机器学习(ML)(五) — 探析
介绍
构建逻辑回归模型的第一步是指定如何根据输入特征z = np.dot(w , x) + b, f_x = 1/(1 + np.exp(-z))。
第一步是指定逻辑回归的输入到输出函数是什么?这取决于输入loss = -y * np.log(f_x) - (1-y) * np.log(1 - f_x)。这是衡量逻辑回归在单个训练示例w = w - alpha * dj_dw, b = b - alpha * dj_db。第一步,指定如何根据输入TensorFlow中训练神经网络的方法。现在让我们看看这三个步骤如何映射到训练神经网络。第一步是指定如何根据输入
1 | model = Squential([Dense(...),Dense(...),Dense(...)]) |
第二步是编译模型并告诉它要使用什么损失,这是用于指定此损失函数的代码:model =.compile(loss = BinaryCrossentropy()),即二元交叉熵损失函数,一旦指定此损失,对整个训练集取平均值,然后第三步是调用函数将成本最小化为神经网络参数的函数:model.fit(x,y,epochs = 100)。接下来更详细地了解这三个步骤。第一步,指定如何根据输入25个隐藏单元,下一个隐藏层有15个隐藏单元,然后是一个输出单元,使用S型激活值。
1 | import tensorflow as tf |
基于此代码片段,我们还知道第一层的参数0,要么是1,到目前为止最常见的损失函数是TensorFlow中,这称为二元交叉熵损失函数。这个名字从何而来?在统计学中,这个函数被称为交叉熵损失函数,而二元这个词只是再次强调这是一个二元分类问题,因为每个图像要么是0,要么是1。TensorFlow使用此损失函数,keras最初是一个独立于TensorFlow开发库,实际上是与TensorFlow完全独立的项目。但最终它被合并到TensorFlow中,这就是为什么有tf.Keras库。