Stable Diffusion模型—探析(PyTorch)
Stable Diffusion是一种基于扩散模型的文本到图像深度学习模型。该模型于2022年推出,由慕尼黑大学CompViz集团开发。基本功能:文本到图像生成:根据文字描述生成高质量图像;图像编辑:支持内补绘制、外补绘制等图像编辑功能;图像到图像转换:在提示词指导下修改现有图像。技术架构:使用潜在扩散模型(Latent Diffusion Model);由三部分组成:变分自编码器(VAE)、U-Net和文本编码器;在潜在空间中进行扩散过程,提高计算效率。性能:生成512x512分辨率的图像(2.0版本支持768x768);相对轻量级,U-Net有860M参数,文本编码器有123M参数。Stable Diffusion的出现标志着AI图像生成技术的重要进步,为创意工作者和普通用户提供了强大的工具。
什么是生成模型?生成模型会学习数据集的概率分布,这样我们就可以从该分布中抽样以创建新的数据实例。例如,如果我们有很多猫的图片,并且我们用它训练生成模型,那么我们就可以从这个分布中抽样以创建新的猫图像。为什么我们要将数据建模为分布?假设你是一个罪犯,你想生成数千个虚假身份。每个虚假身份都由变量组成,代表一个人的特征(年龄、身高)。你可以要求政府统计部门提供有关人口年龄和身高的统计数据,然后从这些分布中抽样。

首先,你可以从每个分布中独立抽样来创建一个虚假身份,但这会产生不合理的(年龄,身高)对。要生成有意义的虚假身份,你需要联合分布,否则你最终可能会得到一对不合理的(年龄,身高)。我们还可以使用条件概率或通过边缘化变量来评估两个变量之一的概率。我们有一个由图像组成的数据集,我们想要学习一个非常复杂的分布,然后可以用来进行采样。
