机器学习(ML)(六) — 探析
偏差和方差
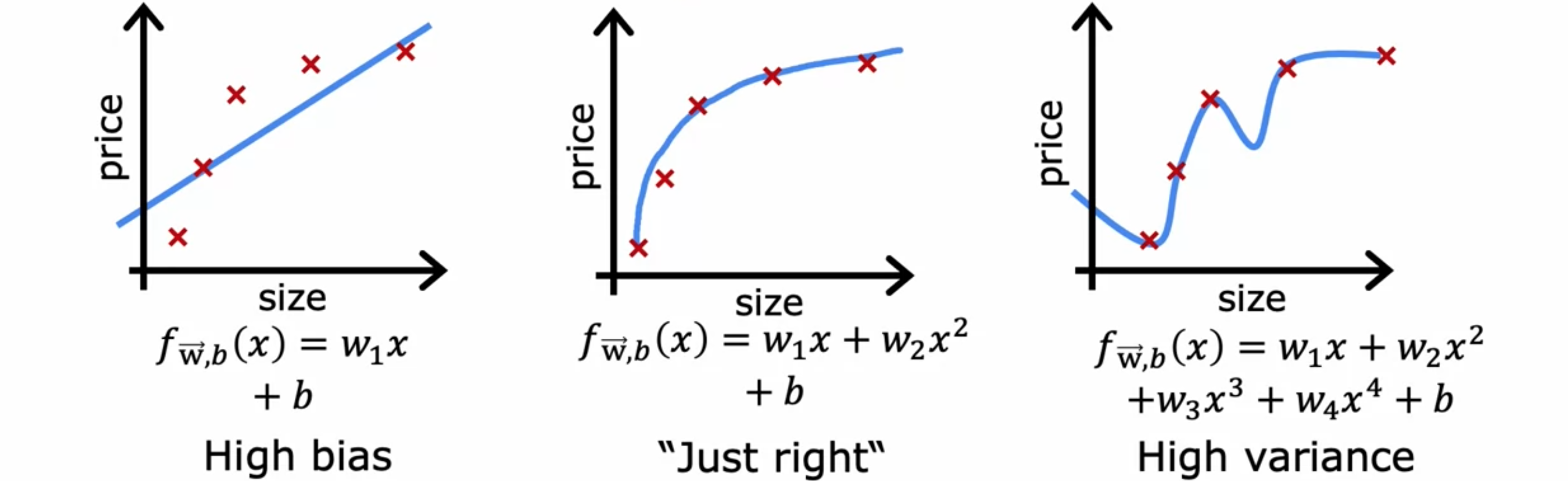
开发机器学习系统的典型工作流程是什么?当训练机器学习模型时。在给定数据集,如果想用直线去拟合它,可能做得并不好。我们说这个算法有很高的偏差,或者它对这个数据集的拟合不足,也可以称为欠拟合。如果要拟合一个四阶多项式,那么它有很高的方差,或者称为过拟合。如果拟合一个二次多项式,那么它看起来相当不错。如下图所示:
但是如果有很多特征,就无法绘制图形来查看,不如诊断或查找算法在训练集和交叉验证集上是否具有高偏差、高方差来的更有效。让我们看一个例子。如果要计算
如下图所示,其中横轴是
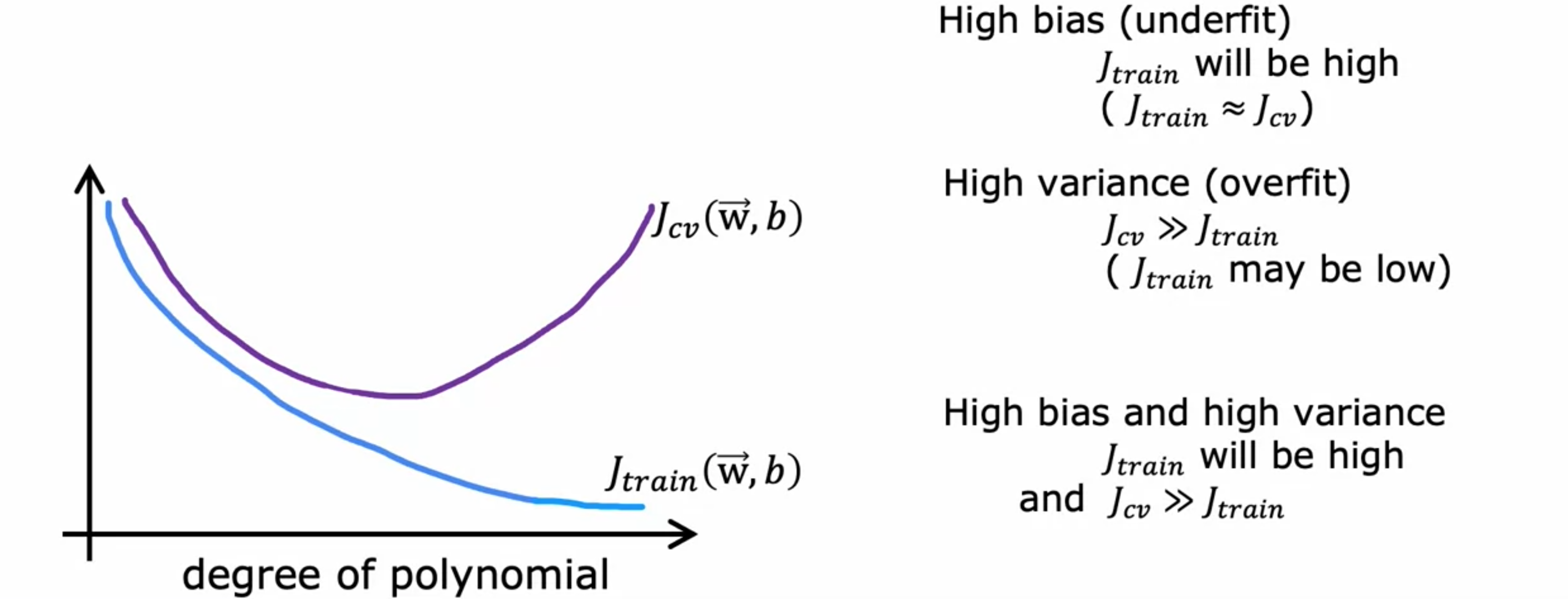
总结一下,你如何诊断是否具有高偏差?如果你的学习算法有高偏差的数据,关键指标将是
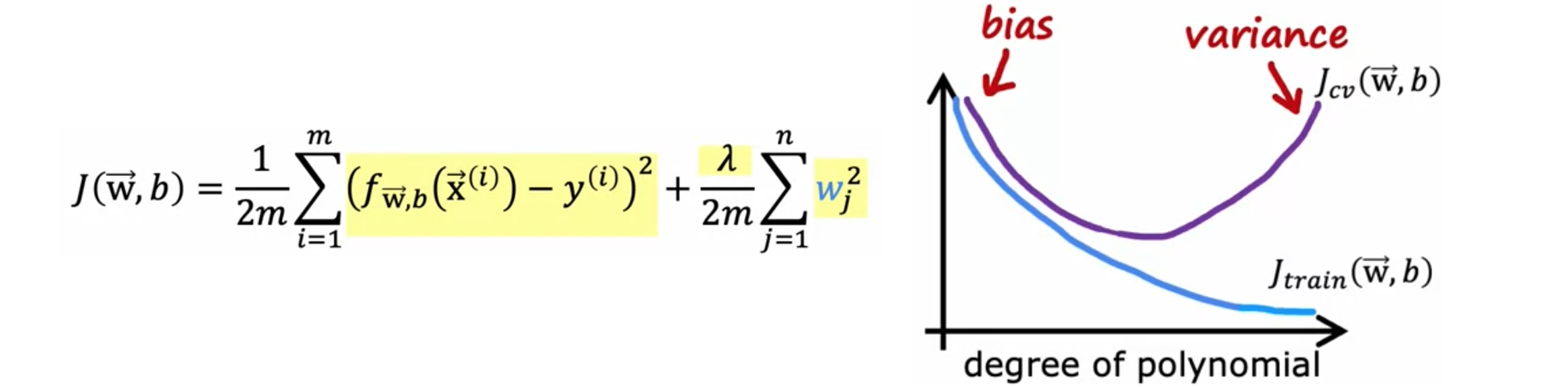
让我们看看正则化,特别是正则化参数
在下图中,再次更改了
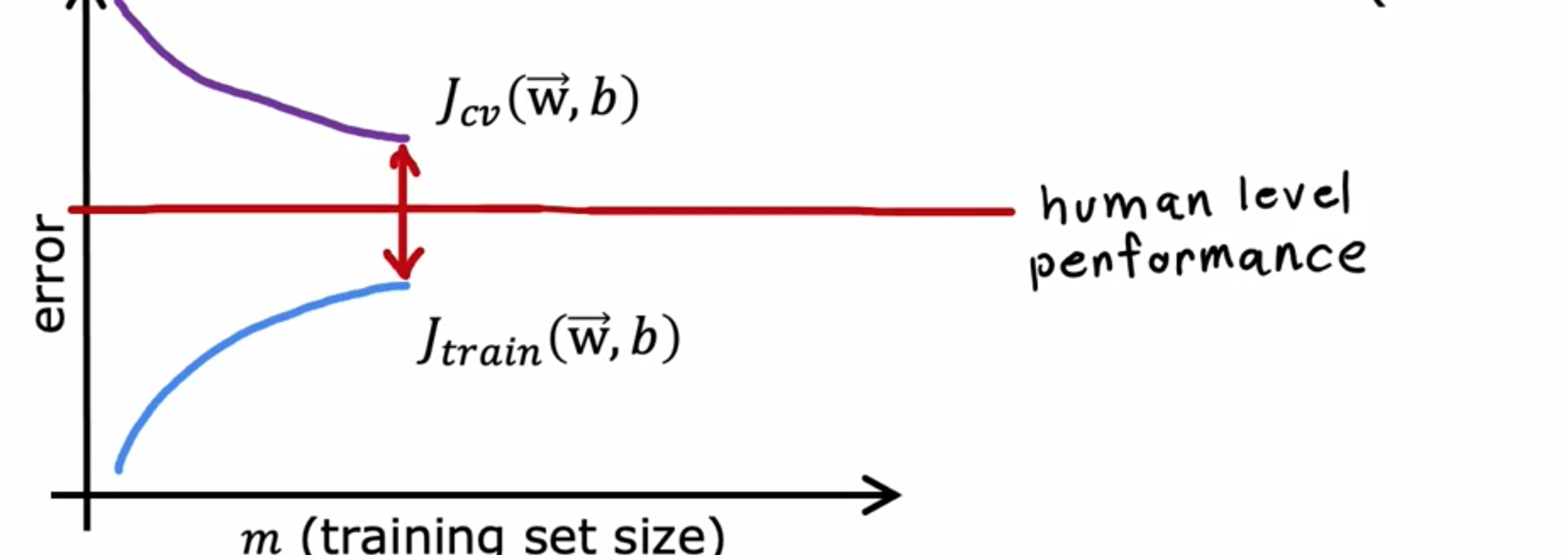
让我们看看10.8%,意味着它可以完美转录89.2%的训练集,但会犯10.8%的训练集错误。如果您还要在单独的交叉验证集上测量语音识别算法的性能,假设其错误率为14.8%。你会发现训练误差非常高,错误率为10%,然后交叉验证误差更高,但即使训练集有10%的错误,这个错误率似乎相当高。它具有很高的偏差,但事实证明,在分析语音识别时,测量另一件事也很有用,那就是人类的表现水平如何?换句话说,人类从这些音频片段中转录语音的准确程度如何?具体来说,假设你测量了流利说话者转录音频片段的能力,发现人类水平的表现达到了10.6%的错误率。为什么人类水平的错误率这么高?对于网络搜索,有很多音频片段有很多嘈杂的音频,由于音频中的噪音,实际上没有人能够准确地转录所说的内容。如果连人类都会犯10.6%的错误率,那么似乎很难指望学习算法能做得更好。为了判断训练错误是否很高,看看训练错误是否远远高于人类水平的表现会更有用,在这个例子中,它的表现只比人类差0.2%。但相比之下,4%。当我们将其与人类水平的表现进行比较时,我们发现该算法在训练集上的表现实际上相当不错,但更大的问题是交叉验证误差远高于训练误差,这就是为什么我会得出结论,该算法实际上存在更多的方差问题而不是偏差问题。判断训练误差是否高通常有助于确定性能的基准水平,而我所说的性能基准水平是指学习算法最终达到的错误水平。确定性能基准水平的一种常见方法是衡量人类在这项任务上的表现如何,因为人类非常擅长理解语音数据、处理图像或理解文本。当您使用非结构化数据(例如:音频、图像或文本)时,人类水平的表现通常是一个很好的基准。