检索增强生成(RAG):嵌入向量 & Sentence BERT & HNSW
语言模型是一种概率模型,它为单词序列分配概率。实际上,语言模型允许我们计算以下内容:我们通常训练一个神经网络来预测这些概率。在大量文本上训练的神经网络被称为大型语言模型(LLM)。

我们如何训练和推理语言模型?
- 训练:语言模型是在文本语料库(即大量文档)上进行训练的。通常,语言模型是在整个维基百科和数百万个网页上进行训练的。这使语言模型能够获取尽可能多的知识。我们通常训练基于
Transformer的神经网络作为语言模型。 - 推理:为了语言模型实现推理,我们构建一个提示词,并让语言模型通过迭代添加
token来生成剩余的部分。
语言模型只能输出经过训练的文本和信息。这意味着,如果我们只用英语内容训练语言模型,它可能无法输出中文。为了教授新的概念,我们需要对模型进行微调。它可能代价高昂。模型的参数数量可能不足以捕获我们想要教给它的所有知识。这就是为什么引入了7B、13B和70B个参数的LLaMA。微调不是附加的。它可能用新知识取代模型的现有知识。例如,一个用英语训练的语言模型,如果用中文进行(大量)微调,可能会“忘记”英语。
检索增强生成(RAG)
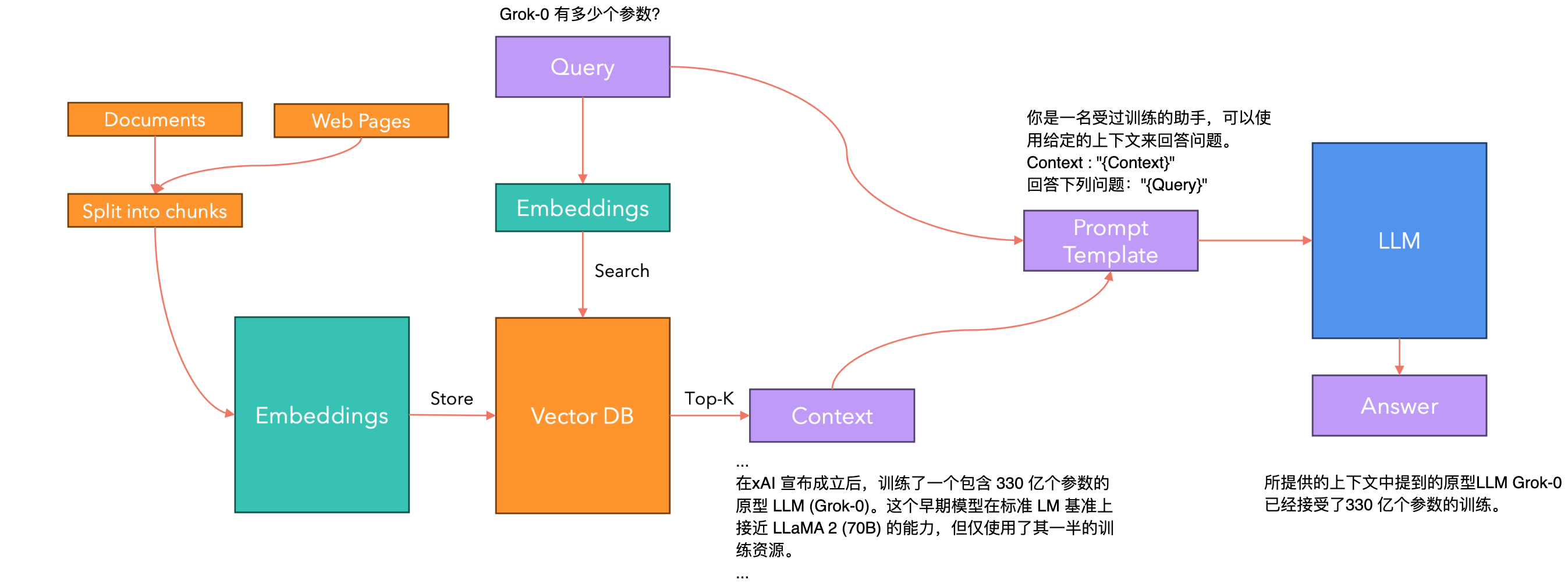
RAG(Retrieval-Augmented Generation)是一种结合了信息检索系统和生成式大语言模型(LLM)优势的AI框架。RAG通过在生成过程中引入外部知识源来增强LLM的输出。它首先检索与用户查询相关的信息,然后将这些信息与原始查询一起输入LLM,从而生成更准确、更相关的回答。主要步骤:
- 创建外部数据:将各种来源的数据转换为向量表示,存储在向量数据库中。
- 检索相关信息:将用户查询转换为向量,在向量数据库中搜索相关信息。
- 增强LLM提示:将检索到的相关信息与用户输入结合,形成增强的提示。
- 生成回答:
LLM基于增强的提示生成最终回答。
RAG的优势:
- 提高准确性:通过引入外部最新信息,减少过时或不准确的回答。
- 增强上下文理解:提供相关背景信息,使回答更加连贯和针对性强。
- 提高可信度:可以提供信息来源,增加用户信任。
- 灵活性:可以轻松更新外部知识库,无需重新训练整个模型。
RAG通过结合外部知识和LLM的生成能力,提供了一种更加灵活、准确和可信的AI解决方案,适用于各种需要最新、专业信息的应用场景。
嵌入向量
为什么要用向量来表示单词?给定单词“cherry”, “digital”和“information”,如果我们仅使用2个维度(X,Y)表示嵌入向量并绘制它们,我们希望看到类似这样的结果:具有相似含义的单词之间的角度很小,而具有不同含义的单词之间的角度很大。因此,嵌入将单词投影到高维空间来“捕获”它们所表示的单词的含义。

我们通常使用余弦相似度,它基于两个向量之间的点积。同义词往往出现在相同的上下文中(被相同的单词包围)。例如,“teacher”和“professor”通常出现在“school”、“university”、“exam”、“lecture”、“course”等单词的包围中。反之亦然:出现在相同上下文中的单词往往具有相似的含义。这被称为分布假设。这意味着要捕捉单词的含义,我们还需要访问其上下文(围绕它的单词)。这就是我们在Transformer模型中采用自注意力机制来捕获每个token的上下文信息的原因。自注意力机制将每个token与句子中的所有其他token相关联。
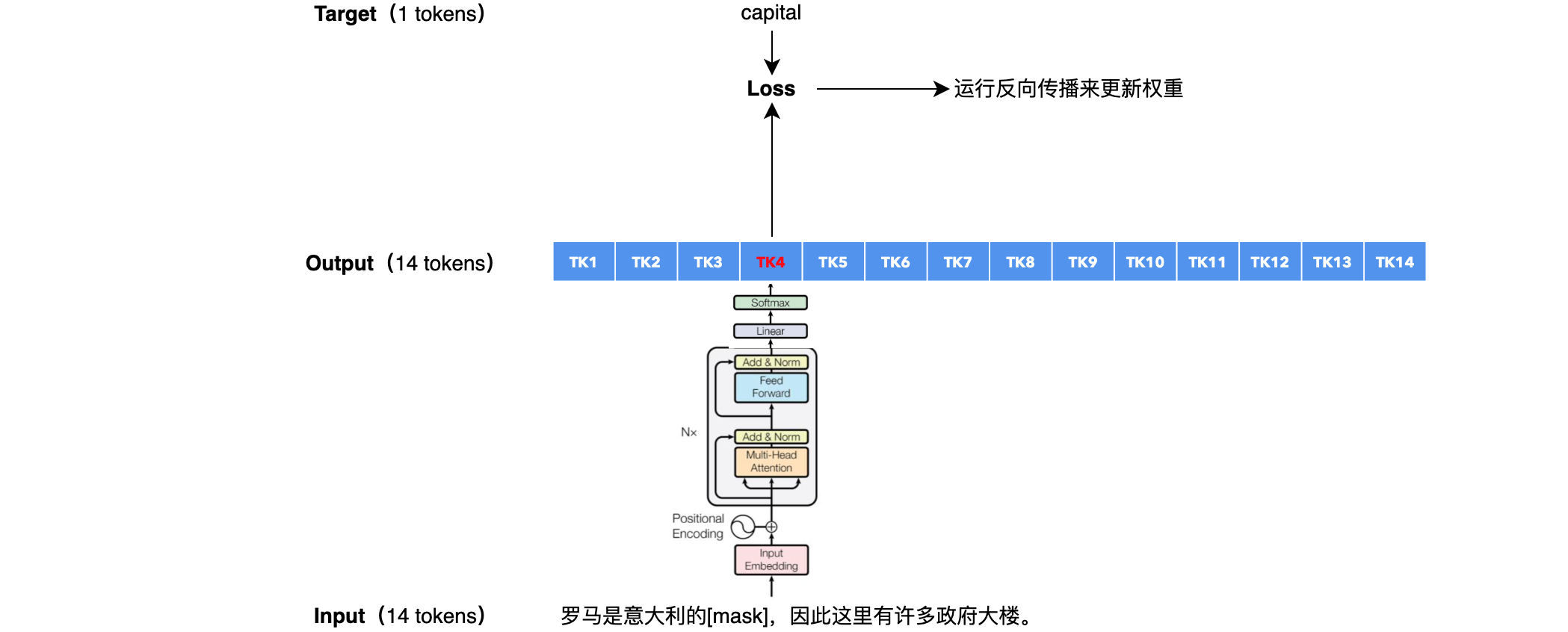
假设我给你以下句子:”罗马是意大利的_____,为什么它拥有许多政府大楼?“。你能告诉我缺失的单词是什么吗?缺少的单词是“capital”,因为从句子的其余部分来看,它是最有意义的单词。这就是我们训练 BERT的方式:我们希望自注意力机制将所有输入标记相互关联,以便BERT拥有足够的有关缺失单词的“上下文”的信息来预测它。
如何在BERT中训练嵌入向量?
