数据科学 — 数学(四)(机器学习)
主成分分析(PCA)
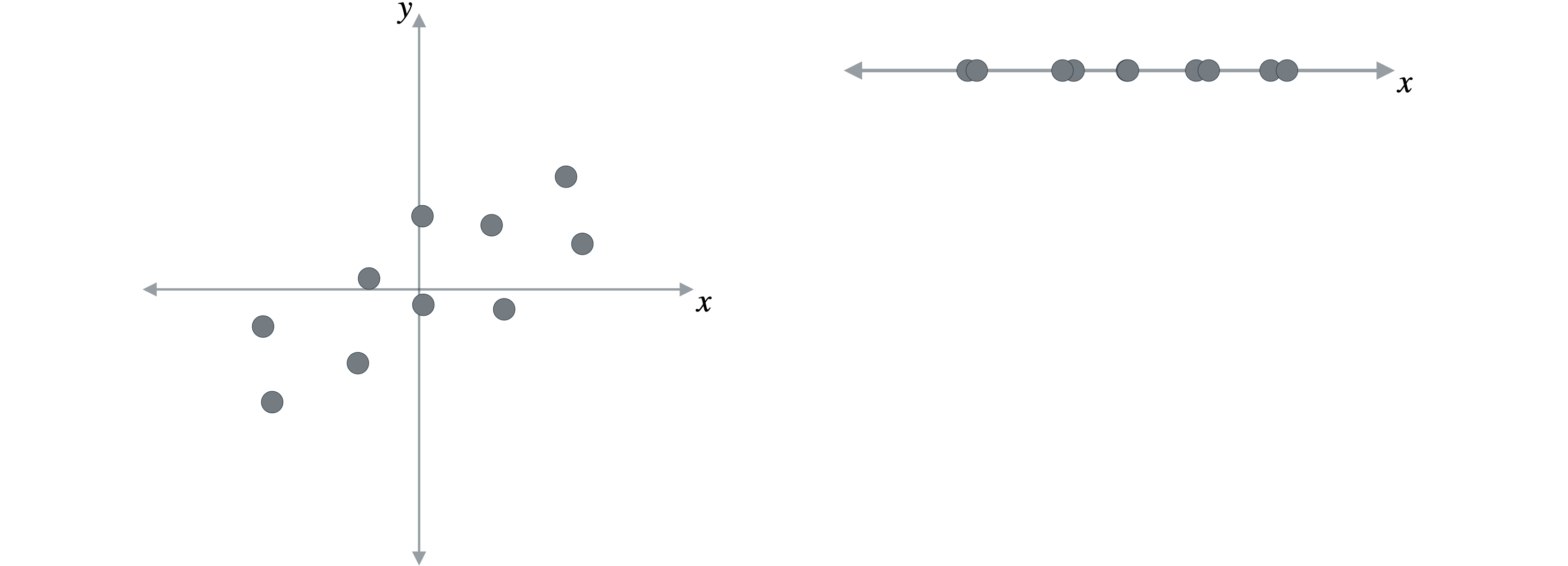
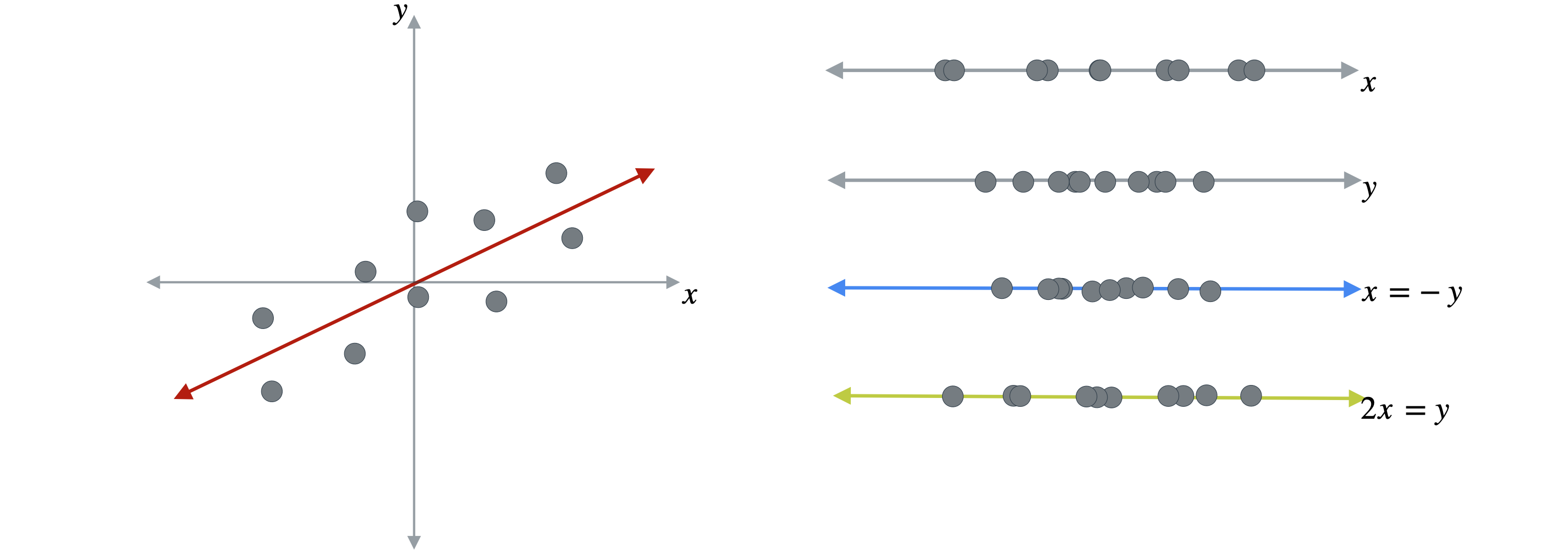
现在您已经了解了投影的概念,让我们看看PCA如何使用它来降低数据集的维度。如下图所示,每个点代表一个不同的观测值,由两个以(0,0)为中心,现在让我们看看如果投影到
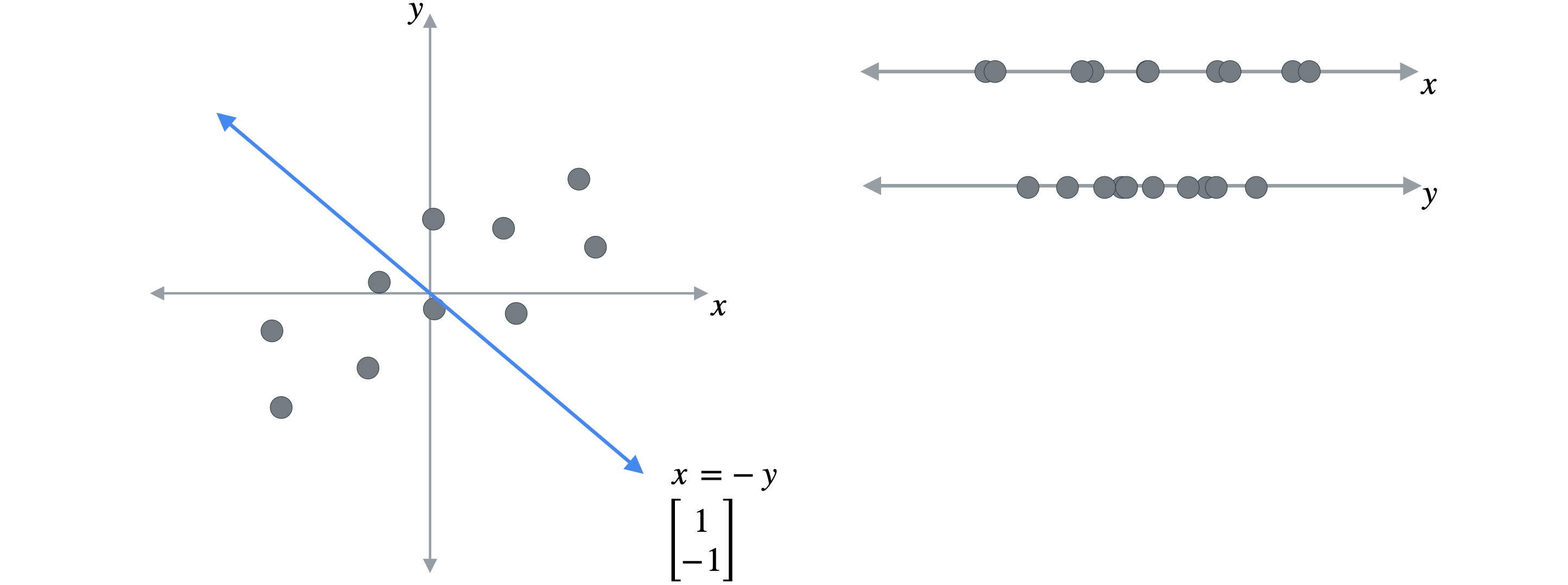
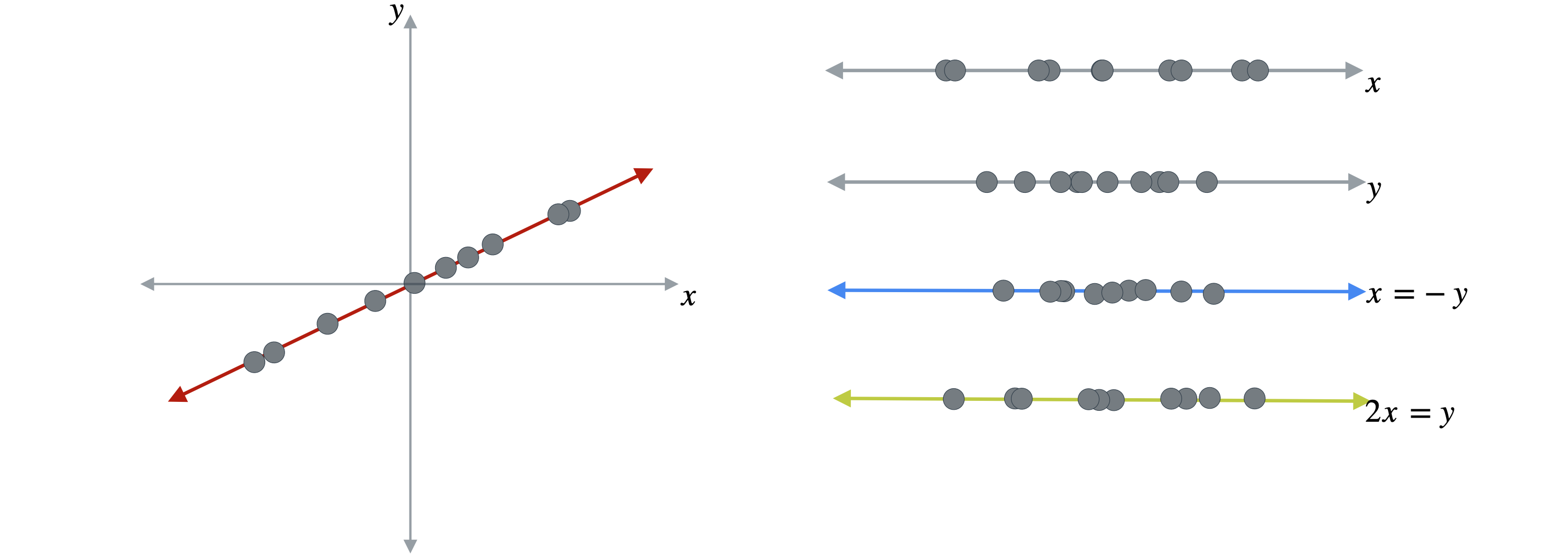
您已经可以看到,此投影中的点分布较少,因为这些点彼此更接近。您可以将它们投影到任何一条线上,例如这条线,可以用方程:(1,-1)上,因为这些点跨越了这条线。
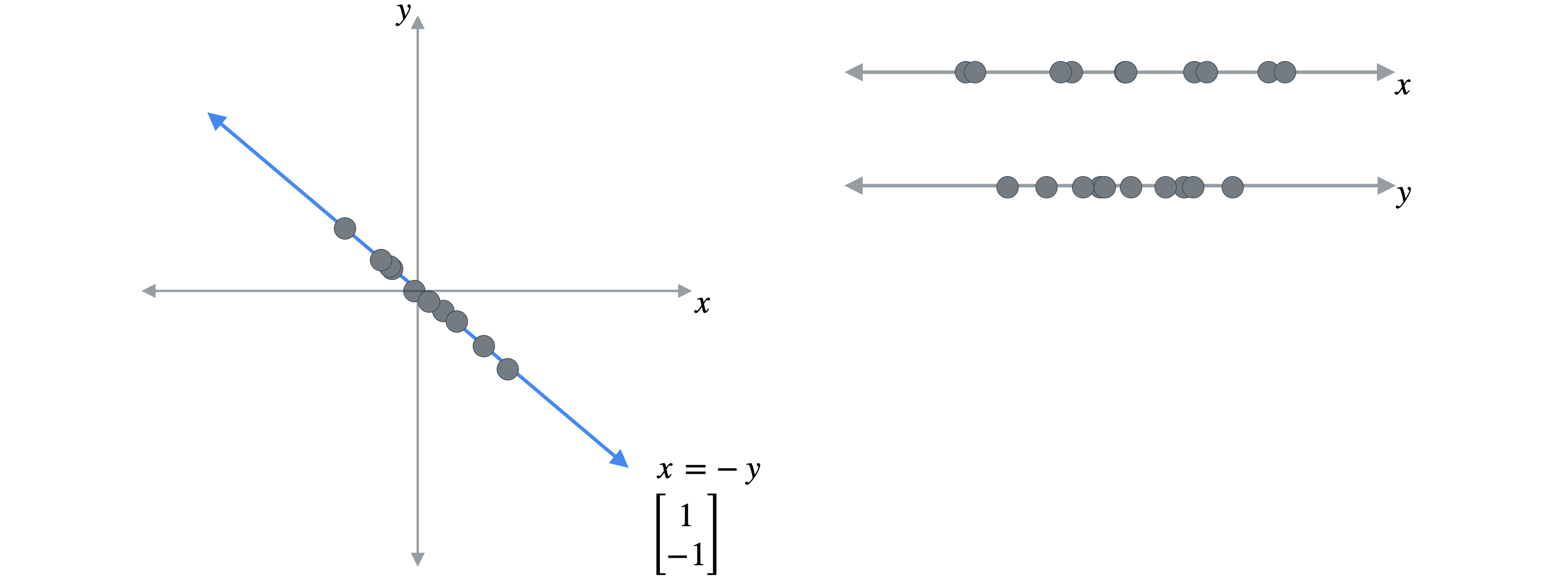
或者你也可以考虑另一条线,它求解方程:(1,2)上。这条线与数据非常吻合,并且得到的投影点仍然相对分散。经过这些投影后,数据点可能会或多或少地分散,而这最终会变得非常重要。原因是分散程度更高的数据点会保留原始数据集中的更多信息。换句话说,保留更多的分散度意味着保留更多信息。现在,我将按点分散程度从大到小对投影进行排序。顶部的投影点分散程度最高,因此它保留了原始数据集中最多的信息,底部的投影点分散程度最低,因此保留的信息最少。因此,PCA的目标是找到即使在降低数据集维度的情况下也能保留数据中最大可能分散度的投影。
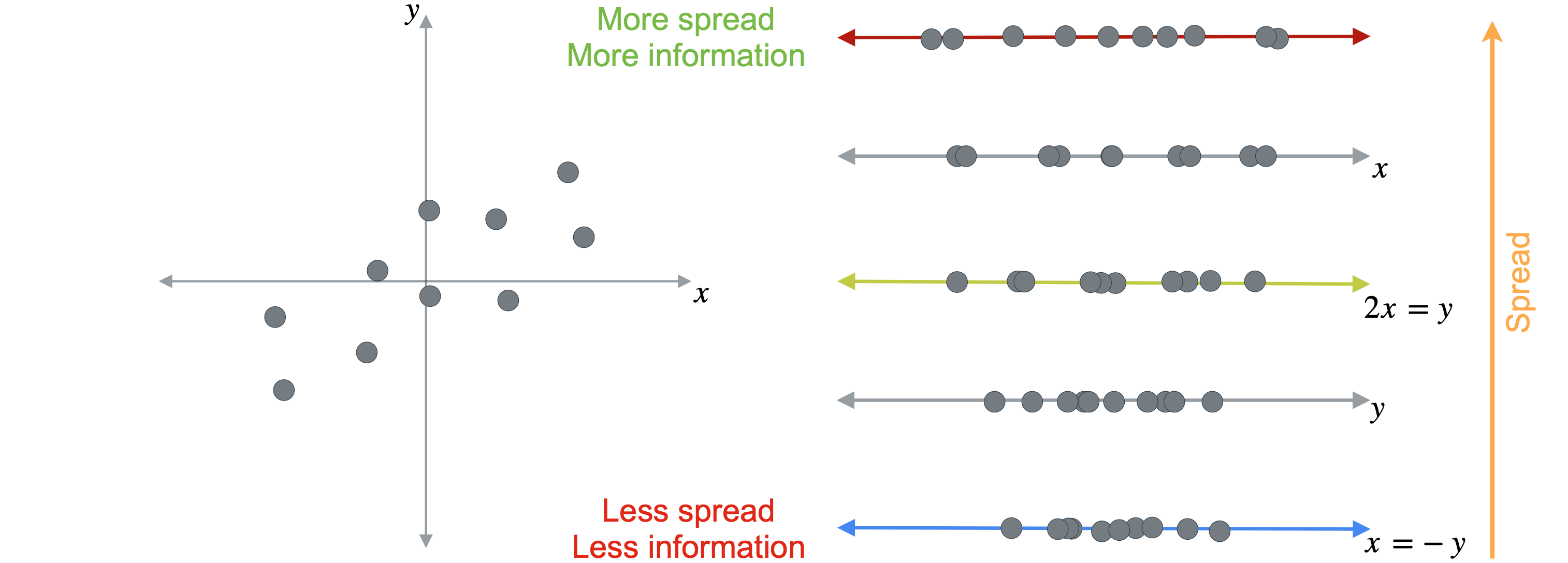
再次强调,降维和PCA的好处如下。降维使数据集更容易管理,因为它们更小。PCA允许您在减少维度的同时最大限度地减少信息丢失。由于维度的减少,实现了不可能的方式分析可视化数据。
