机器学习(ML)(十七) — 搜索引擎探析
介绍
搜索引擎是一种根据用户需求,通过特定算法和策略从互联网上检索信息并反馈给用户的系统。搜索引擎可以被定义为一个自动化系统,它通过计算机程序从互联网收集信息,经过组织和处理后,为用户提供检索服务。搜索引擎的发展经历了多个阶段:第一代搜索引擎(1994):以人工分类为主,代表有Yahoo;第二代搜索引擎:利用关键字进行查询,Google是其代表;第三代搜索引擎:强调个性化和智能化,结合人工智能技术;第四代搜索引擎:应对信息多元化,采用更精确的特征提取和文本处理技术。
搜索引擎的工作过程可以分为以下几个主要步骤:
- 爬虫(
Crawl):网络爬虫自动在互联网上抓取网页信息,并存储到数据库中。 - 解析(
Analyze):对抓取到的数据进行格式化处理和清洗。 - 索引(
Index):将处理后的数据构建索引,以便快速检索。 - 检索(
Search):根据用户输入的查询内容,从索引中找到相关文档。 - 排序(
Rank):根据相关性等因素对检索结果进行排序,并返回给用户。
决定搜索引擎的用户满意度包括3个因素:相关性、内容质量、时效性、个性化。
相关性(Relevance):在搜索中,相关性指的是查询词与文档 两者的关系。相关性是一个客观的标准,不带有个性化,相关性只取决于 和 ,而不取决于用户 (如果大多数有背景知识的人认为 相关,则判定为相关)。相关性是语义上的,不是字面上的(相关是指 能满足 的需求或回答 提出的问题)。查询词 可能有多重意图,只要 命中 的一种主要意图,则 算相关。搜索引擎链路上有召回、粗排、精排这些环节,每个环节都需要计算相关性,搜索召回得到的文档数量很大,至少有几万,在输入排序之前需要进行初步的筛选,过滤掉相关性很低的文档,这个过程叫做召回海选,这里可以用很简单的办法计算相关性,比如文本匹配分数或双塔 BERT模型粗略地估计相关性。粗排阶段候选文档数量为几千,用双塔BERT模型或浅层交叉BERT模型计算相关性。精排阶段候选文档数量是几百,用交叉BERT模型计算相关性。EAT是谷歌提出的内容质量评价标准,相关文档,请参考:search quality evaluator guidelines,对于your money or your life方面的查询词,EAT是排序的重要因子。you money包括:金融理财(保险、报税、投资、贷款、转账等)、电商、购物;your life包括:医疗健康(诊断建议、用药建议、医院介绍、减肥等)、法律等严肃主题(诉讼、移民、选举、离婚、收养)、对人生产生重大影响的主题(高考、择校、出国、就业)。对于严肃和重要的主题,搜索排序应该给EAT很高的权重,如果不重视EAT,搜索引擎损失的不只是用户的体验和主观感受,甚至会造成危害。内容质量:一方面是文章本身的价值,文章是否清晰、全面,事实是否准确,信息是否有用;另一方面是作者的态度和水平,写作是否认真、写作的专业程度、写作的技巧。最后还有文章的意图(有益、有害)。图片质量(视频质量),分辨率、有无水印、是不是截图、图片是否清晰、图片的美学等。内容质量不是一个分数,而是有很多个分数,都会在搜索排序中起作用。对于每个文本质量分数,都有一个专门训练的模型(可以是BERT等NLP模型、CLIP等多模态模型)。训练模型的数据是人工标注的,手下按指定分档规则,比如文本质量分为高、中、低3个档位,然后让人工做标注,给每个定义一个档位。有了了数据就可以训练模型,通常来说模型首先要做预训练,然后采用人工标注的数据做微调,人工标注的数据可多可少,文本质量分数都是静态的,只需要训练一次就够了。在文档发布、或被检索的时候,用模型打分,分数存入文档画像中(搜索排序的时直接读取文档画像)。时效性:如果查询词是query =“最新房贷政策”、“美元汇率”,这时文档的年龄很重要;query =“泰国旅游”、“网红探店”,它们有时效性需求,但是此需求不强。查询词对时效性需求越强,那么文档的年龄权重也就越大。可以看出,优化搜索时效性的关键是识别查询词的时效性意图(即查询词对“新”的需求)。工业界通常对时效性做个分类:突发时效性、一般时效性(强、中、弱、无)、周期时效性。搜索引擎主要通过数据挖掘、语义模型来识别这几种时效性意图。突发时效性,若查询词涉及突发新闻、热点事件,则查询词就带有突发时效性。如果查询词带有突发时效性意图,那么用户大概率是想看最近发布的文档。