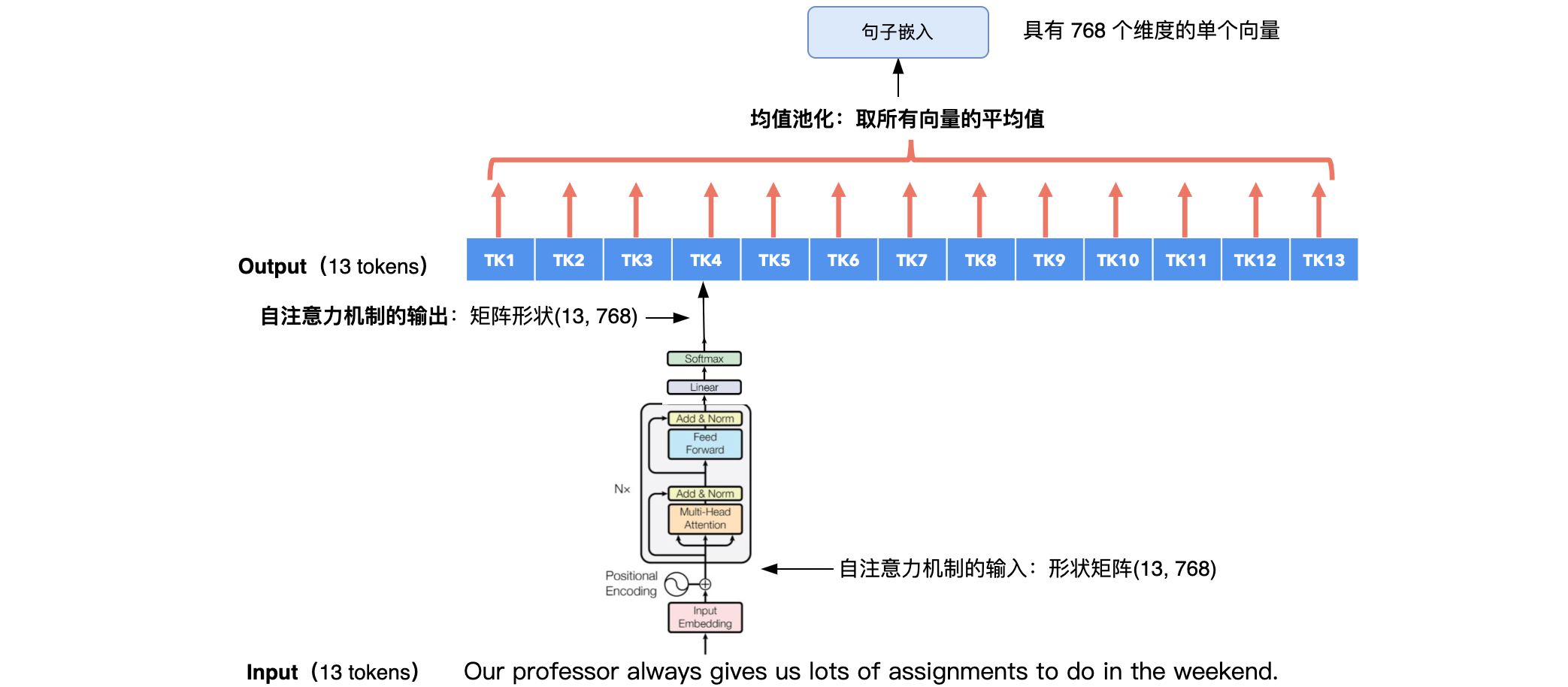
我们还可以使用自注意力机制来捕捉整个句子的“含义”。也可以使用预先训练的BERT模型来生成整个句子的嵌入。使用BERT模型进行句子嵌入:
我们如何比较句子嵌入来查看两个句子是否具有相似的“含义”?这里可以使用余弦相似度,它测量两个向量之间角度的余弦。角度越小,余弦相似度得分越高。
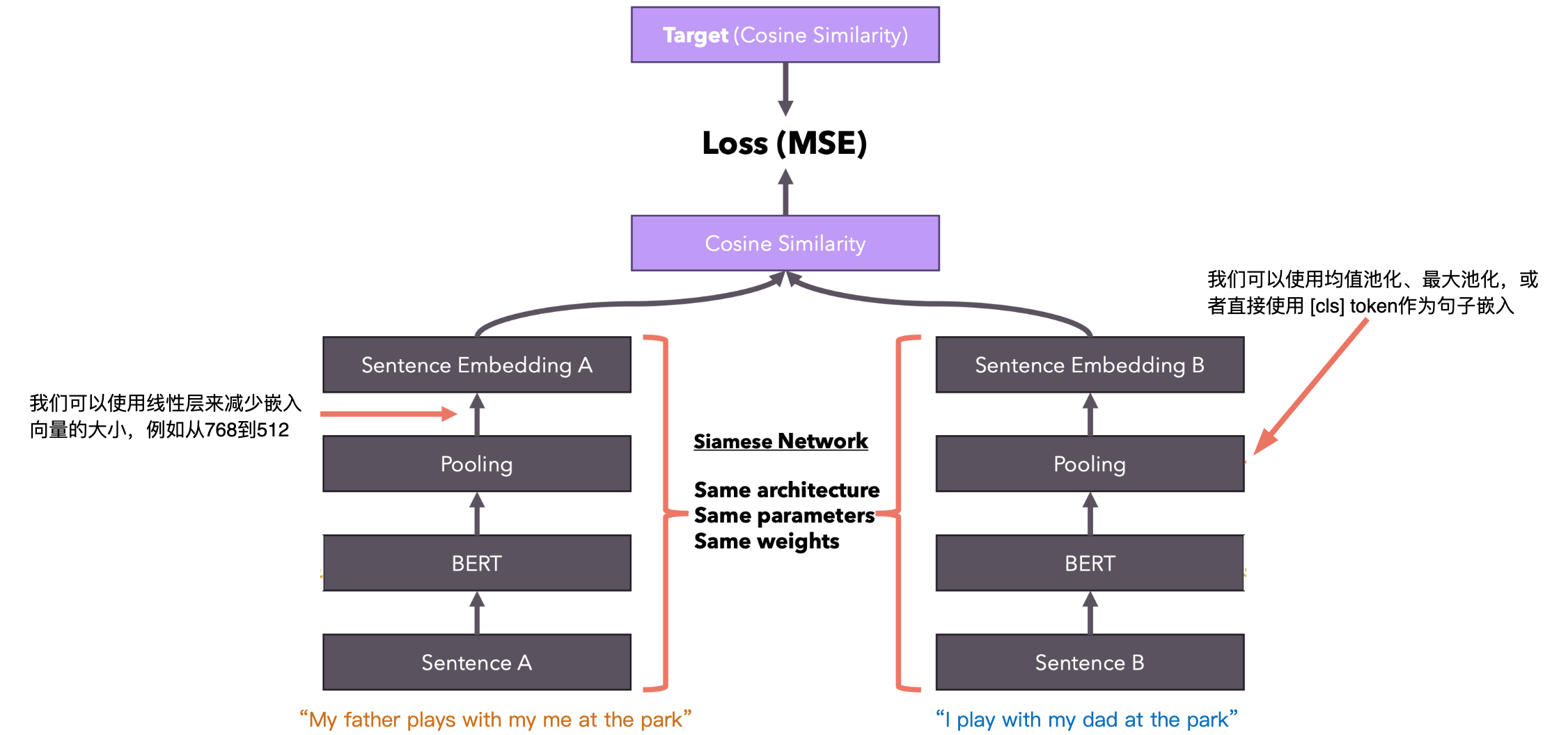
但有一个问题:没有人告诉 BERT,它生成的嵌入应该与余弦相似度相当,也就是说,两个相似的句子应该用指向空间中相同方向的向量来表示。我们如何教授BERT生成可以与我们选择的相似度函数进行比较的嵌入?
Sentence BERT(架构)
向大语言模型(LLM)教授新概念的策略。
HNSW
向量数据库
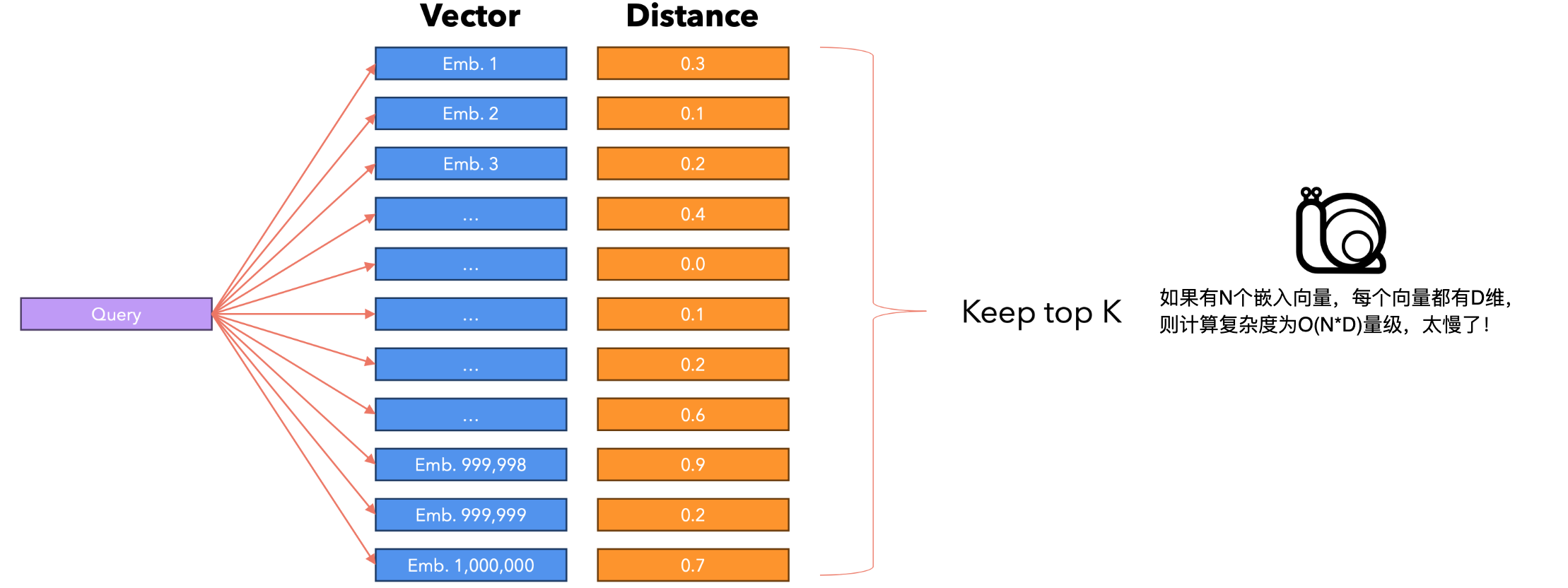