指定了单个训练示例的损失后,TensorFlow知道您想要最小化的成本是平均值,即对所有训练示例的损失取所有m个训练示例的平均值。如果想解决回归问题而不是分类问题。可以告诉TensorFlow使用其它的损失函数编译模型。例如,如果有一个回归问题,并且如果想最小化平方误差损失。如果学习算法输出1/2。然后在TensorFlow中使用此损失函数。在这个表达式中,成本函数表示为表示为:TensorFlow最小化交叉函数。使用梯度下降法训练神经网络的参数,那么对于每个层100次梯度下降迭代之后,希望能得到一个好的参数值。为了使用梯度下降法,需要计算的关键是这些偏导数项。神经网络训练的标准做法,是使用一种称为反向传播的算法来计算这些偏导数项。TensorFlow可以完成所有这些工作。称为fit的函数中实现了反向传播。您所要做的就是调用model.fit(X、y, epochs=100)作为训练集,并告诉它进行100次迭代。

激活函数
到目前为止,在隐藏层和输出层的所有节点中都使用了S型激活函数。之所以这样做,是因为逻辑回归构建神经网络,并创建了大量逻辑回归单元并将它们串联在一起。如果使用激活函数,神经网络会变得更加强大。例如给定价格、运费、营销、材料,尝试预测某件商品是否非常实惠。如果知名度高且感知质量高,则尝试预测它是畅销品。但知名度可能是二元的,即人们知道或不知道。但似乎潜在买家对你所销售的T恤的了解程度可能不是二元的,他们可能有点了解,了解,非常了解,或者它可能已经完全流行起来。因此,不应将意识建模为二进制数0、1,而应估计意识的概率。也许意识应该是任何非负数,因为意识可以是任何非负值,从0到非常大的数字。因此,之前曾使用这个方程来计算第二个隐藏单元的激活(估计意识)
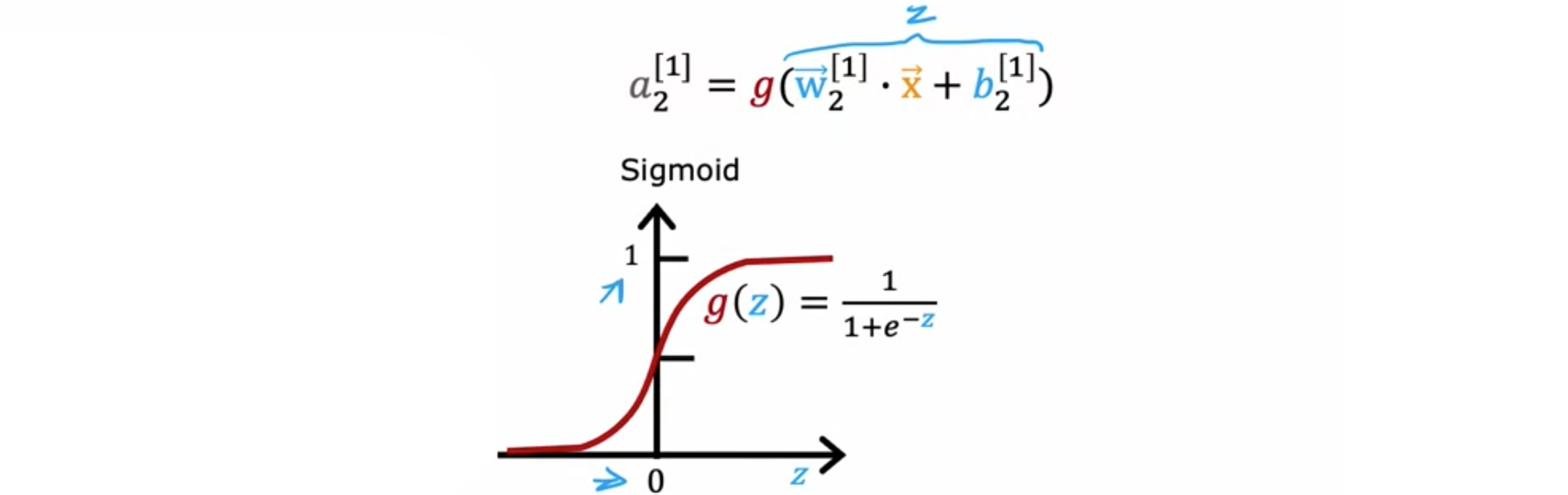
如果想让45°的直线。
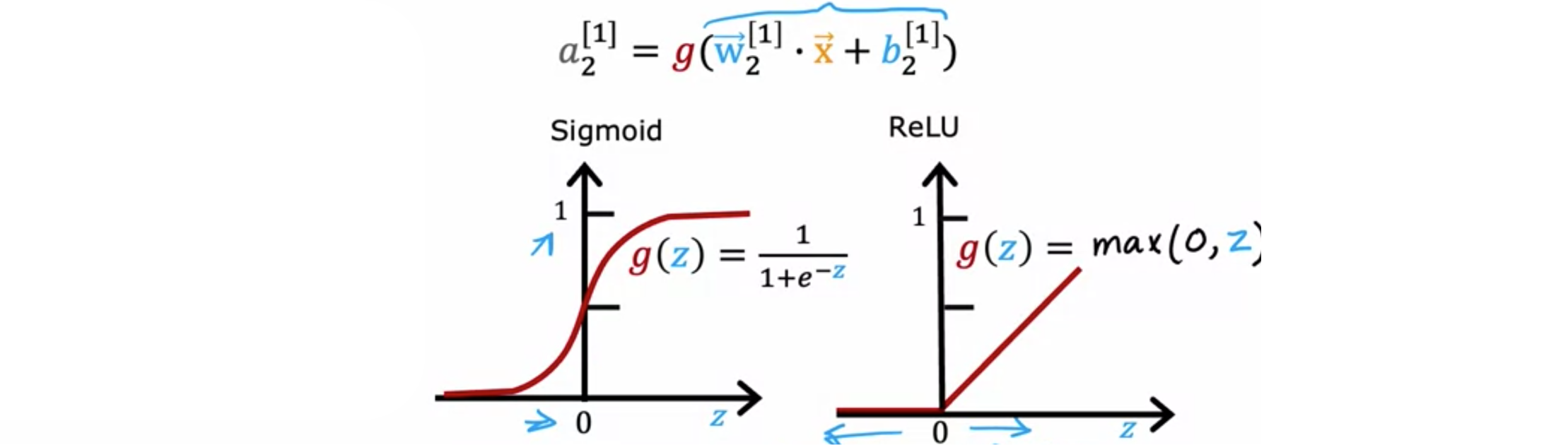
数学方程为ReLU,整流线性单元。还有一个值得一提的激活函数,称为线性激活函数,也就是