证据下界(Evidence Lower Bound, ELBO)是变分贝叶斯方法中的一个重要概念,用于估计观测数据对数似然的下限。ELBO是一个用于近似后验分布的工具。在贝叶斯推理中,我们通常对后验分布感兴趣,但直接计算后验分布通常是不可行,因为需要计算证据(即观测数据的边缘似然),这在大多数情况下是不可计算的。ELBO提供了一种变分方法,通过优化一个易处理的下界来近似后验分布。ELBO在许多概率推理算法中起着核心作用,如期望最大化(EM)算法和变分推理。具体应用包括:变分自编码器(VAE):用于生成模型,学习数据的潜在表示;贝叶斯神经网络:用于不确定性估计和模型正则化。

U-Net
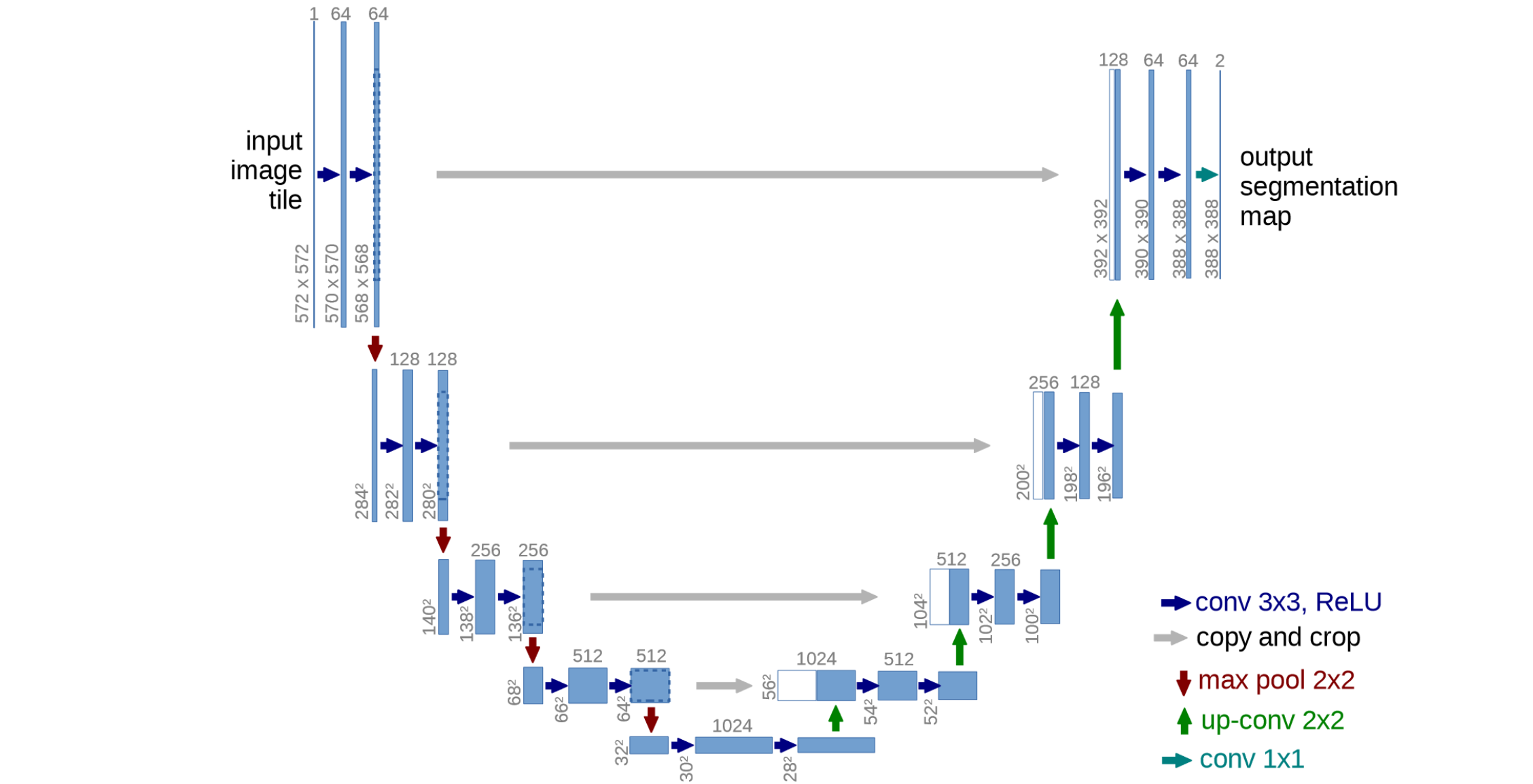
U-Net是一种用于图像分割的卷积神经网络架构,最初由弗赖堡大学的研究人员在2015年提出,主要用于生物医学图像分割。U-Net的结构呈U形,由两个主要部分组成:
- 下采样路径(编码器):由多个卷积层和池化层组成;逐步减小特征图的空间维度,增加通道数;提取图像的高级特征。
- 上采样路径(解码器):由转置卷积(反卷积)层组成;逐步恢复特征图的空间维度;结合下采样路径的特征,实现精确定位。
主要优势:高精度分割:U-Net能够产生精确的分割结果,特别适用于医学图像;少量样本训练:相比其他网络,U-Net可以使用较少的训练样本达到良好效果;快速处理:在现代GPU上,U-Net可以在1秒内完成512×512图像的分割;灵活性:U-Net结构简单,易于修改和扩展,适应不同任务需求。
