BERT模型—探析(Transformer)
语言模型是一种概率模型,它为单词序列分配概率。实际上,语言模型允许我们计算以下内容:我们通常训练一个神经网络来预测这些概率。在大量文本上训练的神经网络被称为大型语言模型(LLM)。

怎样训练&推理一个语言模型?假设我们想要训练一个中文诗歌语言模型,例如下面这个:
假设你是一个(懒惰的)学生,必须记住李白的诗,但只记得前两个字。你如何背诵出全诗?


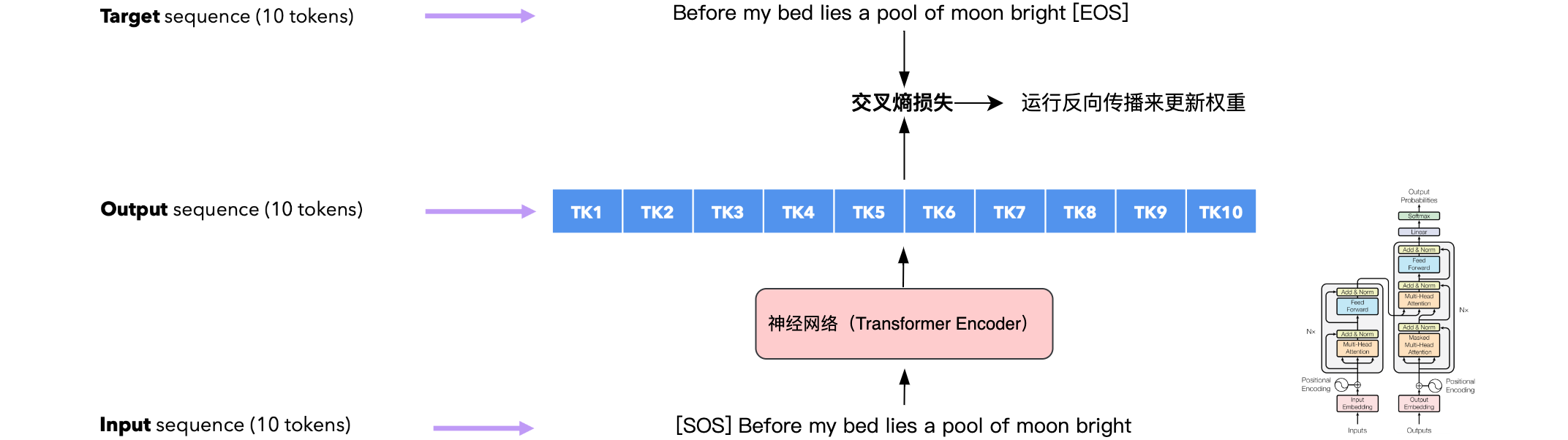
Transformer Encoder架构
让我们将输入转换为输入嵌入。定义
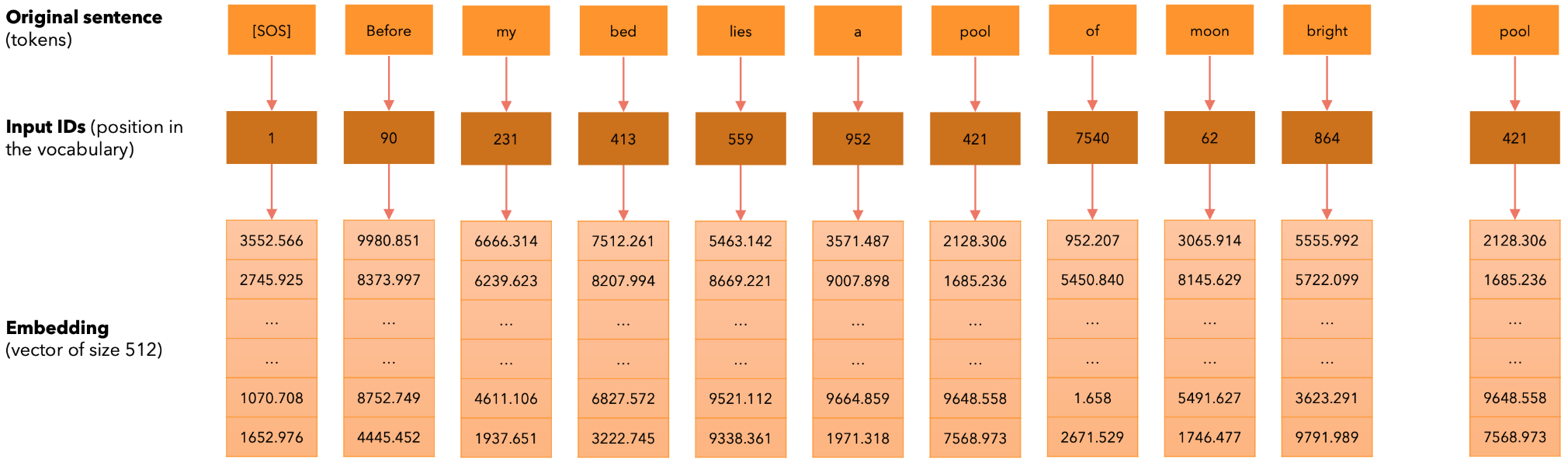
为什么我们要用向量来表示单词?