梯度下降 我们看到了成本函数 、 梯度下降 的算法可实现这一点。梯度下降 在机器学习中随处可见,不仅用于线性回归 ,还用于训练一些最先进的神经网络模型,也称为深度学习模型 。
梯度下降 奠定机器学习中最重要的基石之一。这里有最小化的线性回归 的成本函数 ,事实证明,梯度下降 是一种可用于尝试最小化任何函数的算法,而不仅仅是线性回归 的成本函数 。梯度下降 适用于更一般的函数,包括两个以上参数的模型的成本函数 。例如,如果你有一个成本函数 梯度下降 是一种可用于尝试最小化成本函数线性回归 中,初始值是什么并不重要,因此常见的选择是将它们都设置为0。例如,您可以将0,将0作为初始猜测。使用梯度下降算法 ,您要做的就是,每次都稍微改变参数
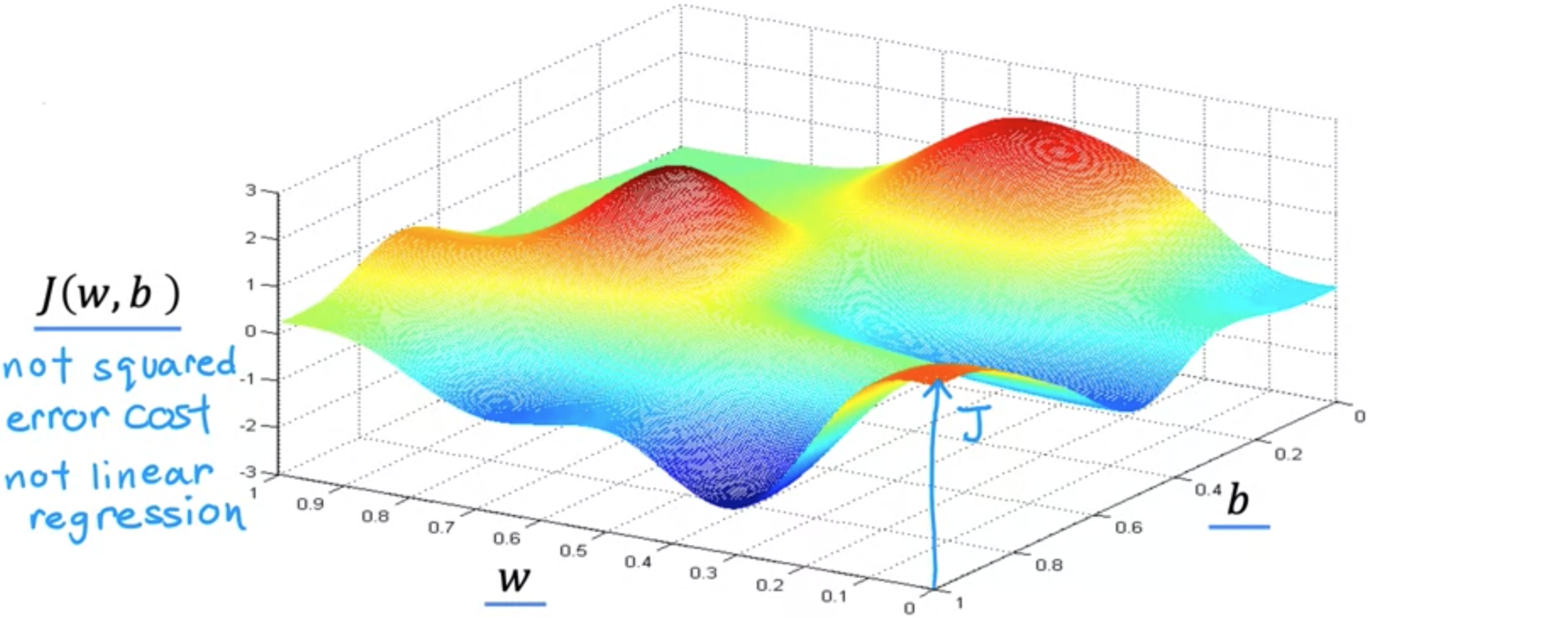
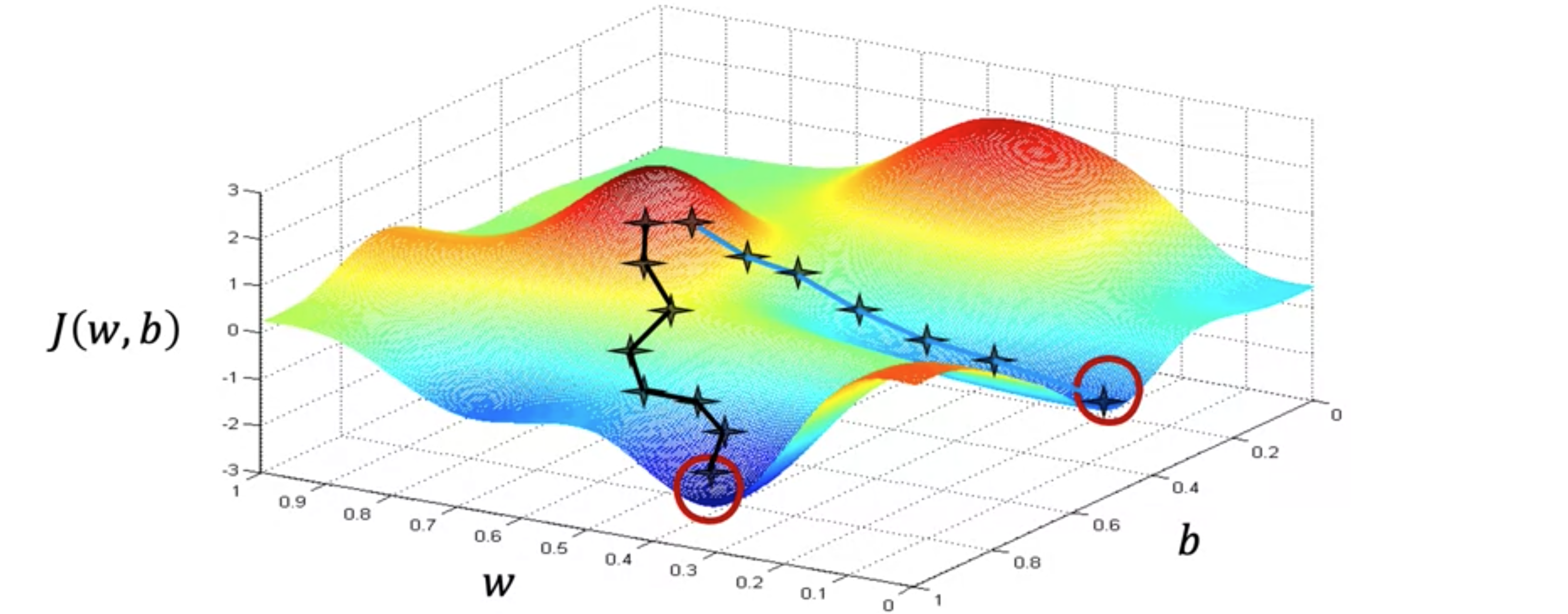
此函数不是平方误差成本函数 。对于具有平方误差成本函数的线性回归 ,您总是会得到弓形或吊床形。但如果您训练神经网络模型,您可能会得到这种类型的成本函数。注意轴,即底部轴上的 成本函数 的值。现在,让我们想象一下,这个曲面图实际上是一个略微丘陵的户外公园,其中高点是山丘,低点是山谷,就像这样。想象一下,你现在正站在山上的这个点上。如果这能帮助你放松,想象一下有很多非常漂亮的绿草、蝴蝶和鲜花,这是一座非常漂亮的山。你的目标是从这里出发,尽可能高效地到达其中一个山谷的底部。梯度下降算法 的作用是,你要旋转360度,环顾四周,问自己,如果我要朝一个方向迈出一小步,我想尽快下坡到其中一个山谷。我会选择朝哪个方向迈出这一小步?如果你想尽可能高效地走下这座山,那么如果你站在山上的这个点上环顾四周,你会发现,你下一步下山的最佳方向大致就是那个方向。从数学上讲,这是下降速度最快的方向。意味着,当你迈出一小步时,这会比你朝其他方向迈出一小步的速度更快。迈出第一步后,你现在就站在山上的这个点上。现在让我们重复这个过程。站在这个新的点上,你将再次旋转360度,问自己,下一步我要朝哪个方向迈出一小步才能下山?如果你这样做,再迈出一步,你最终会朝那个方向移动一点,然后你就可以继续走下去了。从这个新的点开始,你可以再次环顾四周,决定哪个方向可以让你最快地下山。再走一步,再走一步,等等,直到你发现自己到了山谷的底部,到了这个局部最小值,就在这里。你刚才做的是经过多步梯度下降 。