搜索引擎识别突发时效性的方法是通过数据挖掘为主,比如挖掘站内搜索量激增的查询词;挖掘站内发布量激增的关键词;抓取其他网站的热词。只能通过数据挖掘来判断突发时效性。一般时效性,只看查询词字面意思就可以判断时效性意图的强弱。一般时效性可以根据需求的强弱,分为强、中、弱、无,搜索引擎会使用BERT等语义模型来识别一般时效性。周期时效性,在每年特定的时间表现为突发时效性,在其他时间表现为无时效性,例如双十一、春晚小品、高考作文、奥斯卡等。周期时效性可以不做任何处理(当查询词表现为突发时效性时,会被算法挖掘到),可以做人工标注、数据挖掘识别周期时效性查询词。个性化:搜索引擎可以带有个性化,考虑到不同用户有不同的偏好,在排序的时候,搜索引擎可以根据用户特征做排序(类似推荐系统)。查询词越宽泛,就越需要个性化排序;预估点击率和交互率有利于提升相关性和内容质量。
最后搜索引擎会结合相关性、内容质量、时效性、个性化(预估点击率和交互率)等因子对候选文档做排序。
评价指标
搜索引擎的评价指标分为3类:北极星指标,包括用户规模(DAU、MAU、搜索渗透率 = Search DAU / DAU)、留存(次日留存、LT7、LT30);中间指标,包括文档点击率、有点比、首屏有点比、首点位置、主动换词率、交互指标;人工体验评估,包括side by side评估、月度评估。side by side评估的指标是Good Same Bad (GSB),如果新策略更优记作Good(G);如果两者持平,记作Same(S);如果旧策略更优,记作Bad(B),月度评估的指标是Discounted Cumulative Gain (DCG),每个月随机抽取一批搜索日志,每条搜索日志包含查询词DCG评价一次搜索DCG值就越大。一个DCG分数是对一个收缩结果页的评价,如果每个月随机抽取2000个搜索结果页,那么就有2000个DCG分数,去这些DCG分数的均值,作为月度评估的结果。月度评估可以自我对比,看本月的DCG是否由于历史上往期的DCG,可以通过DCG分数考察搜索团队有没有让用户体验逐渐变好,也可以用DCG分数来来评价竞争对手。
搜索链路
搜索引擎的链路主要分为3个环节(如下图所示):分别是查询词处理、召回、排序。当用户输入查询词之后,首先做查询词处理,查询词处理包含很多模块,包括分词、词权重、类目识别、意图识别、查询词改写。链路上的第二个环节是召回,从海量的文档中找出与查询词相关的几万篇文档,这里会有几十条召回通道同时运行,各自有一些配额。召回结束之后,会用简单的规则做初步的筛选,把文档数量降低到几千,然后再送去排序服务器。搜索链路上最后一个环节是排序,它决定搜索结果页上文档展示的顺序,排序比较复杂,需要计算相关性、点击率等很多分数,然后用规则和模型融合这些分数,给出最终的排序。搜索引擎的排序比推荐系统的排序要复杂很多。推荐系统的排序主要靠预估点击率和交互率,搜索引擎的排序也要预估点击率和交互率,把它们作为个性化分数,此外还需要相关性、内容质量、时效性等分数。要综合所有这些分数做排序,在这些分数中,相关性的分数是最重要的。
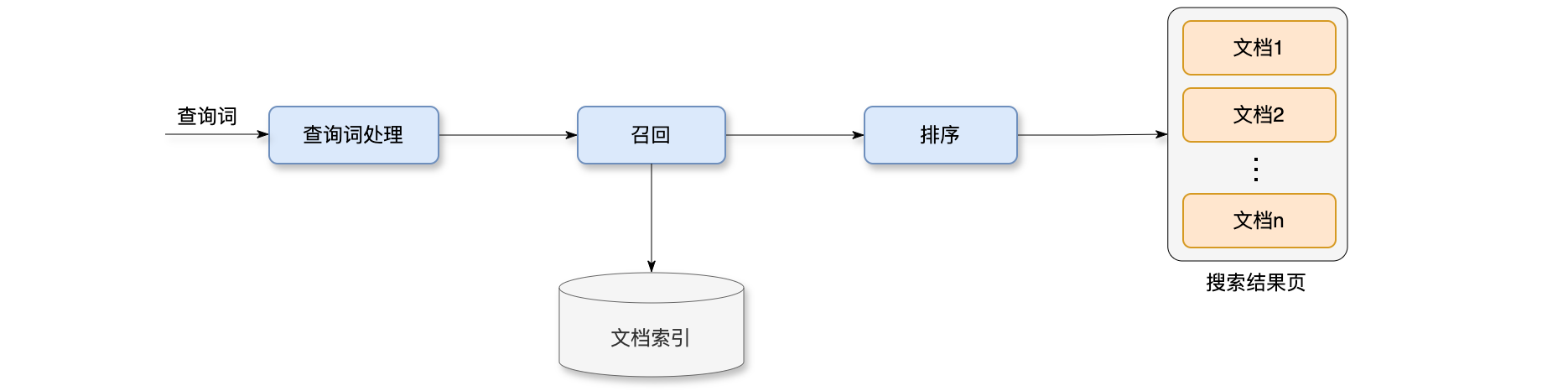
搜索引擎的链路各环节详细介绍:
- 查询词处理:用户搜索查询词之后,系统会调用很多个查询词处理的服务,包括分词、词权重、类目识别、意图识别、查询词改写等。这些模块输出的结果会被下游的召回用到,查询词处理的重要性不高,只要有分词就可以做文本召回,搜索引擎就能勉强工作了,如果有向量召回,那么连分词都不需要。查询词有一个缓存,查询词命中缓存,就直接读取缓存中的查询词处理结果,不需要调用各个服务做计算。对于通用搜索引擎,几百万个高频查询层就能覆盖每天大部分搜索请求,也就是说,对几百万个高频查询词作缓存,就能避免查询词处理环节大部分的计算。查询词处理中必不可少的模块是分词(
