LLaMA 2 模型—探析(PyTorch)
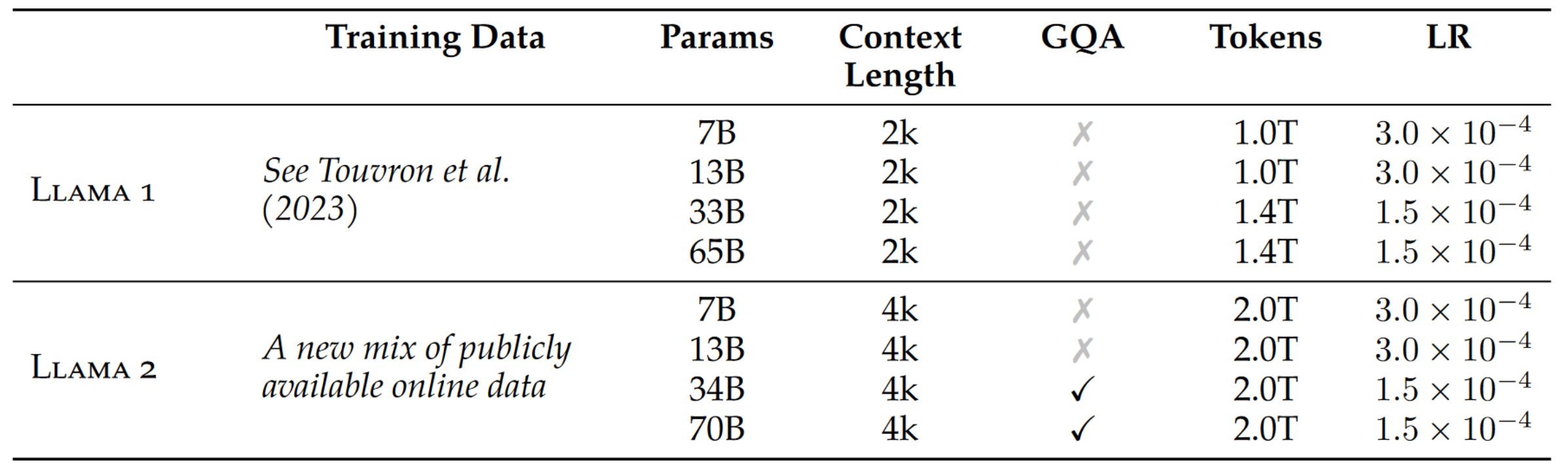
LLaMA 2是Meta AI(原Facebook AI)在2023年7月发布的大型语言模型系列,是LLaMA模型的第二代版本。模型规模:包含70亿、130亿和700亿参数三种规模的模型。比LLaMA 1增加了一个700亿参数的大型模型。训练数据:使用2万亿个tokens进行预训练,比LLaMA 1增加了40%;完全使用公开可用的数据集,不依赖专有数据。性能改进:在多数基准测试中,性能超过了同等规模的开源模型;130亿参数版本在某些任务上甚至超过了GPT-3(1750亿参数)。对话优化:提供了针对对话场景优化的LLaMA 2-Chat版本;使用了超过100万人工标注进行微调。安全性:在模型训练中加入了安全性改进措施;使用人类反馈强化学习(RLHF)来确保安全性和有用性。技术创新:使用分组查询注意力(GQA)机制提高效率;上下文长度增加到4096 tokens,是LLaMA 1的两倍。
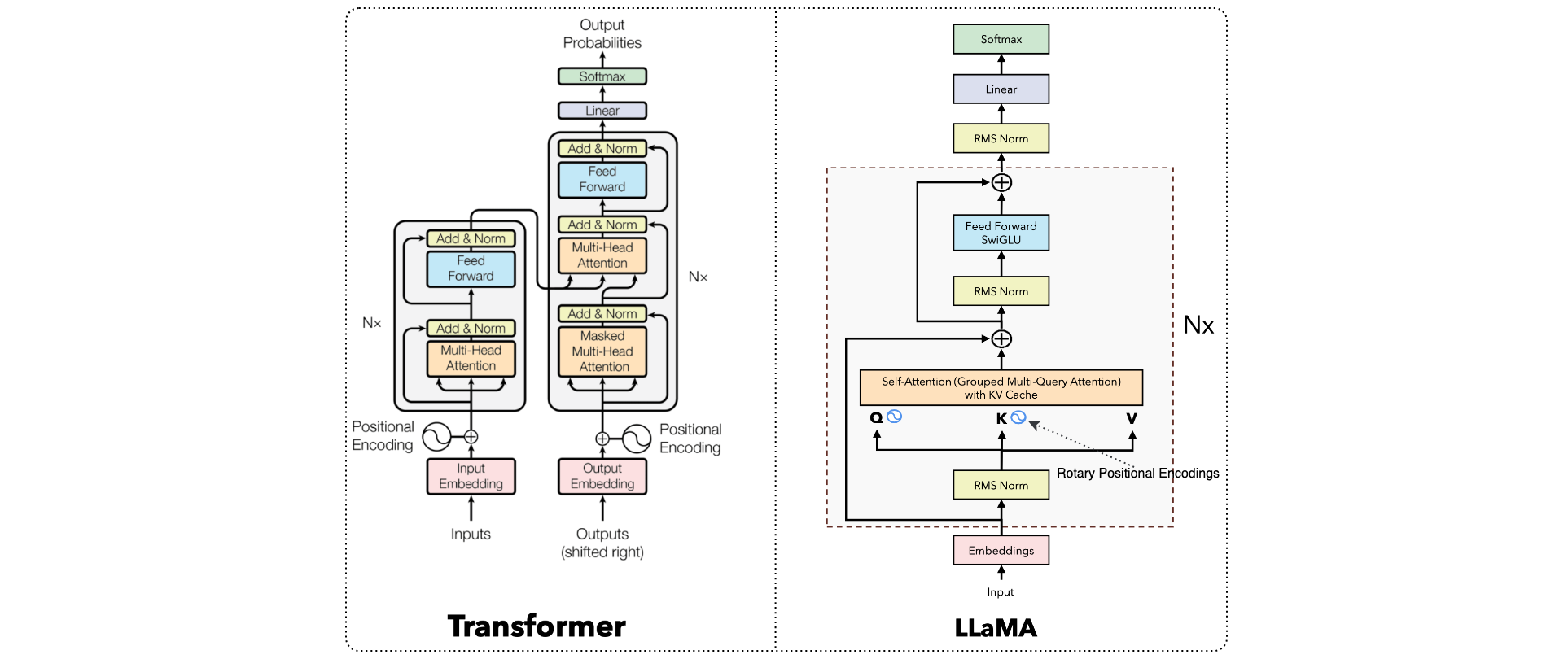
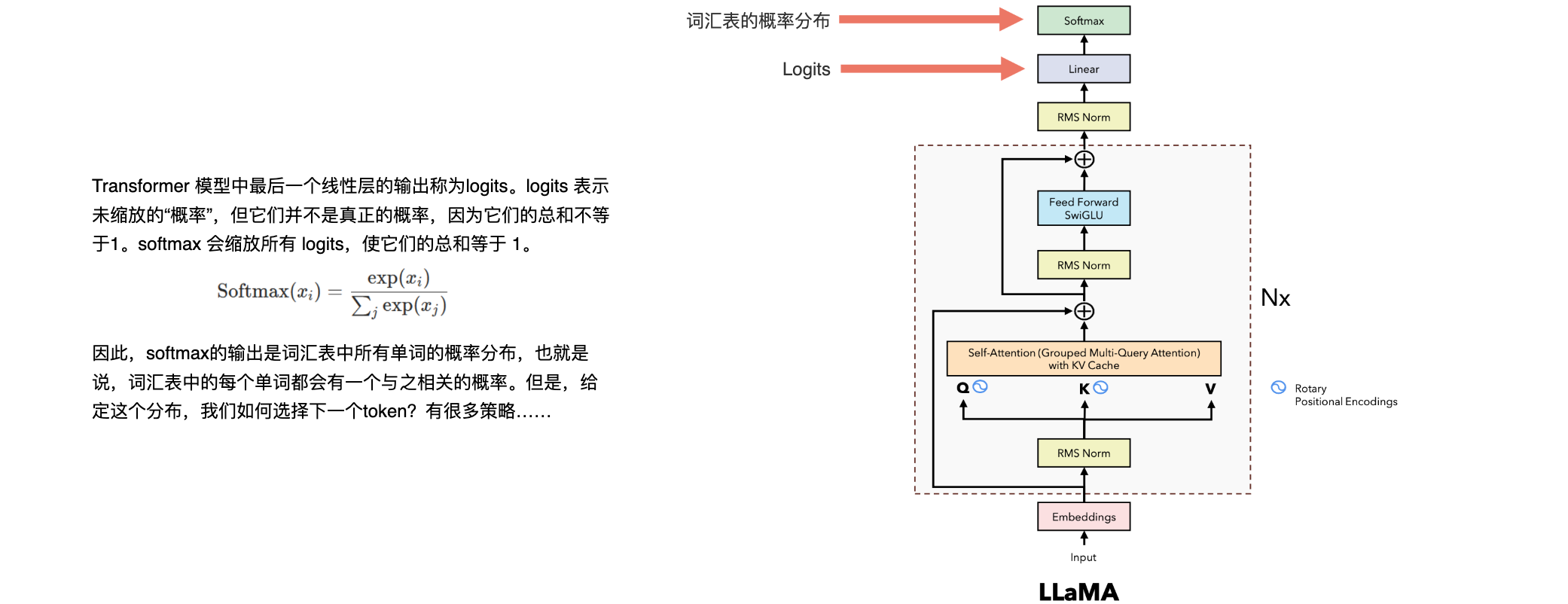
LLaMA 2采用了经典的Transformer架构,但在多个方面进行了优化,以提高模型的性能和效率:
Transformer架构:LLaMA 2基于经典的Transformer架构,利用注意力机制来理解文本的上下文关系。- 解码器结构:
