Transformer模型—探析(深度学习)
介绍
Transformer是一种由Google团队在2017年提出的深度学习模型,专门用于自然语言处理(NLP)任务。它的核心机制是自注意力(Self-Attention)或缩放点积注意力(Scaled Dot-Product Attention),能够处理输入序列中的每个元素,并计算其与序列中其他元素的交互关系。这使得模型能够更好地理解序列中的上下文关系。
主要特点:
- 并行计算:
Transformer模型可以同时处理整个序列,而不像循环神经网络(RNN)那样需要逐个处理序列中的元素。这使得模型能够更好地利用现代硬件的并行计算能力。 - 捕捉长距离依赖关系:
Transformer模型能够直接处理序列中远距离的依赖关系。例如,在处理语言时,一个词的含义可能会受到很远处的其他词的影响。
Transformer模型主要由两个模块构成:
- 编码器(
Encoder):负责处理输入文本,为每个输入构造对应的语义表示。 - 解码器(
Decoder):负责生成输出,使用编码器输出的语义表示结合其他输入来生成目标序列。
这两个模块可以根据任务的需求单独使用:
- 纯编码器模型:适用于只需要理解输入语义的任务,例如句子分类、命名实体识别。
- 纯解码器模型:适用于生成式任务,例如文本生成。
- 编码器-解码器模型(或
Seq2Seq模型):适用于需要基于输入的生成式任务,例如翻译、摘要。
Transformer模型本质上都是预训练语言模型,大都采用自监督学习(Self-supervised learning)的方式在大量生语料上进行训练,也就是说,训练这些Transformer模型完全不需要人工标注数据。

编码器(Encoder)
输入嵌入(input embeding)
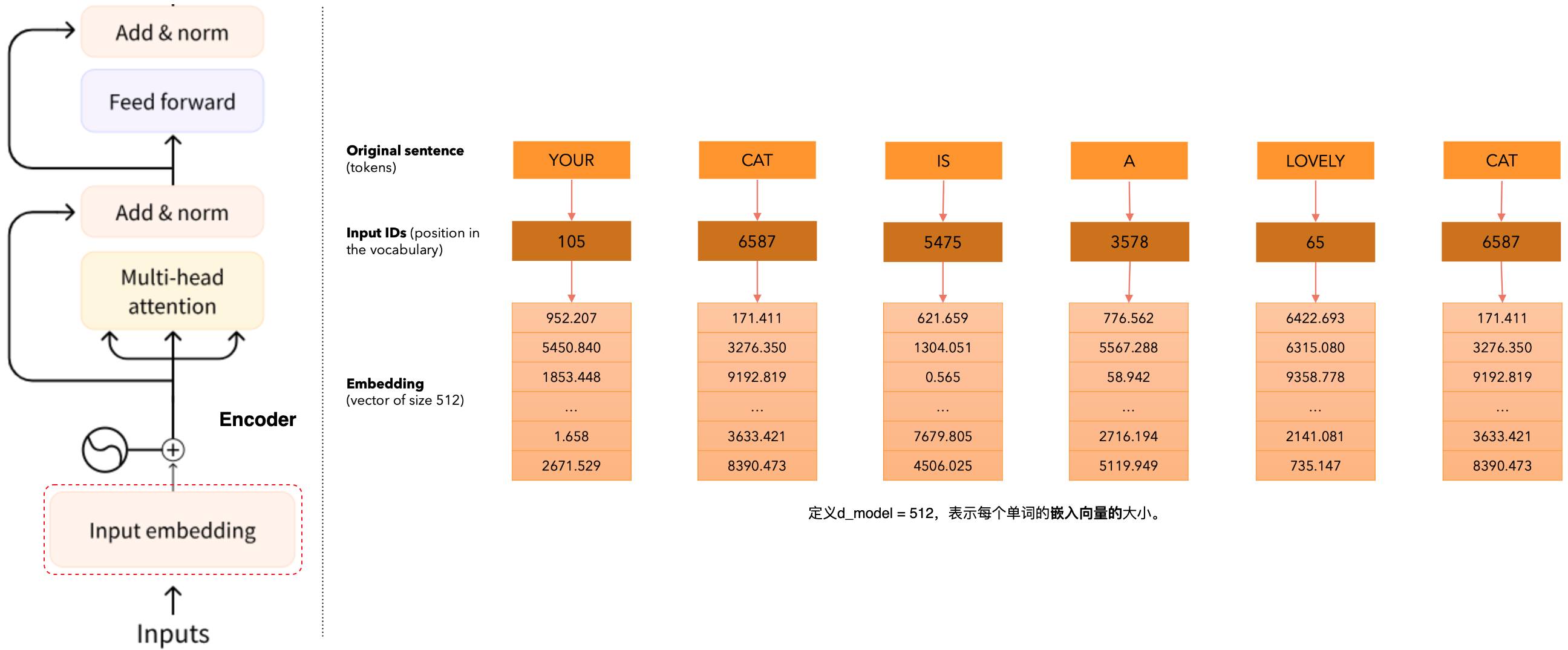