方差(Variance)和协方差(Covariance)
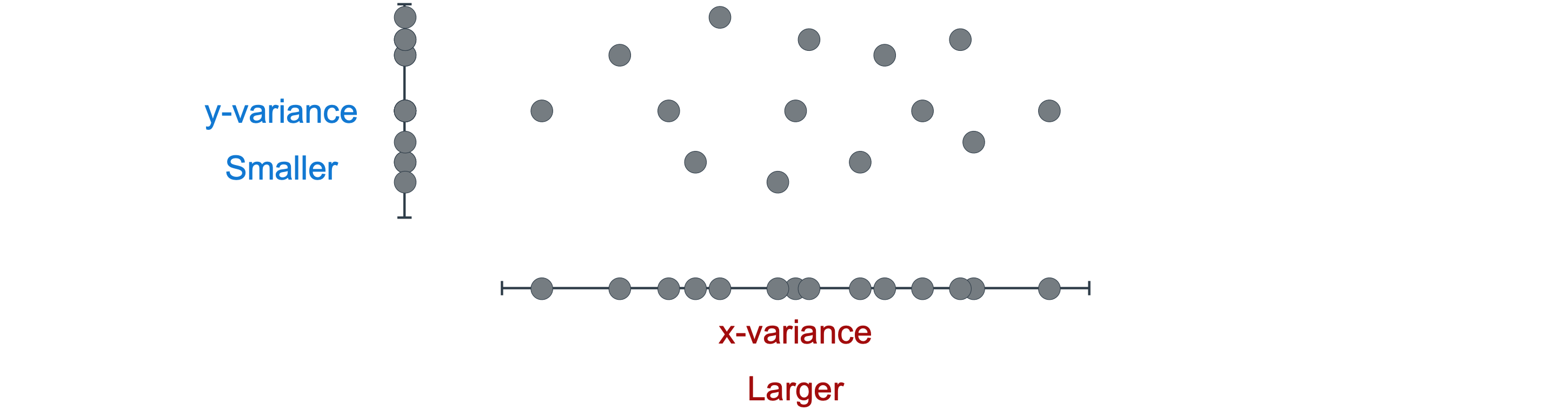
考虑这个数据集,如下图所示,每个点都是由两个变量n个值相加并除以n,

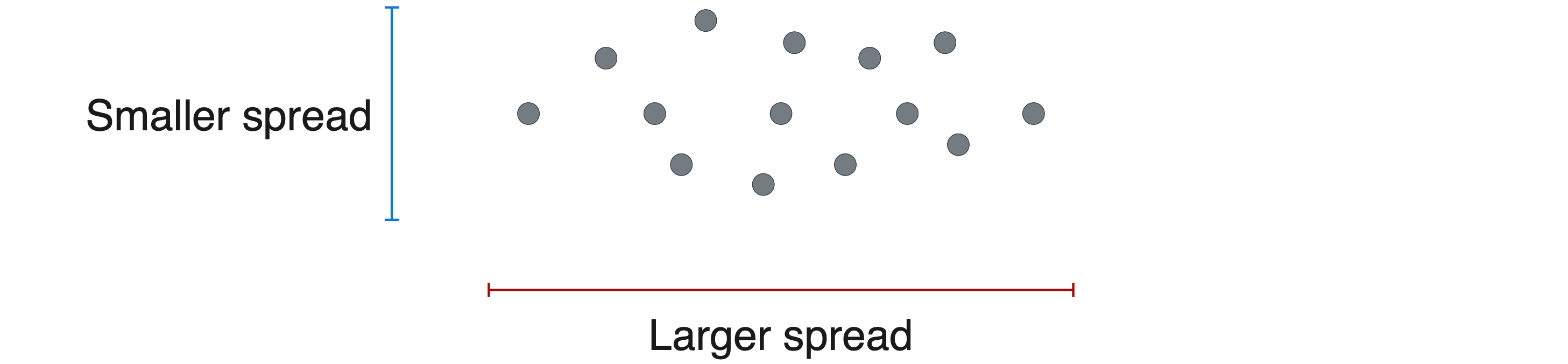
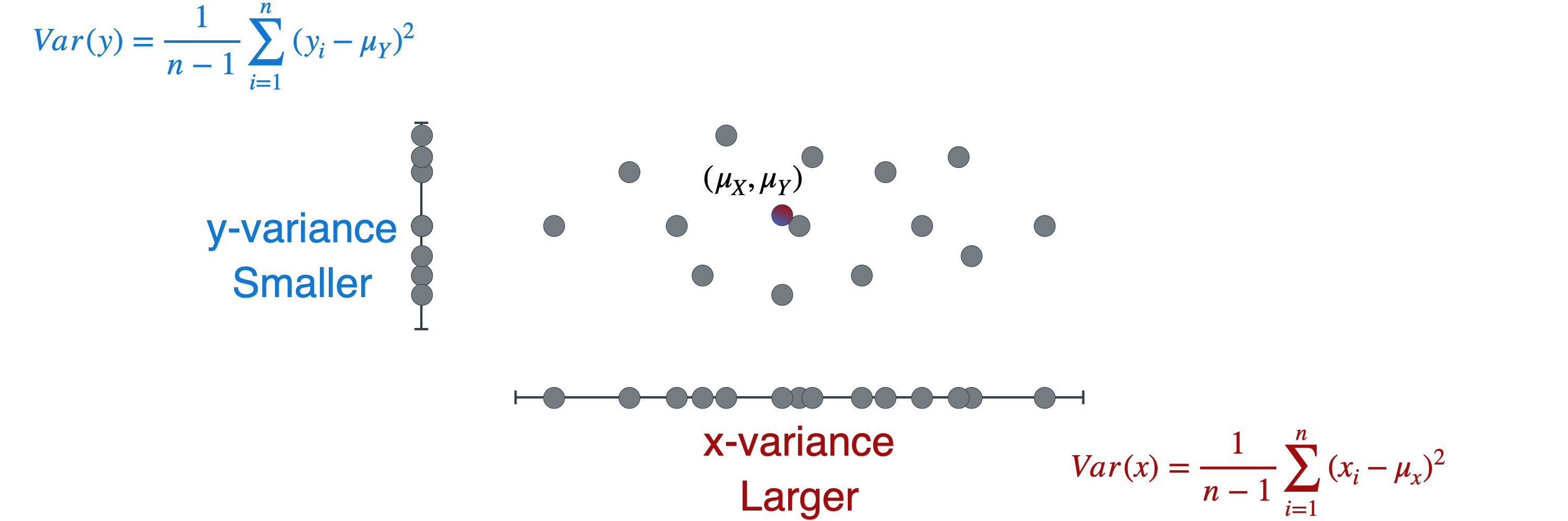
接下来,您将了解方差的概念,它描述了数据的分散程度。如果你想描述这些点在图表中是如何出现的,你可能会说,如果我们沿着横轴看这些点,它们会更分散或分布得更大,而如果我们沿着纵轴看这些点,它们会更紧凑,分布得更小。在统计学中,分布是用数据集的方差来衡量或描述的。没有值分布的数据集的方差为0,而分布较大的数据集的方差较大。为了更清楚地看到这一点,我将使用二维图表,并将每个点移动到横轴上,如下图所示。
不用担心方差是如何计算的,我们可以看到,水平
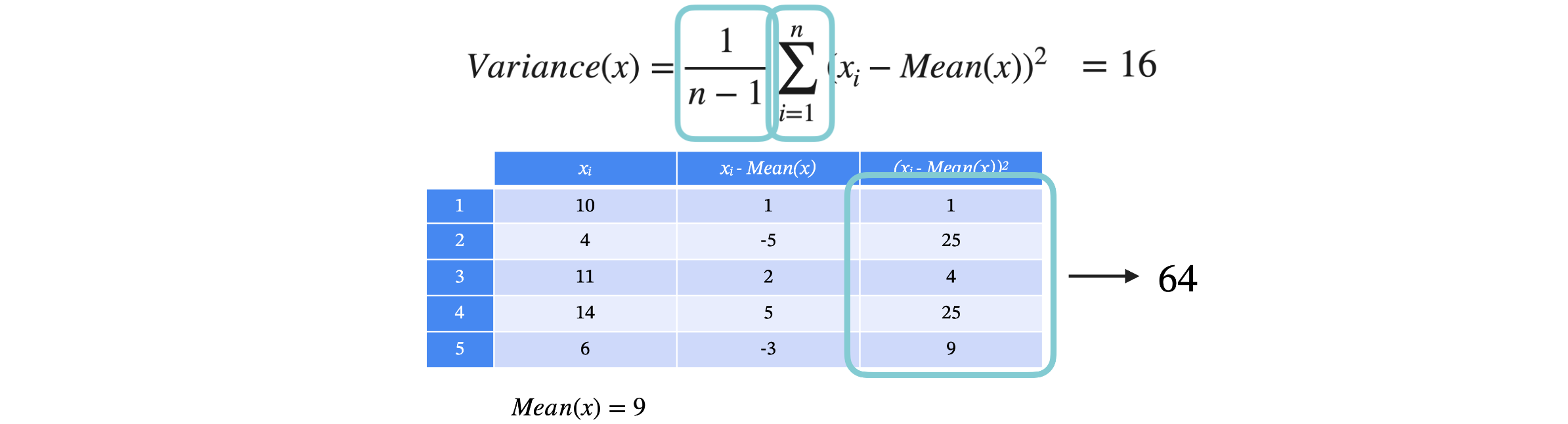
请考虑一个非常简单的数据集,其中一列表示变量1-5。每行都有一个观测值5来计算45,平均值为9。接下来,找出每个值和列9。现在求每个差值的平方,将结果放在一个新列中。求和将64,最后将这个总数除以n是5,我们除以4,得到方差16。
方差通常缩写为
方差有助于我们量化数据的分散程度,但现在考虑单靠方差无济于事的情况。这两个数据集各有三个观测值。它们具有相同的

现在您对它测量的内容有了很高的理解,让我们看看协方差是如何计算的。协方差方程如下所示。
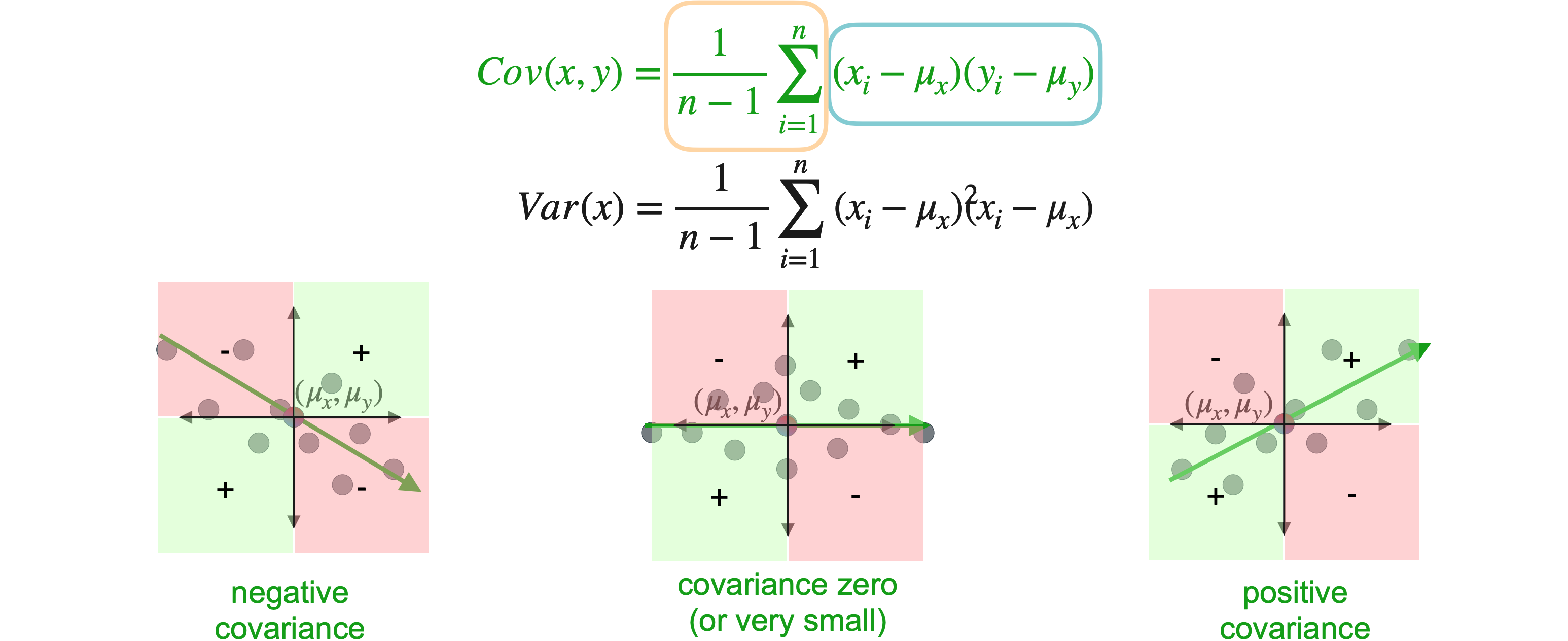