估计基准性能水平的另一种方法是,如果存在某种竞争算法,可能是其他人已经实现的先前实现,甚至是竞争对手的算法,那么如果可以测量基准性能水平,则可以建立基准性能水平。如果可以访问此基准性能水平,那么可以合理地希望达到的错误水平是多少?然后,在判断算法是否具有高偏差或方差时,查看基准性能水平、训练误差和交叉验证误差。然后要测量的两个关键数值是:训练误差与希望获得的基准水平之间的差异是多少?如果这个数值很大,那么会是一个高偏差问题。然后查看训练误差和交叉验证误差之间的差异是多少?如果这个差异很大,那么会是一个高方差问题。第二个例子,如果基准水平的表现;即人类水平的表现,训练误差和交叉验证误差差距是4.4%。训练误差远高于人类所能达到的水平和我们希望达到的水平,而交叉验证误差只比训练误差大一点。这个算法有高偏差问题。通过查看训练误差和交叉验证误差可以直观地了解算法有高偏差或高方差问题的程度。有时,性能的基准水平可能是0%。如果目标是实现比基准水平更好的性能,那么性能的基准水平可能是0%,但对于某些应用程序(例如语音识别应用程序),其中一些音频只是嘈杂的,那么性能的基准水平可能远高于零。您的算法可能存在高偏差和高方差。基线和训练误差之间的差距4.4%,训练误差和交叉验证误差之间的差距是4.7%。则算法具有高偏差和高方差。总而言之,查看训练误差是否很大是判断算法是否具有高偏差的一种方法,但数据有时只是嘈杂且无法期望获得零误差,建立这个基准性能水平很有用。同样,查看交叉验证误差是否比训练误差大得多,可以让您了解算法是否存在高方差问题。
学习曲线是一种帮助理解学习算法并如何根据其经验量(例如,它拥有的训练示例数量)来执行的方法。如下图所示,绘制一个适合二次函数模型的学习曲线。绘制
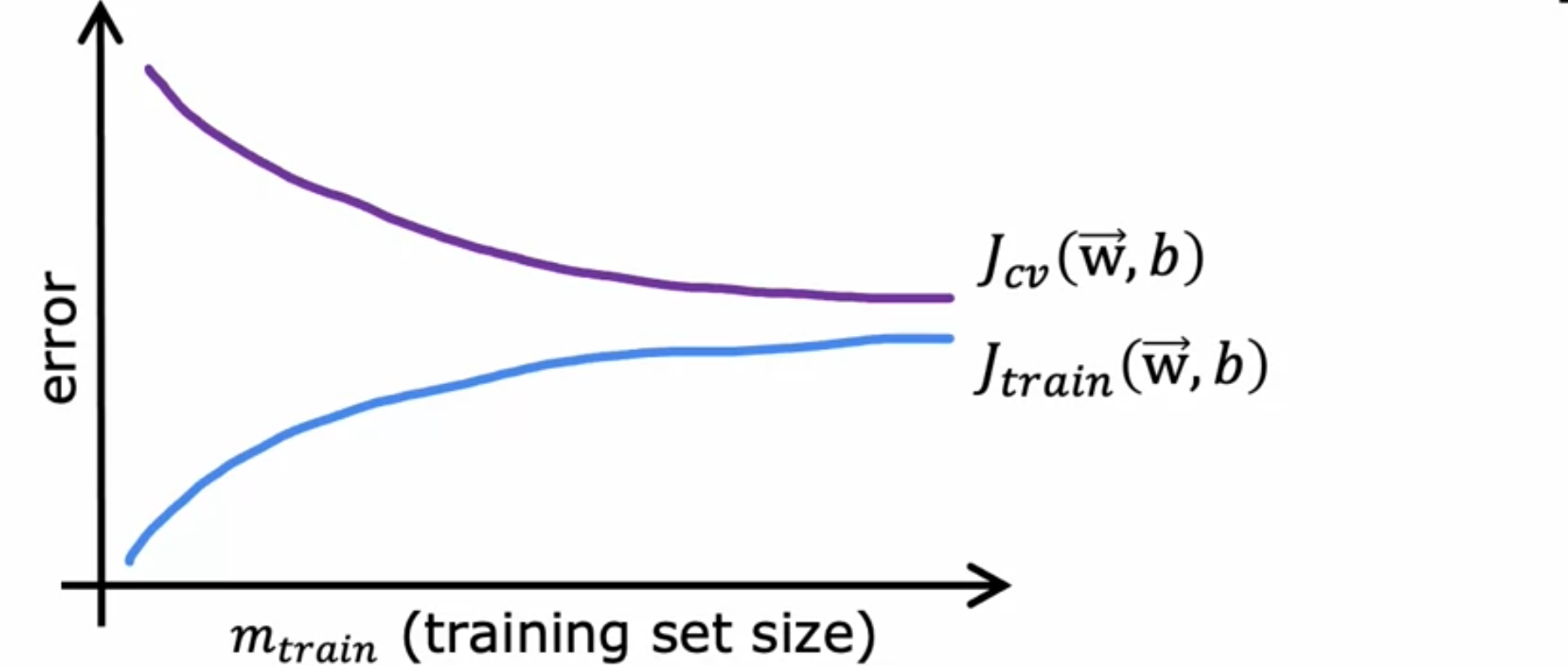
在上图中,横轴是4时,训练误差会稍微增加一点。假设有5个训练样本,要完美拟合所有样本就更难了。总结一下,当你只有很少的训练样本,比如1、2、3个时,相对容易得到零或非常小的训练误差,但是当有更大的训练集时,二次函数很难完美拟合所有训练样本。这就是为什么随着训练集变大,训练误差会增加,因为完美拟合所有训练样本变得更加困难。请注意,交叉验证误差通常会高于训练误差,因为将参数拟合到训练集上。期望在训练集上的表现至少会比在交叉验证集上的表现好一点,或者当m较小时,甚至可能会好很多。现在让我们看看高偏差和高方差的学习曲线是什么样的?先从高偏差的情况开始。如果绘制训练误差,那么训练误差就会像预期的那样上升。这条训练误差曲线可能会开始趋于平缓。我们称之为平台期,意思是一段时间后趋于平缓。这是因为在拟合简单的线性函数时,随着得到越来越多的训练样本,模型实际上并没有发生太大的变化。这就是为什么平均训练误差在一段时间后趋于平缓的原因。同样,交叉验证误差也会在一段时间后下降并变大,这就是为什么