这里的编码器(encoder),从输入嵌入(input embeding)开始,什么是输入嵌入?首先让我们从”You CAT is a Lovely CAT.“句子开始。我们有6个单词组成的句子,目标就是将其转化为token。在这里我们将句子分割成单个单词(为了简单起见),每个单词表示为一个token,下一步我们将要使这些单词映射为数字。这些数字代表的含义是在词汇表的位置。假设有一个包含了所有单词的词汇表在训练集中,每个单词在词汇表中拥有一个位置,例如,”You“单词占据词汇表的位置是”105“,”CAT“单词占据词汇表的位置是”6587“等等,我们将这些数字(称为输入ID)映射到大小为512的向量中。这个向量是由512个数值组成。我们将相同单词映射到相同的嵌入,然而这个数值不是固定的。输入ID不会变化,因为词汇量是固定的,但嵌入会改变,随着模型的训练嵌入值会随着损失函数的需要而发生变化,因此输入嵌入基本上将单个单词映射到大小为512的嵌入。
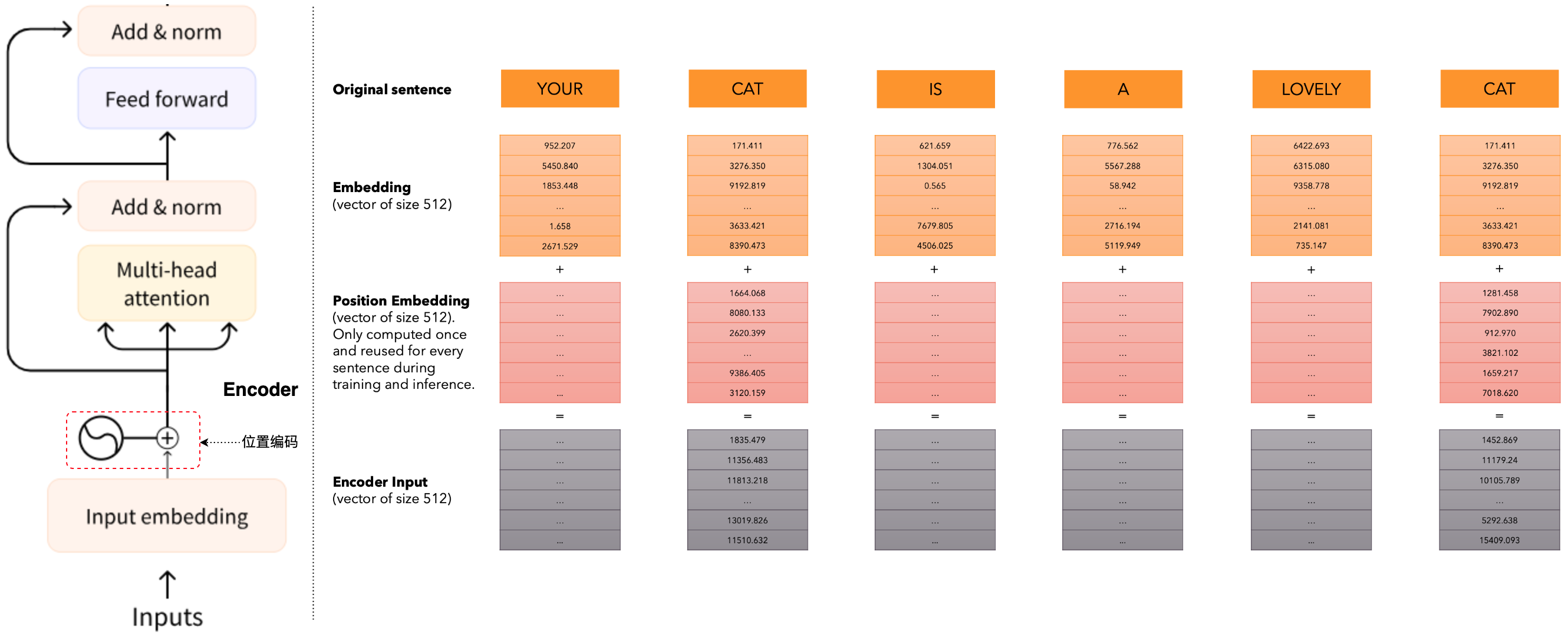
位置编码(positional encoding)
我们希望每个单词都包含一些关于其在句子中位置的信息。模型将彼此靠近的单词视为“close”,将距离较远的单词视为“distant”。我们希望位置编码表示模型可以学习的模式。位置编码称为向量的特殊向量,将其添加到嵌入中。再次看到的红色向量是大小为512的向量,该向量不会被学习,它只计算一次并且是固定的,位置编码(positional encoding)通过将位置信息编码成向量,然后将这些向量加到输入的词嵌入上。这样,每个token的表示就同时包含了语义信息和位置信息。具体步骤如下:
- 为每个位置生成一个位置编码向量。
- 将位置编码向量与相应位置的词嵌入向量相加。