如何为神经网络中的神经元选择不同的激活函数。首先介绍如何为输出层选择激活函数,然后介绍隐藏层激活函数的选择。当考虑输出层的激活函数时,通常会有一个很自然的选择,具体取决于目标标签0或1,即二元分类问题,S型激活函数是最自然的选择,因为神经网络会学习预测S型函数。如果正在解决回归问题,那么可以选择其它的激活函数。例如,如果预测明天的股价与今天的股价相比会如何变化。它可以上涨也可以下跌,在这种情况下,建议使用线性激活函数。使用线性激活函数,ReLU激活函数,因为这个激活函数只取非负值,要么是零,要么是正值。在选择用于输出层的激活函数时,通常取决于预测的标签
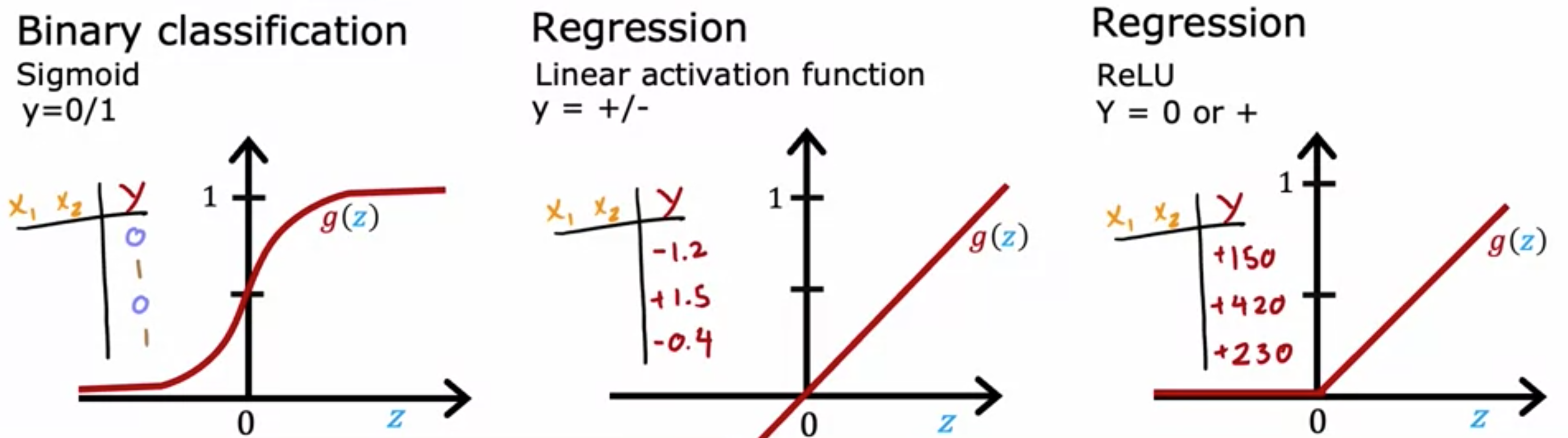
神经网络的隐藏层呢?ReLU激活函数是许多训练神经网络的最常见选择。在神经网络发展的早期历史中,人们在许多地方使用S型激活函数,但该领域已经发展到更频繁地使用ReLU。唯一的例外是,如果有一个二元分类问题,那么在输出层使用S型激活函数。那么为什么呢?首先,如果比较ReLU和S型激活函数,ReLU的计算速度要快一点,因为它只需要计算S型激活函数需要先求幂,然后求逆等等,所以效率稍低一些。但第二个原因更为重要,那就是ReLU激活函数只在图的一部分中平坦;这里左边是完全平坦的,而S型激活函数在两边都平坦。如果你使用梯度下降来训练神经网络,那么当在很多地方都很胖的函数时,梯度下降会非常慢。梯度下降优化的是成本函数ReLU激活函数可以让神经网络学习得更快一些,在隐藏层中使用ReLU激活函数已经成为最常见的选择。

总而言之,对于输出层,使用S型函数,如果你有一个二元分类问题;如果ReLU激活函数。对于隐藏层,建议ReLU作为默认激活函数,在TensorFlow中,您可以这样实现它。
1 | import tensorflow as tf |
顺便说一句,如果你看看研究文献,有时会看到作者使用其他的激活函数,例如tan h激活函数、LeakyReLU激活函数或swish激活函数。