LLaMA 2采用了仅解码器的Transformer架构,这种架构在生成任务中表现出色。 RMSNorm(Root Mean Square Layer Normalization):取代了传统的Layer Normalization,RMSNorm有助于提高训练的稳定性和效率。SwiGLU激活函数:采用了SwiGLU激活函数,而不是标准的ReLU激活函数,这种选择有助于提升模型的表现。RoPE(Rotary Positional Embedding)位置编码:使用旋转位置编码来处理位置信息,这种方法在处理长序列时表现更好。Grouped Query Attention(GQA):引入了分组查询注意力机制,以加速推理过程。
RMSNorm
Llama 2系列模型。标记计数仅指预训练数据。所有模型均使用4M标记的全局批处理大小进行训练。更大的模型(34B和70B)使用分组查询注意力(GQA)来提高推理可扩展性。
什么是归一化?归一化(Normalization)是一种数据处理技术,主要用于调整不同尺度的数据到一个共同的尺度。定义:将数据按照一定的规则转换到特定的范围内,通常是[0,1]或[-1,1]。主要目的:使不同量纲的数据可比较;消除数据的单位影响;改善数据的稳定性和可解释性。常见的归一化方法:最小-最大归一化(Min-Max Normalization)、Z-score归一化、小数定标归一化。
Root Mean Square Normalization(RMSNorm)是一种数据归一化技术,主要用于信号处理、统计学和机器学习等领域。定义:RMS Normalization将数据缩放,使得数据的均方根值等于1。它是通过将每个值除以所有值平方的平均值的平方根来计算的。
