介绍 联邦学习 (Federated Learning,FL)是一种分布式机器学习 技术,旨在保护数据隐私 的同时,利用分散在多个边缘设备或服务器上的本地数据进行模型训练。该方法由谷歌在2016年首次提出,主要用于解决数据孤岛 和隐私保护 问题。它本质上是一种保护隐私的多方协作机器学习框架,它允许参与方建立一个联合训练模型,但参与方均在本地维护其底层数据而不将原始数据进行共享。联邦学习 的核心思想是将模型训练过程分布在多个本地设备上,而不是将所有数据集中到一个中央服务器。每个设备在本地使用其数据进行模型训练,然后将模型参数(而非原始数据)发送到中央服务器进行聚合。通过这种方式,联邦学习能够有效保护数据隐私 ,减少数据传输的风险和成本。
联邦学习 的典型工作流程如下:
初始化模型 :中央服务器初始化一个全局模型,并将其发送到各个客户端设备。本地训练 :每个客户端设备在本地数据上训练模型,并更新模型参数。参数上传 :各个客户端将更新后的模型参数发送回中央服务器。参数聚合 :中央服务器对接收到的模型参数进行聚合,更新全局模型。重复迭代 :重复上述步骤,直到模型收敛或达到预期的性能指标。
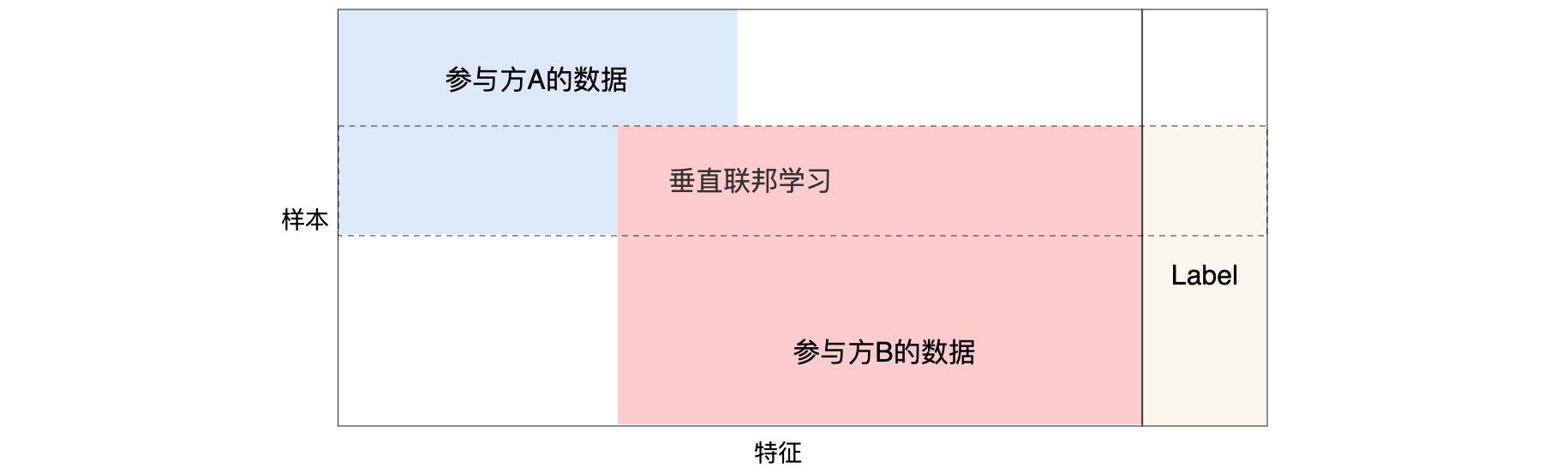
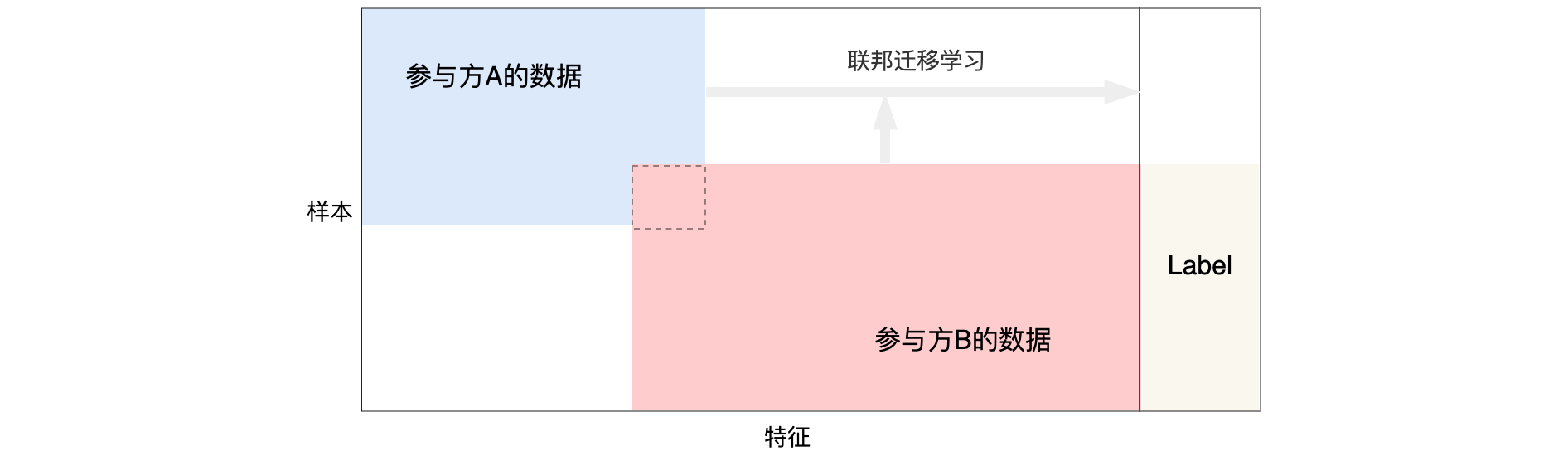
根据数据样本空间和特征空间 的分布模式不同,联邦学习 可以分为以下三类:
水平联邦学习 (Horizontal Federated Learning):适用于数据特征重叠较多,但用户重叠较少的情况。数据集按用户维度水平分割,各个参与者的数据特征是对齐的。垂直联邦学习 (Vertical Federated Learning):适用于用户重叠较多,但数据特征重叠较少的情况。数据集按特征维度垂直分割,各个参与者的数据样本是对齐的。联邦迁移学习 (Federated Transfer Learning):适用于数据样本和数据特征重叠都很少的情况,通过迁移学习的方法进行模型训练。
联邦学习 的优势:
数据隐私保护 :数据不离开本地设备,仅传输模型参数,减少了数据泄露的风险。降低数据传输成本 :避免了将大量数据上传到中央服务器的需求,降低了带宽和存储成本。适应性强 :能够处理异构数据,适用于各种分布式数据环境。
联邦学习 通过在分布式环境中进行模型训练,解决了传统集中式机器学习在数据隐私 和数据孤岛 方面的挑战。随着技术的不断发展,联邦学习 在各种应用场景中的潜力将不断被挖掘和实现。