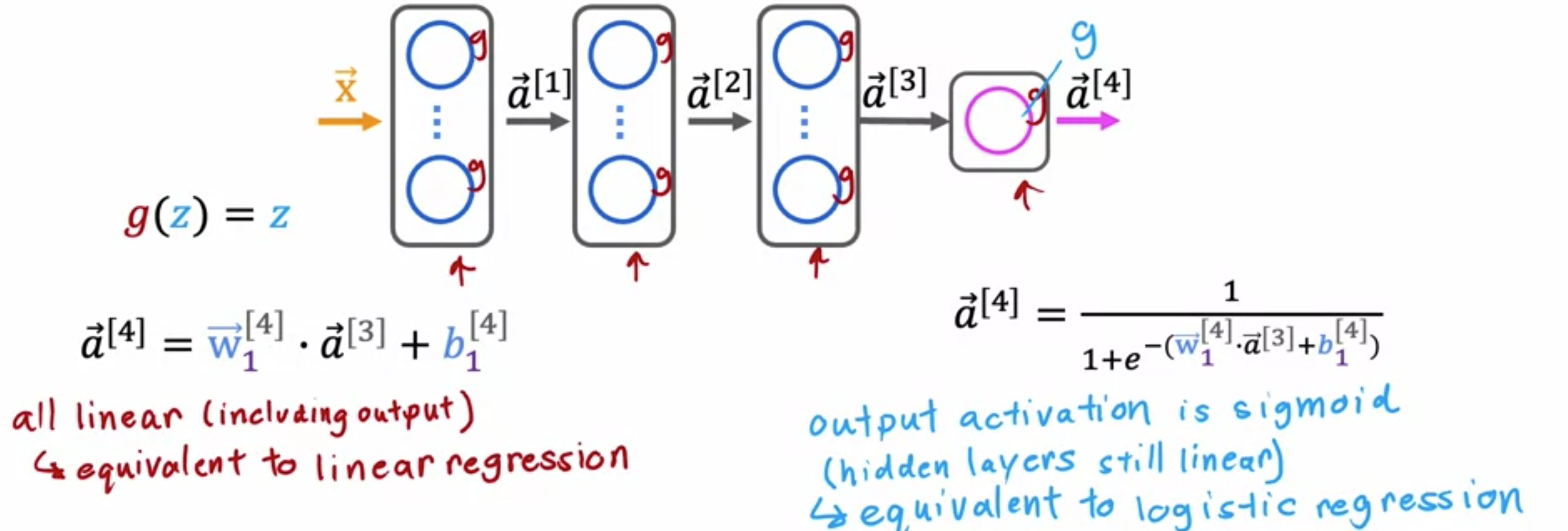
为什么神经网络需要激活函数?如果对神经网络中的所有节点都使用线性激活函数,会发生什么?这个神经网络将变得与线性回归没有什么不同。看一个神经网络的例子,其中输入ReLU激活函数就可以了。
多元分类(softmax)
多元分类是指分类问题,其中的输出标签不止两个。对于手写数字分类问题,我们只是试图区分手写数字0和1。但是,如果阅读信封中的邮政编码,则想要识别10个可能的数字。患者是否可能患有三种或五种不同的疾病进行分类。这也是一个多元分类问题,您可能会查看制药公司生产的药丸的图片,并试图弄清楚它是否有划痕效果、变色缺陷或芯片缺陷。这又将有多种不同类型的缺陷,您可以对这种药丸进行分类。因此,多元分类问题仍然是分类问题,因为O代表一个类,x代表另一个类。三角形代表第三类,正方形代表第四类。那么
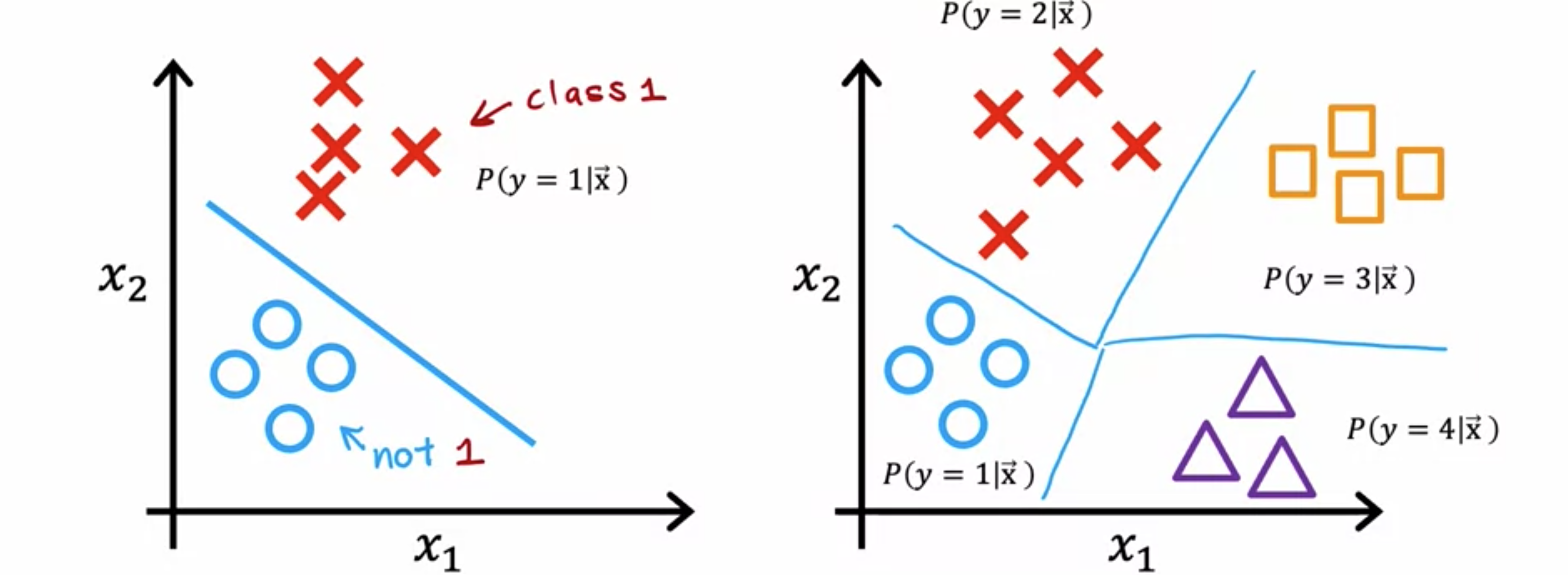
softmax回归算法是逻辑回归的泛化,逻辑回归是一种二元分类算法,适用于多元分类场景。让我们来看看它是如何工作的。回想一下,当0或1)时,适用于逻辑回归,首先计算S型激活函数。给定输入特征1。将逻辑回归视为计算两个数值:第一个是softmax回归,使用一个具体的例子来说明当softmax回归执行的操作,计算softmax回归的参数。接下来,softmax回归的公式,计算
参数1,因此n个可能值,因此softmax回归计算为softmax回归的参数为softmax回归,那么只有两个输出类,softmax回归计算的结果与逻辑回归基本相同。这就是softmax回归模型是逻辑回归的泛化原因。在定义了softmax回归如何计算其输出,现在看一下如何指定softmax回归的成本函数。回想一下逻辑回归。之前softmax回归的成本函数,如果在
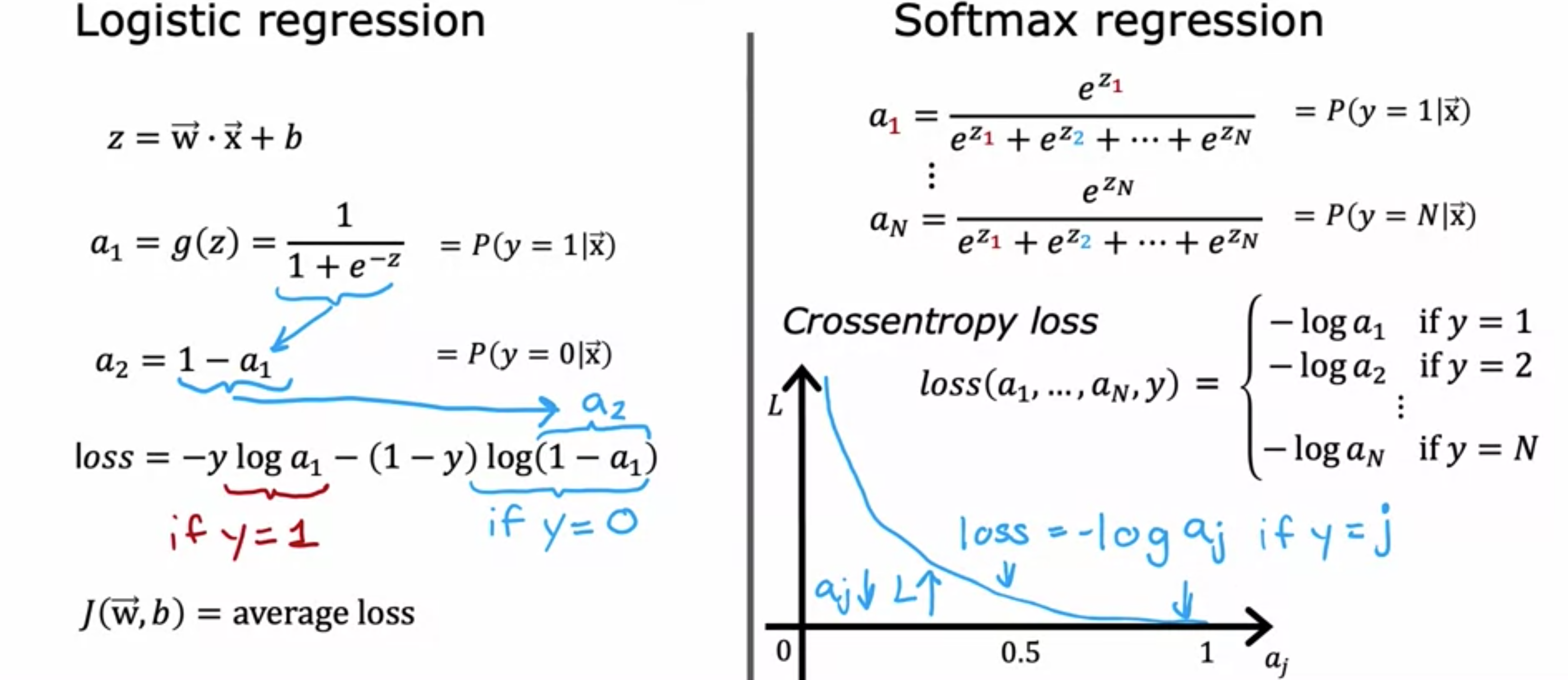
如果1。请注意,每个训练示例中的softmax回归的成本函数。如果您要训练此模型,则可以构建多元分类算法。
为了构建一个可以进行多元分类的神经网络,我们将采用Softmax回归模型,并将其放入神经网络的输出层。如果要对10个类(0~9)进行手写数字分类,那么神经网络具有10个输出单元,如下图所示。这个新的输出层将是一个softmax输出层。有时会说这个神经网络有一个softmax输出。这个神经网络中的前向传播工作方式是给定一个输入softmax层有时也称为softmax激活函数,对于softmax激活函数,softmax激活函数独有的属性。
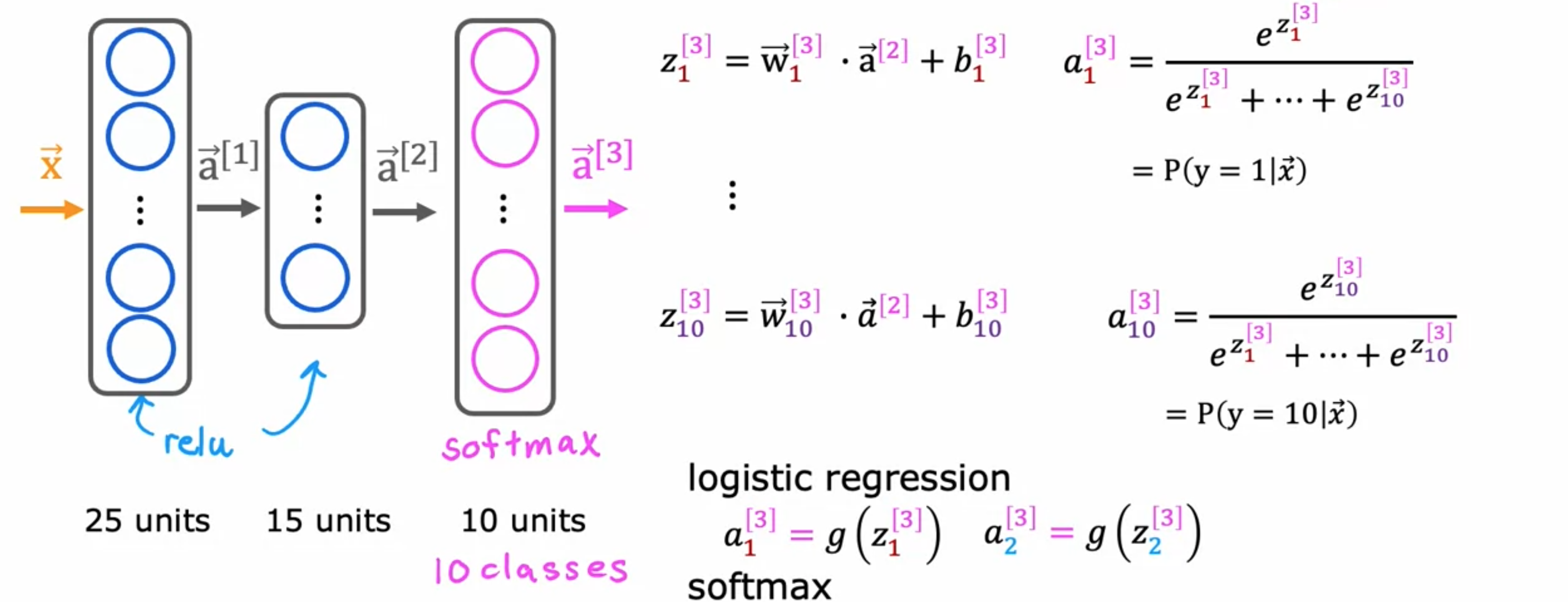
最后,让我们看看如何在TensorFlow中实现它。训练模型有三个步骤。第一步是告诉TensorFlow按顺序串联三层。第一层是25个单元的ReLU激活函数。第二层是15个单元的ReLU激活函数。然后第三层是10个输出单元的softmax激活函数。TensorFlow中的成本函数称之为SparseCategoricalCrossentropy。而对于逻辑回归,有BinaryCrossEntropy函数。稀疏分类指的是将10个值中的一个。你不会看到一幅图像同时是2和7,所以稀疏是指每个数字只是这些类别中的一个。
1 | import tensorflow as tf |
在计算机中计算相同数值的两种不同方法。选项一,可以将softmax成本函数的方法是正确的,但还有一种不同的方法可以减少这些数值舍入误差,从而在TensorFlow中进行更准确的计算。让我首先使用逻辑回归更详细地解释这一点。然后我们将展示如何将这些想法应用于改进我们的 softmax 实现。首先,让我使用逻辑回归来说明这些想法。然后我们将继续展示如何改进您的 softmax 实现。回想一下,对于逻辑回归,如果要计算给定示例的损失函数,则首先要计算此输出激活
1 | import tensorflow as tf |
对于逻辑回归,通常数值舍入误差不会那么严重。TensorFlow不用将TensorFlow提供了更大的灵活性。代码如下所示,它的作用是将输出层设置为线性激活函数,并将激活函数
1 | import tensorflow as tf |
from_logits = True参数。如果想知道logits是什么,它就是这个TensorFlow会将TensorFlow的数值舍入误差小一些。在逻辑回归的情况下,这两种实现实际上都可以正常工作,但当涉及到softmax时,数值舍入误差会变得更糟。现在将这个想法应用于softmax回归。回想一下上一个例子,按如下方式计算激活。激活是TensorFlow可以重新排列项,并以精确的方式进行计算。如果z非常小,TensorFlow可以避免一些非常小或非常大的值,从而为损失函数提供更精确的计算。执行此操作的代码显示在输出层中,现在只使用线性激活函数,输出层只计算from_logists = True参数。Logist回归的数值舍入误差并不是那么糟糕,但建议您改用此实现,从概念上讲,此代码与您之前的第一个版本的功能相同,只是它在数值上更精确一些。虽然缺点可能也更难理解。现在还有一个细节,就是将神经网络中的输出层更改为使用线性激活函数,而不是softmax激活函数。神经网络的输出层不再输出
1 | import tensorflow as tf |
还有一种不同类型的分类问题,称为多标签分类问题,即每个图像可能有多个标签。如果您正在构建自动驾驶汽车或驾驶员辅助系统,那么给出一张汽车前方的图片,您可能想问一个问题,例如,有汽车吗?或者有公共汽车吗?或者有行人吗?在这种情况下,有汽车,没有公共汽车,至少有一名行人,或者在第二张图片中,没有汽车,没有公共汽车,有行人;有汽车,有公共汽车,没有行人。这些是多标签分类问题的示例,因为与单个输入图像10个不同的值。如何构建多标签分类的神经网络?一种方法是将其视为三个完全独立的机器学习问题。您可以构建一个神经网络来判断是否有汽车?第二个神经网络用于检测公交车,第三个神经网络用于检测行人。其实这是一个不合理的方法。还有另一种方法,即训练单个神经网络同时检测汽车、公共汽车和行人这三种情况,如果神经网络架构如下图所示,输入S型激活函数

梯度下降是一种在机器学习中广泛使用的优化算法,也是许多算法(如线性回归和逻辑回归)以及神经网络早期实现的基础。现在有一些其他优化算法可以最小化成本函数,这些算法甚至比梯度下降更好。回想一下,梯度下降时间步的表达式。参数
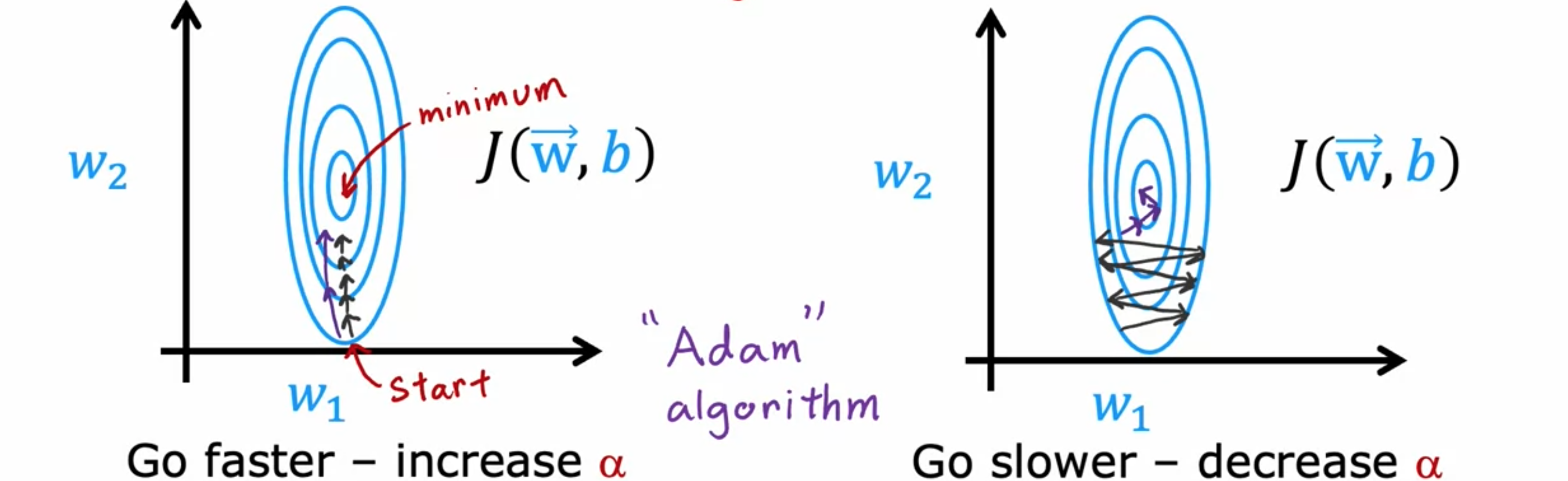
称为Adam算法可以做到这一点。如果发现学习率太小,应该把学习率Adam算法可以自动做到这一点,使用较小的学习率,可以更平滑地找到成本函数的最小值。根据梯度下降的方式,有时希望学习率Adam算法可以自动调整学习率。Adam代表自适应估计。Adam算法不使用单一的全局学习率11个学习率参数Adam可以自动调整学习率,因此它对学习率的选择更具鲁棒性。不过,可以通过调整此参数来查看是否可以加快学习速度。Adam优化算法比梯度下降法更加有效的算法,如果你正在决定使用哪种学习算法来训练神经网络。一个安全的选择是Adam优化算法。
1 | import tensorflow as tf |
到目前为止,所有神经网络层都是密集层类型,其中层中的每个神经元都从前一层获得其输入的所有激活。仅使用密集层类型就可以构建一些非常强大的学习算法。还有其他类型的层,它们具有其他属性。回顾一下,在密集层中,我们一直在使用第二个隐藏层中神经元的激活,它是前一层的所有单个激活值的函数。可能在某些神经网络中看到的另一种层类型称为卷积层。用一个例子来说明这一点。这里有一个输入9。需要构建一个隐藏层,它将根据输入图像
这里使用的示例是心电图的分类。如果你在胸部放置两个电极,将记录与心跳相对应的电压。实际上正在读取EKG信号,用来尝试诊断患者是否有心脏问题。因此,在某些地方只有一串数字,对应于不同时间点的表面高度。可能有100个数字对应于100个不同时间点的曲线高度。并且学习抛出这个时间序列,给定这个EKG信号来分类,例如,这个患者是否患有心脏病。这就是卷积神经网络目的。把EKG信号旋转90度,放在一边。这样就有100个输入,从100个数字。