给定单词“cherry”、“digital”和“information”,如果我们仅使用2个维度(X,Y)表示嵌入向量并绘制它们,我们希望看到类似这样的结果:具有相似含义的单词之间的角度很小,而具有不同含义的单词之间的角度很大。因此,通过嵌入将单词投影到大小为

我们通常使用余弦相似度,它是基于两个向量之间的点积,接下来让我们添加位置编码。每个token都转换为词汇表中的位置(input_id),然后我们将每个input_id转换成大小为512的嵌入向量。接下来,我们给每个token添加一个大小为512的向量,以指示其在句子中的位置(位置编码)。位置编码在训练和推理期间仅计算一次并对每个句子重复使用。
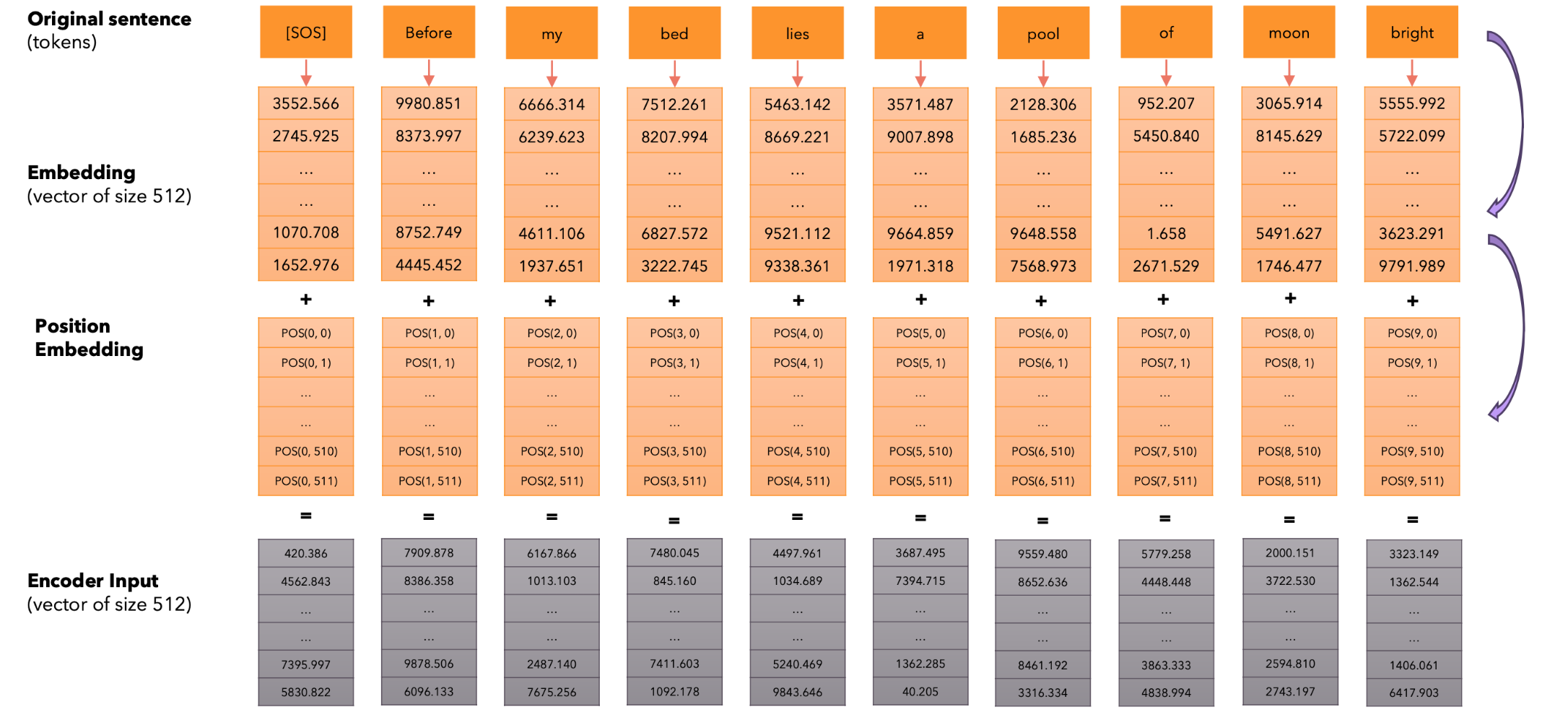
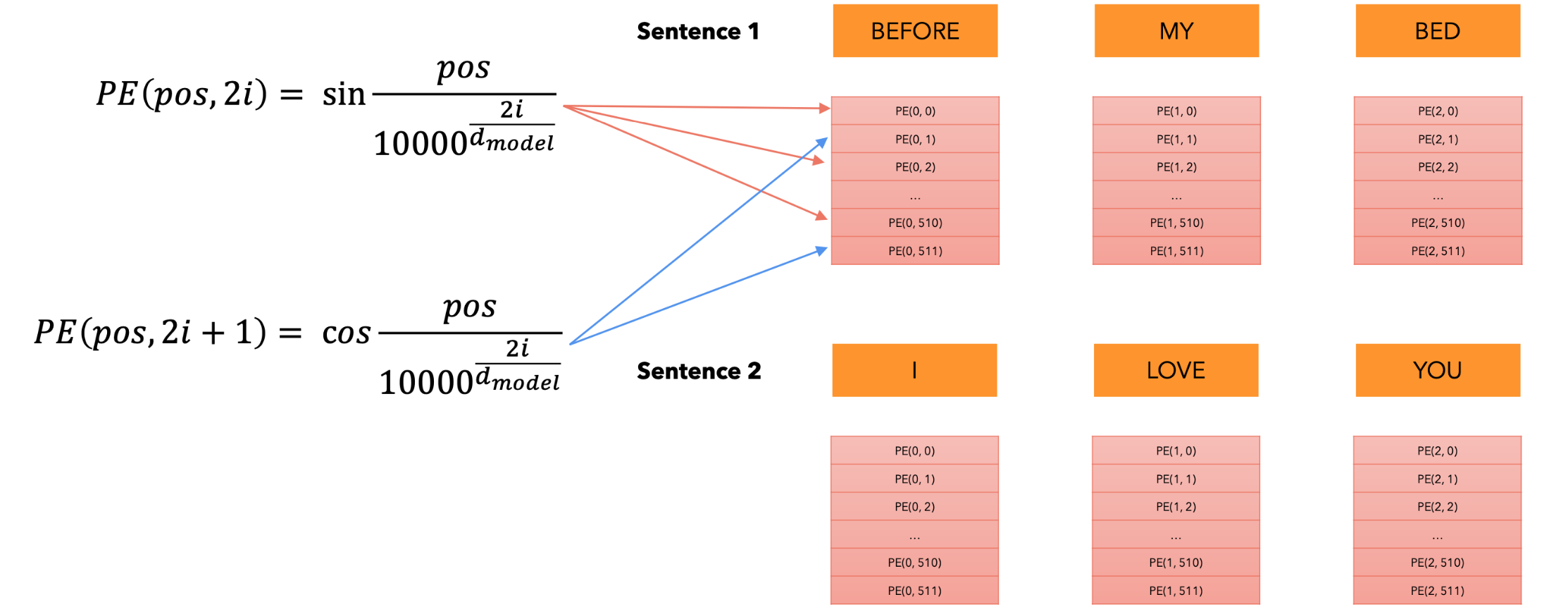
如何计算位置编码?注意,我们只需要计算一次位置编码,然后在每个句子中重复使用它们,无论是训练还是推理。