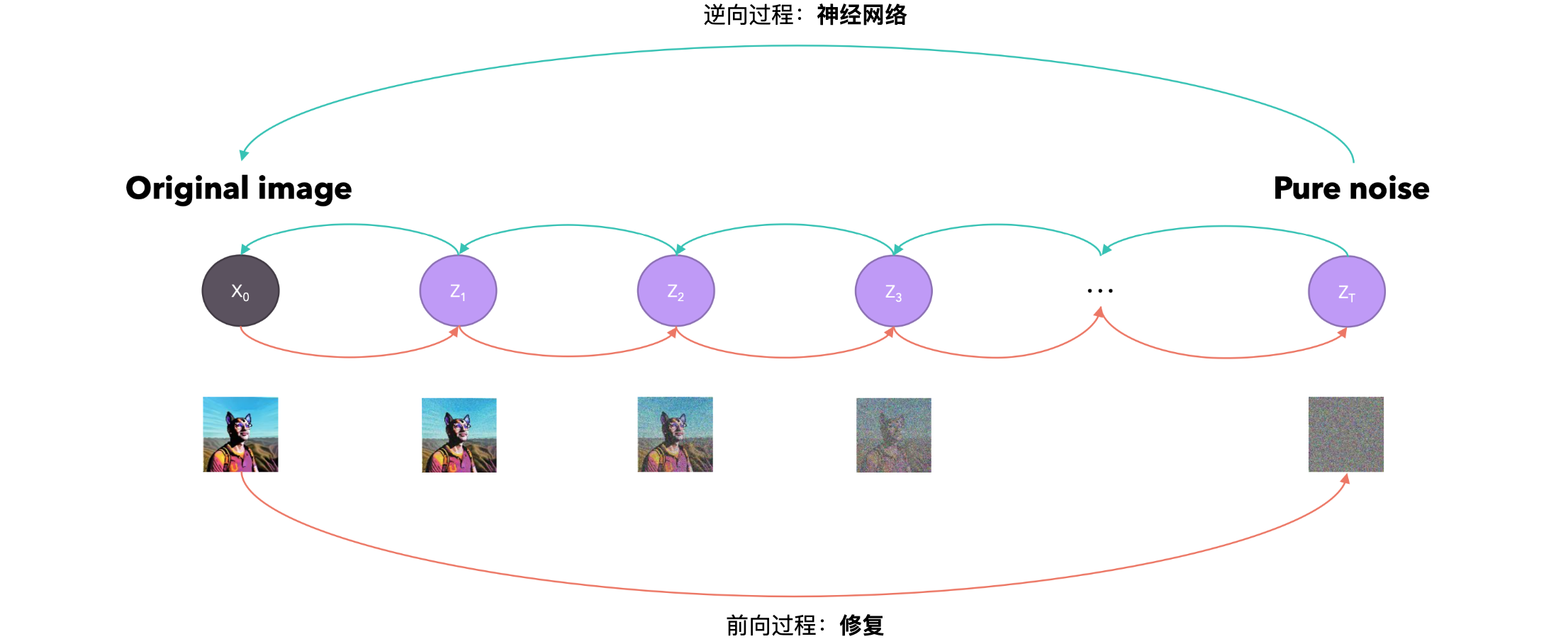
如何调节逆向过程?既然我们从保留过程中的噪声开始,那么模型如何知道我们想要的输出是什么?模型如何理解我们的提示?这就是为什么我们需要调节逆向过程。如果我们想要调节我们的网络,我们可以训练一个模型来学习数据和调节信号
无分类器指导(组合输出):

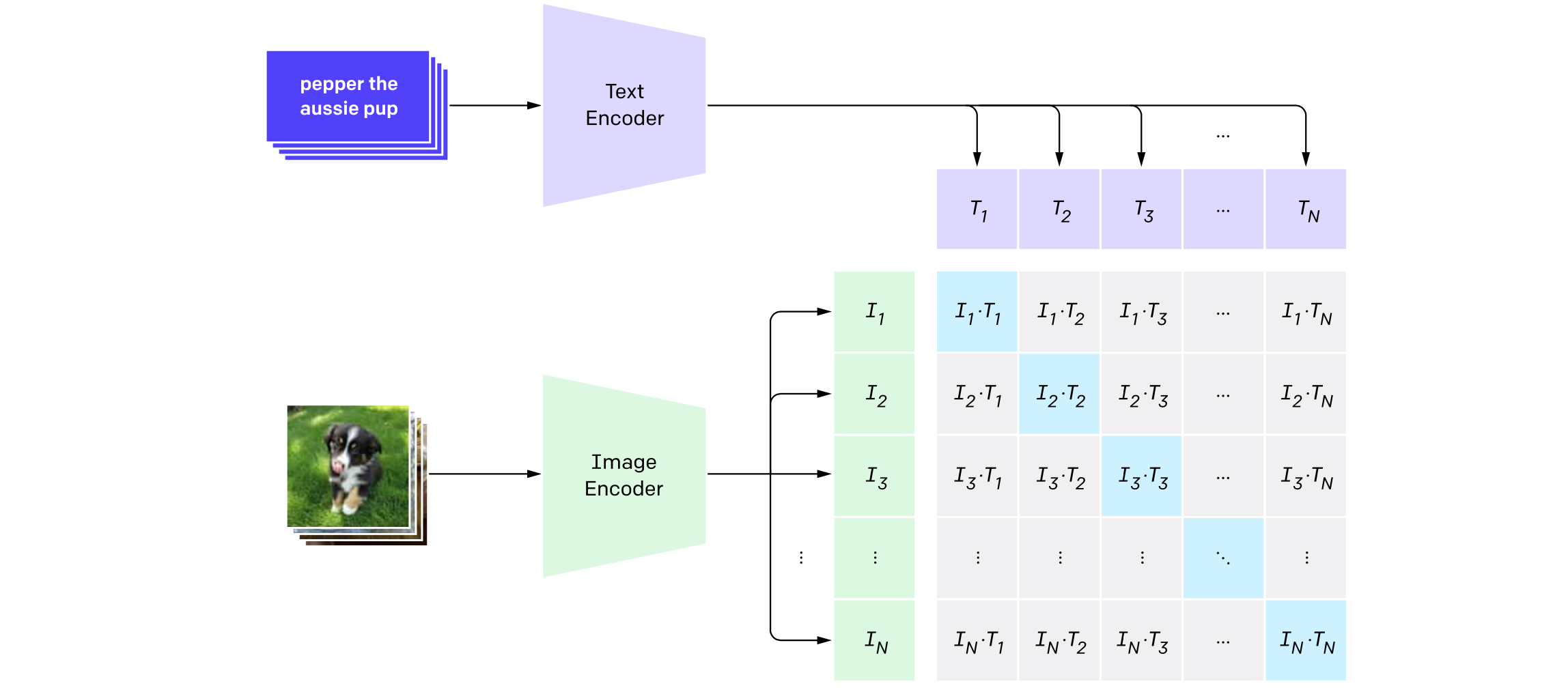
CLIP(Contrastive Language-Image Pre-training)是由OpenAI在2021年提出的一种多模态深度学习模型,主要用于连接图像和文本。CLIP的核心思想是通过对大量图像-文本对进行预训练,学习一个统一的多模态嵌入空间,使得相关的图像和文本在这个空间中距离更近,而不相关的则距离更远。CLIP由两个主要组件构成:图像编码器: 可以是ResNet或Vision Transformer(ViT);文本编码器: 基于Transformer架构。主要优势:零样本学习能力: CLIP可以直接用于未见过的类别,无需额外微调;灵活性: 可以处理各种视觉任务,如分类、检索等;大规模预训练: 在包含4亿(图像,文本)对的数据集上训练,学习了广泛的视觉概念;多模态理解: 能够理解图像和文本之间的关系。
由于潜在变量的维度(向量大小)与原始数据相同,如果我们想执行许多步骤来对图像进行去噪,那么将需要通过Unet执行许多步骤,如果表示我们的数据/潜在变量的矩阵很大,则这可能会非常慢。如果我们可以在正向/反向过程(UNet)之前“压缩”我们的数据,结果会怎样?