联邦学习 多个数据拥有方联邦学习 定义如下:联邦学习是指使得这些数据拥有方
其中,
水平联邦学习 (HFL)适用于联邦学习的参与方的数据有重叠的数据特征,即数据特征在参与方之间是对齐的,但是参与方拥有的数据样本是不同的。
垂直联邦学习 (VFL)适用于联邦学习参与方的训练数据有重叠的数据样本,即参与方之间的数据样本是对齐的,但是在数据特征上有所不同。
联邦迁移学习 (FTL)适用于当两个数据集不仅在样本大小上不同,而且在特征空间上也不同时。将中国的一家银行和美国的一家电子商务公司视为两个独立的实体。由于地理限制,两家机构的用户群体重叠很小。然而,由于企业不同,两家公司的特征空间只有一小部分重叠。具体而言,通过应用受限的一般样本集来学习两个特征空间的典型描述,然后将其用于为仅具有单侧特征的样本生成预测结果。FTL解决了当前联合学习方法无法解决的困难,这就是为什么它是该领域的一个重要补充。
联邦学习保护隐私 大型数据集使机器学习取得了惊人的突破。但数据往往是个人或专有的,并不适合共享,这使得隐私成为集中式数据收集和模型训练的关键问题和障碍。借助联邦学习 ,可以使用来自多个用户的数据协作训练模型,而无需任何原始数据离开他们的设备。通过联邦学习,这些设备(如手机、手表、汽车、相机、恒温器、太阳能电池板、望远镜等等)还可以实现新技术。想想我们的汽车如何在不泄露我们行踪的情况下为自动驾驶汽车的大规模训练做出贡献。而且这种机器学习方法也可以应用于不同的组织。医院可以利用来自世界各地护理提供者的各种干预措施带来的患者结果来设计更好的治疗计划,而无需共享高度敏感的健康数据。拥有专有药物开发数据的制药公司可以合作建立关于人体如何代谢不同化合物的知识。该框架有潜力实现对复杂系统和流程的大规模聚合和建模,例如城市交通、经济市场、能源使用和发电模式、气候变化和公共卫生问题。最终,联邦学习 的目标是让人们、公司、管辖区和机构能够协作提出并回答/决策重大问题,同时保持对个人数据的所有权。
联邦学习系统-设计 举例:“拦截垃圾邮件”。邮聊天应用中的垃圾邮件令人讨厌且无处不在。机器学习提供了一种解决方案——我们可以开发一个模型,根据用户之前在其设备上标记为垃圾邮件的内容自动过滤掉传入的垃圾邮件。这听起来很棒,但有一个问题:大多数机器学习模型都是通过在数据中心上收集大量数据来训练的;而用户消息可能非常私密。为了保护隐私,是否有可能在不与数据中心共享任何潜在敏感信息的情况下训练垃圾邮件检测模型(或任何机器学习模型)?