自注意力机制:输入。每个token都被转换成它在词汇表中的位置(input_id),然后我们将每个input_id转换成大小为512的嵌入向量并添加其位置向量(位置编码)。

形状为(10, 512)的矩阵,其中每一行代表输入序列中的一个token。
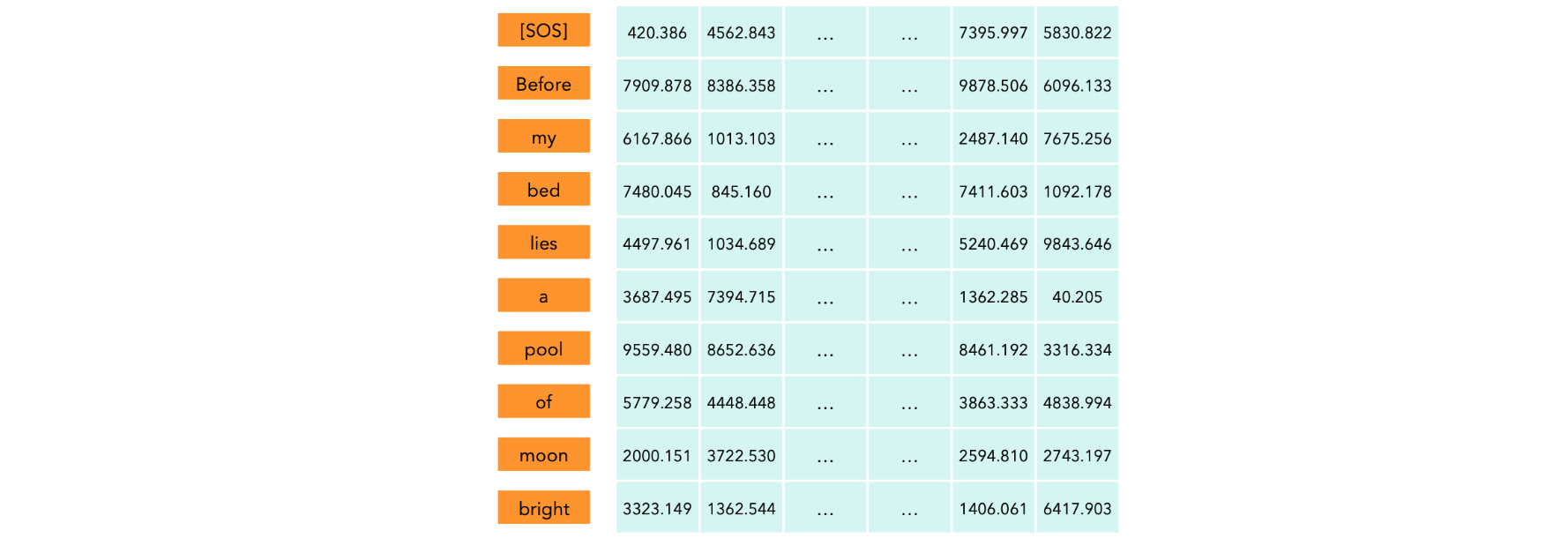
自注意力机制:Q、K和V。在大型语言模型(LLM)中,我们采用自注意力机制,这意味着查询(Q)、键(K)和值(V)是同一个矩阵。
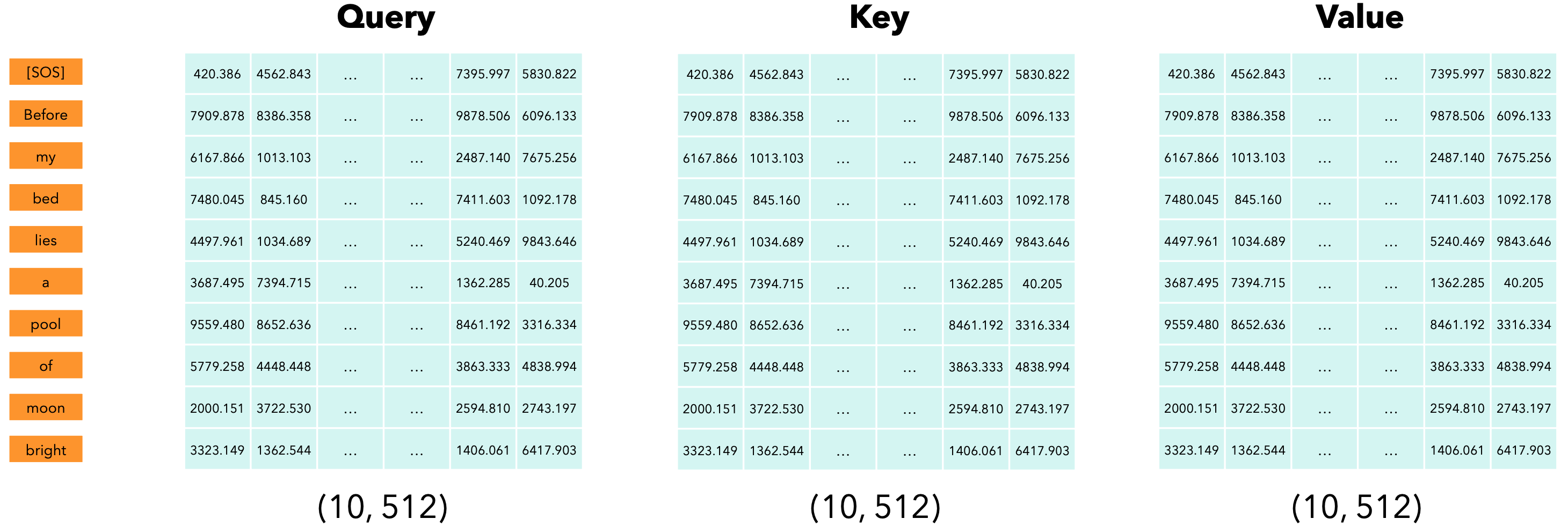
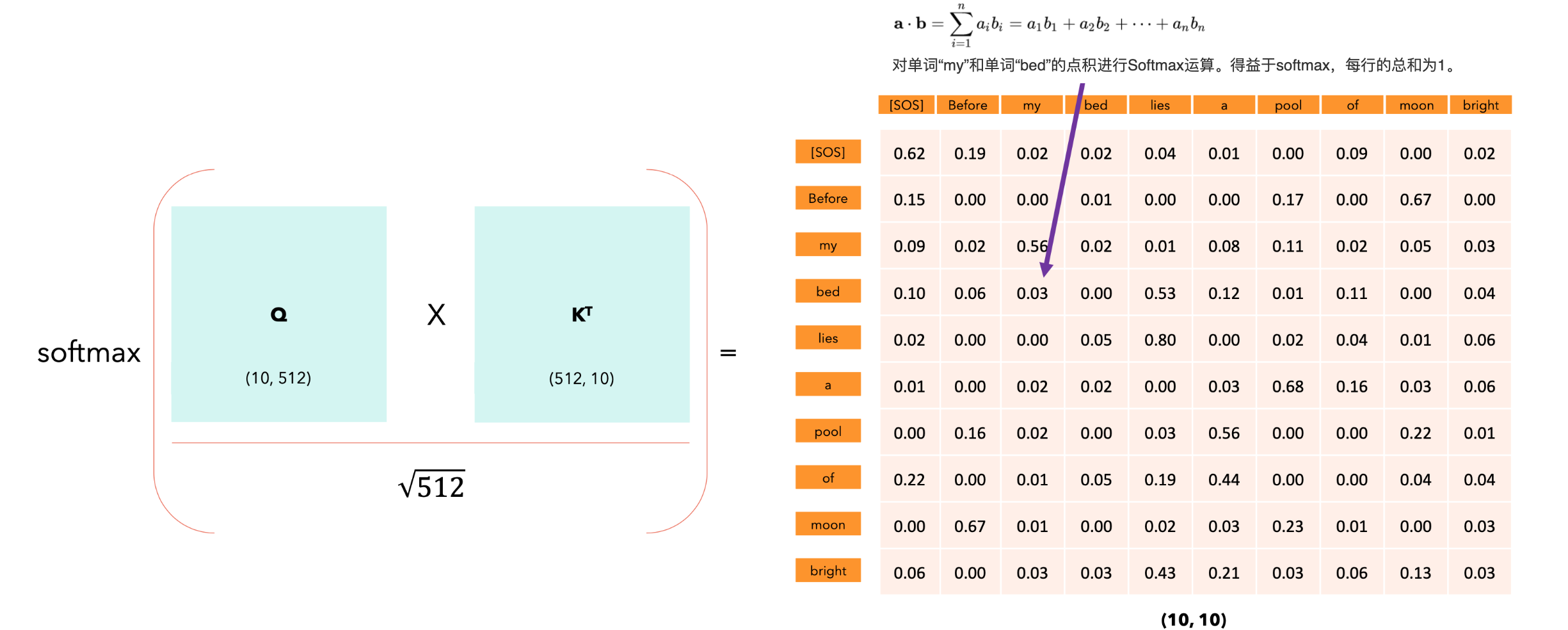
自注意力机制让模型能够将单词相互关联。在我们的例子中,
自注意力机制:因果掩码,语言模型是一种概率模型,它为单词序列分配概率。实际上,语言模型允许我们计算以下内容:
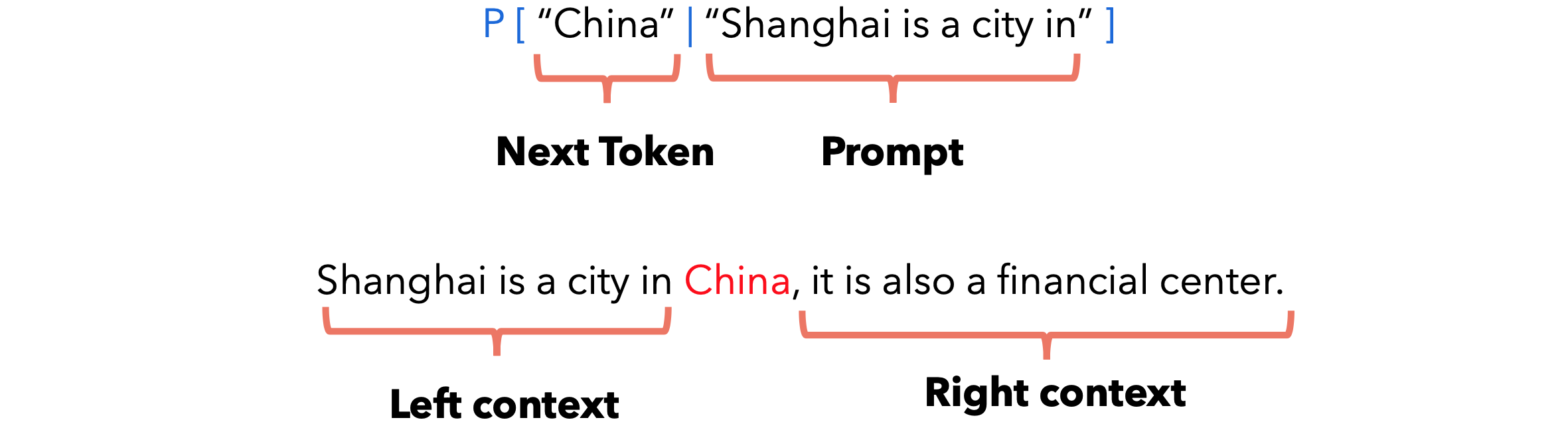
为了对上述概率分布进行建模,每个单词应该只依赖于它之前的单词(左上下文)。稍后会看到,在BERT中我们同时使用了左上下文和右上下文。
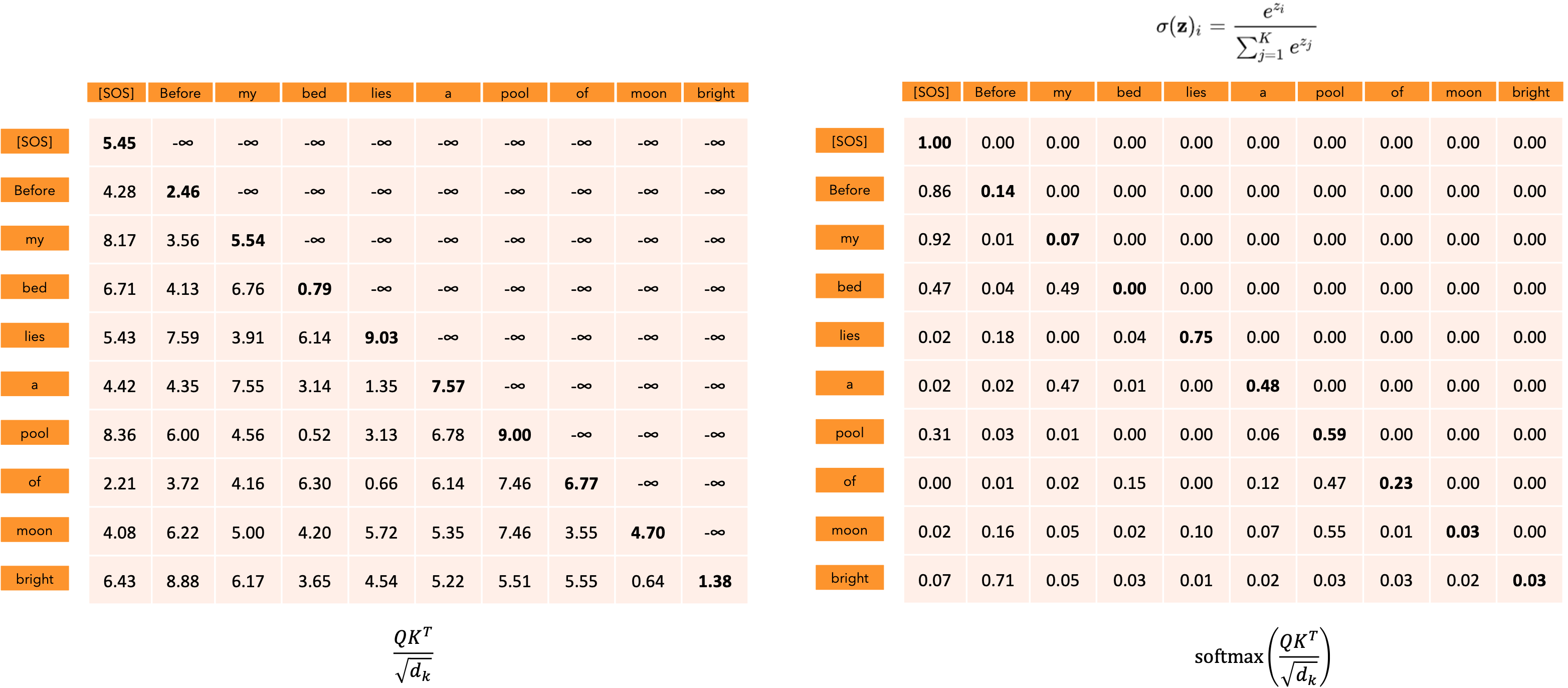
“注意力输出”矩阵的每一行代表输出序列的嵌入:它不仅捕获每个标记的含义、位置,还捕获每个标记与所有其他标记的交互,但只捕获softmax分数不为零的交互。每个向量的512个维度仅取决于非零的注意力分数。
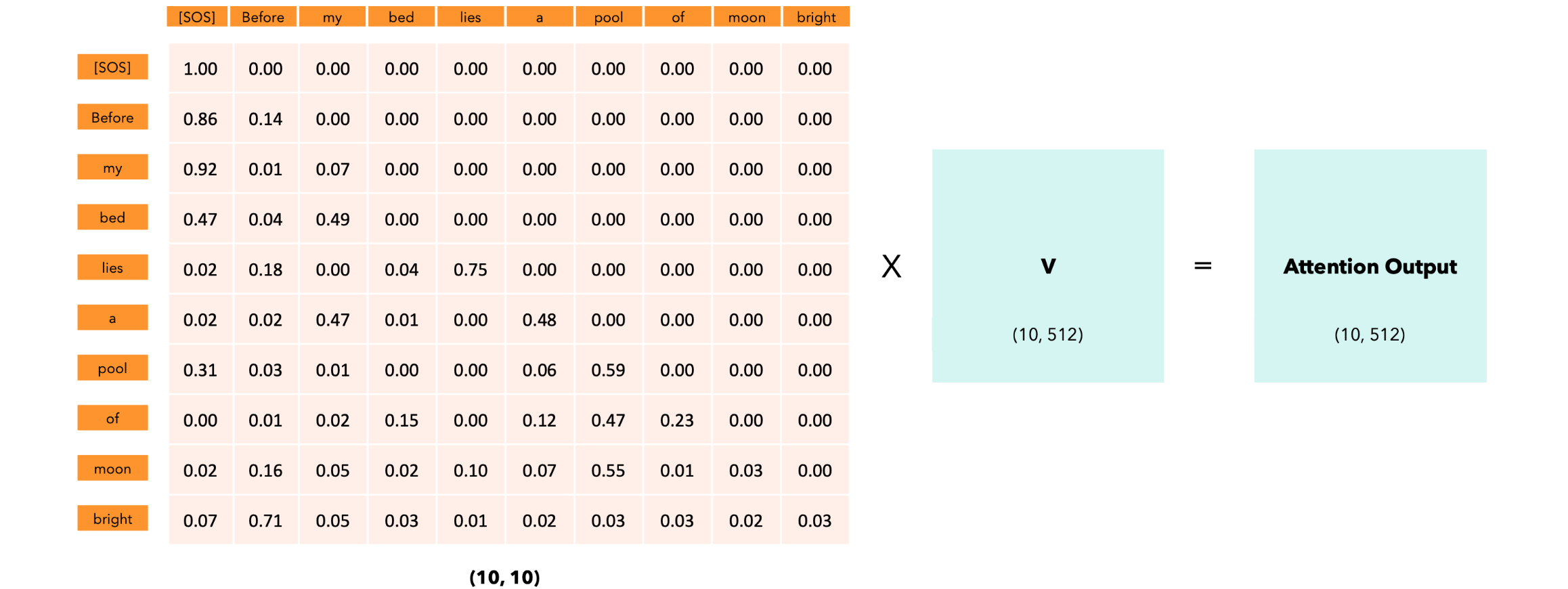
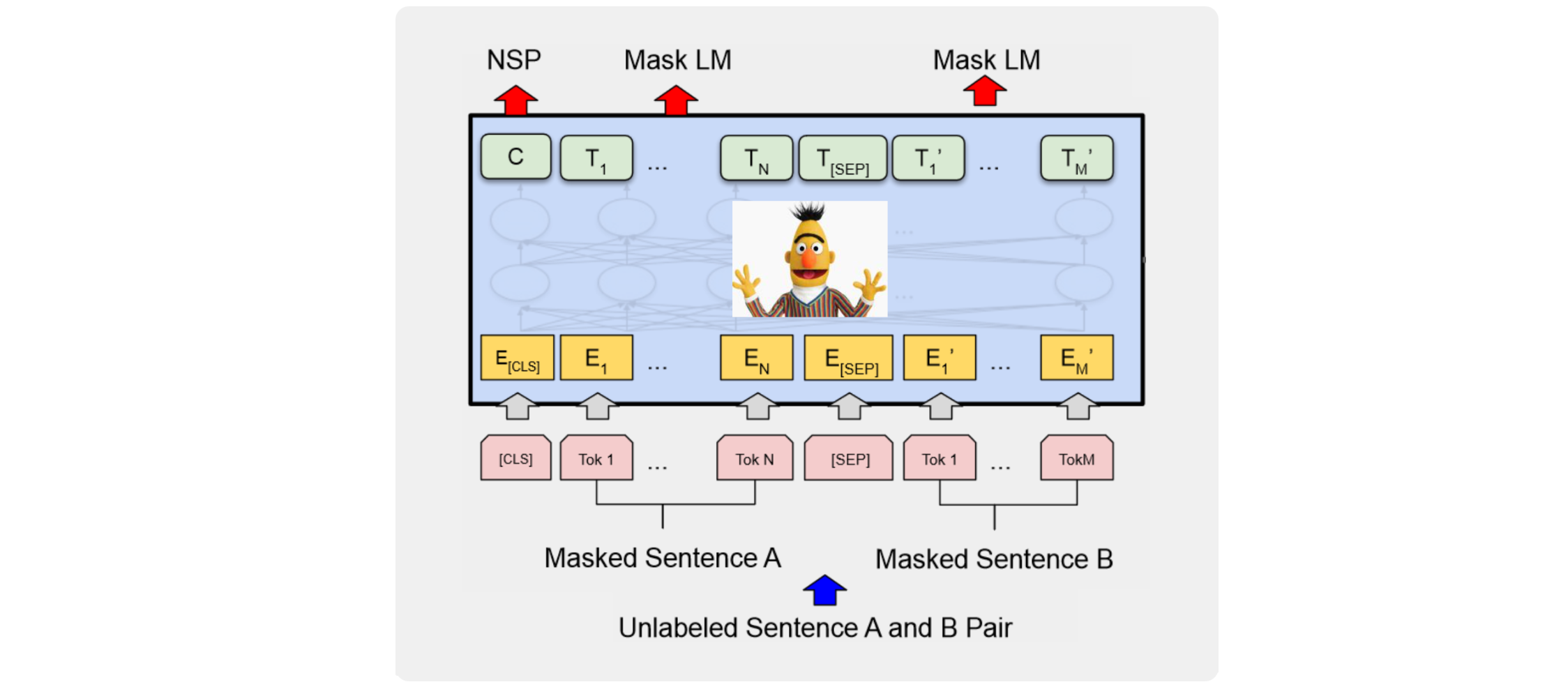
BERT模型
BERT的架构由Transformer模型的编码器层组成:
BERT BASE:12个编码器层、前馈层隐藏层的大小为3072、12个注意力头。BERT LARGE:24个编码器层、前馈层隐藏层的大小为4096、16个注意力头。
与vanilla Transformer的区别:
- 两个模型的嵌入向量分别为
768和1024。 - 位置嵌入是绝对的,在训练过程中学习,并且限制为
512个位置。 - 线性层头根据应用程序而变化。
使用WordPiece标记器,它还允许使用子词token。词汇表大小约为30,000个token。
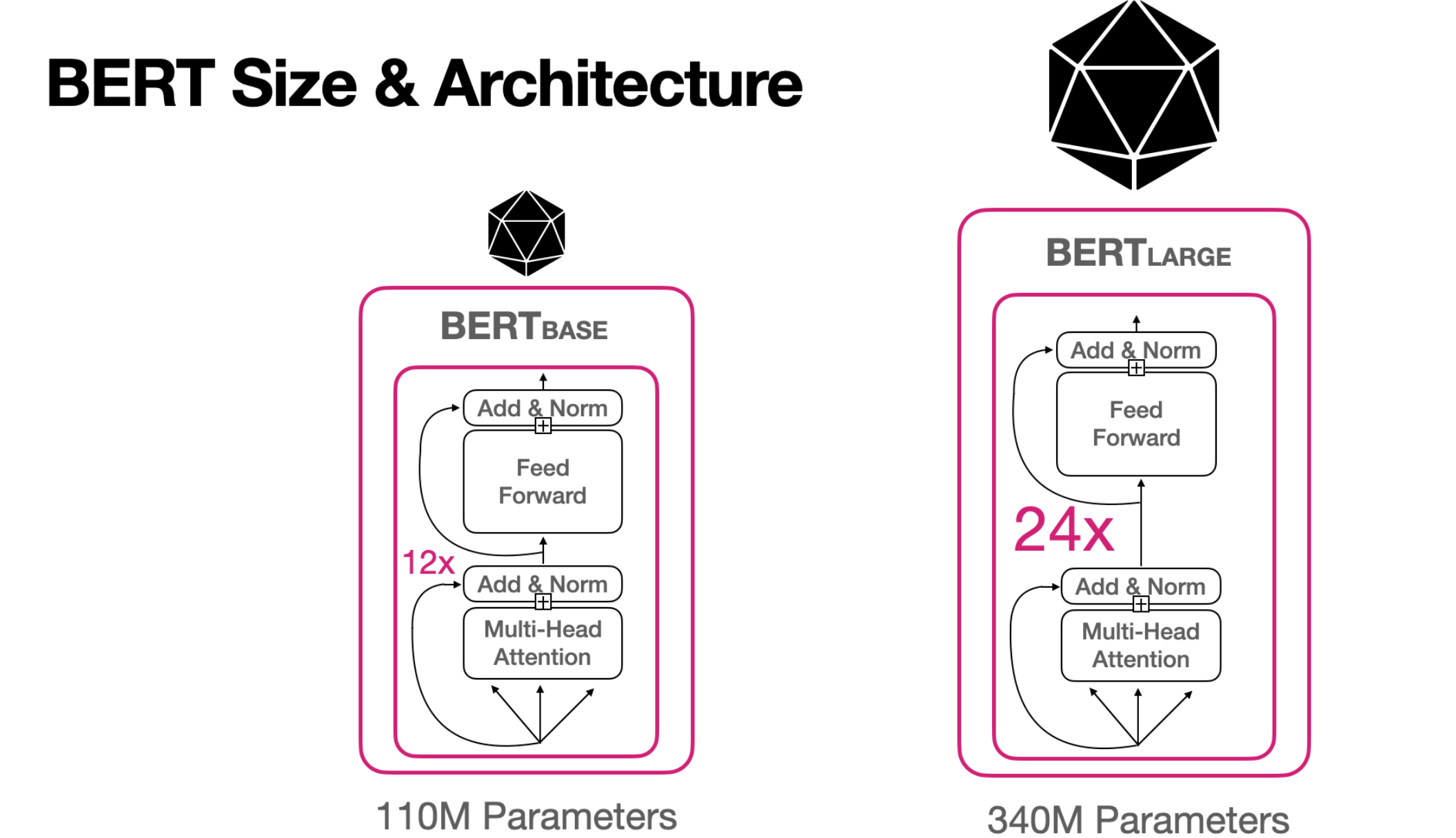
BERT代表Transformer的双向编码器模型。
- 与常见语言模型不同,
BERT不会处理带有提示的“special tasks”,而是可以通过微调专门处理特定任务。 - 与常见语言模型不同,
BERT已使用左上下文和右上下文进行训练。 - 与常见语言模型不同,
