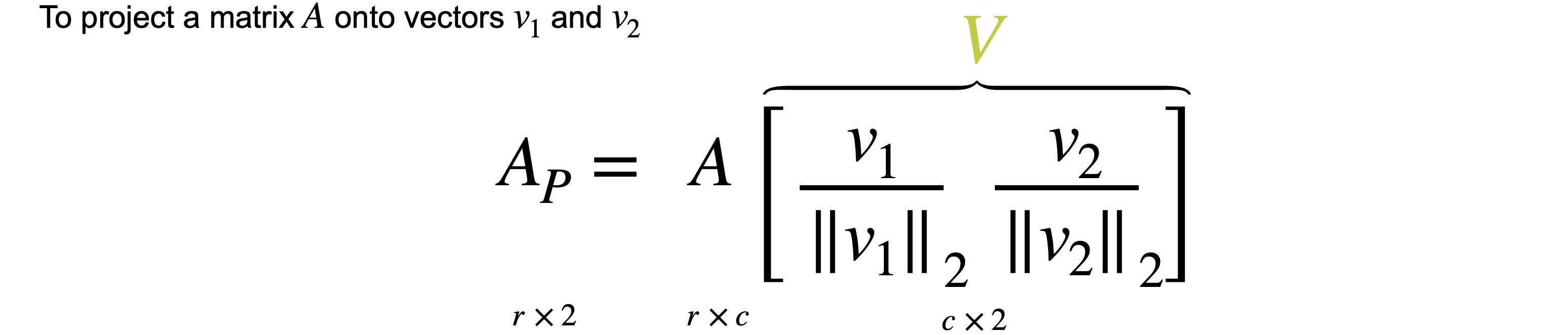数据科学 — 数学(三)(机器学习)
线性变换
线性代数—张成
一组向量的张成(span)就是沿着这些向量的方向以任意组合移动到达的点的集合。例如,您已经看到这两个向量的张成(span)是平面,因为您可以通过沿着这两个方向移动到达平面上的任何点。同样,这两个向量的张成(span)也是平面。到达这些点可能需要一段时间,但可以只使用这两个方向。然而,这两个向量并不跨越平面。因为正如您之前所看到的,并非每个点都可以通过沿着这两个方向移动到达,它们是同一个方向。它们跨越哪一侧?那么这条线上的任何一点都可以通过沿着向量的方向移动到达,因此这两个向量的张成(span)就是那条线。
两个相隔180度的向量呢?那么张成(span)包含它们的线,因为您可以通过沿着这两个方向移动到达该线上的每个点。这个向量的张成(span)是多少?张成(span)就是包含它并通向原点的线,因为那是你沿着那个方向行走可以到达的点的集合。这里有一个问题。这两个向量是否构成这条线的基?你怎么看?答案实际上是否定的。原因是基需要是一个最小生成集。这里有太多的向量。看看这两个向量中的任何一个都跨越这条线,所以这两个向量太多了。基是一个最小生成集,所以它们中的每一个都是基。但是它们两个不是基。它们是生成集,那是这条线的基。事实上,任何从原点开始并朝着同一方向的向量也是这条线的基。
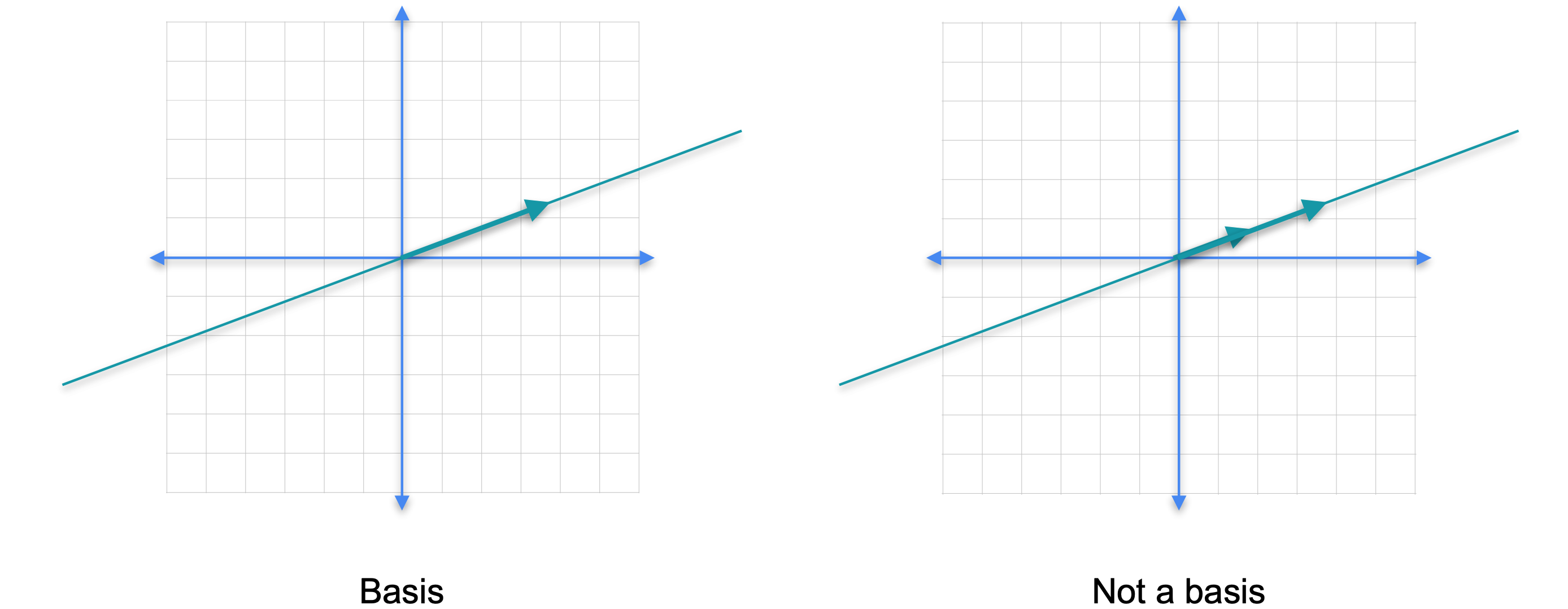
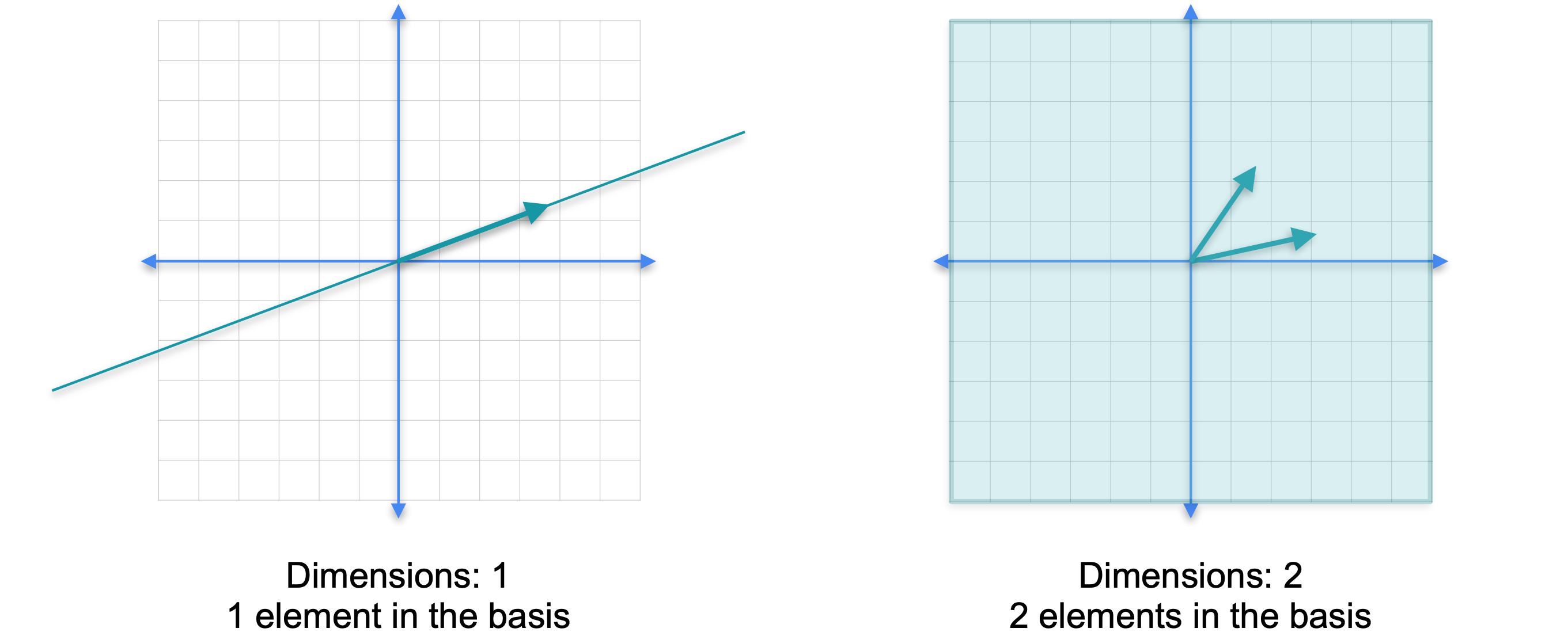
总之,基是一个最小生成集,所以左边的向量构成了这条线的基。但这两个向量不是,因为它们太多了。这种情况也发生在高维空间中。我们来看看这个集合。这个集合构成了平面的基,因为它跨越了平面,因为我们可以通过沿着这两个方向行走到达任何一点。但是如果我们移除其中任何一个,它们就不再跨越平面,现在它们只跨越一条线。然而,这组向量并不构成平面的基。它们跨越平面,因为平面上的任何一点都可以通过沿着这三个方向的组合移动到达。但它们太大了,不能成为基。这三个向量中的两个子集都是基,但第三个是多余的,所以它不是基。现在注意一些有趣的事情,基的长度是平面维度的空间。空间基的长度就是该空间的维度。左边的线有一个长度为1的基,它的维度为1,因为线的维度为1。右边的平面有一个长度为2的基,由两个向量组成,平面的维度为2。意味着任何空间的任何基实际上都具有与其他基相同数量的元素。例如三维空间,想象一下那里的基会是什么样子。现在你已经对基有了很好的直觉,让我们看看正式的定义。
