SAM2模型-探析(深度学习)
介绍
SAM2(Segment Anything Model 2)是Meta AI最新发布的图像和视频分割模型,是Segment Anything Model(SAM)的下一代模型。SAM2是一个统一的模型,可以同时处理图像和视频的分割任务。这种统一的架构简化了部署,并在不同媒体类型中实现了一致的性能。SAM2采用了提示式视觉分割(Promptable Visual Segmentation, PVS)的方法。用户可以通过点击、边界框或掩码等方式在视频的任何帧上提供提示,模型会立即生成相应的分割掩码,并将其传播到整个视频中。
SAM2还可以分割任何视频或图像中的任何对象(通常称为零样本泛化),这意味着它可以应用于以前从未见过的视觉内容,而无需进行自定义调整。

图像分割:Segment Anything(Kirillov等人,2023年)引入了一种可以提示的图像分割任务,其目标是在给定输入提示(例如边界框或指向感兴趣对象的点)的情况下输出有效的分割掩码。在SA-1B数据集上训练的SAM允许使用灵活提示进行零样本分割,从而使其能够应用于广泛的下游应用。最近的工作通过提高其质量扩展了SAM。例如,HQ-SAM(Ke等人,2024年)通过引入高质量输出token并在细粒度掩码上训练模型来增强SAM。另一项工作重点是提高SAM的效率,使其在现实世界和移动应用中得到更广泛的应用,例如EfficientSAM(Xiong等人,2023年)、MobileSAM(Zhang等人,2023年)和FastSAM(Zhao等人,2023年)。
交互式视频对象分割(iVOS):交互式视频对象分割已成为一项关键任务,可在用户指导下有效获得视频中的对象分割(masklets),通常以涂鸦、点击或边界框的形式出现。一些早期方法 (Wang等人,2005年;Bai & Sapiro,2007年;Fan等人,2015年) 部署基于图的优化来指导分割注释过程。较新的方法 (Heo等人,2020年;Cheng等人,2021年;Delatolas等人,2024年) 通常采用模块化设计,将用户输入转换为单个帧上的掩码表示,然后将其传播到其他帧。在视频中分割对象并实现良好的交互体验,并且我们建立了一个强大的模型和一个庞大而多样化的数据集来实现这一目标。具体来说,DAVIS交互式基准 (Caelles等人,2018年) 允许通过多帧上的涂鸦输入以交互方式分割对象。然而,这些方法有局限性:跟踪器可能无法适用于所有对象,SAM可能无法很好地处理视频中的图像帧,并且除了使用SAM从头开始对错误帧进行重新注释并从那里重新启动跟踪之外,没有其他机制可以交互地改进模型的错误。