- 将结果传递给
Transformer的后续层。
最常见的位置编码(positional encoding)实现方式是使用正弦和余弦函数,位置编码(positional encoding)的计算公式:
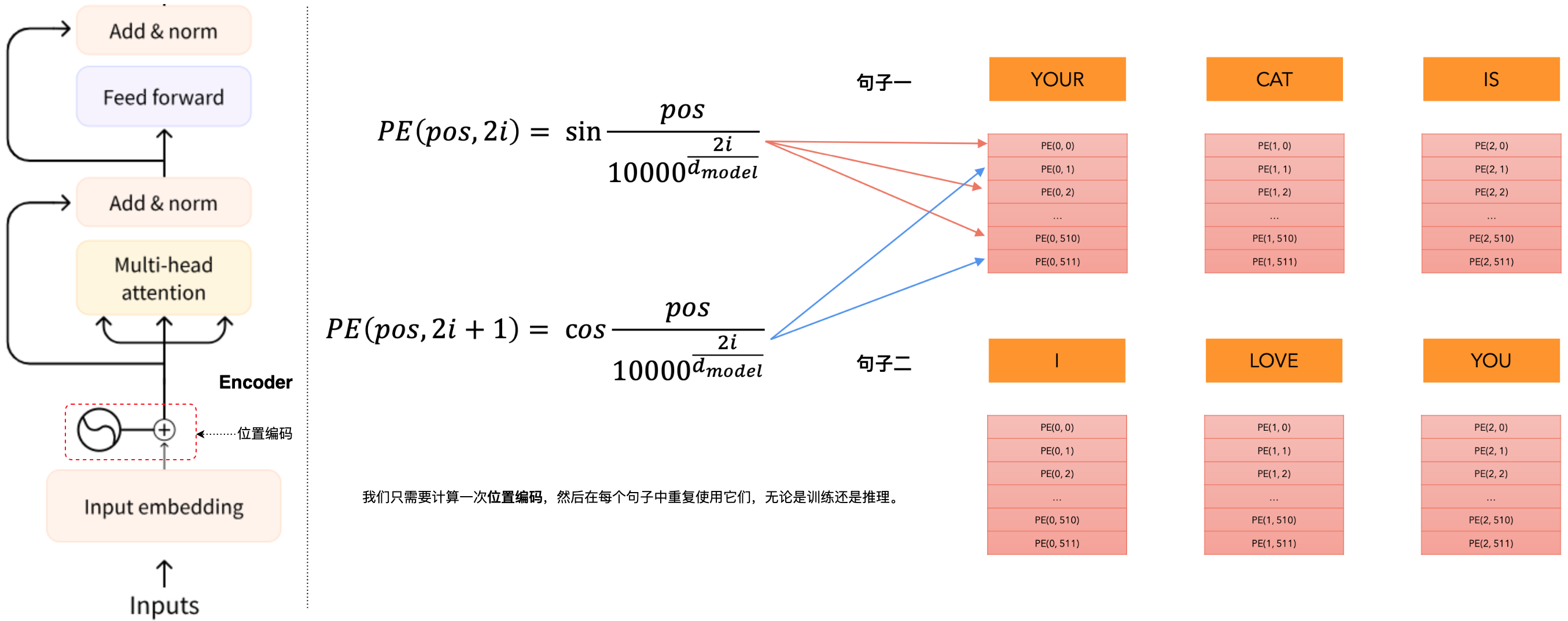
位置编码(positional encoding)的主要目的是解决Transformer模型中自注意力机制无法捕捉序列顺序信息的问题。由于Transformer模型并行处理输入序列,它本身并不能区分元素在序列中的位置。通过添加位置编码(positional encoding),模型能够:区分不同位置的相同token;为序列中的每个位置提供唯一的表示;使模型能够学习和利用序列中的位置信息。为什么是三角函数?像cos和sin这样的三角函数代表了模型识别为连续的模式,因此模型更容易看到相对位置。通过观察这些函数的图,我们还可以看到一个模式的规律。
自注意力(Self-Attention)
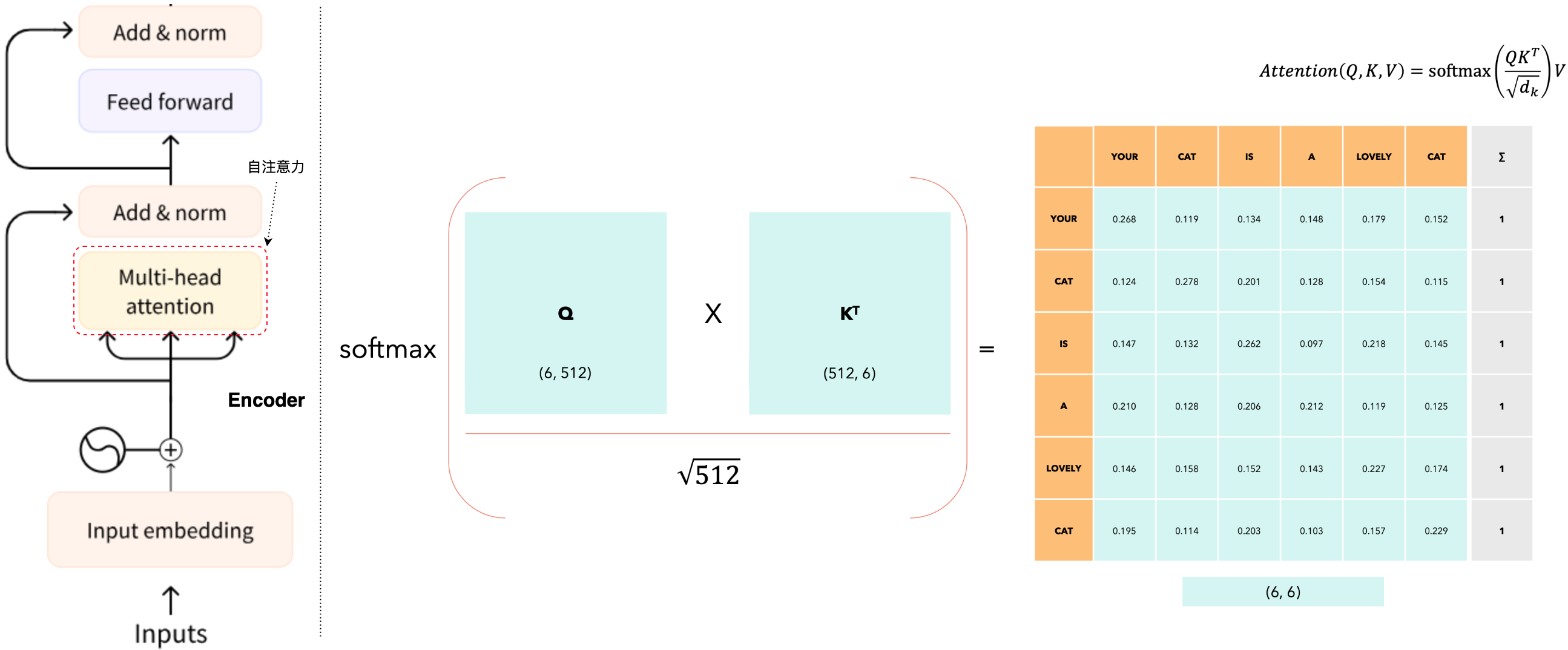
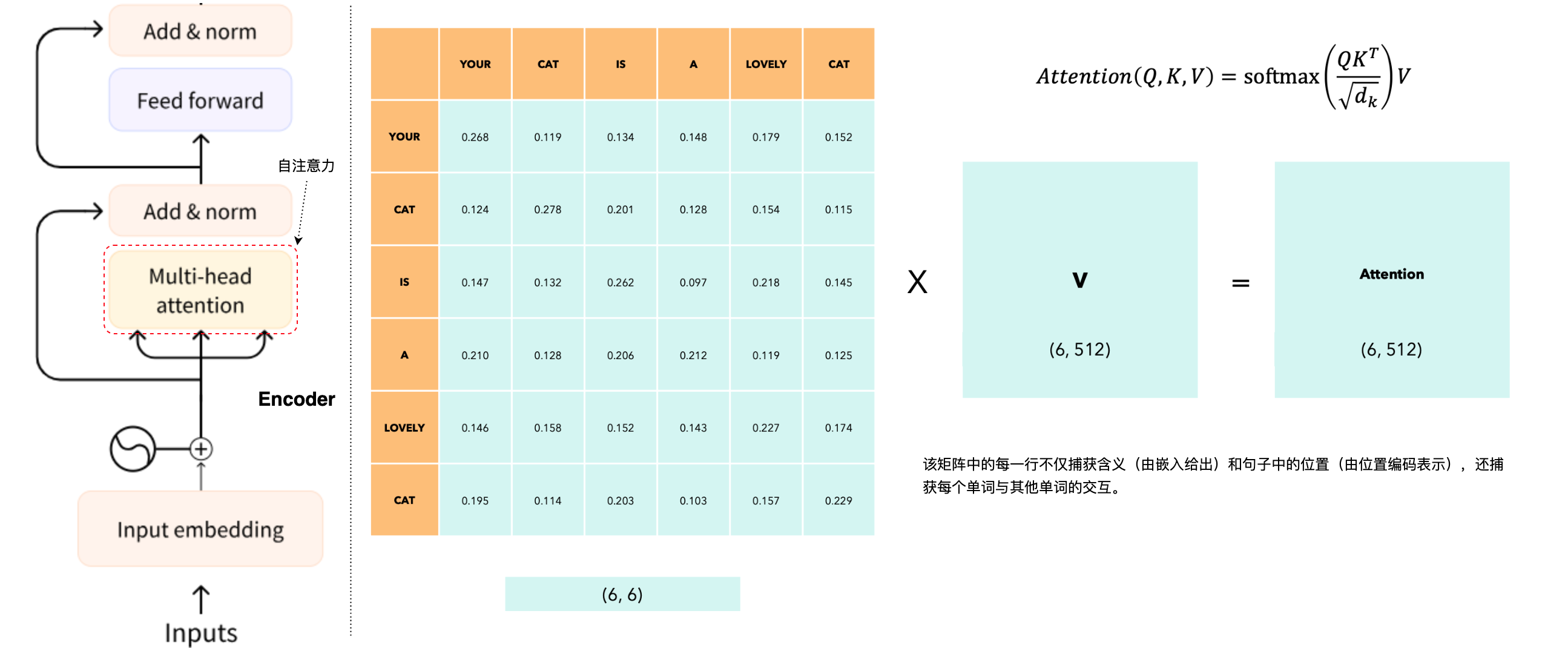
自注意力机制(Self-Attention)是Transformer模型的核心组件之一,广泛应用于自然语言处理(NLP)和计算机视觉等领域。它通过捕捉输入序列中元素之间的依赖关系和相互作用,来增强模型对上下文的理解能力。自注意力机制(Self-Attention)允许模型在处理每个输入元素时,参考同一序列中的其他元素,从而动态地调整各元素对输出的影响。这对于语言处理任务尤为重要,因为一个词的含义可能会因其上下文而变化。自注意力机制通过以下步骤实现:
- 生成查询(
