深度学习(DL)(二) — 探析
介绍
我们一直在使用词汇表来表示单词,词汇表可能有10,000个单词。我们一直在使用1-hot向量(1-Hot编码是一种用于表示分类数据的技术,广泛应用于机器学习和深度学习中。它将每个类别转换为一个二进制向量,向量的长度等于类别的总数。每个向量中只有一个元素为1,其余元素均为0。)来表示单词。例如,如果man是本词典中的第5391个单词,那么你可以用一个在位置5391处为1的向量来表示。我还将使用O代表1-hot。如果woman是第9853个单词,那么你可以用9853处只有一个1,其他地方都是0。然后其他单词king、queen、apple、orange将同样用1-hot向量表示。这种表示的缺点之一是它将每个单词视为一个独立的事物,并且它不允许算法概括交叉单词。
例如,假设你有一个语言模型,它已经学会了当你看到我想要一杯橙子__时。那么,你认为下一个词会是什么?很有可能是果汁。但是,即使学习算法已经知道我想要一杯橙汁,如果它看到我想要一杯苹果,没有任何关系。苹果和橙子之间的关系并不比其他任何单词男人、女人、国王、王后和橙子之间的关系更紧密。因此,学习算法很难知道橙汁是一种流行的东西,推广到苹果汁也可能是一种流行的东西或一个流行的短语。这是因为任何两个不同的1-hot向量之间的任何乘积都是0。如果你取任何两个向量,比如说,女王和国王,它们的乘积是0。如果你取苹果和橙子,它们的乘积是0。无法让这些向量中的任何一对之间的距离也相同。所以它只是不知道苹果和橙子比国王和橙子或王后和橙子更相似。那么,如果我们不使用1-hot向量表示,而是学习每个单词的特征表示,男人、女人、国王、王后、苹果、橙子,字典中的每个单词,我们可以学习每个单词的一组特征和值,那不是很好吗?例如,如果性别从男性的-1变为女性的+1,那么与男人相关的性别可能是-1,与女人相关的性别可能是+1。最终,学习这些东西,对于国王,你可能会得到-0.95,对于王后,你会得到+0.97,而对于苹果和橙子,你可能会得到无性别。另一个特征是这些东西有多高贵。男人和女人并不是真正的高贵,所以他们的特征值可能接近于0。而国王和王后则非常高贵。而苹果和橙子并不是真正的高贵。年龄呢?男人和女人与年龄没有太大关系。也许男人和女人暗示是成年人,但可能既不一定年轻也不一定年老。所以可能值接近于0。而国王和王后几乎总是成年人。苹果和橙子在年龄方面可能更中性。这里的另一个特征是,这是食物吗?男人不是食物,女人不是食物,国王和王后也不是,但苹果和橙子是食物。它们还可以是许多其他特征,大小是多少?价格是多少?这是生命吗?这是一个动词还是名词等等。所以你可以想象出很多特征。为了便于说明,我们假设有300个不同的特征,它的作用是获取这个数字列表,这里只写了四个,但这可能是包含300个数字的列表,然后变成一个300维向量来表示单词man。使用符号 300维向量,表示为woman的300维向量。对于这里的其他示例,也是如此。如果用此来表示单词orange和apple,那么请注意,orange和apple的表示非常相似。某些特征会因橙子的颜色、苹果的颜色、味道而有所不同,或者某些特征会有所不同。但总的来说,apple和orange的很多特征实际上是相同的,或者具有非常相似的值。这使其能够更好地表示不同的单词。

