Mistral / Mixtral:滑动窗口注意力 & 稀疏专家混合 & 滚动缓冲区
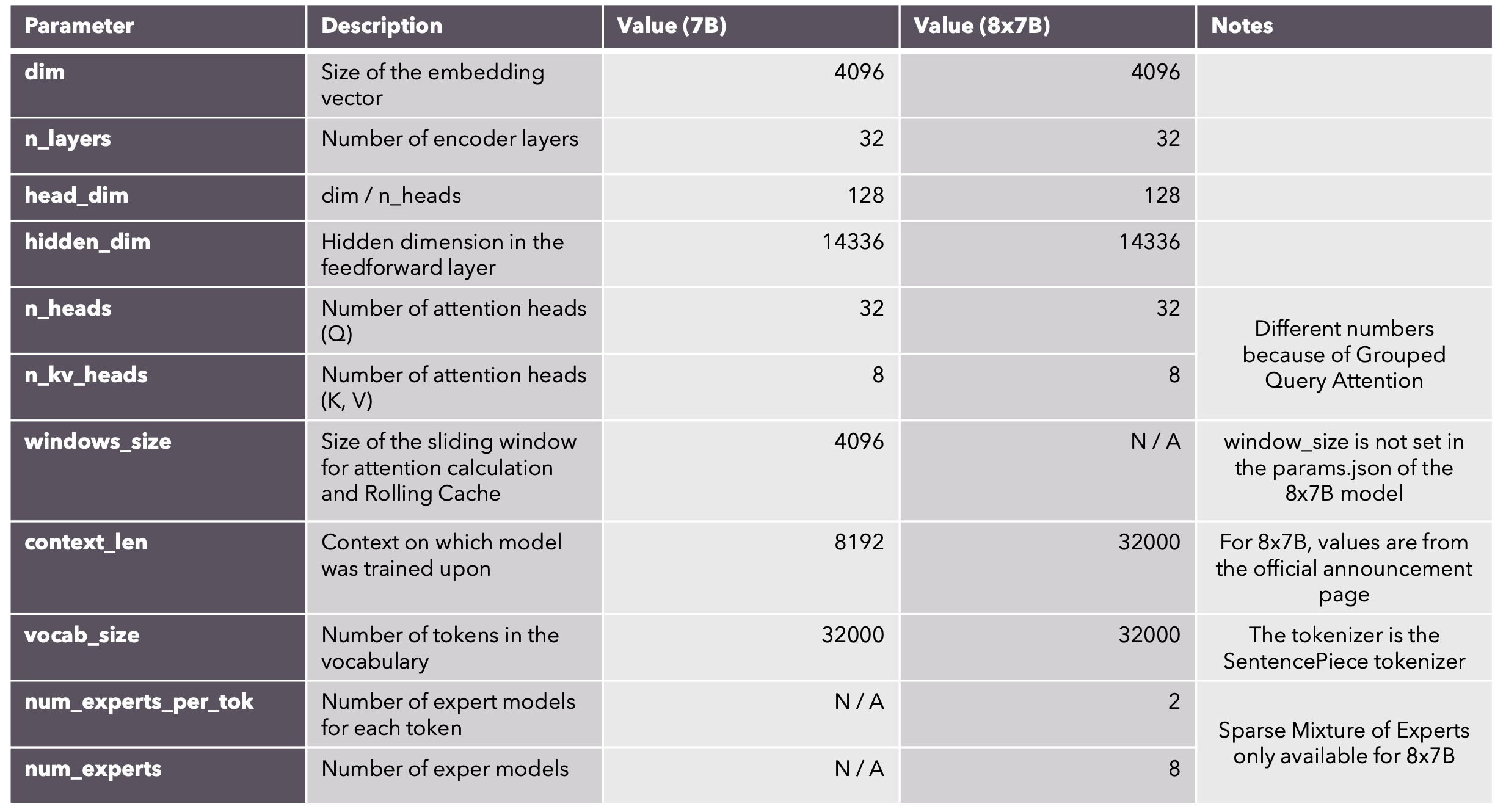
Mixtral是由Mistral AI公司开发的一种先进的大型语言模型。Mixtral采用混合专家(Mixture of Experts, MoE)架构,总参数量为46.7B,但每次推理只使用约12.9B参数,稀疏混合专家网络架构,每层包含8个专家(前馈神经网络块),对每个token,路由器选择2个专家处理,32K tokens的上下文窗口,支持英语、法语、意大利语、德语和西班牙语,在代码生成方面表现出色。在多项基准测试中表现优异,超越了许多更大规模的模型,推理速度快,效率高;在多数基准测试中优于Llama 2 70B和GPT-3.5,推理速度是Llama 2 70B的6倍。
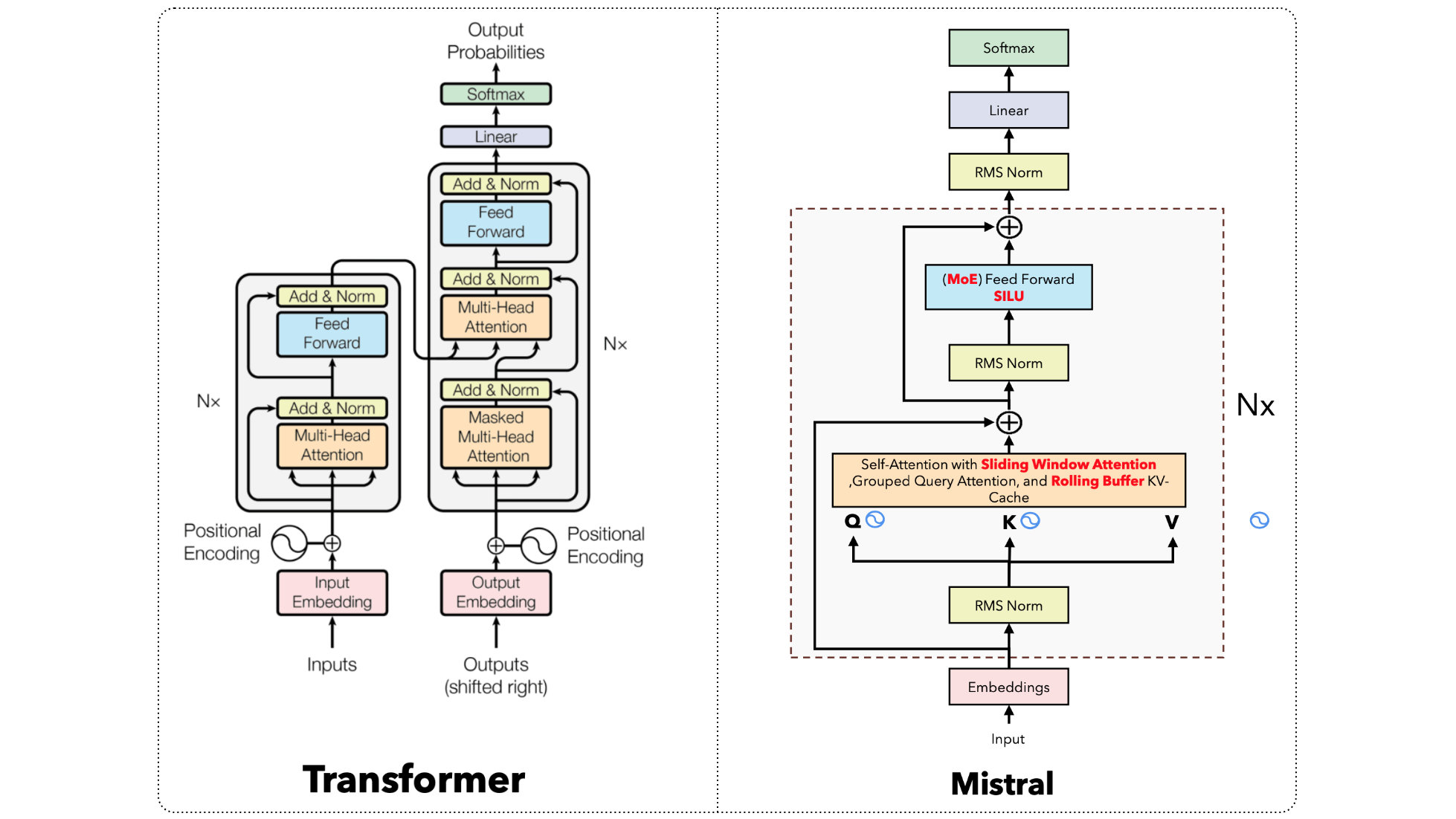
Transformer vs Mistral
滑动窗口注意力机制
自注意力机制允许模型将单词相互关联。假设我们有以下句子:“The cat is on a chair”。
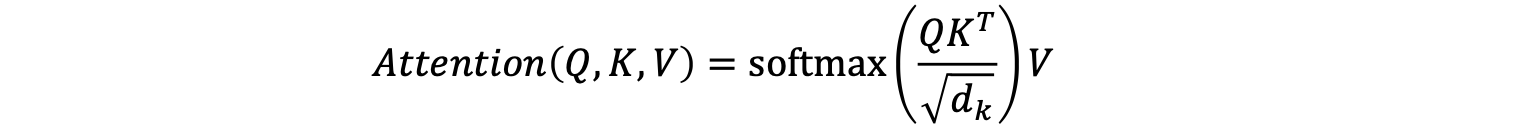
这里我展示了在应用softmax之前
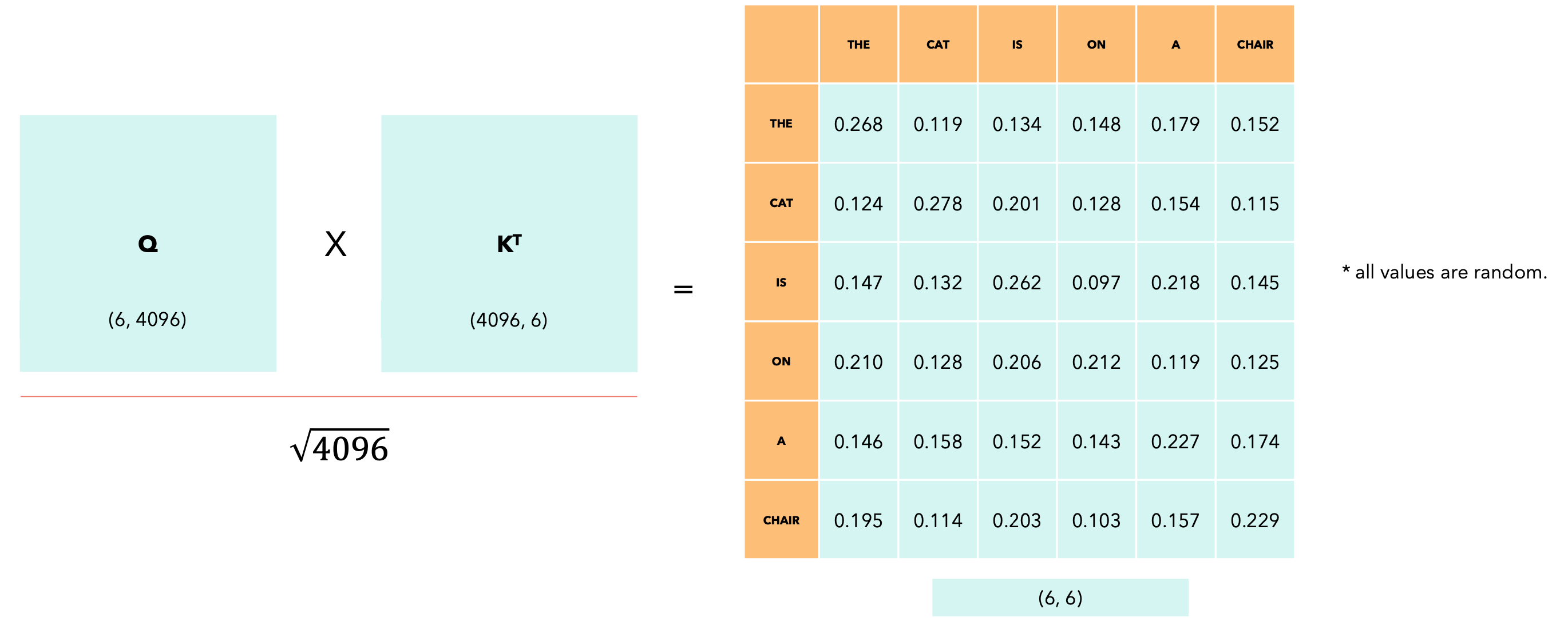
计算因果掩码后,我们应用softmax,行上的剩余值使得行总和为1。现在,让我们看一下滑动窗口注意力。
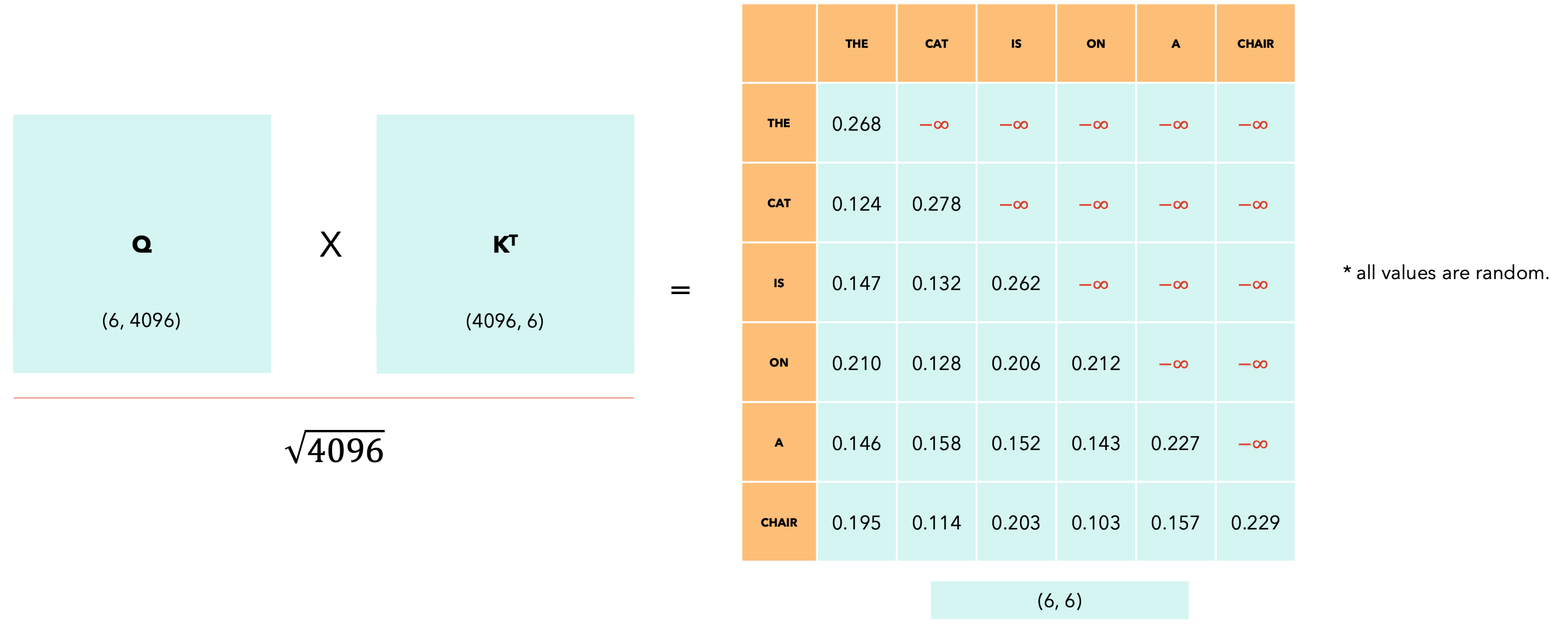
滑动窗口大小为3。
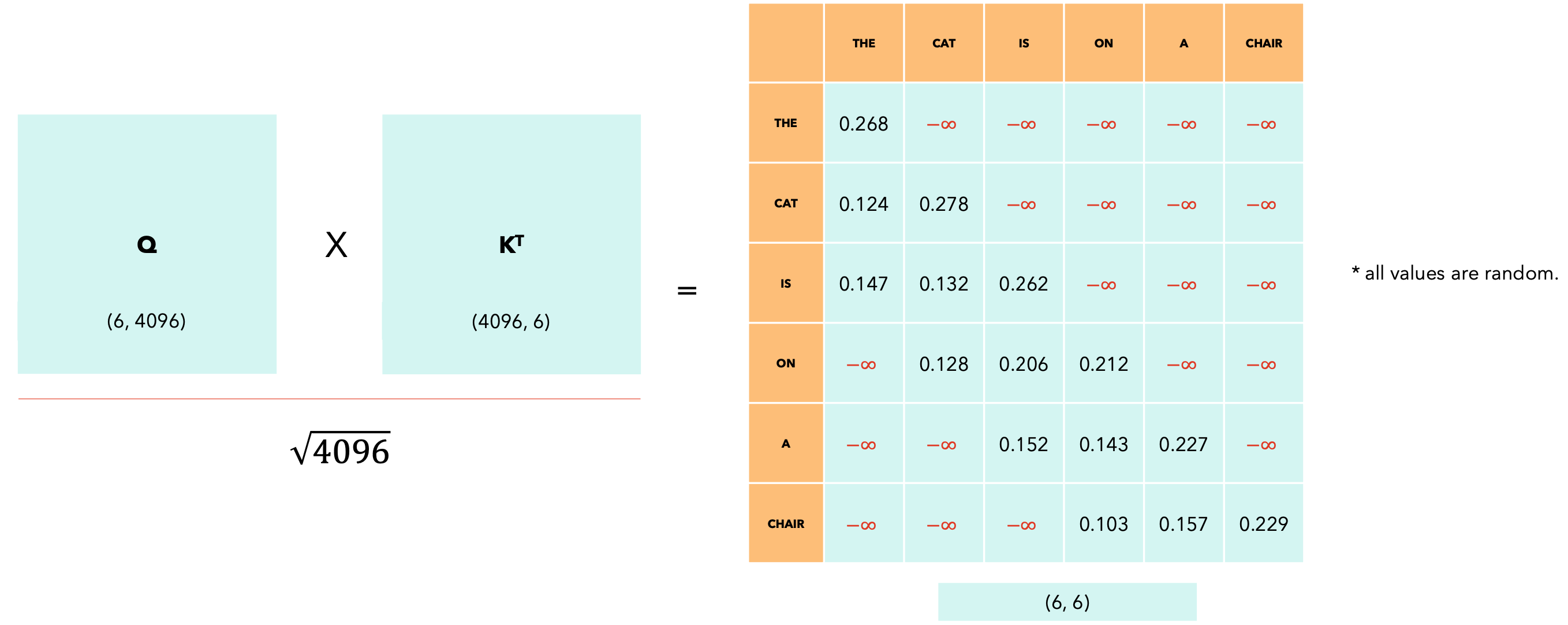
减少要执行的点积数量,从而降低训练和推理期间的性能。滑动窗口注意力可能会导致模型性能下降,因为无法捕获标记之间的某些“交互”。该模型主要关注局部上下文,这取决于窗口的大小,在大多数情况下已经足够了。滑动窗口注意力仍然可以允许一个token观察窗口外的token,使用类似于卷积神经网络中的接受场的推理。
信息流
应用softmax后,0,而行中的其他值则更改为总和为1。softmax的输出可以看作概率分布。
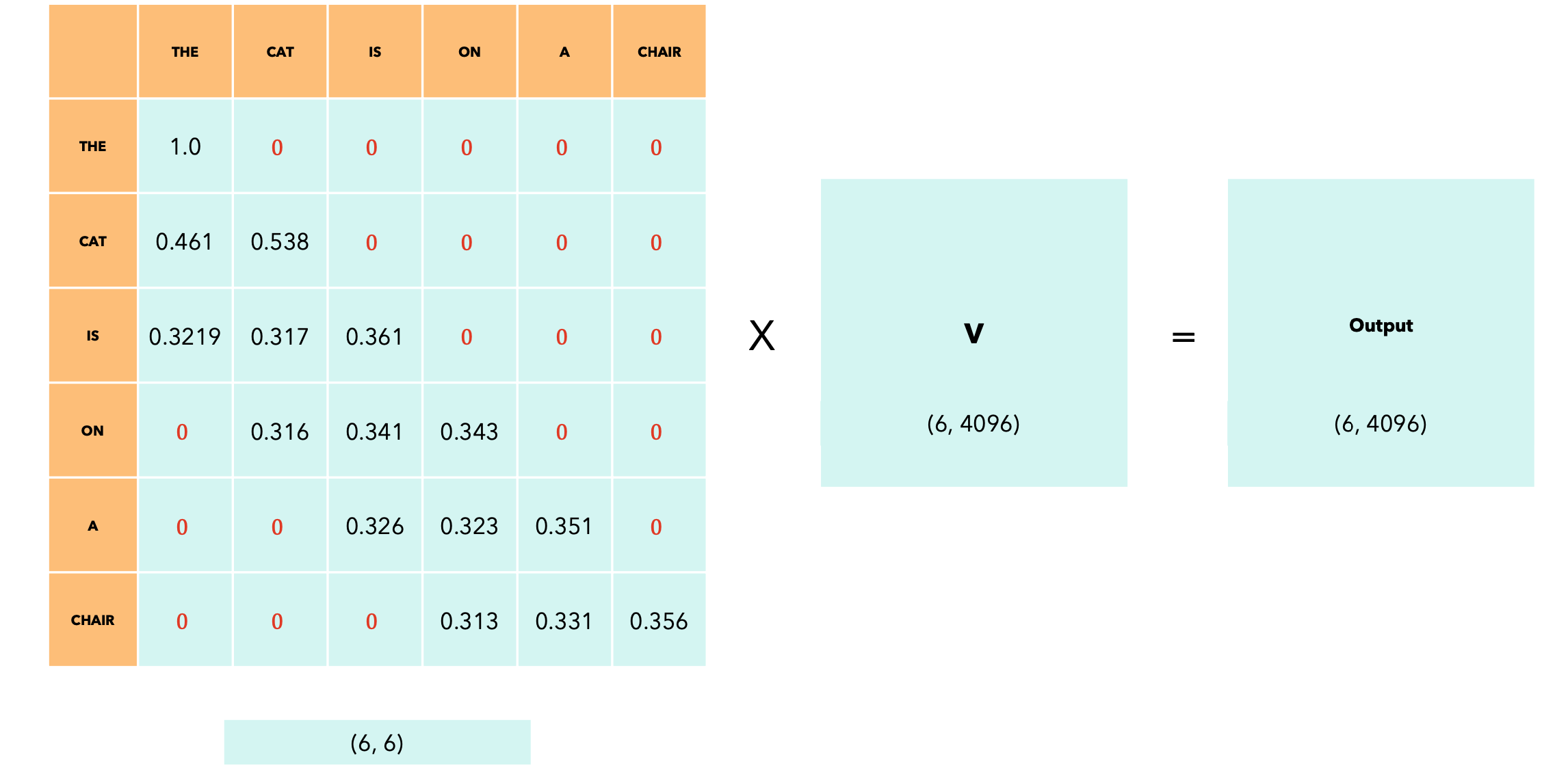
自注意力机制(Self-Attention)的输出是一个与输入序列形状相同的矩阵,但现在每个token都会根据所应用的掩码捕获有关其他token的信息。在我们的例子中,输出的最后一个token会捕获有关其自身和前两个token的信息。

当滑动窗口大小为token的信息。这意味着在
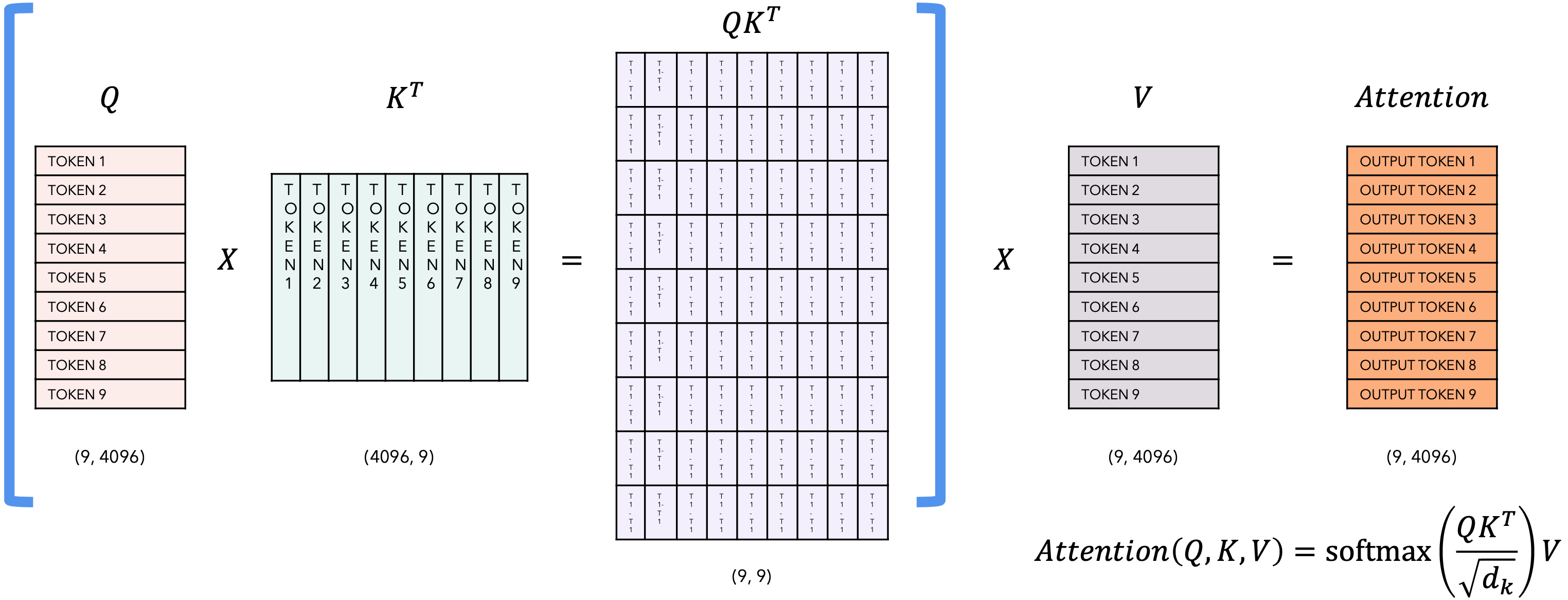
在推理的每一步,我们只对模型输出的最后一个token感兴趣,因为我们已经有了之前的token。但是,模型需要访问所有之前的token来决定输出哪个token,因为它们构成了它的上下文(或“提示”)。有没有办法让模型在推理过程中对已经见过的token进行更少的计算?有!解决方案是KV缓存!
下一个token预测任务中的自注意力机制
Inference |
Prediction task |
|---|---|
| T = 1 | 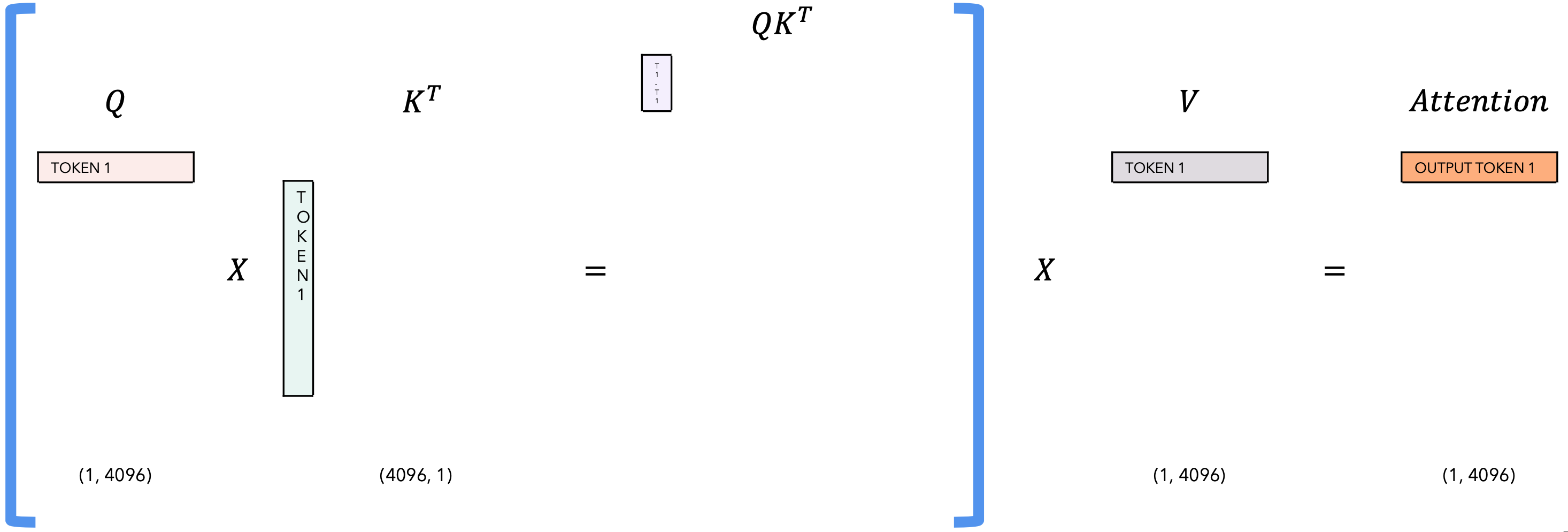 |
| T = 2 |  |
| T = 3 | |
| T = 4 | 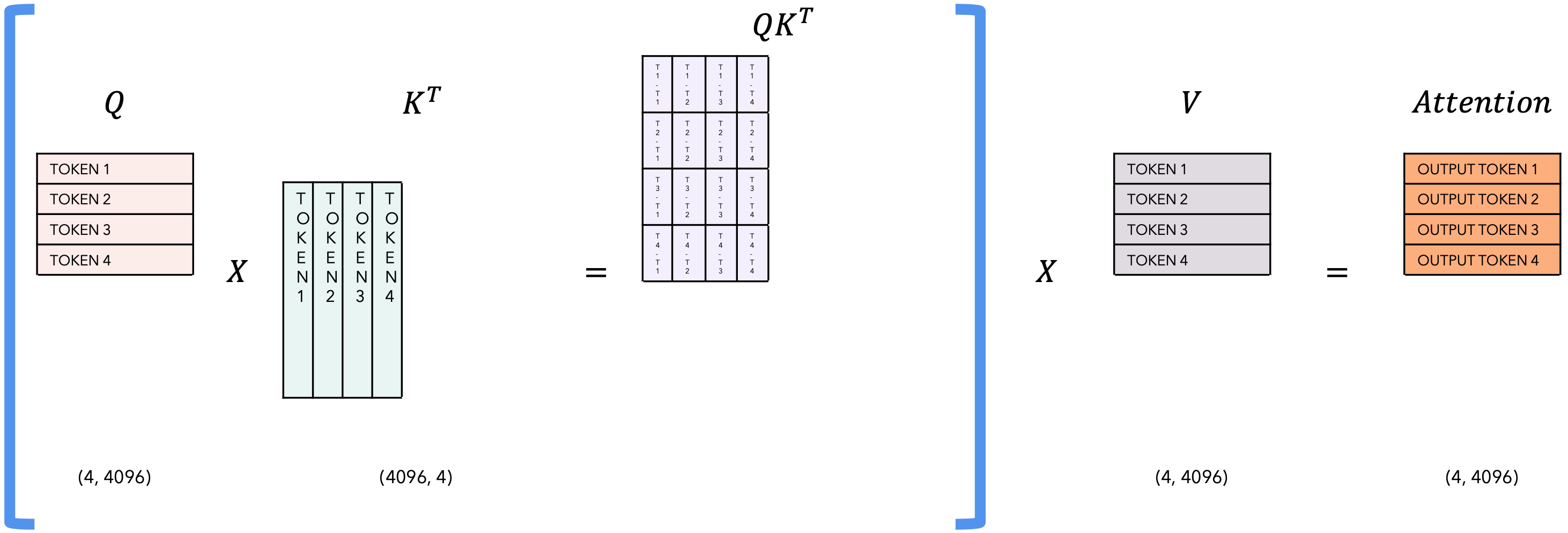 |
| T = 4 | 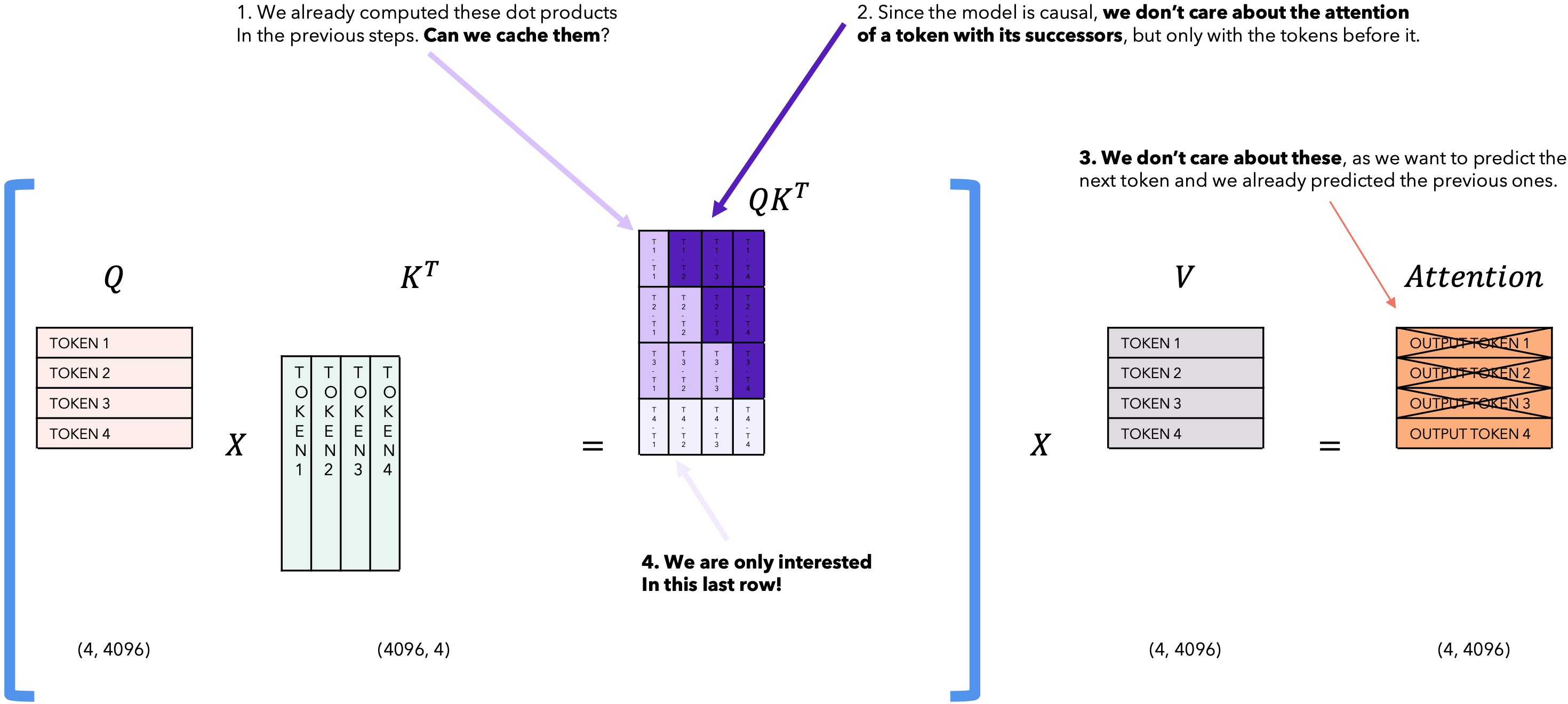 |
自注意力相关的KV-Cache
Inference |
task |
|---|---|
| T = 1 | 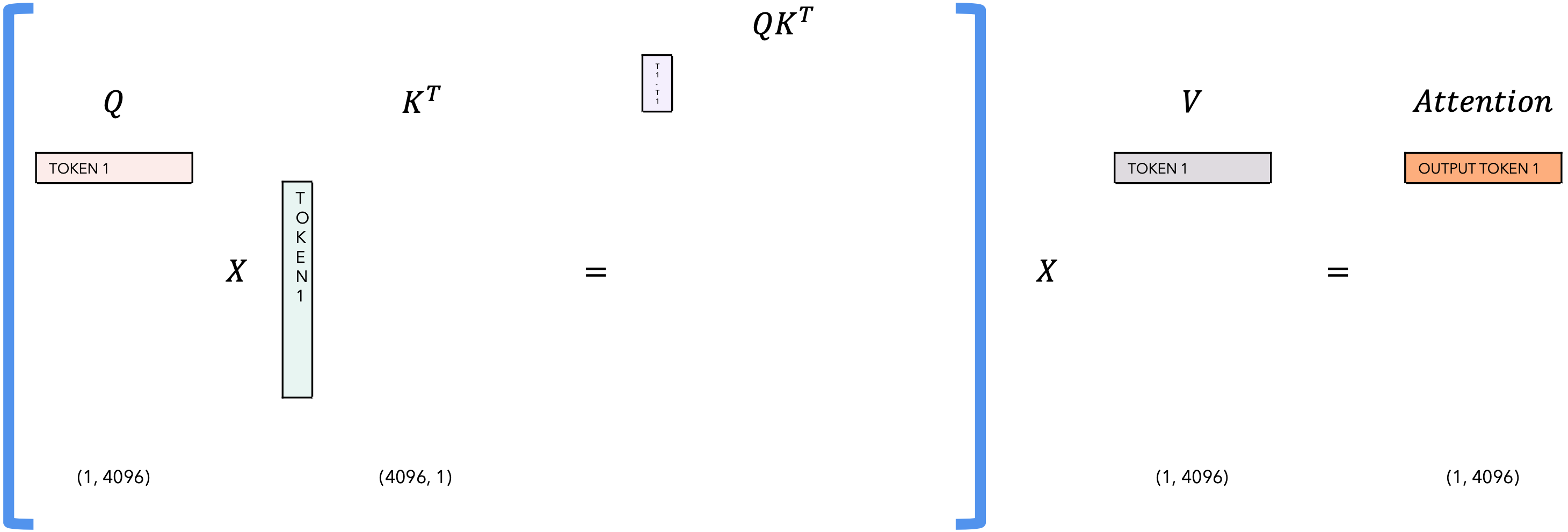 |
| T = 2 | 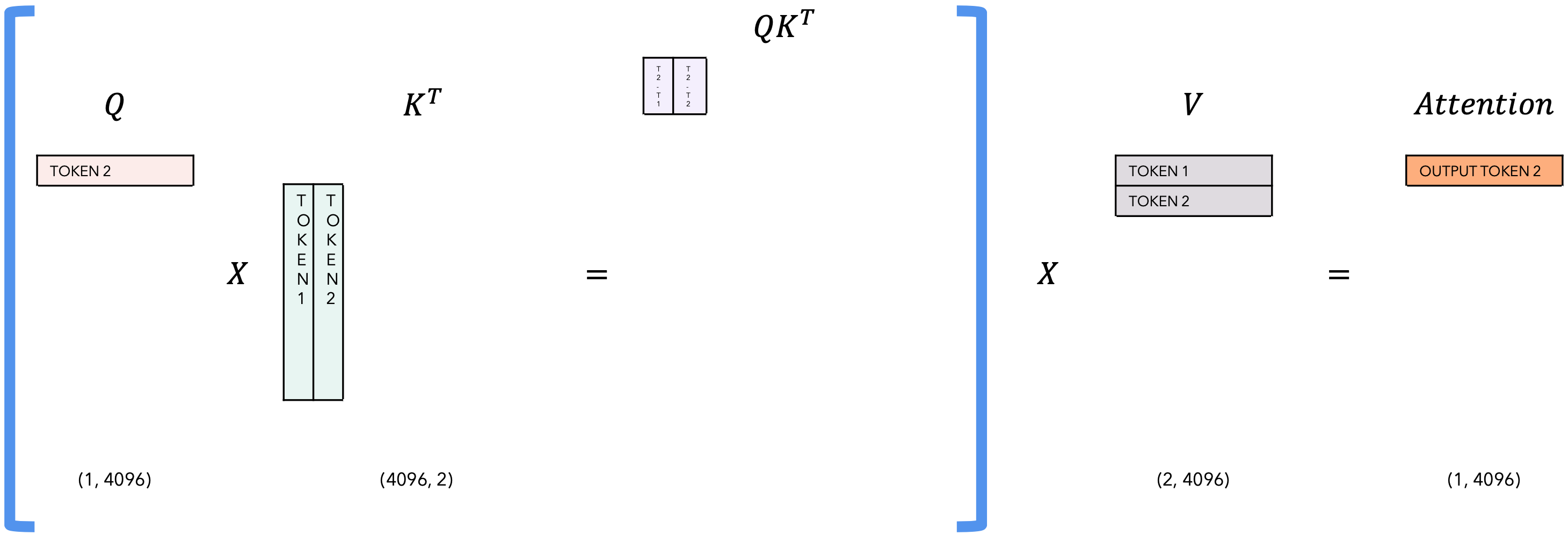 |
| T = 3 | 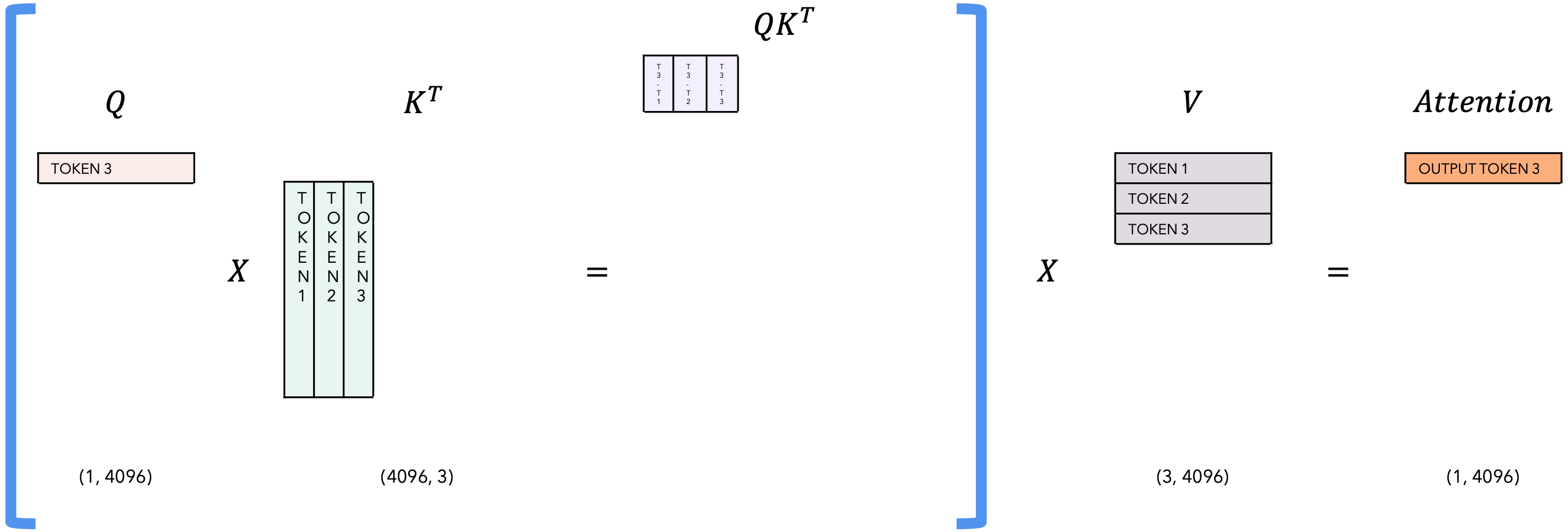 |
| T = 4 | 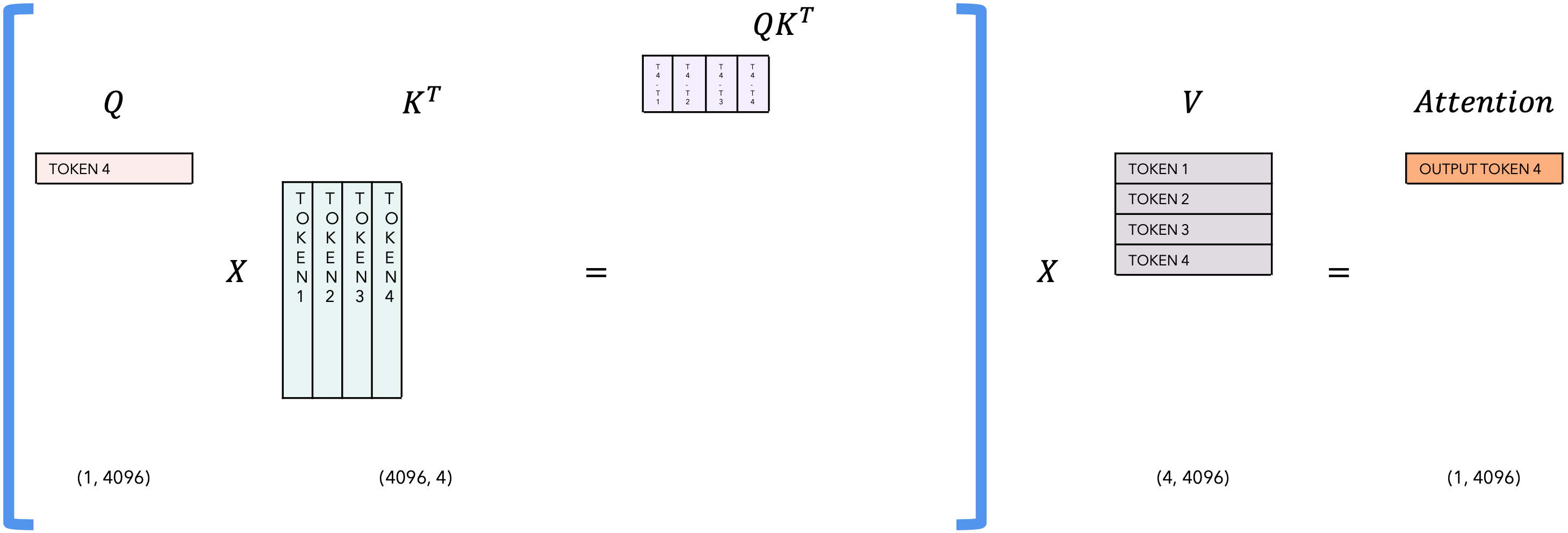 |
滚动缓冲区缓存
由于我们使用滑动窗口注意力(大小为W),我们不需要将所有先前的标记保留在KV-Cache中,但我们可以将其限制为最新的W个token。例如:我们的滑动窗口大小为4,我们只需要当前token与前4个token(包括自身)的点积。因为我们希望输出token仅依赖于前4个token。我们跟踪写入指针,在滚动缓冲区缓存中添加最后一个token的位置。让我们添加一个句子“The cat is on a chair”。首先我们添加一个新的token,并将指针向前移动我们来添加句子“The cat is on a chair”。我们想要“展开”缓存,因为我们想要计算传入token的注意力。这很容易!我们只需要使用写入指针来了解如何对项目进行排序:我们首先获取写入指针之后的所有项目,然后获取从第0个索引到写入指针位置的所有项目。
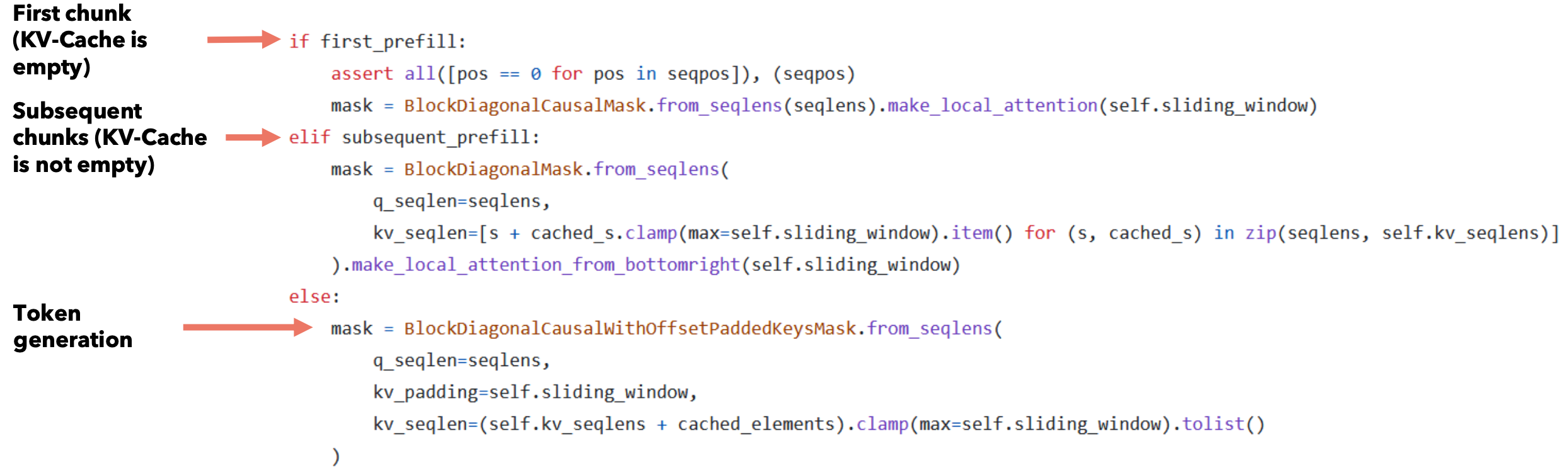
预填充和分块
使用语言模型生成文本时,我们使用提示词,然后使用前一个标记逐个生成token。处理KV-Cache时,我们首先需要将所有提示词的token添加到KV-Cache,以便我们可以利用它来生成下一个token。由于提示词是预先知道的(我们不需要生成它),我们可以使用提示词的token预填充KV-Cache。但如果提示词很大怎么办?我们可以一次添加一个token,但这可能很耗时,否则我们可以一次添加提示词的所有token,但在这种情况下,注意力矩阵(即token。提示词: “Can you tell me who is the richest man in history”。
在每一步中,我们使用KV-Cache的token + 当前块的token作为Key和Value来计算注意力,而仅使用传入块的token作为Query。在预填充的第一步中,KV-Cache最初是空的。计算完注意力后,我们将当前块的token添加到KV-Cache。这与token生成不同,在token生成中,我们首先将之前生成的token添加到KV-Cache,然后计算注意力。
你可能已经注意到,注意力掩码大于KV-Cache的大小。这是故意为之,否则新添加的token将不会与之前在缓存中的项计算点积。此机制仅在提示词的预填充期间使用。我们为什么要这样做?因为 KV-Cache的大小是固定的,但同时我们需要计算所有这些注意力。
只有在预填充期间,才会使用大于KV-Cache的注意力掩码来计算注意力。在第一个块和后续块的预填充期间,我们使用KV-Cache的大小和当前块中的token数量来生成注意力掩码。在预填充期间,注意力掩码是使用KV-Cache + 当前块中的token来计算的,因此注意力掩码可以大于KV-Cache(W)。在生成期间,我们首先将前一个token添加到KV-Cache,然后使用KV-Cache的内容生成注意力掩码。在生成期间,注意力掩码的大小是KV-Cache(W)的大小。
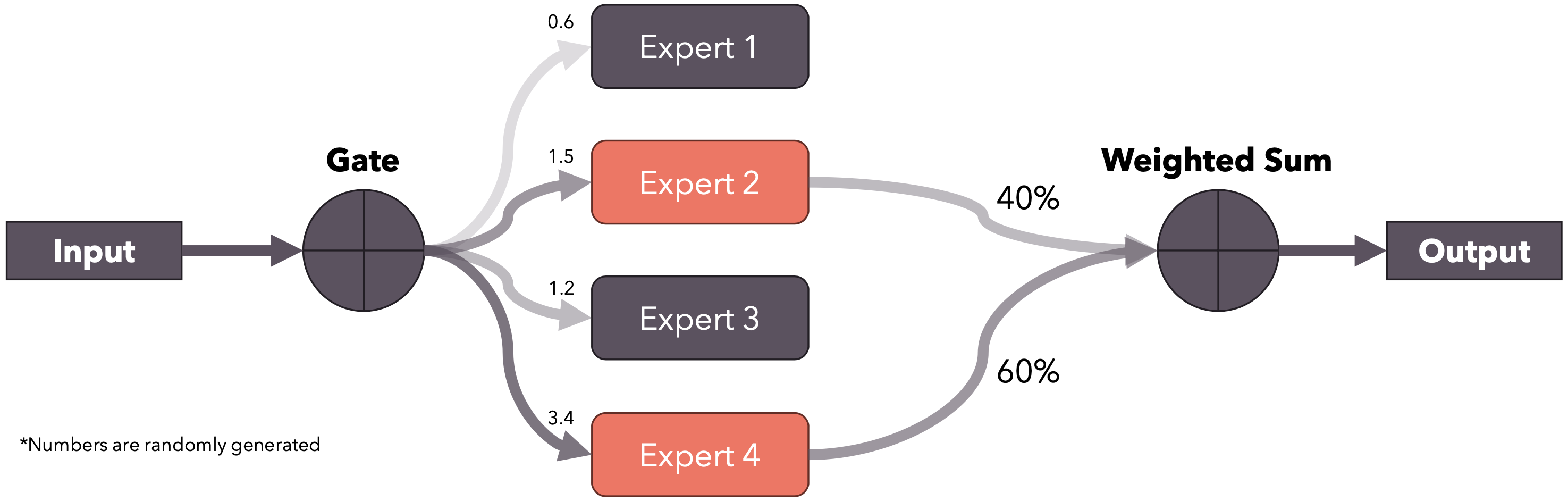
专家混合
专家混合是一种集成技术,其中我们有多个“专家”模型,每个模型都针对数据的一个子集进行训练,这样每个模型都专注于它自己的那一部分,然后将专家的输出组合起来(通常是加权和或平均)以产生一个单一的输出。在Mistral 8x7B的情况下,我们谈论的是稀疏混合专家(SMoE),因为每个token只使用8个专家中的2个。门控生成用于选择前k个专家的logit。然后前k个logit通过softmax运行来生成权重。
专家前馈层
对于Mistral 8x7B,专家是每个编码器层中的前馈层。每个编码器层由一个自注意力机制组成,后面跟着8个FFN专家的混合。门控函数为每个传入的token选择前2个专家。输出与加权和相结合。这里允许增加模型的参数,但不会影响计算时间,因为输入只会通过前2个专家,因此中间矩阵乘法只会在选定的专家上执行。
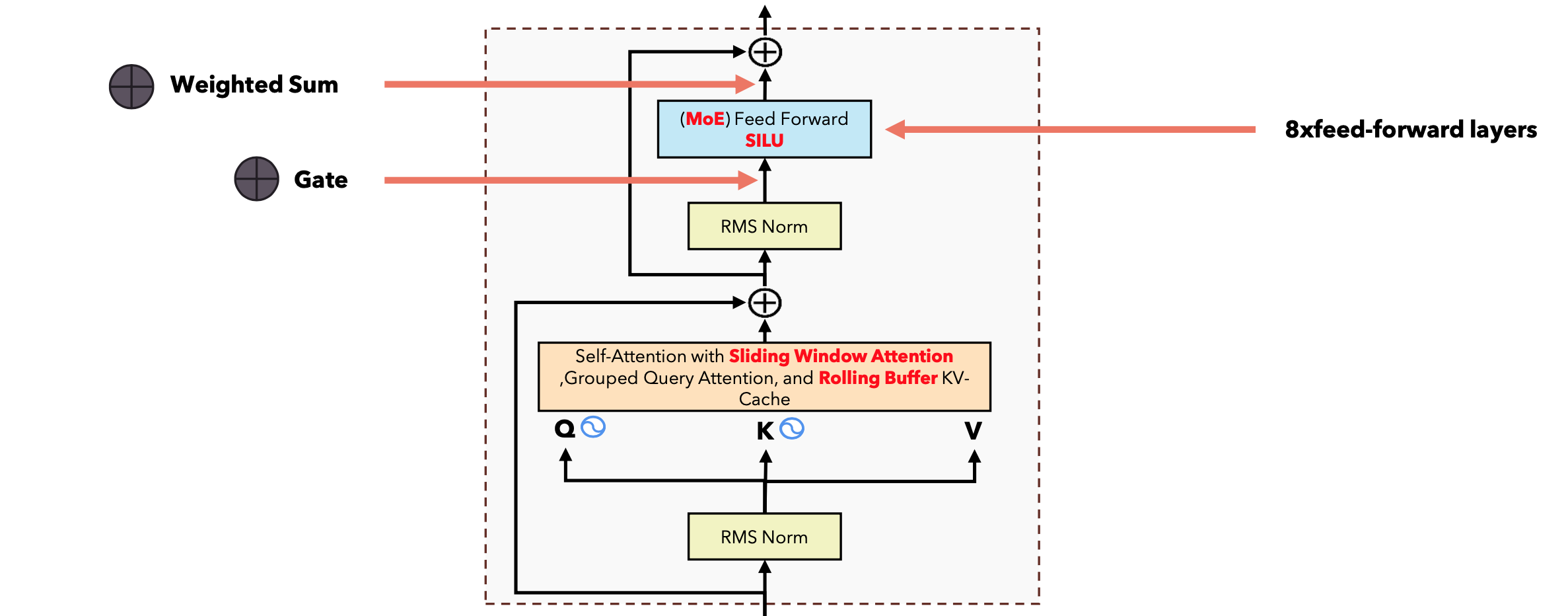
门控函数
门控函数只是一个线性层(in_features=4096,out_feature=8,bias=False),与模型的其余部分一起训练。对于每个token嵌入,它都会生成8个logit,控制要选择哪些专家。如果我们将softmax直接应用于门控函数的输出,这将导致所有专家的“概率分布”(权重总和为1)。但由于我们只使用其中的前k个,因此我们希望只对选定的专家进行“概率分布”。这也使得在不同数量的专家上训练的模型变得更容易,因为应用于输出的权重总和将始终为1,与门控函数选择的专家数量无关。
模型分片
当我们的模型太大而无法放入单个GPU中时,我们可以将模型划分为“层组”,并将每组层放在一个GPU中。当我们进行迭代推理时:每个GPU的输出都会作为下一个GPU的输入,依此类推……
这项技术被称为”模型分片“。对于Mistral来说,由于这里有32个编码器层,如果我们有4个GPU,那么我们可以在每个GPU中存储其中8个。

像这样的管道虽然运行良好,但效率不高,因为任何时候都只有一个GPU在工作。一种更好的方法(未在Mistral的开源版本中实现)尤其适用于训练,即同时处理多个批次,但在时间尺度上进行移动。这种方法称为管道并行。让我们看看它是如何工作的。
管道并行
想象一下,我们想要在单个批次上训练我们的分片模型:这将需要8个时间步来完成,并且在每个时间步,只有一个GPU在工作,而其他GPU处于空闲等待状态。
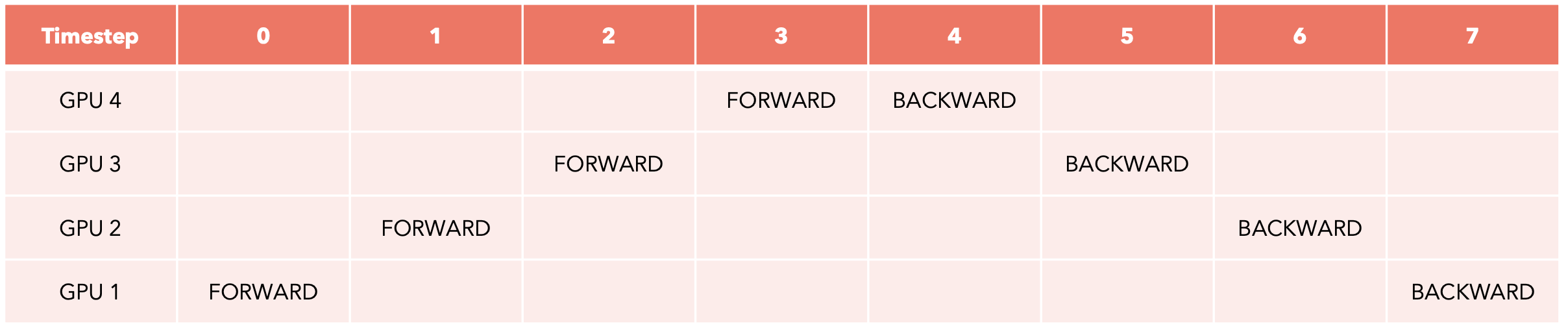
我们将批次划分为更小的微批次,并在时间线上移动每个微批次的前进和后退步骤。在这种情况下,每个时间步骤花费的时间更少,因为我们处理的是小的微批次。每个微批次的梯度都会累积(梯度累积),然后我们可以运行优化器来更新权重。

我们仍然有一些时间步长,其中并非所有GPU都在工作(称为“气泡”)。为了避免气泡,我们可以增加批次的大小。
多提示词优化推理
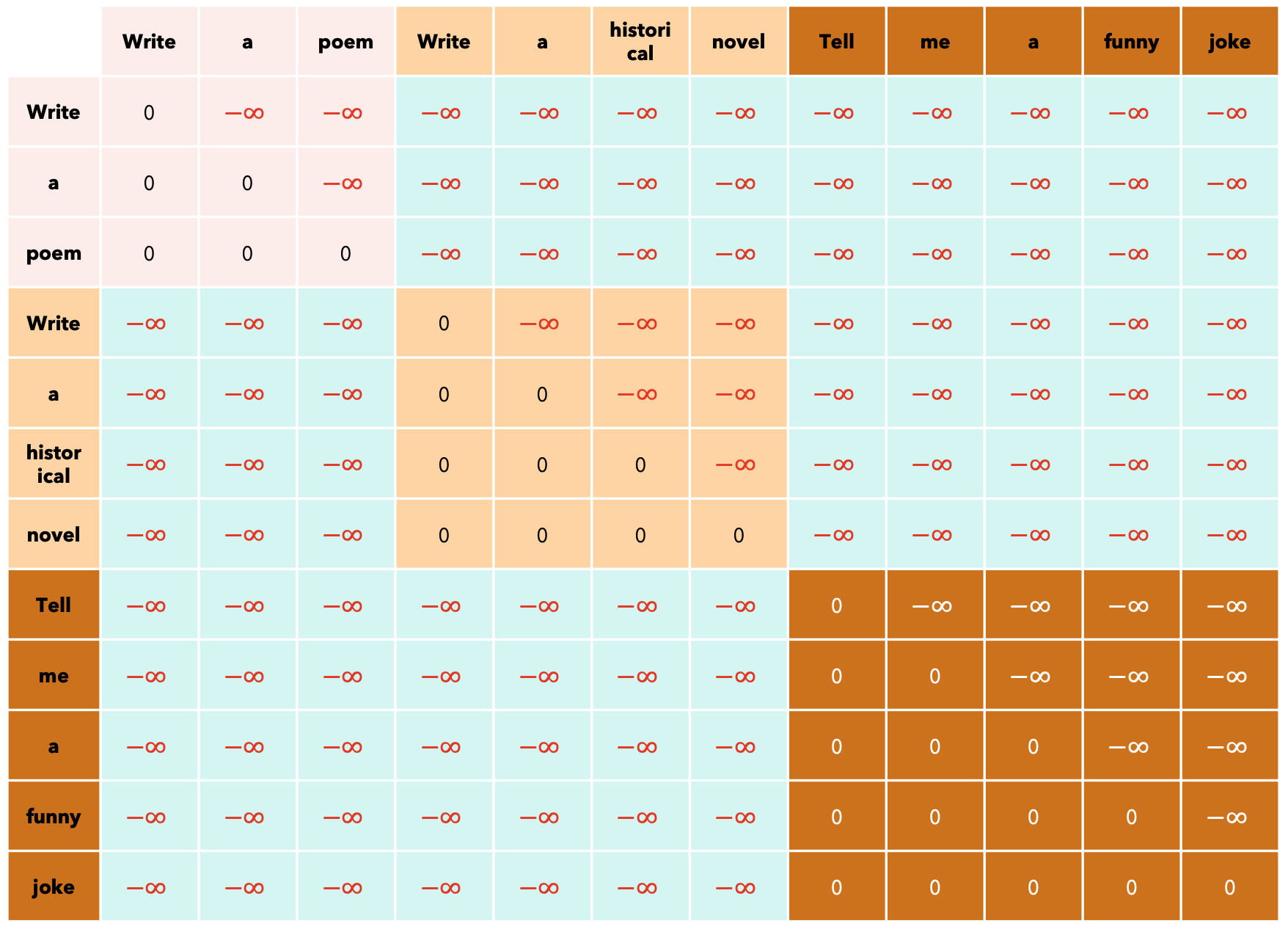
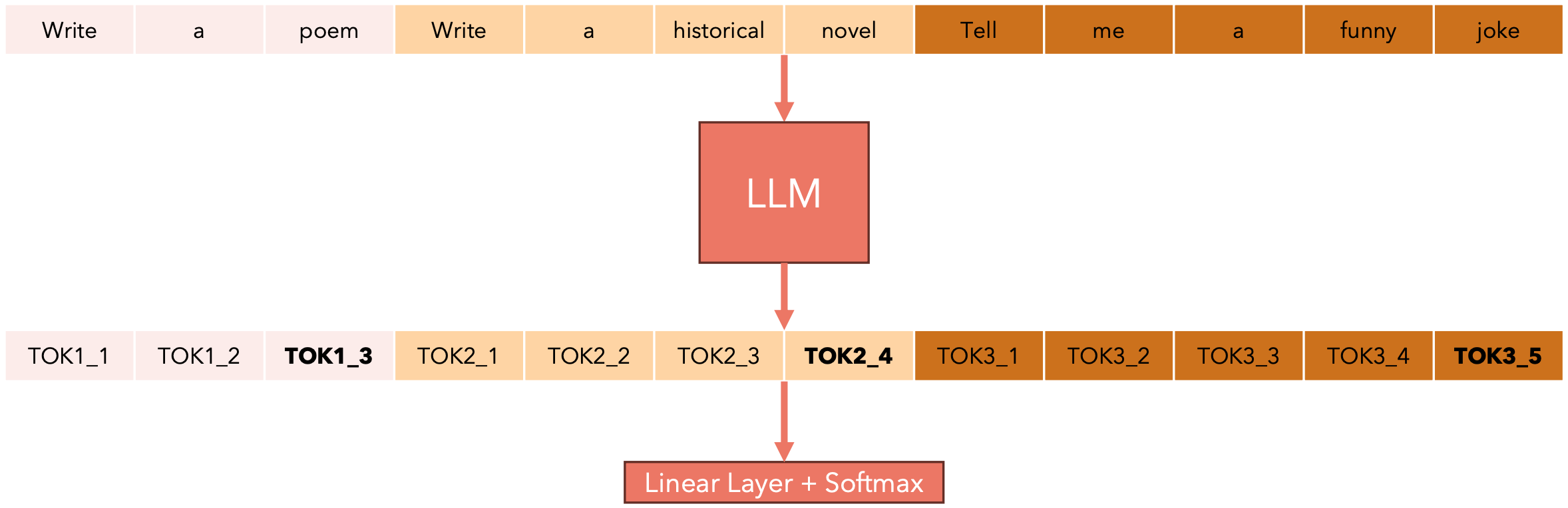
假设您正在经营一家提供LLM推理服务的AI公司:您有许多客户发送的提示词并希望在您的模型上运行推理。每个提示词的长度可能不同。为简单起见,假设每个单词都是一个token。请考虑以下提示词:
- 提示词一:
“Write a poem” (3 tokens)。 - 提示词二:
“Write a historical novel” (4 tokens)。 - 提示词三:
“Tell me a funny joke” (5 tokens)。
如果我们想充分利用我们的GPU,我们应该将所有提示词放在一个批次中,但由于它们的长度不同,我们必须用[PAD]token填充它们,并且当模型产生输出时,我们应该只查看对应于最后一个非填充token的输出,丢弃任何未来的token。

为了选择要生成的下一个token,我们将检查与最后一个非填充token相对应的嵌入,这些嵌入在上面的输出中突出显示。因为我们的模型是LLM,所以我们将使用因果掩码。此掩码适用于所有序列。我们不能对每个提示使用不同的掩码,因为所有提示的长度都相同,所以每个提示词的掩码必须是
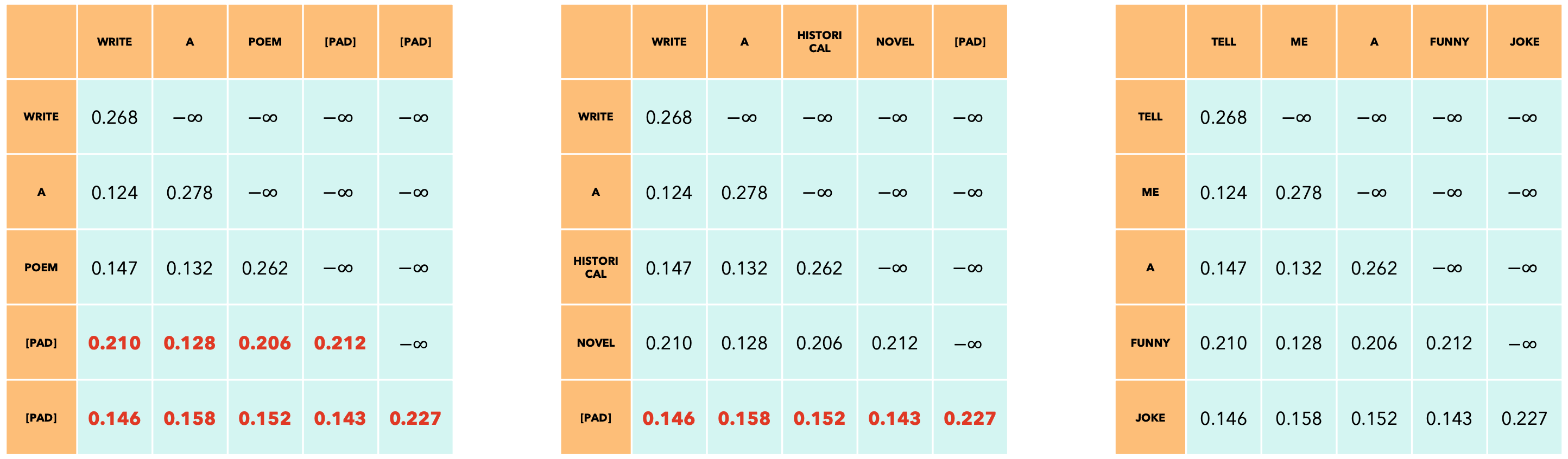
还有KV-Cache的问题:每个提示词可能具有不同的KV-Cache大小(想象一下一个提示词只有10个token,而另一个提示有500个token!)。解决方案是将所有提示词所有的token组合成一个序列,并在计算输出时跟踪每个提示词的长度。你可能会想:我们如何为这样的序列构建注意力掩码?我们可以使用xformers BlockDiagonalCausalMask!
如果我们使用滑动窗口注意力,掩码可能会有所不同。