这得出了一个结论,如果你的算法具有高偏差,那么唯一能做的就是向其投入更多训练数据,但这永远不会将错误率降到很低。这就是为什么在投入大量精力收集更多训练数据之前,需要检查你的学习算法是否具有高偏差。高方差的学习曲线又会是什么样的?如果用1,000个训练示例,可以仅使用100个训练示例训练模型并查看训练误差和交叉验证误差,然后使用200个示例训练模型,保留800个示例并暂时不使用它们),然后绘制
通过查看
如果你发现算法存在高方差,那么主要的方法是:要么获得更多的训练数据,要么简化模型。简化模型的意思是,要么获取一组较小的特征,要么增加正则化参数
我们发现高偏差或高方差都是不好的,因为它们会损害算法的性能。如果用不同阶的多项式拟合一个数据集,一个非常简单的模型,它可能有高偏差,而如果要拟合一个复杂的模型,它可能有高方差。偏差和方差之间存在这种权衡,选择二阶多项式可以帮助做出权衡。如果你的模型太简单,偏差就会很高,如果模型太复杂,方差就会很高。这时必须在它们之间找到一个权衡,才能找到最好的结果。但神经网络提供了一种摆脱这种必须权衡偏差和方差的困境的方法,大型神经网络在小型中等规模的数据集上训练时是低偏差。如果你你的神经网络足够大,总是可以很好地拟合训练集。可以根据需要尝试减少偏差或减少方差,而无需在两者之间进行权衡。
首先在训练集上训练算法,然后询问它在训练集上的表现是否良好。测量GPU。它对加速神经网络也非常有用。但即使使用硬件加速器,超过一定程度,神经网络也会变得非常庞大,需要很长时间进行训练,变得不可行。当然,另一个限制是更多的数据。有时只能获得这么多数据,超过一定程度就很难获得更多数据。但在增加神经网络之后,会发现方差很大,在这种情况下,可能会收集更多数据。当您训练神经网络时,经过精心选择的正则化的大型神经网络通常与小型神经网络一样好或更好。有一个警告,那就是当训练大型神经网络时,它的计算成本会更高。所以它的主要坏处是,它会减慢训练和推理过程,并且非常短暂地对神经网络进行正则化。如果神经网络的成本函数是平均损失,所以这里的损失可能是平方误差或逻辑损失。
然后,神经网络的正则化项看起来与期望的非常相似,即TensorFlow中实现正则化的方式是回想一下,手写数字分类模型的代码。创建三个层,其中包含多个拟合单元激活,然后创建一个包含三个层的顺序模型。添加正则化L2(0.001),为了简单起见,可以为所有权重和所有不同的层选择相同的
1 | import tensorflow as tf |
开发流程