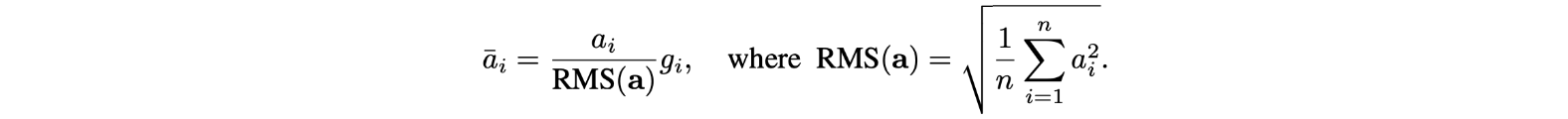
就像层规范化一样,我们也有一个可学习的参数g),它乘以归一化的值。RMSNorm的好处:与层归一化相比,需要的计算量更少;在实践中效果更好。
旋转位置编码
旋转位置编码(Rotary Positional Encoding) 是一种用于Transformer模型的位置编码技术。原理:通过将绝对位置信息编码到查询(query)和键(key)向量中,实现相对位置编码的效果;使用复数旋转的方式来编码位置信息。
什么是旋转矩阵?旋转矩阵可以定义为对向量进行操作并产生旋转向量的变换矩阵,使得坐标轴始终保持固定。这些矩阵将向量沿逆时针方向旋转角度
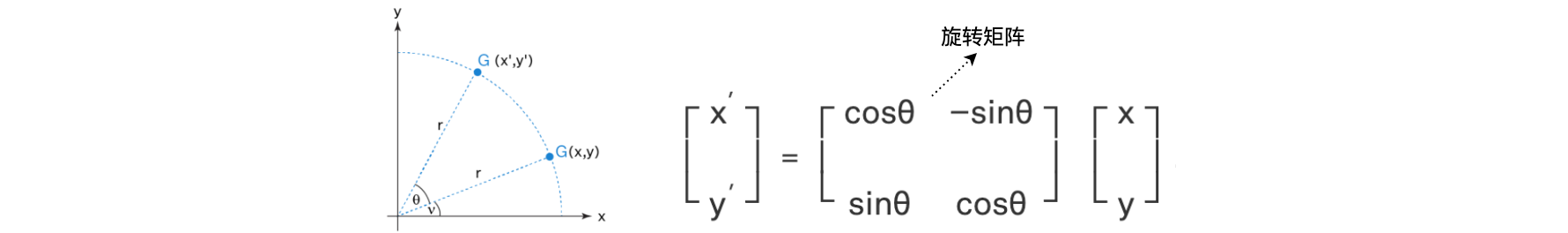
我们看到旋转矩阵保留了原始向量的大小(或长度),如上图中“r”所示,唯一改变的是与x轴的角度。这里旋转位置编码中使用的旋转矩阵是二维旋转矩阵的多个块。如下图所示:

绝对位置编码是固定向量,它们被添加到token的嵌入中以表示其在句子中的绝对位置。因此,它一次处理一个token。您可以将其视为地图上的一对(纬度,经度):地球上的每个点都有一对唯一的token。绝对位置编码的缺点:它没有考虑句子中的相对位置信息。
相对位置编码一次处理两个token,并且在我们计算注意力时会涉及它:由于注意力机制捕获了两个单词相互关联的“强度”,相对位置编码会告诉注意力机制其中涉及的两个单词之间的距离。因此,给定两个token,我们创建一个表示它们距离的向量。相对位置编码的缺点:是计算效率低下,导致成本高,不适合推理(因为每个token的嵌入会随着每个新的时间步长而改变)。