向量数据库存储固定维度的向量(称为嵌入),这样我们就可以查询数据库,使用距离度量(通常是余弦相似度,但我们也可以使用欧几里得距离)找到与给定查询向量最接近(最相似)的所有嵌入。该数据库使用 KNN(K最近邻)算法的变体或其他相似性搜索算法。向量数据库还用于查找类似的歌曲(例如Spotify)、图像(例如Google图片)或产品。
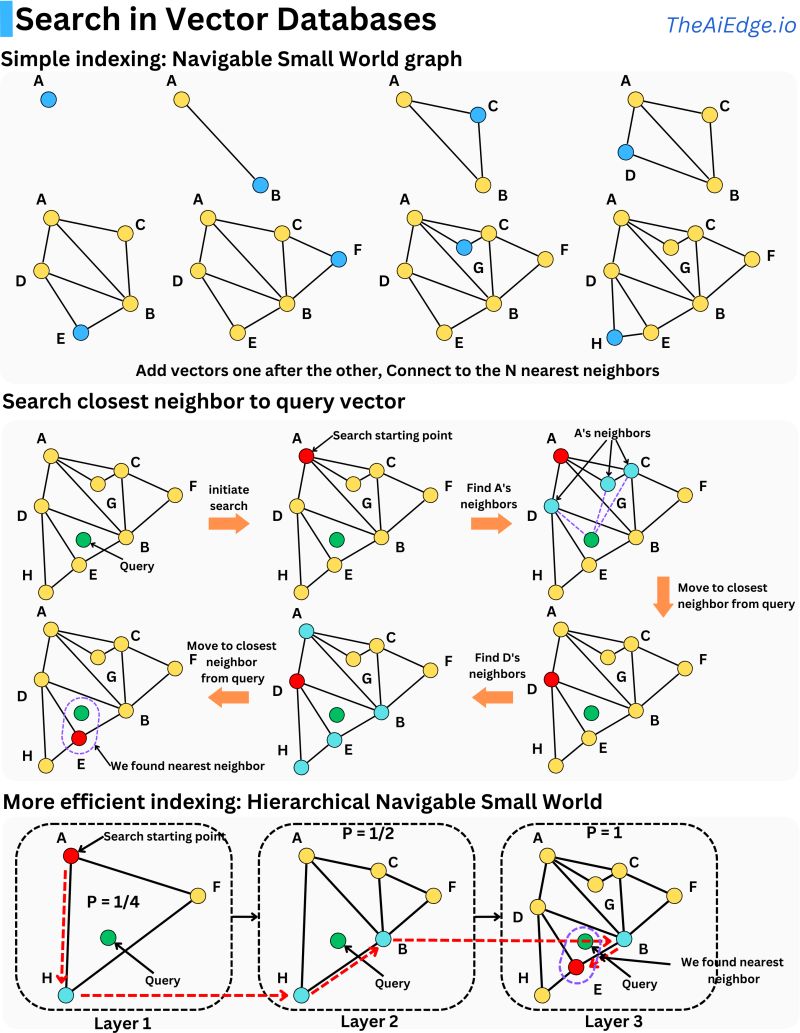
假设我们想要在数据库中搜索查询:一个简单的方法是将查询与所有向量进行比较,按距离对它们进行排序,并保留前K个。
HNSW介绍
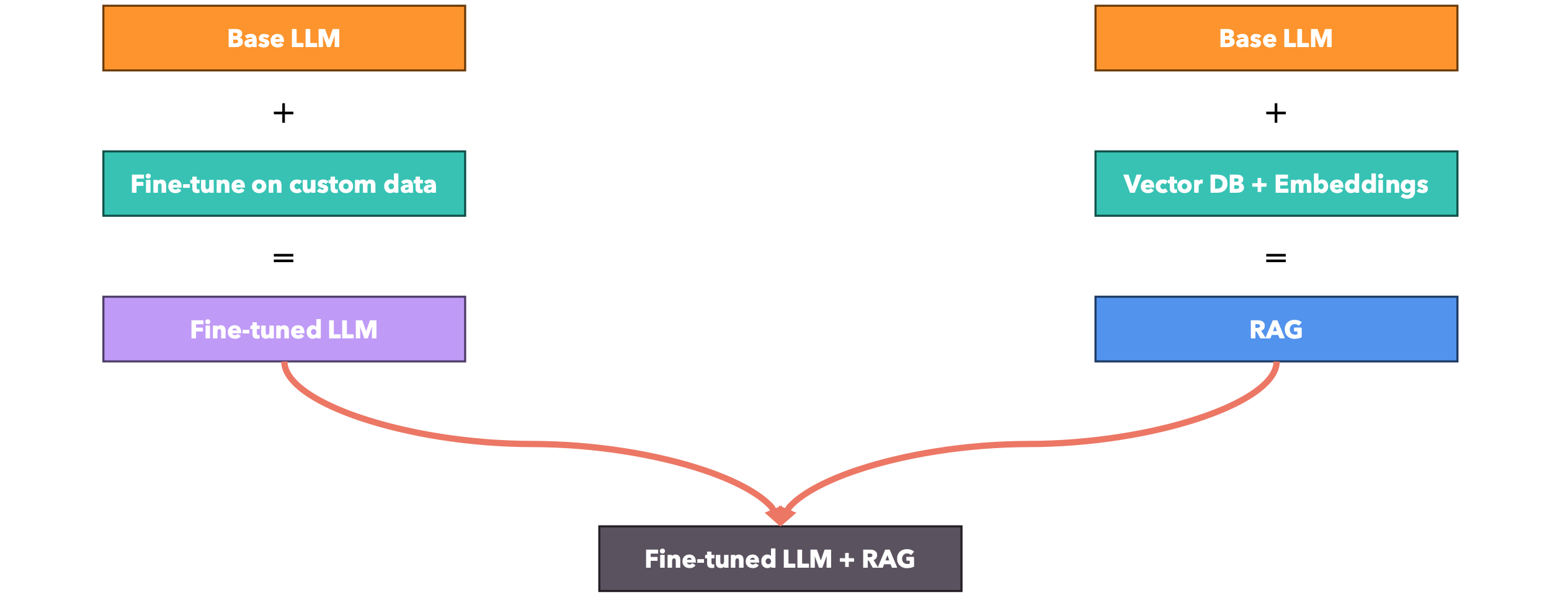
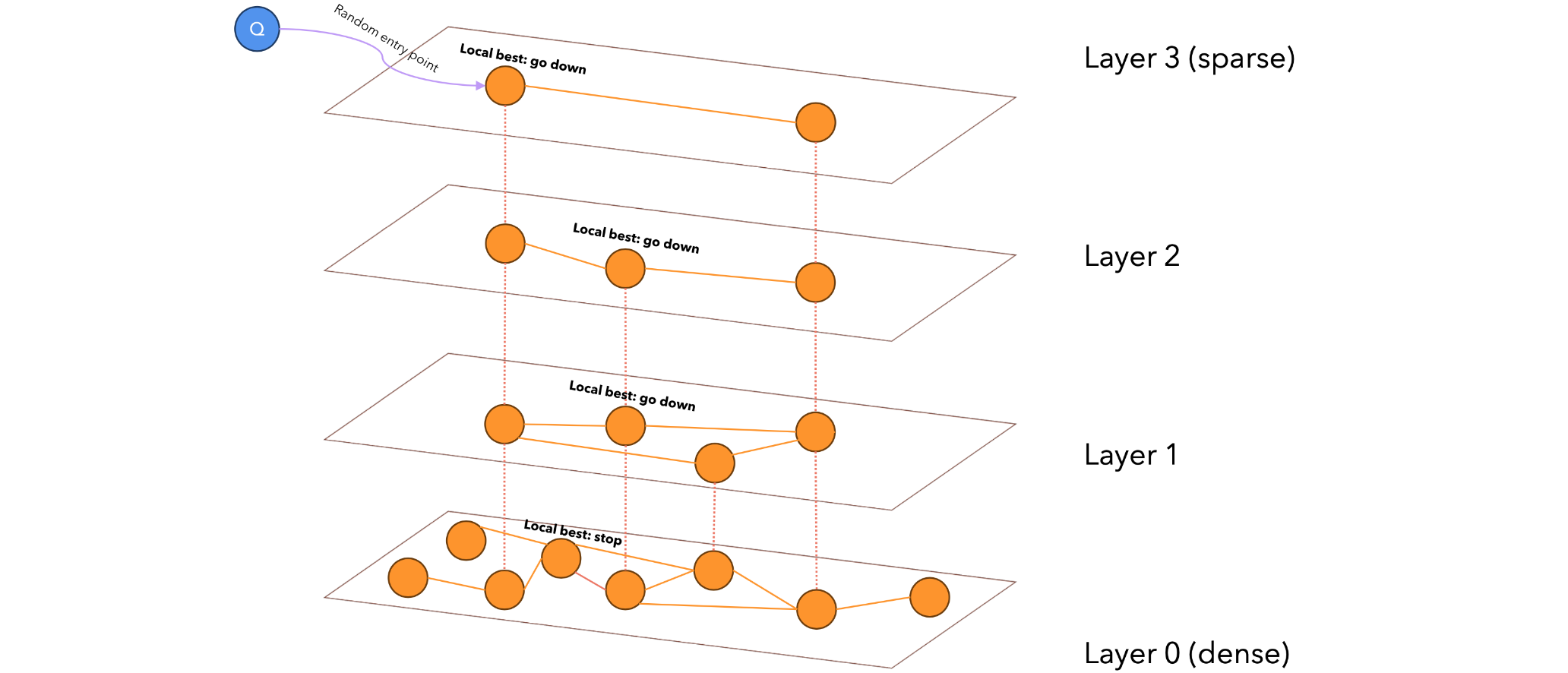