开发机器学习模型,首先,要决定系统的整体架构。选择机器学习模型以及决定使用哪些数据,也许还要选择超参数等等。然后,根据这些决定,训练模型。正如之前提到的,当第一次训练模型时,它几乎永远不会按照希望的那样工作。建议下一步是查看一些诊断,例如查看算法的偏差和方差以及误差分析。根据诊断结果做出决定,例如是否要扩大神经网络、变更1或0,具体取决于它是垃圾邮件还是非垃圾邮件。构建电子邮件特征的一种方法是,取出英语或其他词典中的前10,000个单词,并使用它们来定义特征a、Andrew buy deal discount等等。将这些特征设置为0或1,具体取决于该词是否出现。构建特征向量的方法有很多。另一种方法是让这些数字不仅仅是1或0,而是计算给定单词在电子邮件中出现的次数。如果buy出现了两次,将其设置为2,有了这些特征,您就可以训练分类算法(例如逻辑回归模型或神经网络)来根据这些特征
假设有100个交叉验证示例。误差分析过程只是手动查看这100个示例并了解算法出错的地方。从交叉验证集中找到一组算法错误分类的示例,并将它们分组为共同的属性或共同的特征。例如,如果注意到错误分类的垃圾邮件是药品销售,试图销售药品或药物,假设有21封电子邮件是药品垃圾邮件。假设通过电子邮件路由信息,发现7个具有不寻常的电子邮件路由,18封电子邮件试图窃取密码或钓鱼电子邮件。垃圾邮件有时也不会在电子邮件正文中编写垃圾邮件,而是创建图像,然后将垃圾邮件写入电子邮件中的图像中。这使得学习算法更难弄清楚。也许其中一些电子邮件是嵌入图像的垃圾邮件。即使构建了非常复杂的算法来查找故意的拼写错误,也只能解决100个错误分类示例中的3个。例如,可能有一个具有不寻常路由的医药垃圾邮件,或者一个具有故意拼写错误的密码,并且也在试图进行网络钓鱼攻击。一封电子邮件可以算入多个类别。在这个例子中,算法错误分类了100个示例。如果有一个更大的交叉验证集,假设我们有5,000个交叉验证示例,如果算法错误分类了其中的1,000个,可能没有时间手动查看算法错误分类的1,000个示例。在这种情况下,通常会随机抽取一个子集,通常大约100个,因为这是可以在合理的时间内查看的数量。希望查看大约100个示例将为您提供足够的统计数据,了解最常见的错误类型。经过此分析,如果发现很多错误都是医药垃圾邮件,那么这可能会给您一些灵感,让您知道下一步该做什么。例如,您可能决定收集更多数据,但不是收集所有内容的数据,而只是找到更多有关医药垃圾邮件的数据,以便学习算法能够更好地识别这些医药垃圾邮件。或者,您可能决定提出一些与垃圾邮件发送者试图销售的药品的具体名称相关的新特征,以帮助学习算法更好地识别此类医药垃圾邮件。然后,这可能会启发检测网络钓鱼电子邮件相关的算法进行特定更改。例如,查看电子邮件中的URL并编写特殊代码以添加额外特征,以查看它是否链接到可疑的URL。或者,获取更多钓鱼电子邮件的数据,以帮助学习算法更好地识别它们。此误差分析的重点是手动检查算法错误分类或错误标记的一组示例。通常,这会为下一步尝试提供灵感,有时它还可以告诉您某些类型的错误非常罕见,因此不值得花费太多时间去修复。总的来说,偏差方差诊断以及误差分析对于筛选模型非常有帮助。误差分析的一个限制是,对于人类擅长的问题,它更容易做到。对于人类不擅长的任务,误差分析可能会更难一些。
如果误差分析发现制药垃圾邮件是一个问题,可以采取更有针对性的措施,而不是获取有关所有类型的更多数据,而是专注于获取更多有关制药垃圾邮件的示例。而且,以更适中的成本,来添加所需的电子邮件。如果您有大量未标记的电子邮件数据,比如闲置的电子邮件,但没有人费心将其标记为垃圾邮件或非垃圾邮件,可以让人工快速浏览未标记的数据并找到更多示例,特别是与制药相关的垃圾邮件。这可以大大提高学习算法性能,而不仅仅是尝试添加更多各种电子邮件的数据。但如果有一些方法可以添加更多数据。如果误差分析表明算法在某些数据子集上表现特别差。而想要提高性能,那么只需获取做得更好的类型的数据。无论是更多的制药垃圾邮件示例还是更多的网络钓鱼垃圾邮件示例或其他内容。这可能是一种更有效的方法,只需添加一点点数据,但可以大大提高算法性能。不仅仅是获得全新的训练示例。还有一种技术被广泛使用,特别是用于图像和音频数据,它可以显著增加训练集大小。这种技术称为数据增强。我们要做的是利用现有的训练示例来创建一个新的训练示例。例如,如果你试图识别从A~Z的字母,以解决OCR光学字符识别问题。给定这样的图像,通过稍微旋转图像来创建一个新的训练示例。或者通过稍微放大图像或缩小图像或通过改变图像的对比度。这些是图像扭曲的例子,但不会改变它仍然是字母A的事实。对于某些字母,可以获取字母的镜像,它仍然看起来像字母A。但这仅适用于某些字母,但这些将是获取训练示例A旋转了一点、放大了一点或缩小了一点,它仍然是字母A。创建这样的额外示例可以让学习算法更好地学习如何识别字母A。对于数据增强的更高级示例,还可以取字母A,并在其上方放置一个网格。通过引入此网格的随机扭曲,你可以取字母A。并引入A的扭曲,以创建一个更丰富的字母A示例库。然后,扭曲这些示例的过程将一个示例的图像变成了训练示例,你可以将其提供给学习算法,希望它能够更稳健地学习。数据增强的这个想法也适用于语音识别。假设对于语音搜索,有一个原始音频剪辑,可以将数据增强应用于语音数据的一种方法是获取嘈杂的背景音频。例如,这是人群的声音。事实证明,如果将这两个音频剪辑加在一起,听起来像有人在说今天的天气怎么样。但他们是在背景中吵闹的人群中说这句话的。如果您要获取不同的背景噪音,比如车里的人,这就是汽车的背景噪音。如果您想将原始音频剪辑添加到汽车噪音中,好像说话者是从车里说的。更高级的数据增强步骤是,让原始音频听起来像是在手机连接不良的情况下录制的。这实际上是一种非常关键的技术,可以人为地增加训练数据的大小,从而构建更准确的语音识别器。数据增强的一个技巧是,数据所做的更改或扭曲应该代表测试集中的噪音或扭曲类型。相反,在数据中增加纯随机无意义的噪声通常没有多大帮助。例如,你取字母A,如果只向每个像素添加噪声,它们最终会得到像这样的图像。但如果这不能代表你在测试集中看到的内容,因为你在测试集中通常不会得到这样的图像,那么这实际上就没那么有用了。因此,考虑数据增强的一种方法是,如何修改、扭曲数据,或在数据中制造更多噪声。现在,数据增强采用现有的训练示例并对其进行修改以创建另一个训练示例。其中一种技术是数据合成,你可以从头开始制作全新的示例。不是通过修改现有示例,而是通过创建全新的示例。以照片OCR为例。照片OCR或照片光学字符识别是指查看这样的图像并让计算机自动读取图像中出现的文本的问题。这张图片中有很多文本。如何训练OCR算法来读取图像中的文本?照片OCR任务的一个关键步骤是能够查看这样的小图像并识别中间的字母。因此,中间有T,中间有字母L,中间有字母C 等等。因此,为这项任务创建人工数据的一种方法是,进入计算机的文本编辑器,会发现它有很多不同的字体,使用这些字体并在文本编辑器中输入随机文本。并使用不同的颜色、不同的对比度和非常不同的字体进行截图,你会得到像右边这样的合成数据。左边的图像是从世界上拍摄的真实照片中获取的真实数据。右边的图像是使用计算机上的字体合成的,实际上看起来非常逼真。因此,使用这样的合成数据,可以为照片OCR任务生成大量图像或示例。编写代码为给定应用程序生成逼真的合成数据可能需要大量工作。但是它有时可以帮助你为应用程序生成大量数据,并极大地提升你的算法性能。合成数据生成最有可能用于计算机视觉任务,而较少用于其他应用。有时花更多时间采用以数据为中心的方法会更有成效,这种方法专注于设计算法使用的数据。如果这是误差分析告诉你需要更多这方面的数据。使用数据增强来生成更多图像和音频,或使用数据合成来创建更多训练示例。
对于没有那么多数据的应用,迁移学习是一种很棒的技术,它允许使用来自不同任务的数据来帮助您的应用。让我们来看看迁移学习是如何工作的。迁移学习的工作原理如下。假设您想要识别从0~9的手写数字,但是没有那么多手写数字的标记数据。假设找到一个非常大的数据集,其中包含一百万张猫、狗、汽车、人等图片,一千个类别。然后,在这个包含一百万张图像和一千个不同类别的大型数据集上训练神经网络,以图像1,000个不同类别中的任何一个。在此过程中,学习神经网络第一层的参数10个输出单元(而不是1,000个)的输出层。这 10个输出单元将对应于神经网络识别的类别Adam优化算法),并使用来自顶层神经网络的值初始化参数。
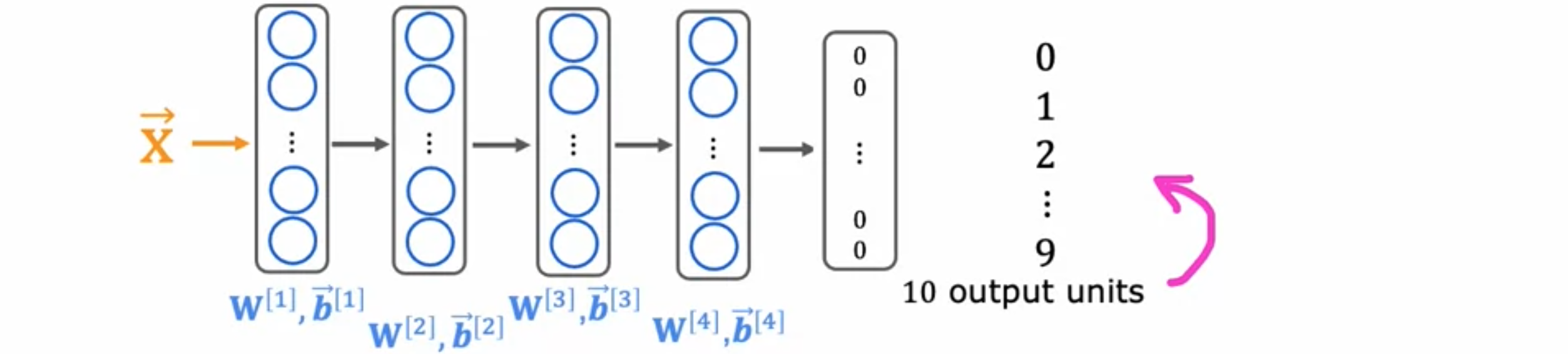