一开始可能有点复杂,所以我会把它分解成几个部分。但是,正如您所见,它看起来与方差方程非常相似,如果您在最后展开平方项,它们几乎相同。唯一的区别是,圆圈内的项现在取决于
您可以将协方差视为平均,正象限中的点更多还是负象限中的点更多?对于第一个象限,负象限中的点更多,因此协方差将为负数。在第二个象限中,点在正象限和负象限之间大致相等,这导致协方差接近于零。在第三个象限中,大多数点位于正象限,导致协方差为正。无论您是否觉得自己完全理解了协方差方程,此时最重要的是直观地了解它们测量的内容。您可以将协方差视为测量两个变量之间关系的方向。负协方差表示负趋势,小协方差表示平缓趋势或无关系,正协方差表示正趋势。
协方差矩阵
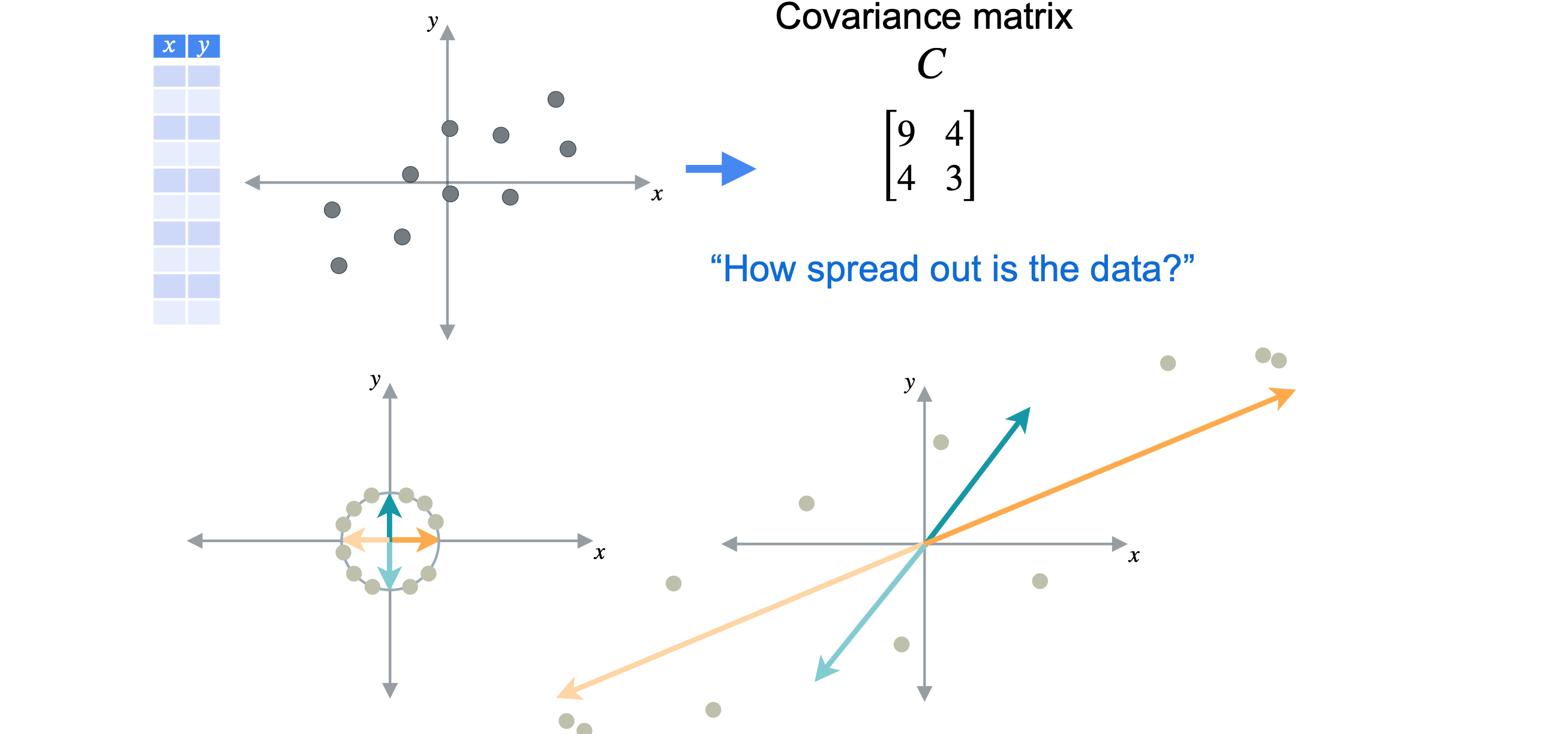
您已经学习了有关方差和协方差的知识,因为您的最终目标是构建一个称为协方差矩阵的特殊矩阵。它是一种存储数据集中变量对之间所有关系的复杂方法。第一个例子的斜率向下,所以我说它的协方差是-2;第二个例子的斜率比较平缓,所以我说它的协方差是0;最后一个例子的斜率是正向的,所以我说它的协方差是2。使用这些度量,我现在将为每个数据集构建一个协方差矩阵。在对角线上,我将放置
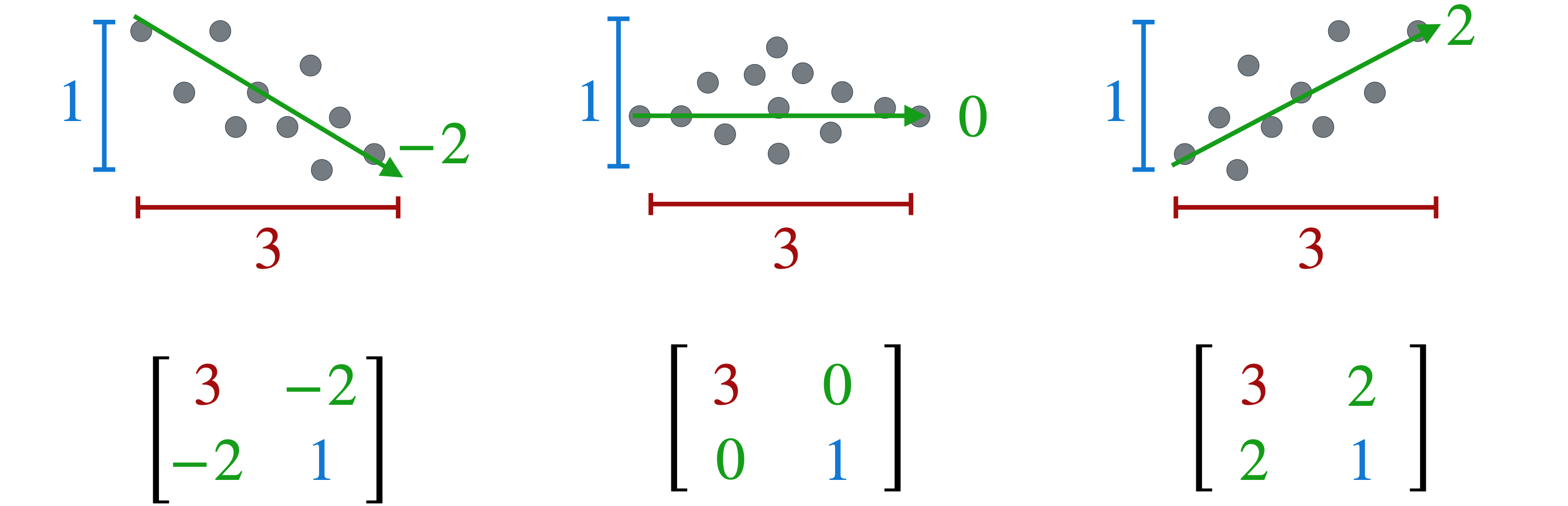
让我们将这个过程更形式化一点。首先计算每个变量的方差和每个变量组合的协方差。这里只有
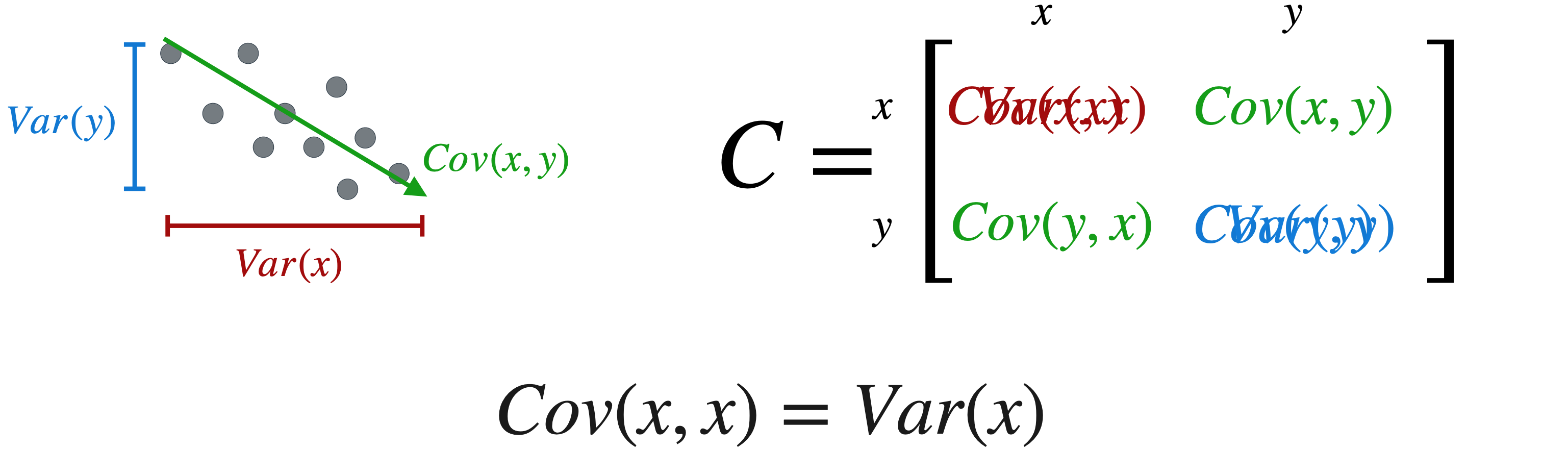
请注意,2,即变量数乘以n,即观测数。第二个矩阵的大小为n,乘以2,这意味着两个矩阵的乘积将为2,乘以2,这恰好是协方差矩阵的大小。现在,开始进行矩阵乘法。对于矩阵的第一个元素,您需要将第一个矩阵的第一行乘以第二个矩阵的第一列,即