为了回答这个问题,我们首先仔细看看典型的集中式训练系统,下面是一个简单的垃圾邮件检测模型。用户消息被上传到数据中心,在那里它们被一次性处理以训练BoW模型(是一种用于自然语言处理(NLP)和信息检索(IR)的文本表示方法。它通过将文本表示为一个无序的词集合(“袋子”),来捕捉词的频率,而忽略词的顺序和语法结构。)。点击一条消息将其标记为垃圾邮件❌或不更改上传到服务器的数据和训练模型。
这种模型可能在过滤垃圾邮件方面表现不错。但集中式训练有一个很大的缺点:所有消息,无论多么敏感,都需要发送到数据中心,这就要求用户信任该数据中心的所有者会保护他们的数据,不会滥用数据。如果训练是在每个用户的设备上本地进行,而不是集中收集数据,结果会怎样?智能手机的功能越来越强大,而且它们经常处于闲置状态(例如,在夜间充电时),这使得机器学习模型训练能够在不影响用户体验的情况下运行。
在本地训练模型对于保护隐私非常有益——数据永远不会离开用户的设备!但我们可以从这里看到,一台数据有限的设备可能无法训练出高质量的模型。如果一个涉及汽车保险的新骗局开始向所有人发送垃圾邮件,那么Alice的手机将无法使用仅限本地的模型过滤掉有关“您的汽车保修续订”的消息,除非她将其中几条消息标记为垃圾邮件。
用户如何才能在不共享私人数据的情况下互相帮助并协作训练模型?一种想法是让用户共享本地训练的垃圾邮件检测模型而不是他们的消息。然后,服务器可以组合这些模型(例如通过均值)来生成每个人都可以用于垃圾邮件过滤的全局模型 。
虽然我们已经停止将每条原始消息发送到数据中心,但上传这些本地模型仍然会泄露一些信息。在这里,数据中心可以直接访问每个用户将不同单词标记为垃圾邮件的比率,并可以推断出他们正在谈论的内容。根据用户对数据中心的信任度,他们可能不愿意让数据中心看到他们的本地模型。理想情况下,数据中心应该只看到聚合结果。我们希望开发一个尽可能减少数据的系统。
联邦学习 是一个通用框架,它利用数据最小化策略 使多个实体能够协作解决机器学习问题。每个实体都将其原始数据保存在本地,并通过旨在立即聚合的重点更新来改进全局模型。在组合用户模型时限制数据暴露的第一步是不要存储单个模型 - 只存储聚合 。安全聚合 和安全区域 可以提供更强大的保证,将许多本地模型组合成一个聚合,而不会向服务器透露任何用户的贡献。在安全聚合协议 中,用户设备同意共享随机数,并保留聚合结果的方式掩盖其本地模型。数据中心不知道每个用户如何修改其模型。
用户的隐藏号码永远不会共享。通过安全聚合 过程交换每个本地模型的所有用户提供的数字。Alice、Bob和Carol的设备使用加密技术交换随机数 — “用户实际上不会亲自接触”。
通过安全聚合,用户可以合并他们的模型,而无需向数据中心透露任何个人信息。总而言之,联邦学习可以实现协作模型训练,同时最大限度地减少数据暴露。
训练联邦模型 虽然像垃圾邮件分类器这样的模型可以通过一轮合并本地模型来学习,但更复杂的模型需要多次迭代本地训练和联合均值 。让我们看看它是如何工作的。看一个简单的“热力图”二元分类模型,该模型旨在猜测网格的哪些区域可能很热或很冷。每个用户只从少数几个位置收集了温度读数:
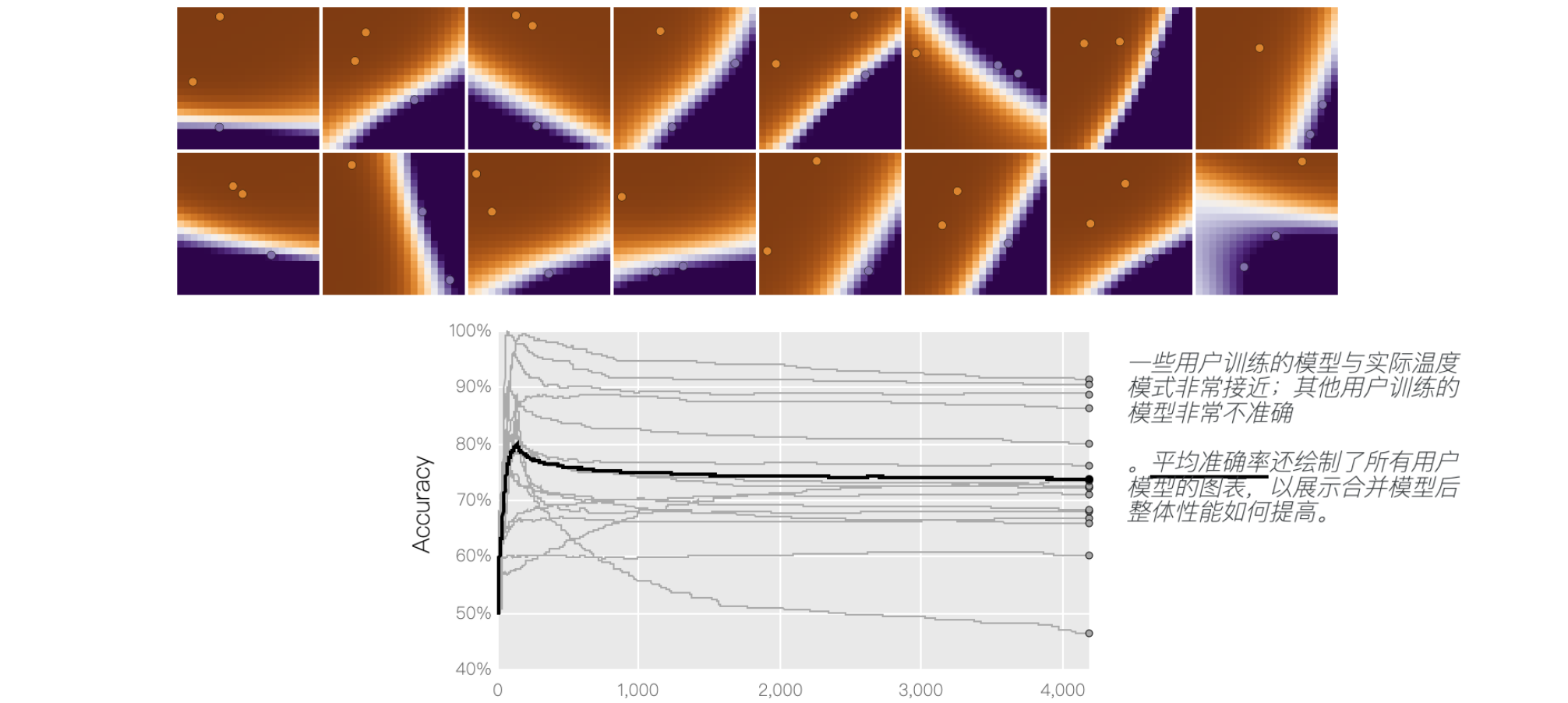
我们的目标是了解整个网格的温度分布——这样每个人都会知道哪里需要穿毛衣!——而无需任何人分享他们的位置历史。如下图所示,每个用户都在使用本地数据不断训练模型,预测网格中每个位置的温度。您可以看到,由于每个用户的模型都过度拟合了他们有限的信息,因此训练的模型差异非常大。局部训练曲线跟踪每个局部模型在地面真实数据上的准确度,表明每个局部模型学习整个网格的真实温度分布的能力。
运行一轮联合训练:对用户模型进行平均,并将更新后的全局模型分发给所有用户。经过多次训练和合并模型后,生成的全局模型比仅基于本地数据训练的模型更能反映地图上的整体温度分布。您可能会注意到,经过一段相当长的局部训练后,局部热图模型会逐渐分离,而最新的全局模型的准确性可能会在合并后下降。使用相对频繁的周期性平均可以避免这种情况。虽然我们绘制了局部模型准确率,以便观察这些训练动态,但实际上,运行联合训练的服务器只能访问全局模型。服务器在训练过程中可以计算和跟踪的唯一指标是全局模型准确率。
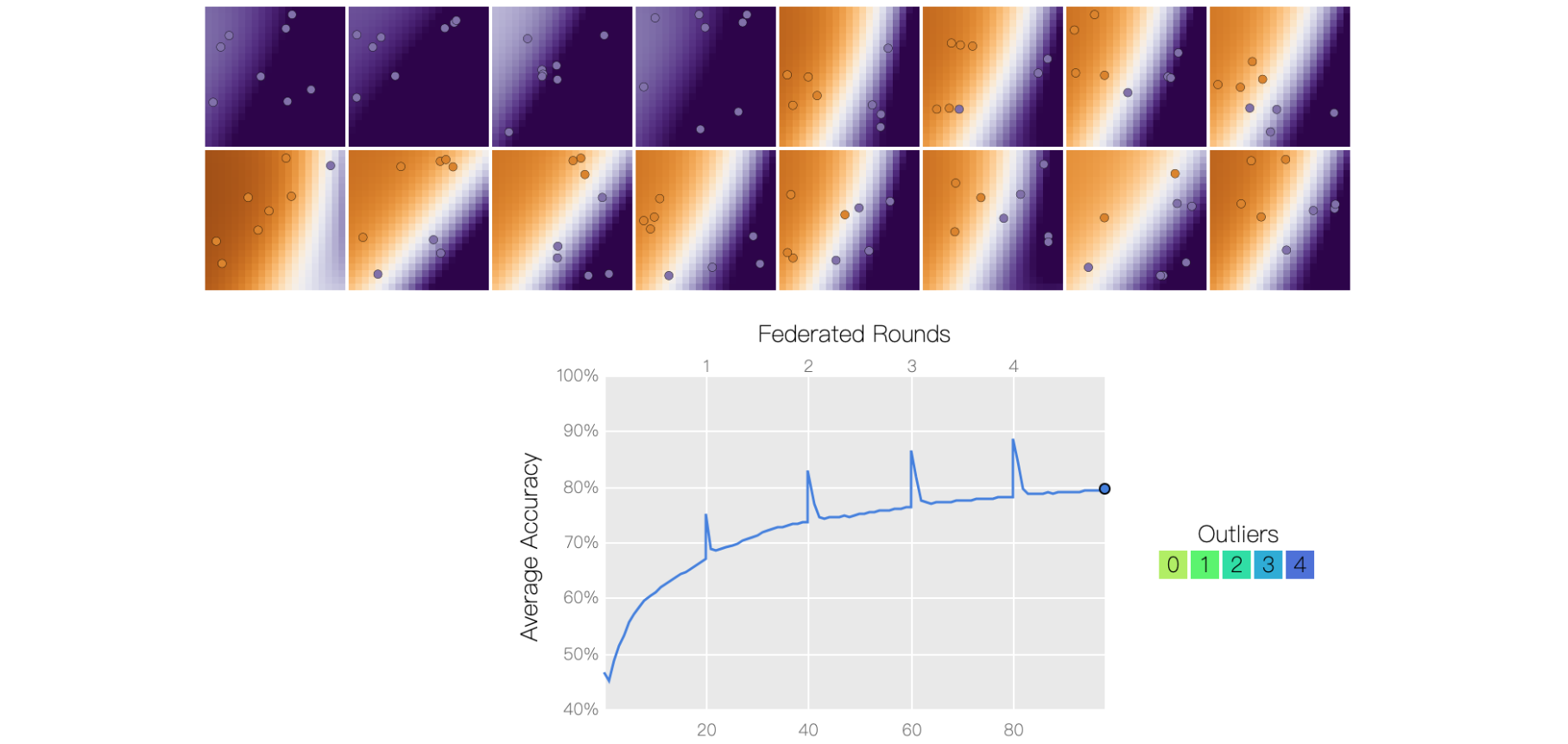
异常值 当所有用户报告的温度体验一致时,这种方法效果很好。如果情况并非如此,会发生什么?也许我们的一些用户的温度计坏了,到处都报告寒冷的天气!单击四个异常值中的每一个,将它们从训练中排除,并注意模型的表现。我们也许能够更好地训练模型来预测大多数用户在没有异常值的情况下观察到的热图,但如果这些异常用户的传感器没有损坏,而他们的数据看起来不同怎么办?有些人可能对什么是“热”或“冷”有不同的看法;从训练中排除异常值可能会降低训练池中代表性较低的人群的准确性。虽然在本例中很容易发现异常值,但实际上联邦学习系统中的服务器无法直接看到用户训练数据,这使得联邦学习中的异常值检测变得很棘手。异常值的存在通常表明用户的模型质量较差。