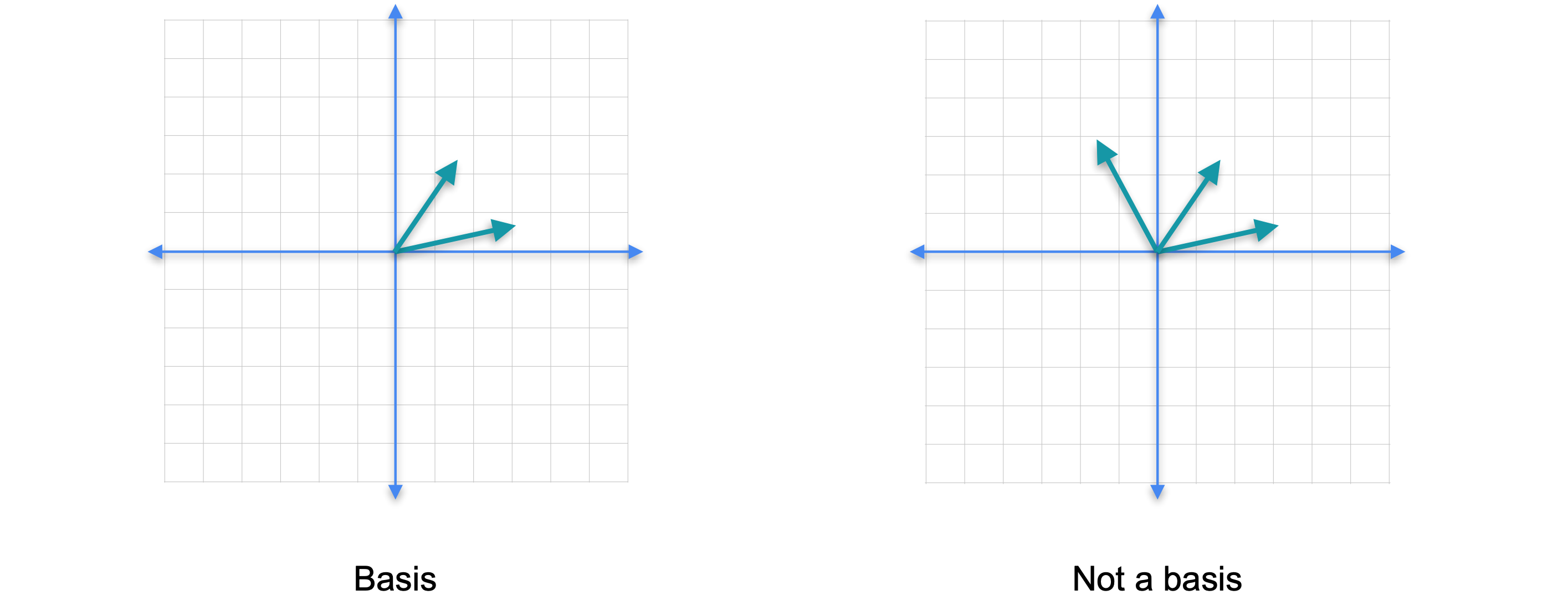
我们需要引入线性无关和线性相关向量的概念。如果一组向量中没有一个向量可以作为其他向量的线性组合获得,则该组向量被称为线性无关的。如果你只考虑平面中的一个向量,它总是线性无关的。现在让我们添加另一个向量。请注意,你不可能将新向量作为第一个向量的线性组合,因为它们指向不同的方向。这两个向量仍然是线性无关的。如果你添加另一个向量会怎么样?在这种情况下,红色的新向量指向与绿色向量相同的方向,但它的长度只是原始向量的2倍。由于一个向量可以通过其他向量的线性组合获得,因此这组向量称为线性相关。还要注意,即使我们在集合中添加了一个新向量,这些向量的张成(span)也不会改变,它仍然是一条直线。
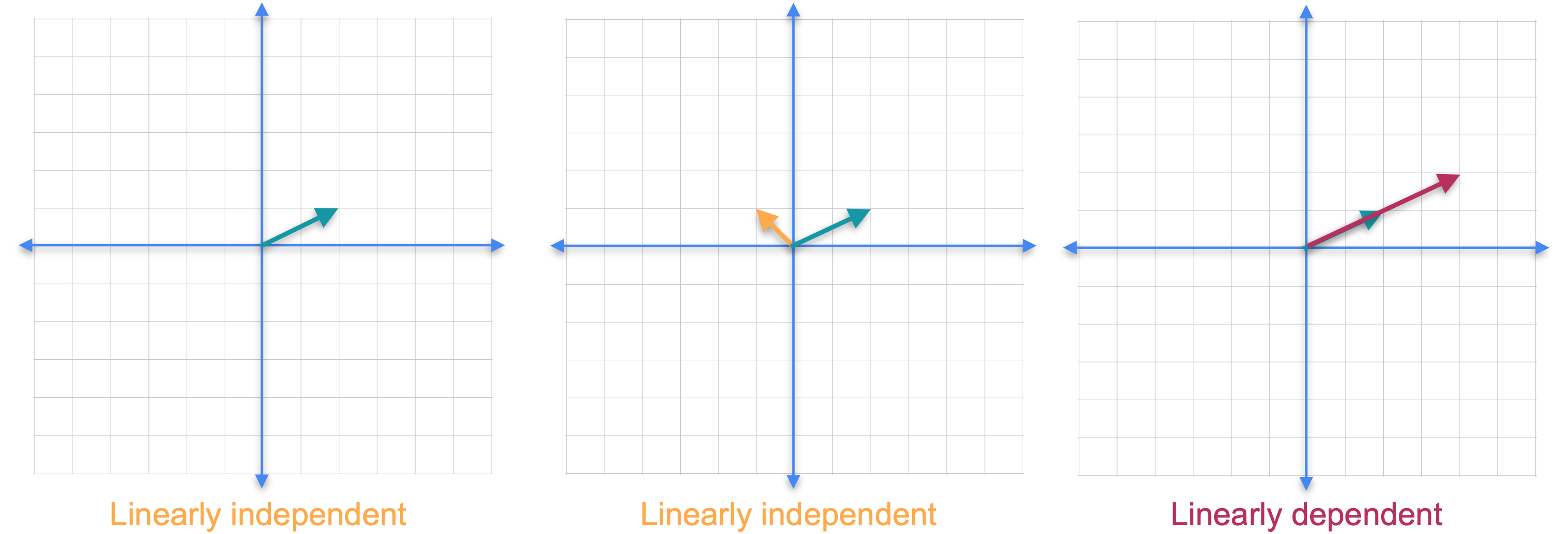
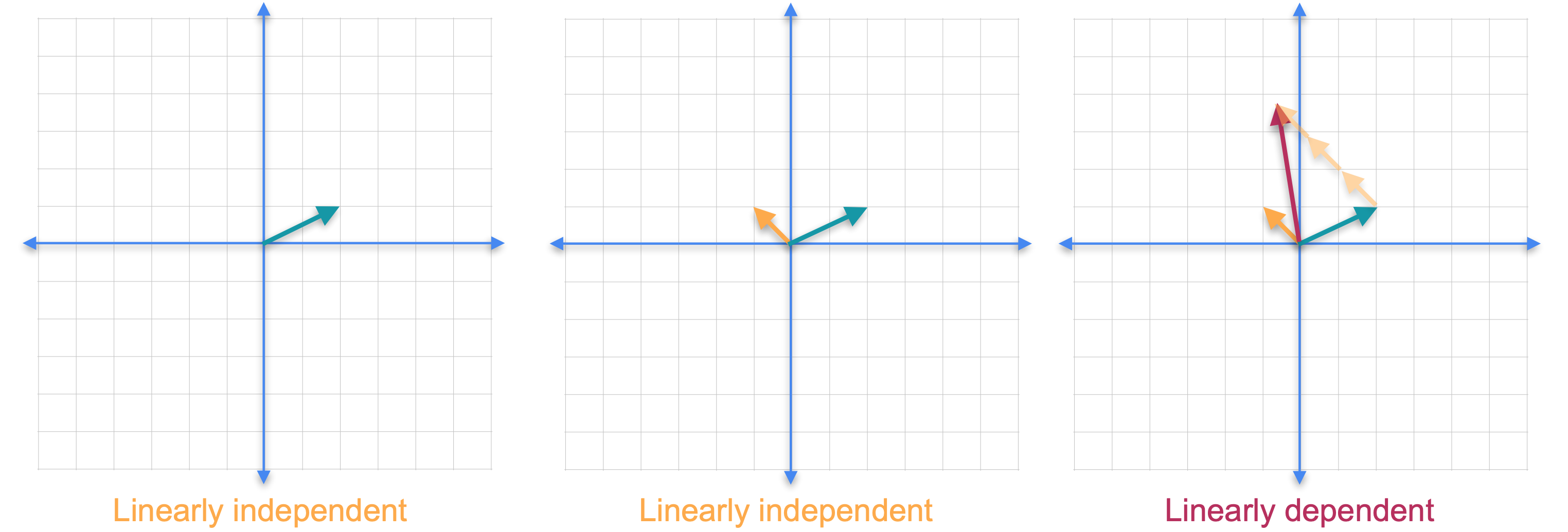
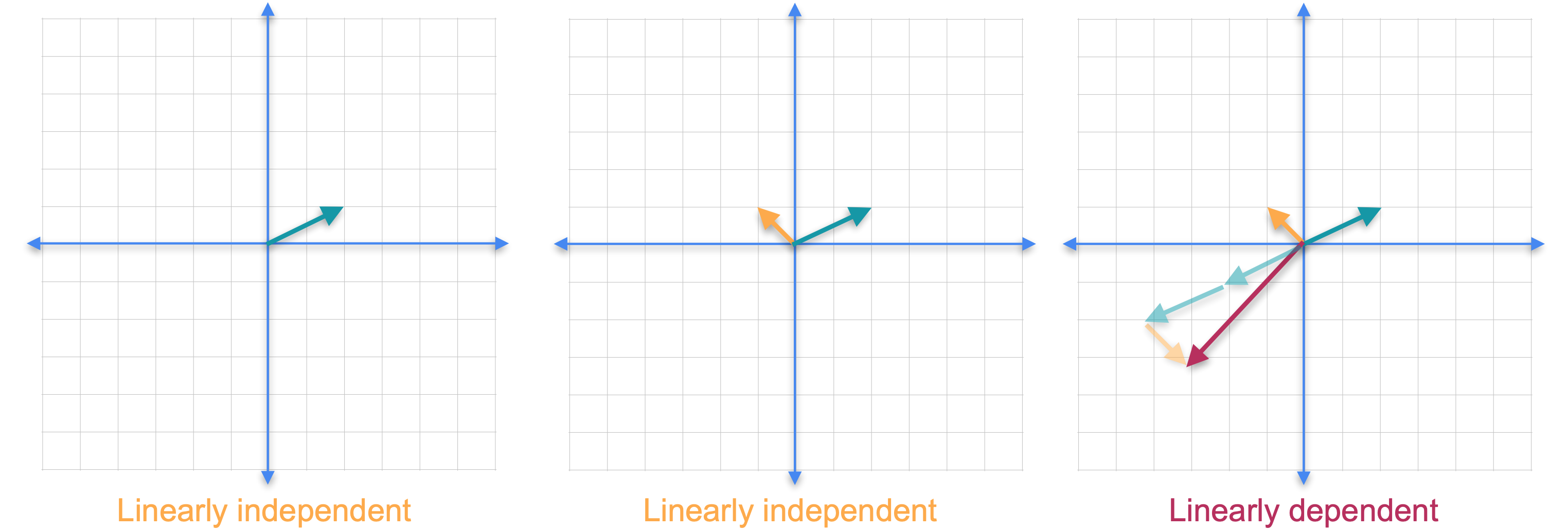
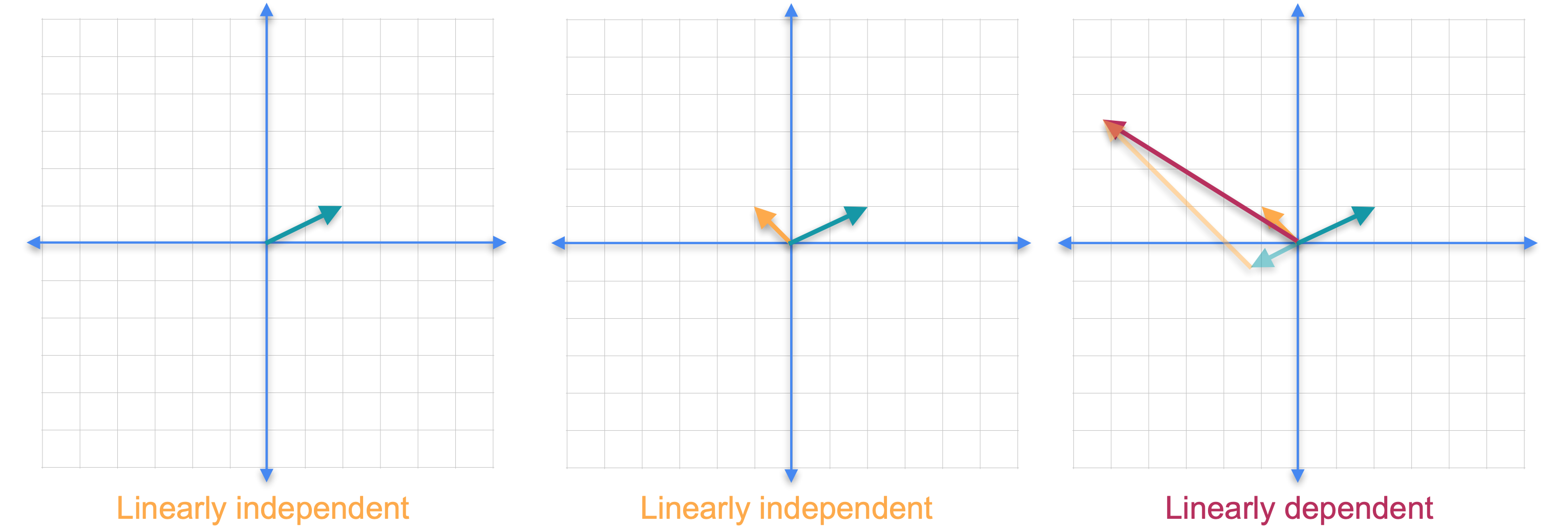
现在让我们看一个不同的例子。这次我们保留线性无关的橙色和绿色向量,并添加第三个红色向量。虽然这两个向量都不是其他向量的倍数,但它们不再独立。这是因为你可以通过将绿色向量的1倍与橙色向量的3倍相加来获得第三个向量。可以肯定的是,我们再次向集合中添加了一个新向量,但是向量的跨度没有改变,它们仍然只跨越平面。事实证明,您添加的任何其他向量都可以写成前两个向量的线性组合。这个结果一般成立。如果您拥有更多向量并且您尝试跨越的空间维数,那么您将始终拥有一个线性相关的组。这意味着在平面中有三个或更多向量,或者在三维空间中有四个或更多向量,等等。让我们看看如何检查集合是否线性相关。我们将橙色向量称为(-1,1)。(2,1)。最后,(-5,3)。要看出向量集是线性相关的,您需要找到满足
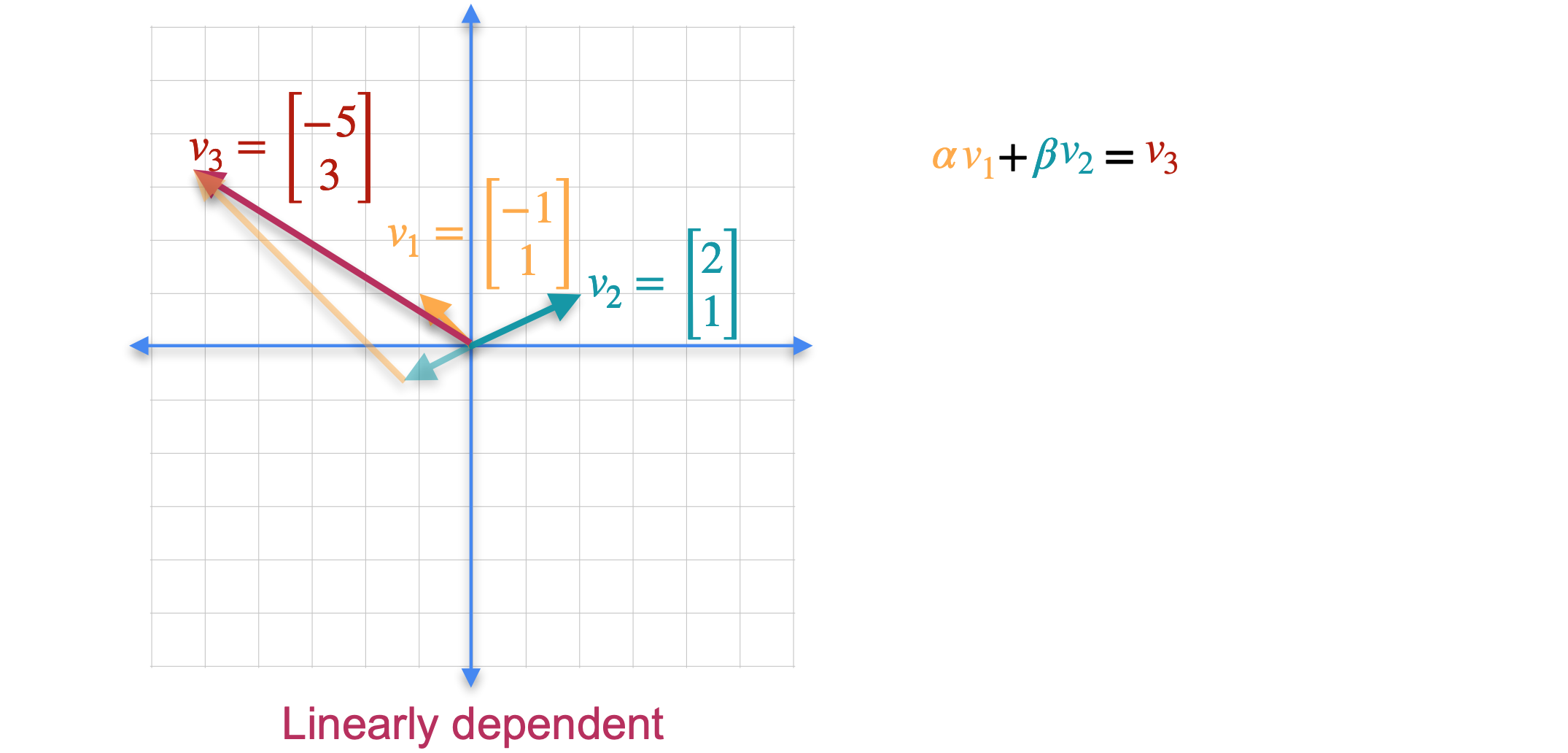
这产生了有两个未知数的两个方程,1和2。如果将方程1和2相加,则会得到2中使用这个结果,您会得到

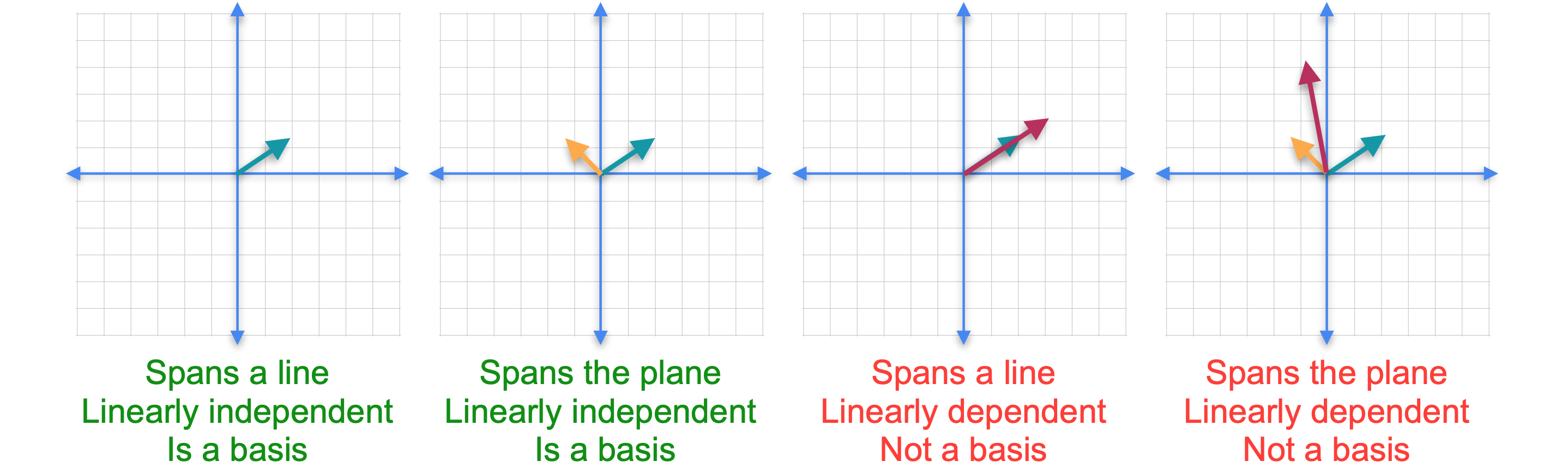