旋转位置嵌入(RoPE)
旋转位置嵌入(RoPE)是一种新型的位置编码方法,用于Transformer模型中。它通过旋转矩阵编码绝对位置信息,同时在自注意力机制中自然地融入了显式的相对位置依赖关系。原理:不是添加位置向量,而是对词向量使用旋转;使用复数旋转的方式来编码位置信息。优点:结合了绝对位置编码和相对位置编码的优势;计算效率高,易于实现;对长序列有更好的处理能力。
旋转位置嵌入:内积,注意力机制中使用的点积是一种内积,可以将其视为点积的泛化。我们可以定义一个函数g,它仅取决于两个嵌入向量q、k及其相对距离。
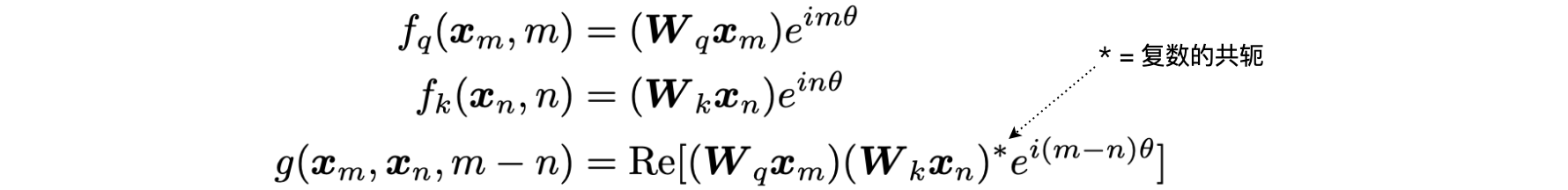
利用欧拉公式,我们可以将其写成矩阵形式。

由于矩阵是稀疏的,因此用它来计算位置嵌入并不方便。给定一个具有嵌入向量x的token,以及该标记在句子内部的位置m,下面就是计算该token的位置嵌入的方式。
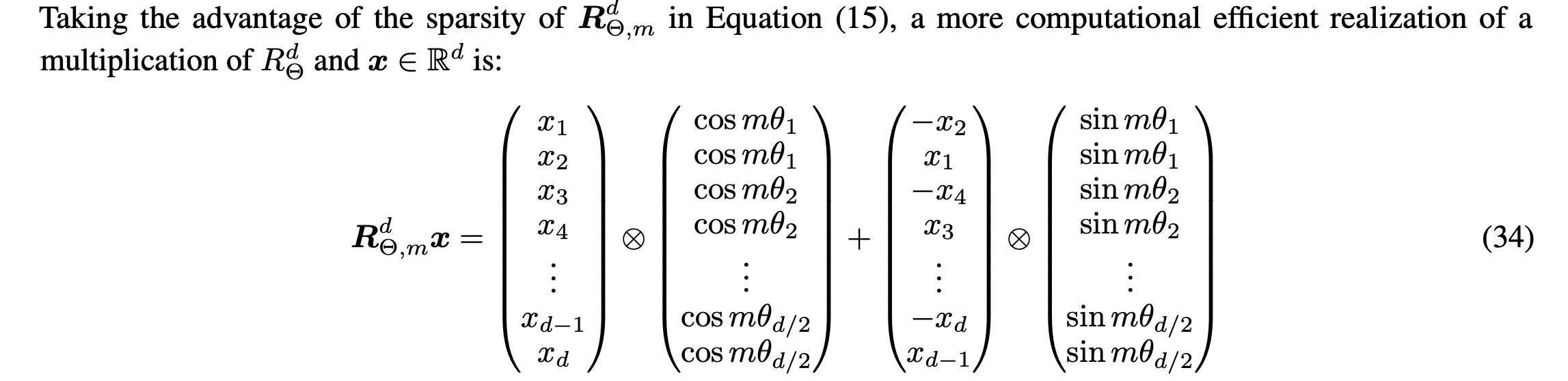
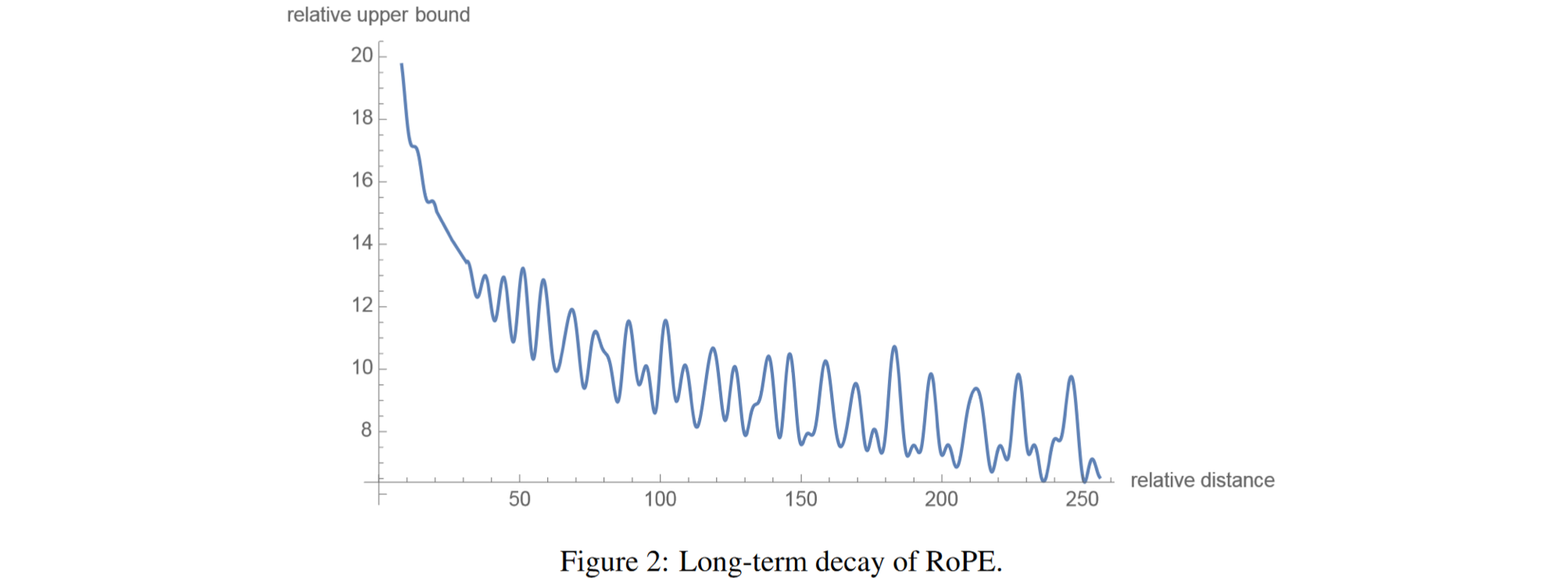
旋转位置嵌入:长期衰减,通过改变两个token之间的距离计算了内积的上限,并证明它会随着相对距离的增长而衰减。意味着,用旋转位置嵌入编码的两个token之间的关系“强度”会随着它们之间距离的增加而变小。旋转位置嵌入仅适用于q和k,而不适用于v。在注意力机制中,旋转位置嵌入是在向量q和k与W矩阵相乘之后使用的,而在vanilla Transformer中,旋转位置嵌入是在之前使用的。下一个token预测任务:在推理的每一步,我们只对模型输出的最后一个token感兴趣,因为我们已经有了之前的token。然而,模型需要访问所有之前的token来决定输出哪个token,因为构成了它的上下文(或“提示词”)。有没有办法让模型在推理过程中对已经见过的token进行更少的计算?有,解决方案就是KV缓存。
分组查询注意力
分组查询注意力(Grouped Query Attention, GQA)是一种介于Multi-Head Attention(MHA)和Multi-Query Attention(MQA)之间的注意力机制。它将查询头(query heads)分成多个组,每组共享一个键头(key head)和值头(value head)。原理:将查询头分成G个组。每个组共享一个键头和值头。GQA-G表示有G个组的GQA;GQA-1等同于MQA,GQA-H(H为头的总数)等同于MHA;通过对原始MHA模型的键和值投影矩阵进行平均池化来转换为GQA模型。优点:相比MQA,降低了质量下降和训练不稳定的问题;相比MHA,提高了推理速度和计算效率。
Item |
Features |
Architecture |
|---|---|---|
Multi-Head Attention |
高质量,计算速度慢 |  |
Grouped Multi-Query Attention |
质量和速度之间有很好的平衡 |  |
Multi-Query Attention |
质量有损失,计算速度快 |  |
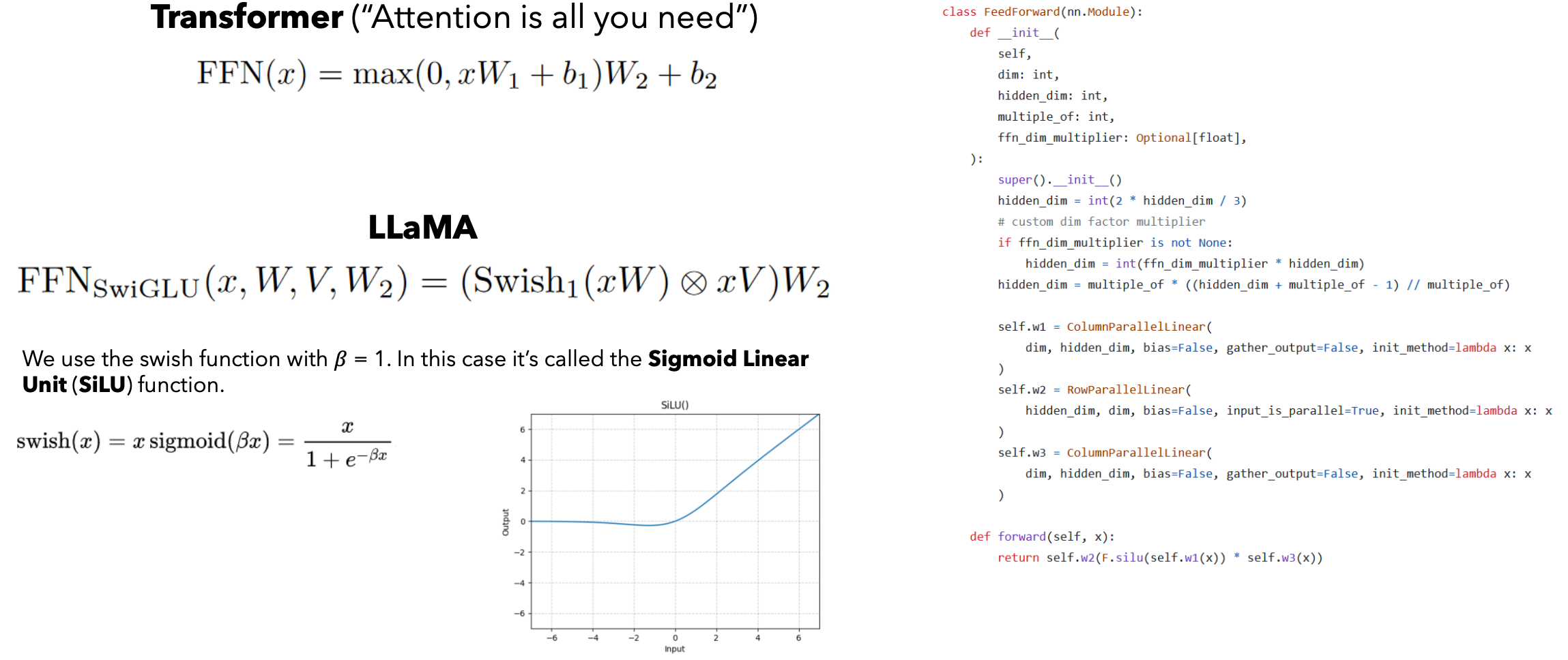
SwiGLU
SwiGLU(Swish-Gated Linear Unit)是一种新型的激活函数,结合了Swish和GLU(Gated Linear Unit)的特点。它在深度学习模型中被用作非线性激活函数,以提高模型的表现和训练效率。SwiGLU激活函数公式如下:
其中SwiGLU特点:非线性:SwiGLU引入了非线性变换,能够捕捉复杂的特征;平滑性:Swish函数的平滑特性使得梯度流动更加稳定,有助于深层神经网络的训练;门控机制:GLU引入了门控机制,能够动态调整输入信号的通过量,提高模型的表达能力。优点:提高模型性能:SwiGLU在一些深度学习任务中表现出色,能够提高模型的准确性和泛化能力;稳定梯度:相比于ReLU等传统激活函数,SwiGLU能够更好地保持梯度的稳定性,减少梯度消失问题;灵活性:结合了Swish和GLU的优点,SwiGLU能够在不同任务和模型架构中灵活应用。
Logits
在神经网络中,logits是指模型最后一层的输出,即在应用激活函数(如softmax或sigmoid)之前的原始、未归一化的预测值。代表了模型在最终决策之前的原始输出,尚未转换为概率。
推理策略
推理策略:Greedy、Beam Search、Temperature、Random Sampling、Top K、Top P。
Inference strategies |
Description |
|---|---|
Greedy |