Q)、键(K)和值(V)向量:输入序列中的每个元素通过三个不同的权重矩阵映射为查询(Query)、键(Key)和值(Value)向量。 - 计算注意力权重:通过计算查询向量和键向量的点积,得到注意力得分:
;为了稳定梯度,将得分除以 ,其中 是键向量的维度: ;使用 softmax函数对得分进行归一化,得到注意力权重: - 计算加权和:使用注意力权重对值向量进行加权求和,得到最终的输出:
在这个例子中,我们考虑序列长度Q)、键(K)和值(V)向量。
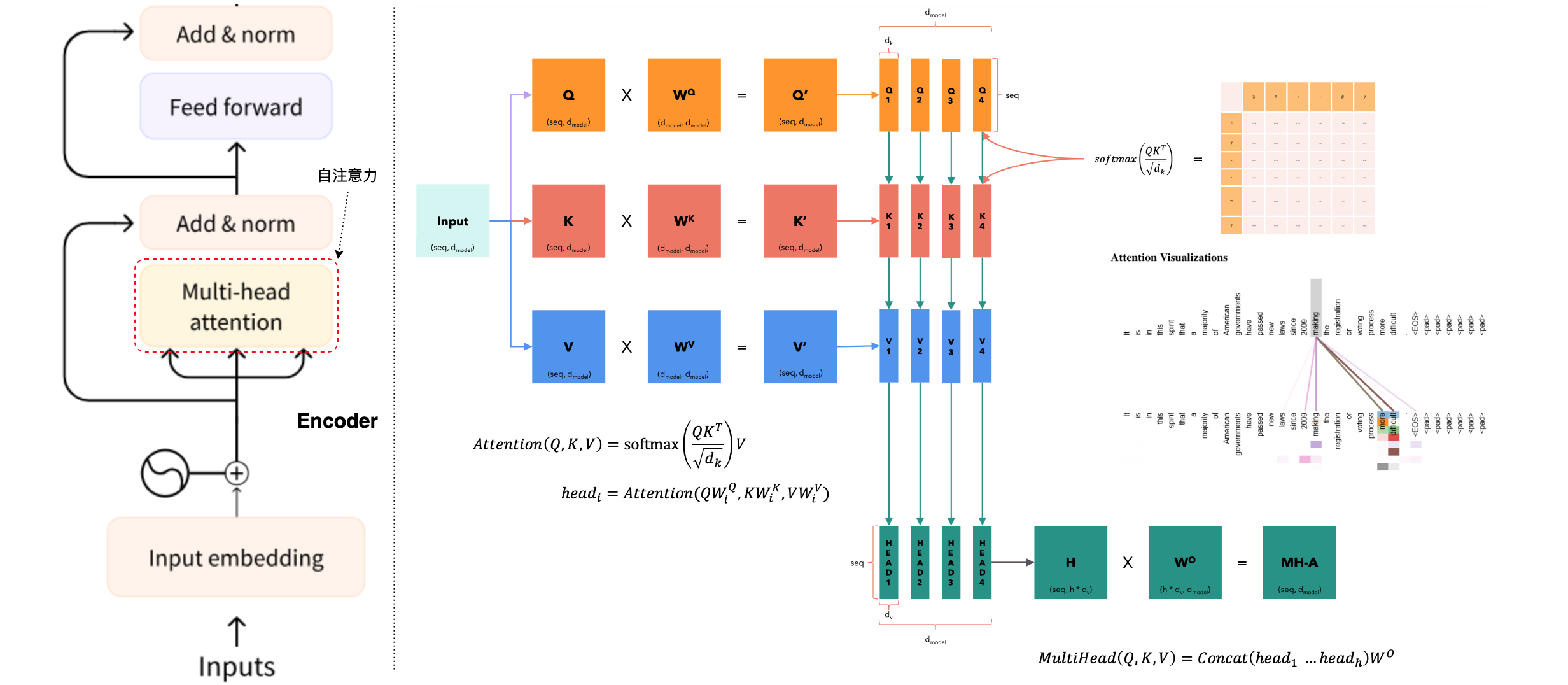
多头注意力(Multi-head Attention)
为了捕捉不同子空间上的信息,Transformer模型使用多头注意力机制(Multi-Head Attention)。具体步骤如下:
- 将查询、键和值向量分别映射到多个头(head)上,每个头有独立的权重矩阵。
- 对每个头独立计算注意力。
- 将所有头的输出拼接起来,并通过一个线性变换得到最终输出。
多头注意力机制允许模型在不同的子空间上关注不同的特征,从而提高模型的表达能力。
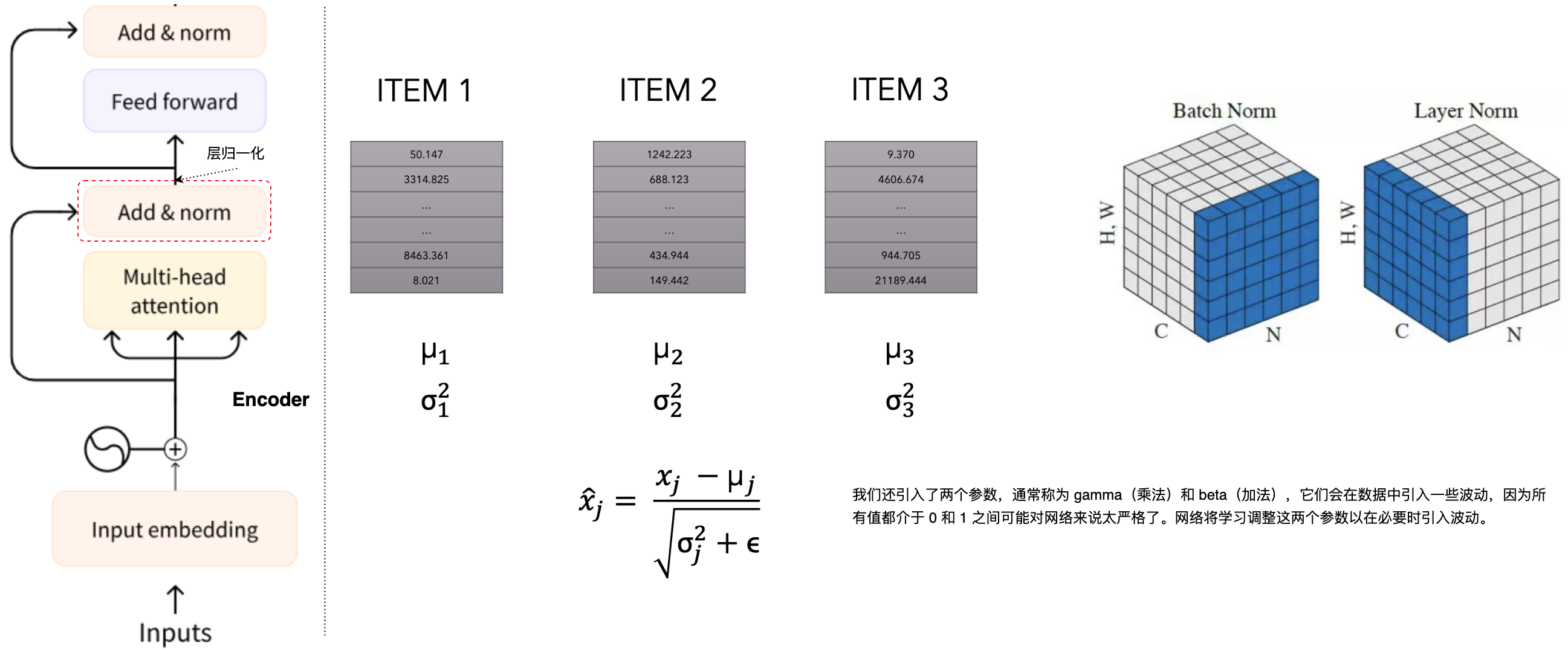
层归一化(layer normalization)
层归一化(layer normalization)是一种用于深度神经网络的正则化技术,旨在稳定和加速训练过程。它由Jimmy Lei Ba、Jamie Ryan Kiros 和 Geoffrey E. Hinton于2016年提出,特别适用于循环神经网络(RNN)和Transformer等序列模型。层归一化(layer normalization)通过对每个输入样本的所有神经元进行归一化,消除不同样本之间的依赖。这与Batch Normalization不同,后者是对一个mini-batch内的所有样本进行归一化。