Latent Diffusion Model(LDM)是一种用于高分辨率图像合成的深度学习模型,由Robin Rombach等人在2021年提出。LDM的核心思想是将扩散模型(Diffusion Model)应用于预训练自编码器的潜在空间,而不是直接在像素空间上操作。这种方法大大降低了计算复杂度,同时保持了高质量的图像生成能力。LDM主要由三个部分组成:预训练的自编码器: 通常是一个向量量化变分自编码器(VQ-VAE),用于将图像压缩到低维潜在空间;U-Net扩散模型: 在潜在空间中进行去噪过程;条件编码器: 用于处理文本、布局等条件信息(在条件生成任务中使用)。工作原理:图像首先通过自编码器压缩到潜在空间;扩散模型在潜在空间中学习去噪过程;生成时,从随机噪声开始,逐步去噪得到潜在表示;最后通过自编码器的解码器将潜在表示转换回图像。主要优势:计算效率: 相比直接在像素空间的扩散模型,LDM大大减少了计算需求;灵活性: 可以应用于多种任务,如无条件生成、文本到图像、图像修复等;高质量输出: 在多个任务上达到了当时的最先进水平;可控性: 通过引入交叉注意力层,可以灵活地接受各种条件输入。
LDM为后续的Stable Diffusion等模型奠定了基础,极大地推动了AI图像生成领域的发展。它在保持高质量输出的同时,显著降低了计算需求,使得在有限计算资源下训练强大的生成模型成为可能。总之,Latent Diffusion Model通过巧妙地结合自编码器和扩散模型,在计算效率和生成质量之间取得了很好的平衡,为高分辨率图像合成提供了一个强大而灵活的框架。