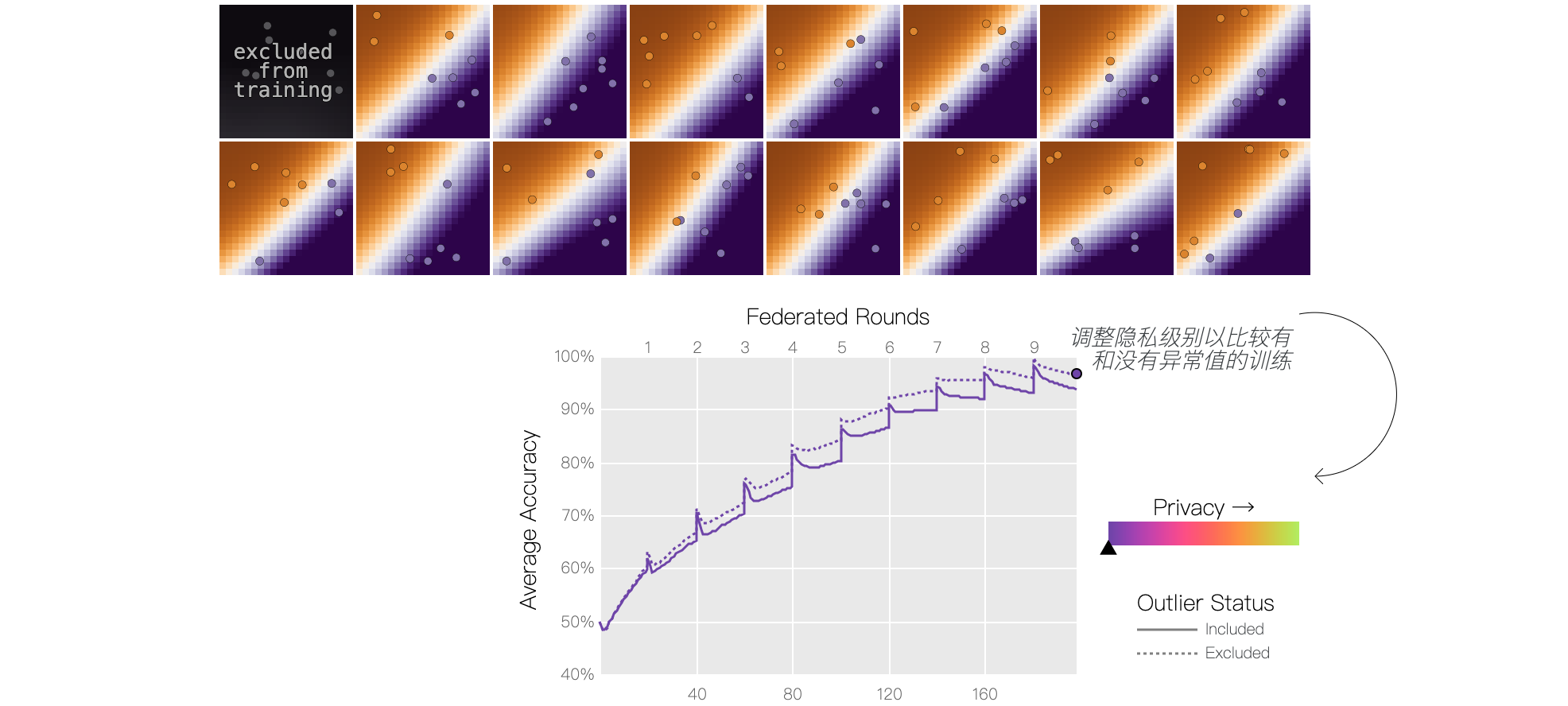
差分隐私 全局模型会因为单个用户的存在而发生巨大变化,这也引发了隐私问题。如果一个用户的参与会显著影响模型,那么观察最终模型的人可能会确定谁参与了训练,甚至推断出他们的本地数据。异常数据尤其可能对模型训练产生更大的影响。例如,假设我们的潜在用户群中有一个以总是穿毛衣并抱怨天气寒冷而闻名的人。如果全局模型准确率低于预期,我们可以推断,这个臭名昭著的穿毛衣的用户可能参与了训练,并且通过总是报告天气寒冷而降低了准确率。即使使用安全聚合,情况也是如此——数据中心无法直接看到哪个用户做出了什么贡献,但由此产生的全局模型仍然表明,很可能有一位认为天气总是适合穿毛衣的用户参与了训练。在联邦学习中使用差异隐私时,全局模型的整体准确性可能会下降,但在训练过程中切换包含异常值(或任何其他用户)时,结果应该保持大致相同。使用滑块调节用户报告位置的扰动程度。在较低的隐私级别下,切换包含异常值对模型的影响更大,而在较高的隐私级别下,即使包含异常值,模型质量也不会有明显差异。
在实践中,用户模型会被裁剪和加噪,而不是原始数据,或者噪声会被应用于许多裁剪模型的组合。集中应用噪声往往更有利于提高模型准确性,但未加噪的模型可能需要通过可信聚合器等技术进行保护。此演示说明了隐私和准确性之间的权衡,但公式中还缺少另一个因素:数据量,包括训练示例数量和用户数量。使用更多数据的成本并非免费 — 这会增加计算量 — 但这是我们可以转动的另一个旋钮,以便在所有这些维度上达到可接受的操作点。
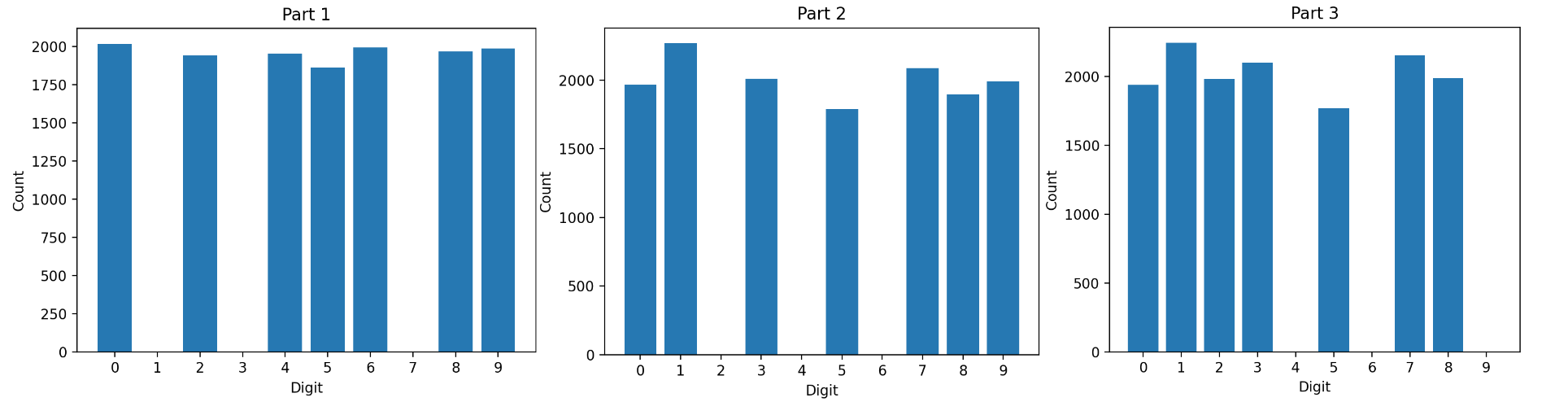
示例 用datasets.MNIST加载MNIST数据集,此示例,将训练数据集拆分为三个数据集。设置三个不同的数据集,排除一些数字,如下所示:
part_1排除数字1、3和7。part_2排除数字2、4和6。part_3排除数字4、6和9。
这模拟了现实世界中可能存在的不同数据集(具有缺失数据、额外数据等的数据集)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 import torchimport torch.nn as nnimport torch.utilsfrom torch.utils.data import Subset, DataLoader, random_splitimport torch.optim as optimimport torch.utils.datafrom torchvision import transforms, datasetsimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.metrics import confusion_matriximport seaborn as snstransform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5 , ), (0.5 , ))]) def include_digits (dataset, included_digits ): including_indices = [idx for idx in range (len (dataset)) if dataset[idx][1 ] in included_digits] return torch.utils.data.Subset(dataset, including_indices) def exclude_digits (dataset, excluded_digits ): including_indices = [idx for idx in range (len (dataset)) if dataset[idx][1 ] not in excluded_digits] return torch.utils.data.Subset(dataset, including_indices) def plot_distribution (dataset, title ): labels = [data[1 ] for data in dataset] unique_labels, label_counts = torch.unique(torch.tensor(labels), return_counts=True ) plt.figure(figsize=(4 , 2 )) counts_dict = {label.item(): count.item() for label, count in zip (unique_labels, label_counts)} all_labels = np.arange(10 ) all_label_counts = [counts_dict.get(label, 0 ) for label in all_labels] plt.bar(all_labels, all_label_counts) plt.title(title) plt.xlabel("Digit" ) plt.ylabel("Count" ) plt.xticks(all_labels) plt.show() def compute_confusion_matrix (model, test_set ): true_labels = [] predicted_labels = [] for Image, label in test_set: output = model(Image.unsqueeze(0 )) _, predicted = torch.max (output, 1 ) true_labels.append(label) predicted_labels.append(predicted.item()) true_labels = np.array(true_labels) predicted_labels = np.array(predicted_labels) cm = confusion_matrix(true_labels, predicted_labels) return cm train_set = datasets.MNIST("./MNIST_data/" , download=True , train=True , transform=transform) total_length = len (train_set) split_size = total_length // 3 torch.manual_seed(42 ) part_1, part_2, part_3 = random_split(train_set, [split_size] * 3 ) part_1 = exclude_digits(part_1, excluded_digits=[1 , 3 , 7 ]) part_2 = exclude_digits(part_2, excluded_digits=[2 , 4 , 6 ]) part_3 = exclude_digits(part_3, excluded_digits=[4 , 6 , 9 ]) plot_distribution(part_1, 'Part 1' ) plot_distribution(part_2, 'Part 2' ) plot_distribution(part_3, 'Part 3' )
训练模型 :定义SimpleModel模型,并初始化化三个模型实例。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 def train_model (model, train_set ): batch_size = 64 num_epochs = 10 train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True ) criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(model.parameters(), lr=0.01 , momentum=0.9 ) model.train() for epoch in range (num_epochs): running_loss = 0.01 for inputs, labels in train_loader: optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() running_loss += loss.item() print (f"Epoch {epoch + 1 } : Loss = {running_loss / len (train_loader)} " ) print ("Training complete" ) class SimpleModel (nn.Module): def __init__ (self ): super (SimpleModel, self).__init__() self.fc = nn.Linear(784 , 128 ) self.relu = nn.ReLU() self.out = nn.Linear(128 , 10 ) def forward (self, x ): x = torch.flatten(1 , x) x = self.fc(x) x = self.relu(x) x = self.out(x) return x model1 = SimpleModel() train_model(model1, part1) model2 = SimpleModel() train_model(model2, part2) model3 = SimpleModel() train_model(model3, part3)
结果输出为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 Epoch 1: Loss = 0.5065847117637479 Epoch 2: Loss = 0.24505144885390304 Epoch 3: Loss = 0.19136880657977834 Epoch 4: Loss = 0.15813053476533223 Epoch 5: Loss = 0.13172560036286365 Epoch 6: Loss = 0.11020874739403641 Epoch 7: Loss = 0.09594884521843389 Epoch 8: Loss = 0.08343400360990401 Epoch 9: Loss = 0.07082434464783169 Epoch 10: Loss = 0.06130250348965096 Training complete Epoch 1: Loss = 0.5141205594174938 Epoch 2: Loss = 0.24732008437859956 Epoch 3: Loss = 0.20709553339778014 Epoch 4: Loss = 0.16869308433031927 Epoch 5: Loss = 0.14205218129574435 Epoch 6: Loss = 0.12770977104397396 Epoch 7: Loss = 0.11071020946195816 Epoch 8: Loss = 0.10024585863294666 Epoch 9: Loss = 0.08707036653882291 Epoch 10: Loss = 0.07732414840035923 Training complete Epoch 1: Loss = 0.5017504044776564 Epoch 2: Loss = 0.2650307032734424 Epoch 3: Loss = 0.20769038726886113 Epoch 4: Loss = 0.1649025677050556 Epoch 5: Loss = 0.1395505760965852 Epoch 6: Loss = 0.12056233629114455 Epoch 7: Loss = 0.10090371655182795 Epoch 8: Loss = 0.09096335670969506 Epoch 9: Loss = 0.07602779161671662 Epoch 10: Loss = 0.07067198011923481 Training complete
评估模型 :调用valuate_model函数在整个测试数据集和测试数据集的特定子集上评估上面定义的每个模型(model1、model2、model3)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 def evaluate_model (model, test_set ): model.eval () correct = 0 total = 0 total_loss = 0 test_loader = DataLoader(test_set, batch_size=64 , shuffle=False ) criterion = nn.CrossEntropyLoss() with torch.no_grad(): for inputs, labels in test_loader: outputs = model(inputs) _, predicted = torch.max (outputs.data, 1 ) total += labels.size(0 ) correct += (predicted == labels).sum ().item() loss = criterion(outputs, labels) total_loss += loss.item() accuracy = correct / total average_loss = total_loss / len (test_loader) return average_loss, accuracy testset = datasets.MNIST( "./MNIST_data/" , download=True , train=False , transform=transform ) testset_137 = include_digits(testset, included_digits=[1 , 3 , 7 ]) testset_246 = include_digits(testset, included_digits=[2 , 4 , 6 ]) testset_469 = include_digits(testset, included_digits=[4 , 6 , 9 ]) _, accuracy1 = evaluate_model(model1, testset) _, accuracy1_on_137 = evaluate_model(model1, testset_137) print (f"Model 1-> Test Accuracy on all digits: {accuracy1:.4 f} , " f"Test Accuracy on [1,3,7]: {accuracy1_on_137:.4 f} " )_, accuracy2 = evaluate_model(model2, testset) _, accuracy2_on_246 = evaluate_model(model2, testset_246) print (f"Model 2-> Test Accuracy on all digits: {accuracy2:.4 f} , " f"Test Accuracy on [2,4,6]: {accuracy2_on_246:.4 f} " )_, accuracy3 = evaluate_model(model3, testset) _, accuracy3_on_469 = evaluate_model(model3, testset_469) print (f"Model 3-> Test Accuracy on all digits: {accuracy3:.4 f} , " f"Test Accuracy on [4,6,9]: {accuracy3_on_469:.4 f} " )
结果输出为:
1 2 3 Model 1-> Test Accuracy on all digits: 0.6571, Test Accuracy on [1,3,7]: 0.0000 Model 2-> Test Accuracy on all digits: 0.6748, Test Accuracy on [2,4,6]: 0.0000 Model 3-> Test Accuracy on all digits: 0.6845, Test Accuracy on [4,6,9]: 0.0000
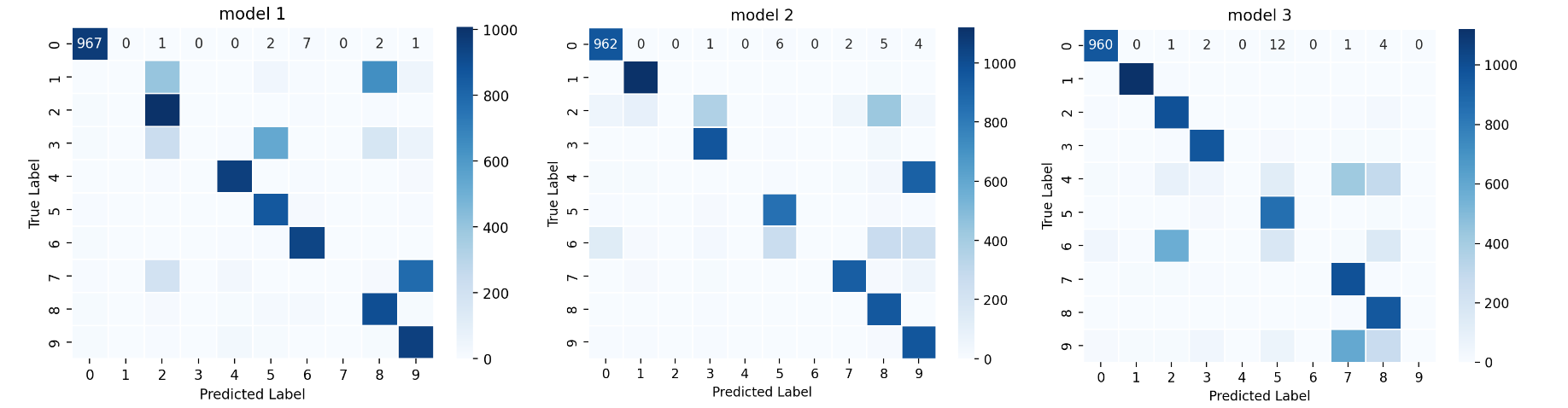
使用compute_confusion_matrix方法,查看刚刚训练的三个模型的“混淆矩阵 ”来分析:
1 2 3 4 5 6 7 def plot_confusion_matrix (cm, title ): plt.figure(figsize=(6 , 4 )) sns.heatmap(cm, annot=True , cmap="Blues" , fmt='d' , linewidths=.5 ) plt.title(title) plt.xlabel('Predicted Label' ) plt.ylabel('True Label' ) plt.show()
联邦学习(算法)
初始化 :初始化数据中心的全局模型。通信轮次 (communication round):每一轮通信—— 数据中心将全局模型发送给所有参与的客户端;并且每一个客户端都收到了全局模型。客户端训练&更新模型 :每一个参与的客户端—— 在本地数据集上客户端训练接收到的模型;本地更新的模型通过客户端发送到数据中心。模型聚合 :数据中心聚合利用聚合算法 从所有客户端收到的更新模型。收敛检查 :如果满足收敛标准,则进行FL处理;如果不满足,则进行下一个通信轮次。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 from flwr.common.logger import console_handler, logfrom flwr.common import Metrics, NDArrays, Scalarfrom flwr.client import Client, ClientApp, NumPyClientfrom flwr.common import ndarrays_to_parameters, Contextfrom flwr.server import ServerApp, ServerConfigfrom flwr.server import ServerAppComponentsfrom flwr.server.strategy import FedAvgfrom flwr.simulation import run_simulationfrom collections import OrderedDictfrom typing import List , Tuple , Dict , Optional def set_weights (net, parameters ): params_dict = zip (net.state_dict().keys(), parameters) state_dict = OrderedDict({k: torch.tensor(v) for k, v in params_dict}) net.load_state_dict(state_dict, strict=True ) def get_weights (net ): ndarrays = [val.cpu().numpy() for _, val in net.state_dict().items()] return ndarrays class FlowerClient (NumPyClient ): def __init__ (self, net, trainset, testset ): super ().