梯度下降 有一个有趣的特性。你可以通过选择参数梯度下降 时,你是从这里的这个点开始的。现在,想象一下,如果你再次尝试梯度下降,但这次你选择一个不同的起点,通过选择将你的起点放在这里右边几步的参数。如果你重复梯度下降过程,这意味着你环顾四周,朝着最陡峭的上升方向迈出一小步,你就会到达这里。然后你再次环顾四周,再迈出一步,依此类推。如果你第二次运行梯度下降 ,从我们第一次执行的位置的右边几步开始,那么你最终会到达一个完全不同的山谷。右边这个不同的最小值。第一个和第二个山谷的底部都称为局部最小值 。因为如果你开始沿着第一个山谷向下走,梯度下降不会带你到第二个山谷,同样,如果你开始沿着第二个山谷向下走,你会停留在第二个最小值,而不会找到进入第一个局部最小值的路。
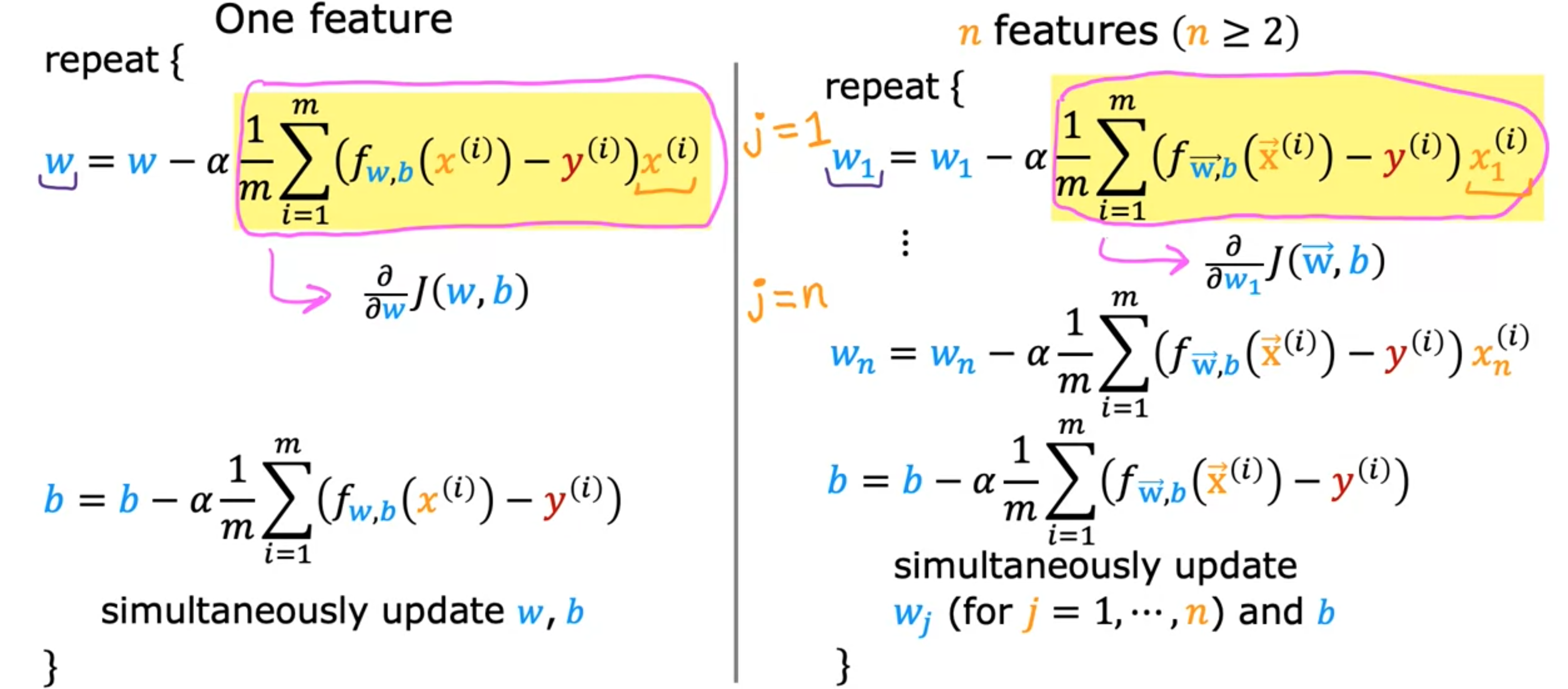
让我们看看如何实现梯度下降算法 。在每一步中,参数
具体来说,在这个上下文中,如果你写的代码是Python和其他编程语言中,真值断言有时写成等于,所以如果你在测试学习率 。学习率 通常是0~1之间的一个正数,比如0.01。梯度下降 过程。如果成本函数 梯度下降算法 ,你将重复这两个更新步骤,直到算法收敛。所谓收敛 ,意思是你到达局部最小值,此时参数语义梯度下降 ,还有一个更微妙的细节,你将更新两个参数 梯度下降 ,你想同时更新梯度下降 的正确方法,它会同时进行更新。当你听到有人谈论梯度下降 时,是指执行参数同步更新的梯度下降 。
这个希腊符号学习率 。学习率 控制更新模型参数成本函数 梯度下降 现在看起来像这样,斜率 。例如,这个斜率可能是2/1,当切线指向右上方时,斜率为正,这意味着这个导数是一个正数,所以大于0。更新后的学习率 始终是正数。如果用-2,宽度是1,斜率就是-2/1,也就是-2,这是一个负数。当你更新梯度下降算法 中的另一个关键量是学习率
学习率 学习率 梯度下降 的效率产生巨大影响。0.0000001。所以你最终会迈出一小步。然后从这一点开始,你将迈出另一个微小的婴儿步。但由于学习率非常小,第二步也微不足道。这个过程的结果是,你最终会降低成本梯度下降 会起作用,但速度会很慢。这将需要很长时间,因为它需要采取这些微小的婴儿步。而且它需要很多步才能接近最小值。如果学习率太大会发生什么?这是成本函数的另一张图。假设我们从这里的发散 。假设有成本函数5。这是5。