稳定扩散是一种潜在扩散模型,在该模型中,我们不会学习图像数据集的分布
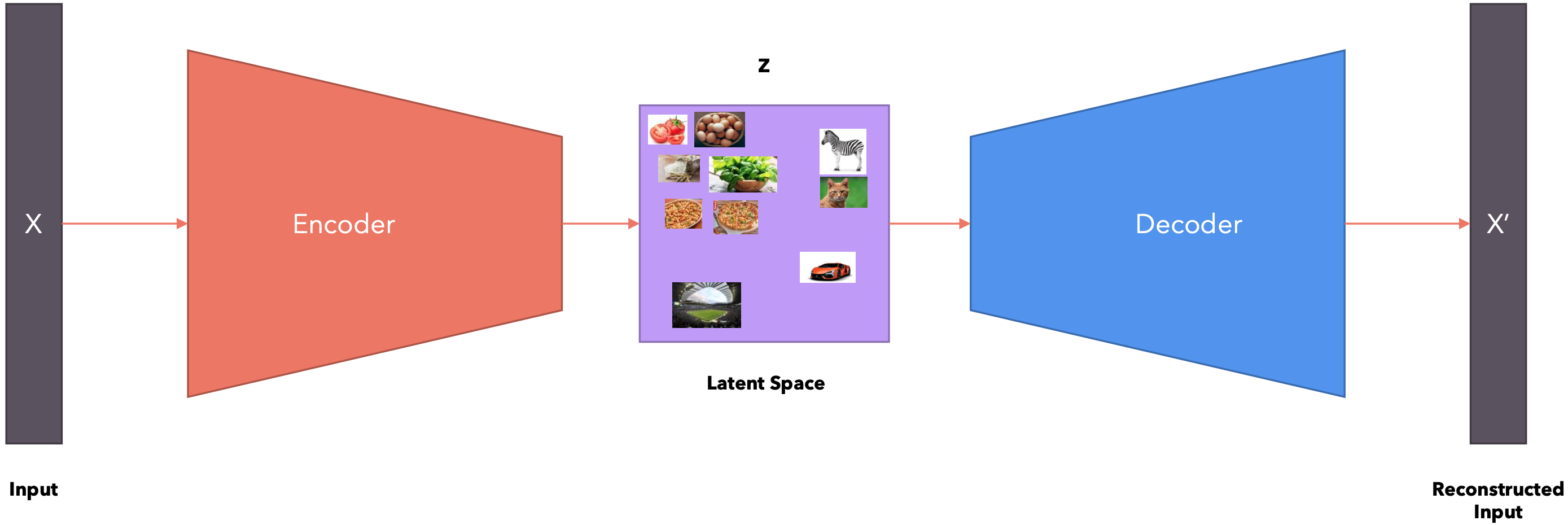
自编码器
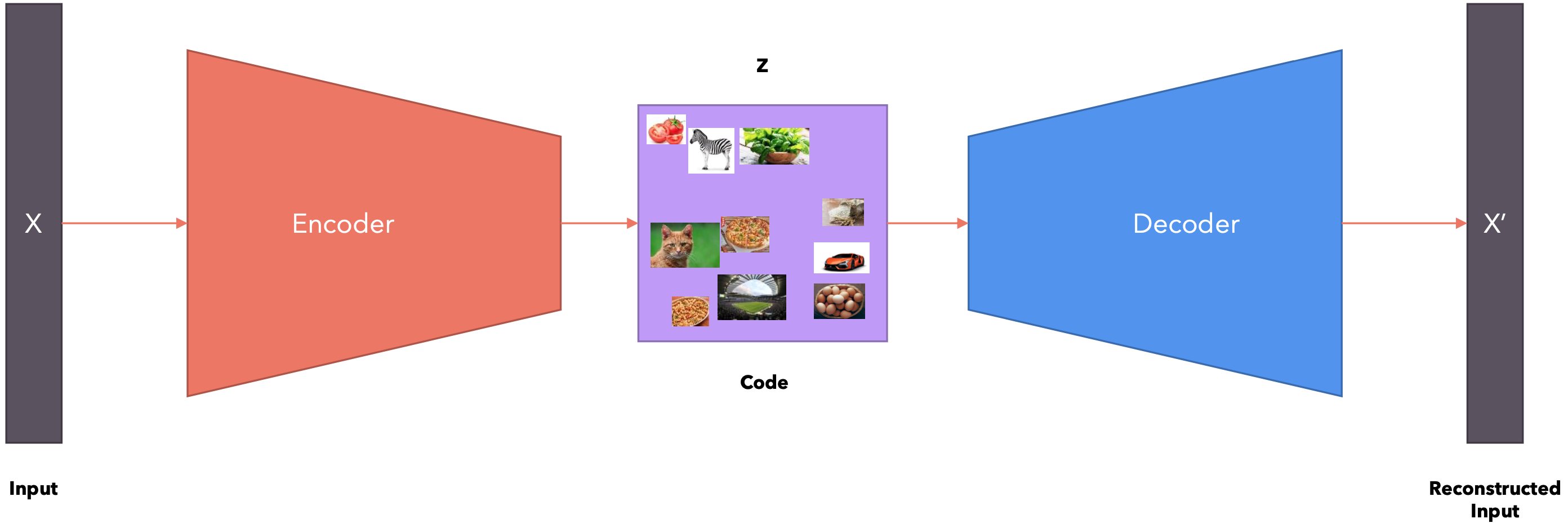
自编码器(Autoencoder)是一种无监督学习的神经网络模型,主要用于数据压缩、特征学习和生成任务。自编码器由两个主要部分组成:
- 编码器(
Encoder): 将输入数据压缩到一个低维表示(称为潜在空间或瓶颈层)。 - 解码器(
Decoder): 尝试从压缩的表示重构原始输入。
工作原理:输入数据通过编码器被压缩到潜在空间;解码器尝试从潜在表示重构原始输入;网络通过最小化重构误差来训练,即使重构的输出尽可能接近原始输入。主要类型:普通自编码器: 最基本的形式,用于数据压缩和特征学习;去噪自编码器(DAE): 通过向输入添加噪声并尝试重构原始无噪声数据来提高鲁棒性;变分自编码器(VAE): 在潜在空间引入概率分布,能够生成新的样本;稀疏自编码器: 在训练过程中加入稀疏性约束,学习更有意义的特征。堆叠自编码器: 将多个自编码器堆叠在一起,用于深度特征学习。