Tokenization),例如用户输入查询词:“冬季卫衣推荐 -> 冬季/卫衣/推荐”,搜索引擎为什么做分词呢?分词(Tokenization)主要是给文本召回使用,查询词被切成多个term之后,会用这些term在倒排索引中检索文档。倒排索引的key大多是“冬季”、“卫衣”、“推荐”等这样的常用词,数量不大。假如不做分词,则倒排索引的key是“冬季卫衣推荐”这样的词,倒排索引会过于巨大,带来工程上的困难。所以作文本召回,必须将查询词切分成多个term。词权重(Term Weight)也是查询词处理的一个模块,词权重(Term Weight)不是必要的,但是对搜索引擎很有用。例如查询词还是:“冬季卫衣推荐 -> 冬季/卫衣/推荐”,分词切成了3个term,这3个term的重要性不同,词权重:“卫衣 > 冬季 > 推荐”。搜索引擎为什么要计算词权重呢?主要是为了给召回使用。如果查询词太长,没有文档可以同时包含其中所有词,所以需要丢弃不重要的term。计算查询词与文档的相关性时,可以用词权重做加权。类目识别,查询词还需要做类目识别,每个平台都有各自的多级类目体系。搜索引擎会使用NLP技术识别文档、查询词的类目。这属于多标签分类问题,一篇文档或查询词有可能属于多个类目,文档类目识别是在文档发布的时候离线做;而查询词类目识别是在用户做搜索的时候在线做。类目识别的结果会给下游的召回、排序用,召回模型、排序模型将文档、查询词类目作为特征。查询词意图识别,首先是时效性意图:查询词对文档“新”的需求,召回和排序均要考虑文档的年龄;地域性意图:对于地域性意图的查询词,召回、排序不止需要文本的相关性,还需要结合用户定位地点,查询词提及的地点、文档定位的地点;用户名意图:如果用户想要找平台的某位用户,输入的查询词是用户名或ID字符串,如果搜索引擎判定查询词带有用户名意图,就应当检索用户名的数据库,而非检索文档数据库;求购意图,用户可能想要购买商品,需要同时在文档库、商品库中做检索;查询词改写:如果把查询词改写做好,搜索引擎的评价指标会提高很多,用户输入查询词,算法将其查询词改写成多个查询词 (独立用 做召回,对召回的文档取并集)。查询词改写有什么用呢?第一,解决语义匹配、但文本不匹配的问题;第二,是解决召回文档数量过少的问题,如果查询词的表达不规范、或查询词太长,会导致召回结果很少。 - 召回:给定查询词
,从文档库(数亿篇文档)中快速检索数万篇可能与 相关的文档 。这里同时有几十条召回通道,这些召回通道都有不同的配额。文本召回:就是最简单的文本匹配,借助倒排索引匹配 中的词与 中的词,文本召回是最传统的搜索引擎技术。在深度学习之前,搜索引擎只有文本召回。现在向量召回的重要性已经超过了文本召回;向量召回:就是用BERT这样的深度学习技术,将 和 表征为向量 和 ,给定查询词的向量 ,在向量数据库中做 ANN查找,召回向量相似度高的文档,除了文本召回、向量召回,搜索引擎还有一些构造的 KV索引,主要用于高频查询词的召回。KV召回:对于高频查询词,离线建立 这样的 key-value索引,把查询词作为key,把文档列表作为value,在线上如果查询词命中索引,就可以直接读取索引上存储的文档。 - 排序:排序的依据,相关性:重要性最高,在线上用
BERT模型实时计算查询词和文档的相关性;内容质量:指文档的文本和图片质量,以及作者网站的EAT。算法离线分析文档的内容质量,把多个分数写到文档画像中;时效性:主要指查询词对“新”的需求,查询词处理分析时效性,把结果传递给排序服务器;个性化:在不同的搜索引擎中,个性化的重要性各不相同。在线上用多目标模型预估点击率和交互率。
文本召回流程:离线处理文档,建立倒排索引(给定词
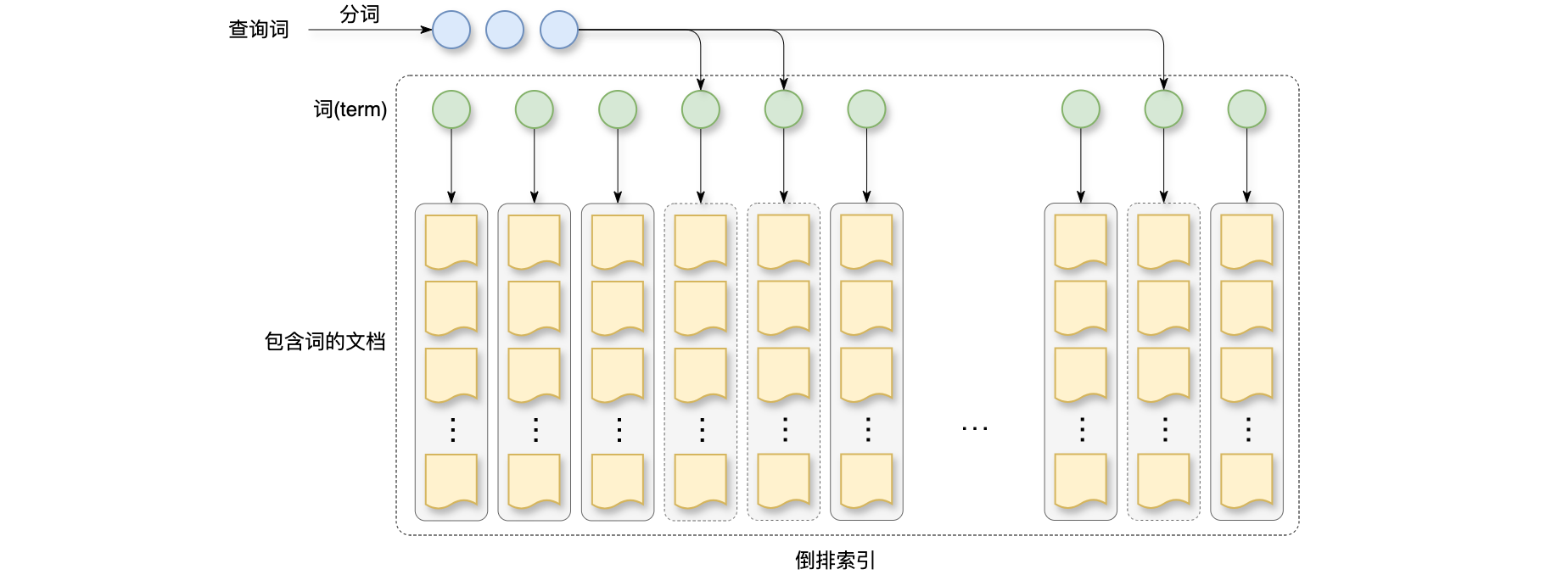
向量召回流程:借助深度学习技术,把查询词和文档表征为向量。在线上通过最近邻查找,检索与查询词相关的文档,如下图所示,左右两边各有一个神经网络,这种模型叫做双塔模型,左边的网络将查询词表征为向量,神经网络的输入是查询词文本,以及查询词类目等特征;右边的神经网络将文档表征为向量,它的输入是文档文本,以及文档类目等特征。两个神经网络输出形状相同的向量,于是可以计算两个向量的内积或余弦相似度,训练模型的时候用相关性、点击作为预测的目标。文档的向量表征是离线计算好的,存入了向量数据库。查询词的向量表征是线上实时计算得,查询词很短,所以左边神经网络推理代价不大。在线上做召回的时候,给定查询词的向量表征,在向量数据库中做ANN查找,找到相似度最高的一批文档,作为召回的结果。
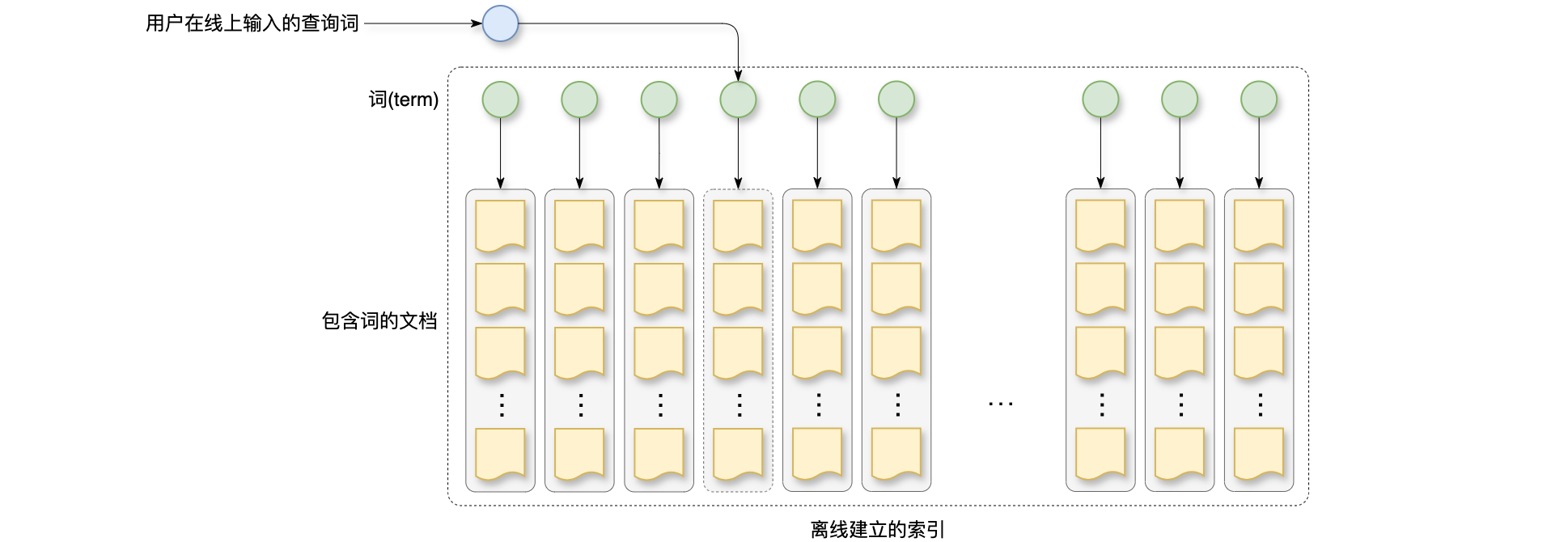
KV召回流程:如下图所示,图上画的是离线建立的索引,索引上的key是高频查询词,这些都是用户真实搜过的查询词,再过去一段时间内,搜索的次数高于某个阈值,索引的value是文档列表,每个查询词都对应很多篇文档,由于离线做过筛选,上面的查询词与下面的文档具有高相关性。当用户在线上输入一个查询词,要去下面检索索引,如果用户搜索的是一个高频查询词,就会命中索引,线面这些文档就是对应召回的结果,构造索引的时候做过筛选,索引存的文档都与查询词高相关,这样做召回的效率很高。
