机器学习(ML)(十五) — 推荐系统探析
特征交叉 - 因式分解机(FM)
假设有bias,第二项
二阶交叉特征:假设有dsquared,是交叉特征的权重
可以把所有权重Factorized Machine),记作
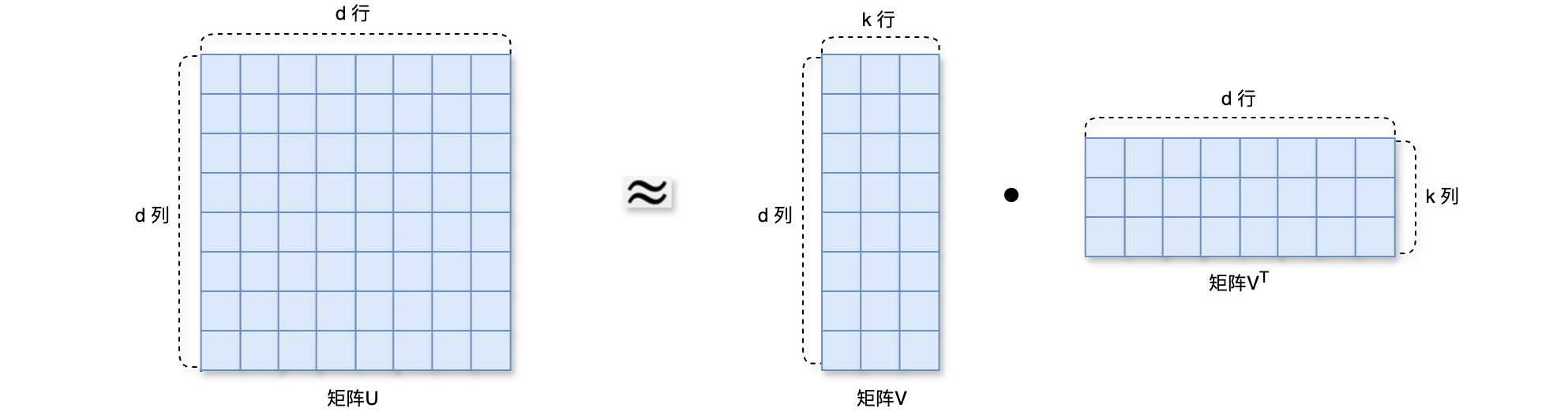
因式分解机(Factorized Machine)模型的参数数量为Factorized Machine)的好处是参数数量更少,由Factorized Machine)是线性模型的替代品,凡是能用线性回归、逻辑回归的场景,都可以用因式分解机(Factorized Machine)。因式分解机(Factorized Machine)使用二阶交叉特征,表达能力比线性模型更强,因式分解机(Factorized Machine)的效果,显著比线性模型要好。通过做近似Factorized Machine)把二阶交叉权重的数量从Factorized Machine)的论文,请参考Factorization Machines。
特征交叉 - 深度交叉网络(DCN)
深度交叉网络(Deep & Cross Networks)是一种结合了深度神经网络(DNN)和特征交叉的混合模型,旨在高效处理高维稀疏数据。深度交叉网络(Deep & Cross Networks)的设计初衷是为了克服传统前馈神经网络在特征交互建模方面的局限性,尤其是在推荐系统和广告点击预测等应用中表现出色。在推荐系统中,深度交叉网络(DCN)既可以用于召回也可以用于排序模型。双塔模型是一种框架而不是网络,用户塔和物品塔可以用任意网络结构,比如深度交叉网络;多目标模型中的神经网络也可以用任意网络结构所替代,比如深度交叉网络。
接下来看一下深度交叉网络(DCN)的结构:
- 交叉层(
cross layer):假设把输入记作向量,经过 层之后,输出向量 ,把向量 输入一个全连接层,全连接层输出向量 ,把第一层的向量 与向量 做阿达玛乘积( Hadamard Product),阿达玛乘积(Hadamard Product)也称为逐项乘积或舒尔乘积,是一种二元运算,适用于两个相同维度的矩阵。该运算的结果是一个新矩阵,其每个元素等于输入矩阵对应位置元素的乘积。如果和 都是 8维的向量,那么它们的乘积也是8维的向量,把输出的向量记作,向量 和 分别是输入和输出,两个向量的形状是一样的,把向量 和 相加,得到向量 ,向量 是第 个交叉层的输出,向量 是这个交叉层的输入,这个交叉层的参数全都在全连接层里边,交叉层可以记作 ,其中 是神经网络最底层额输入, 是第 层的输入, 是全连接层,而全连接层的输出是一个向量,跟输入 的大小是一样的。矩阵 和 是全连接层的参数,也是这个交叉层中全部的参数,参数需要再训练的过程中通过梯度去更新,把向量 与全连接层做阿达玛乘积( Hadamard Product),最后把阿达玛乘积(Hadamard Product)的结果与向量相加,把输入与输出相加,这就是 ResNet中的跳跃连接,这样可以防止梯度消失。向量是交叉层的输出,形状跟 是一样的,也就是说每个交叉层的输入与输出都是向量,而且形状相同。 
- 交叉网络(
cross network):向量是交叉网络的输入,把 送入交叉层(参数: ),交叉层输出向量 ,记作 ,其中 是这个交叉层中的参数,把上一层的输出向量 和 一起输入下一个交叉层(参数: ),这个交叉层输出向量 ,记作 ,把向量 和最底层向量 一起输入下一个交叉层,该交叉层的参数是 ,这个交叉层输出向量 ,重复这个过程,可以加更多的交叉层,如果不加更多的交叉层,那么向量 就是这个神经网络的输出。交叉网络相关的最新论文请参考: DCN V2: Improved Deep & Cross Network and Practical Lessons for Web-scale Learning to Rank Systems。如下图所示:


推荐系统召回、排序模型的输入是用户特征、物品特征、其它特征。把这些特征向量做concatenation,输入到两个神经网络(全连接网络 & 交叉网络),两个神经网络并联,两个神经网络各输出一个向量,把两个向量做concatenation,并输入到一个全连接层,全连接层输出一个向量,全连接网络、交叉网络、全连接层拼接到一起就是深度交叉网络(DCN)。其比单个全连接网络效果更好,深度交叉网络(DCN)既可以用于召回,也可以用于排序,双塔模型中的用户塔和物品塔都可以使用深度交叉网络(DCN),多目标排序模型中的shared bottom、MMoE中的专家神经网络也都可以是深度交叉网络(DCN)。如下图所示:

特征交叉 - HLUC
LHUC(Learning Hidden Unit Contributions)是一种神经网络结构,最初用于语音识别领域,旨在实现说话人自适应(speaker adaptation)。该方法通过为每个说话人学习特定的隐式单位贡献,从而提升不同说话人的语音识别效果。LHUC的核心思想是通过调整隐藏层单元的输出,使模型能够更好地适应不同的输入特征。LHUC只能应用在精排模型当中。在语音识别中的LHUC,语音识别的输入是一段语音信号,我们希望神经网络输入做变换得到更有效的表征,然后识别出语音中的文字,不同的声音会有所区别,最好是加入一些说话者的特征,最简单的特征就是说话者ID,对ID做Embedding,得到一个向量,作为这个说话者的表征。把语音信号输入到一个全连接层,输出一个向量;把说话者的特征输入到另一个神经网络,并输出一个向量。这个神经网络包含多个全连接层,最后一个全连接层的激活函数是0~2之间。这两个向量的形状必须完全一致,这样也就可以计算这两个向量的阿达玛乘积(Hadamard Product),对这2个向量逐元素相乘。这样就可以吧语音信号的特征,说话者的特征相融合。语音信号有的特征被放大,有的被缩小,这样可以做到个性化。阿达玛乘积(Hadamard Product)得到一个向量,形状与输入的特征是相通的,把这个向量输入到下一个全连接层,并输出一个形状相同的向量,把说话者特征也输入一个神经网络,这个神经网络有多个全连接层,最后一层的激活函数也是Hadamard Product),并输出一个形状相同的向量。这个向量是从语音信号提取的特征,还结合了说话者的特征,做到了个性化,最后的向量就是HLUC的输出。这两个神经网络的输入都是刷花这特征,两个神经网络都是由多个全连接层组成,最后一层的激活函数都是Hadamard Product),会放大某些特征、缩小另一些些特征,从而实现个性化。在语音识别的应用中,两个输入的向量分别是:语音信号和说话者的特征。在推荐系统的排序模型中,两个输入变成了用户特征和物品特征。物品特征相当于语音信号特征、用户特征相当于说话者的特征,HLUC的结构还是跟之前一样的。如下图所示:

特征交叉 - SENet & Bilinear 交叉
用户ID、物品ID、物品类目、物品管关键词等是推荐系统用到的离散特征。对这些离散特征做embedding得到多个向量。假设有AvgPool,得到一个ReLU激活函数把1的数,再用一个全连接层和sigmoid激活函数恢复成0~1之间,接下来,用右边的

