CLIP模型—探析(深度学习)
介绍
CLIP(Contrastive Language-Image Pretraining)是由OpenAI开发的一种多模态学习模型,旨在通过自然语言描述来学习视觉概念。CLIP的核心在于将图像和文本嵌入到一个共同的语义空间中,从而实现跨模态的理解和应用。
CLIP工作原理可以分为以下几个步骤:
- 数据收集与预训练:
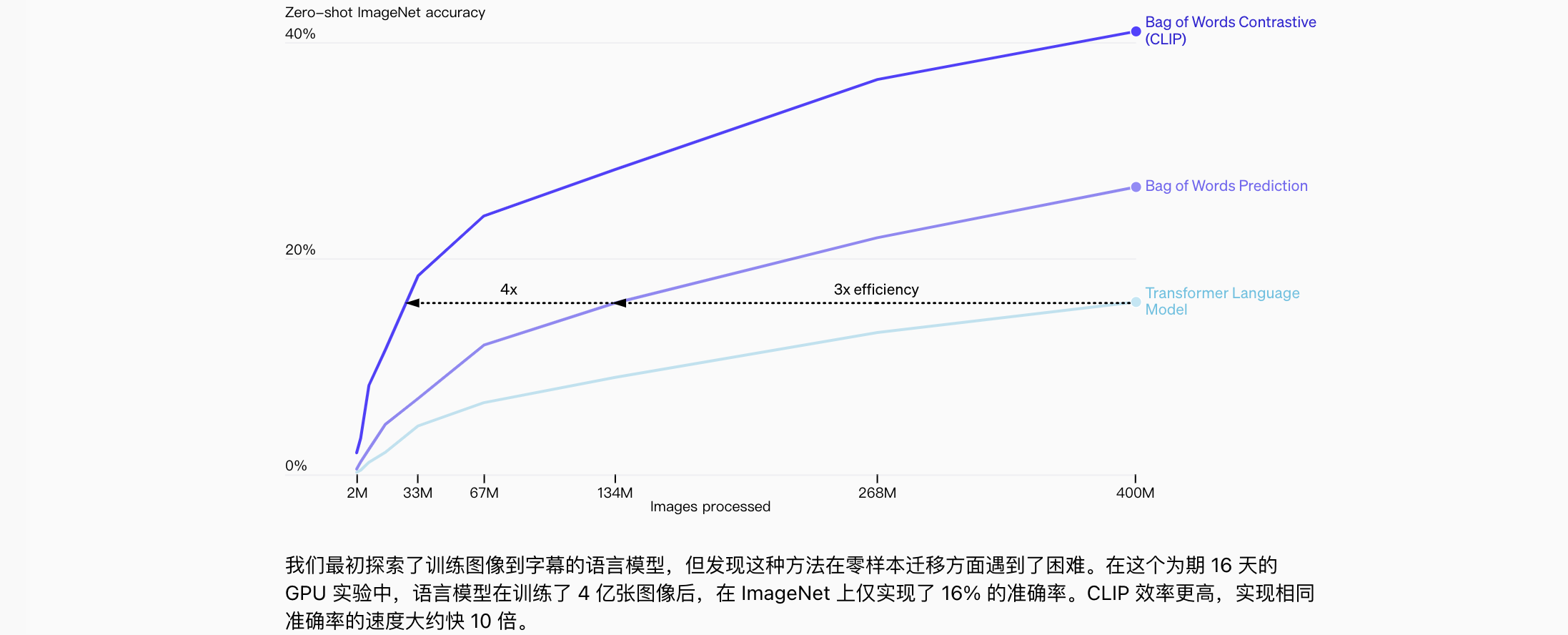
CLIP在互联网上收集了4亿对图像和文本数据进行预训练。模型通过对比学习,将图像和文本映射到一个共享的向量空间中,使得相关的图像和文本靠近,不相关的则远离。 - 编码器:使用图像编码器(如
ResNet或Vision Transformer)和文本编码器(如CBOW或Text Transformer)分别对图像和文本进行编码。 - 相似度计算:计算图像和文本向量之间的余弦相似度,并通过对比损失函数优化模型,使得正样本对的相似度较高,负样本对的相似度较低。
- 零样本预测:训练好的模型可以直接进行零样本预测,即无需额外训练,直接使用自然语言标签进行图像分类或检索。
CLIP的优势:
高效的无监督学习:利用大量的图像-文本对进行训练,减少了对标注数据的依赖。
![]()
广泛的应用场景:在图像分类、检索和生成等任务中表现出色。
灵活性和通用性:能够在多个任务和数据集上实现零样本学习,包括细粒度对象分类、地理定位、视频中的动作识别和
OCR等任务表现出较强的通用性。
原理
虽然CLIP通常能很好地识别常见物体,但它在更抽象或系统的任务(例如计算图像中的物体数量)和更复杂的任务(例如预测照片中最近的汽车有多近)上表现不佳。在这两个数据集上,零样本CLIP仅比随机猜测略胜一筹。与特定任务模型相比,零样本CLIP在非常细粒度的分类上也表现不佳,例如区分汽车型号、飞机变体或花卉种类。CLIP对其预训练数据集中未涵盖的图像的泛化能力仍然较差。例如,尽管CLIP学习了一个功能强大的OCR系统,但在对MNIST数据集中的手写数字进行评估时,零样本CLIP的准确率仅为88%,远低于人类在该数据集上的99.75%。最后观察到CLIP的零样本分类器可能对措辞或短语很敏感,有时需要反复试验的才能取得良好效果。
对。在测试时,学习到的文本编码器通过嵌入目标数据集类别的名称(或描述)来合成零样本线性分类器。")
CLIP采用了两种不同的图像编码器架构:一种是ResNet-50作为图像编码的基础架构(注意力池替换了全局平均池);另一种是Vision Transformer(ViT),在位置嵌入中添加了一层(层归一化)。
1 | # image_encoder - ResNet or Vision Transformer |