相关性 - 定义与分档
工业界做搜索相关性有一套比较成熟的流程(制定标注规则 -> 标注数据 -> 训练模型 -> 线上推理),首先是制定相关性的标注规则,然后人工标注数据,在做监督学习训练模型,最终把模型部署在线上做推理。通常是由搜索产品和搜索算法团队来定义相关性标注规则,制定规则的时候,人为将
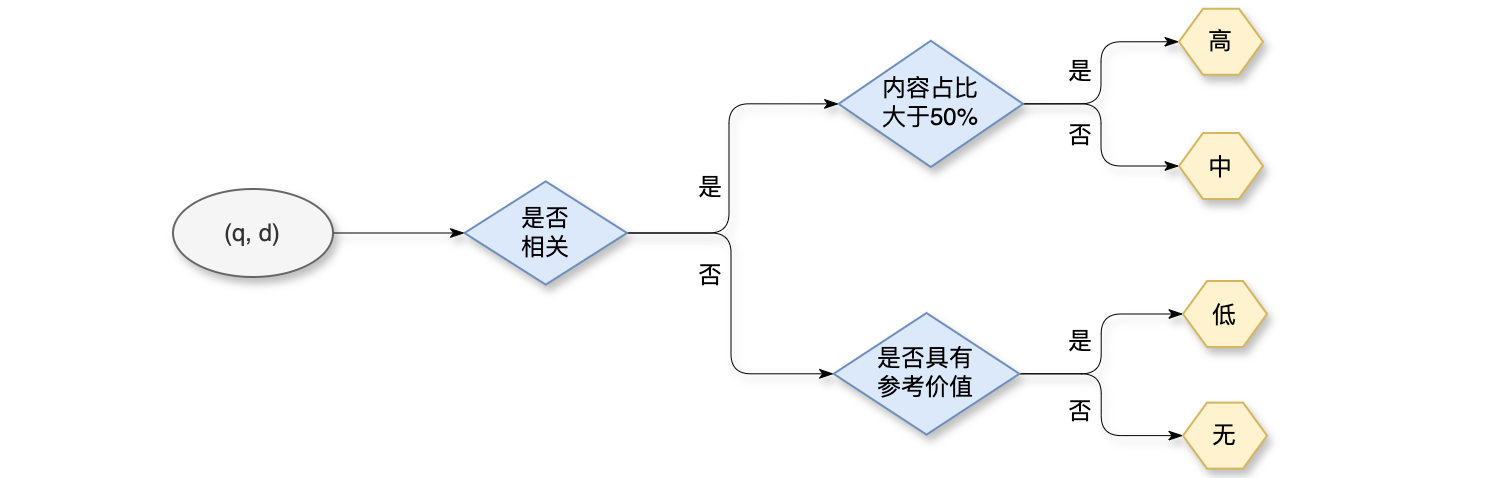
标注员首先判断
档位细分:给定查询词50%,则判定为高相关性,否则判定为中相关性;如果不相关,就进一步判定内容是否具有参考价值,如果有参考价值,则判定为低相关,否则判定为不相关和参考价值。
相关性 - 评价指标
相关性的评价指标,包括Pointwise评价指标:Area Under the Curve (AUC)、Pairwise评价指标:正逆序比(Positive to Negative Ratio, PNR)、Listwise评价指标:Discounted Cumulative Gain (DCG)。用AUC和PNR作为离线评价指标,用DCG评价模型在线上的排序效果。
Pointwise评价指标:用Pointwise评价相关性的时候,会把相关性看做二分类问题,训练集还是用4个小档位,但是测试集只用2个大档位。测试集的标签只有0/1,把高、中两档合并,作为标签;把低、无两档合并,作为标签 。以及训练好的相关性模型输出预测值 。 指越大,模型认为查询词与文档越有可能相关,评价二分类的指标有很多种,工业界最常用AUC来评价搜索相关性。 Pairwise评价指标:意思是每次取2个二元组作对比,正逆序比(PNR)是Pairwise评价指标,实际做排序的时候,给定一个查询词和很多文档,让模型根据查询词估计每篇文档的相关性,根据估计的分数对文档做排序。注意一下,排序使用的模型估计的分数,不是真实的相关性分数。给定一个查询词和篇文档,对文档做两两组合,则有 种组合,一个二元组可以是正序对,也可以是逆序对。 Listwise评价指标:设有篇候选文档,根据模型打分做降序排列,把排序好的文档,记作 , 真是相关性分数为 (人工标注相关性档位,档位映射到 [0,1]之间的实数),如果模型的排序是正确的,那么降序排列,也就是说模型的排序与真实的排序是一致的,这种情况下, Pairwise与Listwise指标都最大化,如果出现逆序对,Pairwise与Listwise指标都减小,逆序对越多,则指标越差。对于Pairwise指标来说,逆序对出现在哪里都无所谓,逆序对出现的位置不影响Pairwise指标,只有逆序对数量才会影响Pairwise指标。但是逆序对出现的位置会对Listwise指标有影响。逆序对越靠前,对Listwise指标造成损失就越大。Cumulative Gain(CG):设有篇候选文档,根据模型打分做降序排列,他们真实的相关性分数为 。但一般只关注排在前 的文档,它们最有可能获得曝光,对用户的体验影响最大。 Cumulative Gain记作。CG可以评价排序做的准不准,CG何时最大化?真实相关性分数 最高的 篇文档被模型排在前 ,那么 CG指标会最大化。前篇文档的序不重要,它们之间可以存在逆序对。这些逆序对不影响模型指标。DCG:设有 篇候选文档,根据模型打分做降序排列,他们真实的相关性分数为 。 Discounted Cumulative Gain记作, DCG何时最大化?真实相关性分数最高的 篇文档被模型排在前 ,前 篇文档不允许存在逆序对。
离线评价指标:事先准备人工标注的数据,划分为训练集和测试集。完成训练之后计算测试集上的AUC和PNR。线上评价指标:一个搜索session,用户搜索session,覆盖高、中、低频查询词。对于每个搜索session,只保留排序最高的DCG(session都有一个DCG分数,分数越高,你就说明相关性越好。把所有的搜索session取平均,就能反应线上相关性模型的好坏。
相关性 - 文本匹配