一次迭代后,它仍然等于5。因此,如果你的参数已经将你带到了局部最小值,然后进一步的梯度下降会趋于零。它不会改变参数,这正是你想要的,因为它将解决方案保持在局部最小值。这也解释了为什么梯度下降可以达到局部最小值,即使学习率梯度下降 将自动采取较小的步长。这是因为当我们接近局部最小值时,导数 会自动变小。这意味着更新步骤也会自动变小。学习率梯度下降算法 ,你可以用它来尝试最小化任何成本函数均方误差成本函数 。
线性回归的梯度下降 如下图所示,这是线性回归模型 。右边是平方误差成本函数 。下面是梯度下降算法 。如果您计算这些导数,您将得到这些项。关于误差项 ,即预测值与实际值之间的差乘以输入特征梯度下降 ,它就会起作用。现在,你可能想知道,我从哪里得到这些公式?它们是使用微积分 推导出来的。如何计算导数项 。让我们从第一项开始。成本函数
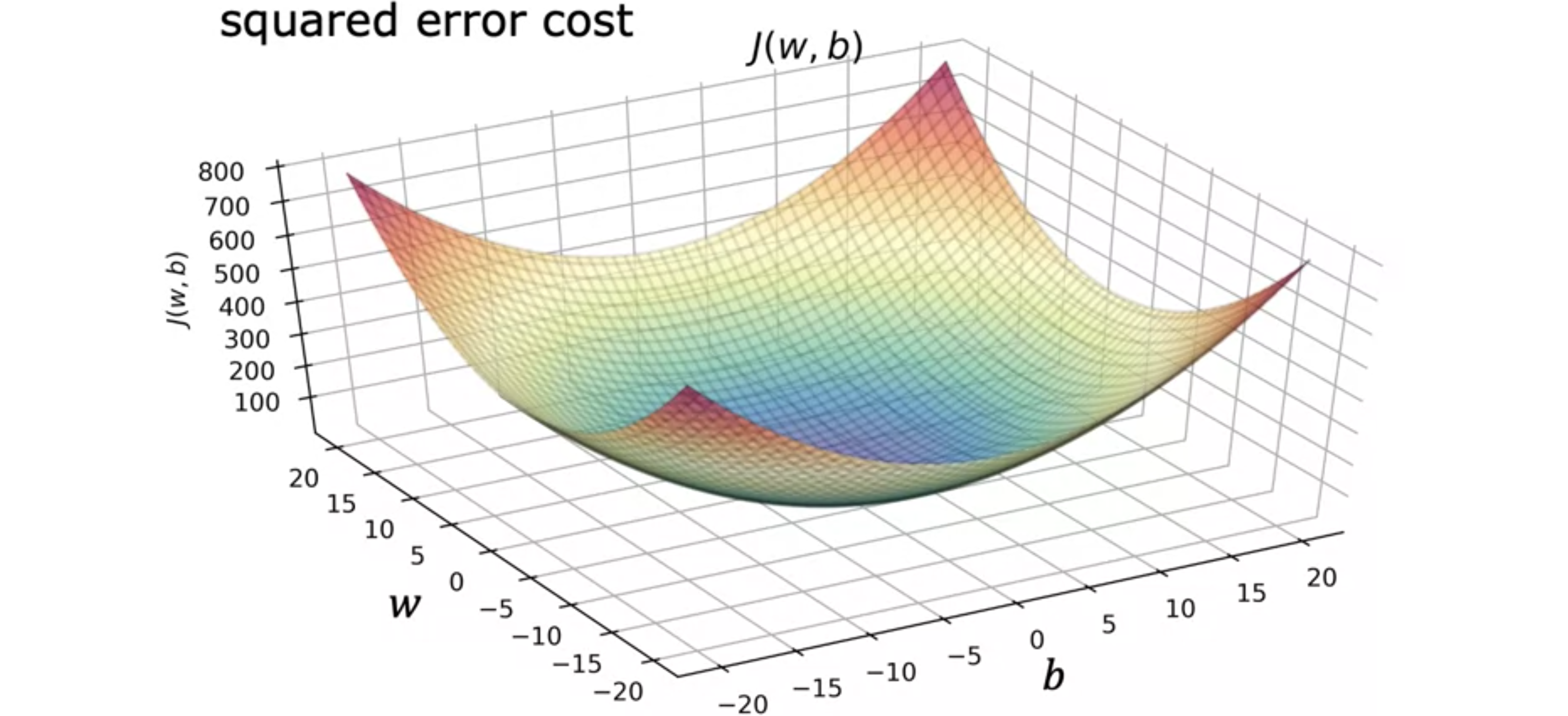
根据您初始化参数线性回归 中使用平方误差成本函数 时,成本函数永远不会有多个局部最小值。它只有一个全局最小值 。这个成本函数是一个凸函数。通俗地说,凸函数 是碗状函数,除了单个全局最小值外,它不能有任何局部最小值。当你在凸函数 上实现梯度下降 时,只要你选择适当的学习率 ,它就会一直收敛到全局最小值 。
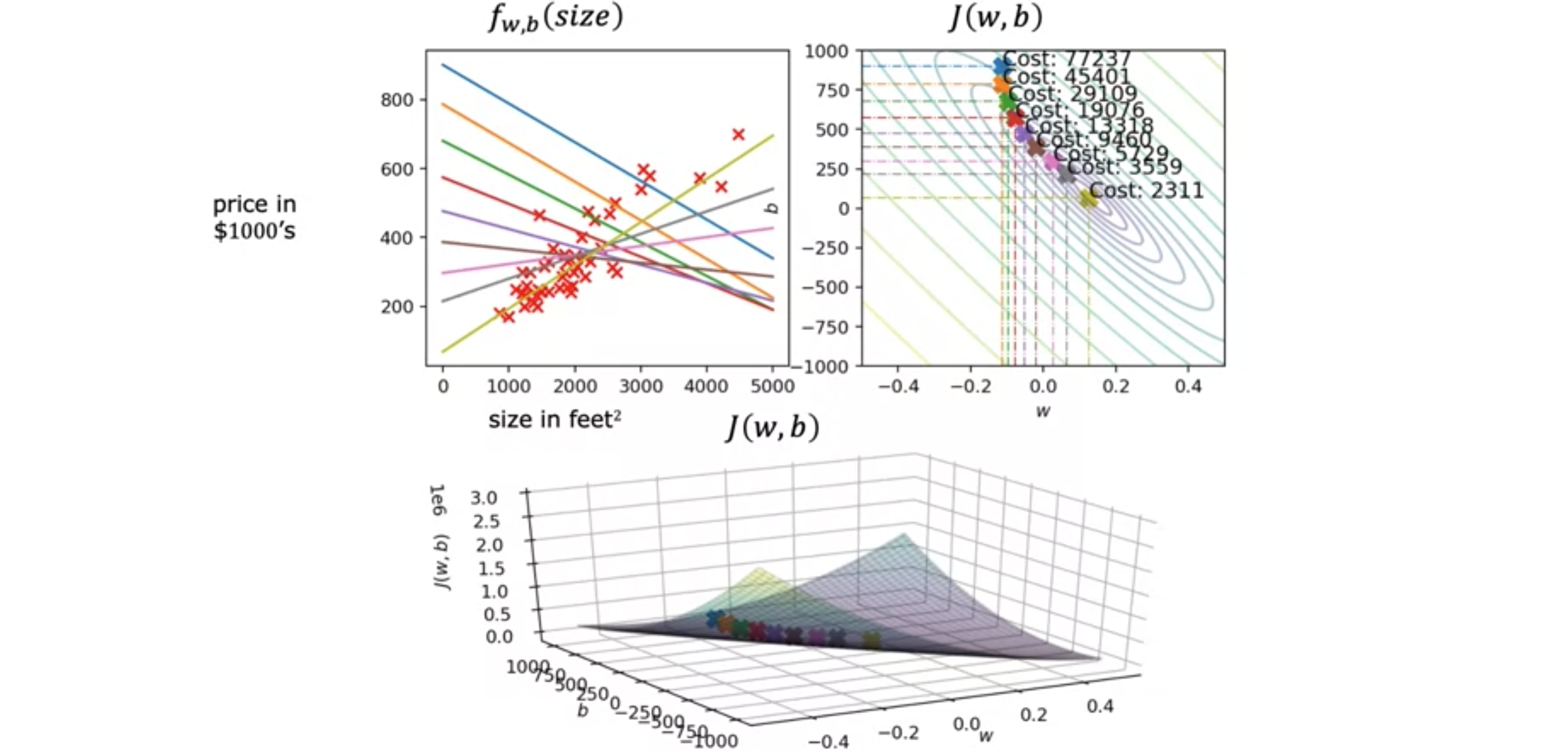
让我们看看在线性回归 中运行梯度下降 时会发生什么?如下图所示,左上角是模型和数据的图,右上角是成本函数 的轮廓图,底部是同一成本函数的表面图。通常0,但为了演示,我们初始化梯度下降 迈出一步,最终会从成本函数的这一点向右下方移动到下一点,注意到直线拟合也发生了一点变化。成本函数 现在已移至第三个点,并且函数梯度下降 ,我们将用它来拟合模型以适配数据。
多元线性回归 如果您不仅有房屋的大小作为预测价格的特征,而且您还知道卧室数量、楼层数量和房屋的年限,会怎么样呢?这似乎会为您提供更多信息来预测价格。为了引入一些新的符号,我们将使用变量1~4。使用小写2。有时为了强调80,000美元开始,假设房屋没有大小、没有卧室、没有楼层和没有年龄。你可以把这个0.1想象成,每增加一平方英尺,价格就会增加0.1美元,因为我们说的是每平方英尺的价格增加0.1乘以1,000美元,也就是100美元。