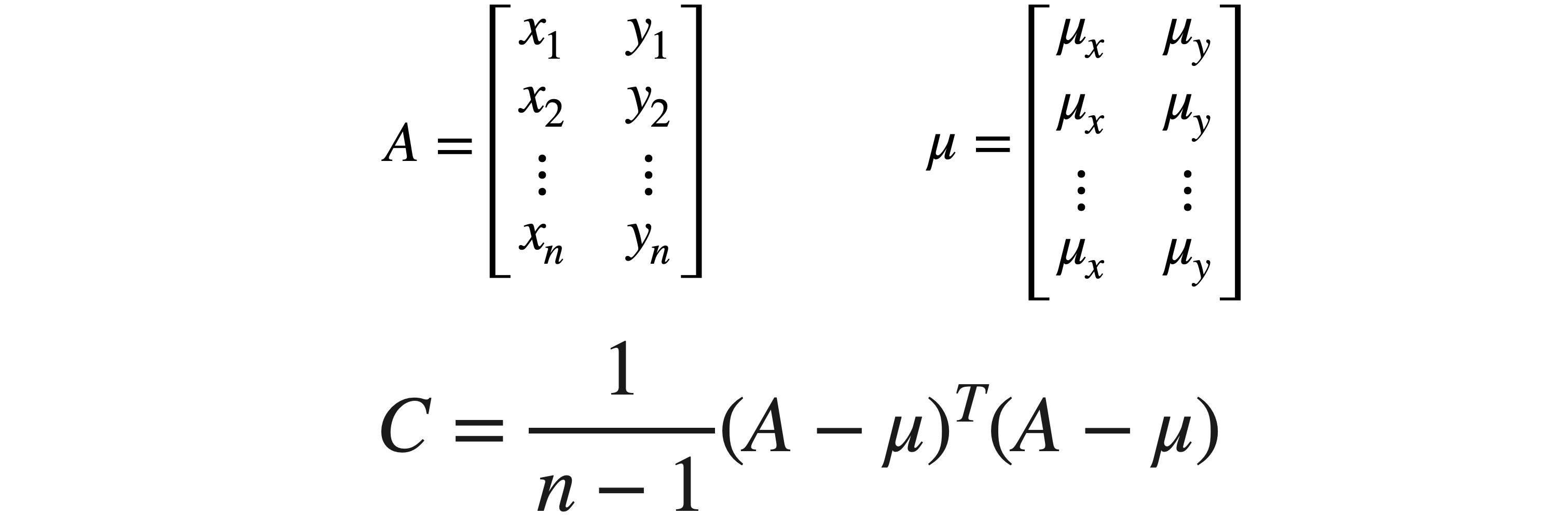



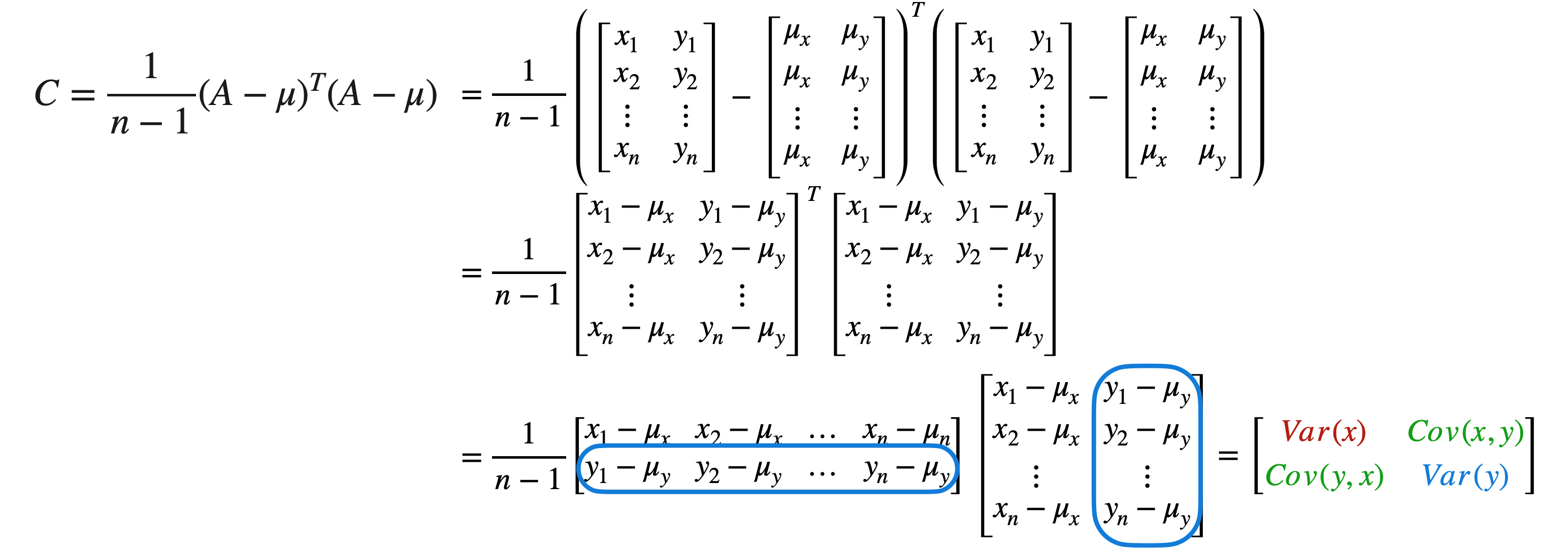
这实际上简化为变量n项之和。如果我们合并8个观测值。考虑到数据的分布,您会希望8和6,现在创建矩阵8个观测值,因此在此乘积前面添加
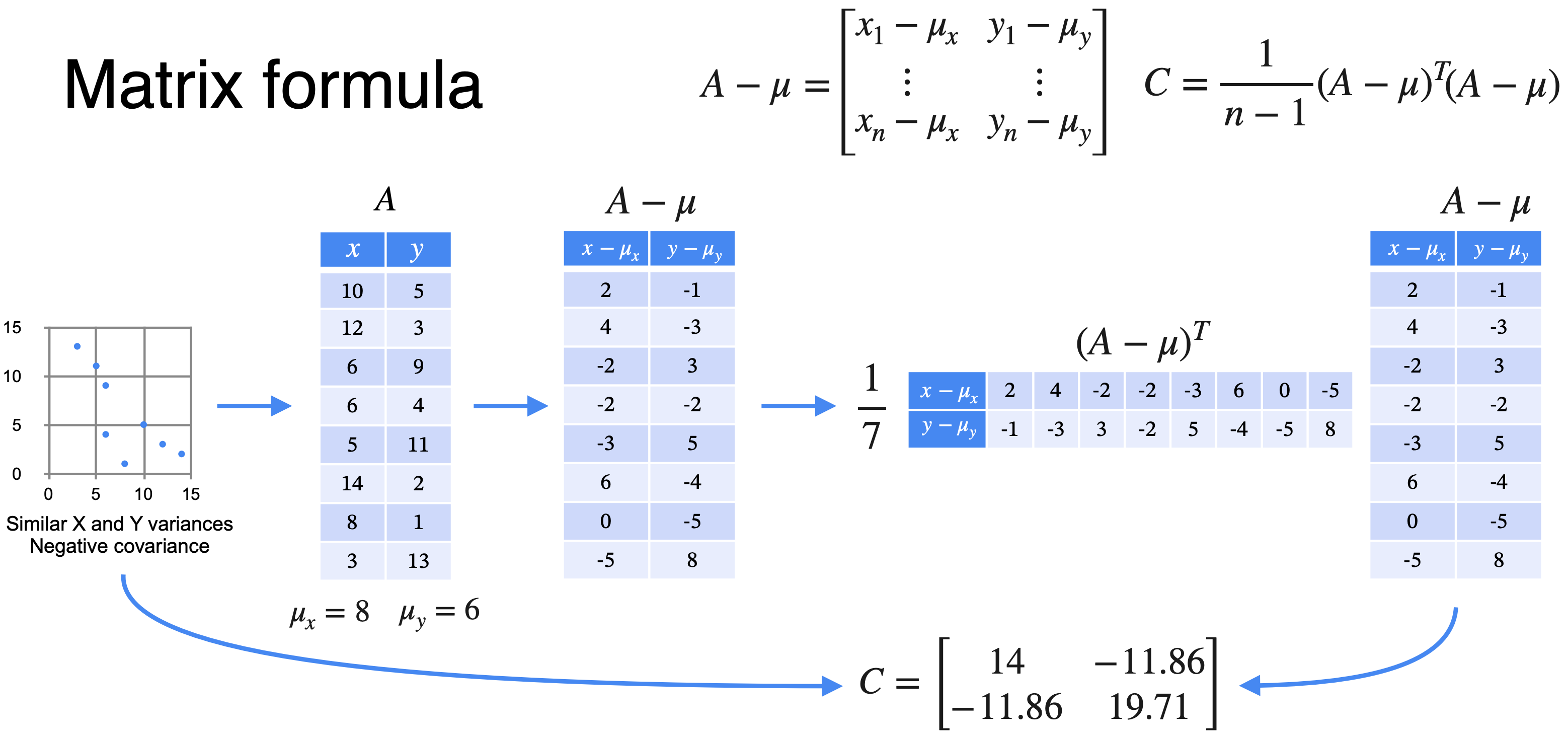
计算协方差矩阵的步骤:
- 在每列中包含不同的特征数据。
- 计算每列的平均值
。 - 从各自的列中减去平均值,生成矩阵
。 - 计算公式为:
。
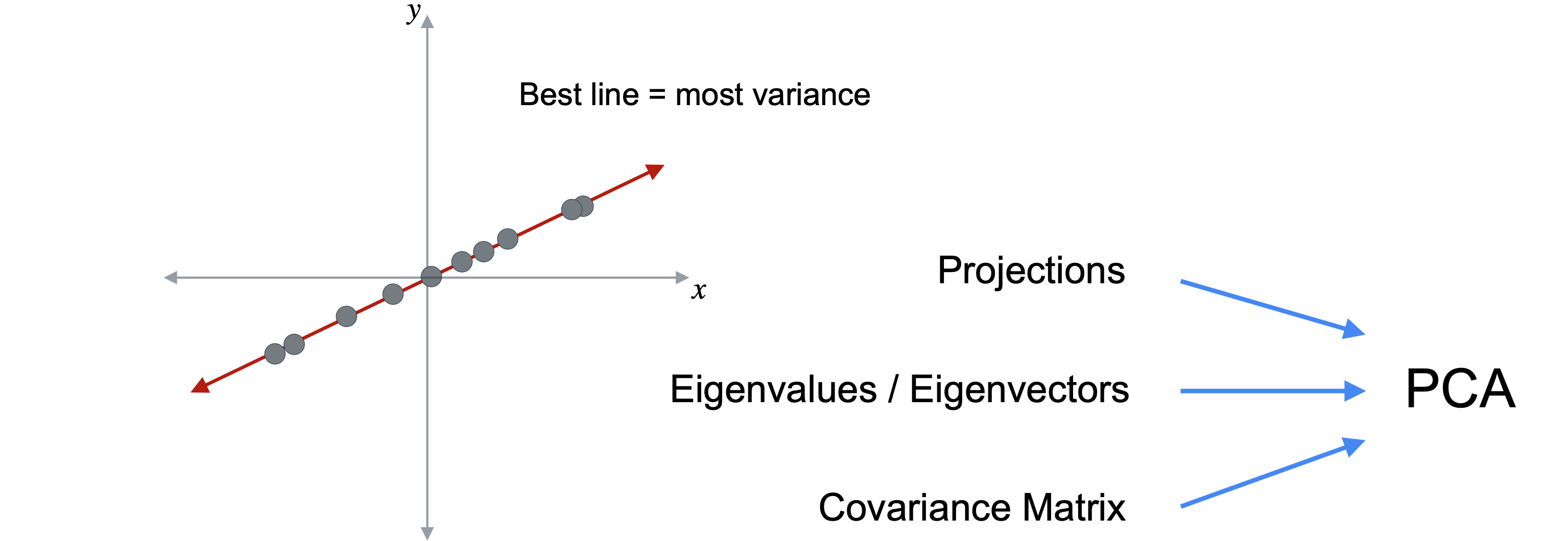
PCA概述
有一个的数据集,目标是将数据投影到保留信息最多的线上。这条最佳线是保留数据中最大方差的线。那么问题是,你如何找到这条最佳线?到目前为止,你已经了解了投影,以及矩阵乘法如何将数据投影到低维空间。你还了解了特征值和特征向量,以及它们如何捕捉线性变换仅拉伸空间但不旋转或共享空间的方向。了解了协方差矩阵以及它如何紧凑地表示数据集中变量之间的关系。PCA的工作原理是巧妙地结合这三项技术,有助于减少数据中的维数。
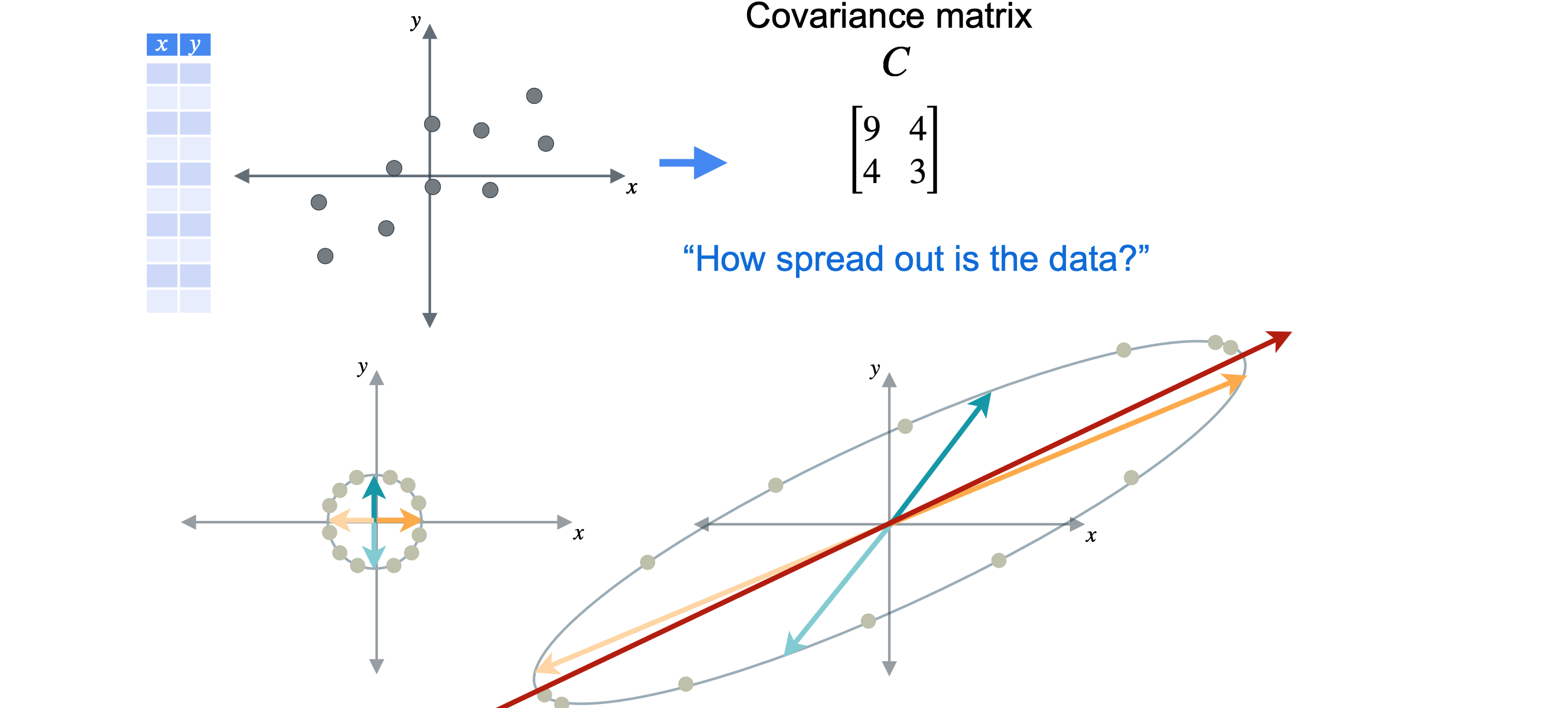
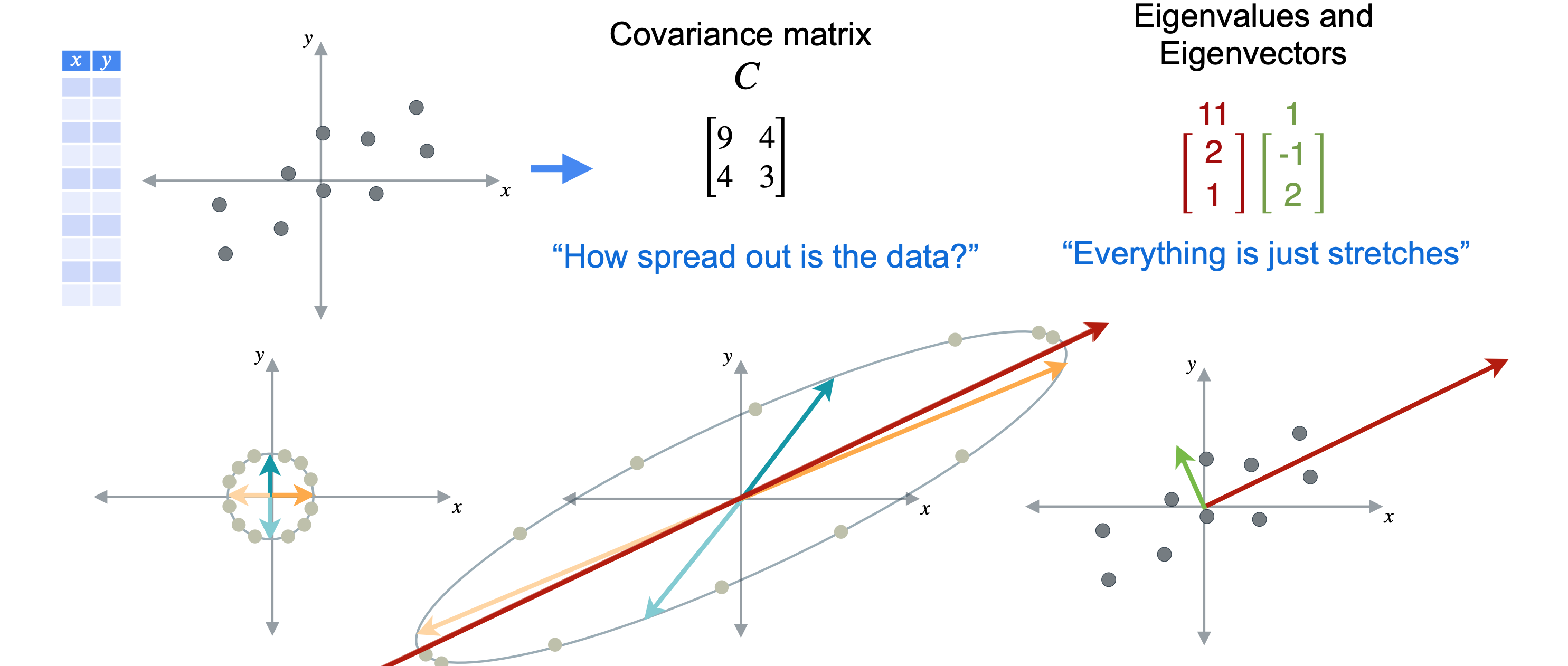
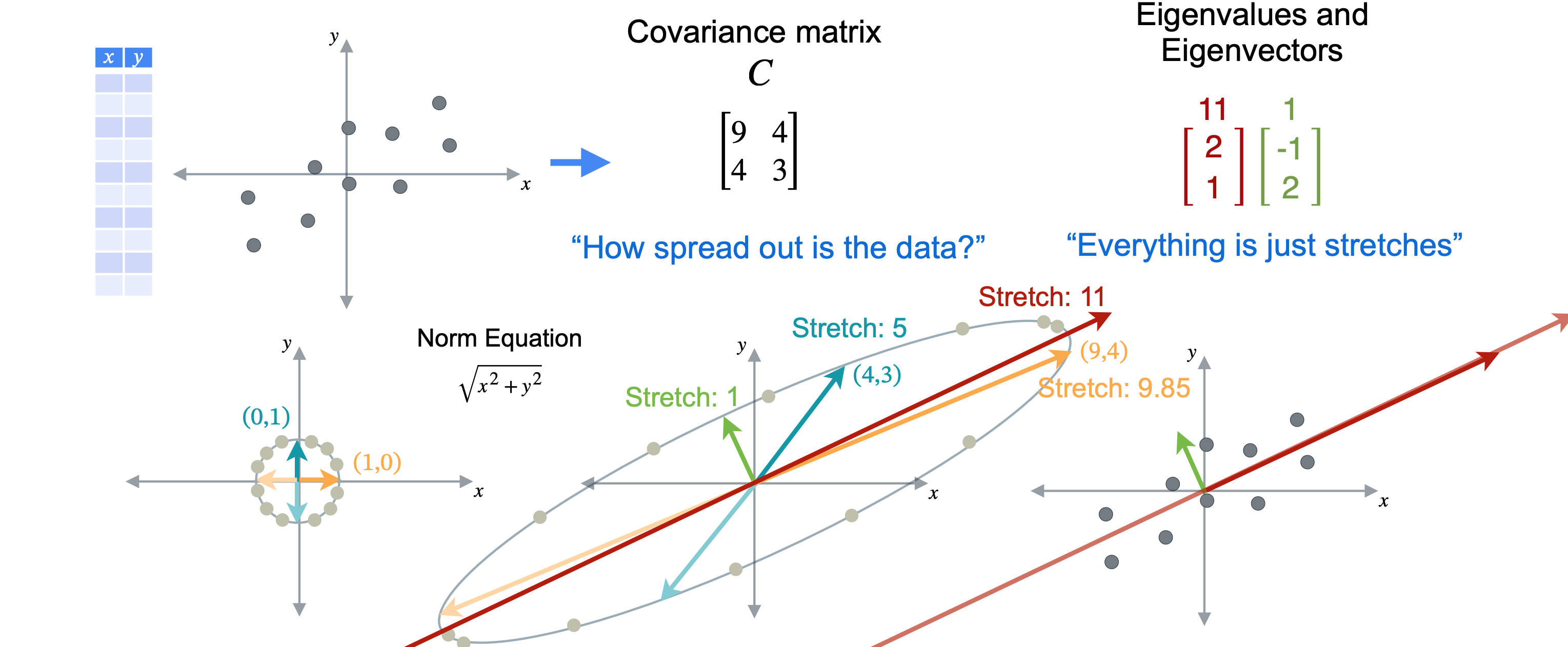
首先,来计算数据点的协方差矩阵9,3。协方差为4。现在,计算协方差矩阵的特征值和特征向量。应该将数据投影到的那条线。请记住,特征向量和特征值是成对出现的,特征向量具有方向,特征值具有幅度。第一个特征向量为(2,1),其特征值为11。第二个特征向量为(-1,2),其特征值为1。这两个向量彼此成90度角,这也称为正交。这并非巧合,但对于每个沿对角线对称的矩阵的特征向量来说,这都是正确的。
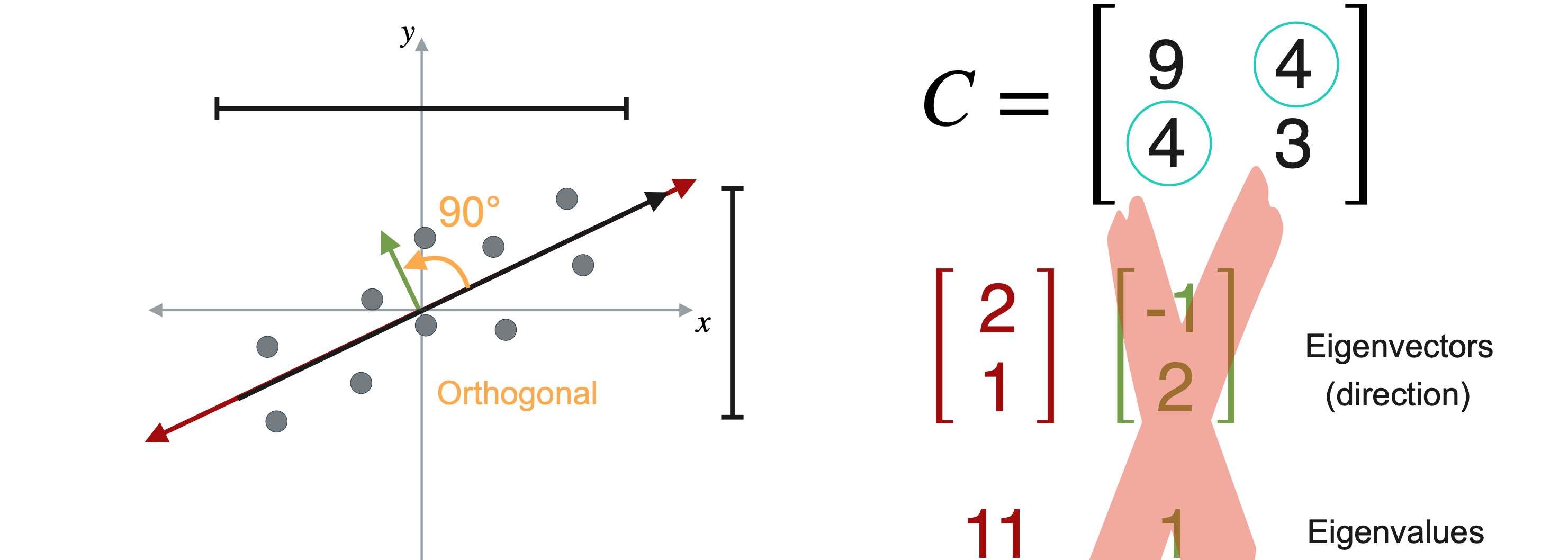
在本例中,向量(2,1)的特征值为11,远大于1。所以将沿着这条线投影数据。同时,您可以丢弃具有较小特征值的第二个特征向量。现在您可以绘制向量(2,1)跨越的线,剩下要做的就是将数据投影到这条线上。现在这些点已沿着该向量投影,您不需要在二维中绘制它们。重要的是它们在向量上的位置。就这样,您已降低了数据的维度并保留了尽可能多的方差,这是PCA的两个目标。您看到数据从二维变为一维。您可以认为数据已减少为单个新值n个观测值。对这些数据执行PCA操作。您可以获得协方差矩阵。由于您有九个变量,这将产生一个
现在你可能相信这个过程是可行的,为什么在这里展示严格的证明会有点困难。让我们回到只有两个特征的数据集的情况,将其称为(1,0)将移动到(9,4),基向量(0,1)将移动到(4,3)。让我们从添加这个点开始,看看它的变换,然后继续绕着圆周移动。如果将变换平面上的所有点连接起来,你会看到它们映射出一个椭圆。这样半径为1的圆就变换成了椭圆,你可以看到所有点都向不同的方向拉伸。请注意,我们将圆的半径视为1,因为我们只对拉伸的方向感兴趣。如果你选择了另一个更大的圆上的点,你仍然会得到相同的椭圆,只是更大。看看变换后的点,你认为哪个方向的拉伸最大?我会说就是这里的红线,它与椭圆的长轴对齐。如果你以任何其他方向切割椭圆,你会得到一条更短的线。这就是特征值和特征向量的用武之地。此协方差矩阵具有两个特征向量(2,1),其特征值为11,以及(-1,2),其特征值为1。这两个向量合在一起形成一个特征基,从这些特征基的角度来看,变换11倍,即特征值。向量上的任何点都将被拉伸12倍,即特征值。平面中的任何其他向量都会被拉伸1~11之间的某个因子。举例说明,我将使用范数方程计算变换前后向量的范数,并找到它们之间的比率。将从蓝绿色向量(0,1)开始,你已看到它被移动到向量(4,3)。在这种情况下,向量以1开始,以5结束,因此它被拉伸了5倍。现在考虑橙色向量(0,1),你已看到它被移动到向量(9,4)。这个向量也是以1开始,如果使用范数方程,你可以计算出最终范数约为9.85。所以,这再次说明了这个向量被拉伸了多少。这次拉伸更接近11,但仍然小于沿特征向量(2,1)发生的最大拉伸。协方差矩阵
PCA—数学公式
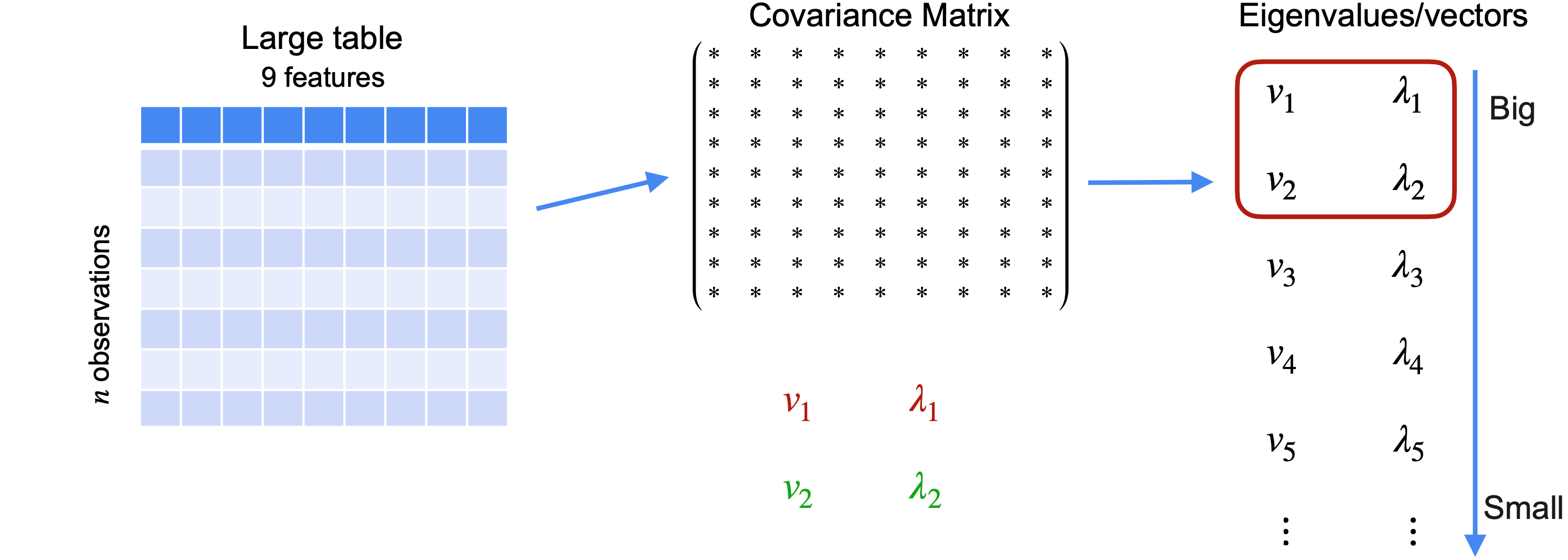
在这个例子中,将有五个变量。从一组包含五个变量n个观测值的数据集开始。您的目标是将数据从维度5减少到维度2。首先,构建一个数据矩阵。这个矩阵将有五列,每个变量(特征)为一列,n行,每个观测值一行。这是您之前用来获取协方差矩阵的相同矩阵,称为
接下来,找到协方差矩阵的特征值和特征向量。找到它们后,按特征值从大到小对它们进行排序。现在,您将创建一个矩阵来投影数据。由于您的目标是将数据集减少到只有两个变量,因此您将只保留第一和第二个特征值、特征向量。创建一个矩阵PCA对数据进行降维所需的操作步骤。
PCA步骤 |
Description |
Computing Graph |
|---|---|---|
step 1 |
创建X矩阵 |
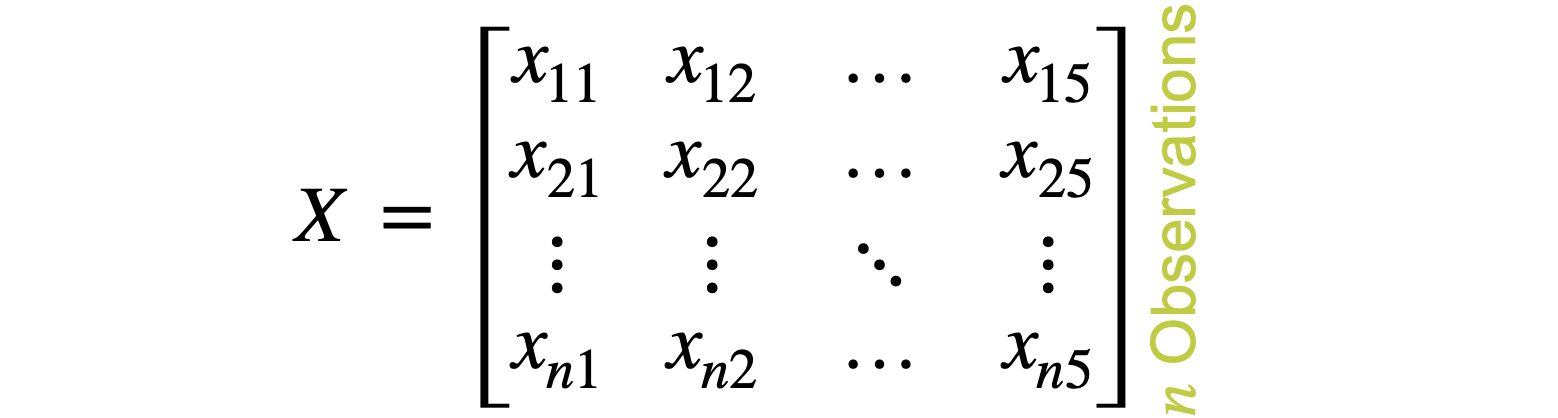 |
step 2 |
生成中间矩阵数据: |
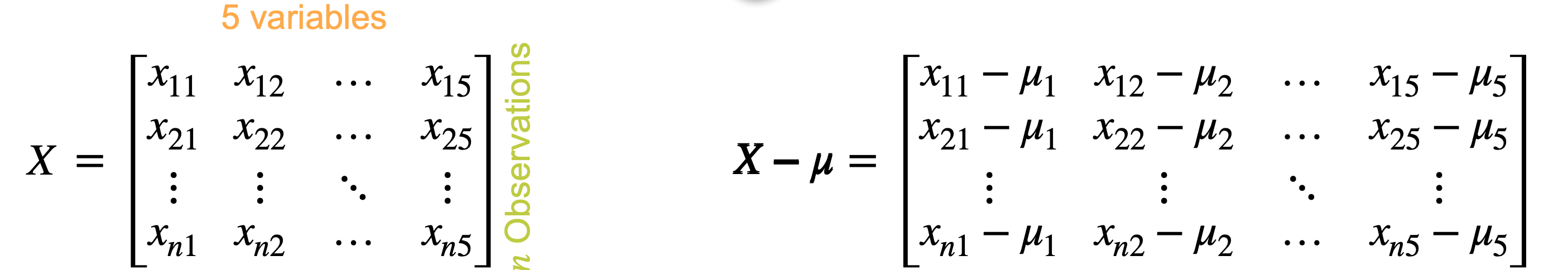 |
step 3 |
计算协方差矩阵 | 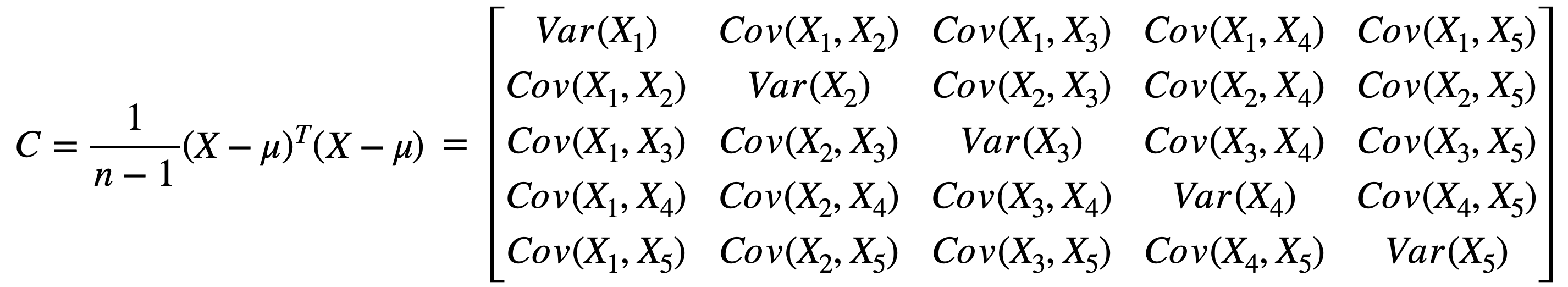 |
step 4 |
计算特征向量和特征值 | 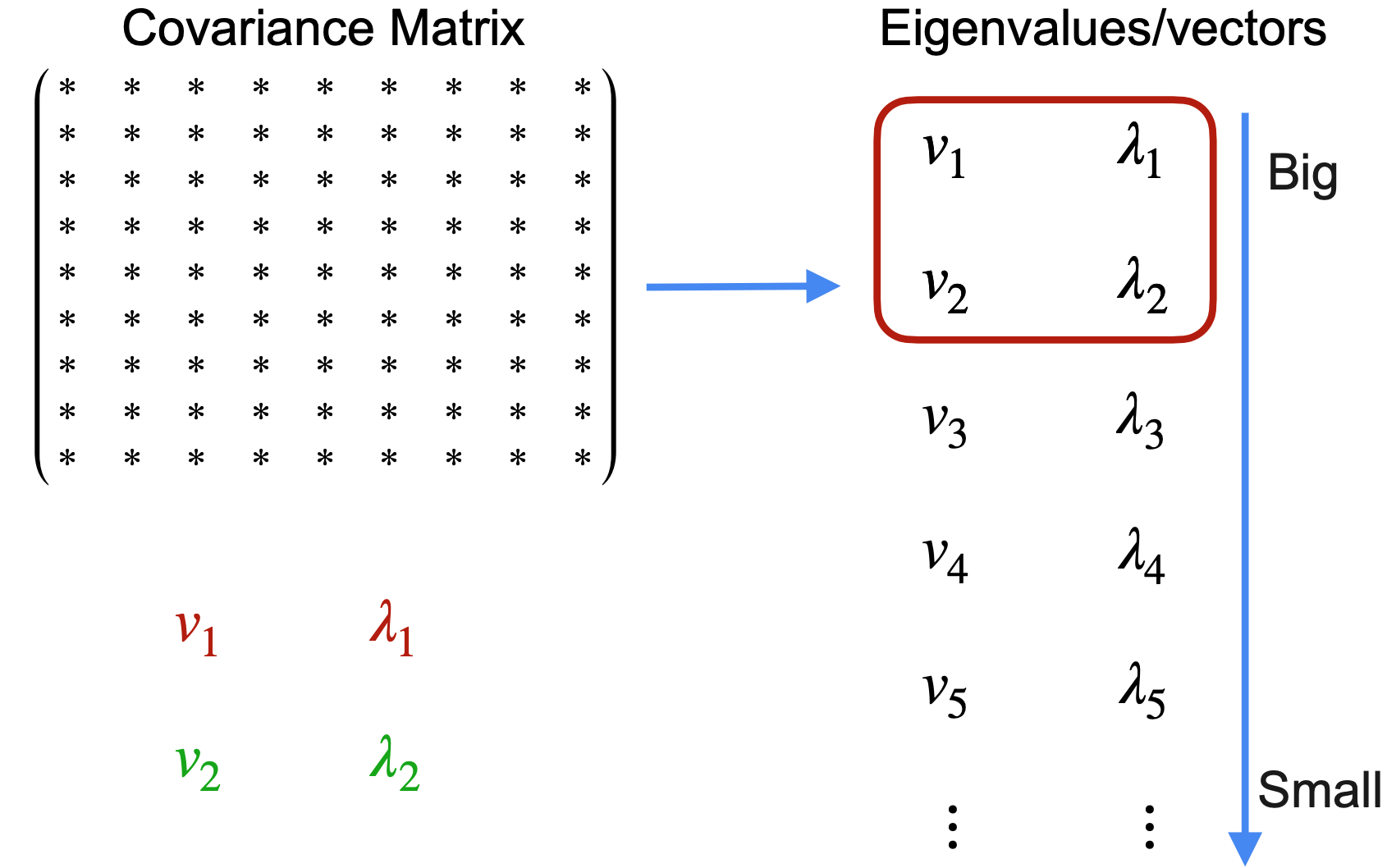 |
step 5 |
创建投影矩阵 | 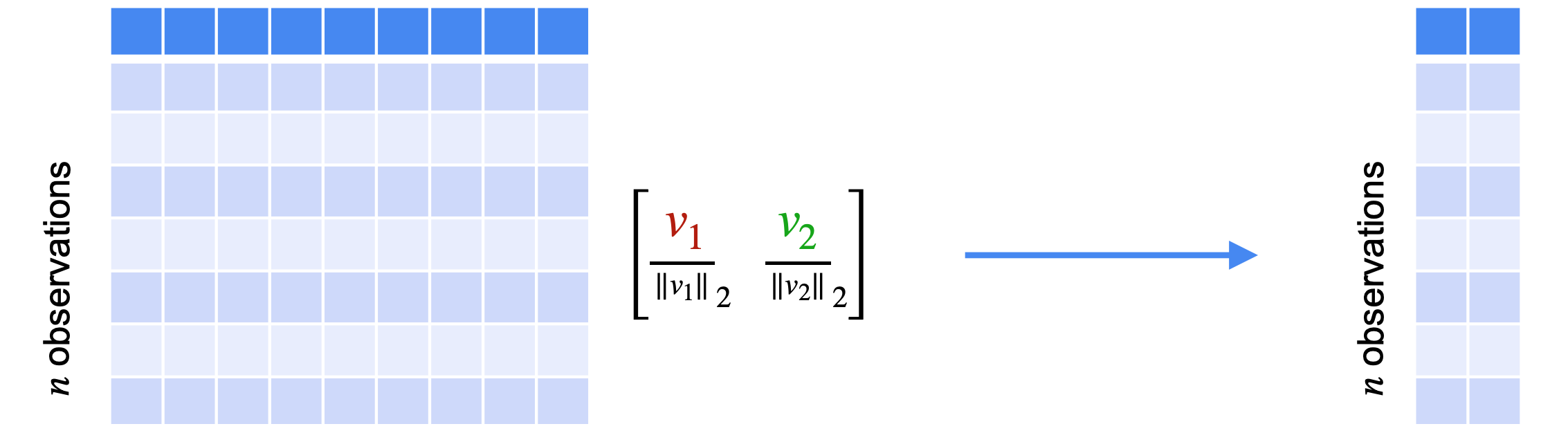 |
step 6 |
 |
离散动力系统
离散动力系统是数学中的一个重要领域,主要研究系统在离散时间步长下的演变。这些系统通过迭代函数来描述状态的变化,通常用以下形式表示:
其中
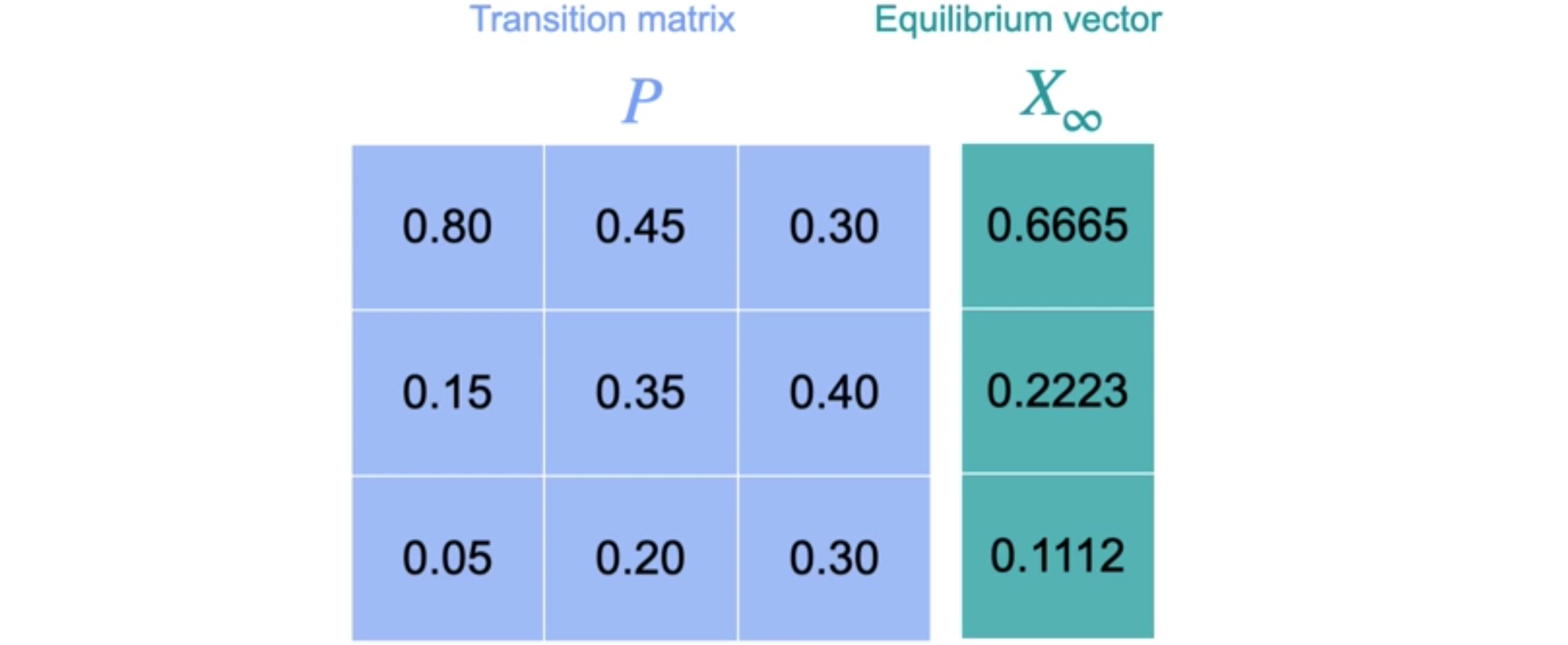
离散动力系统是特征向量的一个简单应用。假设今天是晴天,您想知道明天是晴天、多云或下雨的概率有多少?假设今天是晴天,明天晴天的概率为0.8,多云的概率为0.15,下雨的概率为0.05。如果今天是多云呢?那么明天晴天的概率可能会变为0.45,多云的概率为0.35,下雨的概率为0.2。最后,如果今天下雨,那么明天晴天的概率为0.3,多云的概率为0.4,下雨的概率为0.3。您可能已经注意到这些值是正数,尽管它们也可能是零,并且列加起来为1。如果方阵具有这些属性,我们称它为马尔可夫矩阵。马尔可夫矩阵很重要,因为它们允许您推断系统如何演变的概率。假设今天是多云天气。您可以用向量(0,1,0)来表示,因为您100%确定今天是多云天气。