现在我们来做个测验。我会给你三个向量,你告诉我这些向量是否是线性无关的。实际上它们不是,因为第一个向量乘以1加上第二个向量乘以-1等于第三个向量。事实上它们是线性相关的。但是如果你移除这三个向量中的任何一个,那么你就会得到一个线性独立的集合。但是由于每个线性独立集合只有两个向量,并且它们存在于三维空间中,因为它们有三个坐标,所以这些都不是三维空间的基。从几何学上讲,意味着如果你在三维空间中绘制这三个向量,它们都将位于同一平面内。现在你已经看到了一些线性独立的例子,让我们回到基的定义。基是满足两个条件的一组向量。该集合必须跨越一个向量空间,并且该集合中的向量必须线性独立。回到您之前看到的示例,前两个跨越一条线或一维空间,以及一个平面或二维空间,它们是线性独立的,因此它们构成一个基。后两个是线性相关的,它们不构成基。正如我们在这两个示例中看到的,并非所有n个向量的集合都会构成n维空间的基。
特征概述
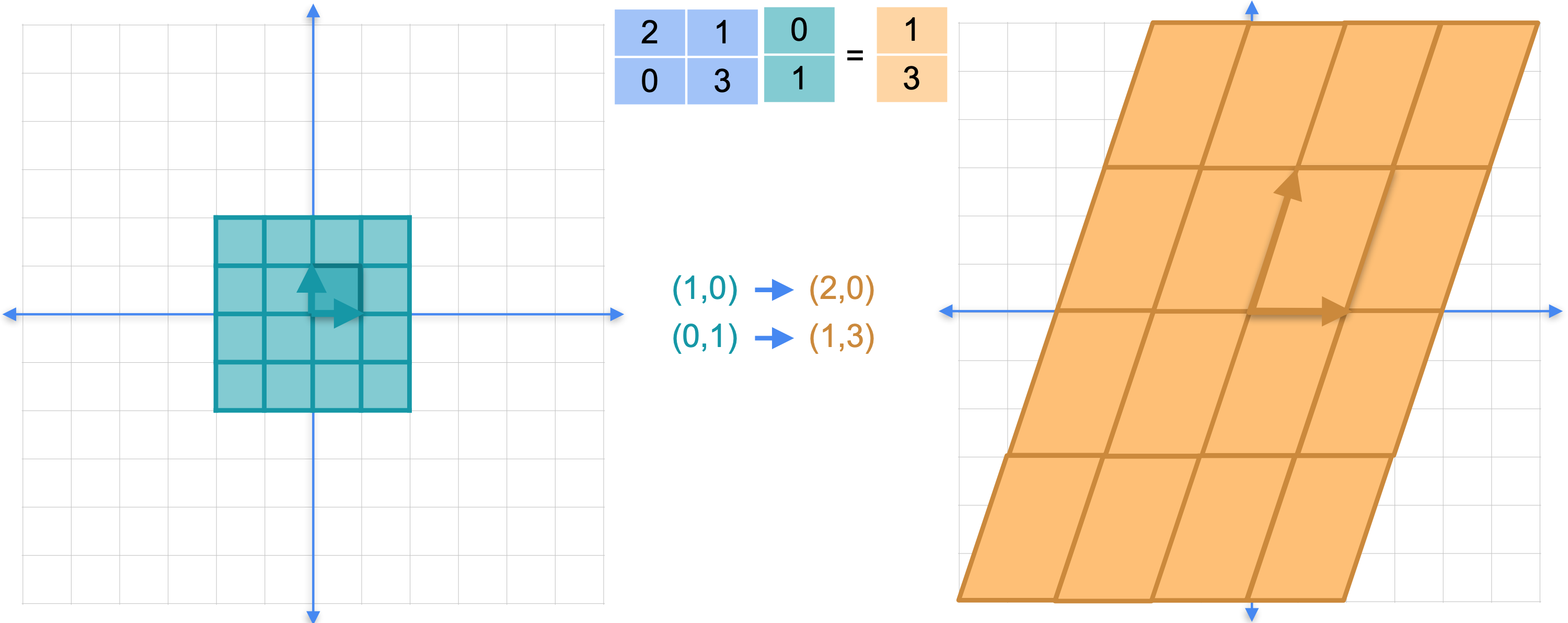
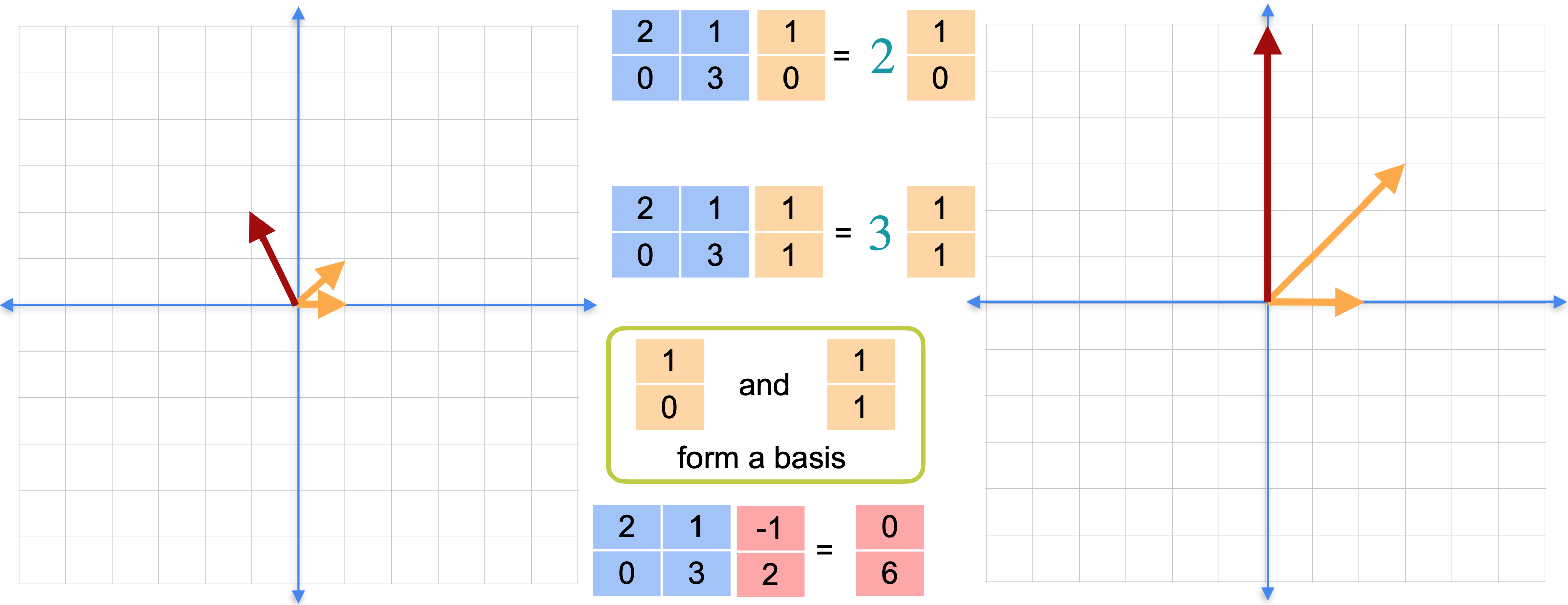
有一种基(basis)可以统领所有基(basis),称为特征基。特征基非常有用,特别是在机器学习应用中,例如我们之前提到的主成分分析(PCA)。特征基的工作原理如下。让我们看一下矩阵(1,0),当您将其乘以矩阵时,您会看到它得到向量(2,0)和向量(0,1),当您将其乘以矩阵时,您会得到向量(1,3)。如下图所示,左边的这个正方形变成右边的这个平行四边形,平面的其余部分也随之改变。这也被称为坐标变换或基变换。从左侧的正方形坐标移动到右侧的平行四边形坐标。
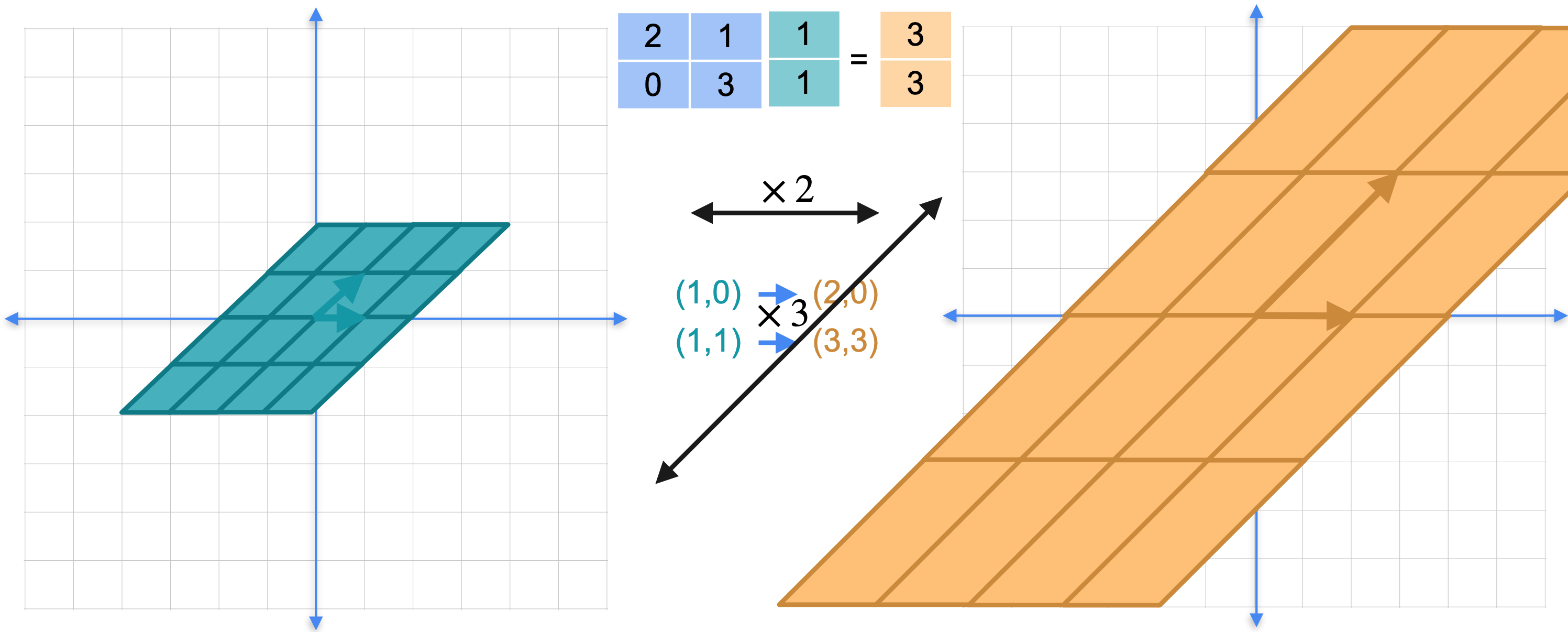
正方形的选择非常随意。实际上选择一个不同的基,看看会发生什么。再次选择向量(1,0),它指向向量(2,0)。作为该基的第二个元素,选择这个向量(1, 1)。它指向向量(3, 3)。这个平行四边形指向这个平行四边形。这里有什么特别之处?请注意,两个平行四边形的边与另一个基中相应的边平行。平面的其余部分也随之平行。因为这些点是平行的,所以我们对平面所做的就是在这个方向(水平方向)拉伸2倍,在这个对角线方向拉伸3倍。这是一个非常特殊的基。它只包含两个拉伸。这就是所谓的特征基。这是观察线性变换的一种非常特殊的方式,相对于一个基,将一个平行四边形移动到到另一个平行四边形,其边与原始平行。
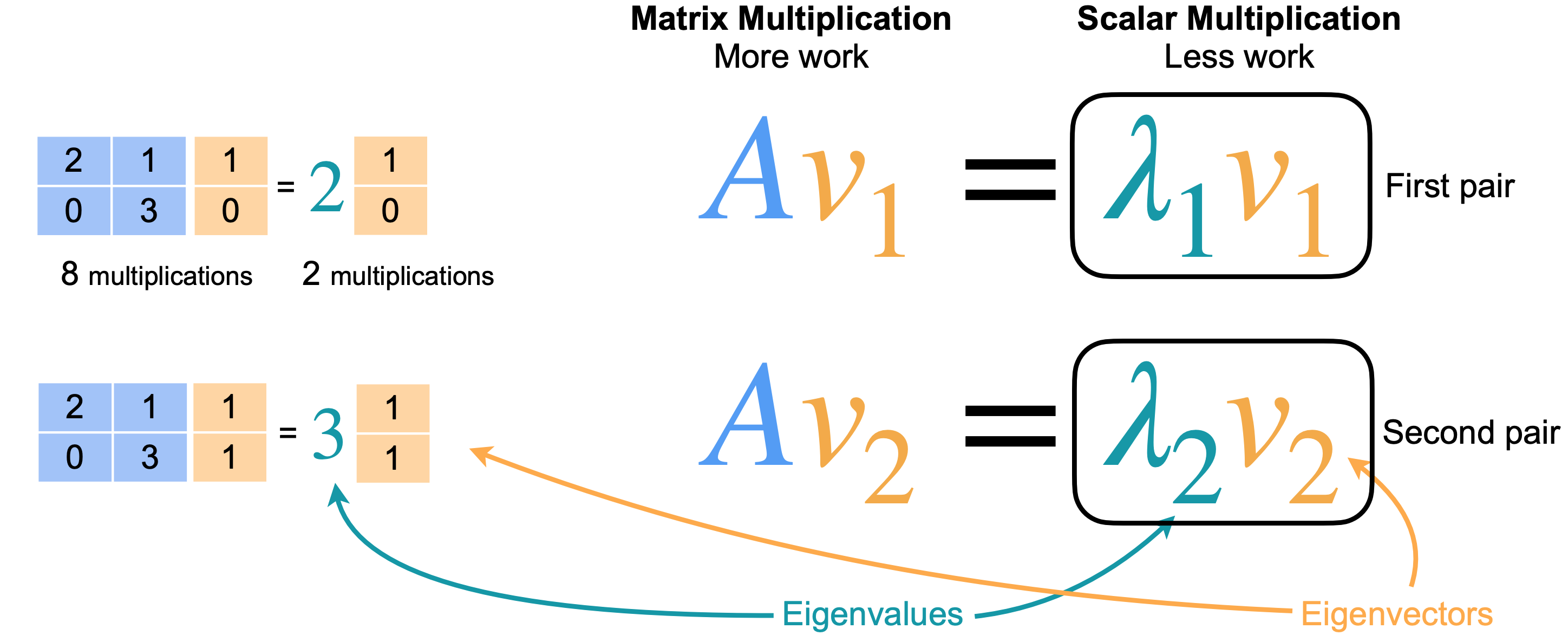