也许每增加一个浴室,价格就会增加4,000美元,每增加一层楼,价格可能会增加10,000美元,而房子的年龄每增加一年,价格可能会下降2,000美元,因为参数是-2。一般来说,如果你有向量 。接下来,点积 是什么?两个数字列表点积 是通过检查相应的数字对 来计算的,输入特征 的线性回归模型 的名称为多元线性回归 。这与只有一个特征的单变量回归形成对比。把这个模型称为多元线性回归 。就是具有多个特征的线性回归 。为了实现这一点,有一个非常巧妙的技巧叫做矢量化 。
您将看到一个非常有用的概念,即矢量化 。使用矢量化 既可以使代码更短,也可以使其运行得更高效。学习如何编写矢量化代码将使您能够利用现代数值线性代数库,甚至是代表图形处理单元的GPU硬件。这种硬件的设计是为了加速计算机中的计算机图形处理,当您编写矢量化代码时,它也可以用于帮助您更快地执行代码。让我们看一个具体的例子来说明矢量化的含义。这是一个带有参数1开始,因此第一个值是下标Python代码中,您可以使用这样的数组定义这些变量、 Python中一个名为NumPy的数值线性代数库。因为在Python中,数组的索引计数时从0开始,所以你可以使用Python在内的许多编程语言都从0开始计数,而不是从1开始。让我们看一个没有矢量化的实现,用于计算模型的预测。你取每个参数3而是矢量化 ,而是使用for循环。在数学中,您可以使用求和运算符0开始初始化。您可以将for循环之外,添加b。让我们看看如何使用矢量化来实现这一点。这是函数Python代码实现为:f = np.dot(w,x) + b。这个NumPy点积函数是两个向量之间点积运算的矢量化实现,尤其是当n很大时,它的运行速度会比前面两个代码示例快得多。矢量化有两个明显的好处。首先,它使代码更短。其次,它还使你的代码运行速度比之前两个没有使用矢量化 的实现快得多。矢量化 实现速度更快的原因在于。NumPy点积函数能够使用计算机并行计算,无论你是在普通计算机(即普通计算机CPU)上运行它,还是在使用GPU(图形处理器单元)上运行都是如此。NumPy点积函数利用并行计算的能力使其比for循环或顺序计算效率高得多。