CLIP采用了两种不同的文本编码器架构:一种是CBOW架构;另一种是Text Transformer架构。文本编码器是一个Transformer模型(修改于Radford)。使用了63M的参数、12层、512的维度模型,带有8个注意力头。对文本用小写字节对编码(BPE)进行分词,词汇量为49,152。为了提高计算效率,最大序列长度上限为76。文本序列用了[SOS]和[EOS]两个token,Transformer最高层在[EOS]token处的激活被视为文本的特征表示,该文本进行层归一化,然后线性投影到多模态嵌入空间中。虽然之前的计算机视觉研究通常对于单独增加宽度(Mahajan等人,2018)或深度来扩展模型,但对于ResNet图像编码器,采用了Tan & Le (2019)的方法,该方法发现在宽度、深度和分辨率上分配额外的计算要优于只将其分配给模型的一个维度。虽然Tan & Le (2019)调整了分配给其EfficientNet架构的每个维度的计算比例,但平等地分配额外的计算以增加模型的宽度、深度和分辨率。对于文本编码器,将模型的宽度缩放为与ResNet宽度的计算增加成比例,并且根本不缩放深度,发现CLIP的性能对文本编码器的容量不太敏感。
代码实现(Python & PyTorch)
分词器实现:
1 |
|
抗混叠步进卷积(Anti-aliasing strided convolutions)是一种改进卷积神经网络中下采样操作的技术,旨在提高网络的平移不变性和泛化能力。传统的卷积神经网络中,常用的下采样方法(如最大池化、步进卷积等)可能导致混叠(aliasing)效应。这种效会使网络对输入的微小平移变得敏感,从而降低网络的平移不变性和泛化能力。抗混叠步进卷积(Anti-aliasing strided convolutions)的核心思想是在下采样操作之前应用低通滤波器。这一做法借鉴了经典信号处理理论中的采样定理,通过滤除高频成分来防止混叠。实现步骤:1.密集评估卷积操作;应用低通滤波器(模糊核);子采样(步进)。优势:提高平移不变性:使网络对输入图像的小幅平移更加稳定;改善泛化能力:减少混叠伪影,提高网络应对小型图像变换的能力;兼容现有架构:可以轻松集成到现有的CNN架构中;可调节平滑度:通过改变模糊核的大小,可以调整抗混叠的程度。研究表明,在多种常用架构(如ResNet、DenseNet、MobileNet等)中应用这种技术,可以提高ImageNet分类的准确率,并增强网络对输入扰动的鲁棒性。
ModifiedResNet类与torchvision类似,但包含以下变化:现在有3个“stem”卷积,而不是1个,并且使用平均池(average pool)而不是最大池(max pool)。执行抗混叠步进卷积(Anti-aliasing strided convolutions),其中平均池(average pool)被添加到步幅大于1的卷积前面。最后的池化层是QKV注意力,而不是平均池(average pool)。
1 |
|
残差注意力块实现:
1 | # 层归一化类 |
图像编码器(Vision Transformer)代码实现:
1 |
|
CLIP类代码实现:
1 | class CLIP(nn.Module): |
构建CLIP模型:
1 |
|