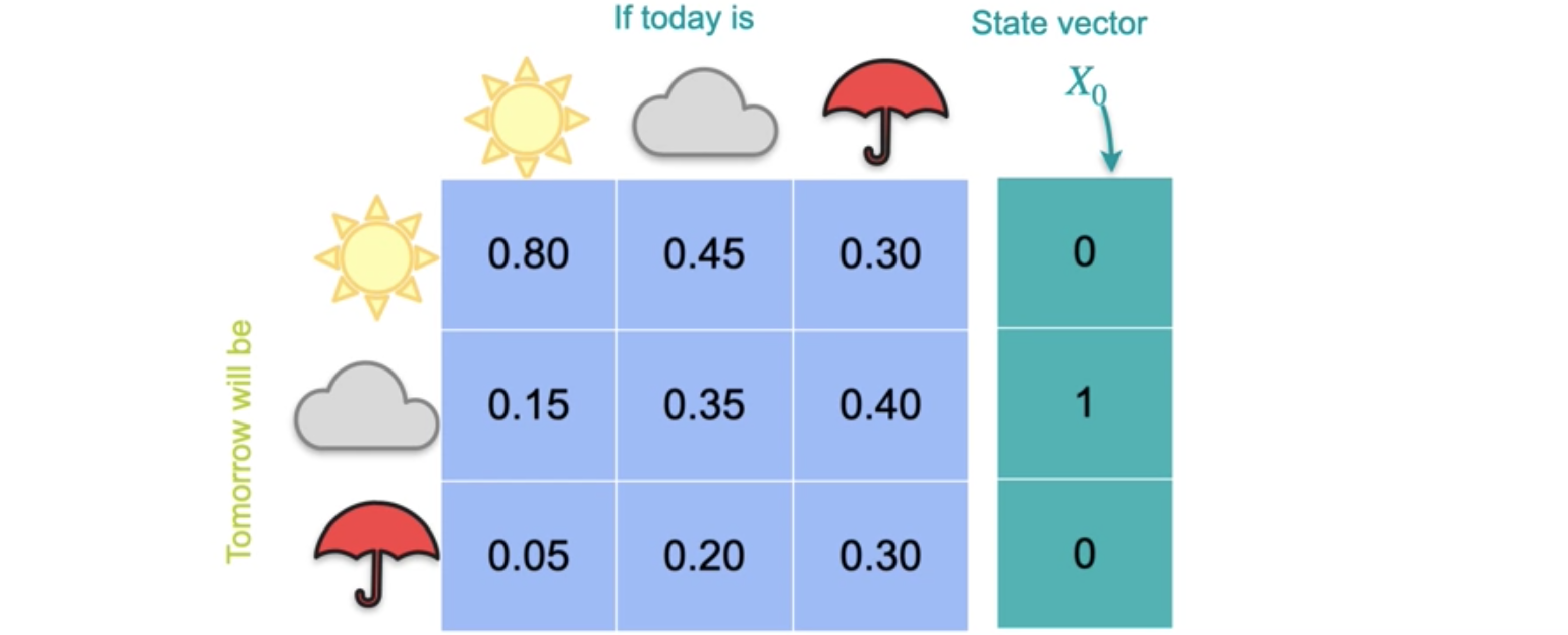
这被称为状态向量,因为它表示系统的状态。由于这是您要考虑的第一个向量,我将其称为0.45、0.35和0.2。
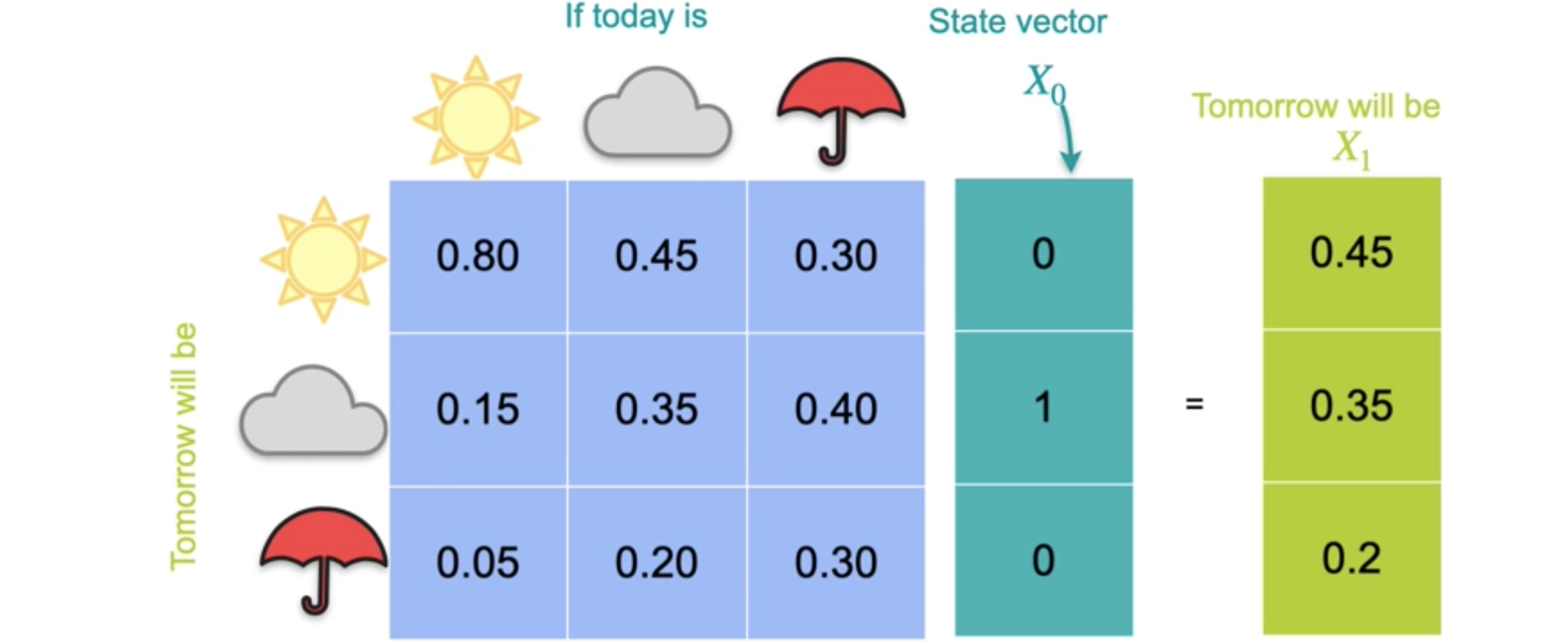
请注意,这只是矩阵的第二列,对应于多云天气,这是对未来一天的天气预测。现在,假设您想要第二天的预测,因此您将矩阵和新的状态向量0.5575、0.27和0.01525。
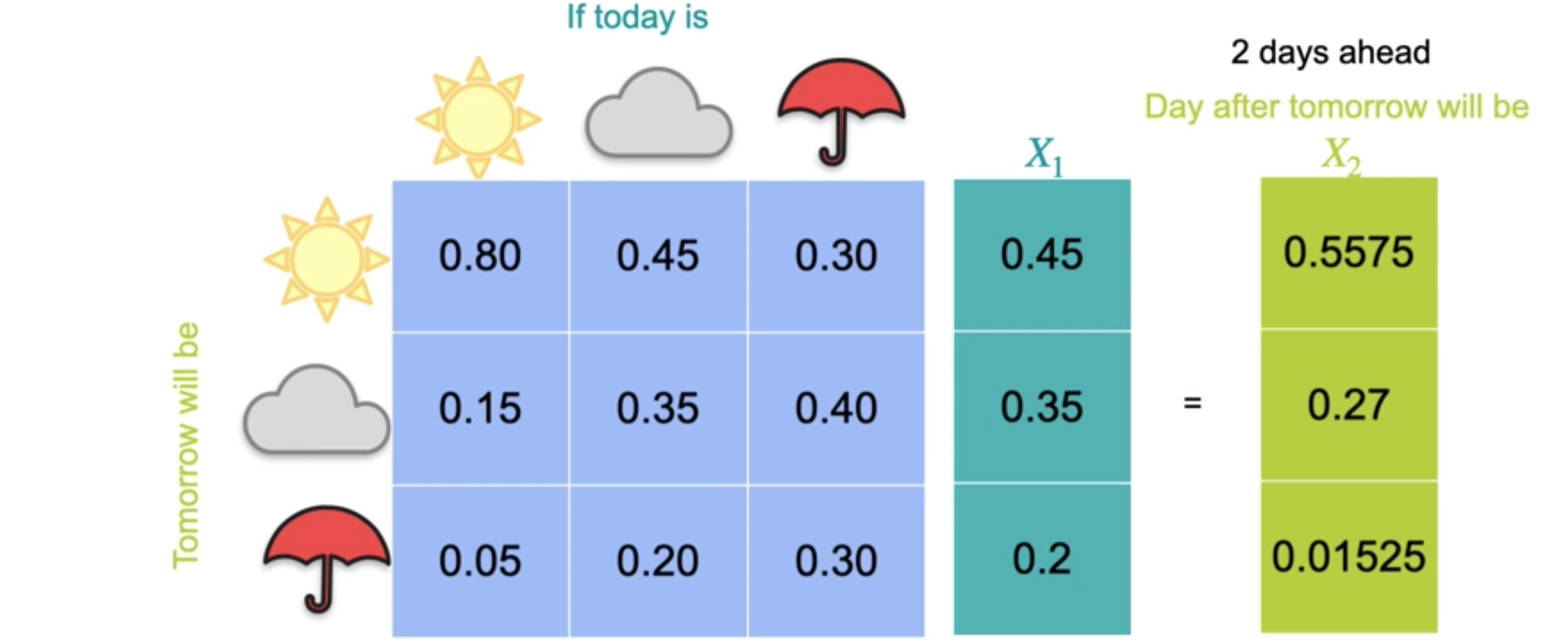
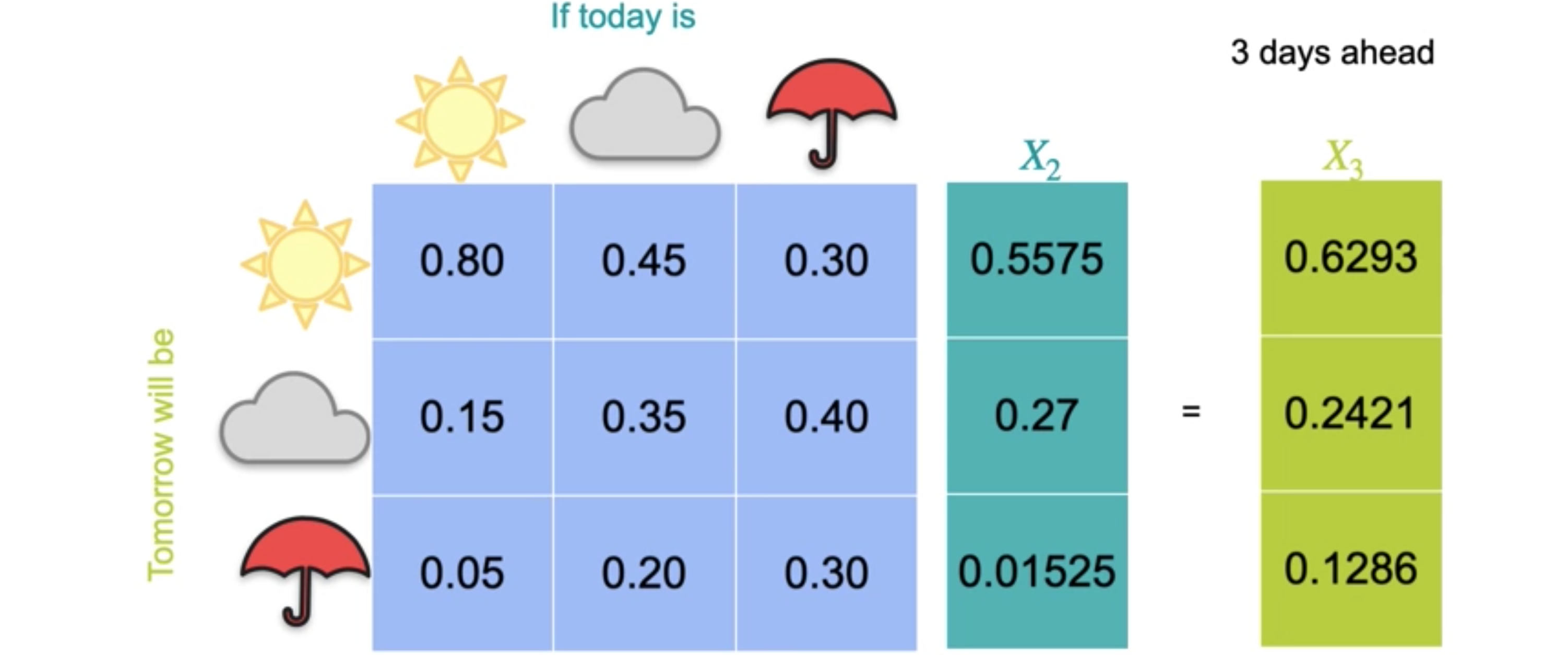
您可以继续执行此过程以找到未来三天的预测。这个预测的晴天概率为0.6293,多云概率为0.2421,下雨概率为0.1286。
现在,再次重复此过程以找到未来四天、五天的预测。请注意,状态之间的变化越来越小。对于未来六天,您现在有0.6665、0.2223和0.1112)是同一向量的1倍。这意味着1是与其相关的特征值。一旦达到这个向量状态,您就再也无法移动到其他任何地方,因为它是一个特征值为1的特征向量。这个矩阵通常称为过渡矩阵。
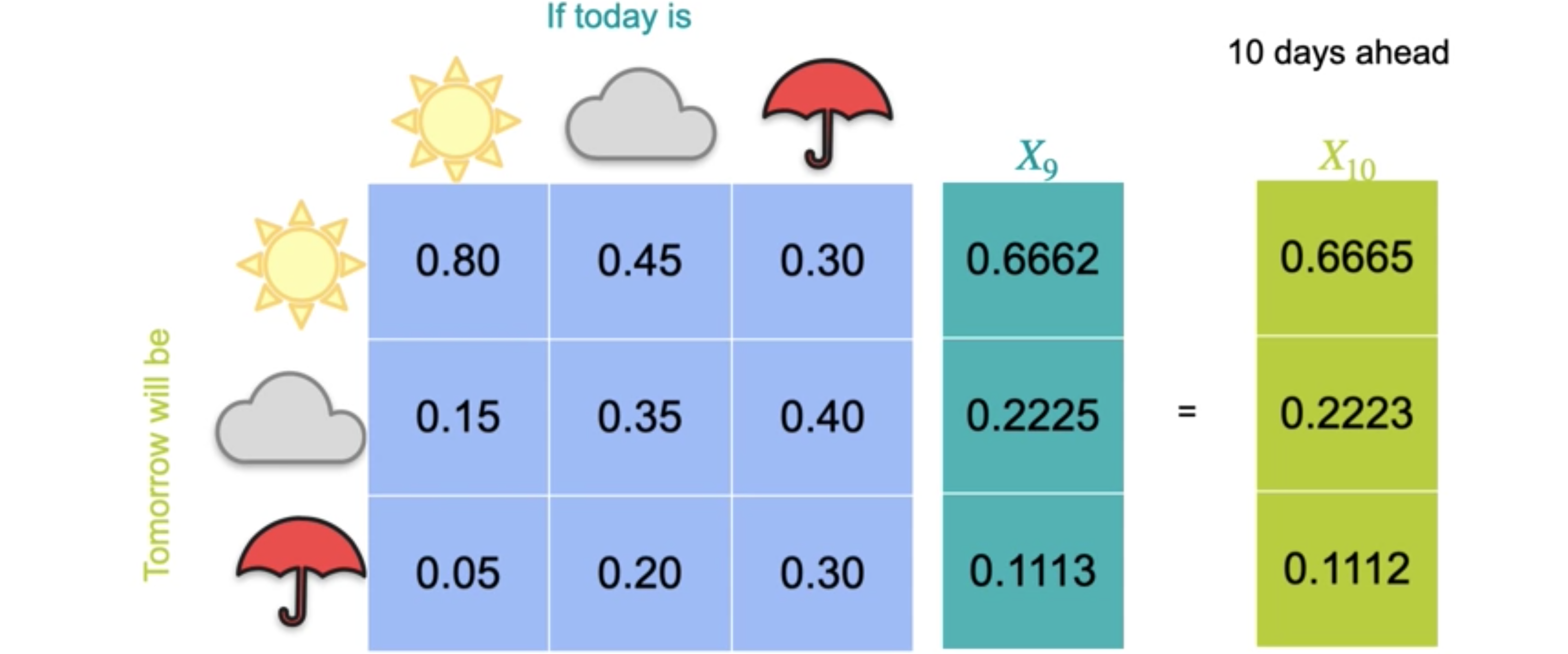
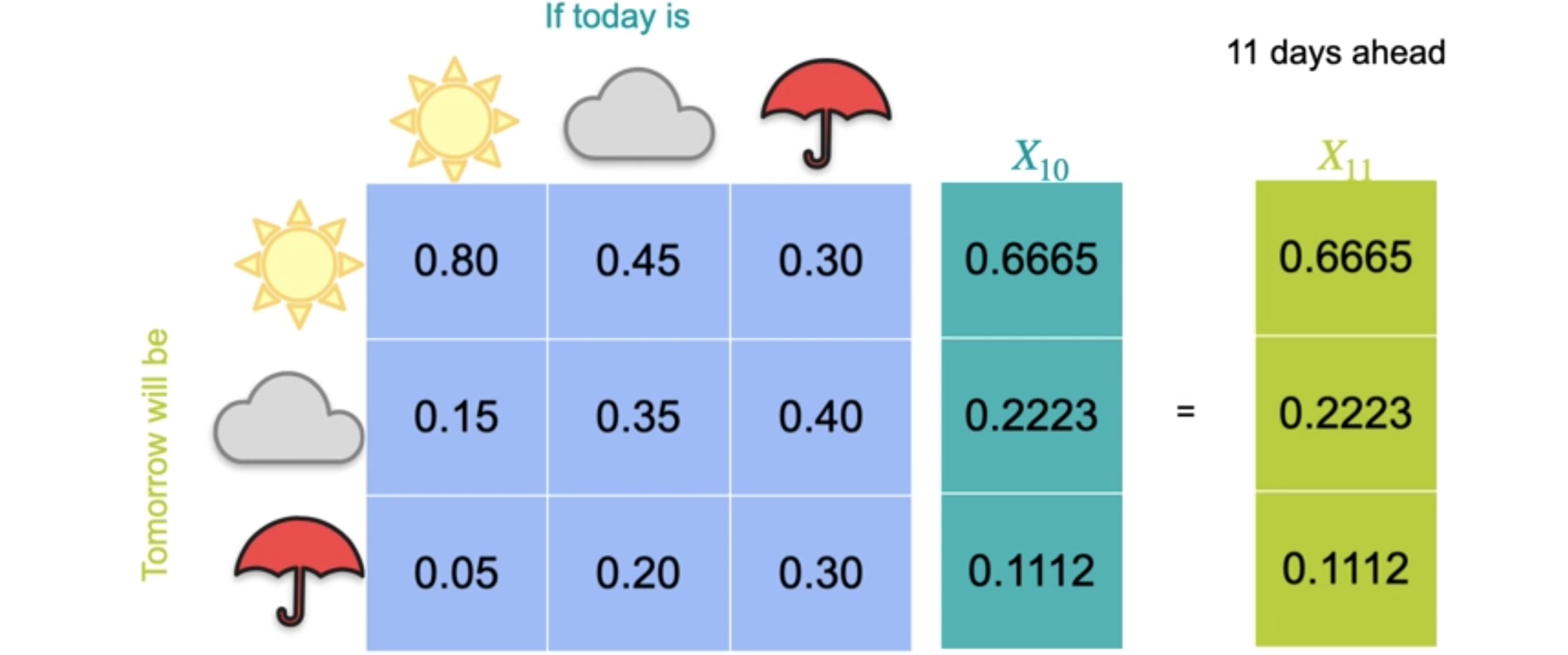
请记住,为了使此方法有效,转移矩阵必须是一个马尔可夫矩阵,每列由非负值组成,这些非负值的总和为1。此矩阵通常称为转移矩阵。此向量称为平衡向量,它提供在给定日期是晴天、多云或下雨的长期概率。它的妙处在于,无论您的初始状态如何,在无穷大的极限下,都会达到此平衡状态。它也是转移矩阵的特征向量。