同样的算法,矢量化 后运行速度会快得多。让我们深入了解一下矢量化 是如何在计算机上工作的。看看这个for循环。像这样的for循环在没有矢量化的情况下运行。如果0处的值进行操作。在下一个时间步,它计算与索引1相对应的值,依此类推,直到第15步。相比之下,NumPy中的这个函数是在计算机硬件中使用矢量化 实现的。计算机可以获取向量16个数值使用专门的硬件非常高效地加在一起,而不是需要逐个执行不同的加法来将这16个数值相加。意味着具有矢量化的代码比没有矢量化的代码更少的时间内执行计算。当您在大数据集上运行算法或尝试训练大模型时,这一点尤为重要,而机器学习通常就是这种情况。这就是为什么能够矢量化学习算法,是让学习算法高效运行的关键步骤,因此可以很好地扩展到许多现代机器学习算法的大数据集上。现在,让我们看一个具体的例子,看看它如何帮助实现多元线性回归 以及具有多个输入特征的线性回归。假设除了参数16个特征和16个参数(16个权重计算16个导数项,你将np.arrays中,矢量化 ,则可以对(0,16)范围内使用for循环。相反,如果进行因式分解,则可以将计算机的并行处理硬件想象成这样。它获取向量16个值并行减去向量16个值的16个计算同时且一次性地分配回NumPy数组16个计算。使用矢量化实现,您可以获得更高效的线性回归 实现。如果有16个特征,速度差异可能并不大,但如果您有数千个特征,并且训练集可能非常大,这种矢量化 实现将对学习算法的运行时间产生巨大影响。
梯度下降应用于线性回归 我们有参数点积 。请记住,这里的点积表示.product。成本函数 可以定义为梯度下降 在多个特征下会变得略有不同。这是我们使用一个特征进行梯度下降时得到的结果。我们有一条针对2或更大。我们得到了梯度下降的更新规则:多元回归 的梯度下降 。
特征缩放 特征缩放 的技术将使梯度下降 运行得更快。让我们首先看一下特征的大小与其相关参数的大小之间的关系。作为一个具体的例子,让我们使用两个特征300~2000平方英尺之间。数据集中的0~5个卧室。对于这个例子,2000平方英尺的房子有五个卧室,价格为500k或500,000美元。对于这个训练示例,您认为参数1亿美元。因此,这显然与500,000美元的实际价格相差甚远。因此,对于50比0.1大得多。所以这里预测的价格是200k,第二项变成250k,再加上50。所以这个版本的模型预测价格为500,000美元,这是一个更合理的估计,恰好与房屋的真实价格相同。所以您可能会注意到,当特征的值范围很大时,例如面积和平方英尺,一直到2000。一个好的模型更有可能学会选择一个相对较小的参数值,例如0.1。同样,当特征的可能值很小时,例如卧室数量,其参数的合理值将相对较大,例如50。那么这与分级下降 有何关系?