搜索引擎的召回都需要计算查询词与文档的相关性,召回结束之后,会做一个简单简单的排序,也叫作“召回海选”,有几万篇候选文档,需要计算它们与查询词的相关性,由于打分量很大,需要模型足够快,比如用文本匹配 + 线性模型计算相关性分数,也可以用双塔BERT模型,推理代价不大。召回海选之后,有几篇文档需要进行粗排,粗排可以用单塔BERT、双塔BERT模型,单塔BERT也叫交叉BERT模型,双塔的推理代价很小,准确性不高;单塔模型推理代价大,但准确性好。最后是精排,只给几百篇文档打分,可以用较大的模型,业界通常用单塔BERT模型,可以是4、6、12层。
传统的搜索引擎使用几十种人工设计的文本匹配分数,作为线性模型或树模型的特征,模型预测相关性分数。文本匹配包括:词匹配分数(TF-IDF、BM25)、词距分数(OKaTP、BM25TP)、类目匹配和核心词匹配等,目前搜索排序普遍放弃文本匹配,改用BERT模型,仅剩文本召回使用文本匹配做“海选”。
- 词匹配分数(
TF-IDF、BM25):对于中文来说,想要计算词匹配分数,首先要分词,把查询词和文档切分成很多小字符串。每个小字符串是一个词,称为term。比如这个查询词,分词得到: , 中的 term在文档中出现的越多,则 与 越可能相关。分词结果记作 ,例如: , 是一个词( term),每次只看一个term,例如, 在文档 出现的次数叫做词频,记作 ,词频 越大,说明 与 越可能相关。查询词 中包含多个 term,我们可以计算每个term在文档中的词频,然后再把它们相加,记作, 越大,则 与 越可能相关。用词频 衡量相关性有一个缺陷:文档 越长,则 越大。解决方法:用文档 的长度(记作 )对词频做归一化。将原有的 改为 ,消除文档长度的影响。但是 衡量相关性任然有缺陷,加和同等对待所有 ,查询词中的各个 term重要性各不相同,term不该被同等对待。应该根据term的重要性设置权重,对词频term加权求和。那么如何设置每个term的权重?最好的方法是根据语义重要性(term weight)来设定。语义重要性(term weight)由查询词处理环节来负责计算。词频term在多少文档中出现过,记作,假设数据集一共有 篇文档, 的大小介于 0~N之间,如果一个term的很大,说明这个 term在很多个文档中出现过,说明这个term判别能力较弱,应当设置较小的权重。Inverse Document Frequency(IDF)定义为,每个 term都有自己的IDF,IDF只取决于文档的数据集。对于人工智能论文数据集,“深度学习”的IDF很小,对于维基百科数据集,“深度学习”的IDF很大。可以衡量 term的重要性,越大,词频 term越重要。原本用衡量相关性,改用加权和 。 TF-IDF的全称为Term Frequency——Inverse Document Frequency,查询词的分词结果记作 ,它与文档 的相关性可以用 TF-IDF来衡量:。 BM25:如果学习一个线性模型或树模型预测相关性,那么BM25的相关性的特征权重是最高的,可以把BM25看作是TF-IDF的一个变体:,其中 和 是参数,通常设置 和 。 BM25对传统的搜索相关性很重要。TF-IDF、BM25都属于词袋模型,它们都隐含了词袋模型的假设:只考虑词频,不考虑词的顺序和上下文。词袋模型的缺点:它完全忽略了词序和上下文,不利于准确计算相关性。在深度学习之前有很多词袋模型,例如Latent Semantic Analysis(LSA)、Latent Dirichlet Allocation(LDA)。它们可以使查询词映射成向量,RNN、BERT、GPT都不是词袋模型,它们会考虑词的顺序和上下文,更好的理解查询词和文档的语义,做出更准确的预测。BERT和GPT是当前最优的模型,在自然语言任务上远优于各种词袋模型。 - 词距分数(
OKaTP、BM25TP):例如查询词是,文档 是“我在亚马逊网购了一本书,介绍东南亚热带雨林的植物群落…”,文档 同时包含亚马逊、雨林两个词,会被文本召回检索到,虽然查询词 与文档 的文本匹配,但文档并没有满足查询的需求,所以两者不相关。如果用词匹配分数( TF-IDF、BM25)计算相关性,会得出错误的结论。想要避免这类错误,需要用到词距。词距:查询词中的两个词出现在文档 中,两个 term中间间隔多少term。两个term间隔越小,也就是词距越小,则与 越相关。计算词距方法有 OKaTP、BM25TP。OKaTP:词在文档 中出现的位置记作集合 ,假设 出现在文档 中第 27、84、98位置上,那么。这个集合 大小等于词频: 。设 是查询词 中的两个词,它们的词距分数为: 。根据上面公式中的定义,查询词中的 在文档 中出现次数越多、距离越近,则词距分数 越大。 OKaTP定义为:。