在每一步中,我们都选择概率最大的token,将其附加到输入中以生成下一个token,依此类推…。如果初始token恰好是错误的,则下一个token很可能也会是错误的。Greedy易于实现。在实践中表现不佳。 |
Beam Search |
在每一步中,我们保持前K条路径有效,其他所有路径均被终止。增加了推理时间,因为每一步都必须探索K个可能的选项。通常,比贪婪策略表现更好。 |
Temperature |
这个想法是在使用softmax之前缩放logits。低温使模型更可信(低概率和高概率之间的差距增加)。高温使模型可信度降低(低概率和高概率之间的差距缩小)。 |
Random Sampling |
我们从softmax输出的随机分布中抽样。第一个token被选中的概率为12.06%,第二个token被选中的概率为7.31%,最后一个token被选中的概率为80.63%。概率越高,被选中的概率就越大。问题:我们可能会以极小的概率选择完全无意义的token。 |
Top K |
在随机采样策略中,可能会发生选择到概率很小的单词的情况,这通常表示该token与前面的token无关。使用Top K,仅保留前k个最高概率的token,因此概率非常低的 token永远不会被选中。问题:给定以下分布,低概率token仍会进入前k个token(k = 2)。分布1:0.5、0.4、0.05、0.025、0.025;分布2:0.9、0.05、0.025、0.020、0.005。 |
Top P |
使用Top P,我们仅保留概率最高的token,使得它们的累积概率大于或等于参数p。这样,对于更“平坦”的分布,我们会获得更多token,而对于模式非常突出的分布,我们会获得更少的token。 |