层归一化(layer normalization)的具体步骤如下:
- 计算均值和方差:对于某一层的输入向量
计算其均值 和方差 。 - 归一化:使用计算得到的均值和方差,对输入进行归一化:
,其中, 是一个小常数,用于防止除零错误。 - 缩放和平移:引入可学习的缩放参数
和偏移参数 ,对归一化后的输入进行线性变换: 。
优点:
- 独立于批次大小:层归一化(
layer normalization)不依赖于mini-batch的大小,因此在小批次或在线学习(batch size为1)时也能有效工作。 - 一致性:在训练和测试时,层归一化(
layer normalization)的计算方式完全一致,不需要像Batch Normalization那样在训练和推理阶段使用不同的统计量。 - 适用于序列模型:层归一化(
layer normalization)特别适用于RNN和Transformer等序列模型,因为它可以在每个时间步独立计算归一化统计量。
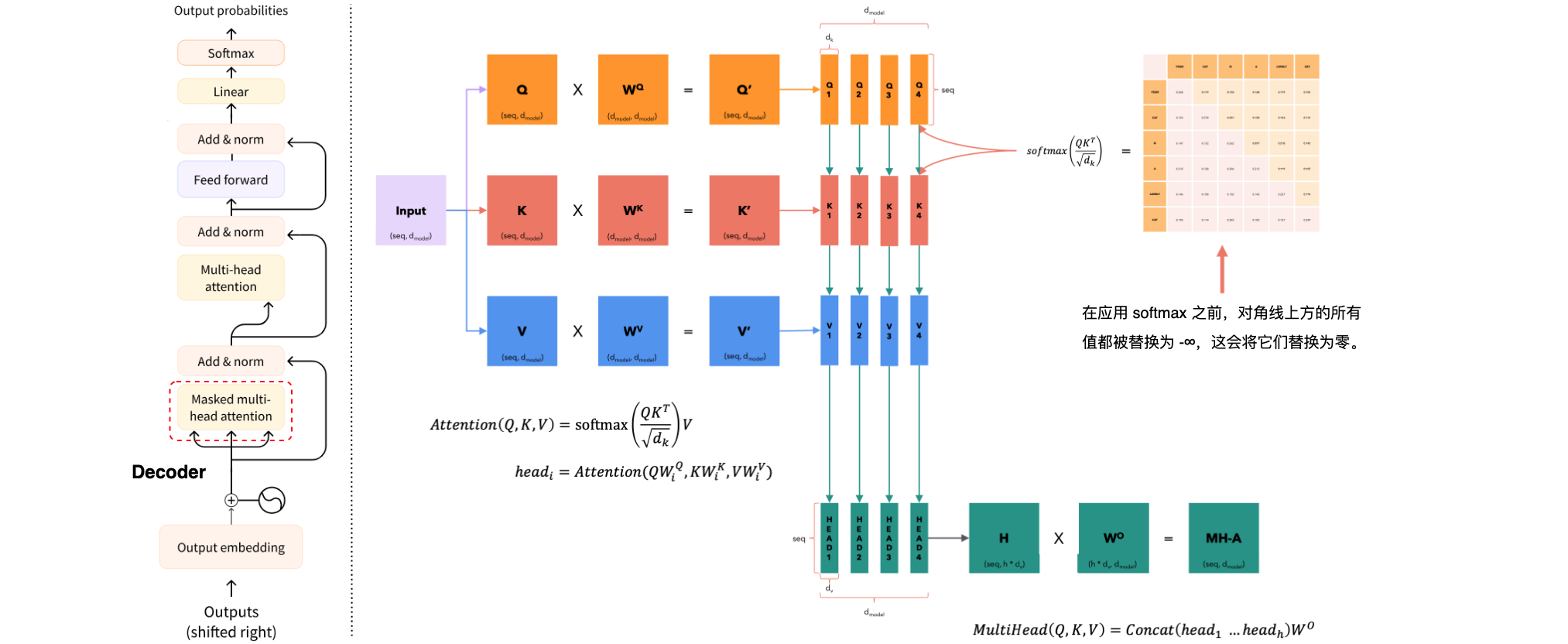
解码器(Decoder)
掩蔽多头注意力机制(Masked Multi-Head Attention)
掩蔽多头注意力机制(Masked Multi-Head Attention)是Transformer模型中的一种注意力机制,主要用于解码器部分,确保生成序列的顺序处理,并防止未来信息泄露。在解码过程中,掩蔽多头注意力机制(Masked Multi-Head Attention)通过掩码机制确保每个生成的token只能依赖于当前及之前的token,而不能看到未来的token。这种机制对于保持生成序列的顺序和一致性非常重要。掩蔽多头注意力机制(Masked Multi-Head Attention)的工作原理可以分为以下几个步骤:
- 输入嵌入:解码器接收整个目标序列的输入嵌入。
- 线性投影:对于每个注意力头,将输入嵌入投影到查询(
Query)、键(Key)和值(Value)向量上:, , 。 - 计算注意力得分:使用查询向量和键向量的缩放点积计算注意力得分:
。 - 生成掩码:生成一个上三角矩阵掩码,将未来的标记位置设置为负无穷大
,以确保这些位置在 softmax计算中权重为零: - 应用掩码:将掩码添加到注意力得分中:
- 计算注意力权重:使用
softmax函数对掩码后的注意力得分进行归一化,得到注意力权重:。 - 加权求和:使用注意力权重对值向量进行加权求和,得到最终的输出:
。
优点:
- 防止信息泄露:通过掩码机制,确保每个生成的标记只能依赖于当前及之前的标记,防止未来信息泄露。
- 顺序处理:保证生成序列的顺序处理,维护生成数据的顺序和一致性。
- 并行计算:尽管有掩码机制,掩蔽多头注意力机制(
Masked Multi-Head Attention)仍然可以并行计算,提高计算效率。
掩蔽多头注意力机制(Masked Multi-Head Attention)是Transformer模型中的关键组件,通过掩码机制确保生成序列的顺序处理和信息一致性。它在各种生成任务中发挥了重要作用,显著提高了模型的性能和效率。
我们的目标是让模型具有因果关系:这意味着某个位置的输出只能取决于之前位置的单词。模型必须无法看到未来的单词。
训练(Training)
训练(Training)是深度学习中的核心过程,旨在通过大量数据来优化模型参数,使模型能够准确地完成特定任务。训练过程主要包括以下几个步骤:1.数据准备;2.模型初始化;3.前向传播;4.计算损失;5.反向传播;6.参数更新;7.迭代优化。
举例,有一个句子(英语)“I love you very much”翻译成意大利语(“Ti amo molto“)。
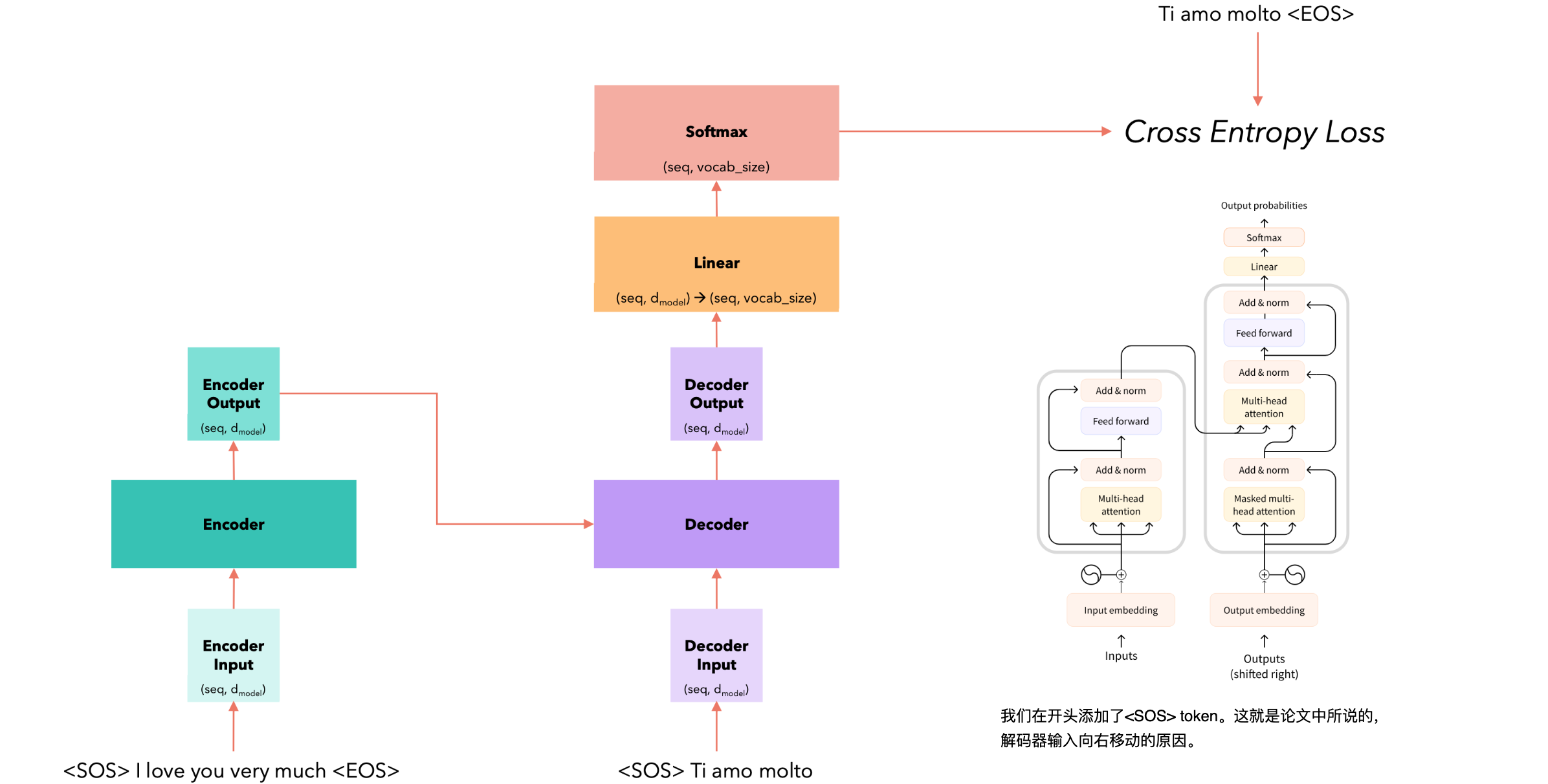
有两种常见的预训练任务:
- 基于句子的前个词来预测下一个词,因为输出依赖于过去和当前的输入,因此该任务被称为因果语言建模(
causal language modeling)。![]()
- 基于上下文(周围的词语)来预测句子中被遮盖掉的词语(
masked word),因此该任务被称为遮盖语言建模(masked language modeling)。![]()


推理(Inference)
举例,有一个句子(英语)“I love you very much”翻译成意大利语(“Ti amo molto“)。
Time Steps |
Task |
|---|---|
Time Steps = 1 |
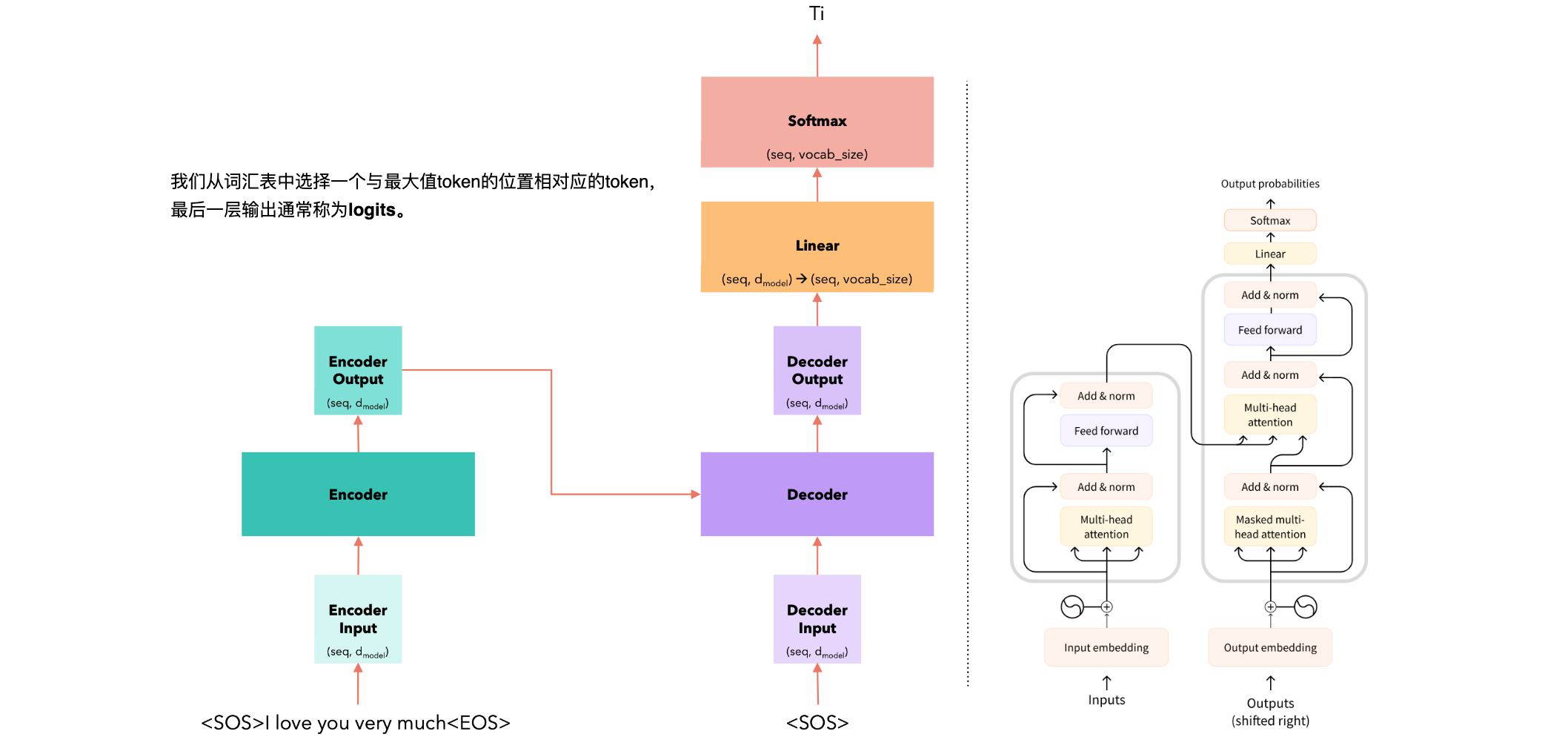 |
Time Steps = 2 |
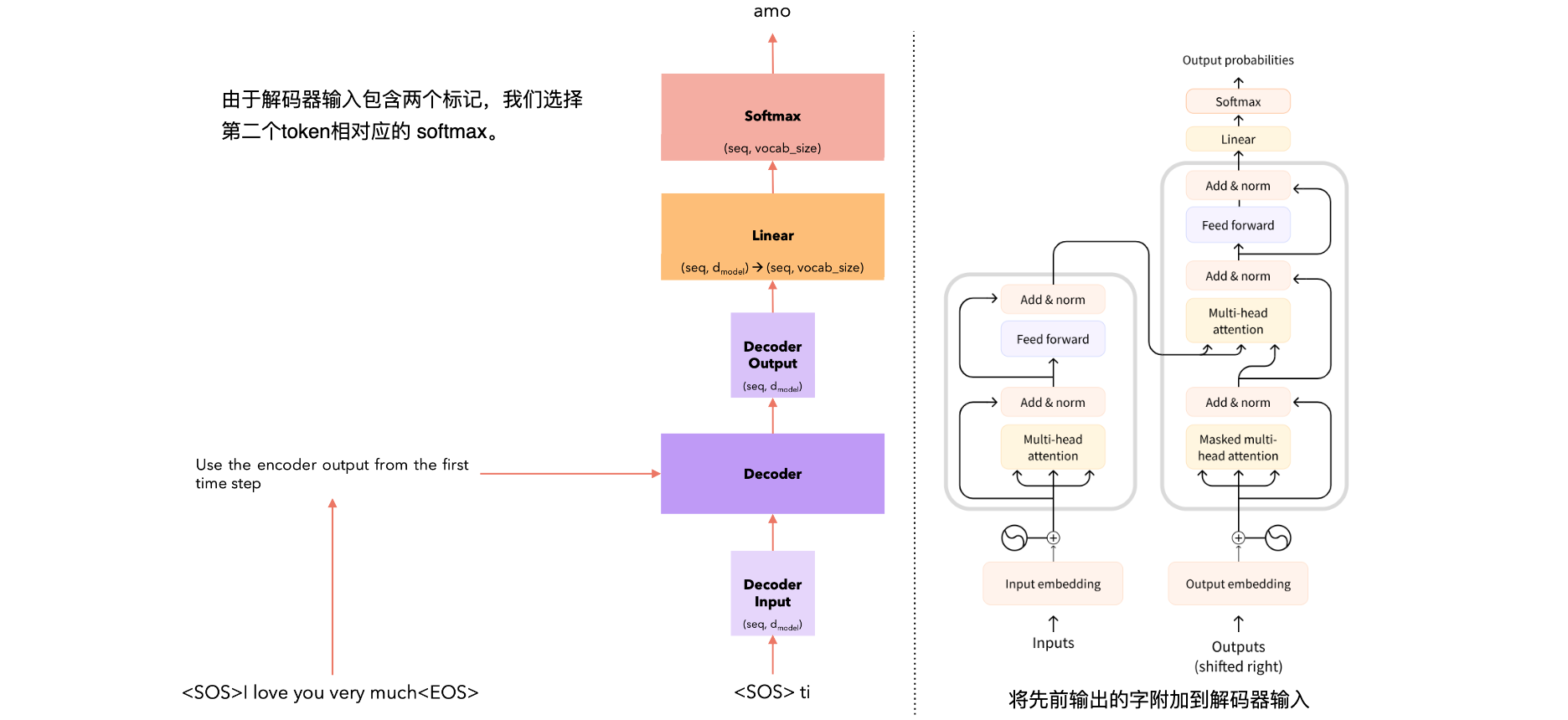 |
Time Steps = 3 |
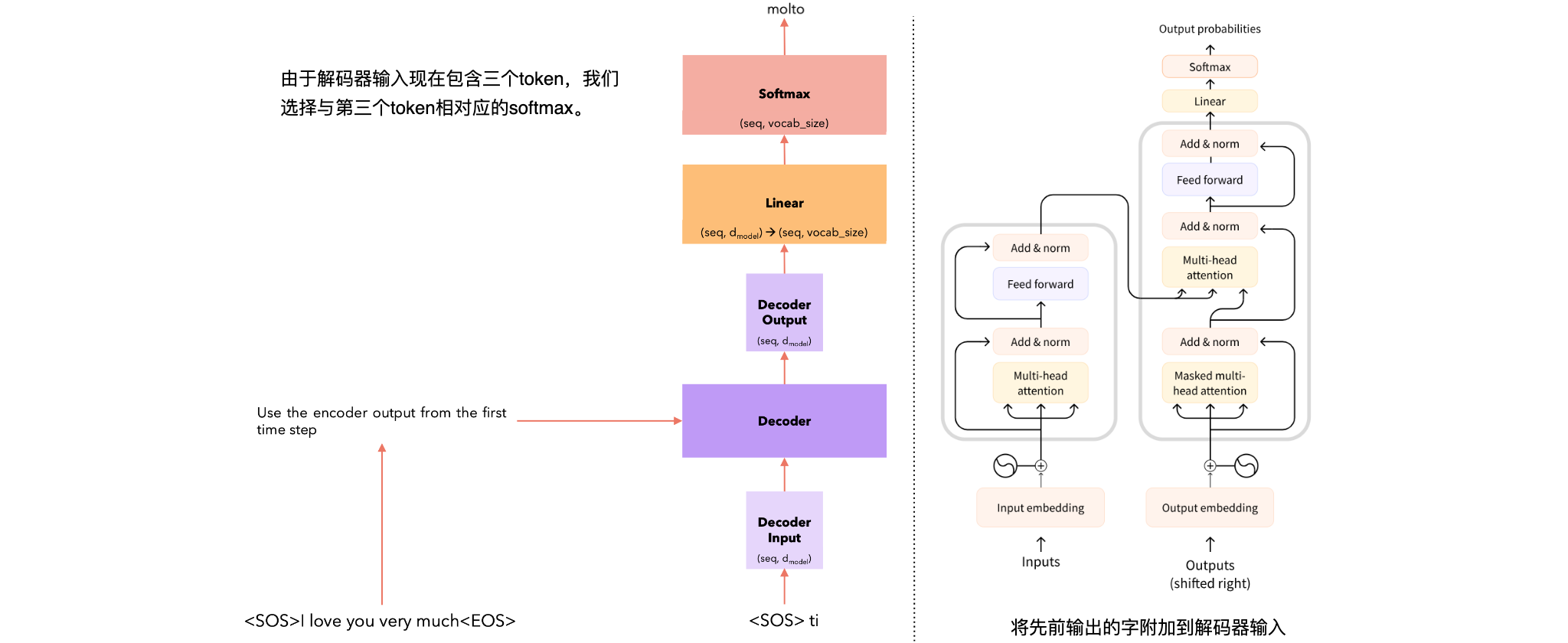 |
Time Steps = 4 |
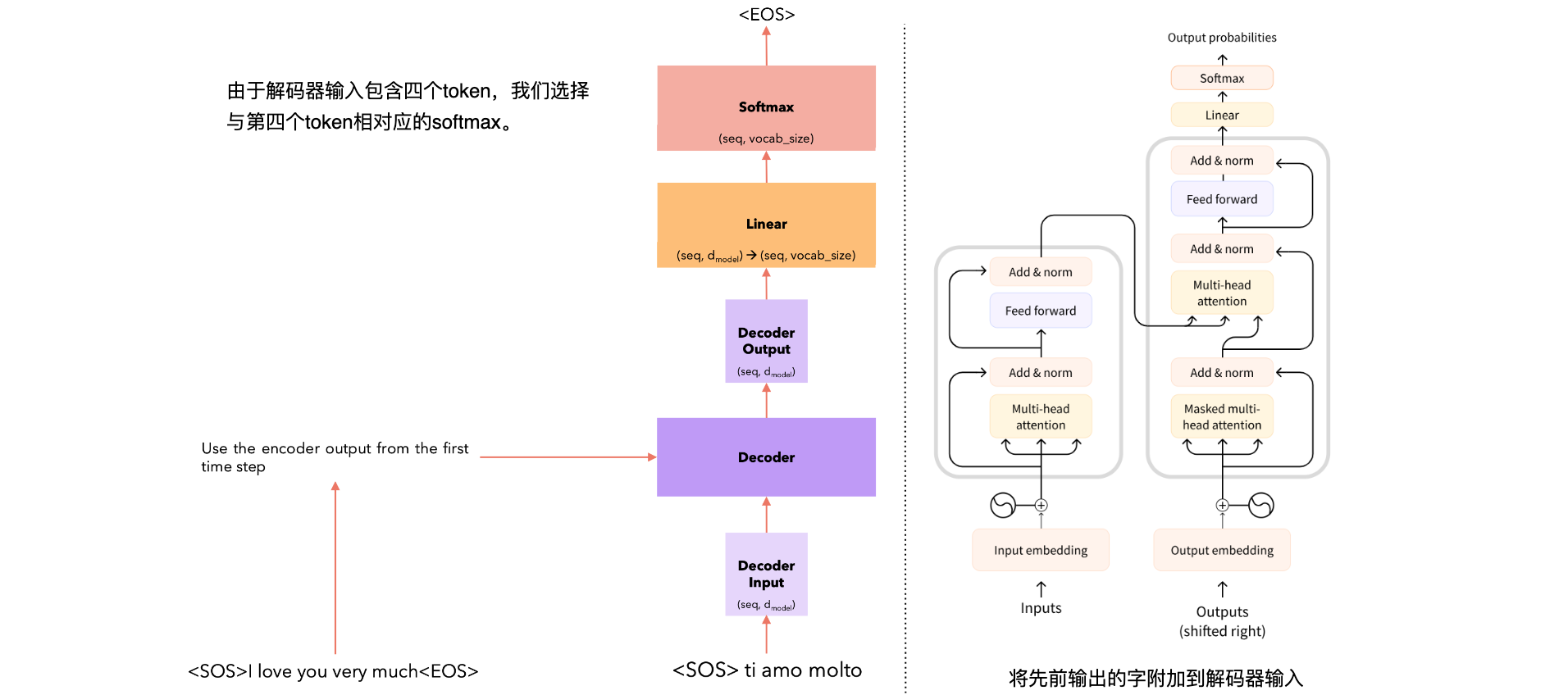 |
推理策略:我们在每一步都选择具有最大softmax值的单词。这种策略称为贪婪策略,通常效果不佳。更好的策略是在每个步骤中选择前B个单词,并评估每个单词的所有可能的下一个单词,并在每一步中保留前B个最可能的序列。这是Beam Search策略,通常效果更好。
代码实现(Python)
Layers/Blocks/Modules |
Coding |
|---|---|
嵌入输出(Input Embeding) |
 |