相关性 - BERT模型
当前工业界的搜索引擎普遍使用BERT模型计算BERT模型也叫单塔模型,把查询词和文档拼成一个序列输出BERT模型,这种模型的准确性好,但是推理的计算量很大,通常用于搜索链路的下游(精排)。双塔BERT模型不够准确,但是推理代价很小,常用于链路的上游(粗排、召回海选)。不论用哪种BERT模型,训练的方法都是相同的,有4个步骤:预训练、后预训练、微调、蒸馏。
交叉BERT模型:如下图所示,这是交叉BERT模型的结构,模型的输入包括查询词、标题、正文等。交叉的意思是自注意力层对查询词和文档做了交叉。输入的查询词、标题、正文会被切分成token,每个token可以是汉字词、拉丁字词、英文字母或其它的字符串,token会被embedding层表征为向量,具体用了3种embedding:第一种是token embedding,表征token本身,每个token对应一个embedding向量;第二种是position embedding,翻译成位置编码,表征token的序,意思是token出现在第几个位置;第三种是segment embedding,用于区分查询词、标题、正文3个不同的字段。每个token就被表征为3个向量,取向量的加和就是token的表征。模型的输入有token,被表征为[0,1]之间的实数,作为相关性分数。对于中文有2种分词的粒度:字粒度和字词混合粒度,字粒度很简单,就是把每一个汉字/字符作为一个token,用字粒度时,词表很小(embedding table也很小),只有几千,只包含汉字、字母、常用字符。用字粒度的好处是实现简单,不需要做分词。所以第一个版本的相关性,最好用字粒度,实现起来简单;字词混合粒度:需要做分词,将分词结果作为tokens,这种方法更复杂,效果更好。用字词混合粒度,词表比较大(几万、几十万),包括汉字、字母、常用符号、常用中文词语、常用英文单词。与字粒度相比,字词混合粒度得到的序列长度更短(即token的数量更少)。BERT的计算量是token数量的超线性函数,介于线性和平方复杂度之间,自注意力层是平方时间复杂度,全连接层是线性时间复杂度。序列越长推理代价越大,文档可能很长,有几百个token,为了控制推理成本,会限制token的数量。例如128或256,把token长度限定的越短,推理成本也就越低。如果文档长度太长,超出token数量的上限,会被截断,或者做抽取式摘要,但这样会使准确性降低。跟字粒度相比,字词混合粒度token数量会减少一半,token数量少了推理成本降低(如果字粒度需要256 token,则字词混合粒度只需要128 token)。做排序的时候,要给每个score,代价很大。最常用的办法是内存换计算,用Redis数据库缓存key,相关性分数(socre)作为value,存储在Redis里面。线上做排序的时候,要计算相关性,如果50%以上的推理成本,如果超出内存上限,按照LRU清理缓存,腾出空间。模型量化技术也是一种常见的推理降本方案。神经网络的参数都是用浮点数表示的,通常用float32表示单精度浮点数,占32个byte的存储,如果float32压缩成int8,推理会快很多。但是会丢失一些精度,模型量化技术就是丢失的精度尽量少,现在int8量化技术已经很成熟了,用在相关性上损失的精度可以忽略不计。量化技术主要分为两种:训练后量化(PTQ)和训练中量化(QAT)。训练后量化(PTQ):就是训练不变,训练完了再做量化,把float32压缩成int8低精度整数;训练中量化(QAT):训练和量化是结合在一起做的,训练模型的时候,要做前向传播和反向传播,前向传播使用量化后的低精度整数做计算,反向传播仍然使用原始的浮点数权重和浮点数梯度。使用文本摘要技术降低token数量,做推理的时候,会给token数量设置一个上限,比如128,超过了上限就会做截断,把超出部分给丢弃掉,做截断肯定会使模型计算出的相关性分数变得不准确,文档越长,截断的越多,损失就越大。如果文档超出了上限,可以用摘要替换文档,摘要是在文档发布的时候做,只做一次,传统的是抽取式摘要,去一些句子或段落,未来的趋势是生成式摘要,比如用大语言模型生成摘要,效果会优于抽取式摘要,如果摘要效果好,可以将token数量上限降低,比如从128降低到96。