为什么这很有用?假设你想找到点(3,2)的图像。你可以将其乘以矩阵并得到(8, 6)。但你也可以将该点表示为基中元素的组合。这是什么意思?我们利用拥有的两个方向找到一条到达该点的路径。现在线性变换对应于将水平向量拉伸2倍,将垂直向量拉伸3倍。这确实简化了线性变换。它只包含两次拉伸。基中的两个向量将被称为特征向量,拉伸因子2和3将被称为特征值。特征值和特征向量在线性代数中非常重要,因为它确实简化了计算。
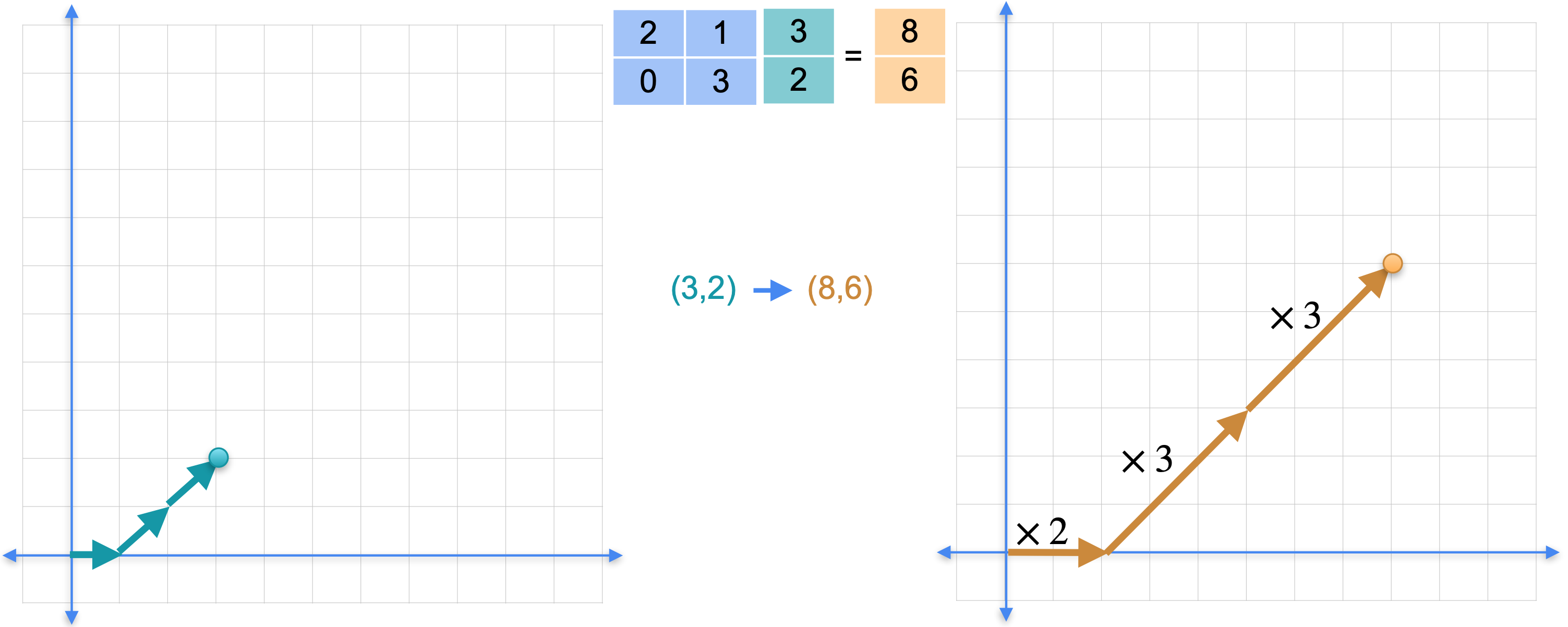
特征值和特征向量
为什么特征值和特征向量如此特殊。我将把矩阵(1,0)是特征向量。变换后,它变为(2,0)。请注意,向量仍然指向同一方向。原始向量(1,0)的2倍。第二个向量(1,1)也是特征向量。变换后,它变为(3、3)。同样,它指向同一方向,因此可以将结果写为原始向量的3倍。最后一个向量(-1,2)不是特征向量。变换后,它变成了向量(0,6)。注意,它不再指向同一方向,而且没有常数可以与原始向量相乘来得到最终的向量(0,6)。
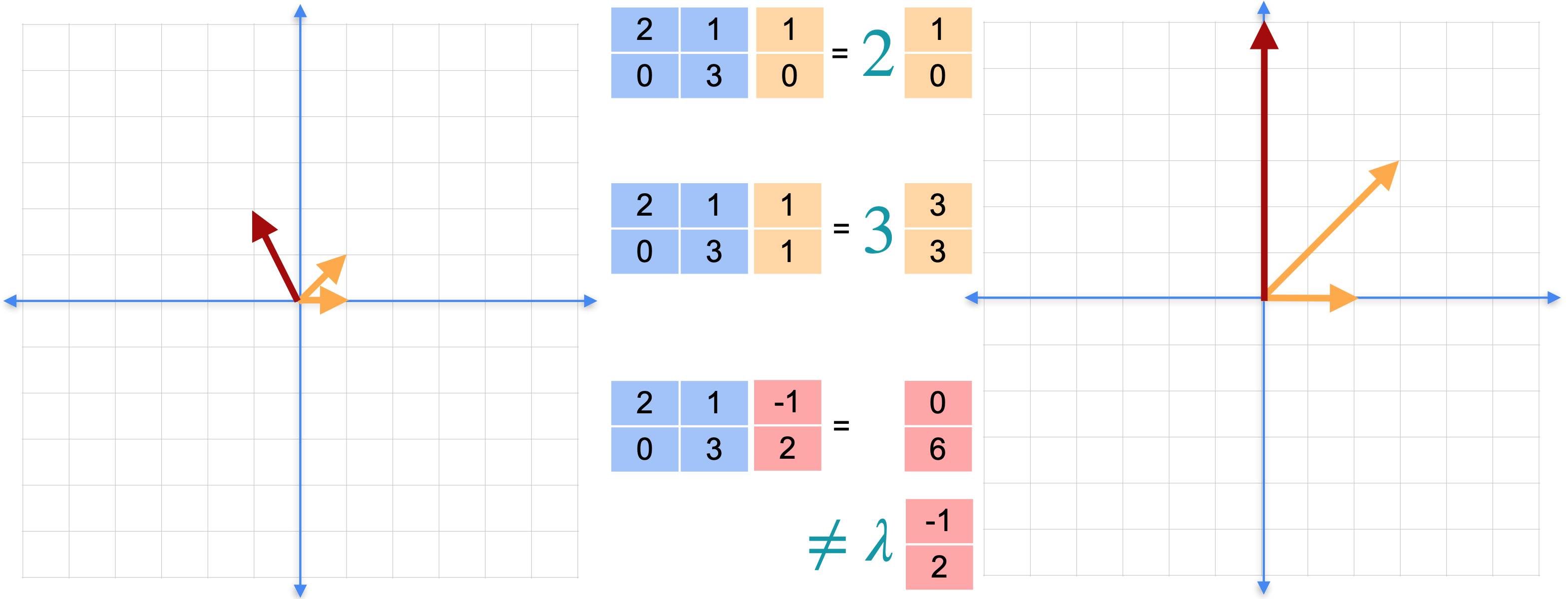
将这里的矩阵称为(1,0),而2。第二个方程定义为(1,1),标量为3。8次乘法,而右边只需要2次乘法。对于具有数百或数千列的矩阵,差异将变得非常大。这个等式的意思是,至少沿着矩阵特征向量,你可以将一个大计算变成一个小计算。
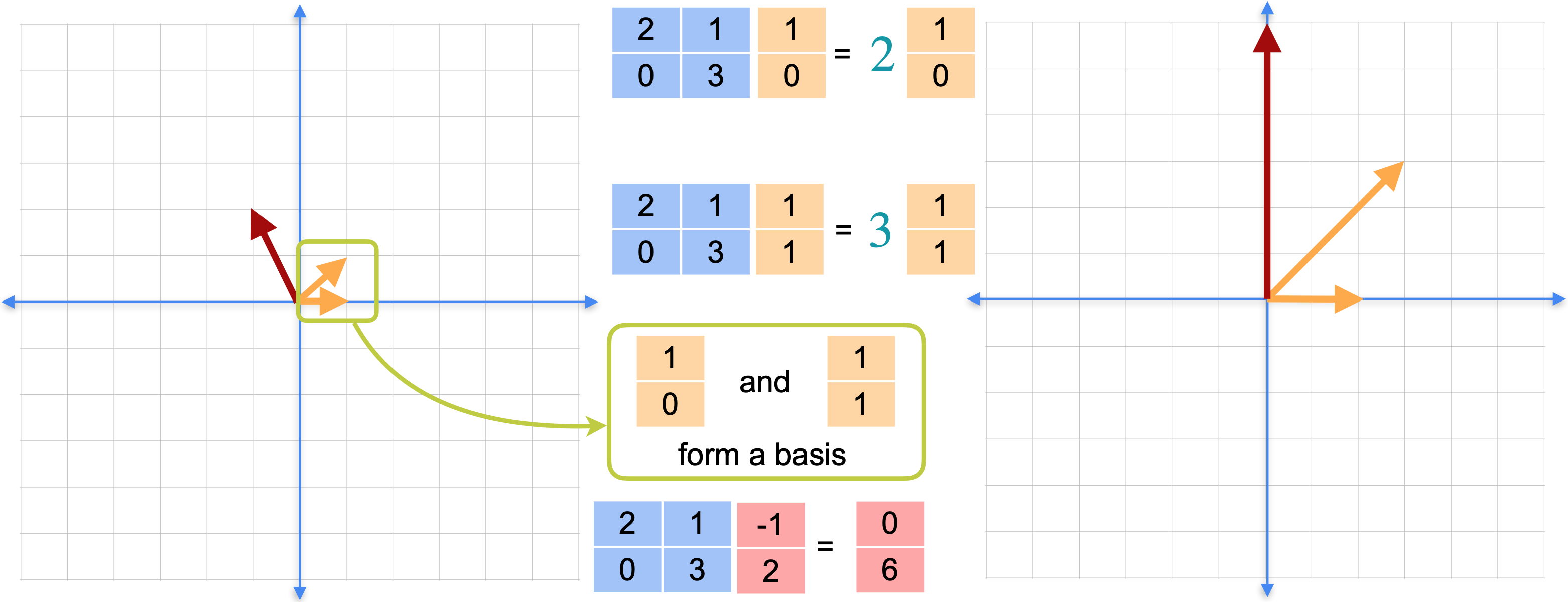
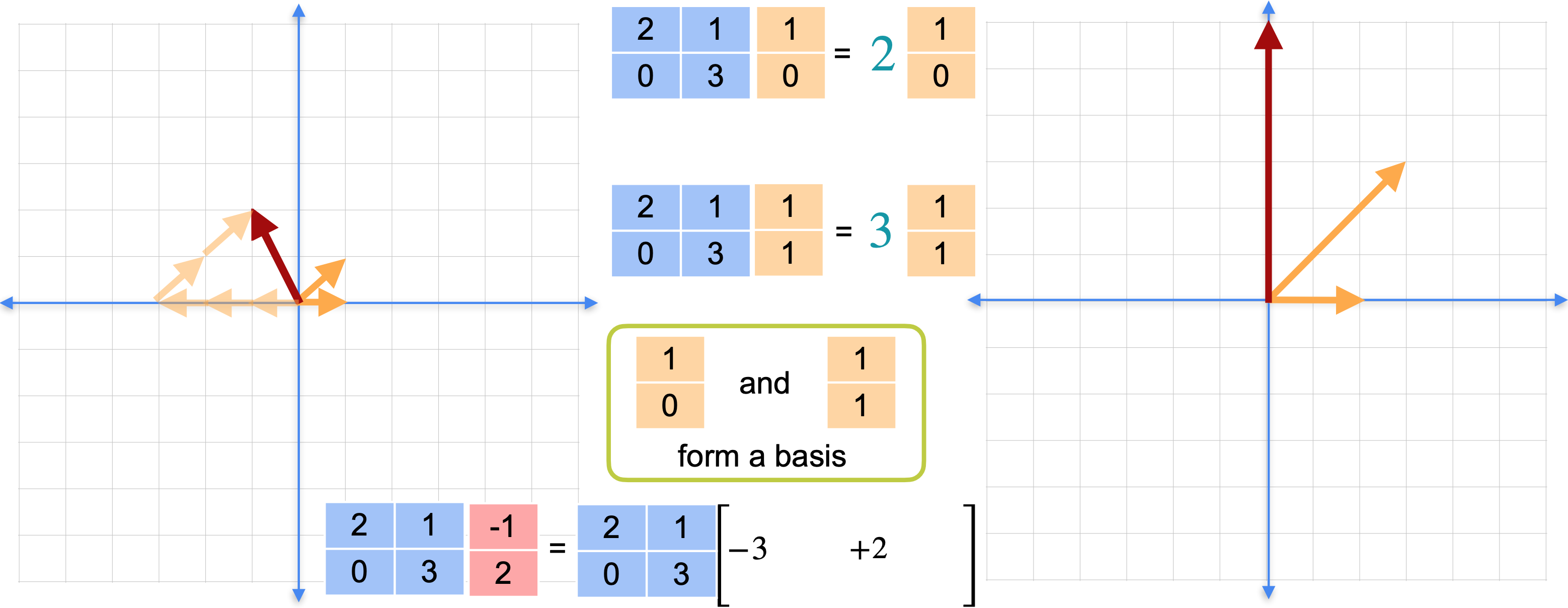
如果使用基,实际上可以在任何地方使用这个快捷方式。如下图所示,红色向量不是特征向量。你只需要像平常一样完成矩阵乘法。但是,这两个特征向量(1,0)和(1,1)是线性无关的,并且跨越平面,因此它们形成一个基。这实际上是矩阵(1,0)和(1,1)形成一个基,那么你可以将向量(-1,2)写成这些基向量的线性组合。在这种情况下,它是(-1, 2)替换为(-1,2),重写为基向量的线性组合。将矩阵乘法移到括号内,并将-3和2向前移动。此时,您就可以使用特征向量快捷方式了。如下图所示,您已经计算了这些矩阵乘法,可以像这样替换标量乘法。(0,6)。即使红色向量是特征向量,你也能够解决这个线性变换,而无需进行任何矩阵乘法。你只是在整个过程中使用了标量乘法。还记得之前,红色向量相对于特征基(-3,2) 的坐标。但一般来说,获取这些坐标实际上需要大量的工作。但要做到这一点,对于平面上的每个点,你都需要计算特征基的逆,然后将该逆乘以红色向量。或者换句话说,这需要做很多工作,甚至需要进行矩阵乘法。
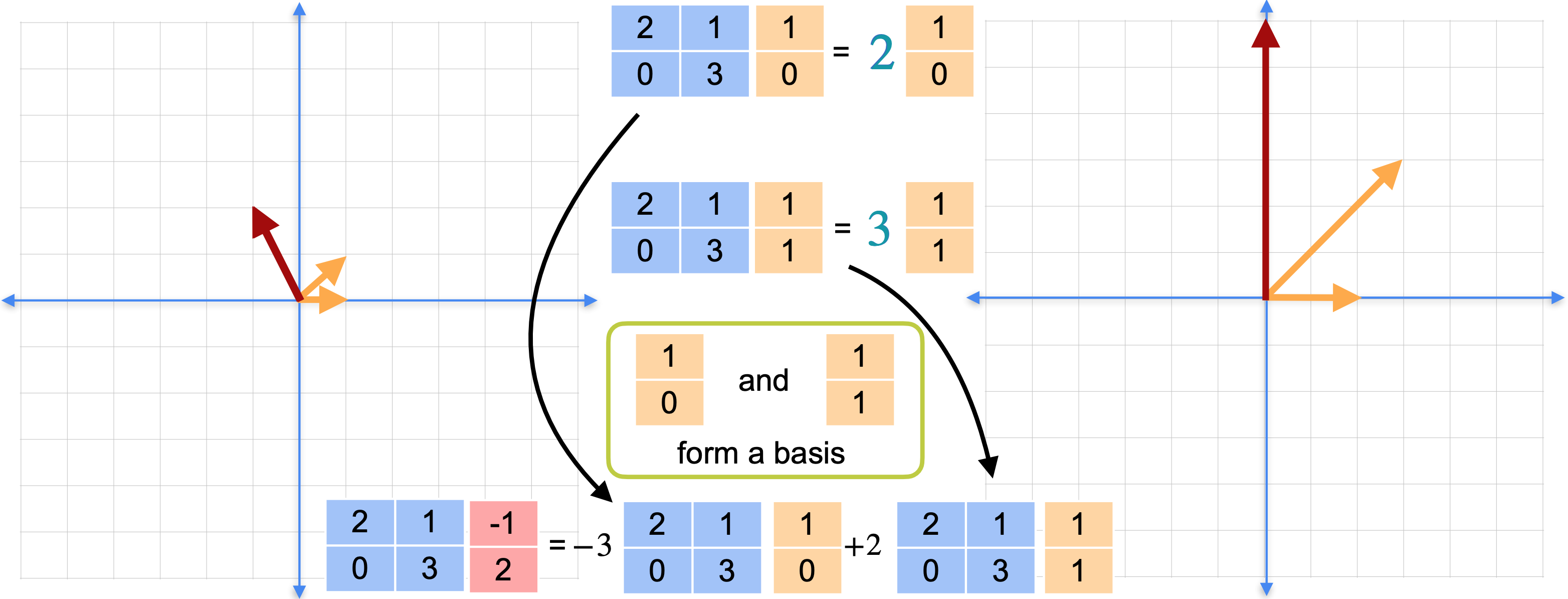