BERT并非专门为文本生成而构建。 - 与常见语言模型不同,
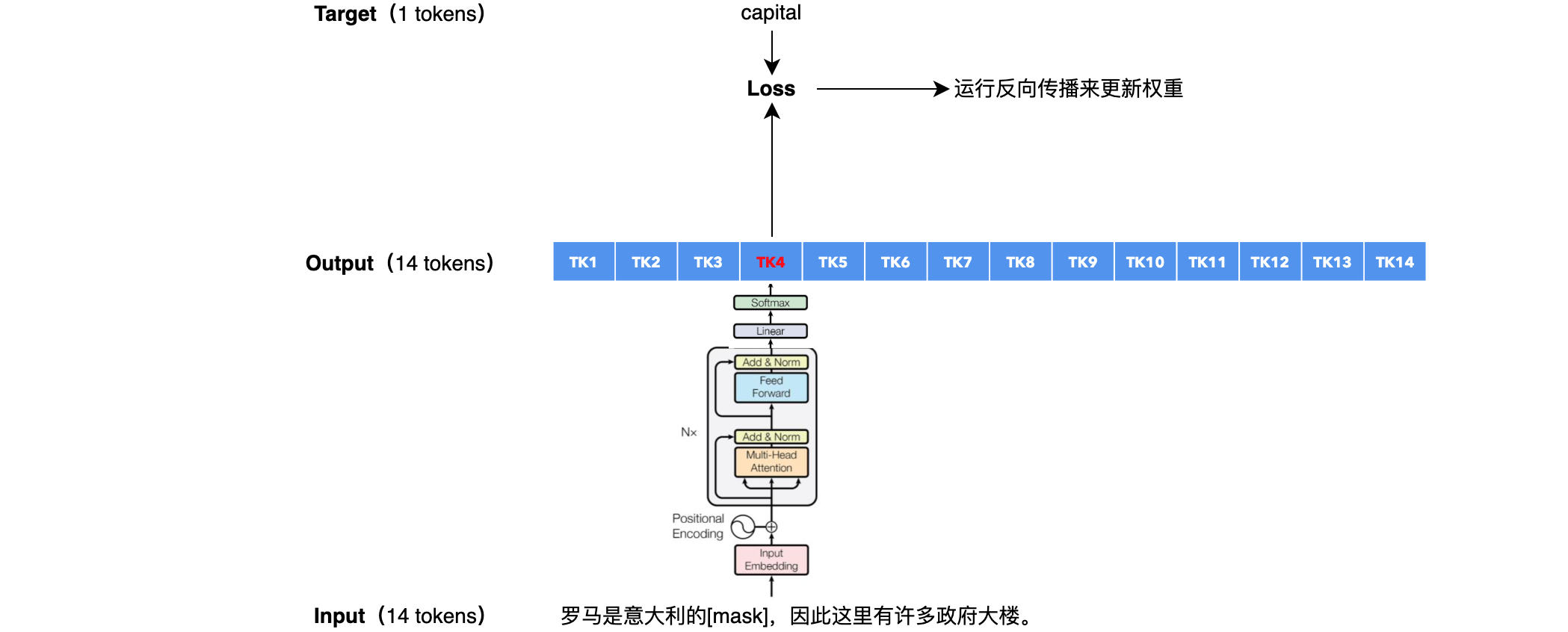
BERT不在下一个Token预测任务上进行训练,而是在Masked Language Model和下一个句子预测任务上进行训练。
掩蔽语言模型 (MLM)
也称为完形填空任务。这意味着句子中随机选择的单词被屏蔽,并且模型必须根据左右上下文预测正确的单词,BERT中的左/右上下文。
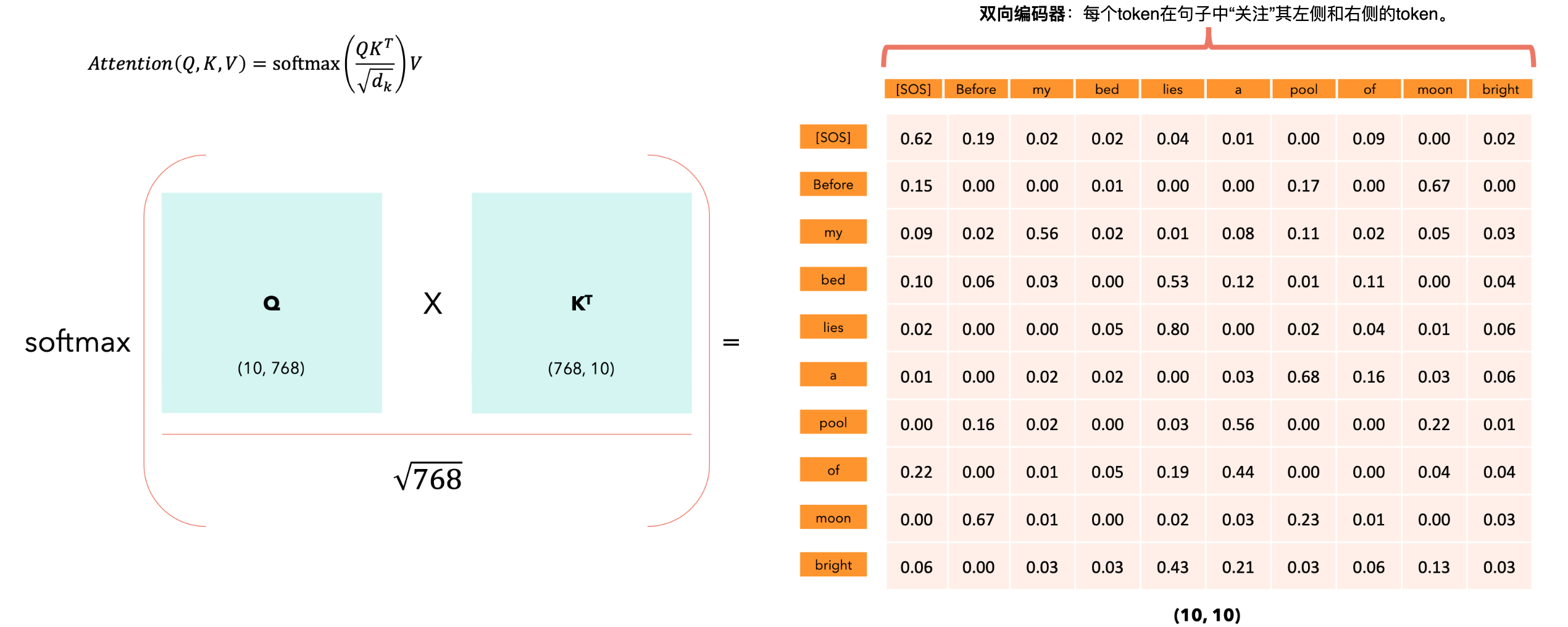
掩蔽语言模型(MLM):训练。
下一句预测(NSP)。许多下游应用(例如在4个选项中选择正确答案)需要学习句子之间的关系而不是单个token,这就是为什么BERT已在下一句预测任务上进行了预训练。给定句子A和句子B,BERT如何理解哪些token属于句子A,哪些属于句子B?我们引入了分割嵌入。我们还引入了两个特殊token:[CLS]和[SEP]。