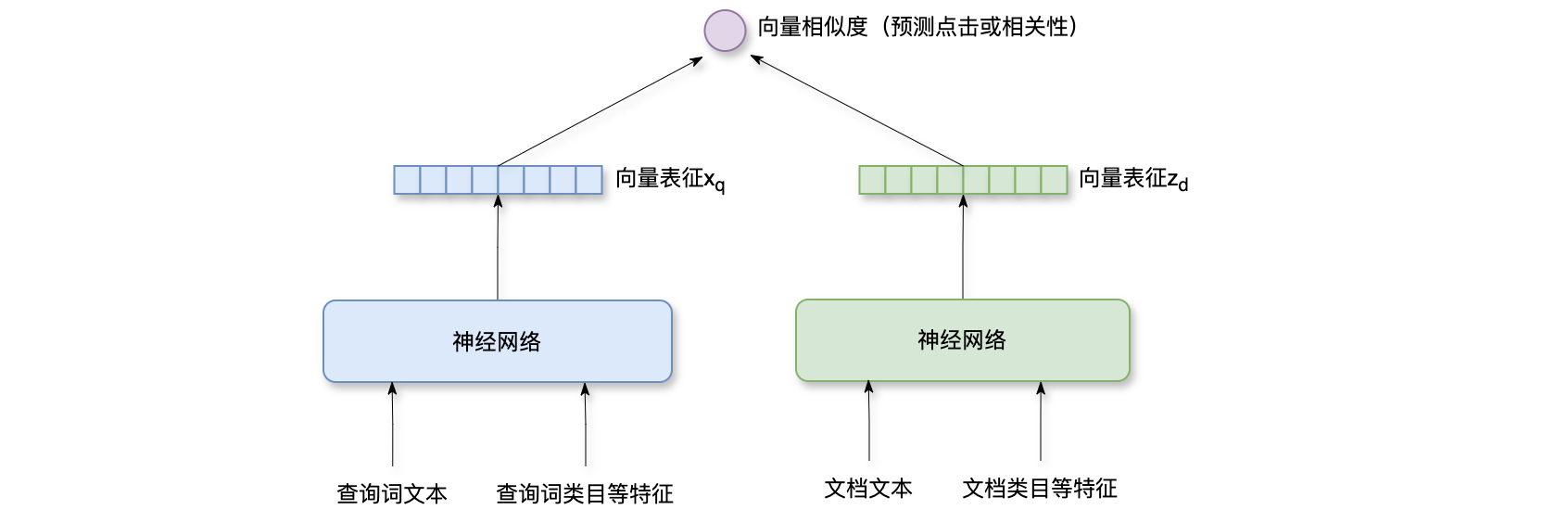
双塔BERT模型:如下图所示,双塔BERT模型的示意图,左右两边各有一个神经网络,左边的神经网络把查询词映射成向量,右边的神经网络把文档映射成向量,左边BERT模型的输入是查询词文本,查询词很短,所以这部分的推理代价很小。左边全连接网络的输入是查询词类目等特征,这些特征是由查询词处理环节所提供,左边再经过一个浅层的全连接网络,最终得到向量BERT模型的输入是文档文本,右边全连接网络的输入是文档类目等特征,右边再经过一个浅层的全连接网络,最终得到向量token,那么BERT模型每次推理都要做很多计算,而且每次粗排都要给几千篇文档打分,在线上做几千次推理,代价会非常大。所以右边的神经网络不会在线上做推理,而是在文档发布的时候做一次推理,把算出的文档向量表征存储起来(将

训练相关性BERT模型,训练分为4个步骤:预训练(pretrain)、后预训练(post pretrain)、微调(fine tunning)、蒸馏(distillation)。预训练(pretrain):就是用MLM等任务预训练模型,用自己的搜索引擎文档库做训练效果会更好;后预训练(post pretrain):是一种比较新的技术,简单的说就是利用用户的点击、交互数据训练相关性模型,点击、交互与相关性有很强的关联,相关性越好的文档 ,越有可能被点击、交互;微调(fine tunning):就是用人工标注的相关性数据训练模型;蒸馏(distillation):就是把大模型变小,线上用小的模型做推理,先训练大模型,再蒸馏小模型,效果远好于直接训练小模型。
- 微调(
fine tunning):微调用监督学习训练模型,让模型估计和 的相关性。微调需要人工标注的数据通常是几十万、几百万条样本,每条样本记为 ,分别是查询词、文档和人工标注的相关性分数。做训练的时候,可以把估计相关性看作是回归任务,也可以看做是排序任务。回归、排序任务拥有不同的损失函数,回归任务让预测的值 拟合 ,起到“保值”的作用,给定 ,模型估计相关性为 ,回归任务鼓励 接近标签 , 越接近真实标签 越好。排序任务有所不同,它让 的序拟合 的序,起到“保序”的作用,只在乎预测的序是否正确,不在乎预测的值离 是远是近,给定2条样本 ,有相同的查询词 ,设真实相关性分数 ,满足 ,我们希望模型预测的相关性分数 ,且满足 ,这样就组成了一个正序对,若 就是逆序对,这里不希望出现逆序对。回归任务:设有 条样本,每条样本都是三元组,记作 ,其中 是归一化之后的相关性分数,且 ,模型预测( )第 条样本的相关性分数为 ,定义 和 的损失函数,最小化 条样本的损失函数的均值,记作 ,这样可以使模型预测的 尽量接近 ,由于是回归任务,可以使用均方差损失函数,记作 。实际上交叉熵损失函数效果会更好(这有点像 二分类任务,但使用了 soft label),记作。不论是最小化均方差或最小化交叉熵都是让 的值拟合 的值。排序任务:一条样本包含一条查询词 和 篇文档 ,把查询词和第 篇文档 的真实相关性分数记作 ,模型预测的相关性记作 ,有2种方式给 篇文档排序,一种是按照真实的 排序,另一种按照 排序。最理想的情况,这两种排序方式完全一致,没有逆序对,排序任务不在乎 和 的值是否接近,只在乎两种排序是否接近。对两篇文档 ,设真实的相关性分数 ,那么损失函数应当鼓励 应该尽量大。也就是说让模型预测的序跟真实的序一致,让文档 成正序对,如果文档 ,那么模型预测是正确的,则称文档 是正序对,反之文档 ,模型预测是错误的,则称文档 是逆序对。损失函数应当鼓励正序对,惩罚逆序对。可以通过鼓励 尽量大,来达到增加正序对,而减少逆序对的目的。排序任务最常使用 pairwise logistic损失函数:。其中 是大于 0的超参数,控制pairwise logistic损失函数的形状。 - 后预训练(