半监督视频对象分割(VOS)。半监督VOS通常以第一帧中的对象掩码作为输入开始,必须在整个视频中准确跟踪该掩码(Pont-Tuset等,2017)。之所以被称为“半监督”,是因为输入掩码看作是仅适用于第一帧的对象轮廓的监督信号。这项任务因其与各种应用的相关性而引起了广泛关注,包括视频编辑、机器人技术和自动背景去除。半监督VOS可以看作是可提示视觉分割(PVS)任务的一个特例,因为它相当于仅在第一个视频帧中提供掩码提示。然而,在第一帧中注释高质量的对象掩码实际上具有挑战性且耗时。
视频分割数据集:已经提出了许多数据集来支持VOS任务。然而当前的视频分割数据集缺乏足够的覆盖范围来实现“分割视频中的所有内容”的能力。它们的注释通常覆盖整个对象(而不是部分),数据集通常以特定对象类别为中心,例如人、车辆和动物。与这些数据集相比,当前发布的SA-V数据集不仅关注整个对象,还广泛覆盖对象的子部分,并包含超过一个数量级的掩码。
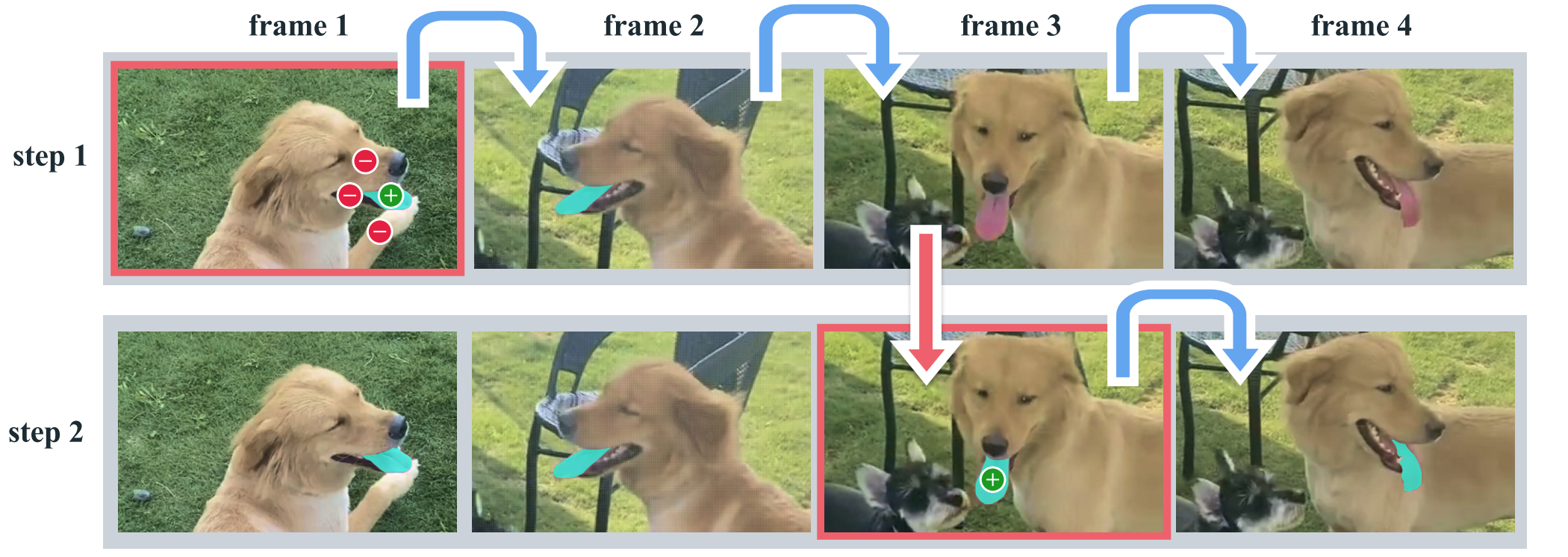
使用SAM2进行交互式分割:
- 步骤1(选择):我们在第
1帧中提示SAM2获取目标对象(舌头)的片段。绿点/红点分别表示正/负提示。SAM2自动将片段传播到后续帧(蓝色箭头)以形成masklet。如果SAM2丢失了对象(第2帧之后),我们可以通过在新帧(红色箭头)中提供额外提示来更正masklet。 - 步骤2(细化):在第
3帧中单击一次就足以恢复对象并传播它以获得正确的masklet。分离的SAM+ 视频跟踪器方法需要在第3帧(如第1帧)中单击几次才能在从头开始重新开始正确地分割并重新注释对象。借助SAM2的内存,单击一次即可恢复舌头。
提示视觉分割(PVS)任务
PVS任务允许在视频的任何帧上向模型提供提示。提示可以是正/负点击、边界框或蒙版,用于定义要分割的对象或细化模型预测的对象。为了提供交互式体验,在收到特定帧上的提示后,模型应立即响应该帧上对象的有效分割蒙版。在收到初始(一个或多个)提示(在同一帧或不同帧上)后,模型应传播这些提示以获取整个视频中对象的蒙版,其中包含每个视频帧上目标对象的分割蒙版。可以在任何帧上向模型提供其他提示,以细化整个视频中的片段。
SAM2模型
SAM2支持在单个帧上提示(点、框和掩码),以定义视频中要分割的对象的空间范围。对于图像输入,该模型的行为类似于SAM。提示的掩码解码器接受当前帧上的帧嵌入和提示(如果有),并输出该帧的分割掩码。可以在帧上迭代添加提示以细化掩码。与SAM不同,SAM2解码器使用的帧嵌入,以过去预测和提示帧的记忆为条件。提示帧也可能来自相对于当前帧的“未来”。帧的记忆由记忆编码器根据当前的预测创建,并放置在记忆库中以供后续帧使用。记忆注意力操作从图像编码器获取每帧嵌入,并在记忆库上对其进行调节以生成嵌入,然后将其传递给掩码解码器。
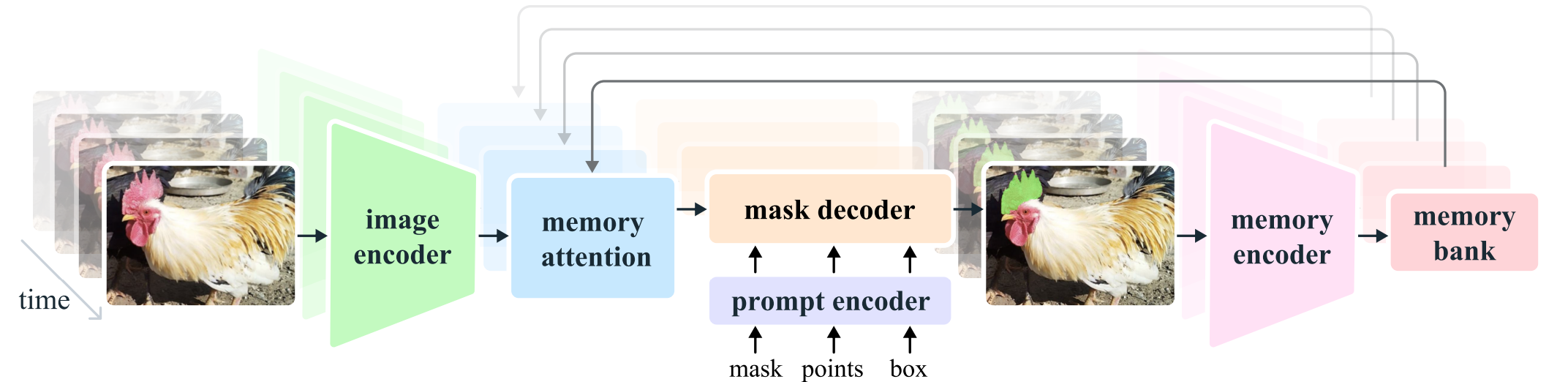