位置编码(Positional Encoder) |
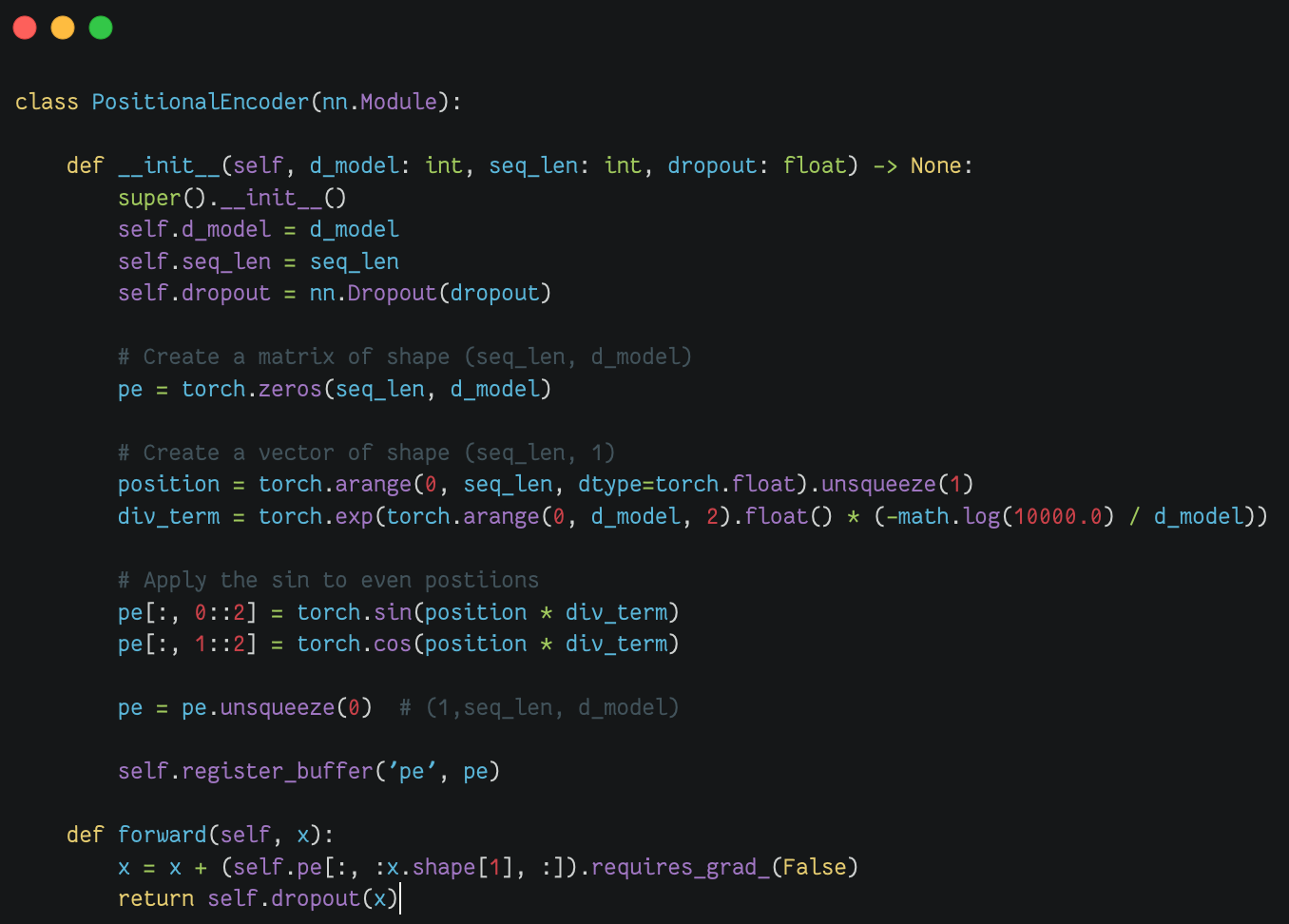 |
层归一化(Layer Normalization) |
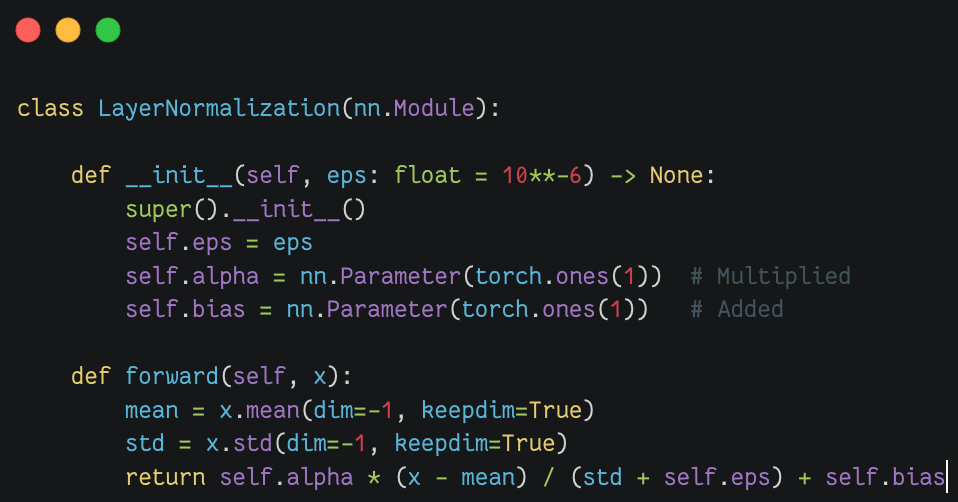 |
前馈块(Feed Forward Block) |
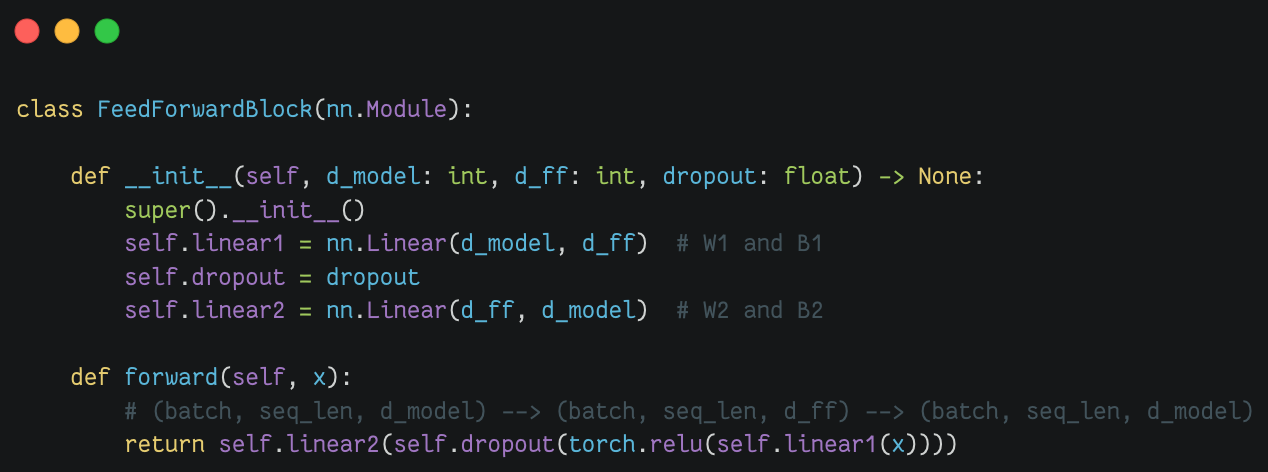 |
多头注意力块(Multi Head Attention Block) |
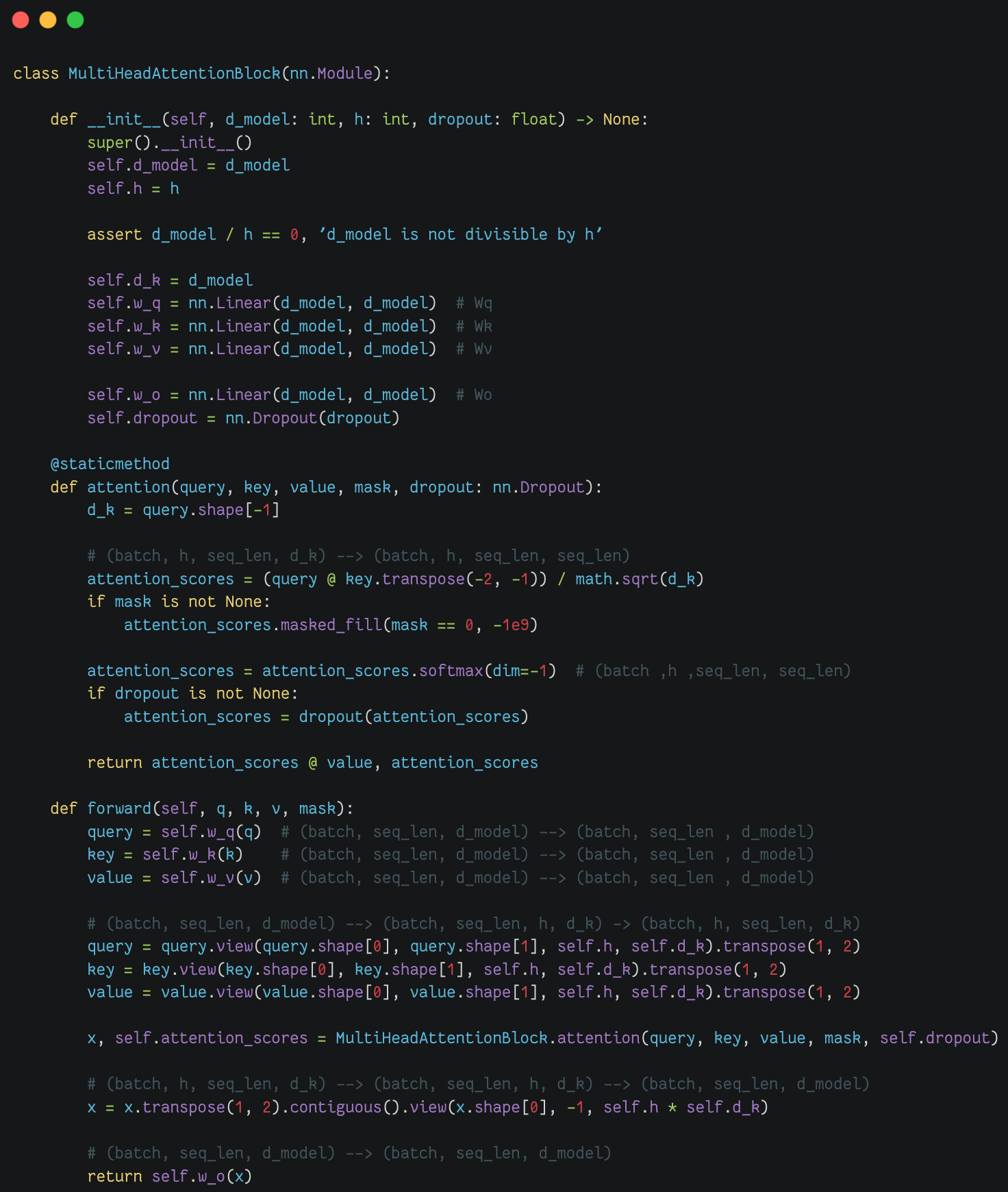 |
残差连接(Residual Connection) |
 |
编码块(Encoder Block) |
 |
编码器模块(Encoder) |
 |
解码器块(Decoder Block) |
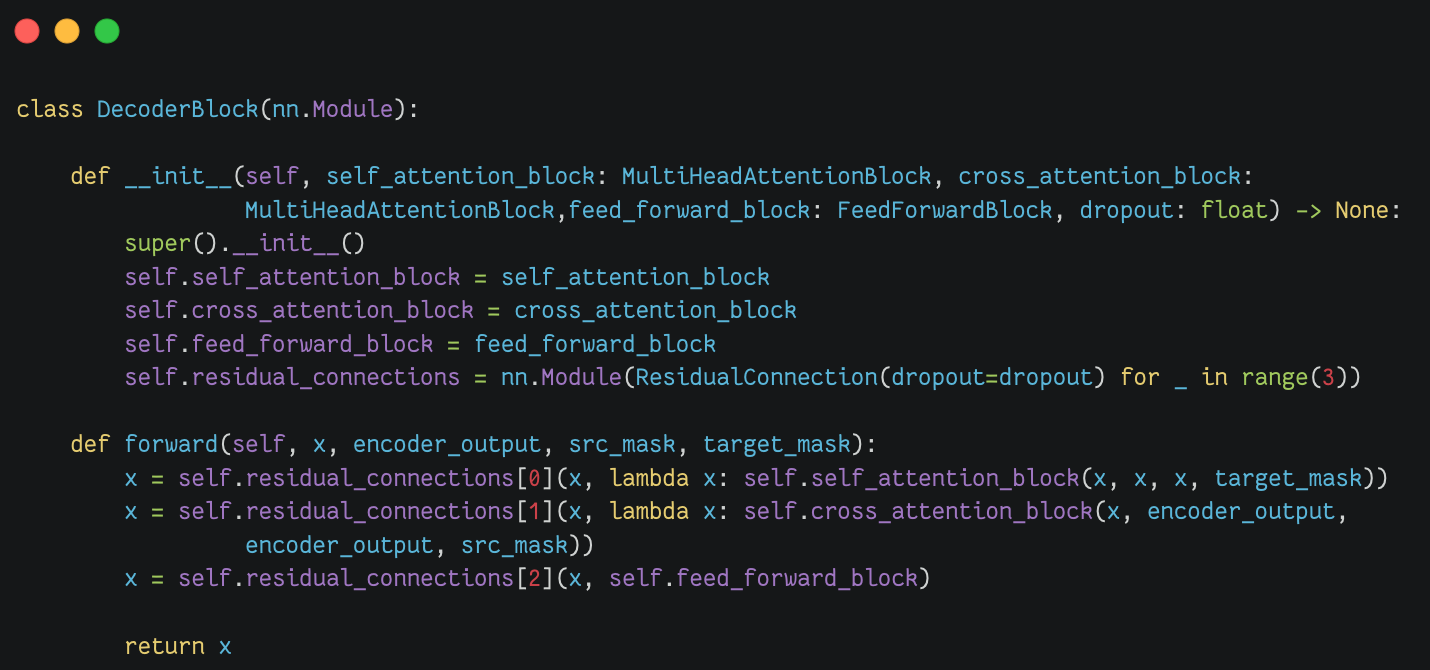 |
解码器模块(Decoder) |
 |
投影层(Projection Layer) |
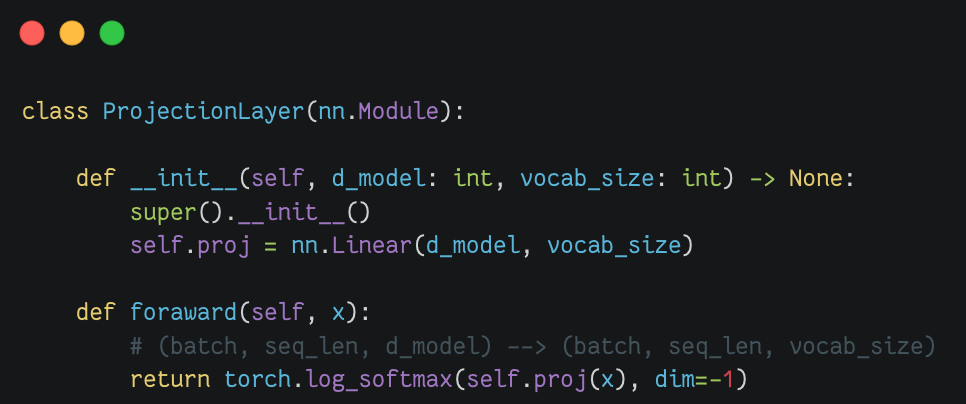 |
Transfrmer模块(Transfrmer) |
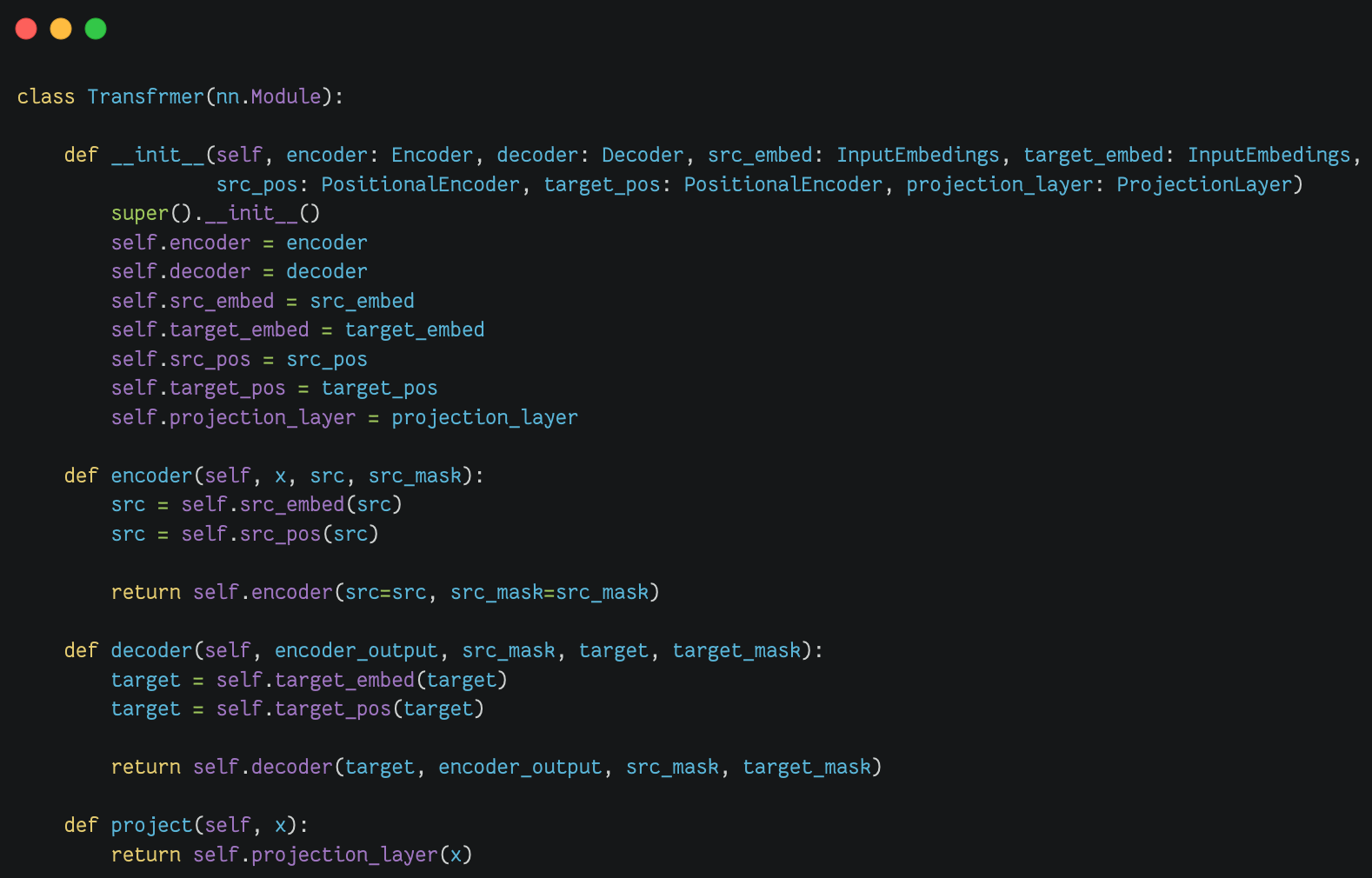 |
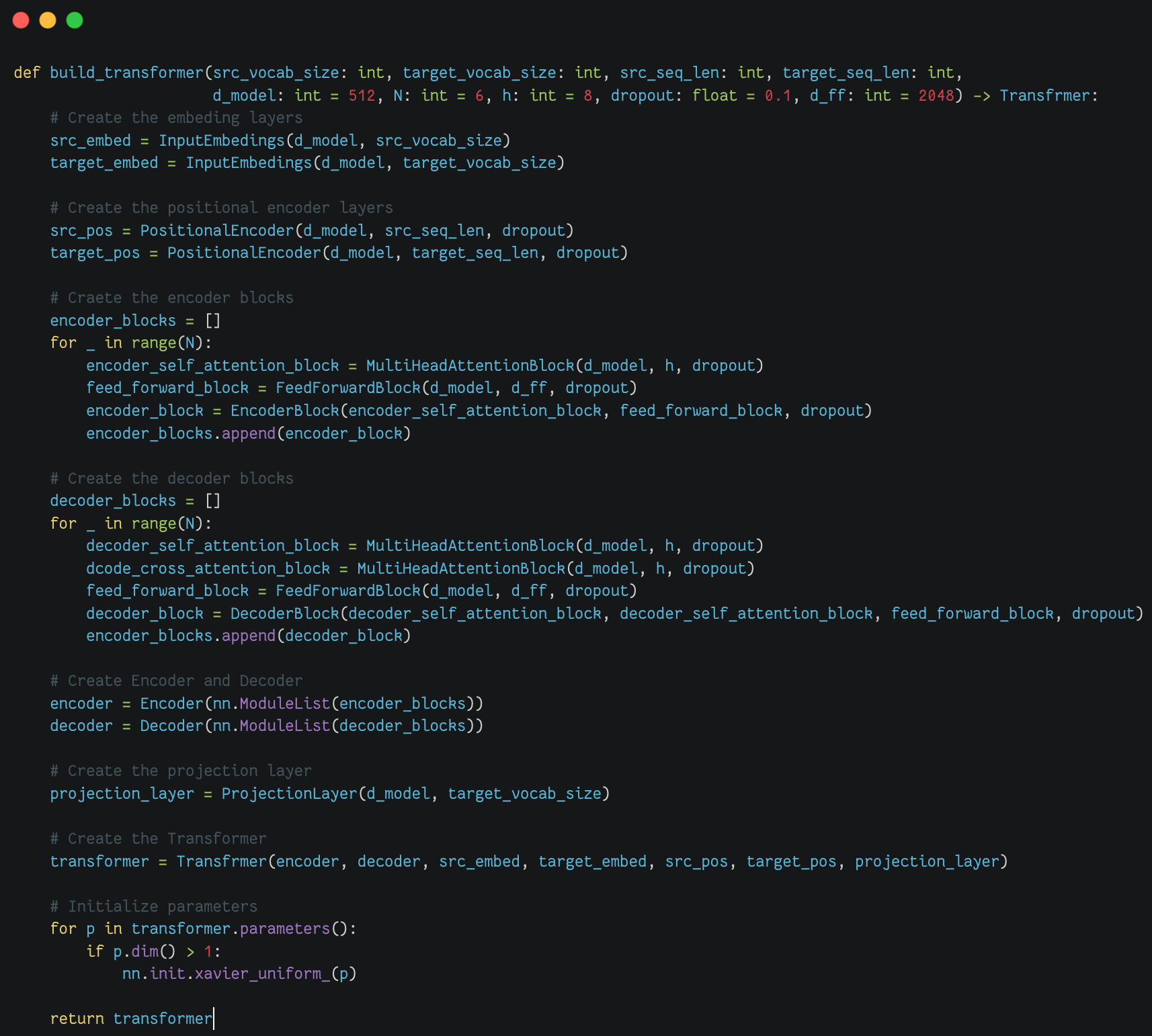
模型构建方法(build_transformer) |
 |
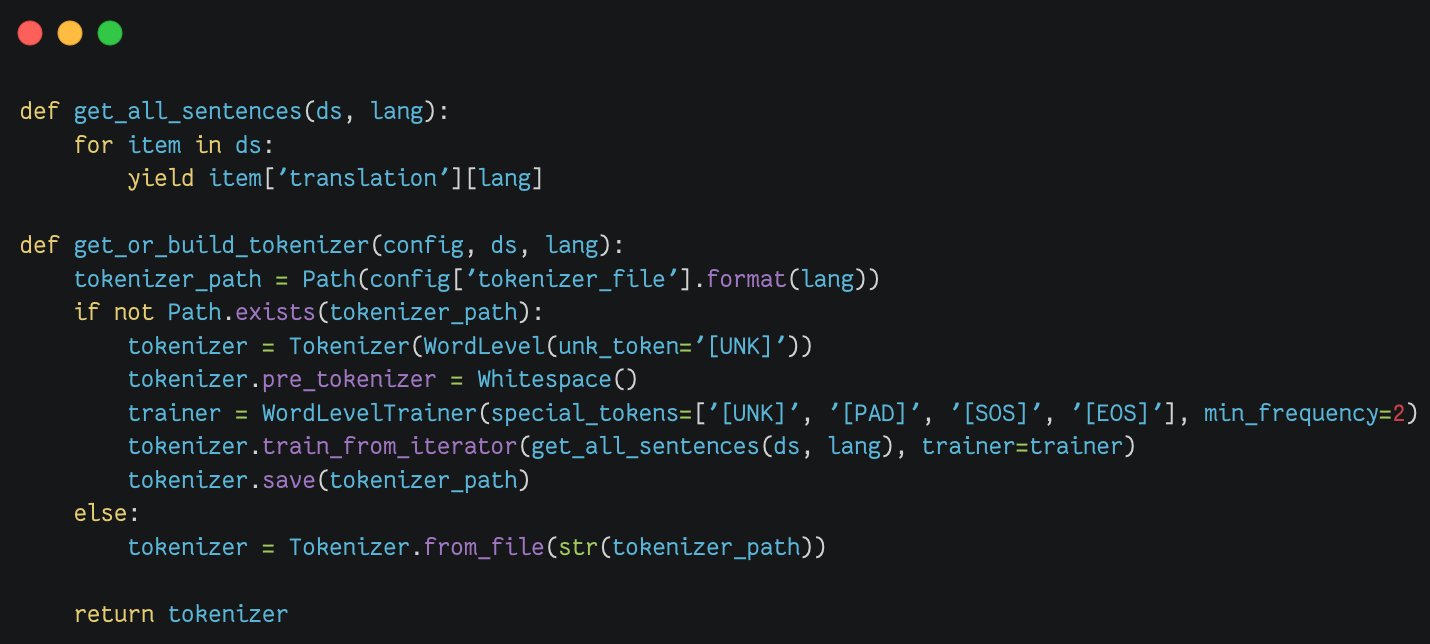
构建分词器模块(Tokenizer) |
 |
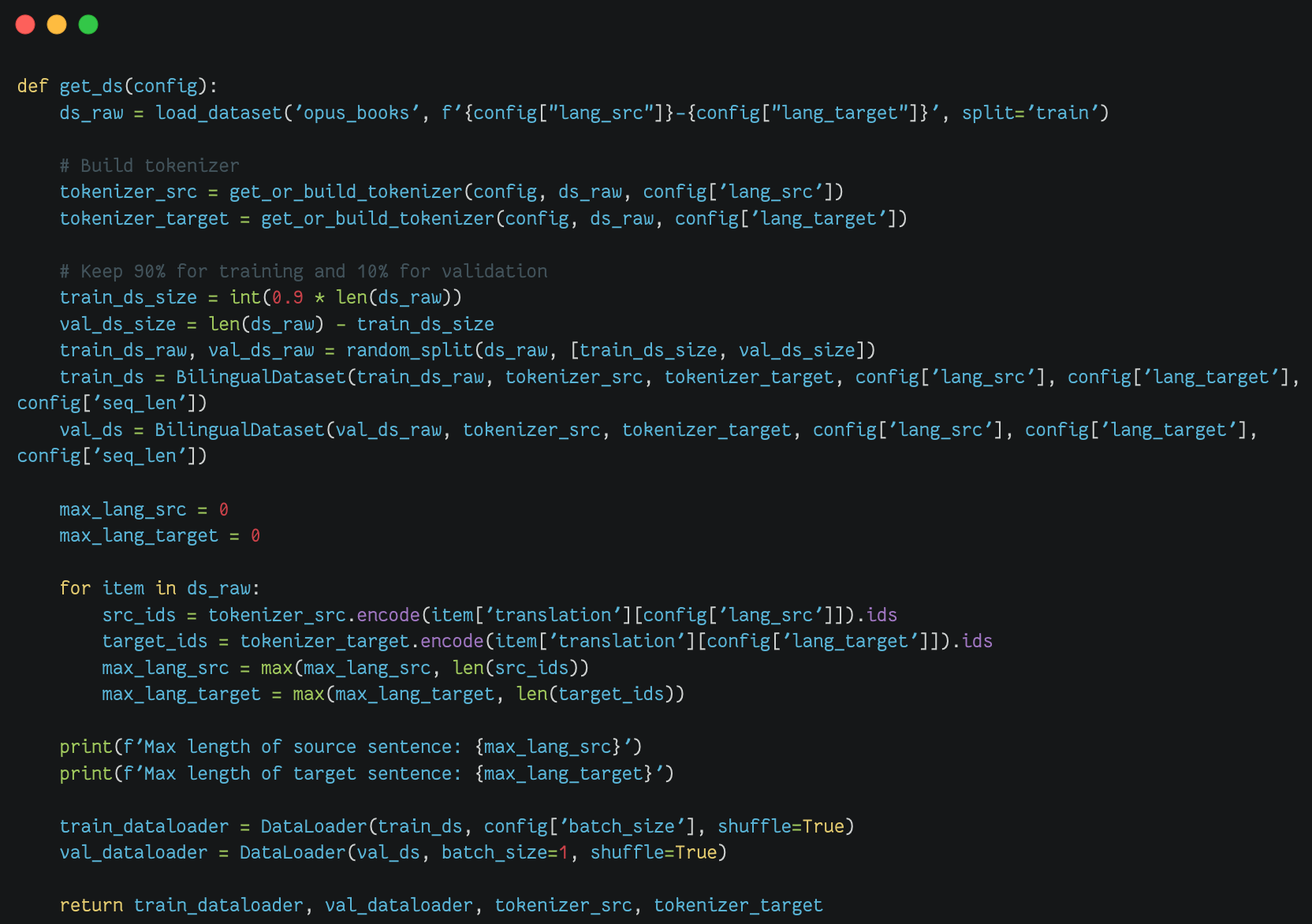
加载数据集(train & val dataset) |
 |