该模型学习到的代码毫无意义。也就是说,该模型可以将任意向量分配给输入,而向量中的数字不代表任何模式。该模型不会捕获数据之间的任何语义关系。
变分自编码器(VAE):变分自动编码器不是学习代码,而是学习“潜在空间”。潜在空间表示(多变量)分布的参数。
文本转图像-架构
Text-to-Image模型是一种机器学习模型,能够根据输入的自然语言描述生成与之匹配的图像。Text-to-Image模型通常由两个主要部分组成:
- 文本编码器(
Text Encoder):将输入的文本描述转换为潜在表示(latent representation);常见的文本编码器包括基于Transformer的模型,如BERT或GPT。 - 图像生成器(
Image Generator):根据文本编码器生成的潜在表示生成图像;常用的图像生成器包括生成对抗网络(GANs)和扩散模型(Diffusion Models)。
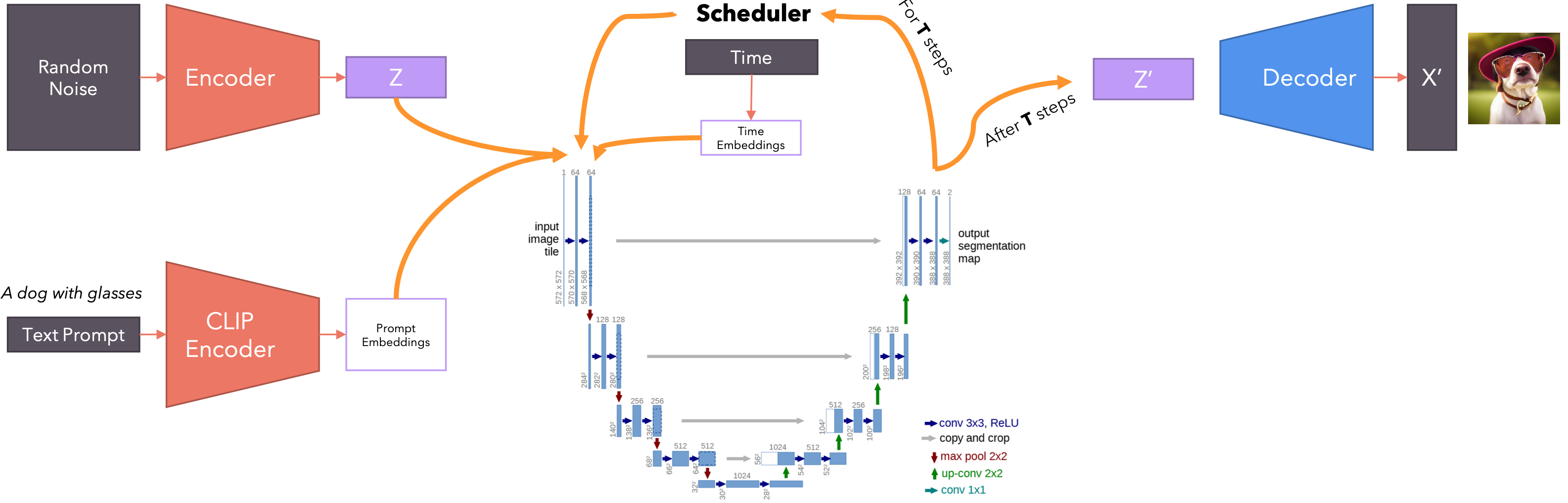
工作原理:
- 文本编码:输入的文本描述首先通过文本编码器转换为潜在表示。这一步骤可以使用循环神经网络(
LSTM)或Transformer模型。 - 图像生成:图像生成器根据潜在表示生成图像。早期的方法主要使用条件生成对抗网络(
Conditional GANs),而近年来扩散模型(Diffusion Models)变得越来越流行。 - 多阶段生成:为了生成高分辨率图像,常用的方法是先生成低分辨率图像,然后使用一个或多个辅助模型进行超分辨率处理,填充细节。
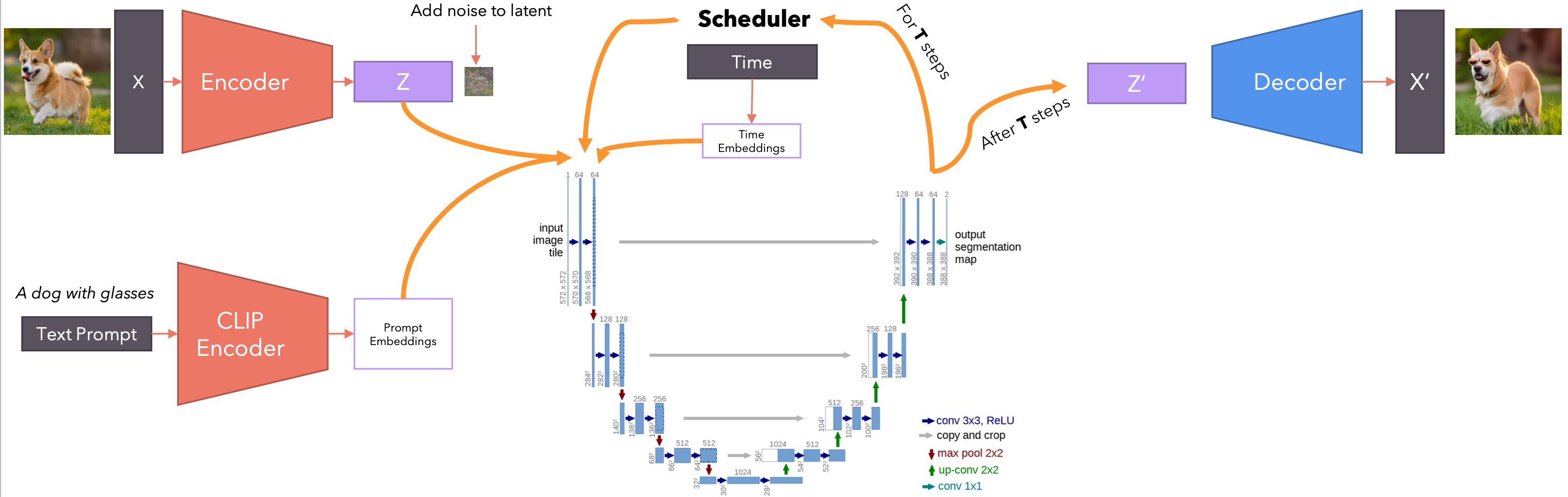
图像转图像-架构
Image-to-Image模型是一种将输入图像转换为目标图像的深度学习模型。Image-to-Image模型通常由两个主要部分组成:
- 编码器(
Encoder):将输入图像编码为潜在表示(latent representation);通常使用卷积神经网络(CNN)来提取图像特征。 - 解码器(
Decoder):将潜在表示解码为目标图像;常用的解码器包括转置卷积(transposed convolution)或上采样(upsampling)层。
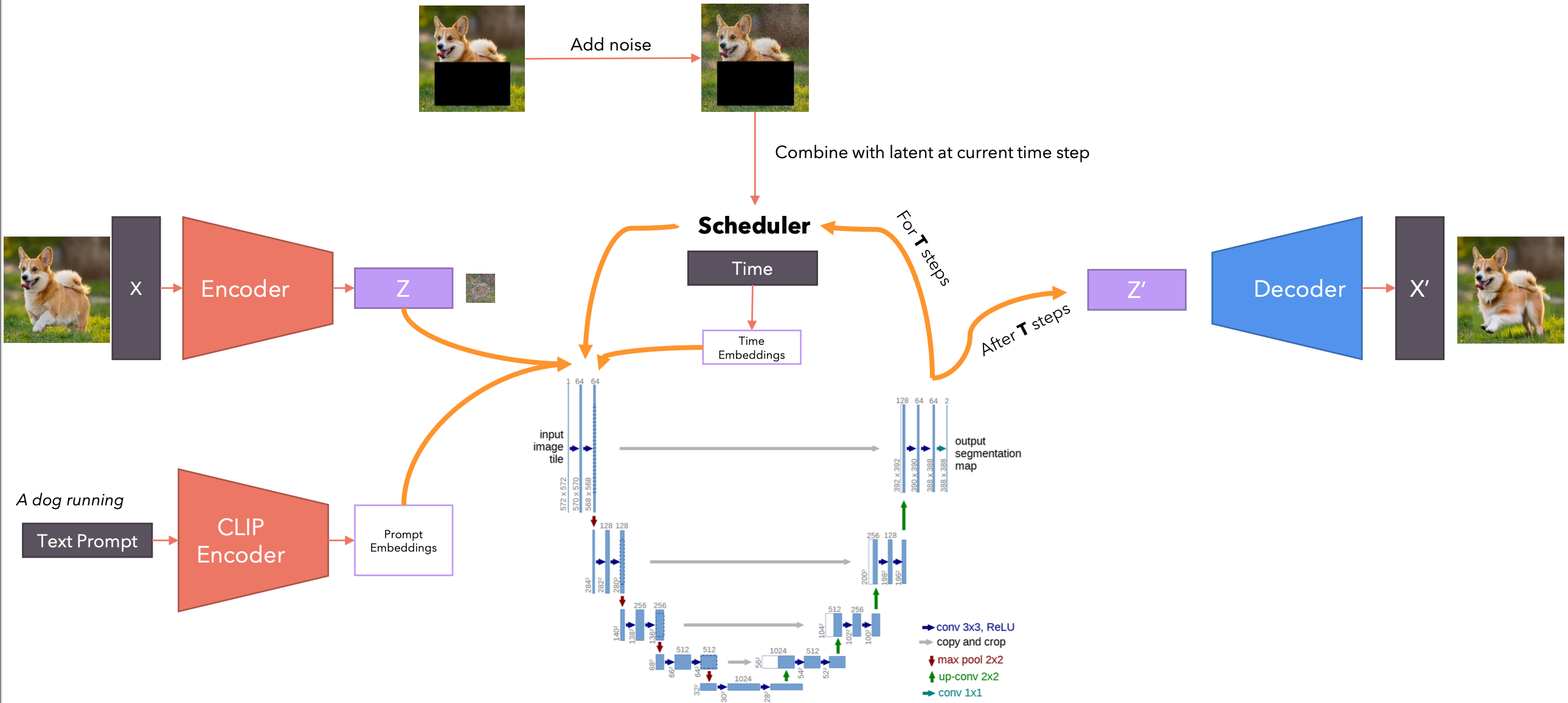
图像修复-架构
In-Painting(图像修复)是一种图像处理技术,旨在填补图像中缺失或损坏的部分。In-Painting模型通常由以下部分组成:
- 编码器(
Encoder):将输入的不完整图像编码为特征表示;通常使用卷积神经网络(CNN)来提取图像特征。 - 解码器(
Decoder):将特征表示解码为完整的修复图像;常用上采样或转置卷积层来生成修复区域。 - 注意力机制(
Attention Mechanism):用于关注需要修复的区域和周围的上下文信息。
层归一化