HNSW(Hierarchical Navigable Small World)是一种高效的近似最近邻搜索算法,主要用于高维向量数据的相似度搜索。分层结构:HNSW由多层图组成,形成一个分层结构;每一层都是一个NSW(Navigable Small World)图;上层连接较长,节点较少;下层连接较短,节点较多。搜索过程:从最顶层开始搜索,逐层向下进行;在每一层中使用贪婪搜索找到最近的节点;将找到的节点作为下一层搜索的起始点。图构建:节点被随机分配到不同层级,概率呈指数衰减;使用启发式方法选择邻居节点,优化图的连接性。关键参数:M和Mmax:控制每个节点的最大连接数;efConstruction:影响图构建过程的精确度。优势:搜索时间复杂度为对数级别,比NSW更高效;在高维数据上表现良好;能在保持高查询速度的同时提供高质量的近似结果。HNSW通过其独特的分层结构和图构建方法,在保证搜索质量的同时大大提高了搜索效率,特别适合处理大规模高维数据的近似最近邻搜索问题。
相似性搜索:用精度换取速度,我们之前使用的简单方法总是会产生准确的结果,因为它将查询与所有存储的向量进行比较,但如果我们减少比较的次数,但仍然以高概率获得准确的结果会怎样?在相似性搜索中我们通常关心的指标是召回率。
HNSW是近似最近邻的可导航小世界算法的演变,该算法基于六度分离的概念。米尔格拉姆的实验旨在测试美国人之间的社会联系。最初位于内布拉斯加州和堪萨斯州的参与者被要求将一封信寄给波士顿的某个人。但是,他们不能直接把信寄给收信人。相反,他们被要求把信寄给他们认识的人,他们认为这个人更有可能认识目标人。在米尔格拉姆的小世界实验结束时,米尔格拉姆发现大多数信件需要五到六个步骤才能到达最终收件人,这创造了一个概念,即全世界的人都是通过六度分离联系在一起的。Facebook在2016年发现,其15.9亿活跃用户之间的联系平均有3.5个分离度:参考文章。这意味着您和马克·扎克伯格仅相隔3.5个连接!