第一个隐藏单元只看EKG 信号的一个小窗口。第二个隐藏单元只看EKG信号的另一个窗口。第三个隐藏单元看另一个窗口EKG时间序列末尾的一个小窗口。这是一个卷积层,因为这一层中的这些单元只查看输入的有限窗口。神经网络的这一层有九个单元。下一层也可以是卷积层。在第二个隐藏层中,设计的第一个单元,使其不查看前一层的所有9个激活,而是查看前一层的前5个激活5个激活5个激活S单元,该单元会查看
反向传播
您已经了解了如何在TensorFlow中指定神经网络架构输入TensorFlow将自动使用反向传播来计算导数并使用梯度下降或Adam来训练神经网络的参数。反向传播算法是神经网络学习中的关键算法。但它实际上是如何工作的呢?让我们来看看。简化的成本函数0.001,那么0.001,使用向上的箭头来表示6倍,即0.006。它实际上不是增加到9.006,而是9.006001。如果6倍的0.002,那么6倍的1:6。
计算图是深度学习的一个关键思想,也是TensorFlow等编程框架自动计算神经网络导数的方式。让我们来看看它是如何工作的。这里用一个小的神经网络示例来说明计算图的概念。这个神经网络只有一层,也是输出层,输出层只有一个单元。它接受输入

如果2变为了2.01,那么2变为2.02。因此,如果2。反向传播的第一步是在这里填入2。我们知道如果2。接下来是查看上一个的节点,0.001,0.001,0.001。但是已经得出结论,0.001,0.001,0.001,那么0.002。则1,0.001,0.001,0.001。如果0.001,那么0.002。最后得出结论,如果0.001,那么0.001,则0.002。现在最后一步,即0.001。2.001,则0.002,如果0.002,则0.004。得出结论,如果0.001,0.004。则0.001,那么0.000002,因此4倍的4倍的p个参数,那么在这种情况下有两个参数。这个计算过程能够在大约10,000个节点和100,000个参数。按照现代标准,这不算是一个非常大的神经网络。能够计算