这些表示将在300维空间中使用这些特征化的表示,这些被称为嵌入。它们不能在二维空间中绘制,因为它是3D空间。你要做的是,把每个单词(如 orange)都取出来,并得到一个三维特征向量,这样单词orange就嵌入到这个300维空间中的一个点。而单词apple则嵌入到300维空间的另一个点。当然,为了将其可视化,像t-SNE这样的算法会将其映射到一个低维空间,你可以绘制二维数据并查看它。但这就是嵌入的由来。词嵌入一直是NLP中最重要的思想之一。
词嵌入
让我们从一个例子开始。继续使用命名实体识别示例,如果您尝试检测人的名字。给出一个句子,如Sally Johnson is an orange farmer,希望能弄清楚Sally Johnson是一个人的名字,确保Sally Johnson必须是一个人,而不是说公司的名称,您知道orange farmer是一个人。之前讨论了1-hot来表示这些单词,
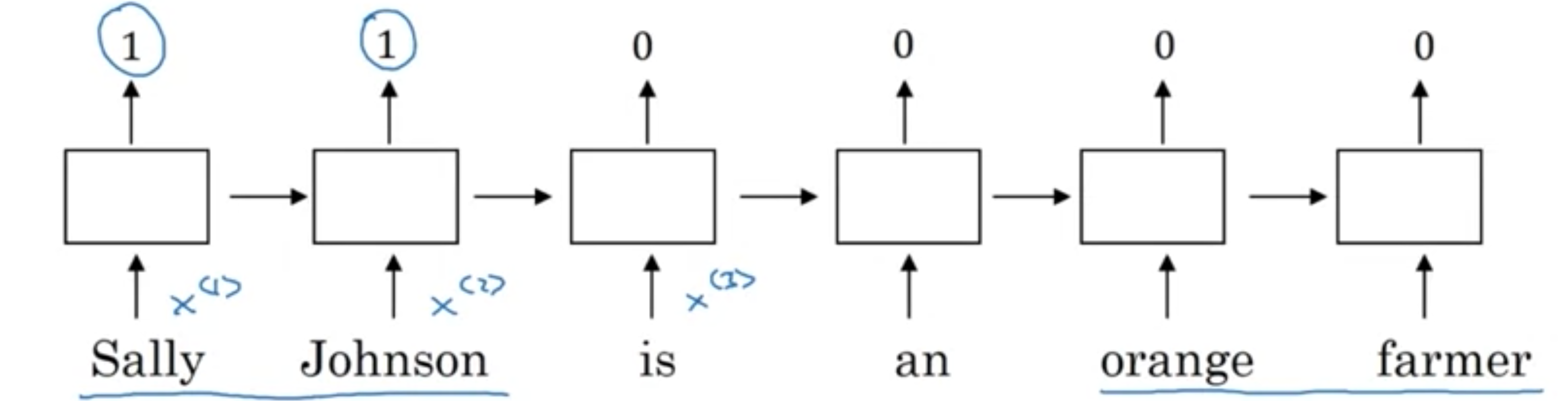
但是如果使用特征化表示,在训练了一个使用词嵌入作为输入的模型之后,如果看到一个新的输入,Robert Lin is an apple farmer。橙子和苹果非常相似,将使学习算法更容易表示,从而找出Robert Lin也是一个人的名字。如果在测试集中没有看到Robert Lin is an apple farmer,但看到了不常见的单词,那会怎么样?如果你看到Robert Lin is a dusian cultiztor,那会怎么样?榴莲是一种稀有的水果。但是如果你有一个用于命名实体识别任务的小标签训练集,没有在训练集中看到榴莲这个词,也没有看到种植者这个词。如果已经学习了词嵌入,告诉你榴莲是一种水果,所以它就像一个橙子,而种植者,种植的人就像一个农民,那么你可能仍然会在你的训练集中看到橙子农民的表示知道榴莲种植者也可能是一个人。词向量能够做到这一点的原因是,学习词向量的算法可以检查非常大的文本语料库,这些文本语料库可能是从互联网上找到的。因此,可以检查非常大的数据集,也许有十亿个单词,甚至多达1000亿个单词也是相当合理的。只有未标记的文本的训练集非常大。通过检查大量未标记的文本),你会发现橙子和榴莲很相似。农民和种植者也很相似,因此,学习嵌入,将它们归为一类。现在,通过阅读大量互联网文本,你发现橙子和榴莲都是水果,你可以将这个词嵌入应用到命名实体识别任务中,而命名实体识别任务的训练集可能要小得多,训练集中可能只有10万个单词,甚至更小。这允许进行迁移学习,从大量未标记的文本中获取信息,这些信息基本上是免费的,可以从互联网上获取,从而找出橙子、苹果和榴莲是水果。然后将这些知识迁移到命名实体识别等任务中,而命名实体识别任务的标记训练集可能相对较小。当然,为了简单起见,将其绘制为单向RNN。如果你真的想执行命名实体识别任务,当然应该使用双向RNN,而不是简单的RNN。