具体来说,有两种方式可以训练这个神经网络参数。选项1是只训练输出层参数。可以将参数Adam优化算法仅更新2是训练神经网络中的所有参数,包括1可能会更好一些,但是如果训练集稍大一些,那么选项2可能会更好一些。这种算法之所以被称为迁移学习,是因为通过学习识别猫、狗、牛、人等等。希望它已经学会了一些合理的参数集,用于处理图像输入的早期层。然后通过将这些参数转移到新的神经网络,新的神经网络会从更好的参数开始,这样我们就可以进行进一步的学习。希望它最终能得到一个相当不错的模型。这两个步骤,首先在大型数据集上进行训练,然后在较小的数据集上进一步调整参数,第一步被称为监督预训练。然后第二步称为微调,从监督预训练中获得的参数,然后进一步运行梯度下降来微调权重。如果有一个小型数据集,即使只有几十、几百、几千或几万张手写数字图像,能够从这些与任务不太相关的数百万张图像中学习,实际上可以大大提高学习算法的性能。迁移学习的一个好处是不需要亲自进行监督式预训练。对于许多神经网络,已经有研究人员在大型图像上训练了一个神经网络,并将训练好的神经网络发布在互联网上,任何人都可以免费下载和使用。意味着你不必自己执行第一步,只需下载别人可能花了数周时间训练的神经网络,然后替换输出即可。将层与自己的输出层组合,并执行选项1或选项2来微调其他人已经进行过监督预训练的神经网络,只需进行微调,就可以快速获得一个表现良好的神经网络。但为什么迁移学习会有效?如果正在训练神经网络来检测图像中的不同物体,那么神经网络的第一层可能会学习检测图像的边缘。我们认为这些是图像中用于检测边缘的低级特征。这些方块中的每一个都是单个神经元学会检测的可视化,学会将像素组合在一起以找到图像中的边缘。神经网络的下一层然后学习将边缘组合在一起以检测角点。这些方块中的每一个都是单个神经元可能学会检测的可视化,必须学会技术性的、简单的形状,如像这样的角点形状。神经网络的下一层可能已经学会检测一些更复杂但仍然是通用的形状,如基本曲线或像这样的较小形状。这就是为什么通过学习检测大量不同的图像,从而教授神经网络检测边缘、角点和基本形状。这对许多计算机视觉任务很有用,例如识别手写数字。不过预训练的一个限制是,预训练和微调步骤中的图像类型
以语音识别为例来说明机器学习项目的整个开发周期。机器学习项目的第一步是确定项目范围(你想做什么)。决定要做什么之后,接下来需要收集数据。决定需要什么数据来训练机器学习系统。在完成初始数据收集后,就可以开始训练模型了。在这里,训练语音识别系统并进行误差分析,然后迭代改进模型。在对训练模型进行误差分析或偏差方差分析后,接下来可能需要回去收集更多数据,或者只收集更多特定类型的数据。训练出高性能机器学习模型(例如语音识别模型)后,部署模型的常见方法是将机器学习模型部署到服务器中,一般将这个服务器称为推理服务器,它的工作是调用机器学习模型(即训练好的模型)进行预测。机器学习中有一个不断发展的领域,称为MLOps。代表机器学习操作。这指的是如何系统地构建、部署和维护机器学习系统的实践。为了确保机器学习模型可靠、可扩展、具有良好的规律、受到监控,然后根据需要对模型进行更新以使其运行良好。