让我们看一下特征的散点图,其中面积平方英尺是横轴成本函数 在等高线图中的样子。您可能会看到等高线图中横轴的范围要窄得多,比如在0~1之间,而纵轴的值要大得多,比如在10~100之间。因此,等高线形成椭圆形,它们一边短,另一边长。这是因为对成本函数 。那么这给我们带来了什么?如果您在dissent中运行良好,并且按原样使用训练数据,最终可能会发生这种情况。由于轮廓线太高,梯度下降 可能会反复来回很长时间,然后才能最终找到全局最小值 。在这种情况下,一个有用的方法是缩放特征 。意味着对训练数据进行一些变换,这样0~1,0~1。所以数据点现在看起来更像这样,你可能会注意到底部图的比例现在与顶部图的比例完全不同。关键在于,重新缩放成本函数 上运行梯度下降法 ,找到此结果,使用转换后的数据重新缩放梯度下降法 可以找到一条更直接的路径,到达全局最小值 。总结一下,当您拥有不同的特征,它们取的值范围非常不同时,梯度下降法 运行缓慢,但重新缩放不同的特征,使它们都取可比较的值范围。
让我们看看如何实现特征缩放 ,将取值范围相差很大的特征转换为具有可比值范围的特征。如何缩放特征?如果3~2,000,则获取0.15~1。同样,由于0~5,您可以通过取每个原始0~1。如果您将均值归一化 。具体做法是,先从原始特征开始,然后重新调整它们的比例,使它们都以零为中心。之前,它们只有大于零的值,而现在它们同时具有负值和正值,这些值通常介于-1和1之间。要计算平均归一化 ,首先找到平均值,也称为训练集上600平方英尺。2,000是最大值,300是最小值,如果这样做,您将得到归一化的-0.18~0.82。类似地,要计算归一化x_2的平均值,您可以计算特征-0.46~0.54。如果您使用平均归一化Z分值归一化 。要实现Z分值归一化,您需要计算每个特征的标准差 。如果您听说过正态分布 或钟形曲线 (有时也称为高斯分布 ),这就是正态分布的标准差。那么为了实现Z分值标准化 ,你首先要计算平均值450,平均值是600,那么为了对Z分值标准化 ,取Z分值标准化 的-0.67~3.1。类似地,如果您计算出第二个特征的标准差为1.4,平均值为2.3,那么您可以计算Z分值可能在-1.6~1.9之间。如果您在图表上绘制归一化特征缩放 时,您可能希望使特征的范围从(-1, 1)。如果特征范围从(-3,-3)或(-0.3, 0.3)。如果您有一个特征0~3之间,那不是问题。您可以根据需要重新缩放它,但如果您不重新缩放它,它应该正常工作。或者,如果你有一个不同的特征-2~0.5之间,那么重新缩放它也没有问题,但如果你不改变它,也没问题。但是,如果另一个特征(比如这里的-100~100,那么它的范围就会大不相同,比如说从-1~1。你最好重新缩放这个特征-1~1。同样,如果你有一个特征-0.001~0.001之间,那么这些值就太小了。这意味着你可能重新缩放它。最后,如果你的特征98.6~105华氏度,该怎么办?在这种情况下,这些值约为100,与其他尺度特征相比,这实际上相当大,这实际上会导致梯度下降 运行得更慢。在这种情况下,特征重新缩放可能会有所帮助。执行特征重新缩放几乎没有任何坏处。这就是特征缩放的全部内容。使用这个小技巧,通常可以让梯度下降运行得更快。这就是特征缩放 。无论有没有特征缩放 ,当您运行梯度下降 时,如何检查梯度下降 是否真的有效?