__init__() self.net = net self.trainset = trainset self.testset = testset def fit (self, parameters, config ): set_weights(self.net, parameters) train_model(self.net, self.trainset) return get_weights(self.net), len (self.trainset), {} def evaluate (self, parameters: NDArrays, config: Dict [str , Scalar] ): set_weights(self.net, parameters) loss, accuracy = evaluate_model(self.net, self.testset) return loss, len (self.testset), {"accuracy" : accuracy} def client (context: Context ) -> Client: net = SimpleModel() partition_id = int (context.node_config['partition-id' ]) client_train = train_set[int (partition_id)] client_test = testset return FlowerClient(net=net, trainset=client_train, testset=client_test).to_client() client = ClientApp(client_fn=client) def evaluate (server_round, parameters, config ): net = SimpleModel() set_weights(net, parameters) _, accuracy = evaluate_model(net, testset) _, accuracy_137 = evaluate_model(net, testset_137) _, accuracy_246 = evaluate_model(net, testset_246) _, accuracy_469 = evaluate_model(net, testset_469) log(INFO, "test accuracy on all digitss: %.4f" , accuracy) log(INFO, "test accuracy on [1,3,7]: %.4f" , accuracy_137) log(INFO, "test accuracy on [2,4,6]: %.4f" , accuracy_246) log(INFO, "test accuracy on [4,6,9] %.4f" , accuracy_469) if server_round == 3 : cm = compute_confusion_matrix(net, testset) plot_confusion_matrix(cm, "Final Global Model" ) net = SimpleModel() params = ndarrays_to_parameters(get_weights(net)) def server (context: Context ): strategy = FedAvg(fraction_fit=1.0 , fraction_evaluate=0.0 , initial_parameters=params, evaluate_fn=evaluate) config = ServerConfig(num_rounds=3 ) return ServerAppComponents(strategy=strategy, config=config) server = ServerApp(server_fn=server) run_simulation(server_app=server, client_app=client, num_supernodes=3 , backend_config=backend_setup)





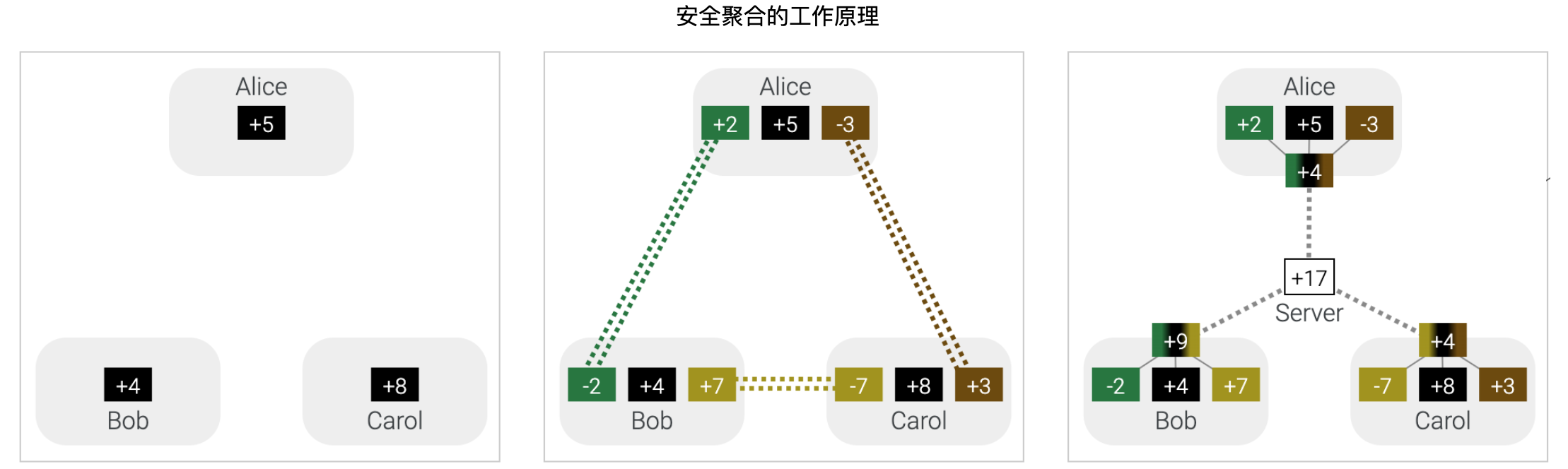
,在保护隐私的同时生成共享模型")