如果正例与负例的比例非常不平衡,远远偏离50%:50%,错误指标(如准确率)的效果就不太好。假设你正在训练一个二元分类器,根据实验室测试的数据来检测患者的罕见疾病。如果疾病存在,则1%的错误率,正确率为99%。如果你有一个算法实现了99.5%的准确率,另一个算法实现了99.2%的准确率,另一个算法实现了99.6%的准确率。很难知道哪一个才是最好的算法。因为误差最小的可能不是特别有用的预测,在处理倾斜数据集的问题时,我们通常使用不同的误差度量,而不仅仅是分类误差,来确定学习算法的表现如何。具体来说,常见的误差度量是精确度和召回率。为了评估学习算法对一个罕见类的性能,构建一个所谓的混淆矩阵很有用,它是一个1或0。在纵轴上,我将写下预测类别,为了评估算法在交叉验证集上的表现,100个交叉验证示例,其中15个,学习算法预测为1。因为在交叉验证集的这100个示例中,总共有25个示例的实际类别为1,75个示例的实际类别为0,通过将这些数字垂直相加即可。当实际类别为1且预测类别为1时,我们将其称为真阳性,因为预测为阳性,并且结果为真,因此有一个阳性示例。在右下角的这个单元格中,实际类别为0,且预测类别为0,将其称为真阴性,右上角的这个单元格称为假阳性,因为算法预测为阳性,但结果为假。它实际上不是阳性,所以这被称为假阳性。这个单元格称为假阴性数量,因为算法预测为0,但结果为假。它实际上不是阴性。实际类别为1。将分类为这四个单元格,您可能要计算的两个常见指标是精确度和召回率。它们的含义如下。学习算法的精确度计算75%,因为它预测为阳性的所有事物中,患有这种罕见疾病的所有患者中,它有75%的时间是正确的。第二个有用的计算指标是召回率。召回率指的是:在所有确实患有罕见疾病的患者中,我们正确检测出患有该疾病的比例是多少?召回率定义为真阳性数除以实际阳性数。它实际上是真阳性数加上假阴性数,因为通过将这个左上单元格和这个左下单元格相加,可以得到实际阳性示例的数量。在这个例子中,召回率是0.75,召回率为0.60。


召回率指标有助于您检测学习算法是否一直预测为零。因为如果您的学习算法只是打印75%,同时还要确保在所有患病的病人中,比如这里发现了60%。当你有一个罕见的类别时,查看精确度和召回率,并确保这两个数字都相当高。如果你有一组病人,那么召回率衡量的是在患有这种疾病的病人中,有多少人你能准确地诊断为患有这种疾病。所以当你有偏斜的类别,精确度和召回率可以帮助你判断学习算法是否做出了好的预测。