梯度下降的收敛性 运行梯度下降 时,如何判断它是否正在收敛 ?也就是说,它是否能帮助你找到接近成本函数全局最小值的参数。关键是学习率 最小化成本函数 学习曲线 。机器学习中使用了几种不同类型的学习曲线,具体来说,如果您查看曲线上的这一点,意味着在您运行梯度下降100次迭代后,即同时更新100次参数后,您会学到一些200次梯度下降迭代后得到的参数的300次迭代时,成本400次迭代时,曲线似乎已经变平。这意味着梯度下降 或多或少已经收敛 ,因为曲线不再下降。梯度下降转换所需的迭代次数在不同的应用程序之间可能有很大差异。在一个应用程序中,它可能仅在30次迭代后就收敛。在其它的应用中,可能需要1,000或100,000次迭代。事实证明,很难提前知道梯度下降 需要多少次迭代才能收敛,这就是为什么你可以创建这样的一个图表,即学习曲线 。
另一种确定你的模型何时完成训练的方法是使用自动收敛测试 。这是希腊字母学习曲线图表 ,而不是依赖自动收敛测试 。
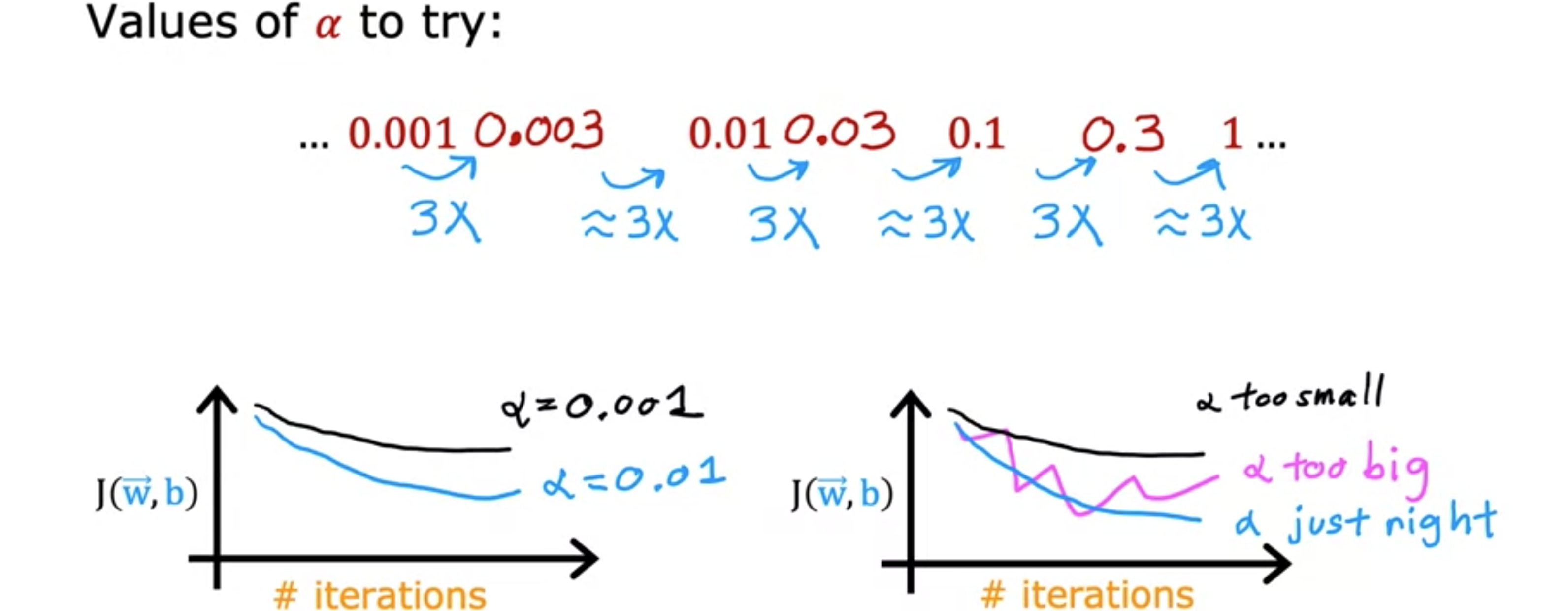
选择学习率 选择合适的学习率 ,学习算法会运行得更好。如果学习率 太小,它会运行得非常慢,如果学习率 太大,它甚至可能无法收敛。让我们来看看如何为你的模型选择一个好的学习率 。具体来说,如果你绘制了多次迭代的成本图,并注意到成本有时上升,有时下降,你应该把它看作是梯度下降 不正常工作的明显迹象。这可能意味着代码中有一个错误。或者有时它可能意味着你的学习率太大。所以这里有一种可能发生的情况。这里的纵轴是成本函数全局最小值。 有时你会看到成本在每次迭代后持续增加,就像这里的曲线一样。这也是由于学习率太大,可以通过选择较小的学习率来解决。但像这样的学习率也可能是代码损坏的标志。例如,如果编写的代码是将全局最小值 而不是更接近。所以请记住,你想使用减号,所以代码应该将成本函数 应该在每次迭代中下降。因此,如果梯度下降 不起作用,我经常会做的一件事是将