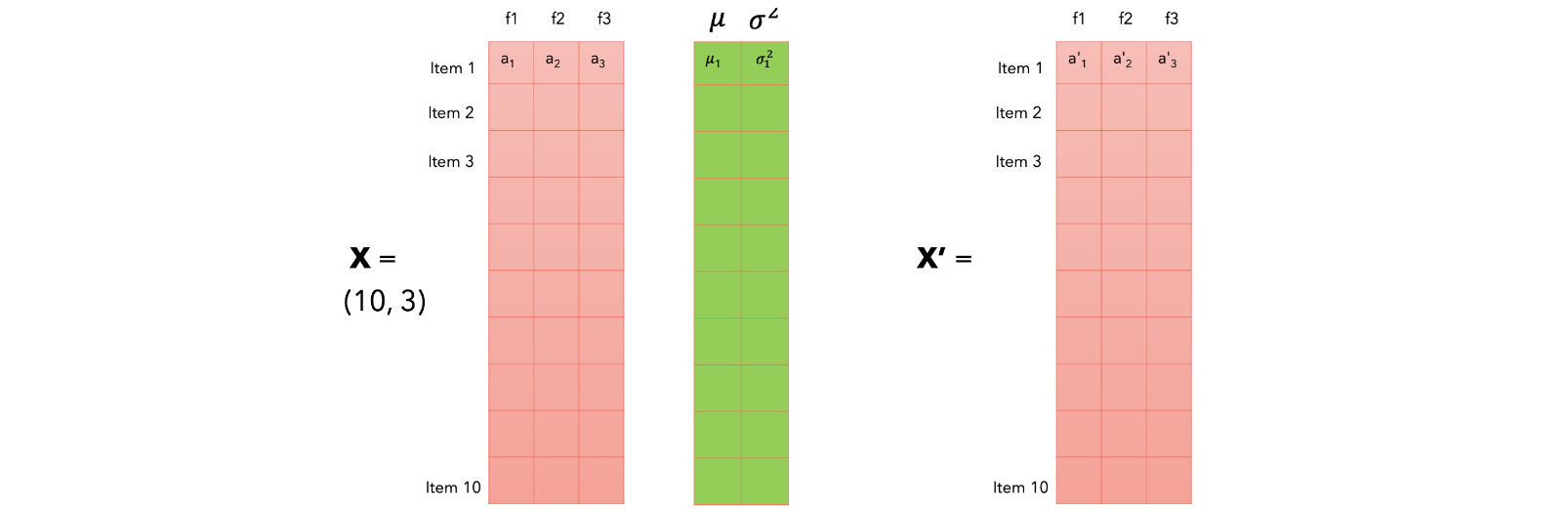
Layer Normalization是一种用于深度神经网络的归一化技术,主要用于改善网络训练的稳定性和收敛速度。Layer Normalization的核心思想是对每个样本的特征进行独立的归一化,而不是像Batch Normalization那样对整个批次的数据进行归一化。
每个项目都用其归一化的值进行更新,这将使其变成均值为0、方差为1的正态分布。两个参数
组归一化
Group Normalization(GN)是一种用于深度神经网络的归一化技术,主要用于改善网络训练的稳定性和性能。GN的核心思想是将每一层的通道(channels)分成若干组,然后在每个组内进行归一化。这种方法不依赖于批次大小,因此在小批量或在线学习场景下表现更加稳定。
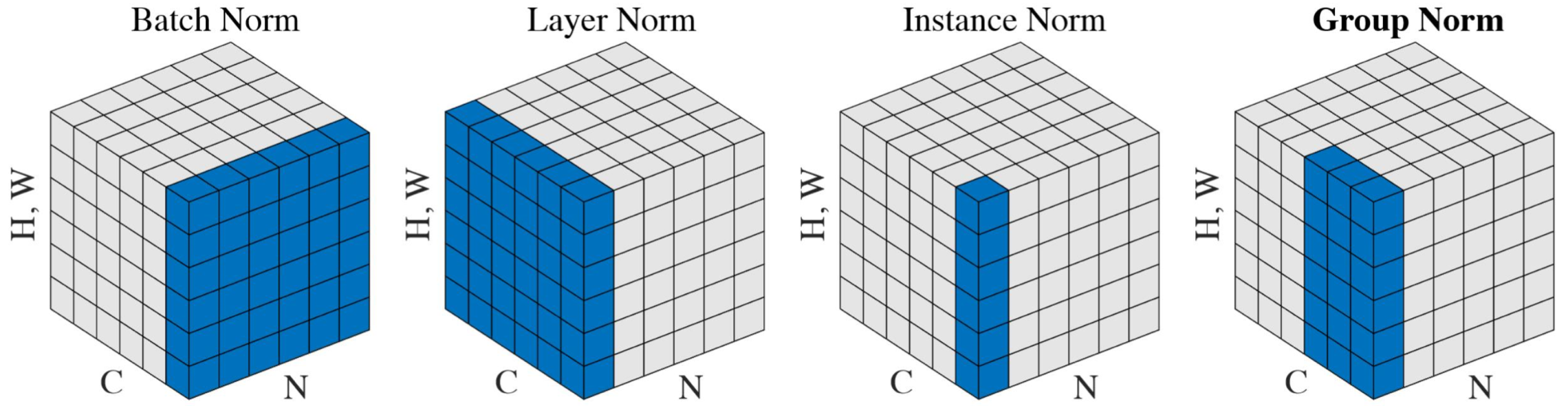
主要优势:
- 独立于批次大小:
GN的计算不依赖于批次大小,因此在小批量或在线学习场景下表现更加稳定。 - 适用于各种任务:
GN可以有效应用于图像分类、目标检测、语义分割等多种计算机视觉任务。 - 改善训练稳定性: 通过组内归一化,
GN可以减少对超参数的敏感性,提高训练稳定性。 - 灵活性: 通过调整组的数量,
GN可以在Layer Normalization和Instance Normalization之间平滑过渡。