post pretrain):分为3个步骤:1、从搜索日志中挑选十亿对二元组;2、自动生成标签,将用户行为 映射到相关性分数 ;3、用自动生成的数据 训练模型,方法与微调类似,都是监督学习,但也有额外的不同,后预训练会额外加上预训练的 MLM任务,避免预训练的结果被清洗掉。后预训练的第一个步骤根据搜索日志挑选二元组,搜索日志记录了用户每次搜索的查询词 和搜索引擎返回的文档,想要选 ,需要先根据搜索日志抽取查询词 ,这里要做非均匀抽样,需要覆盖高、中、低频查询词 ,用户搜索查询词 ,搜索引擎返回 篇文档 ,这些都记录在搜索日志中,搜索日志还记录了相关性分数(它们是精排模型相关性分数的打分,不是人工标准的真实分数),这些相关性分数不需要很准确,只是用来筛选文档而已,根据线上模型估计的相关性分数,选取 篇文档的一个子集,均匀覆盖各个相关性档位,用这种方法,我们抽取了很多查询词,查询词对应多篇文档。后预训练的第二个步骤就是自动给搜索日志中挑选的 二元组生成相关性分数,要对搜索日志做统计,得出 的点击率和多种交互率,记作向量 , 是全体用户的行为,可以某种程度上反映出 的相关性。通过挖掘搜索日志,已经得到了十亿条样本 ,其中向量 是用户行为,相关性 与用户行为 存在某种函数关系, 与 的函数关系为: 。其中 为一个小模型。生成的标签 是真实标签 的近似,首先选取几万对 二元组,人工标注它们的相关性分数 ,对于每对 二元组都有用户行为,记作向量 ,这样就有了几万条样本 ,然后训练一个小模型 来拟合 , 通常是 GPT这样的小模型,几万条样本就足够训练好这样的小模型。向量的维度不算高,没必要使用更大的模型。小模型 只能使用点击率、交互率作为输入,尽量不要用文本特征作为 的输入。小模型 的作用是把用户行为转换成相关性分数,而不是用文本特征去判定 的相关性。绝对不能用相关性 BERT模型打分作为输入,否则会产生反馈回路(BERT模型打分 -> 训练小模型-> 小模型 生成数据 -> 训练 BERT模型)。所以小模型的输入只有用户行为 ,小模型 训练好之后,可以用它生成相关性标签,对于十亿条样本 ,用训练好的小模型将 映射到相关性分数 ,记作 ,这样就得到了十亿条样本 。后预训练的第三个步骤:基于预训练的 BERT模型,用自动生成的数据做监督学习,继续训练 BERT模型,让BERT模型预测,监督学习要同时用 3个任务,有3个损失函数,取3个损失函数的加权和。第一个是回归任务,起到“保值”的作用(让模型的输出尽量接近),这样有利于 AUC指标。第二个是排序任务,起到“保序”的作用,会鼓励正序对,惩罚逆序对,最有利于正逆序比指标。前两个任务跟微调完全一样,第三个是预训练的MLM任务,让BERT模型预测被遮住的词,避免清洗掉预训练的结果。后预训练大幅增加了有标签样本的数量(百万 -> 十亿条)。人工标注的相关性数据是有限的(几十万 -> 几百万条),数据量肯定是越大越好,如果有几亿或者几十亿条,则根本就不需要后预训练。后预训练的数据可以自动生成,所以没有数量的限制。有了巨大的数据量,模型可以从有噪声的数据中学习到其中的信息,最终模型效果会更好。 ![]()
- 蒸馏(
distillation):用户每搜一个查询词,排序需要用相关性BERT模型给数百、数千对二元组打分。 BERT模型越大,推理的计算量也就越大,给相关性的打分就越准。为了平衡计算量和准确性,精排模型通常用4~12层交叉BERT在线上做推理,粗排模型通常用2~4层交叉BERT(或双塔BERT)。先训练48层交叉BERT模型作为teacher,在蒸馏小模型,,效果优于直接训练小模型(48层对比12层,AUC高2%以上)。用48层蒸馏12层,参数量压缩了10倍以上,但AUC几乎无损。也就是说用蒸馏的方法训练12层BERT比直接训练12层BERT,AUC提升了2%以上;用48层蒸馏4层,AUC的损失为0.5%,也就是说用蒸馏得到的4层BERT几乎可以有48层的效果,尽管参数量差了100倍,但如果不做蒸馏,AUC会很低。蒸馏步骤:做预训练、后预训练、微调,训练好48层BERT大模型,作为teacher,teacher模型越大越好,蒸馏出来的student就越准确。用48层teacher,效果优于24、12层teacher。训练好teacher之后,可以把teacher当做标注员,给数据生成标签,要从搜索日志中选取出几亿对二元组,然后用 teacher给几亿对二元组打分,得到相关性标签 ,蒸馏的数据量越大越好,最后用 teacher大模型标注的数据上做监督学习训练小模型(训练制作 1 epoch)。这里的训练与微调相同,同时用回归和排序任务。注意:student小模型需要先预热,然后再蒸馏。预热:先做预训练、后预训练、微调训练student(与训练teacher的步骤相同),基于预热好的模型,再用蒸馏数据训练 student。其次不要做逐层蒸馏,逐层蒸馏的代价比较大。单级蒸馏要好于多级蒸馏。

