离散去噪扩散模型(DDMs) — 数据隐私探析(深度学习)
介绍
离散去噪扩散模型(Discrete Denoising Diffusion Models, DDMs)是一种用于生成合成数据的深度学习模型,近年来因其在隐私保护方面的潜力而受到关注。随着对数据隐私的日益重视,研究人员开始探索这些模型在生成合成数据时的隐私保护能力。在生成合成数据的过程中,传统的隐私保护方法往往无法有效应对数据泄露的风险。离散去噪扩散模型通过逐步引入噪声并在后续步骤中去噪,生成与原始数据分布相似的合成数据。尽管已有实证研究评估了这些模型的性能,但对其隐私保护能力的数学表征仍存在较大缺口。
离散去噪扩散模型在隐私保护方面的研究为合成数据生成提供了新的视角。通过理论分析和实证验证,研究者们不仅揭示了这些模型的隐私泄露机制,还为未来的隐私保护技术提供了理论基础。这一研究方向将有助于在数据生成和使用中更好地平衡隐私保护与数据实用性之间的关系。
模型
“On the Inherent Privacy Properties of Discrete Denoising Diffusion Models”,这篇论文主要介绍了,隐私问题导致合成数据集创建的激增,而扩散模型则成为一种很有前途的技术手段。尽管先前的研究已经对这些模型进行了实际的评估,但在提供其隐私保护能力的数学表征方面仍存在差距。为了解决这个问题,作者提出了用于离散数据集生成的离散去噪扩散模型(DDMs)固有的隐私属性的开创性理论探索。作者的框架专注于每个实例的差异隐私(pDP),阐明了给定训练数据集中每个数据点的潜在隐私泄露,并深入了解了每个点的隐私损失如何与数据集的分布相关联。结果表明,使用s-sized的数据点进行训练会导致(DDMs)从纯噪声阶段过渡到合成清洗数据阶段时从
具有分类属性的离散表格或图形数据集在许多隐私敏感领域中很普遍,包括金融、电商和医学。例如,医学研究人员经常以离散表格形式收集患者数据,例如种族、性别和就医状况。然而,在这些领域使用和共享数据存在泄露个人信息的风险。为了解决这类问题,有人提出生成具有隐私保护的合成数据集,作为保护敏感信息和降低隐私泄露风险的一种方式。
的原理")
在论文中,作者分析了固定训练数据集的DDM隐私保护。利用了数据相关的隐私框架,称为每个实例差异隐私(pDP),该框架是根据固定训练数据集中的实例定义的。pDP的分析允许对训练集中每个数据点的潜在隐私泄露进行细粒度的表征。这让数据管理员能够更好地了解训练数据的敏感性。作者的分析考虑了一个在s个样本上训练的DDM并生成m个样本,跟踪每个生成步骤中的隐私泄漏。实验证明,随着数据生成步骤从t = T(噪声状态)过渡到t = 0(无噪声状态),隐私泄漏从DDM中的主要隐私泄漏。此外,分析表明,当m = 1时,隐私边界DDM固有的弱隐私保护。此外,扩散系数衰减越快,隐私保护效果越好。对于数据部分,作者开发了一种算法,根据pDP边界估计真实数据集中每个数据点的隐私泄漏。通过从数据集中删除最敏感的数据点(根据数据相关隐私参数)来训练DDM,然后评估基于DDM生成的合成数据集训练的ML模型,从而评估数据部分。有趣的是,作者观察到,在删除部分数据后获得的ML模型甚至超过没有删除此类数据的其他模型。作者将其归因于这样一个事实,即删除的数据点可能是异常值,这可能实际上不利于ML模型学习。
为了避免混淆,作者提供了几个重要的解释。最坏情况并与数据集无关的DP(Wang,2019)相比,针对训练集量身定制的pDP为数据管理员提供了对每个数据点潜在隐私泄漏的更准确、更细粒度的估计。然而,重要的是要理解pDP。直接为数据添加噪声是不允许的,因为添加的噪声可能会因其数据依赖性而泄露隐私信息。可以使用其他方法,例如平滑灵敏度(Nissim等人,2007)和提议测试发布(Dwork & Lei,2009)。作者的分析旨在深入了解 DDM所提供的固有隐私,并指导数据管理员评估与数据集不同部分的隐私泄露风险。这里并非以开发一种匹配特定隐私评估的算法为目标。鉴于此目的,pDP是比DP更合适。在实践中,pDP评估应该保密,并由数据管理员了解数据集并使用 DDM生成合成数据集时的潜在隐私泄露。
首先介绍一下用于分析的符号和概念。假设n维的离散空间,每个维度有
基于实例的差分隐私:DP是量化隐私泄露的事实标准。作者针对特定的相邻数据集调整了DP定义,引入了基于实例的DP:让
需要强调的是,pDP是针对特定数据集-数据点对唯一的定义。
离散扩散模型(DDMs):是可以生成分类数据的扩散模型。让ELBO学习
具体来说,前向处理过程由一批转换核来描述
这个损失作为我们后边充分训练的一个基础,在训练的过程中,我需要桥接
其他符号,给定两个样本KL散度和总变化。让
主要结果
DDMs的固有隐私保护
首先,定义下面的分析机制。让DDM的生成过程在时间DDM最终生成的数据集。下面是一些假设的概述:
- 假设一:给定数据集
,让 表示时间 0处的预测随机变量,让表示在数据集 上训练的去噪神经网络( NNs)。如果存在小的常量使得 ,则假设一是成立的。 - 假设二(前向和反向扩散路径之间的间隙): 给定数据集
,让 表示前向和反向处理过程在时间 处的中间分布采样的随机变量。如果存在 的正常数,则假设二成立。
假设一指出,当使用第一个公式中的损失函数训练去噪网络时,它可以有效地从中间噪声数据分布中推断出干净的数据。给定一个好的模型,估计DP。基于上述假设,作者研究了隐私泄露沿产生过程的流动情况。作者的分析主要围绕在特定训练下的固有隐私保护由DDM生成的样本,表示为
- 定理一(
DDMs固有的pDP保护):给定数据集,大小为 和要保护的数据点 ,表示 ,正如 。假设在 和 上训练的去噪网络满足于假设一和假设二。给定一个具体的时间步 ,机制 相对于 ,给定 满足 :
其中
并且
定理一量化了训练集DDMs固有的pDP保护,突出了界限的数据依赖性,以及一个去噪网络训练和路径差异的误差项。这些数据相关量很复杂,无法对数据集-数据点对进行严格的测量。接下来,将进一步解释这些量。首先,由于生成过程形成马尔可夫链,其中转移概率
其中
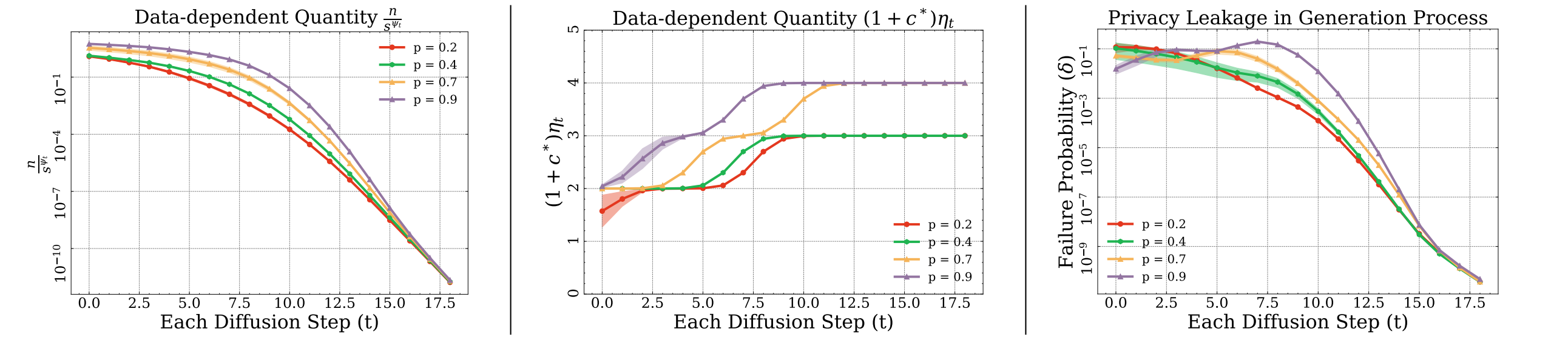
的数量:如下图所示, 量化了 ,其中最大值在被移除的点 。通过仔细检查发现 依赖于 和 。根据 的定义,让 和 的剩余点进行对齐。 的变化:在生成阶段, 从 减少到 , 从 增长到 。随着数据生成过程从噪声演变成无噪声状态,潜在的隐私泄露风险会升级。


和 :很明显,生成的中间度量 偏离了最敏感点( )的狄拉克测度。因此,以 为特征的实际隐私泄露对度量值 取均值远小于其最大值。为了提供此类的严格表征,引入两个量 和 来定义以脆弱点 为中心的局部区域 。其中,隐私泄露可以被限制在 与 和 与 之和的范围内。
DDM系数和数据集分布对隐私界限的影响
- 扩散系数的影响:隐私项在很大程度上受
和 之间邻近性的影响。随着时间 的推移,这种相似性由转换比率 决定,扩散系数趋于零的速度越快,该比率就越高,从而提高了隐私保护。 - 数据集分布的影响:作者发现
对隐私边界有很大影响。 受附加点 与 中其余点的相似性影响,如果 变小(大),相应项 变大(小),这表明 的保护较弱。 特别低的点可能是数据中的敏感点。
在简单分布下表征数据依赖量
作者考虑从某些特定分布中抽样的训练数据集,进一步说明数据相关的量化。考虑一个分布,其中每一列以概率
具有足够大的
在无噪声状态下R.H.S单调增加,导致
在给定数据集上评估以下公式中隐私界限的算法
在实际情况下,当数据策展人发布合成数据时,评估在特定数据集上训练隐私保护措施至关重要。确保合成数据隐私和训练数据敏感信息的私密性。为此,我们引入了算法1(与算法2配对),以计算隐私界限,从而能够针对给定特定训练集的DDM生成的数据集计算每个实例的隐私泄漏。


结论
作者分析了DDM生成的合成数据集的数据相关隐私约束,结果显示DDM的隐私保护能力较弱。为了满足实际需求,可能需要结合其他隐私保护技术,例如DP-SGD(Abadi等人,2016年)和PATE(Papernot等人,2016年)。作者对合成数据集和真实数据集的观察结果非常吻合。