一个重要的权衡是,如果你的学习率太小,那么梯度下降可能需要很多次迭代才能收敛。所以当运行梯度下降 时,通常会尝试一组学习率10倍的学习率,比如0.01和 0.1等等。对于每个学习率 ,但也会保持一致。尝试0.001后,我会将学习率提高三倍至0.003。之后,我会尝试0.01,这又是0.003的三倍。所以这些都是尝试,每个
特征工程 特征的选择会对学习算法的性能产生巨大影响。事实上,对于许多实际应用来说,选择或输入正确的特征是算法正常工作的关键。让我们看看如何为学习算法选择最合适的特征 。假设每栋房子有两个特征。特征工程 的一个例子,在特征工程 中,你可以利用对问题的知识或直觉来设计新特征,通常是通过转换或组合问题的原始特征,以便让学习算法更容易做出准确的预测。根据你对应用程序的了解,有时通过定义新特征,而不仅仅是采用刚开始使用的特征,这样可能会得到一个更好的模型。这就是特征工程 。事实证明,这种特征工程 不仅可以让你拟合直线 ,还可以拟合曲线 和非线性函数 。
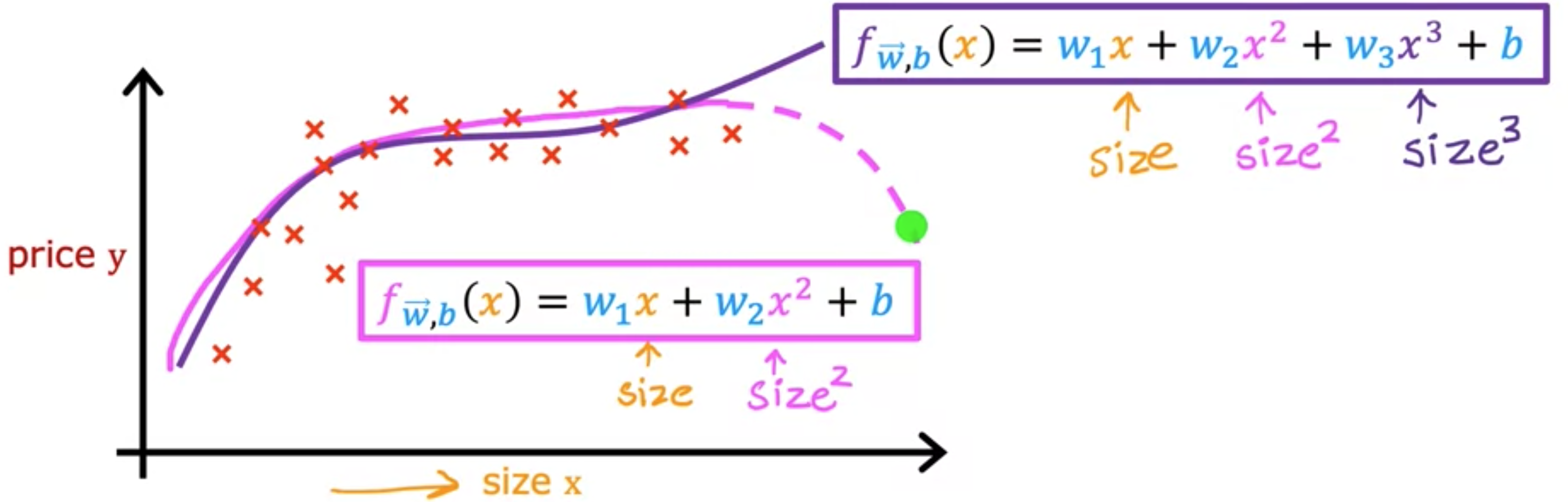
多项式回归 到目前为止,我们只是用直线拟合 数据。让我们利用多元线性回归 和特征工程 的思想,提出一种称为多项式回归 的新算法,该算法可让您将曲线(非线性函数)拟合到数据中。假设您有一个如下所示的房屋数据集,其中特征 2次方、3次方或任何其他次方。在三次函数的情况下,第一个特征是尺寸,第二个特征是尺寸的平方,第三个特征是尺寸的立方。如果你创建的特征是原始特征的平方幂,那么特征缩放 就变得越来越重要。如果房子的大小范围是1~1,000平方英尺,那么第二个特征(即尺寸的平方)的范围将从1~100万,第三个特征(即尺寸的立方)的范围将从1~10亿。这两个特征(梯度下降 ,应用特征缩放 使特征进入可比较的值范围非常重要。
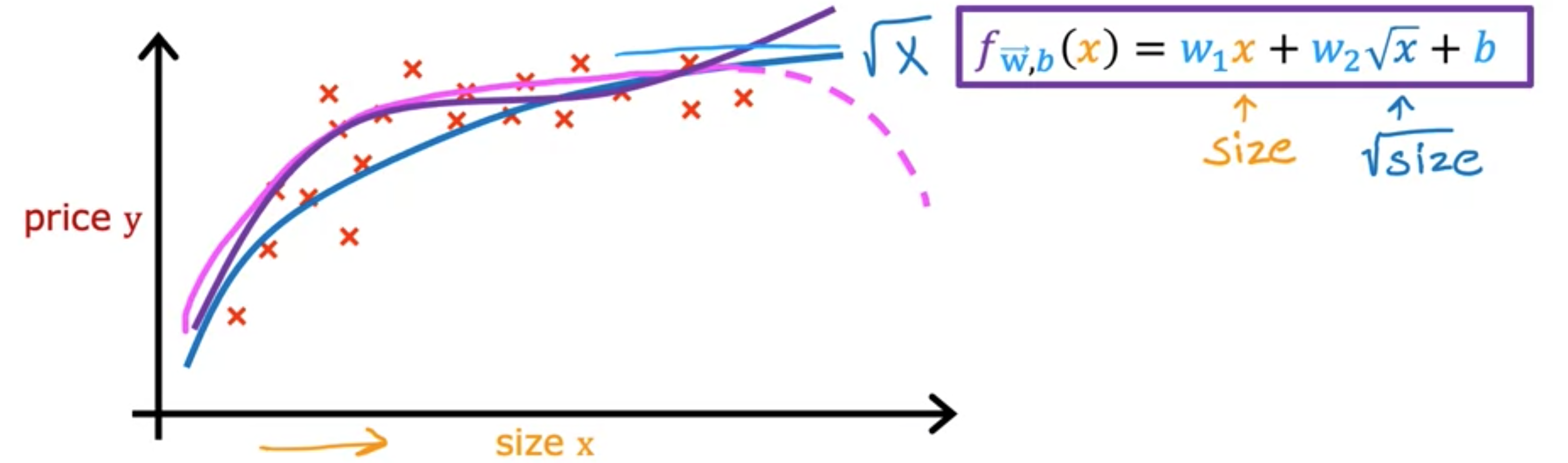
取尺寸平方和尺寸立方的另一种合理替代方法是使用