总而言之,这就是使用词向量进行迁移学习的方法。第一步是从大型文本语料库(非常大的文本语料库)中学习词向量,或者也可以在线下载预先训练好的词向量。然后,您可以利用这些词向量,将嵌入迁移到新任务中,在那里,您有一个小得多的标记训练集。使用这个300维嵌入来表示您的单词。这样做还有一个好处,就是可以使用相对低维的特征向量。因此,可以使用300维的密集向量,而不是使用10,000维的1-hot向量。尽管1-hot向量很快,但嵌入学习的300维向量是一个密集向量。当你在新的任务上训练模型时,在具有较小标签数据集的命名实体识别任务上,你可以继续微调,继续使用新数据调整词嵌入。只有当这个任务具有相当大的数据集时,你才会这样做。如果标签数据集非常小,通常不会费心继续微调词嵌入。对许多NLP任务都很有用。它对命名实体识别、文本摘要、解析都很有用。这些可能是非常标准的NLP任务。它对于语言建模、机器翻译的用处不大,特别是语言建模或机器翻译任务,而你有大量专门用于该任务的数据。正如在其他迁移学习设置中所看到的,如果从某个任务A迁移到某个任务B,迁移学习过程只有在恰好拥有大量A数据和相对较小的B数据集时才最有用。这对于NLP任务来说都是如此,但对于某些语言建模和机器翻译来说则不那么如此。
最后,编码和嵌入这两个词的意思相当相似。在人脸识别文献中,人们也使用编码来指代这些向量10,000个单词。我们将学习向量
词嵌入最迷人的特性之一是可以进行类比推理。这里词嵌入可以捕获的一组单词的特征表示。假设提出一个问题,男人之于女人就像国王之于什么?许多人会说,男人之于女人就像国王之于王后。但是,是否能让算法自动解决这个问题?可以这样做,假设使用四维向量来表示男人。这将是50~1,000维。这些向量的一个有趣特性是,如果1-1,因为国王和王后的皇室地位大致相同。所以这是0,然后是年龄差异,食物差异,0。所以这捕捉到的是男人和女人之间的主要差异是性别。而国王和王后之间的主要差异,正如这些向量所表示的,也是性别。Tomas Mikolov、Wentau Yih和Geoffrey Zweig首次提出的。这是关于词嵌入最具影响力的结果之一。这有助于整个社区更好地了解词嵌入的作用。
词嵌入可能存在于300维空间中。单词man表示为空间中的一个点,单词woman表示为空间中的一个点。单词king表示为另一个点,单词queen表示为另一个点。男人和女人之间的向量差异与国王和王后之间的向量差异非常相似。箭头实际上是表示性别差异的向量。为了类比推理来弄清楚,男人和女人的关系是国王和什么的关系,你可以尝试找到单词w,使这个等式成立:w的嵌入与右边的相似度。然后找到使相似度最大化的单词。值得注意的是,这确实有效。如果学习一组单词嵌入并找到一个使这种相似度最大化的单词w,可以得到完全正确的答案。只有当它正确猜出单词时,类比才算正确。只有在这种情况下,选出了单词“queen”。t-SAE所做的是获取300维数据,并以非线性的方式将其映射到2D空间。t-SAE学习的映射是一种非常复杂且非线性的映射。实际上,在这个300维空间中,在通过t-SAE映射后,平行四边形关系可能成立,但在大多数情况下,由于t-SAE的非线性映射,不应指望这一点。 t-SAE会破坏许多平行四边形类比关系。最常用的相似性函数称为余弦相似性。在余弦相似性中,你将两个向量0,则余弦相似度等于1。如果它们的角度是90度,余弦相似度就是0。如果它们的角度是180度,余弦相似度最终就是-1。它对这些类比推理任务非常有效。你也可以使用平方距离或欧几里得距离,
当你实现一个算法来学习词嵌入时,最终会学习一个嵌入矩阵。假设使用10,000个单词的词汇表。词汇表中有A、Aaron、Orange、Zulu,也许还有未知单词作为标记。学习嵌入矩阵10,000个单词的词汇表,10,001是未知单词标记,那么就会有一个额外的标记。Orange是10,000个单词的词汇表中的第6257个单词。符号1-hot向量,只有位置6257处是1,其它都是0。它应该和左边的嵌入矩阵一样高。如果嵌入矩阵1-hot向量,再乘以6257中的0,那么这是一个300维的向量。300维向量的第一个元素,您要做的就是将矩阵6257之外,其它元素都是0,最终你会得到第一个元素,即上面的Orange列下的元素。然后,计算300维向量的第二个元素,你需要取向量1-hot向量选出这个对应于单词Orange的300维列。这等于Orange的300个一维向量的嵌入向量的符号。
单词嵌入: Word2vec & GloVe
假设正在构建一个语言模型,并且使用神经网络来实现。在训练期间,您可能希望神经网络执行一些操作,例如输入:I want a glass of orange,然后预测序列中的下一个单词。构建神经语言模型是学习一组嵌入的方法。可以这样构建神经网络来预测序列中的下一个单词。拿一个单词列表,I want a glass of orange,让我们从第一个单词I开始。构建一个与单词I相对应的加法向量。在位置4343处有一个值为1的加法向量。这将是10,000维的向量。得到一个参数矩阵want是位置为9665的一个加向量,乘以A是字典中的第一个单词。对于这个短语中的其他单词也是如此。现在你有一堆三维嵌入,每个都是300维的嵌入向量。将它们全部填充到神经网络中。然后神经网络会将数据馈送到softmax,它也有自己的参数。softmax会在词汇表10,000个可能输出中对预测的单词进行分类。如果在训练中看到juice这个词,那么训练中softmax的目标就是预测后面的另一个单词juice。这个隐藏的名称会有自己的参数。将其称为softmax有自己的参数300维词嵌入,这里有六个单词。所以,这是1,800维向量,它通过将六个嵌入向量堆叠在一起而获得。实际上,更常见的做法是使用固定的历史窗口。例如,您可能根据前四个单词来预测下一个单词,其中4是算法的超参数。如果您始终使用四个单词的历史记录,意味着神经网络将输入一个1,200维特征向量,进入这一层,然后使用softmax预测输出。使用固定的历史记录意味着可以处理任意长的句子,因为输入大小始终是固定的。因此,这个模型的参数将是这个矩阵300维特征向量来表示所有这些单词,算法会发现它最适合训练集。如果是苹果、橙子、葡萄、梨等等,也许还有榴莲,这是一种非常稀有的水果,具有相似的特征向量。所以,这是学习词向量的早期且非常成功的算法之一,用于学习这个矩阵a glass of orange,右边有四个单词,你将左侧四个单词和右侧四个单词的嵌入输入到神经网络中,预测中间的单词,将其放在中间的目标单词,这也可以用于学习单词嵌入。或者如果你想使用更简单的上下文,你只使用最后一个单词。那么只给出单词orange,那么orange后面是什么?
Word2vec
上下文不是总是最后四个单词或紧接在目标单词之前的最后一个单词,而是随机选择一个单词作为上下文单词。假设我们选择了单词orange。随机选择某个窗口中的另一个单词。比如说,加上上下文单词的五个单词或加上上下文单词的十个单词,选择它作为目标单词。或者可能在之前选择两个词。目标可能是glass,或者偶然选择了my这个单词作为目标单词。给定上下文词,预测一个随机选择的单词是什么,比如说,在输入上下文词的正负十个单词窗口内,或者正负五或十个单词窗口内。显然,这不是一个非常简单的学习问题,因为在orange这个单词的正负十个单词内,可能有很多不同的单词。但是监督学习问题的目标不是在监督学习问题本身上做得很好,而是想用这个学习问题来学习好的词嵌入。。假设使用10,000个单词的词汇表。但是要解决的监督学习问题是学习从某个上下文orange)到某个目标(称为juice、glass 或my。在词汇表中,orange单词是6257,而单词juice是10,000个单词中的单词4834。要表示诸如单词orange之类的输入,可以从某个1-hot向量开始,该向量将写为1-hot向量。可以取嵌入矩阵softmax单元。将softmax单元绘制为神经网络中的节点。这是softmax单元softmax的损失函数将是常用的。使用1-hot表示。那么损失将是负对数似然,softmax的损失,将目标1-hot向量。这将是一个1-hot向量。如果目标单词是juice,那么它将是上面的元素4834。它等于1,其余的将等于0。softmax单元输出的10,000维向量,其中包含所有10,000个可能目标词的概率:softmax单元还有skip-gram模型,它将一个单词(如orange)作为输入,然后尝试预测一些跳过左侧或右侧几个单词的单词。预测上下文单词之前和之后的单词。事实证明使用这种算法存在一些问题。主要问题是计算速度。特别是对于softmax模型,每次想要评估这个概率时,需要对词汇表中10,000个单词进行求和。也许10,000个还不错,但如果使用的词汇量为100,000或1,000,000,那么每次对这个分母求和就会变得非常慢。事实上10,000已经很慢了,但这会使扩展到更大的词汇量变得更加困难。对此有几种解决方案,文献中提到的一种是使用分层softmax分类器。不必一次性将某个词归类到10,000个词中。想象一下,如果您有一个分类器,它会告诉目标词是否在词汇表的前5,000个词中?还是在词汇表的后5,000个词中?假设这个分类器告诉您这是在词汇表的前5,000个词中,那么第二个分类器会告诉您这是在词汇表的前2,500个词中,还是在词汇表的后2,500个词中,依此类推。直到最终您开始对它进行分类,这样这棵树的叶子,以及像这样的分类器树,树的每个检索器节点都只是一个绑定分类器。您无需对全部10,000个单词求和,否则它将无法进行单一分类。事实上,像这样的计算分类树的扩展方式与词汇量成对数关系,而不是与词汇量成线性关系。这被称为分层softmax分类器。在实践中,分层softmax分类器不使用完全平衡的树或完全对称的树,每个分支的左侧和右侧的单词数量相等。在实践中,可以开发分层软件分类器,以便将常用词放在顶部,而将不太常见的词埋在树中更深的地方。可能只需要几次遍历就可以找到像the和of这样的常用词。很少看到像durian这样的不太常见的词,可以将它们埋在树的深处。有各种启发式方法可用于构建树,就像构建分层软件尖塔一样。加速softmax分类。对于加速softmax分类器和需要对分母中的整个上限大小求和的问题也非常有效。
GloVe
GloVe算法是由Jeffrey Pennington、Richard Socher和Chris Manning创建的。GloVe用于词表示的全局向量。通过选择文本语料库中彼此接近的两个单词来采样单词对、上下文单词和目标单词。首先假设 10个单词范围内来定义对称关系。虽然,如果你选择的上下文是目标词之前的单词,那么GloVe算法来说,可以将上下文和目标词定义为这两个单词是否出现在彼此的近距离内,比如说彼此的10个单词范围内。GloVe模型优化了以下内容。最小化0的对数是未定义的,是负无穷大。因此,我们要做的就是对this、is、of、a等等。但实际上,在常用词和不常用词之间存在一个连续体。还有一些不常用词,如durian,实际上仍然要考虑这些词,但它们的出现频率不如常用词高。因此,加权因子可以是一个函数,它为不常用词(如durian)提供有意义的计算量,并为诸如this、is、of、a之类的词提供更多权重,但不会过大,因为这些词在语言中似乎已经消失了。因此,有各种启发式方法来选择这个加权函数GloVe论文。最后,这个算法的一个有趣之处在于,GloVe算法。我认为这个算法的一个令人困惑的部分是,如果你看一下这个等式,它似乎太简单了。怎么可能仅仅通过最小化平方成本函数就可以学习有意义的词向量呢?但事实证明这是可行的。发明者最终得到这个算法的方式是,他们建立在更复杂的算法的历史之上,比如较新的语言模型,后来出现了Word2Vec skip-gram模型,然后是这个。希望简化所有早期的算法。在结束对词向量算法的讨论之前,我们应该简要讨论一下它们的另一个属性。也许嵌入向量的第一个组件表示性别,第二个组件表示皇室的等级,然后是年龄,然后是它是否是食物,等等。”但是,当您使用我们所见过的算法之一(例如GloVe算法)学习词嵌入时,会发生什么,您无法保证嵌入的各个组件是可解释的。为什么会这样?假设在某个空间中,第一个轴是性别,第二个轴是皇室。您可以做的是保证嵌入向量的第一个轴与这个意义轴(性别、皇室、年龄和食物)对齐。特别是,学习算法可能会选择这个作为第一维的轴。因此,给定一个单词上下文,那么第一个维度可能是这个轴,第二个维度可能是这个。甚至可能不正交,也许它会是第二个非正交轴,可能是实际学习的词向量的第二个组成部分。当我们看到这一点时,如果你对线性代数有理解,如果存在某个可逆矩阵
词嵌入应用
情感分类
情感分类是一项任务,即查看一段文本并判断某人是喜欢还是不喜欢他们正在谈论的内容。它是NLP中最重要的构建块之一,并用于许多应用程序。情感分类的挑战之一是没有大量的标签训练集。但是使用词嵌入,即使只有中等大小的标签训练集,您也可以构建良好的情感分类器。这是一个情感分类问题的示例。输入X、Facebook、Instagram 或其他形式的社交媒体上发布有关餐厅的消息。如果有一个情感分类器,它们可以只看一段文本,就能判断出发帖人对餐厅的情绪是积极还是消极。还可以跟踪是否存在任何问题,或者餐厅随着时间的推移是变好还是变坏。情感分类的挑战之一是没有庞大的标签数据集。对于情感分类任务,包含10,000到100,000个单词的训练集并不罕见。有时,甚至小于10,000个单词,可以使用的词嵌入帮助您更好地理解,尤其是当您有一个小型训练集时。这就是可以做的事情。
您可以取一个句子,例如“dessert is Excellent”,然后在字典中查找这些单词。我们像往常一样使用10,000词的字典。让我们构建一个分类器,将其映射到输出1-hot向量1-hot向量乘以嵌入矩阵“the”的嵌入向量,然后对“dessert”执行相同的操作,对“is”执行相同的操作,对“excellent”执行相同的操作。如果这是在一个非常大的数据集上训练的,比如一千亿个单词,那么你可以从不常用的单词中获取大量知识,并将它们应用到你的问题中,即使这些单词不在你的标记训练集中。现在这里有一种构建分类器的方法,你可以取这些向量,假设它们是300维向量,然后你可以对它们求和或求平均值。我在这里放一个更大的平均值运算符,你可以使用求和或平均值。这会给你一个300维的特征向量,然后你将其传递给soft-max分类器,然后输出softmax可以输出从一星到五星的五种可能结果的概率。这将是预测100个字,您也可以对所有100个字的所有特征向量求和或平均,这样您就可以得到一个表示,一个300维的特征表示,然后您可以将其传递到情感分类器中。因此,这个平均值会相当好用。它所做的是真正平均所有单词的含义或对示例中所有单词的含义求和。此算法的问题之一是它忽略了词序。特别是,这是一条非常负面的评论,“完全缺乏良好的品味、良好的服务和良好的氛围”。但“好”这个词出现了很多次。如果你使用这样的算法,忽略单词顺序,只对不同单词的所有嵌入进行求和或平均,那么最终的特征向量中就会有很多“好”的表示,你的分类器可能会认为这是一个好的评价,即使这实际上非常苛刻。这是一个一星评价。所以这里有一个更复杂的模型,它不是简单地对所有单词嵌入进行求和,您可以改用RNN进行情感分类。您可以查看该评论“完全缺乏良好的品味、良好的服务和良好的氛围”,然后为每个评论找到一个1-hot向量。所以我将跳过1-hot向量表示,而是取1-hot向量,像往常一样将其乘以嵌入矩阵RNN。RNN的工作是计算最后一个时间步的表示,以便预测10亿或1000亿个语料库中,它仍然能正确做到这一点,甚至可以更好地推广到用于训练词向量的训练集中的单词,但不一定在标签训练集中。
词嵌入去重
人们越来越信任机器学习和人工智能算法,它们可以帮助做出极其重要的决定。我们希望尽可能确保它们没有不良形式的偏见,例如性别偏见、种族偏见等。偏见指性别、种族、性取向偏见。词向量可以反映用于训练模型的文本的性别、种族、年龄、性取向和其他偏见。我特别感兴趣的是与社会经济地位有关的偏见。我认为每个人,无论你来自富裕家庭、低收入家庭还是介于两者之间的任何家庭,我都认为每个人都应该拥有巨大的机会。因为机器学习算法被用于做出非常重要的决策。它们影响着一切,从大学录取,到人们找工作的方式,到贷款申请是否被批准,到刑事司法系统量刑指南。学习算法正在做出非常重要的决定,所以我认为我们要尝试改变学习算法,尽可能减少或者消除这些不良偏见。现在就词嵌入而言,它们可以拾取用于训练模型的文本偏见。我认为也许对人工智能来说幸运的是有更好的想法来快速减少人工智能中的偏见,而不是快速减少人类中的偏见。虽然我认为我们在人工智能方面的研究还远远没有结束,我们还需要进行大量的研究和艰苦的工作来减少学习算法中的偏见。假设我们已经学习了一个词嵌入,所以单词babysitter,doctor在这里。我们有grandparents和grandgrafts。单词girl,boy,she,he嵌入在那里。所以我们要做的第一件事就是确定我们想要减少或消除的特定偏见所对应的方向。这里将重点介绍性别偏见,在这个例子中,你如何确定偏见相对应的方向?对于性别的情况,我们可以做的是取“he”的嵌入向量,减去“she”的嵌入向量,因为这因性别而异。取1维子空间,而非偏见方向,将是299维子空间。偏差方向可以高于1维,而且它不是取平均值,而是使用一种更复杂的算法找到的,称为奇异值分解(SVU)。如果你熟悉pr,它与主成分分析算法类似的思想。下一步是中和步骤。因此,对于每个非定义性的单词,将其投影以消除偏见。有些单词本质上捕捉了性别。像祖母、祖父、女孩、男孩、她、他这样的词,性别在定义中是固有的。而像医生和保姆这样的词,它们是性别中立的。一般的情况下,希望医生或保姆这样的词是种族中立或性取向中立的,但对于每个非定义性的单词,这基本上意味着不像祖母和祖父这样的词,它们确实具有性别成分,根据定义,祖母是女性,而祖父是男性。对于像医生和保姆这样的词,只需将它们投影到这个轴上,在偏见方向上减少它们的成分,或消除它们的成分。在水平方向上减少它们的分量。最后一步称为均衡,例如祖母和祖父,或女孩和男孩,它们嵌入中的唯一差异是性别。在这个例子中,保姆和祖母之间的距离或相似度实际上小于保姆和祖父之间的距离。因此,这可能强化了一种不健康的或可能不受欢迎的偏见,即祖母最终比祖父更愿意照顾孩子。因此,在最后的均衡步骤中,我们希望确保像祖母和祖父这样的词与性别中立的词(例如保姆或医生)具有完全相同的相似度或完全相同的距离。因此,有几个线性代数步骤可以实现这一点。但它基本上会将祖母和祖父移动到与中间轴等距的一对点上。这样做的效果是,babysitter与这两个词之间的距离将完全相同。所以,比如祖母-祖父、男孩-女孩、姐妹会-兄弟会、女孩-男孩、姐妹-兄弟、侄女-侄子、女儿-儿子,希望通过这个均衡步骤来实现。你如何决定要中和哪个词?例如,单词doctor似乎是一个应该中和的词,以使其不具有性别或种族特征。而单词grandsitter和grandparents不应该具有性别特征。还有像beard这样的词,这只是一个统计,男性比女性更有可能有胡须,所以也许beards应该更接近male而不是female。因此,找出哪些词是定义性的,哪些词应该是性别特定的,哪些词不应该是。英语中的大多数词都不是定义性的,意味着性别不是定义的一部分。而且,像这样的词子集相对较小,例如祖母-祖父、女孩-男孩、姐妹会-兄弟会等,不应该被中和。线性分类器可以告诉您哪些词需要通过中和步骤来投射出这种偏差方向,将其投射到299维的子空间上。