SAM2的架构。对于给定帧,分割预测取决于当前提示and / or先前观察到的记忆。视频以流式方式处理,图像编码器一次消耗一个帧,并与先前帧中的目标对象的记忆交叉关注。掩码解码器(也可以选择接受输入提示)预测该帧的分割掩码。最后,记忆编码器变换预测和图像编码器嵌入以用于未来的帧。
- 图像编码器:对于任意长视频的实时处理,我们采用流式传输方式,在视频帧可用时使用。图像编码器在整个交互过程中仅运行一次,其作用是提供代表每个帧的无约束
tokens(特征嵌入)。我们使用MAE(He等人,2022年)预训练的Hiera(Ryali等人,2023年;Bolya等人,2023年)图像编码器,它是分层的,允许我们在解码过程中使用多尺度特征。 - 记忆注意力(
Memory Attention)。记忆注意力的作用是根据过去帧的特征和预测以及新的提示来调节当前帧的特征。这里堆叠L个转换器块,第一个将当前帧的图像编码作为输入。每个块执行自注意力操作,然后对存储在内存中的(提示/未提示)帧和对象指针的记忆进行交叉注意,然后是MLP。我们使用原始的注意力操作进行自我注意力和交叉注意力,这样能够从高效注意力内核的最新发展中受益(Dao,2023年)。 - 提示编码器和掩码解码器:
SAM2的提示编码器与SAM的相同,可以通过点击、边界框或掩码来提示,以定义给定帧中对象的范围。稀疏提示由位置编码表示,并与每个提示类型的学习嵌入相加,而掩码则使用卷积嵌入并与帧嵌入相加。解码器的设计在很大程度上遵循了SAM的设计。堆叠“双向”Transformer块来更新提示和帧嵌入。与SAM一样,对于可能存在多个兼容目标掩码的模糊提示(即单击),我们会预测多个掩码。这种设计对于确保模型输出有效掩码非常重要。在视频中,模糊性可以扩展到视频帧,模型会在每个帧上预测多个掩码。如果没有后续提示解决模糊性,则模型仅传播当前帧具有最高预测IoU的掩码。与SAM不同的是,在SAM中,只要给出积极的提示,就总会有一个有效的对象可供分割,而在PVS任务中,某些帧上可能不存在有效对象(例如由于遮挡)。为了解释这种新的输出模式,我们添加了一个额外的注意力头,用于预测当前帧上是否存在感兴趣的对象。与SAM的另一个不同之处在于,我们使用来自分层图像编码器的跳过连接(绕过记忆注意力)来整合高分辨率信息以进行掩码解码。 - 记忆编码器:记忆编码器通过使用卷积模块对输出掩码进行下采样,并将其与图像编码器的无条件帧嵌入逐个元素相加,然后使用轻量级卷积层融合信息,从而生成记忆。
- 记忆库(Memory Bank):记忆库通过维护最多
