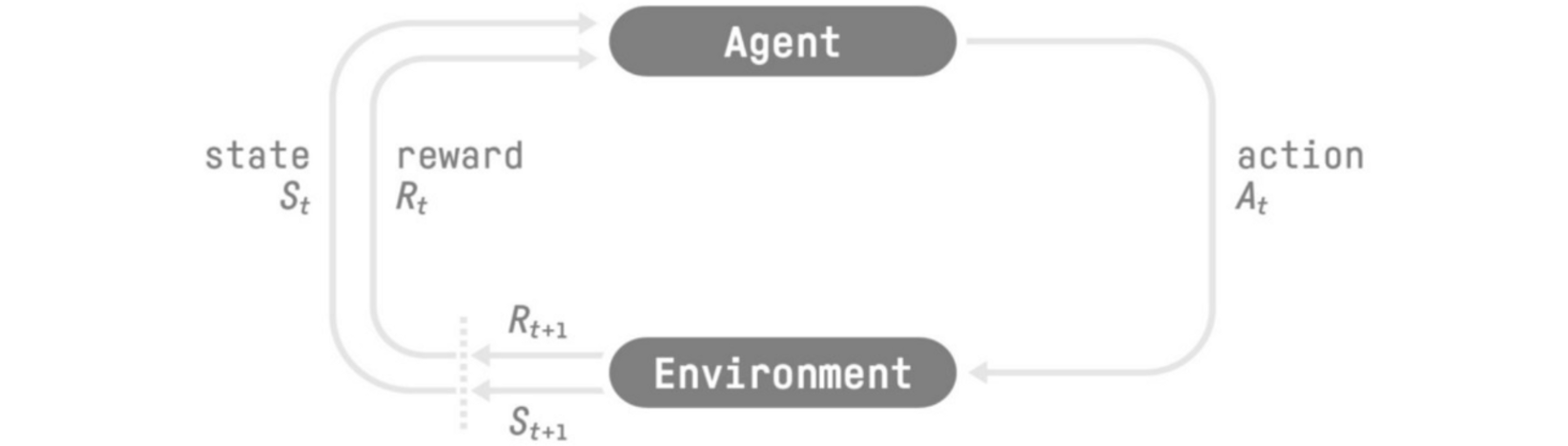
强化学习(RL)背后的想法是智能体(Agent)通过与环境(Environment)交互(通过反复试验),并从环境中接收奖励(Rewards)作为执行动作(Action)的反馈来学习。从环境的互动中学习,源自于经验。这就是人类与动物通过互动进行学习的方式,强化学习(RL)是一个解决控制任务(也称决策问题)的框架,通过构建智能体(Agent),通过反复试验与环境交互从环境中学习并获得奖励(正面或负面)作为独特反馈。强化学习(RL)只是一种从行动中学习的计算方法。
任务是强化学习(RL)问题的一个实例,这里有两种类型的任务:情景式任务和持续式任务。
- 情景式任务:这种情况下,会有一个起点和终点(称为终端状态),这将创建一个情节:状态、动作、奖励和新状态的列表。
- 持续式任务:这些任务会永远持续下去(没有终止状态),在这种情况下,智能体(
Agent)必须学习如何选择最佳动作(Action),并同时与环境进行交互,例如,一个执行自动股票交易的代理。对于此任务,没有起点和终点。
探索:是通过尝试随机动作来探索环境以便找到有关环境的更多信息。利用权衡:是利用已知信息来最大化回报。强化学习(RL)智能体(Agent)的目标是最大化预期累积奖励。我们需要平衡对环境的探索程度和环境的利用程度。因此,我们必须定义一个有助于处理这种权衡的规则。例如,选择餐厅的问题,利用权衡:你每天都去同一家你知道不错的餐厅,但却有可能错过另一家更好的餐厅。探索:尝试从未去过的餐厅,可能会有不愉快的经历,但也有可能获得美妙的体验。策略Agent)的大脑,它是一种函数,可以告知在指定状态下采取什么动作。
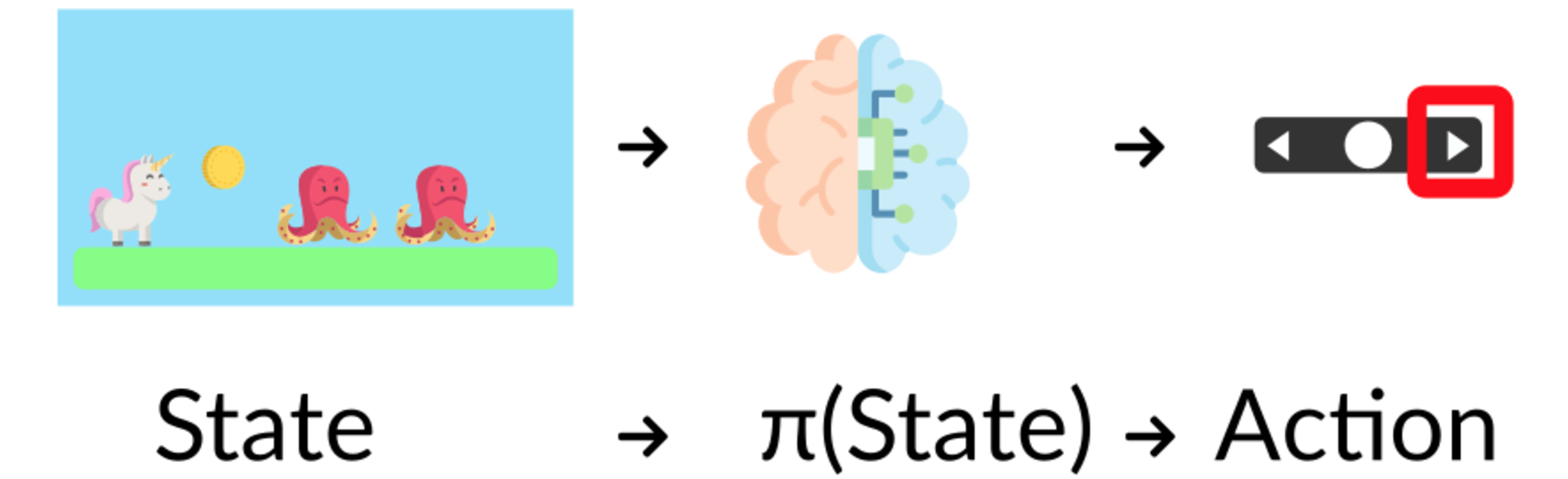
策略Agent)按照这个策略行动时,能够最大化预期回报的策略。通过训练找到Agent)来找到最佳策略
- 基于策略的方法:在基于策略的方法中,学习策略函数。此函数定义从每个状态到最佳动作的映射。或者定义该状态下可能动作集的概率分布。这里的策略分为:确定性策略,给定状态下的策略将始终返回相同的动作,记作
。随机性策略:输出动作的概率分布,记作 。 - 基于价值的方法:在基于价值的方法中,不是学习策略函数,而是学习将状态映射到它的预期值的价值函数,记作
,这里可以看到价值函数为每一个可能得状态定义了值。
任何强化学习(RL)智能体(Agent)的目标都是最大化预期累积奖励(也称为预期回报),因为强化学习(RL)基于奖励假设,即所有目标都可以描述为预期累积奖励的最大化。强化学习(RL)过程是一个循环,输出状态、动作、奖励和下一个状态的序列。为了计算预期累积奖励(预期回报),我们会对奖励进行折扣:更早出现的奖励(在游戏开始时)更有可能发生,因为它们比长期未来奖励更可预测。要解决强化学习(RL)问题,您需要找到一个最佳策略。策略是智能体的“大脑”,它将告诉我们在给定状态下应采取什么动作。最佳策略是智能体(Agent)最大化预期回报的行动的策略。深度强化学习引入了深度神经网络来估计要采取的动作(基于策略)或估计状态的值(基于价值),来解决强化学习问题。
| 概念 | 描述 |
|---|---|
智能体(Agent) |
智能体通过反复试验并根据周围环境的奖励(正面或负面)来学习做出决策。 |
环境(Environment) |
环境是一个模拟的世界,智能体可以通过与其交互来学习。 |
观察(Observe) |
环境/世界状态的部分描述。 |
状态(State) |
对世界状态的完整描述。 |
动作(Action) |
离散动作:有限数量的动作,例如左、右、上、下;连续动作:动作的无限可能性;例如,在自动驾驶汽车的情况下,驾驶场景中发生动作的可能性是无限的。 |
奖励(Reward) |
强化学习中的基本要素。判断智能体采取的动作的好坏。强化学习算法专注于最大化累积奖励。强化学习问题可以表述为(累积)回报的最大化。 |
折扣(Discounting) |
刚刚获得的奖励比长期奖励更可预测,因此更有可能发生。 |
任务(Task) |
任务分为:情景式,有起点和终点;连续式,有起点,没有终点。 |
探索(Exploration) |
通过尝试随机动作来探索环境并从环境中获取反馈/回报/奖励。 |
利用(Exploitation Trade-Off) |
它平衡了对环境的探索程度和环境的利用程度。 |
| 离线策略算法 | 训练和推理时使用不同的策略 |
| 在线策略算法 | 训练和推理过程中使用相同的策略 |
策略(Policy) |
它被称为智能体的大脑。在给定状态下要采取什么动作。当智能体按照该策略执行时,最大化预期回报的策略。它是通过训练来学习的。以 |
| 强化学习中常见策略是平衡探索和利用。 | |
| 贪婪策略 | 根据当前对环境的了解,始终选择预计会带来最高回报的动作(仅限探索),总是选择预期回报最高的行动。不包括任何探索。在不确定性或最佳行动未知的环境中可能会不利。 |
| 基于策略的方法 | 在这个方法中,策略是直接学习的。将每个状态映射到该状态下最佳对应的动作。或者该状态下可能动作集合的概率分布。策略通常用神经网络进行训练,选择在给定状态下采取什么动作。在这种情况下,神经网络输出智能体应该采取的动作,而不是价值函数。根据环境获得的经验,神经网络将重新调整并提供更好的动作。 |
| 基于价值的方法 | 在这个方法中,不需要训练策略,而是训练一个价值函数,将每个状态映射到该状态的预期值。价值函数经过训练,输出状态或状态-动作对的值。但是,这个值并没有定义智能体应该采取什么动作。相反,需要根据价值函数的输出指定智能体的动作。例如,我们可以决定采用一种策略来采取始终能带来最大回报的动作(贪婪策略)。总之,该策略是一种贪婪策略,它使用价值函数的值来决定要采取的动作。 |
蒙特卡洛(MC)学习策略 |
在回合结束时进行学习。使用蒙特卡洛,等到回合结束,然后根据完整的回合更新价值函数(或策略函数)。 |
时间差分(TD)学习策略 |
每一步都进行学习。通过时间差分学习,在每一步更新价值函数(或策略函数)。 |
深度Q-Learning |
一种基于价值的深度强化学习算法,使用深度神经网络(卷积神经网络)来近似给定状态下动作的Q值。深度Q-Learning的目标是通过学习动作值来找到最大化预期累积奖励的最佳策略。 |
| 策略梯度 | 基于策略的方法的子集,其目标是使用梯度上升最大化、参数化策略的性能。策略梯度的目标是通过调整策略来控制动作的概率分布,方便更频繁地采样好的动作(最大化回报)。 |
| 蒙特卡洛强化 | 一种策略梯度算法,使用整个回合的预测回报来更新策略参数。 |
Gymnasium是一个为所有单智能体强化学习环境提供API的框架,其中包括常见环境的实现:cartpole(游戏)、pendulum(游戏)、mountain-car(山地车)、mujoco(物理引擎模拟器)、atari(游戏)等。Gymnasium包括其四个主要功能:make()、Env.reset()、Env.step()和Env.render()。Gymnasium的核心是Env,一个Python类,代表强化学习理论中的马尔可夫决策过程(MDP)(注意:这不是完美的重构,缺少MDP的几个组成部分)。该类为用户提供了生成初始状态、根据操作转换/移动到新状态以及可视化环境的能力。除了Env之外,还提供Wrapper来帮助增强/修改环境,特别是智能体观察、奖励和采取的动作。
1 | import gymnasium as gym |
我们将训练一个智能体(Agent),即月球着陆器,使其正确地着陆在月球上。智能体(Agent)需要学习调整其速度和位置(水平、垂直和角度),从而实现正确着陆。我们看到,通过观察空间形状(8,),观察到是一个大小为8的向量,其中每个值包含有关着陆器的不同信息:水平坐标(x)、垂直坐标(y)、水平速度(x)、垂直速度(y)、角度、角速度、左腿接触点是否已接触地面(布尔值)、右腿接触点是否已接触地面(布尔值)。动作空间(智能体(Agent)可以采取的一组可能的动作)是离散的,有4个动作可用:动作0-不做任何事,动作1-启动左方向的引擎,动作2-启动主发动机,动作3-启动右方向引擎。
1 | env = gym.make("LunarLander-v2") |
奖励函数(在每个时间步给予奖励的函数),每一步之后都会获得奖励。一个回合的总奖励是该回合中所有步的奖励总和。 对于每一步,奖励:随着着陆器距离着陆台越来越近或越来越远,其变化幅度会越来越大或越来越小;着陆器移动得越慢/越快,其增加/减少量就越大;着陆器倾斜越大(角度不水平),其衰减就越小;着陆器倾斜越大(角度不水平),其衰减就越小;每条腿接触地面一次,增加10分;每帧侧发动机启动时减少0.03分;主发动机启动每帧减少0.3分。该回合将因坠毁或着陆分别获得-100或+100分的额外奖励。如果某一回合得分达到200分,则该回合则被视为解决方案。我们创建了一个由16个环境组成的矢量化环境(将多个独立环境堆叠成一个环境的方法)。
1 | # Create the environment |
通过控制左、右和主方向引擎,能够将月球着陆器正确地着陆到着陆台。为此,我们将使用深度强化学习库:Stable Baselines3 (SB3)。SB3是PyTorch实现的深度强化学习算法库。为了解决这个问题,我们将使用 SB3的PPO算法。PPO(又名近端策略优化)。PPO是基于价值的强化学习方法(学习一个动作价值函数,在给定状态和动作的情况下采取的最有价值的动作)和基于策略的强化学习方法(学习一种策略,为我们提供行动的概率分布)。Stable-Baselines3设置:
- 创建环境;
- 定义模型并实例化该模型(
model = PPO("MlpPolicy")); - 使用
model.learn训练智能体(Agent),并定义训练时间步数。
1 | # Define a PPO MlpPolicy architecture |
接下来训练智能体(Agent)包含1,000,000个时间步。
1 | # Train it for 1,000,000 timesteps |
1 | --------------------------------- |
智能体(Agent)评估:将环境包装在监视器中。当评估智能体(Agent)时,不应该使用训练环境,而是创建一个评估环境。
1 | # 创建一个新的评估环境 |
接下来介绍另外一个例子“小狗Huggy捡棍子”,它是Thomas Simonini根据Puppo The Corgi创建的环境,使用的库是MLAgents。首先需要下载MLAgents代码库:
1 | # Clone the repository (can take 3min) |
下载并解压环境Huggy文件,需要将解压的文件放在./trained-envs-executables/linux/文件夹下。
1 | # 创建./trained-envs-executables/linux/ 文件夹。 |

Huggy的腿是由关节马达驱动的。为了完成目标,Huggy需要学会正确地旋转每条腿的关节马达,这样它才能移动。奖励函数的初衷是为了让Huggy完成目标:”取回棍子”。强化学习的核心之一是奖励假设:目标可以描述为预期累积奖励的最大化。在这里,目标是Huggy朝棍子走去并捡起棍子,但不要旋转太多。因此奖励函数必须转化这个目标。奖励函数:
- 定位奖励:这里奖励它接近目标。
- 时间惩罚:每次动作都给予固定时间惩罚,以迫使它尽快到达棍子所在的位置。
- 旋转惩罚:如果
Huggy旋转太多或者转得太快,就对它进行惩罚。 - 达到目标奖励:奖励
Huggy完成目标。
在用ML-Agents训练智能体(Agent)之前,你需要创建一个/content/ml-agents/config/ppo/Huggy.yaml来保存训练的超参数。
1 | behaviors: |
checkpoint_interval:每个检查点之间收集的训练时间步数。keep_checkpoints:要保留的模型检查点的最大数量。为了训练智能体(Agent),只需要启动mlagents-learn并选择包含环境的可执行文件。
1 | mlagents-learn "./config/ppo/Huggy.yaml" --env="./trained-envs-executables/linux/Huggy" --run-id="Huggy" --no-graphics |
使用ML Agents运行训练脚本。这里定义了四个参数:
mlagents-learn <config>:超参数配置文件所在的路径。--env:环境可执行文件所在的位置。--run-id: 为训练运行ID创建的名称。--no-graphics:在训练期间不启动可视化。--resume:训练模型,发生中断时使用--resume标志继续训练。
Q-Learning
在强化学习(RL)中,构建了一个可以做出智能决策的智能体(Agent)。例如,一个学习玩视频游戏的智能体(Agent)。或者一个通过决策买入以及何时卖出股票来学习最大化其收益的交易智能体智能体(Agent)。
为了做出明智的决策,智能体(Agent)将通过与环境互动从环境中学习,并获得奖励(正面或负面)作为反馈。其目标是最大化其预期累积奖励 。智能体(Agent)的决策过程称为策略Agent)应该采取的一个动作(或每个动作的多个概率)。这里的目标是找到一个最优策略RL)问题的方法:
- 基于策略的方法:直接训练策略来学习在给定状态(或该状态下动作的概率分布)下采取什么动作(
)。策略以状态作为输入,并输出在该状态下采取的动作(确定性策略:在给定状态下输出一个动作的策略,与输出动作概率分布的随机策略相反)。我们不需要手动定义策略的动作,而是通过训练来定义它。 - 基于价值的方法:训练一个价值函数来了解哪种状态更有价值,并使用该价值函数 采取该状态的动作,通过训练输出状态或状态-动作对的值的价值函数。给定这个价值函数,策略将采取动作。由于策略未经训练/学习,所以需要指定其动作。例如,如果想要一个策略,在给定价值函数的情况下,采取始终带来最大回报的动作,这时需要创建一个贪婪策略。无论你使用什么方法解决问题,你都会有一个策略。在基于价值的方法的任务,你不需要训练策略:策略只是一个简单的预先指定的函数(例如,贪婪策略),它使用价值函数给出的值来选择其动作。
在基于价值的方法中,需要学习一个价值函数,将状态映射到该状态的预期值。状态的预期值是智能体(Agent)从该状态开始并按照当前策略执行时获得的预期折扣回报。在基于策略的训练中,通过直接训练策略来找到最佳策略(表示为
现在有2种基于价值的函数:
- 状态值函数:我们将策略
下的状态值函数写成如下形式: 。对于每个状态,如果智能体( Agent)从该状态开始,然后永远遵循该策略,则状态值函数输出预期的回报。 - 动作值函数: 在动作价值函数中,对于每个状态-动作对,如果智能体(
Agent)从该状态开始,采取该动作,然后永远遵循策略,则动作值函数输出预期的回报。写成如下形式:
状态值函数与动作值函数的区别是:对于状态值函数,需要计算状态Agent)从该状态开始时可以获得的所有奖励相加。使用贝尔曼方程简化了状态值或者状态-动作对值的计算。贝尔曼方程是一个递归方程,其工作原理如下:不必从头开始计算每个状态的回报,而是可以将任何状态的值视为:
强化学习(RL)的智能体(Agent)通过与环境交互来学习。其理念是根据经验和获得的的奖励,智能体(Agent)将更新其价值函数或策略。蒙特卡洛和时间差分学习是训练价值函数或策略函数的两种不同策略,它们都使用经验来解决强化学习(RL)问题。蒙特卡洛在学习之前使用了整个经验。而时间差分学习可以在每一步
蒙特卡洛等待一个回合结束,计算Epsilon Greedy策略,即在探索(随机动作)和利用之间交替的策略,得到了奖励和下一个状态。在这一回合结尾有一个包含(State, Actions, Rewards, Next States)的多元组的列表,智能体(Agent)将所有奖励回报Agent)学习的越来越好。
时间差分学习的核心思想是利用当前的估计值来更新未来的估计值。它通过比较当前状态的价值与下一个状态的价值之间的差异(即“时间差”)来进行更新。这种方法允许智能体在每一步都进行增量学习,而不必等待整个回合结束。因为没有经历整个过程,所以没有
通过蒙特卡洛方法学习,可以从一个完整的回合中更新价值函数,使用该事件的实际准确的折扣回报。使用时间差分学习学习,可以一步一步更新价值函数,并替换了
Q-Learning是基于离线策略价值的方法,它使用时间差分学习(TD)方法来训练其动作值函数:基于价值的方法,通过训练价值或动作值函数间接地找到最优策略,该函数将告诉我们每个状态或每个状态-动作对的值;时间差分学习方法,在每一步而不是在回合结束时更新其动作值函数。Q-Learning是我们用来训练Q函数的算法,Q函数是一个动作值函数,它决定在该状态下采取动作的值。给定一个状态和动作,Q函数输出一个状态-动作值(也称为Q值)。价值和奖励的区别:状态或状态-动作对的值(价值)是智能体(Agent)从该状态(或状态-动作对)开始并根据其策略执行时获得的预期累积奖励;奖励是某个状态下执行某个动作后从环境中获得的反馈。Q函数由Q表编码,该表中的每个单元格对应一个状态-动作对值。给定一个状态和动作,Q函数将在其Q表中搜索以输出该值。

Q-Learning是一种强化学习算法。训练一个Q函数(动作值函数),其内部是一个包含所有状态-动作对值的Q表。给定一个状态和动作,Q函数将在其Q表中搜索相应的值。当训练完成后,有一个最佳的Q函数,意味着有一个最佳的Q表。如果有一个最佳Q函数,那么就有一个最佳策略。它可以表示为:Q表的内容毫无意义,因为它将每个状态-动作对初始化为0。随着智能体(Agent)探索环境并更新Q表,它将越来越接近最优策略的近似值。如下图所示,这是Q-Learning伪代码。

- 步骤一:初始化
表,需要为 表中的每个状态-动作对做初始化为 0。 - 步骤二:使用
epsilon-greedy策略选取一个动作。贪婪策略是一种处理探索/利用的策略。初始时,在训练开始时,探索的概率会很大( 值较大),这时候选择探索的策略(随机选取动作);但随着训练的进行, 表内容的值越来越接近, 值逐渐降低,这时候选择利用策略(智能体选取具有最高状态-动作对值的动作)。 - 步骤三:执行动作
,获得奖励 和下一个状态 。 - 步骤四:更新
表。
请记住,在时间差分学习(TD)学习中,在交互的一个回合之后更新策略或价值函数(取决于选择的强化学习方法)。
为了实现时间差分学习(TD)的目标,这里使用了即时奖励加上下一个状态的折扣值,记作
则
为了更新epsilon-greedy策略,它将始终采取具有最高状态-动作对值的动作。当完成此epsilon-greedy策略来选取动作。这也是Q-Learning是离线策略算法的原因。离线策略,使用不同的策略进行推理和训练;在线策略,使用相同的策略进行推理和训练。
深度Q-Learning
Q-Learning是一种用于训练Q函数的算法,Q函数是一种动作值函数,它决定了该状态下采取动作的值,Q来自于该状态下该动作的“质量”(the Quality)。但存在一个问题,由于Q-Learning是一种表格方法,如果状态和动作空间不够小,则无法用数组和表格表示,也就是说,Q表无法进行扩展。

深度Q网络(DQN)的网络架构:由3部分组成,分别是神经网络,DQN使用深度神经网络(通常是卷积神经网络)作为函数逼近器,当前状态作为输入,所有可能动作的Q值向量为输出。通过这种方式,DQN能够处理高维输入;经验回放,DQN引入了经验回放机制,将智能体与环境交互过程中获得的经验存储在一个回放缓冲区中。每次更新时,从这个缓冲区中随机抽取一批经验进行训练。这种方法可以打破样本之间的相关性,提高学习效率和稳定性;目标网络,DQN使用两个神经网络:一个是主网络(用于选取动作),另一个是目标网络(用于计算目标Q值)。目标网络的参数定期更新,以保持相对稳定。这有助于减少训练过程中的波动性。
深度Q-Learning算法使用深度神经网络(卷积神经网络)来近似某一状态下每个动作的Q值(价值函数预测)。与Q-Learning算法不同之处在于,在训练阶段,不会直接更新状态-动作对的Q值;而是创建一个损失函数,用于比较预测Q值与目标Q值,并使用梯度下降来更新深度Q网络(DQN)的权重,为了更好的接近目标Q值。这里Q-Target记作Q-Loss记作为:Q-Learning训练可能存在不稳定性,主要是结合了非线性Q值函数(神经网络)和引导程序(使用现有预测而不是实际的、完整的回报来更新目标)。为了实现稳定训练,有3种不同的解决方案:
- 经验回放,使经验利用变得更加高效。
- 固定
Q-Target以稳定训练。 - 双重深度
Q-Learning,解决Q值预测过高的问题。
深度Q-Learning的经验回放有两个作用:1、在训练过程中更有效地利用经验。通常,在在线强化学习中,智能体(Agent)与环境交互,获得经验(状态、动作、奖励和下一个状态),从中学习(更新神经网络),然后丢弃它们。这种方式效率不高。经验回放有助于更有效地利用经验。使用回放缓冲区来保存经验,并在训练期间重复使用的经验样本,这使得智能体(Agent)可以从相同的经验中多次学习;2、避免忘记之前的经验(又称灾难性遗忘),从而减少经验之间的相关性。灾难性遗忘:如果将连续的经验样本提供给神经网络,那么就会遇到一个问题,当它获得新的经验时,就会忘记旧的经验。解决方案:创建一个重放缓冲区,在与环境交互时存储经验元组,然后对一小批元组进行采样。这样可以防止网络只学习它之前做过的事情。经验回放还有其他好处。通过随机抽样经验,可以消除观察序列中的相关性,并避免动作值发生剧烈震荡或发散。如下图所示,在Deep Q-Learning伪代码中:

初始化一个容量为N的重放内存缓冲区D(N是定义的超参数)。然后,将经验存储在重放内存缓冲区中,并在训练阶段抽取一批经验来提供给深度Q网络。使用具有固定参数的单独网络来预测TD目标,每隔C步从深度Q网络复制参数以更新目标网络。
双重深度Q网络:又称双重深度Q学习神经网络,由Hado van Hasselt提出 。此方法可解决Q值预测过高的问题。在计算TD目标时,如何确定下一个状态的最佳动作是Q值最高的动作?解决方案是:当计算Q目标时,使用两个网络将动作选取与目标Q值分离。使用DQN网络来选择下一个状态的最佳动作(具有最高Q值的动作)。使用目标网络来计算在下一个状态下采取该动作的目标Q值。
策略梯度
强化学习(RL)的主要目标是找到最优策略RL)是基于“奖励假设”:所有目标都可以描述为预期累计奖励的最大化。例如,在一场足球比赛中,您将训练两个智能体(Agent),目标是赢得比赛。我们可以在强化学习(RL)中将此目标描述为最大化对方球门的进球数(当球越过球门线时),并最小化自己球门的进球数。基于价值的方法:通过最优价值函数来实现最优策略
- 在基于策略的方法中,直接搜索最优策略。通过使用
hill climbing、模拟退火或进化策略等技术最大化目标函数的局部近似值来优化参数。 - 在基于策略梯度方法中,由于它是基于策略的方法的子集,直接搜索最优策略。但优化参数
直接通过对目标函数的性能进行梯度上升 。
策略梯度方法优点:集成简单,可以直接预测策略,而无需存储额外的数据;策略梯度方法可以学习随机策略,而价值函数则不能;策略梯度方法在高维动作空间和连续动作空间中更有效;策略梯度方法具有更好的收敛特性。策略梯度方法缺点:通常,策略梯度方法会收敛到局部最大值而不是全局最大值。策略梯度逐渐变慢,训练可能需要更长的时间(效率低下)。策略梯度可能具有较高的方差。
策略梯度的目标是通过调整策略来控制动作的概率分布,以便将来更频繁地采样好的动作(最大化回报)。每次智能体(Agent)与环境交互时,都会调整参数,以便将来更有可能采样好的动作。但是要如何利用预期回报来优化权重呢?随机策略记作Agent)的性能,并输出预期累积奖励。记作
:从任意轨迹获得的回报。要获取此量并用它来计算预期回报,需要将其乘以每个可能轨迹的概率。 :每个可能轨迹的概率 (该概率取决于 ,因为它定义了用于选择轨迹动作的策略,而该策略会对所访问的状态产生影响) 。 :预期回报,通过对所有轨迹求和,给定 乘以该轨迹的回报,得出采取该轨迹的概率。我们的目标是通过找到输出最佳动作概率分布的 来最大化预期累积奖励: 。
策略梯度是一个优化问题:想要找到最大化目标函数2个问题:
- 无法计算目标函数的真实梯度,因为它需要计算每条可能轨迹的概率,这在计算上代价非常大。所以使用基于样本的预测值(收集一些轨迹)来计算梯度预测值。
- 为了区分这个目标函数,需要区分状态分布,称为马尔可夫决策过程动力学,这与环境有关。它给出了环境进入下一个状态的概率,考虑到当前状态和智能体(
Agent)采取的动作。问题是无法区分状态分布。
解决办法是使用策略梯度定理,它将目标函数重新表述为可微函数,而不涉及状态分布的微分。记作
- 使用策略
来收集一个回合的 。 - 使用回合来预测梯度
。 - 更新策略的权重
。