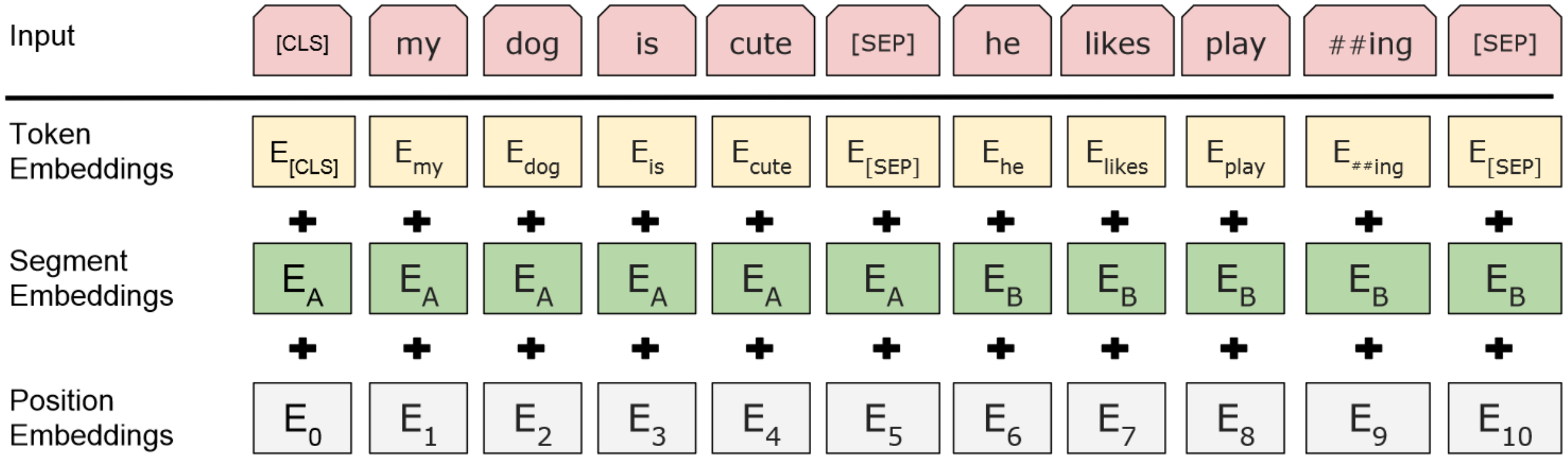
BERT中的[CLS] token。
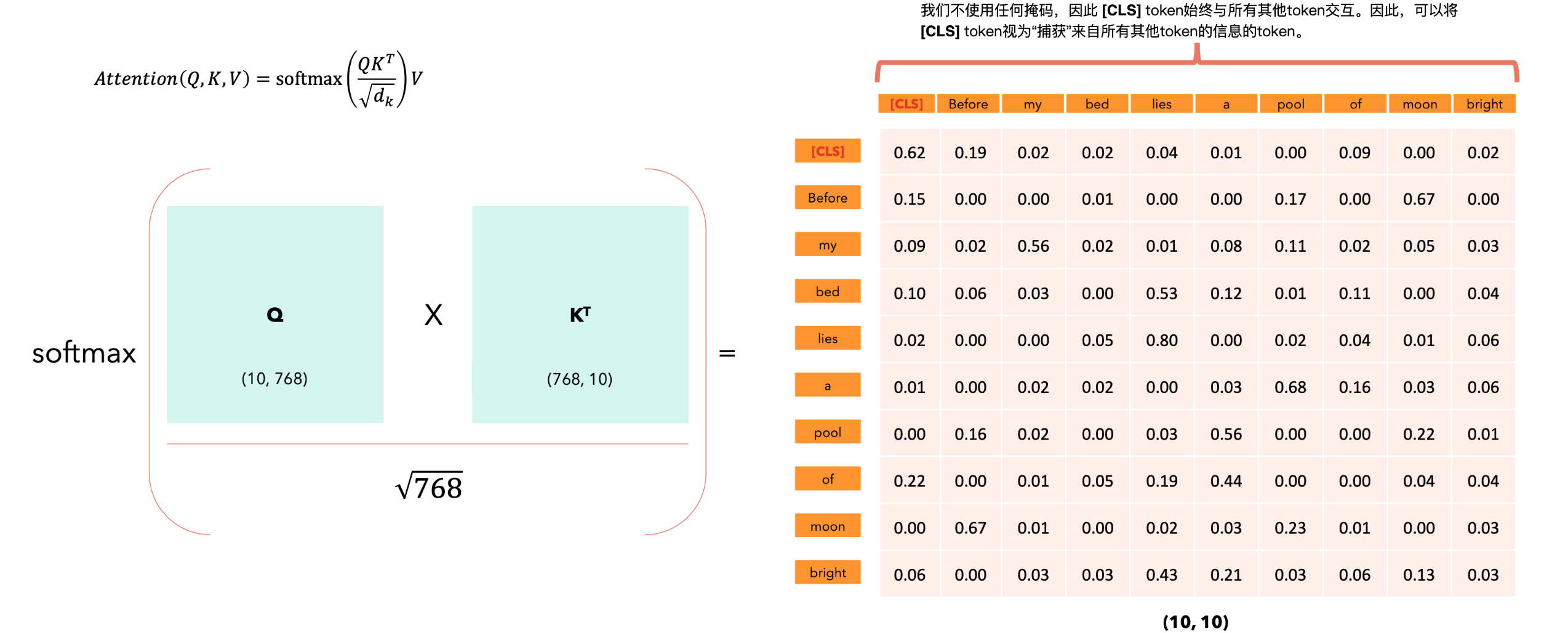
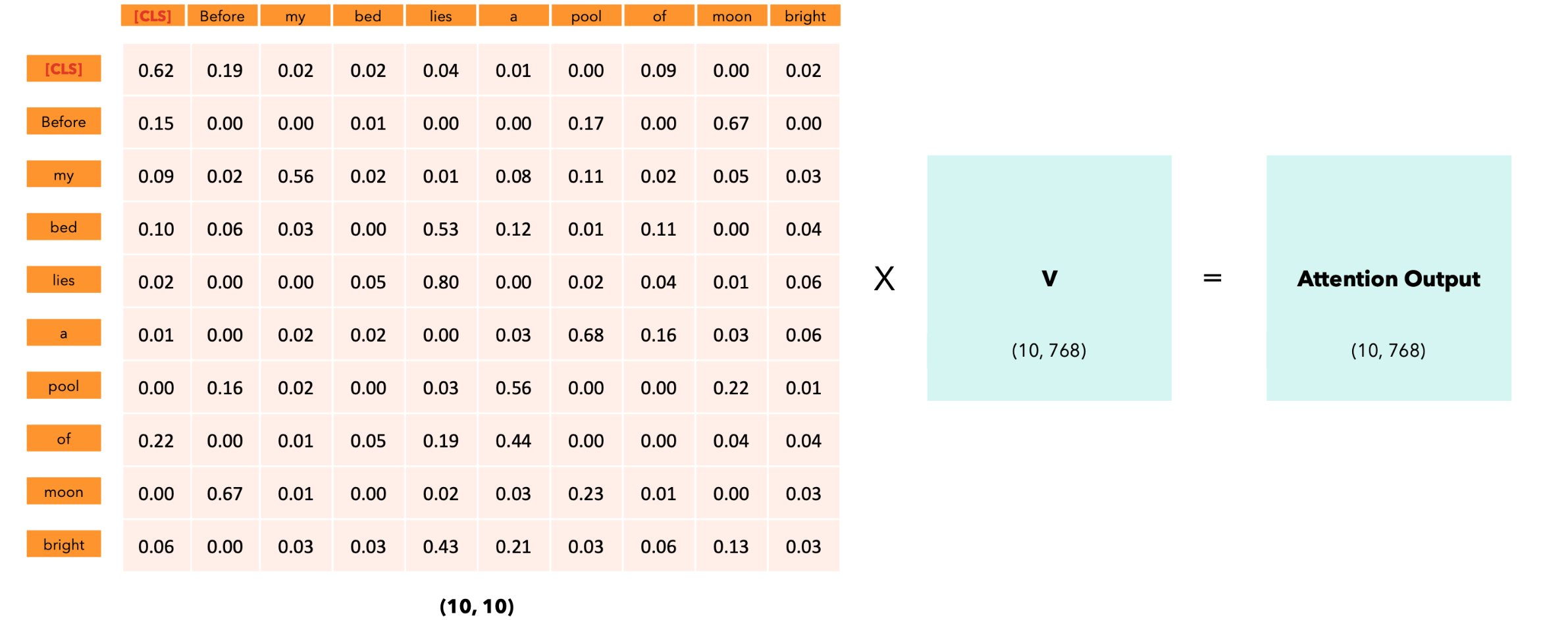
[CLS] token:输出序列。“注意力输出”矩阵的每一行代表输出序列的嵌入:它不仅捕获每个token的含义、位置,还捕获每个token与所有其他token的交互,但只捕获softmax分数不为零的交互。每个向量的512个维度仅取决于非零的注意力分数。
BERT微调
Task |
Description |
Computing graph |
|---|---|---|