在某些机器学习应用中,提前计算这些坐标是值得的,这样当需要应用转换时,你可以更快地完成。它们的特征在于,对于每对特征向量和特征值,方程
计算特征值和特征向量
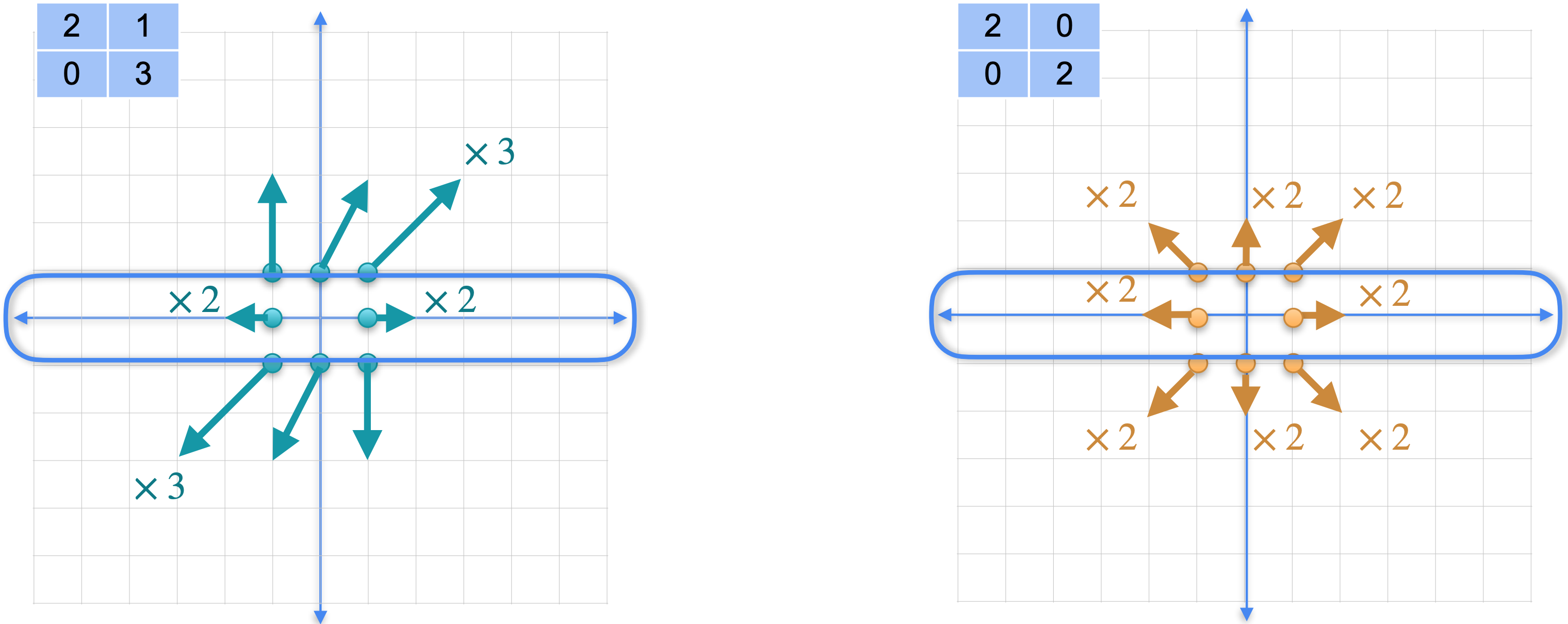
首先,看一下矩阵2倍,对角线被拉伸了3倍。对于其他点,情况也是如此。与另一个矩阵进行比较,该矩阵只是将整个平面在任何方向上拉伸3倍。矩阵3倍。这两个变换不是同一个变换,但它们在许多点上确实重合。换句话说,它们对无限多个点的作用完全相同。更具体地说,在这个对角线上,这两个变换做完全相同的事情。
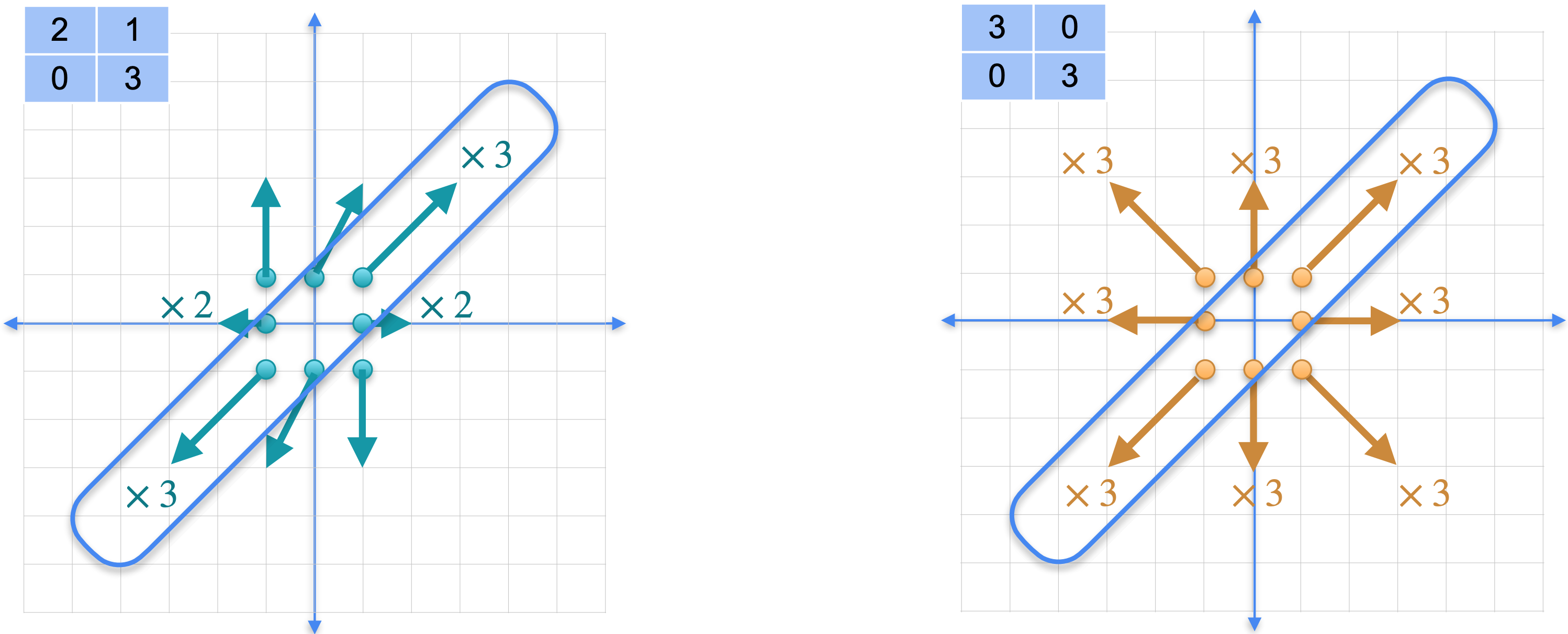
它们在无限多个点上匹配。这很奇怪,变换应该只在一个点匹配,即点(0,0)。当它们在无限多个点匹配时,就会发生一些非奇异的事情。发生了什么?让我们看看区别。如果这两个变换在无穷多个点上匹配,意味着在无穷多个点上的差异为0。如果将这两个矩阵的差异应用于这些对角线上的任意向量,则会得到向量(0,0)。换句话说,这个矩阵乘以向量(0,0)。这就是奇异变换的特征。回想一下,非奇异变换对方程矩阵乘以向量等于(0,0)有一个唯一解,那就是向量(0,0)。如果你有无穷多个解,意味着你的矩阵是奇异的,你可以验证这确实是一个奇异矩阵,因为行列式为0。
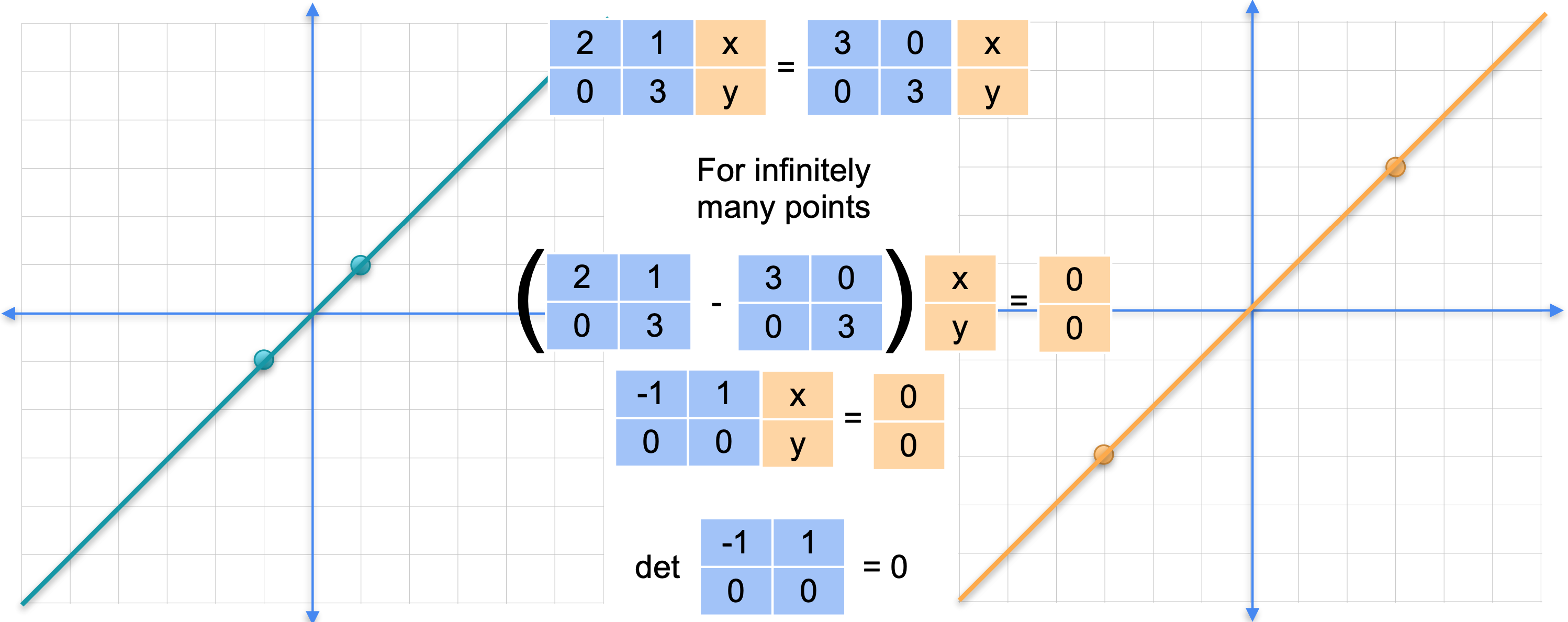
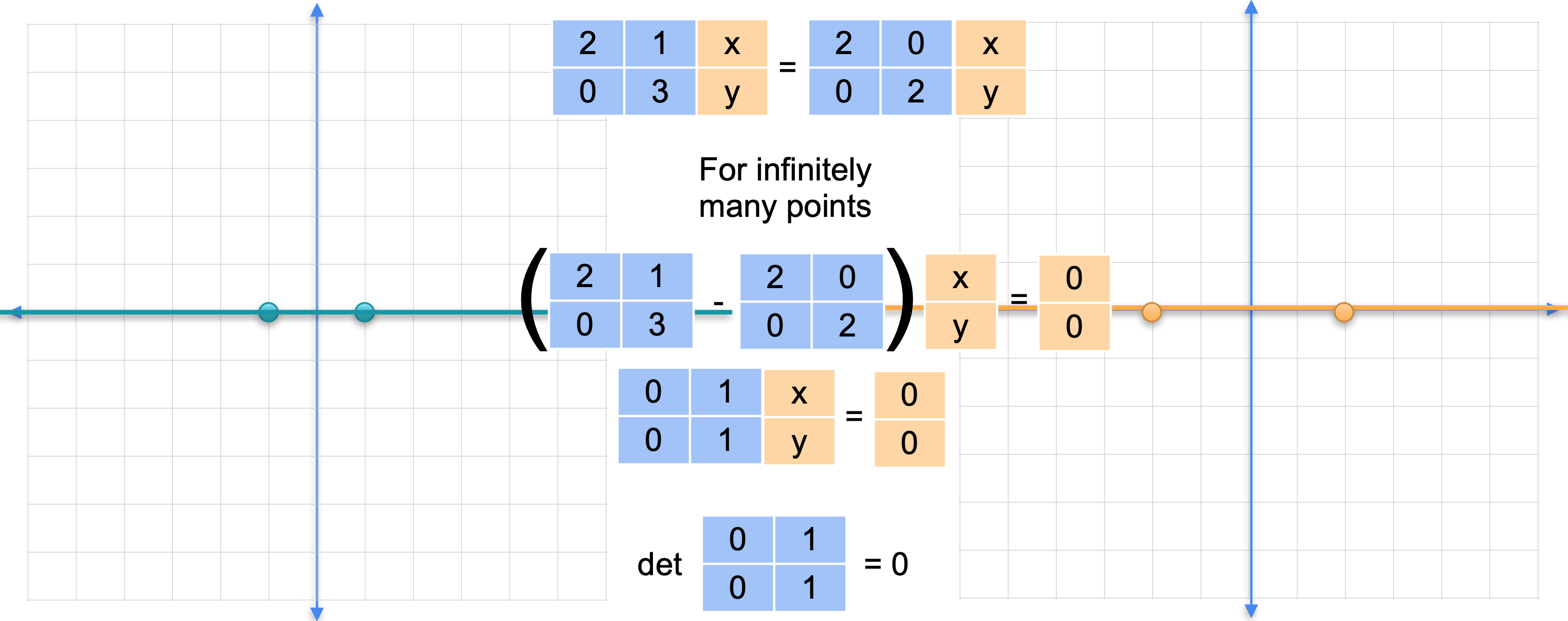
但对于右边的另一个变换。我们的变换与之前完全一样。将它与在每个方向上将平面拉伸2倍的变换进行比较。这两个并不相同,但它们在整条线上匹配。
左边的矩阵乘以(0,0)。这意味着矩阵2倍恒等矩阵之间的差值,是一个奇异矩阵。您可以检查它确实是奇异矩阵,因为它的行列式为0。
特征值有什么特别之处?如果(0,0),这是一个创建许多解的方程。因此,这个矩阵0,当我们展开它时,它的行列式由这个方程给出,这被称为特征多项式。基本上,要找到特征值0的地方就是特征值。在这种情况下,它们将是

现在你有了特征值,让我们找到特征向量。回想一下,特征向量是满足方程矩阵乘以向量等于特征值乘以向量的向量。如果我们展开它,我们会得到这些方程,它们的解是2。我们对3个特征值做同样的事情,求解这些方程并得到(1,1)对应于特征值3。
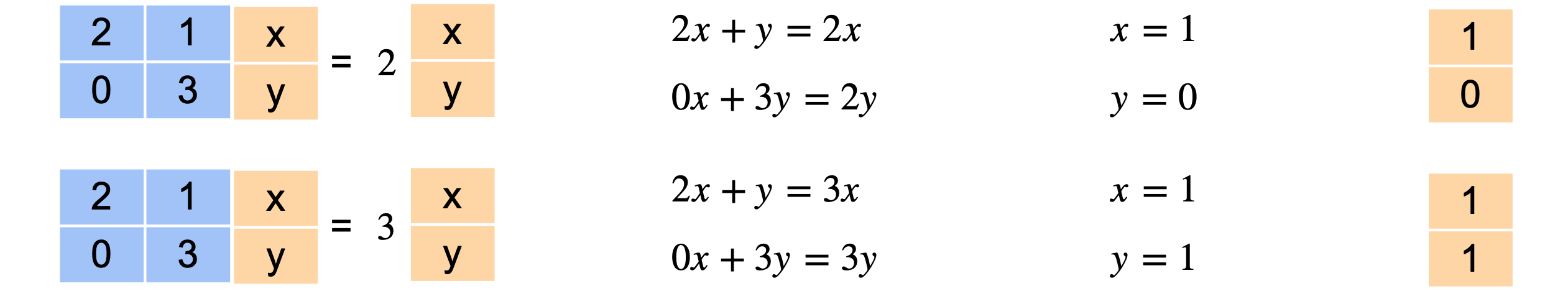
特征向量的数量
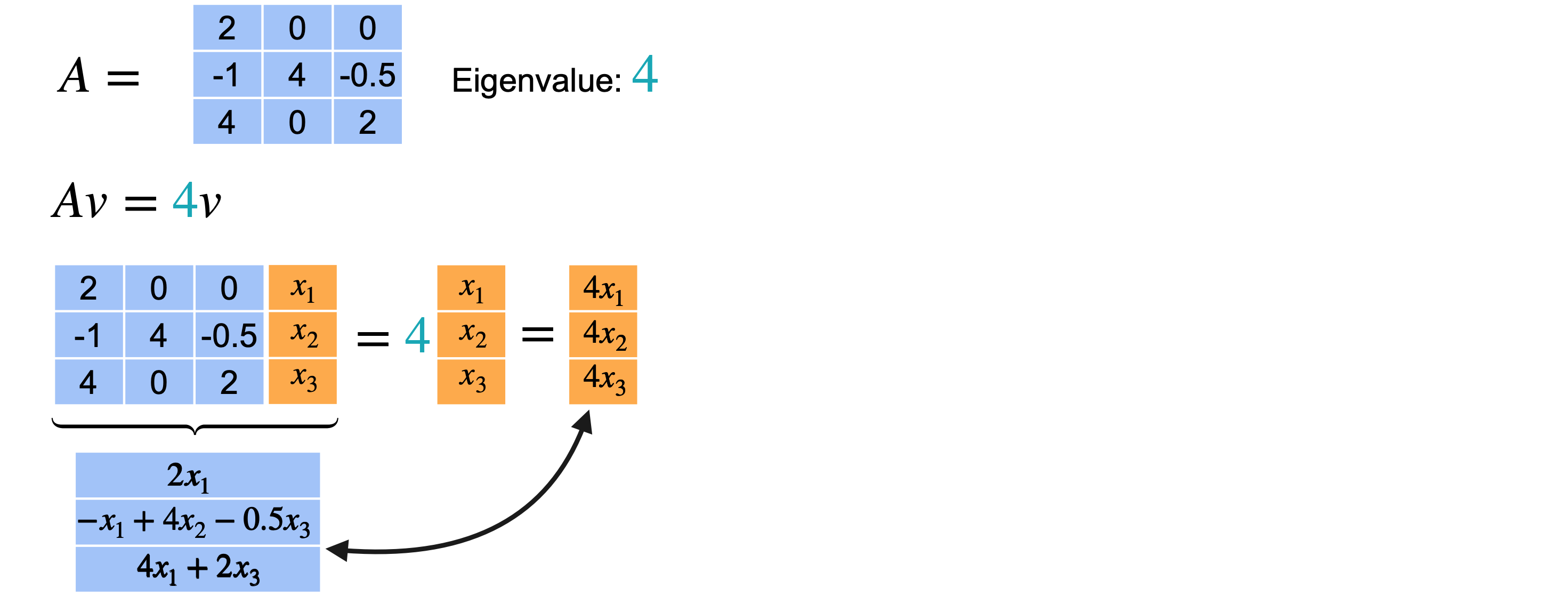
你有一个3个不同的特征值和3个不同的特征向量。难道所有3个特征向量吗?事实证明情况并非总是如此。让我们看一些例子。考虑这个(4,2,2)。

2重复了两次。现在看看当我们找到与它们相关的特征向量时会发生什么?让我们从特征值4开始。特征向量需要满足
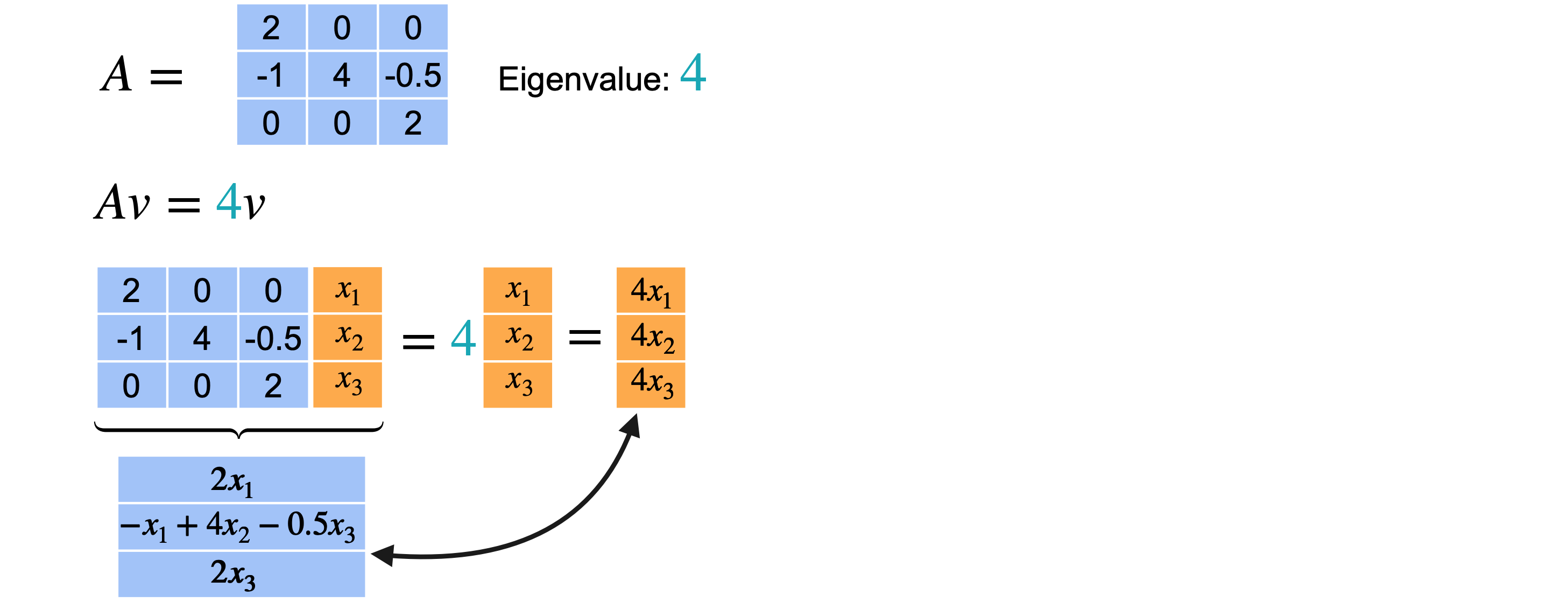
希望它等于向量4相关的特征向量(0,1,0)。现在让我们对特征值2重复上述步骤。向量2才能成为特征向量,从而给出向量(2,1,0)。但你也可以选择(1,1,2)。这两个向量指向不同的方向。所以实际上有两个不同的特征向量。请记住,您只关心特征向量的方向,因为它的任何缩放版本仍将是同一特征值的特征向量。值得一提的是,您可以根据2找到两个不同的方向。
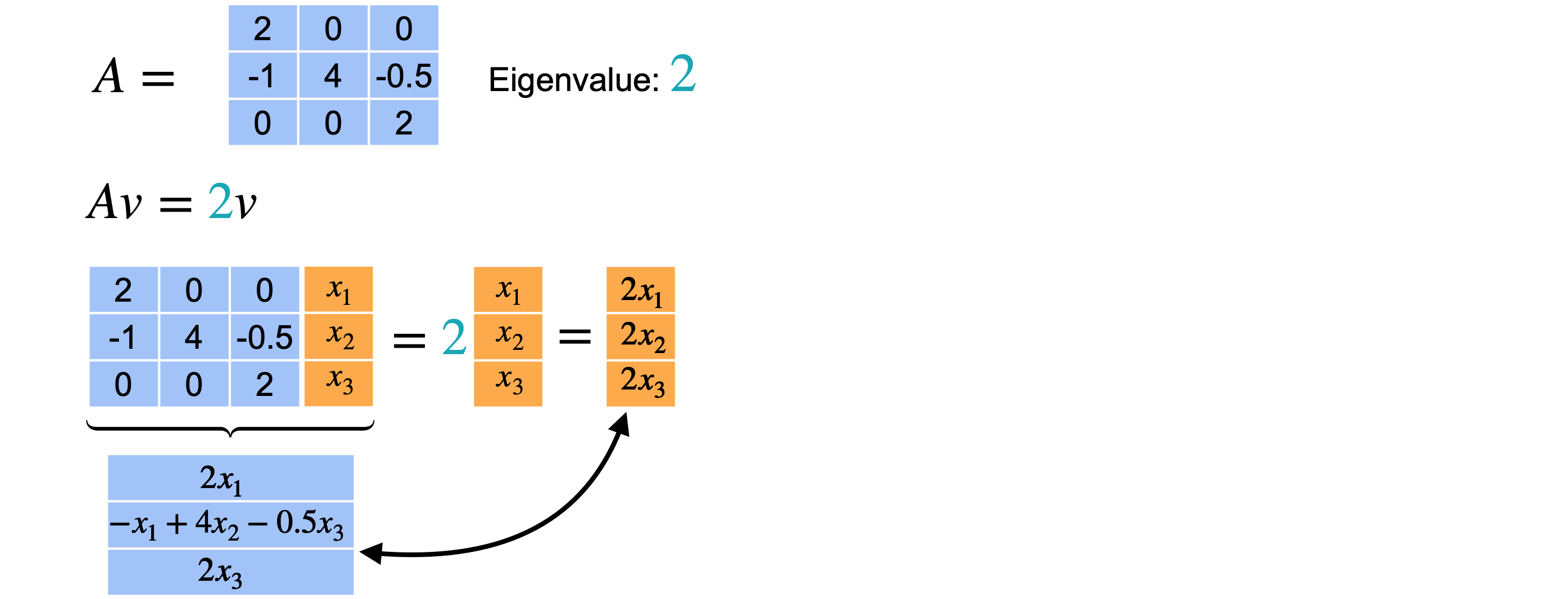
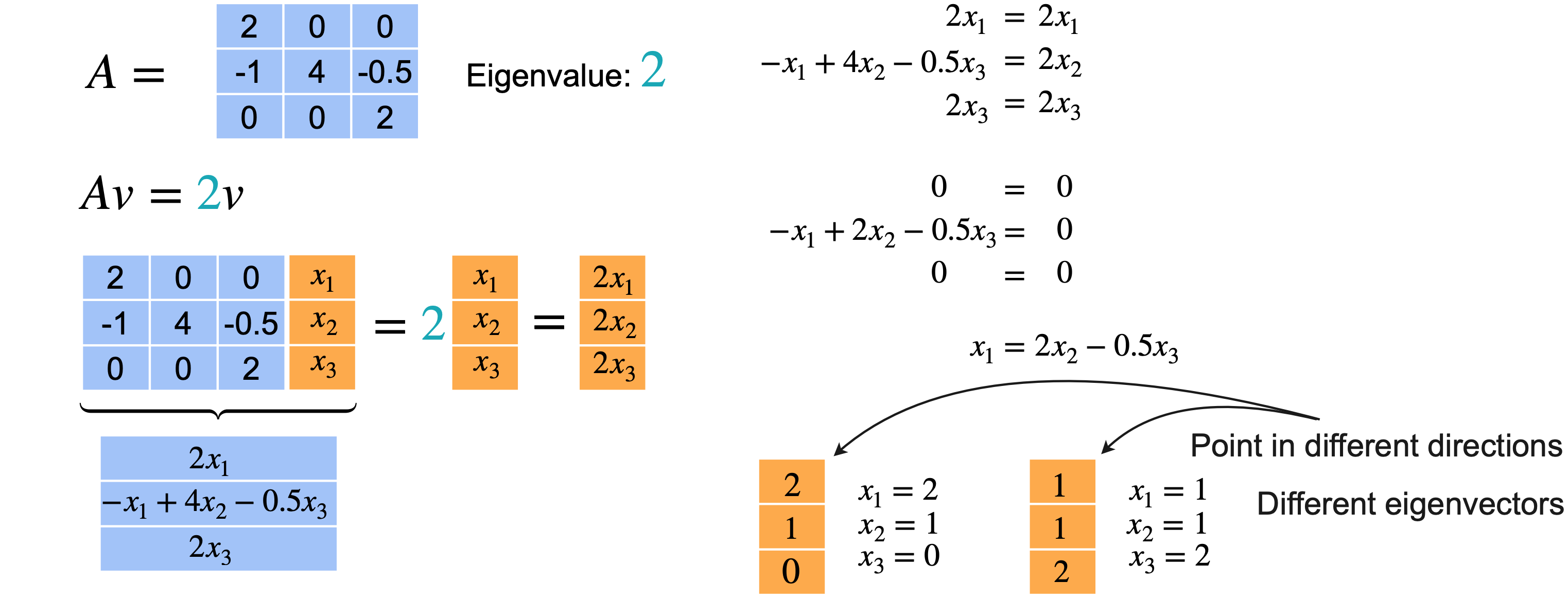
总而言之,此矩阵(0,1,0)。第二个特征值(2,1,0)。最后,第三个特征值(1,1,2)。在这种情况下,即使特征值重复,您也可以找到三个不同的特征向量。
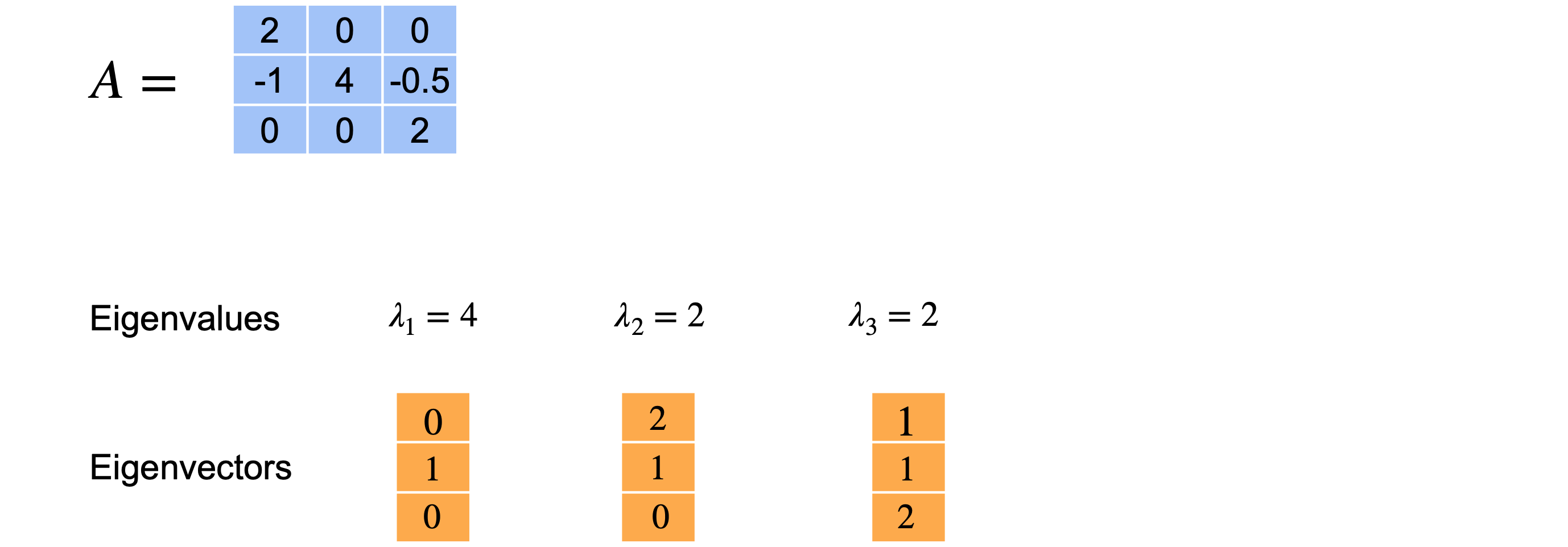
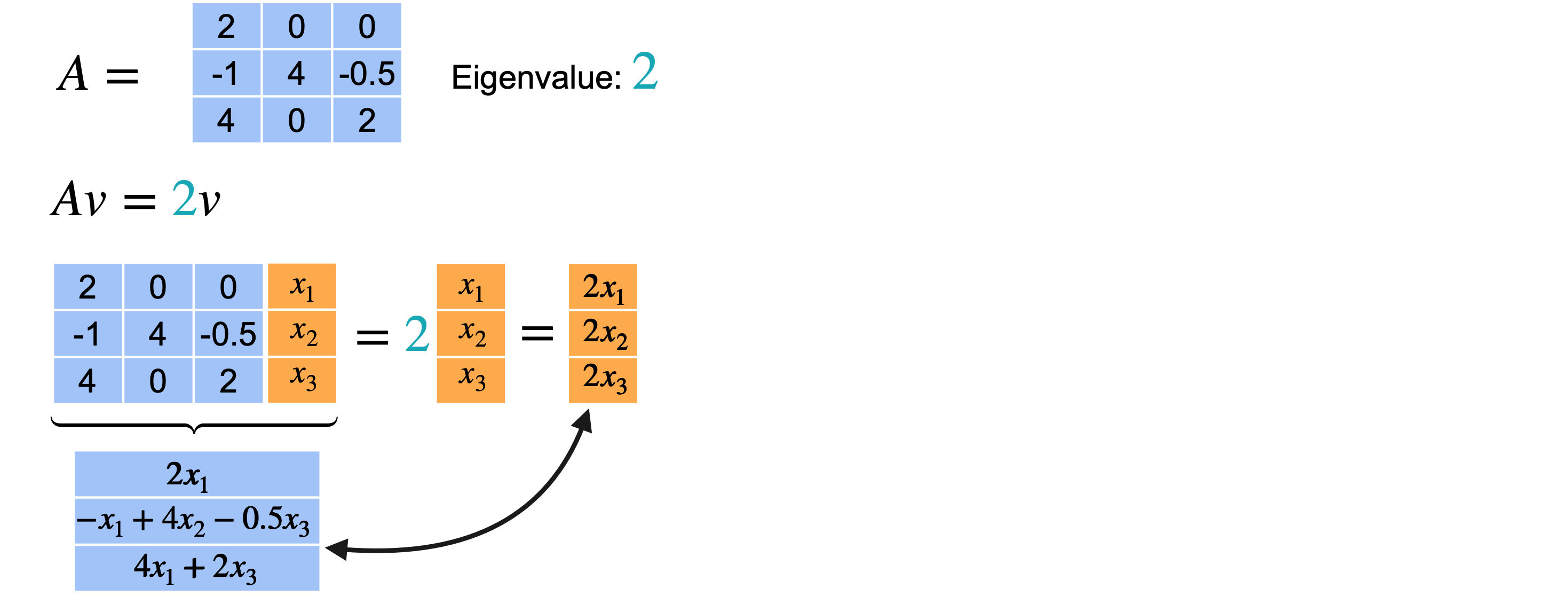
让我们再看一个例子。只改变矩阵中的一个值,看看会发生什么。特征多项式与之前相同。再一次,我们将值(4、2、2)作为特征值。让我们重复之前的过程来找到特征向量并从特征值4开始。这里唯一改变的方程是最后一个方程,现在有1、2、3。从方程1中,您可以得出3和1,您可以得出(0,1,0)作为特征向量。它和上一个矩阵的特征向量相同。
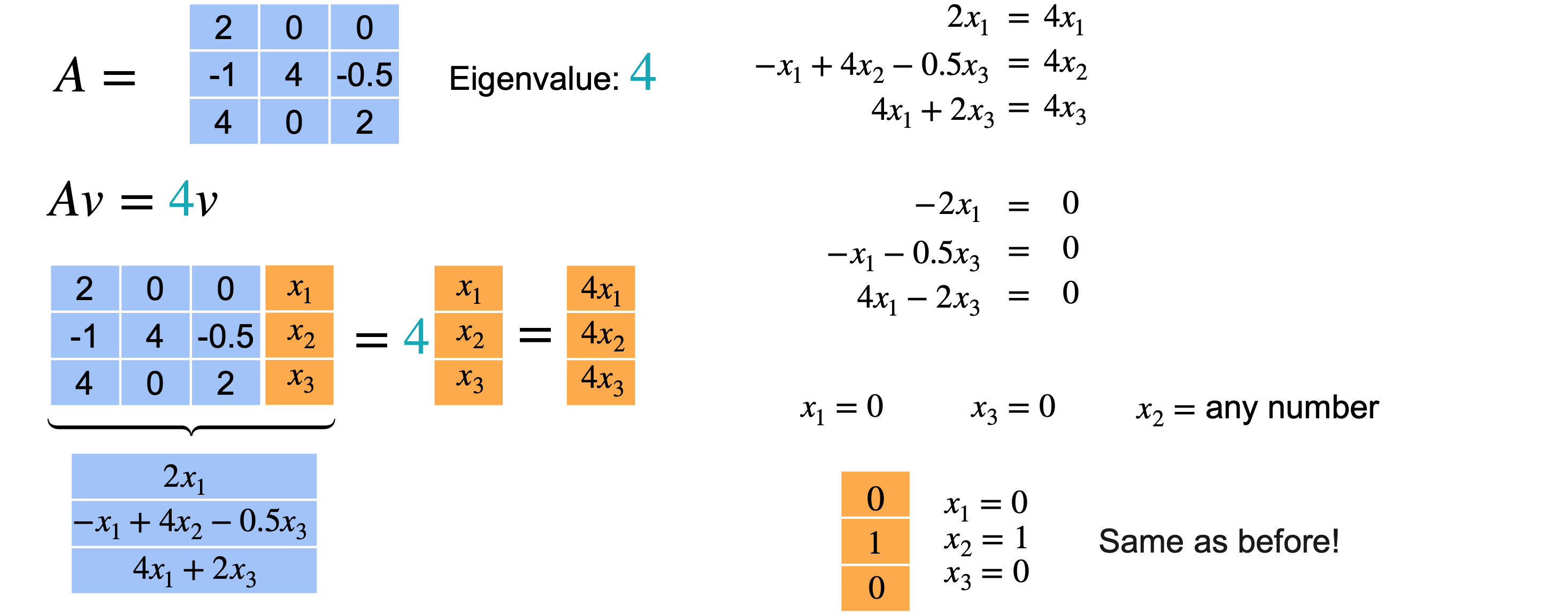
对于特征值2,也会发生同样的事情。当您解这个方程时,您会得到0的限制。现在,从方程2和方程3可以得出0。一旦固定了(0,1,4)。例如,如果您选择(0,1/2,2),x_3必须为2。但是,这两个向量位于同一条线上。一个只是另一个的缩放,意味着它们实际上是相同的特征向量。意味着2是特征值的2倍,但您只能找到一个与之相关的特征向量。然后,特征向量的形式为(0,k,4k),但只有一个方向可以与特征值2配对,即使2作为特征值出现了2次。对于矩阵项(2,0、0,-1,4,-0.5,4,0,2),特征值4与特征向量(0、1、0)相关联。然后特征值2与特征向量(0、1、4)相关联。同样,特征值2没有相关联的特征向量。意味着您无法创建n个特征基的三维空间,因为您缺少一个向量来跨越整个空间。
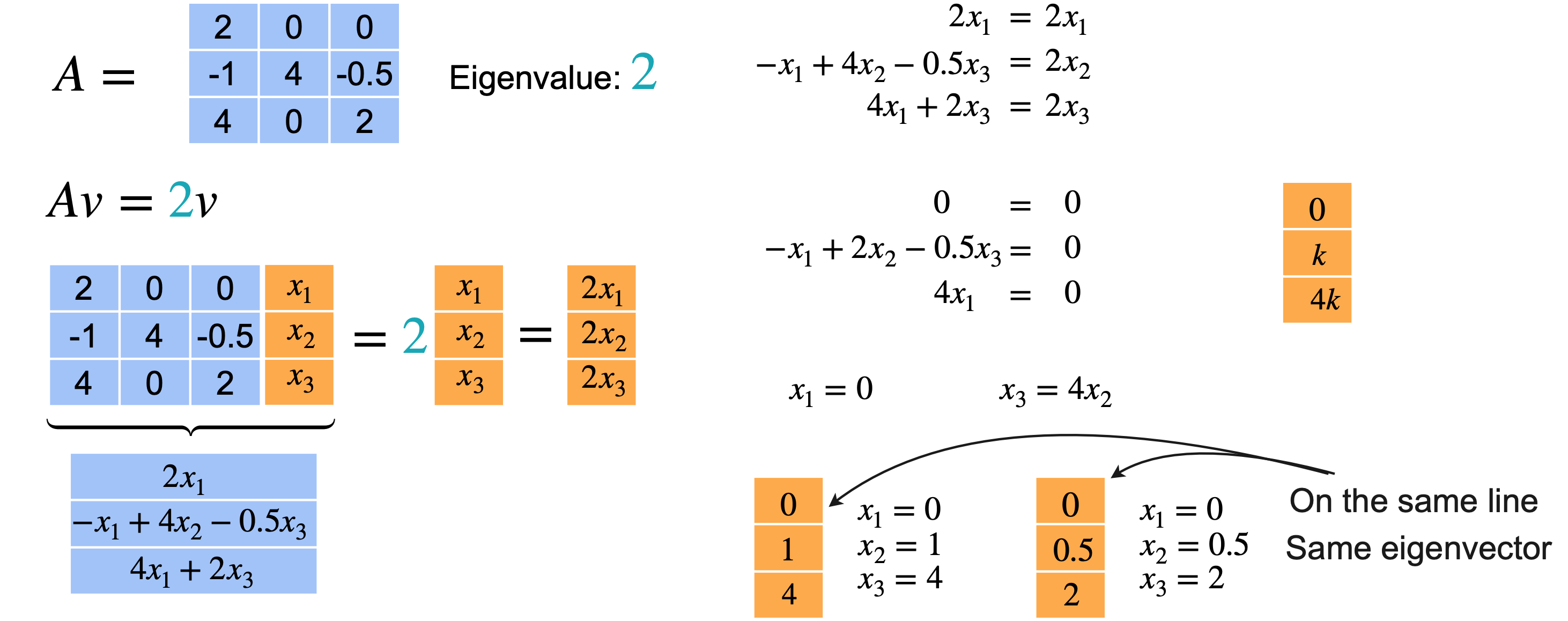
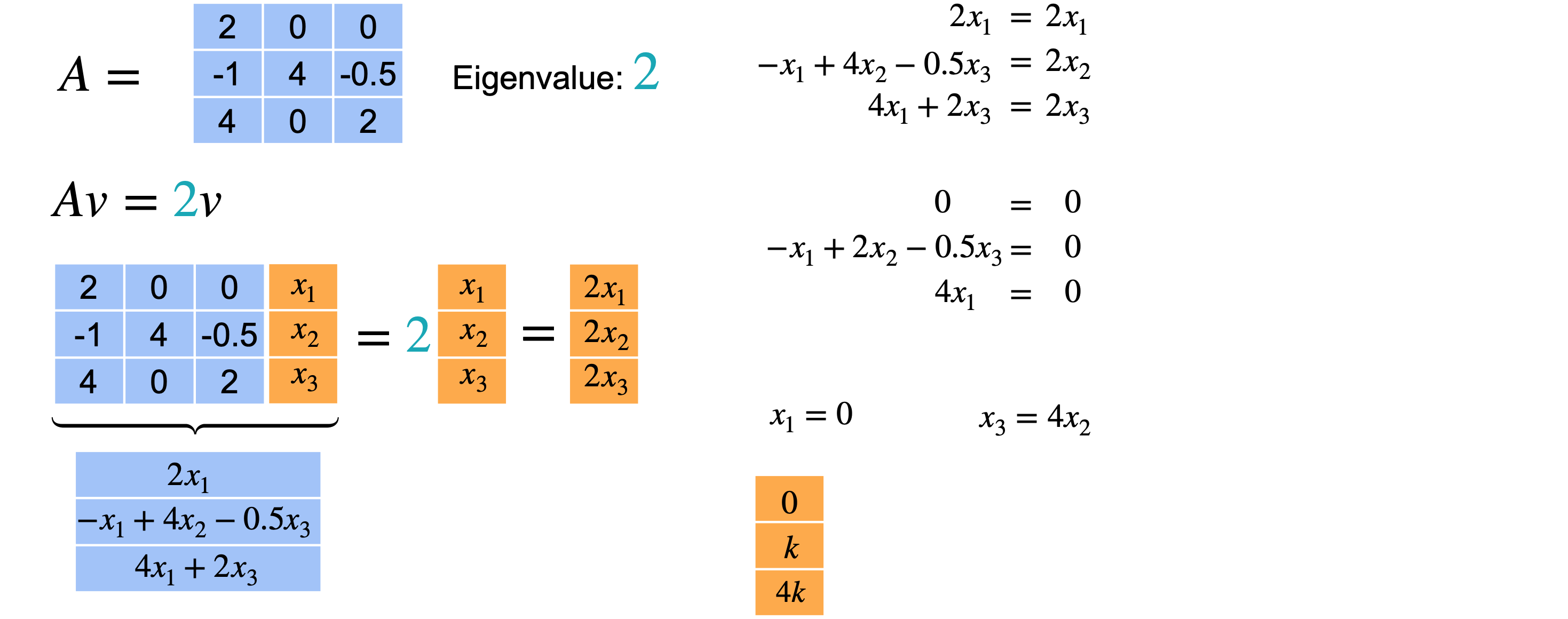
总之,如果您有一个3个特征值都不同,那么您总是可以找到3个不同的特征向量。如果一个特征值重复2次,而另一个不同,那么您可以有两个或三个特征向量。但是,如果相同的特征值重复三次,则可以有1~3之间的任意数量的特征向量。
降维与投影
主成分分析(PCA)的目标是减少数据集的维度或列数,同时保留尽可能多的信息。简而言之,PCA将一个大表或数据集转换为一个较小的表或数据集。原始数据集有许多行或列或特征,用于存储每个有用的信息。PCA将减少表中的特征数量,同时保持相同的观察数量。换句话说,数据集将具有相同数量的行和更少的列。它将一样高,但会变得更瘦。
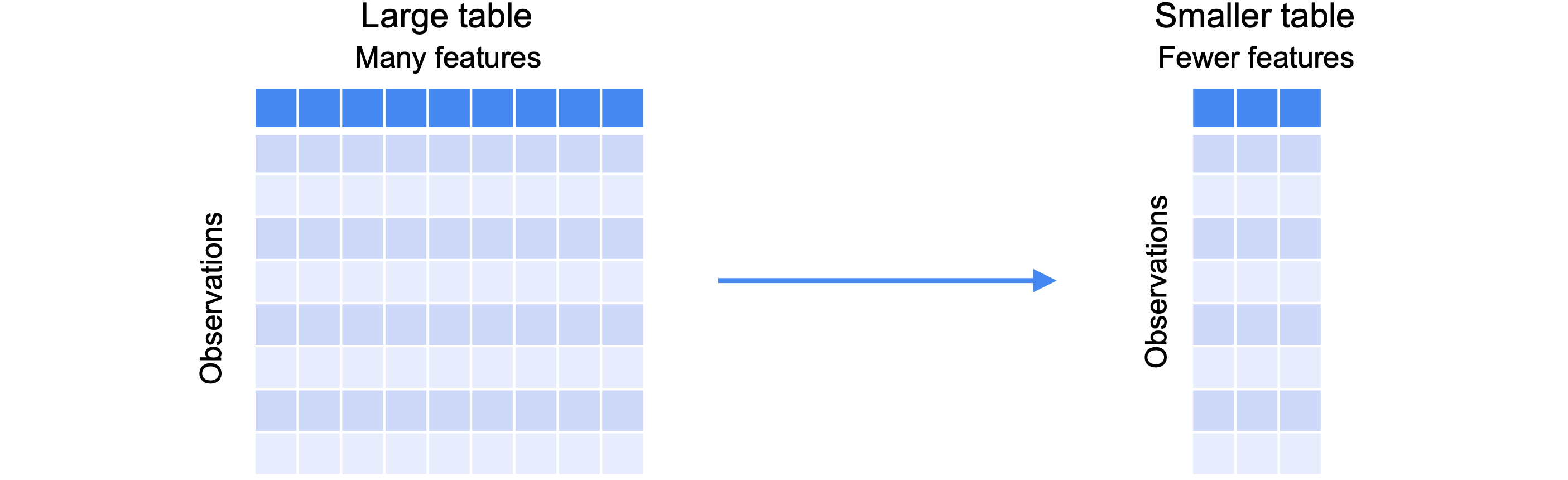
以下是一家在线商店收集的有关其客户的示例数据集。此表有4个观察值和5个特征。客户年龄、帐户年龄(自上次登录以来的天数)、总购买量和总支出金额。希望减少数据集的维度有两个主要原因。第一个原因是:它实际上太大了,您想使用较小的数据集。您只有五个特征,但在某些机器学习环境中,您很容易拥有数百或数千个特征。能够将数据集缩小到更易于管理的大小。其次是可视化,尤其是在探索性分析中。许多常见的图表,如散点图或条形图,实际上只能帮助一次查看一两个特征时可视化数据。减少需要考虑的维度或列的数量可以更轻松地可视化数据。应该怎么做?这里有一个简单的方法。只需删除列。您可以轻松删除包含每个客户的总购买量和总支出金额的最后两列。这个数据集看起来已经很容易使用了。然而不幸的是,您也删除了很多有用的信息。数据集的维度较少,但从这两列中获得的任何信息都丢失了。PCA旨在解决这个问题。它允许减少数据的维度,但它也保留了删除列可能会丢失的大量信息。降维的理念是将数据点移动到维度更少的向量空间中。这称为投影。

让我通过一个例子向您展示它们的工作原理。假设您有一张数据表,其中有变量(1.0,1.0)、(1.2,1.6)、(-0.5,0.2)、(-1.3,-0.6)。
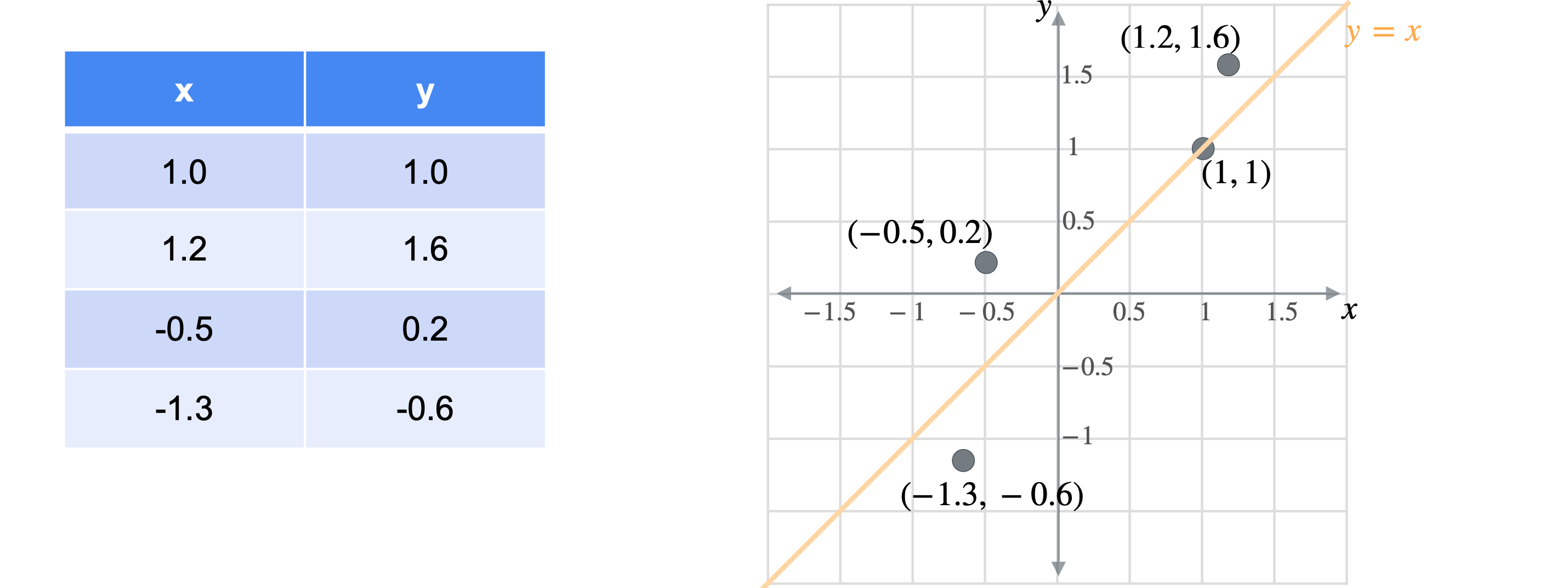
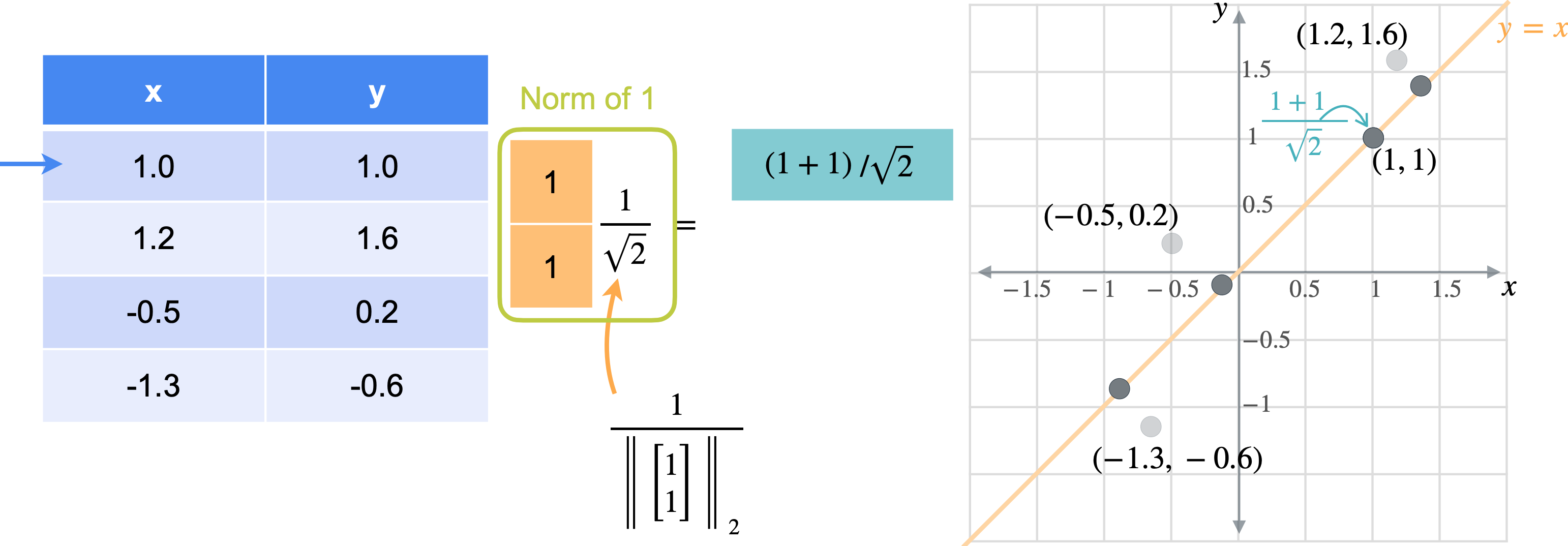
想象一下,您想将数据移动或投影到方程(1,1)已经在线上。但这些点最终会在哪里?我将从最简单的例子开始,即根本没有移动的点(1,1)。之前我会将此点位置指定为(1,1),但这些实际上是二维坐标。可以将这个点的位置指定为一个坐标,即它与原点的距离。通过一些基本的三角学知识,你可以知道这条线段的长度是(1,1)的向量的张成。所以让我们使用向量(1,1)。现在,如果取表中第一行和橙色向量的点积,你基本上是1乘以点x坐标,取1乘以点y坐标,以找到沿线投影的新位置。但是,将两个变量相加会得到一个比预期更长的向量。这个向量的长度是2。但是你知道这个新向量的最终长度应该是1除以2的平方根实际上是1除以向量(1,1)的范数。这是投影的主要思想。乘以向量会将点投影在该向量上,除以向量的范数可确保不会拉伸。另一种思考方式是,你只是将向量更改为新的范数1。但是,如果你将其缩小到3行也同样会。你将用向量(1,1)相乘。就像之前一样,你会超出范围。再用(1.4142、1.9799、-0.2121 和 -1.344),您可能已经注意到,现在只需要一个列向量而不是两列矩阵即可表示沿这些线的点位置。
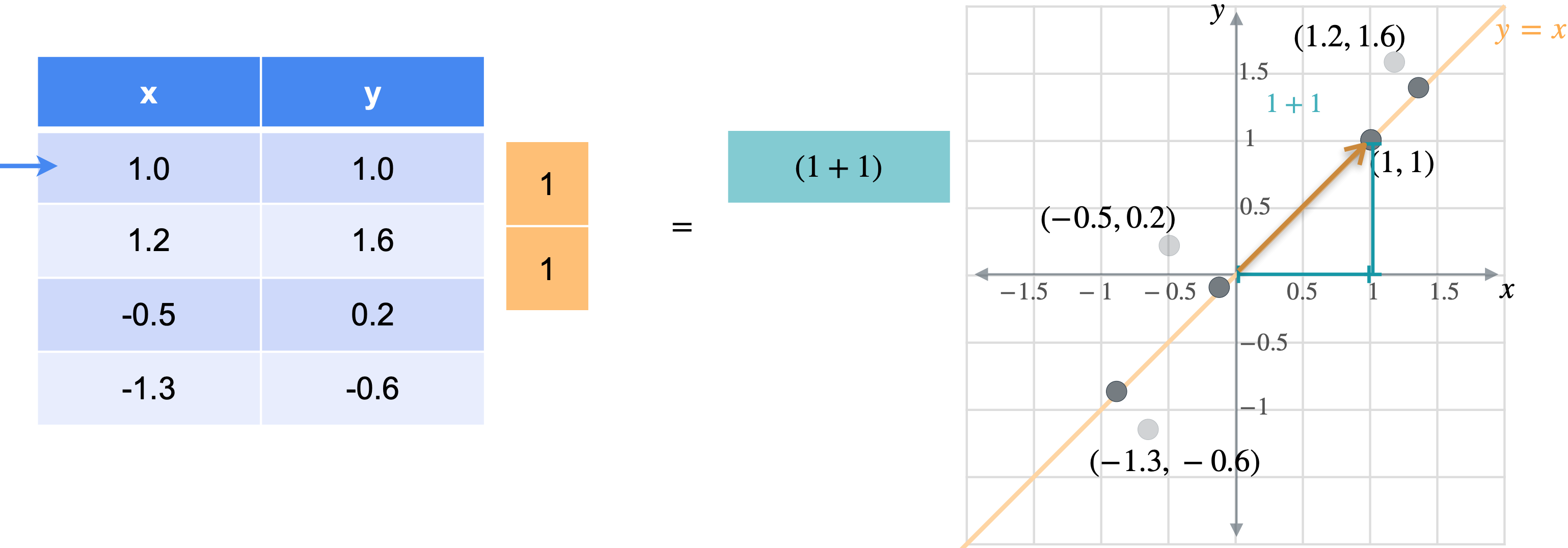
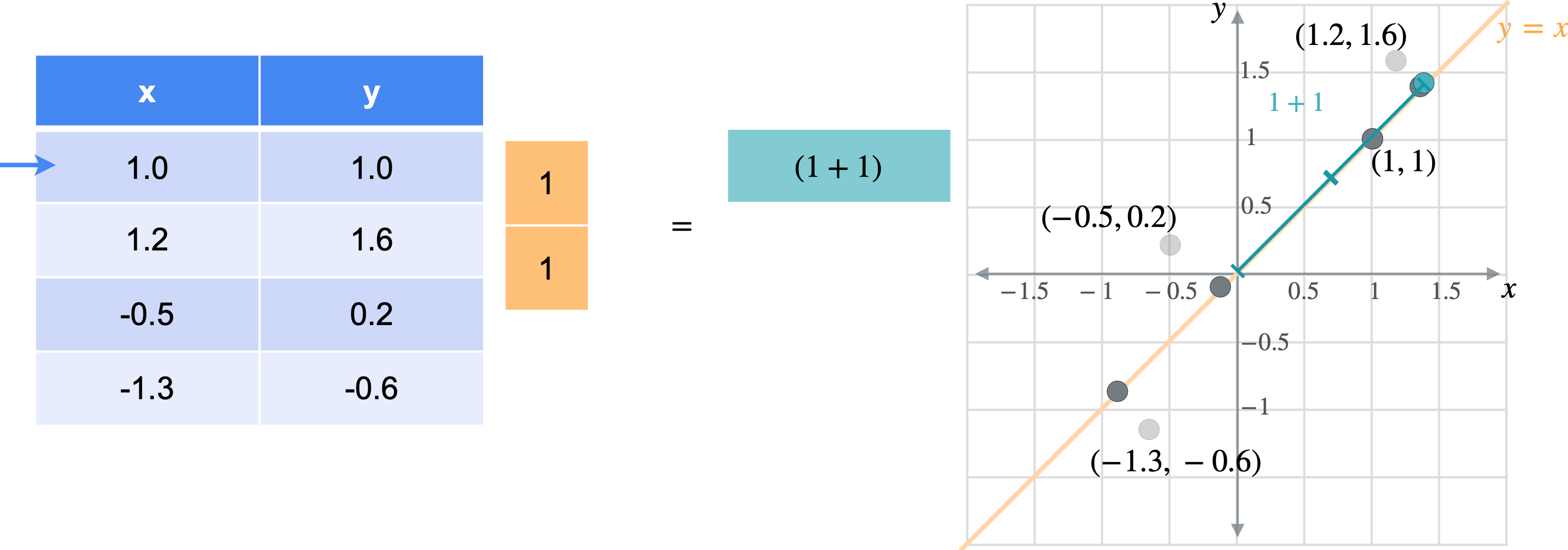
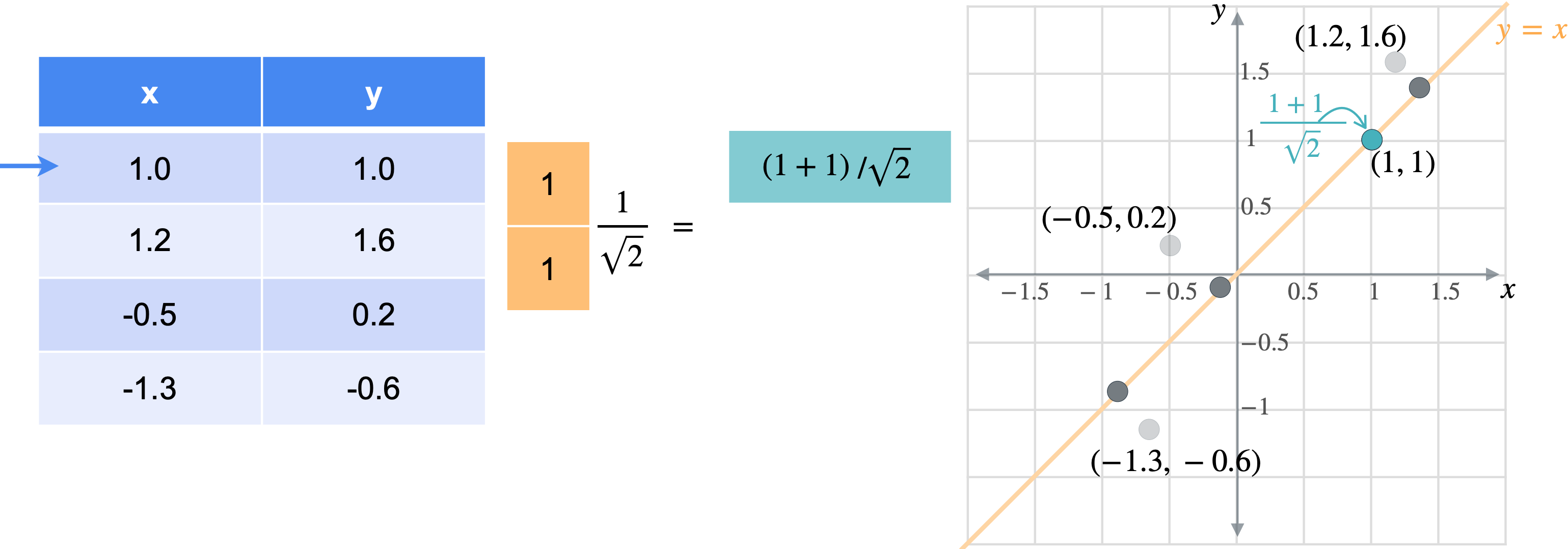
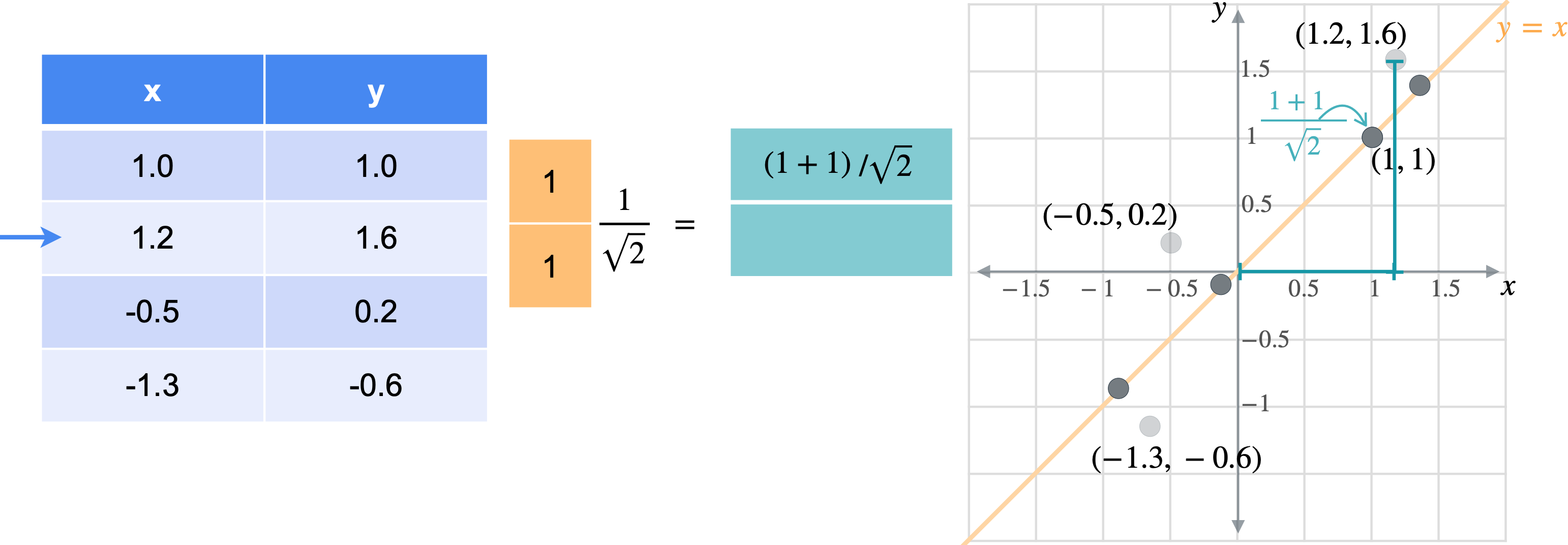
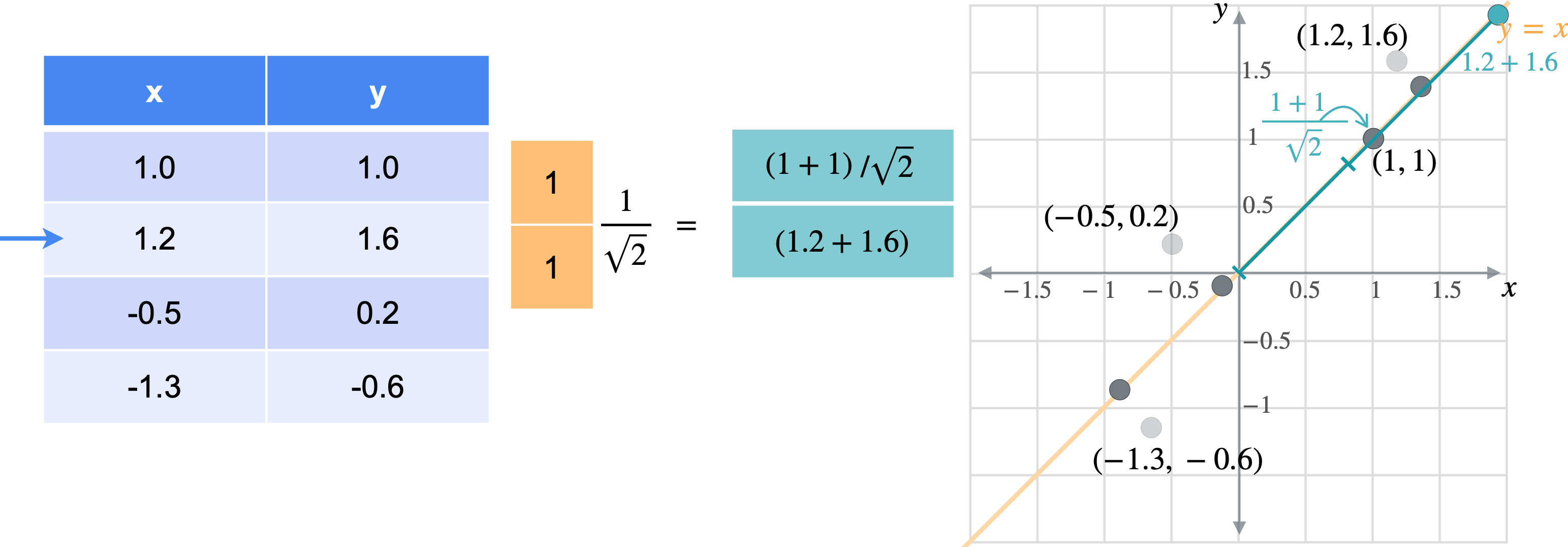
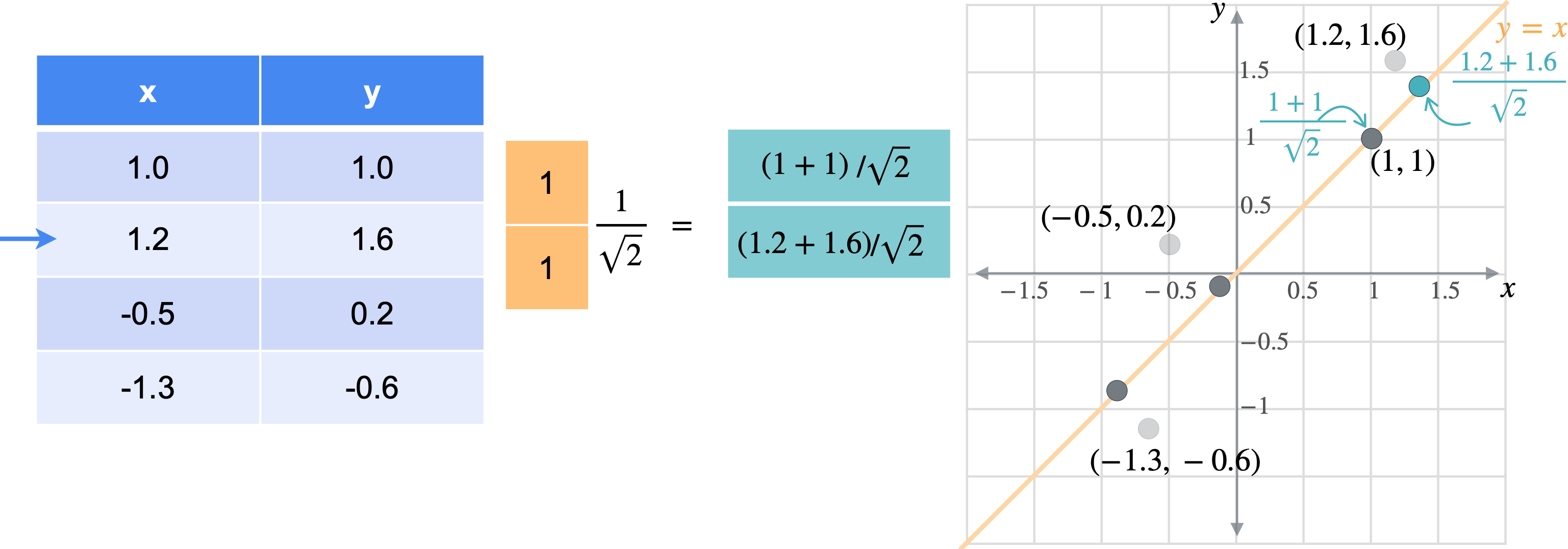
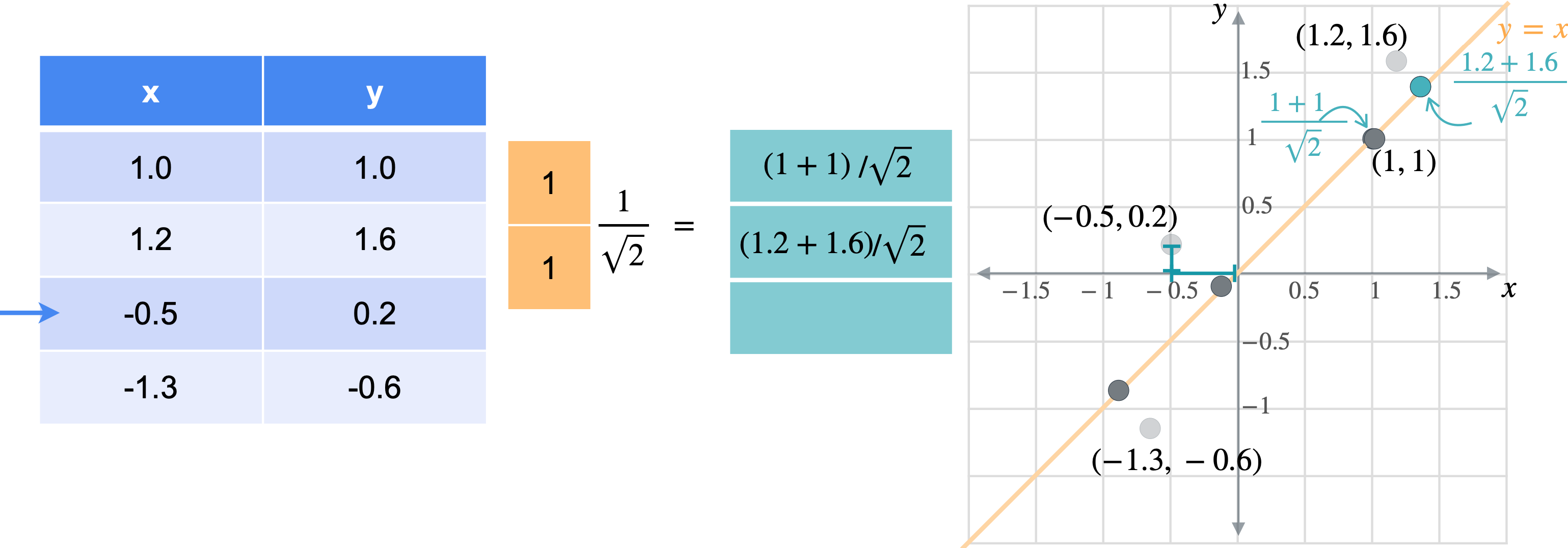
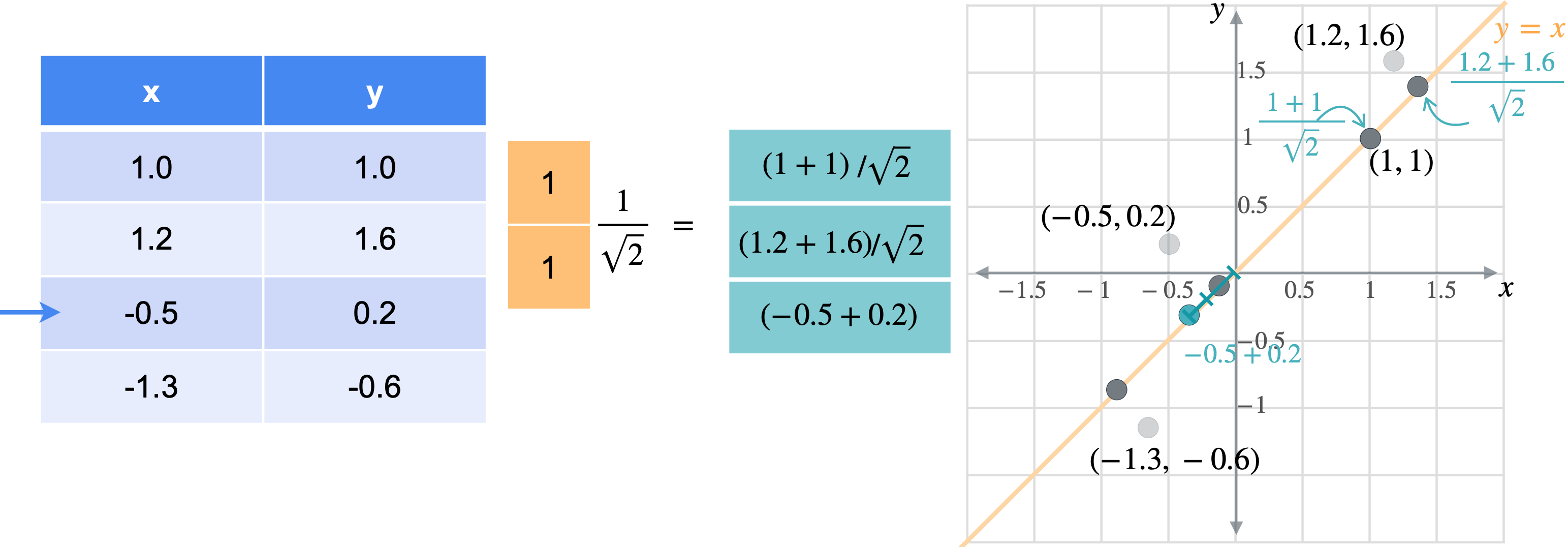
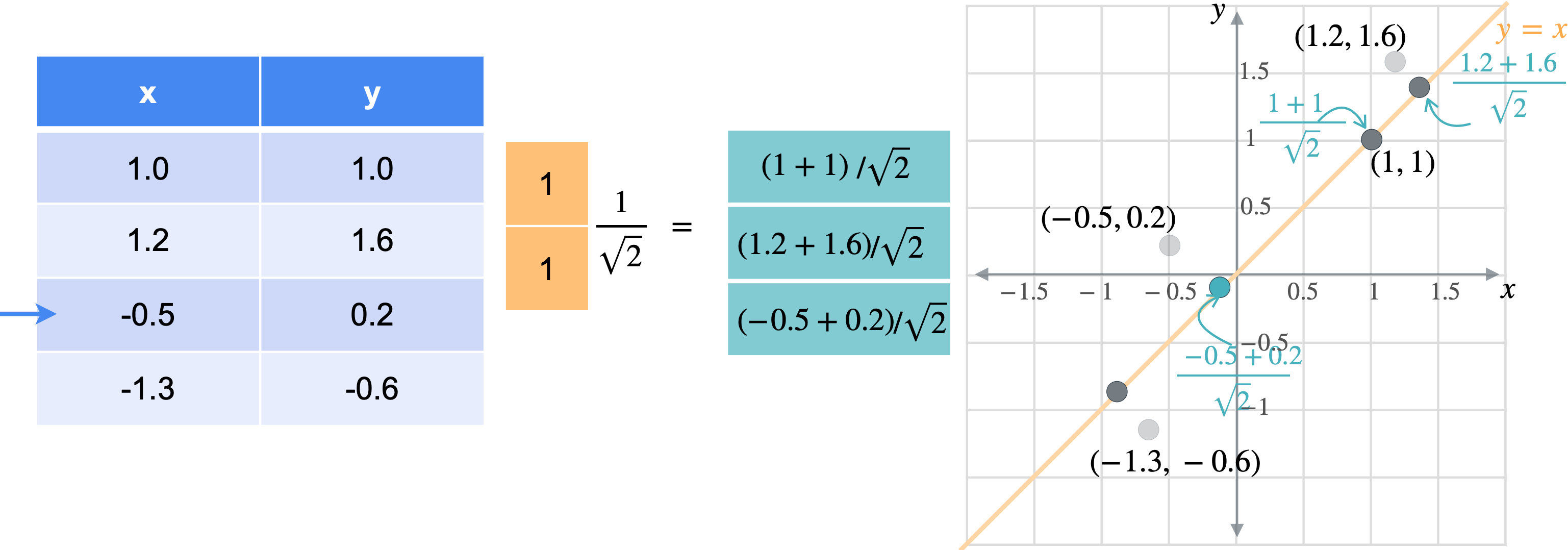
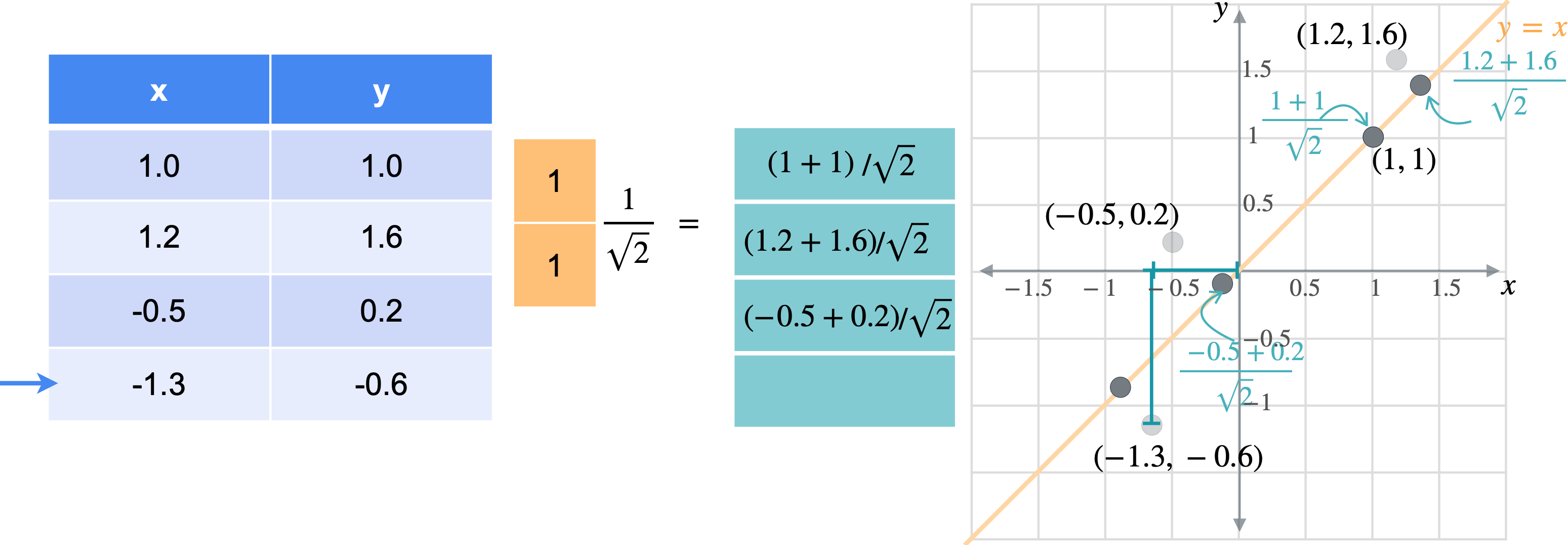
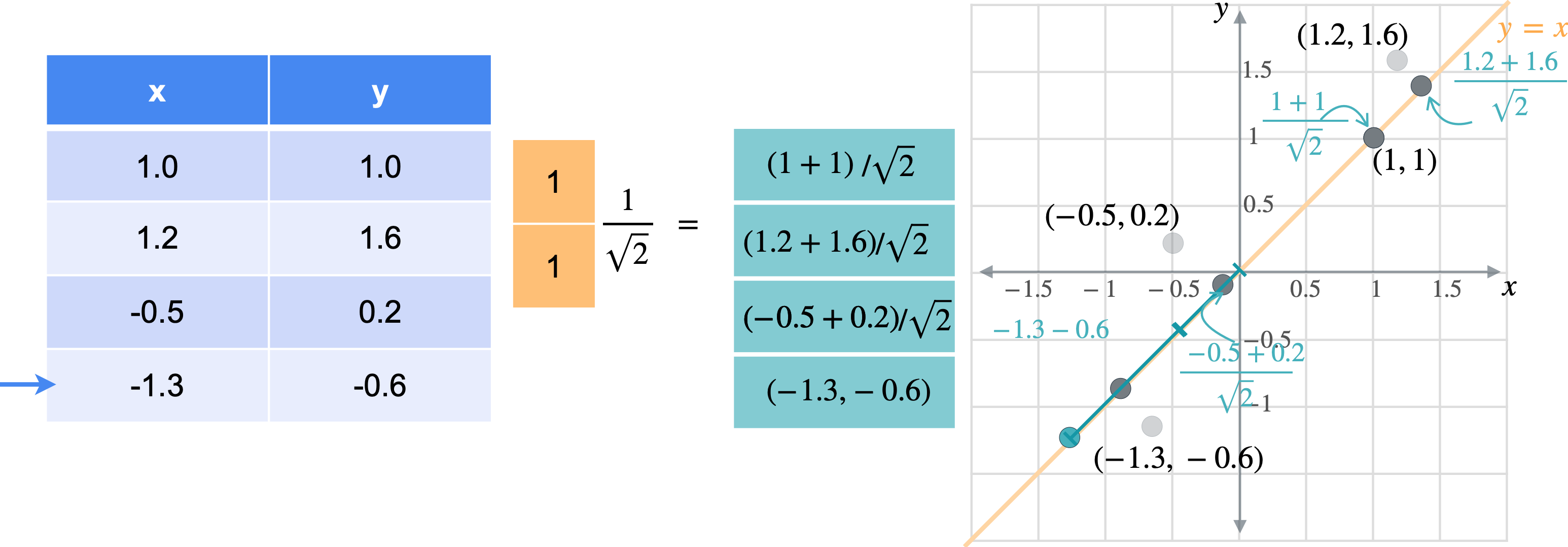
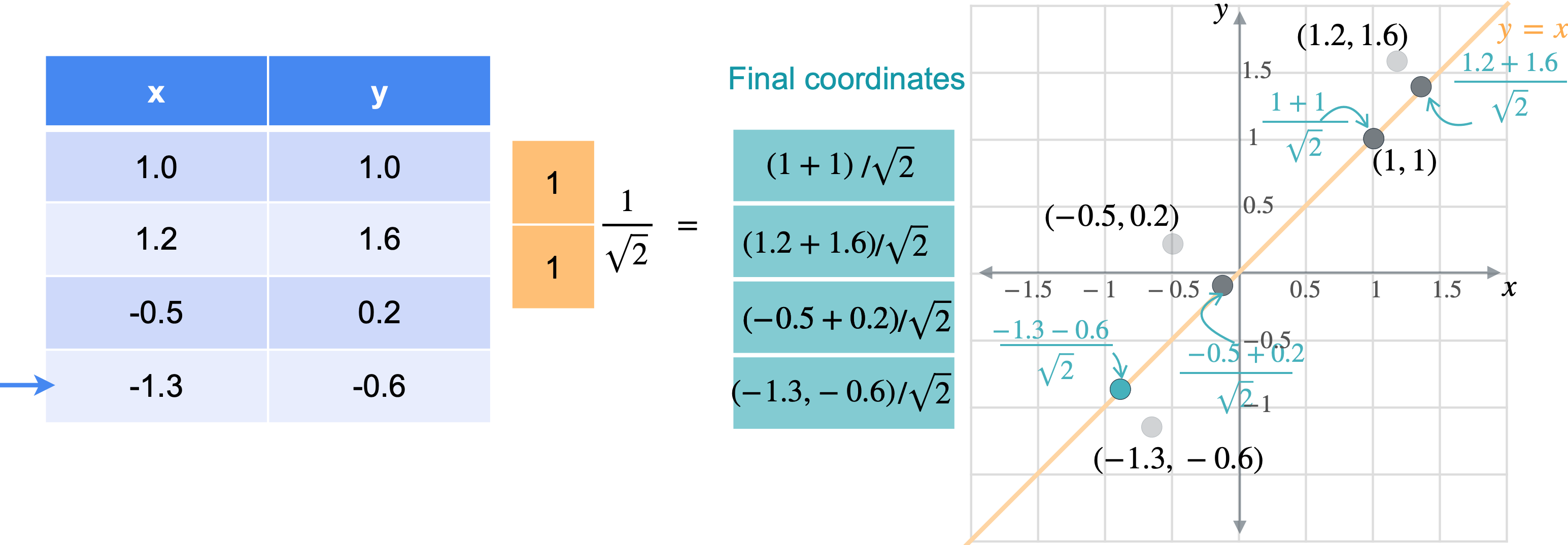

通常,如果要将任何矩阵1。因此,将1列。
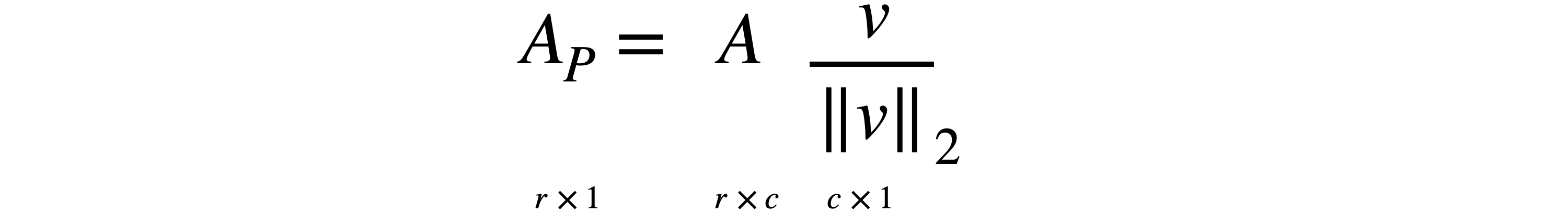
您可以一次将其投影到多个向量上。投影到两个向量上与投影到这些向量所跨的平面上是一回事。在本例中,只需创建一个大小为2列的投影,意味着您拥有相同数量的数据点,但现在只有两个变量。最后,投影可以用简单的方程