为了方便,把SENet,SENet对每个向量做AvgPool得到一个SENet输出SENet的本质是对离散特征做field-wise加权,field:用户ID Embedding是64维向量,向量的64个元素算一个field,并获得相同的权重。如果有fields,那么权重向量就是field做加权,也就是说,SENet会根据所有特征自动判断每个field特征重要性,重要的field权重高、不重要的field权重低。
field间特征交叉:意思是把两个field做交叉,得到新的特征,比如说,把物品所在位置和用户所在位置各自做embedding,然后把两个embedding向量做交叉。交叉两个向量方法如下图所示:

内积和阿达玛乘积(Hadamard Product)是最简单的交叉方法:
- 内积:
和 是两个特征的 embedding,求它们的内积得到一个实数,如果有 fields,也就是说有个离散特征,会计算出 个实数,推荐系统中 的数量不是很大,数量也就几十个。 - 阿达玛乘积(
Hadamard Product):和 是两个特征的 embedding,求阿达玛乘积(Hadamard Product)也就是逐元素相乘,得到一个向量,它们的维度大小是相同的,如果有 个 fields,就会计算出个向量,这会非常庞大,通常来说如果用阿达玛乘积( Hadamard Product)来做特征交叉,必须要人工选择一些来做交叉,不能对个 fields做两两交叉。不论是内积还是阿达玛乘积(Hadamard Product)都要求每个特征的embedding向量的形状保持一样,都是维向量,如果形状不一样,就不能计算内积或阿达玛乘积( Hadamard Product)。
Bilinear Cross是一种更先进的特征交叉方法,Bilinear Cross有内积、阿达玛乘积(Hadamard Product)两种形式:
Bilinear Cross(内积):和 是两个特征的 embedding,它们的形状可以相同,也可以不同。计算转置乘以 ,再乘以 ,记作 ,其中得到一个实数 , 是两个 fields的交叉,用这种特征交叉的方式,如果有个 fields,那么会产生个交叉特征,都是实数。交叉特征的数量不是很大,做 Bilinear Cross的时候,需要很多像这样的参数矩阵,如果有 个fields,那么就会有 个参数矩阵。加入每个参数矩阵的大小都是 ,有 1000个这样的参数矩阵,那么Bilinear Cross的参数量是个,参数数量太大。想要减少数量,需要人工指定某些相关的而且重要的特征做交叉,而不能让所有特征做两两交叉。 Bilinear Cross(阿达玛乘积):和 是两个特征的 embedding,先把矩阵和 相乘得出另一个向量,再求与向量 的阿达玛乘积,也就是让两个向量逐元素相乘,阿达玛乘积得出一个向量 ,用这种特征交叉的方式,如果有 个 fields,就会计算出个向量,对 个向量做 concatnation得到的向量维度太大了,而且其中大多数都是无意义的特征,在实践中,最好人工指定一部分特征做交叉,而不是让所有个特征两两做交叉。这样既可以减少参数的数量,又可以让 concatnation之后的向量变小。,右边基于Bilinear Cross(阿达玛乘积)")
,右边基于Bilinear Cross(阿达玛乘积)")
FiBiNet:把SENet和Bilinear Cross结合起来就是FiBiNet,用户ID、物品ID、物品类目等等是用到的离散特征,对这些离散特征做embedding,用1个向量表示一个特征,把这些向量做concatenation,得到一个高维向量,对这些embedding向量做Bilinear Cross,得到很多交叉特征,拼接成一个向量。用SENet对embedding向量做加权,得到一个一个同样大小的向量,在对这些向量做Bilinear Cross,得到很多交叉特征,拼接成一个向量。这些是FiBiNet对离散特征变换之后得到的向量,对它们做concatenation,输入上层的神经网络,这是还有连续特征,连续特征变换之后,输入上层的神经网络。跟简单排序模型相比,FiBiNet用了SENet加权和Bilinear Cross,在精排模型中使用效果很显著。如下图所示:

行为序列 - 用户行为序列建模
用户行为序列叫做LastN,表示用户最近交互过的LastN行为序列能够反映出用户对什么样的物品感兴趣,召回的双塔模型、粗排的三塔模型和精排模型都可以用LastN特征,LastN特征很有效,把它应用到召回和排序模型中,所有指标都会大涨,用户的LastN记录是用户交互过得最近ID,做embedding,把LastN特征就是用户最近的ID。对LsatN物品ID做embedding,得到
行为序列 - DIN模型
系统记录了用户的LastN,也就是最近交互过的embedding,把LastN序列建模方法,DIN模型是一种很好的序列建模方法,有关DIN模型的相关论文,请参考Deep Interest Network for Click-Through Rate Prediction,DIN模型使用加权平均代替平均,即注意力机制(attention),权重是候选物品与用户LastN物品的相似度,哪个LastN物品与候选物品越相似,它的权重就越高,这里500个物品就是精排的候选物品。精排模型要给每个候选物品打分,分数表示用户对候选物品的兴趣,最后根据分数的高低,给这500个候选物品做排序,保留分数最高的几十个展示给用户。请注意区分LastN物品和候选物品。接下来要计算相似度,向量LastN向量的加权和,权重是相似度DIN模型加权平均,如下图所示:

DIN模型的本质就是注意力机制。LastN物品的向量表征,key和value,把向量query,全都输入单头注意力层,query只有一个向量,单头注意力层的输出也是一个向量,所以它和注意力机制完全一致。简单平均和注意力机制都适用于精排模型,单间平均还适用于召回的双塔模型和粗排的三塔模型。简单平均只用到用户的LastN,属于用户自身的特征,跟候选物品无关,因此可以把LastN的平均作为用户塔的输入。但是注意力机制(attention)就不适用于双塔模型和三塔模型。注意力机制(attention)既用到LastN,也要用到候选物品。用户塔看不到候选物品,因此不能把注意力机制(attention)用在用户塔上。比如在双塔召回的时候,一共有上亿个候选物品,用户塔只能够看到用户特征,却看不到候选物品特征,但是DIN模型需要知道候选物品的特征,因此DIN模型不能放在用户塔,DIN模型不能运用到双塔模型、三塔模型。
行为序列 - SIM模型
DIN模型其实是注意力机制(attention),注意力层的计算量正比于DIN模型的计算量也就越大,DIN模型通常只能记录最近几百个物品,否则计算量太大。因此记录的用户行为太短,模型只关注短期兴趣,遗忘了长期兴趣。如何保留用户长期行为序列,而且计算量不会过大?改进DIN的思路是:DIN对LastN向量做加权平均,权重是候选物品与每个LastN物品的相似度,如果LastN物品与候选物品差异很大,则权重接近于0。快速排除掉与候选物品无关的LastN物品,只把相关物品输入注意力层,这样就大幅降低注意力层的计算量。这种方法被称作SIM模型。SIM模型相关论文,请参考:Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction。
如果使用SIM模型的话,可以保留用户的长期历史行为记录,LastN记录中做快速查找,找到1000个物品ID,也就是说LastN物品,只保留最相关100个,通过查找,把LastN变成了Top-K,然后Top-K输入到注意力层。SIM模型的好处是减少了计算量(从SIM模型分为了两步:第一步是查找,第二步是注意力机制。
SIM模型第一步的查找有2种方法:
Hard search:就是根据规则做筛选,比如根据候选物品的类目,保留LastN物品中类目相同的,这样用规则做筛选的方式简单、快速,无需训练。Soft search:就是向量的最近邻查找,需要把LastN物品和候选物品都做embedding,变成向量。把候选物品的向量作为query,做近邻查找,保留 LastN物品中最接近的个物品。实践效果更好,编程实现更复杂,计算代价也更高。
第二步注意力机制:跟DIN模型的区别是LastN的交互记录,而是用户Top-K交互记录。第一步的查找把LastN物品缩小到了Top-K,排除掉的物品大多与候选物品无关,所以把LastN变成了Top-K,这几乎不会影响加权平均的结果。注意力层输出的向量作为用户行为特征,与其它特征一起作为精排模型的输入,用于预估点击率等指标。用户与某个LastN物品的交互时刻距今为1000小时以前,则embedding,得到向量embedding,向量embedding,把这两个向量做concatenation,拼接成一个向量,作为一个LastN物品的表征。这些向量就是对用户记录的表征,保留LastN物品中Top-K,使用向量embedding,把这些向量都输入注意力层,然后输出一个向量,这个向量就是对用户兴趣的表征。
为什么SIM模型需要使用时间信息?因为DIN模型记录了用户交互过的几百个物品,使用短序列,几乎都是用户的近期的行为。SIM模型使用长序列,记录了用户的长期行为,LastN中的物品可能是1年前的交互,也可能是10分钟前的交互。通常来说时间越久远,重要性就越低。所有SIM模型预测点击率的时候,应该把时间也考虑到。SIM模型的注意力机制,如下图所示:

重排 - 多样性
如果曝光给用户的物品两两之间不相似,就说明推荐的结果具有多样性,想要提升多样性,首先想办法度量两个物品有多相似,有2种度量相似性的方法。这两种方法都是实际有用的,第一种方法是基于物品属性的标签,比如类目、品牌、关键词等等。2个物品有越多相同的标签,则2个物品就越相似。第二种方式是基于物品的向量表征,两个物品向量余弦值越大,则两个物品就越相似。有很多种方法对物品向量表征,但并不是所有向量表征的方法都适用多样性的问题。比如说用召回的双塔模型学到的物品向量不适用于多样性问题。从实验的结果来看,最好还是基于物品内容的表征,也就是基于CV和NLP模型提取图片和文字的表征向量。
- 基于物品属性的标签:物品属性的标签有很多,比如说类目、品牌、关键词等等,这些标签通常是根据
CV和NLP算法根据图文内容推算得出的,未必准确。我们可以根据一级类目、二级类目、品牌计算相似度,比如说物品的一级类目是美妆、二级类目是彩妆、品牌是香奈儿;物品 的一级类目是美妆、二级类目是香水、品牌是香奈儿;一级类目、二级类目、品牌对应 3个相似度分别是。意思是一级类目相同、二级类目不同、品牌相同。对3个分数求加权和,即可得到 3个分数的总分。其中的权重需要根据经验设置。 - 基于物品的向量表征:召回的双塔模型,有2个塔,分别把用户特征、物品特征映射成向量,记作
和 。两个向量的余弦相似度表示用户对物品的兴趣。用在多样性的问题上,我们只需要物品塔的输出。物品塔把每个物品表征为向量 。如果两个物品相似,则向量表示的内积比较大或余弦相似度比较大。如果把物品塔学到的物品表征用在多样性问题上效果一般,推荐系统的头部现象很严重,曝光和点积都集中在少数物品上,新物品和长尾物品的曝光或点击次数都很少。双塔模型学不好它们的向量表征,如果用物品塔输出的向量计算物品的相似度,肯定处理不好新物品和长尾物品,最终多样性算法的效果很差。用在多样性问题上最好是基于图文内容的物品向量的表征, CLIP是很有效的预训练方法,CLIP相关论文,请参考:Learning Transferable Visual Models From Natural Language Supervision,CLIP的思想是:对于图片文本二元组,预测图文是否匹配。CLIP的优势是:无需人工标注,做预训练的时候同一个物品的图片和文字作为正样本,图片的向量和文字的向量应该高度相似,如果图片和文字来自不同的物品,那么就可以作为一组负样本。
在推荐系统中,我们希望曝光的物品具有多样性,两两之间都不相似。粗排和精排用多目标模型对物品做pointwise打分,即把每个物品作为独立的个体,尽量准确预估点积、交互、时长。对于物品reward几百个物品。粗排之后的多样性算法也能提升业务指标。
重排 - 多样性算法(MMR)
精排给reward和sim这两种分数,从
MMR(Maximal Marginal Relevance)多样性算法:如下图所示,图中画的是Marginal Relevance分数)。其中0~1之间的参数,平衡物品的价值和多样性,MMR(Maximal Marginal Relevance)多样性算法:就是对MR分数,选出分数最高的,从集合MMR(Maximal Marginal Relevance)多样性算法流程如下:
- 已选中的物品集合
初始化为空集,未选中的物品 初始化为全集 。 - 选择精排分数
最高的物品,从集合 移到集合 。 - 接下来,做
轮循环,每一轮循环用 MMR选出一个物品,当循环结束的时候,一共选出了个物品。
每一轮循环中计算集合MR分数都会发生变化。所以下一轮需要从新计算MR分数,用这种方法,做
但是以这样的方法(MMR)来计算物品的多样性会存在一个问题,已选中的物品越多(即集合1,导致MMR(Maximal Marginal Relevance)算法失效。解决方案:设置一个滑动窗口10个物品,滑动窗口MMR(Maximal Marginal Relevance)公式中的集合MMR(Maximal Marginal Relevance)算法每一轮要从集合MMR(Maximal Marginal Relevance)的标准公式为:MMR(Maximal Marginal Relevance)的公式为:30个物品与第1个物品不相似,用户看到第30个物品的时候,大概率忘记了第1个物品是什么。两个离的远的物品可以相似,不会影响用户体验。但两个物品离得比较近,就应当有较大的差异,佛则用户可以感知到多样性不好。如下图所示:

重排的规则很多,例如:最多连续出现1个某种物品、前MMR(Maximal Marginal Relevance)每一轮选出一个物品:MMR(Maximal Marginal Relevance)公式与规则,在满足规则约束的前提下,最大化MMR(Maximal Marginal Relevance)每一轮从上面的公式都从集合MMR(Maximal Marginal Relevance)公式中的集合