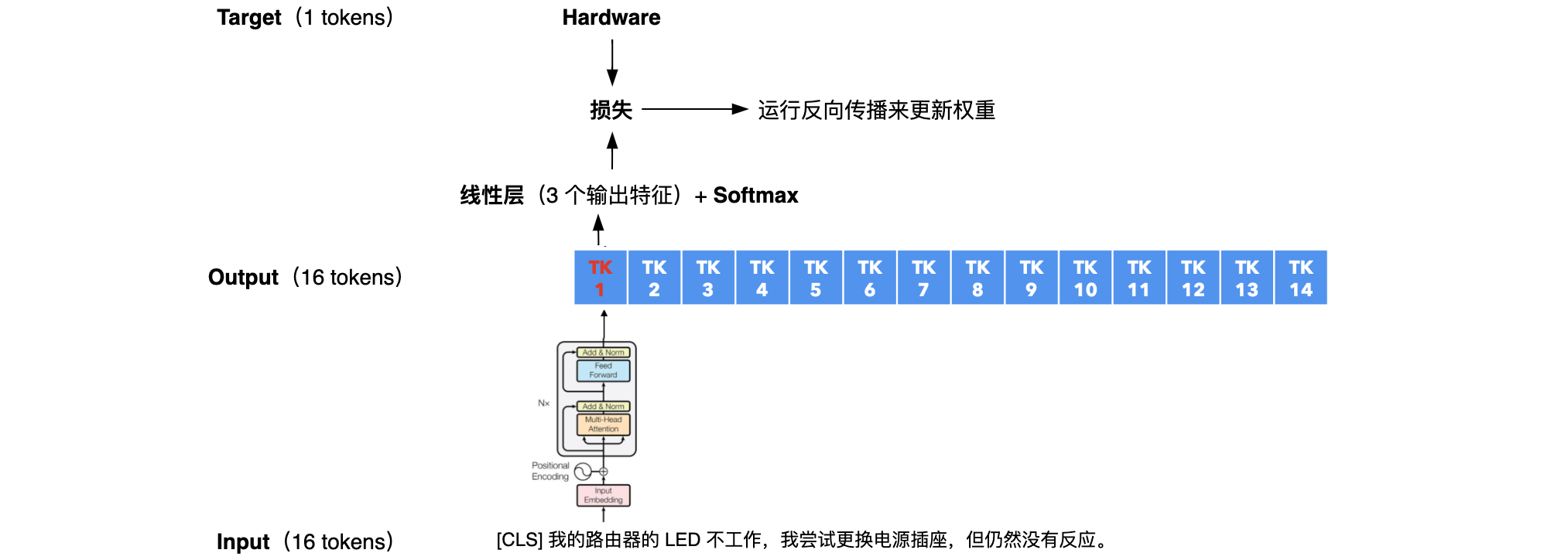
| 文本分类任务 | 文本分类是给一段文本分配标签的任务。 例如,假设我们正在运营一家互联网提供商,并收到客户的投诉。我们可能希望将来自用户的请求分类为硬件问题、软件问题或计费问题。 |
 |
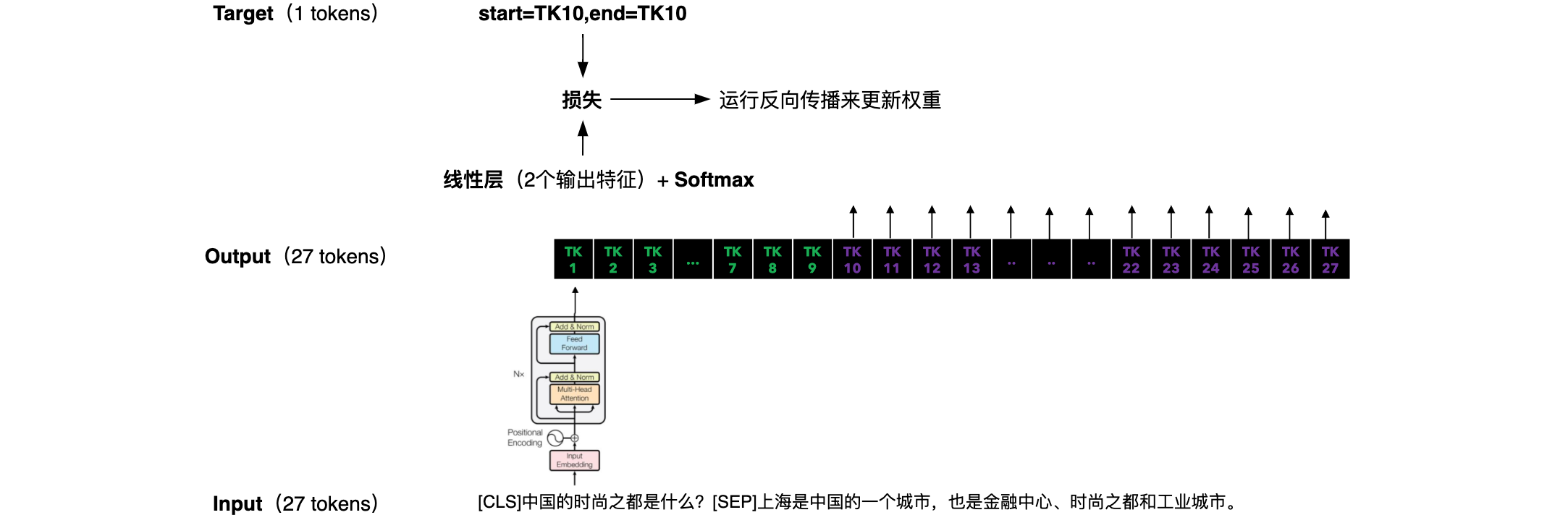
| 问答任务 | 问答是在给定上下文的情况下回答问题的任务。上下文:“上海是中国的一个城市,也是金融中心、时尚之都和工业城市。”问题:“中国的时尚之都是什么?”答案:“上海是中国的一个城市,也是金融中心、时尚之都和工业城市。” 问题: 1.我们需要找到一种方法让 BERT理解输入的哪一部分是上下文,哪一部分是问题。2.我们还需要找到一种方法让 BERT告诉我们在提供的上下文中答案从哪里开始,在哪里结束。 |
 |