NSW算法构建了一个图谱,就像Facebook好友一样,将距离较近的向量相互连接,但保持连接总数较少。例如,每个向量最多可以连接到6个其他向量(在模拟六度分离)。
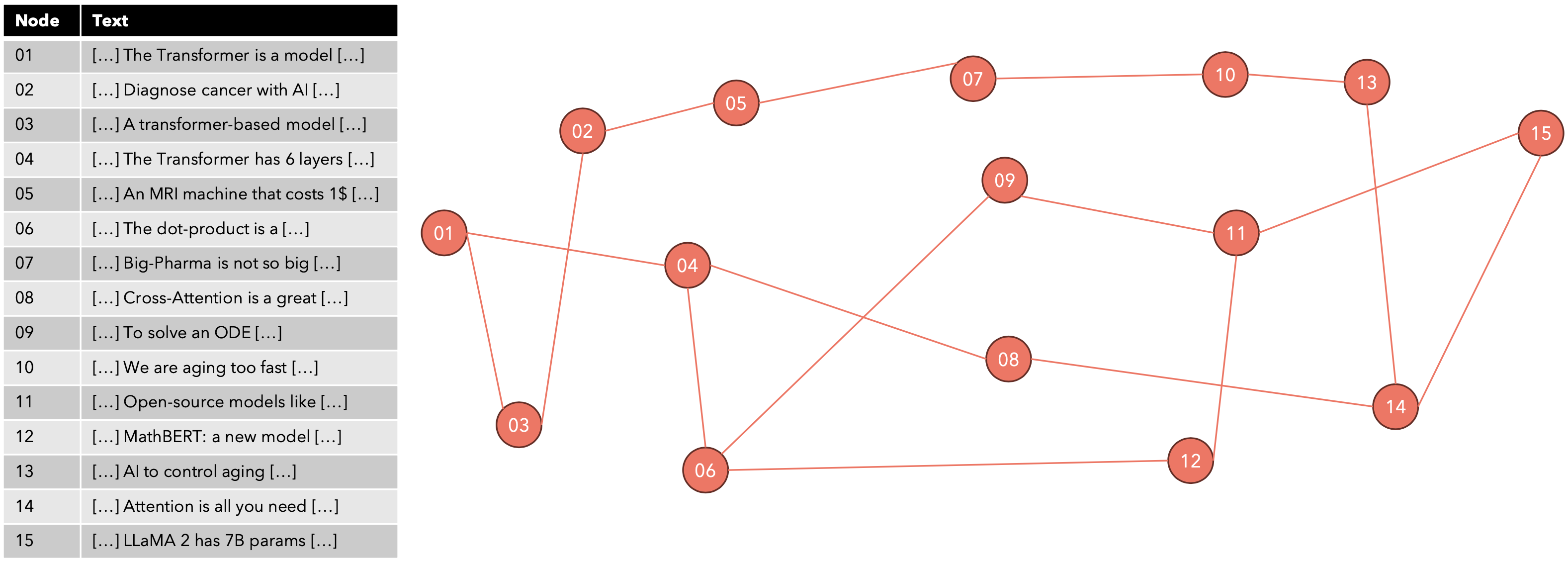
给出以下查询:“Transformer模型中有多少个编码器层?”算法如何找到K个最近邻?我们使用随机选择的起点重复搜索,然后在所有访问的节点中保留前K个结果。
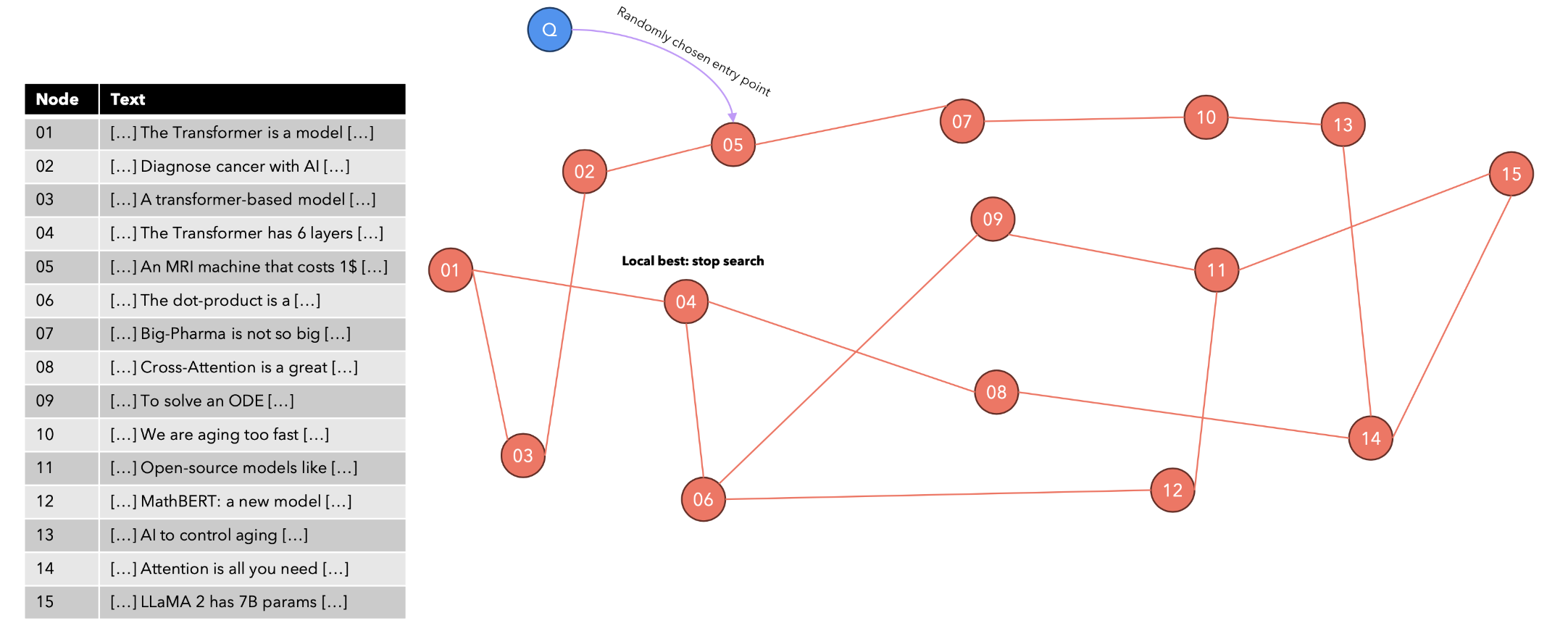