N个最近帧记忆的(FIFO)队列来保留有关视频中目标对象的过去预测的信息,并将来自提示的信息存储在最多M个提示帧的(FIFO)队列中。例如,在初始掩码是唯一提示的VOS任务中,记忆库始终保留第一帧的记忆以及最多N个最近(未提示)帧的记忆。这两组记忆都存储为空间特征图。除了空间记忆之外,我们还根据每帧的掩码解码器输出token将对象指针列表存储为向量,用于要分割对象的高级语义信息(Meinhardt等人,2022年)。我们的记忆注意力交叉关注空间记忆特征和对象指针。我们将时间位置信息嵌入到N个最近帧的记忆中,允许模型表示短期物体运动,但不能嵌入到提示帧的记忆中,因为来自提示帧的训练信号更稀疏,并且更难以推广到推理设置,其中提示帧可能与训练期间看到的时间范围有所不同。 - 训练:该模型在图像和视频数据上进行联合训练。与之前的工作(
Kirillov等人,2023;Sofiiuk等人,2022)类似,这里模拟了模型的交互式提示。采样8帧序列并随机最多选择2帧提示,并概率性地接收使用masklet和模型预测在训练期间采样的校正点击。
数据集
SA-V数据集包含50.9K个视频和642.6K个掩码片(masklet)。这里将SA-V与VOS数据集在视频、masklet和mask数量方面进行了比较。值得注意的是,带注释的mask数量比现有VOS数据集大53倍(不带auto为15倍)。视频收集了一组由众包工作者拍摄的50.9K个新视频。视频包含54%的室内场景和46%的室外场景,平均时长为14秒。视频以“野外”多样化环境为特色,并涵盖各种日常场景。数据集比现有VOS数据集包含更多视频,视频涵盖47个国家/地区,由不同的参与者拍摄。
")
masklet大小分布(按视频分辨率)、(b)视频的地理多样性、(c)录制视频的众包工作者自我报告的人口统计数据。")
与半监督VOS比较
方面表现良好。")
PVS任务
提示式视觉分割(PVS)任务可以看作是分割静态图像到视频的扩展。在PVS设置中,给定一个输入视频,模型可以对视频中的任何帧进行不同类型的输入(包括点击、框或蒙版)的交互提示,目的是分割(和跟踪)整个视频中的有效对象。与视频交互时,模型会对提示的帧提供即时响应(类似于SAM在图像上的交互式体验),并且实时地返回整个视频中对象的分割。
的图示。例如“分割任何事物”(SA)和半监督视频对象分割(VOS),可以看作是PVS任务的特殊案例。")
PVS与静态图像和视频领域的多项任务相关。在图像上,SA任务可以被视为PVS的一个子集,视频被缩减为单帧。同样,传统的半监督和交互式VOS任务是PVS的特殊案例,仅在第一帧上提供的掩码提示和在多个帧上涂鸦在整个视频中分割对象。在PVS中,提示可以是点击、掩码或框,重点是增强交互式体验,从而能够以最少的交互轻松细化对象的分割。
限制:SAM2在静态图像和视频领域都表现出色,但在某些情况下会遇到困难。该模型可能无法在镜头变化中分割物体,并且可能会在拥挤的场景、长时间遮挡后或延长的视频中丢失或混淆物体。为了缓解这个问题,我们设计了在所有帧中提示SAM2的功能:如果模型丢失物体或出错,在大多数情况下,对其他帧进行细化点击可以快速恢复正确的预测。SAM2还难以准确跟踪细节非常细小或精细的物体,尤其是在它们快速移动时。另一个具有挑战性的情况是,附近有外观相似的物体。将更明确的运动建模纳入SAM2可以减轻这种情况下的错误。虽然SAM2可以同时跟踪视频中的多个对象,但SAM2分别处理每个对象,仅使用共享的每帧嵌入,而没有对象间通信。虽然这种方法很简单,但结合共享的对象级上下文信息可以帮助提高效率。
SAM2
图像编码器:使用特征金字塔网络(Lin et al., 2017)融合了Hiera图像编码器的第3阶段和第4阶段的步长16和32个特征,生成每个帧的图像嵌入。此外,第1阶段和第2阶段的步长4和8个特征未使用记忆注意力,而是在掩码解码器中添加了上采样层,这有助于生成高分辨率分割细节。在Hiera图像编码器中使用窗口绝对位置嵌入。RPB提供了跨主干中窗口的位置信息,取而代之的是,SAM2采用了一种更简单的方法来插值全局位置嵌入,而不是跨窗口。不使用任何相对位置编码。
记忆注意力:除了正弦绝对位置嵌入之外,还在自注意力和交叉注意力层中使用二维空间旋转位置嵌入(RoPE)(Su等人,2021;Heo等人,2024)。对象指针token被排除在RoPE之外,因为它们没有具体的空间对应关系。默认情况下,记忆注意力使用L = 4层。

提示编码器和掩码解码器:提示编码器设计遵循SAM,使用与输出掩码对应的掩码token作为帧的对象指针token,该token放置在存储库中。还引入了遮罩预测头。这是通过在掩码和IoU输出token中包含一个附加token来实现的。将附加MLP头应用于新token产生一个分值,该分值表示感兴趣的对象在当前帧中可见的概率。当面对图像中被分割对象的歧义时,SAM引入了输出多个有效掩码的能力。例如,当一个人点击自行车的轮胎时,模型可以将此点击解释为仅指轮胎或整个自行车并输出多个预测。在视频中,这种歧义可以扩展到视频帧。例如,如果在一帧中只有轮胎可见,则点击轮胎可能只与轮胎有关,或者随着自行车的更多部分在后续帧中变得可见,这次点击可能是针对整个自行车的。为了处理这种歧义,SAM2在视频的每个步骤中预测多个掩码。如果进一步的提示不能解决歧义,模型将选择当前帧中预测IoU最高的掩码,以便在视频中进一步传播。
记忆编码器和记忆库:记忆编码器不使用额外的图像编码器,而是重用Hiera编码器生成的图像嵌入,并将其与预测的掩码信息融合生成记忆特征。这种设计允许记忆特征受益于图像编码器生成的强表示(尤其是当我们将图像编码器缩放到更大尺寸时)。此外,我们将记忆库中的记忆特征投影到64维,并将256维对象指针拆分为4个64维tokens,以便交叉注意力记忆库。
结论
基于三个关键方面展示了“Segment Anything”在视频领域的自然演进:
- 1.将提示式分割任务扩展到视频。
- 2.使
SAM架构能够在应用于视频时使用了内存。 - 3.用于训练和基准测试视频分割的多样化
SA-V数据集。