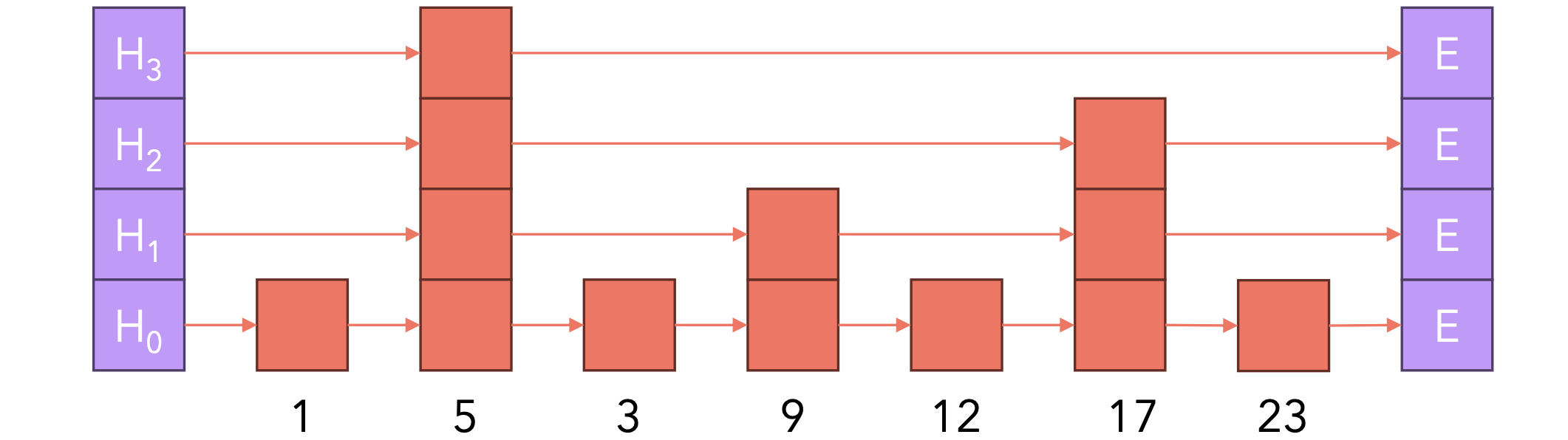
我们可以通过使用前面描述的搜索算法搜索top KNN并在向量和前K个结果之间建立边来插入一个新向量。要从NSW(可导航小世界)转变为HNSW(分层可导航小世界),我们需要引入跳跃表(Skip-List)的数据结构。跳跃表是一种维护排序列表的数据结构,允许以9。
我们使用随机选择的起点(在顶层)重复搜索,然后在所有访问的节点中保留前K个结果。
带有检索增强生成的问答系统: