直接偏好优化(DPO):Bradley-Terry模型 & 对数概率(深度学习)
直接偏好优化(Direct Preference Optimization,DPO)是一种用于微调大型语言模型(LLMs)以符合人类偏好的新方法。DPO旨在通过人类偏好数据来优化语言模型的输出,使其更符合人类期望,而无需使用强化学习或显式的奖励模型。DPO利用了奖励函数和最优策略之间的映射关系;它直接在策略(语言模型)上优化,而不是先学习奖励模型再优化策略;DPO将问题转化为一个简单的分类任务,在人类偏好数据上进行训练。
在实践中为单词序列分配概率,例如:“Shanghai is a city in”,如下图所示:
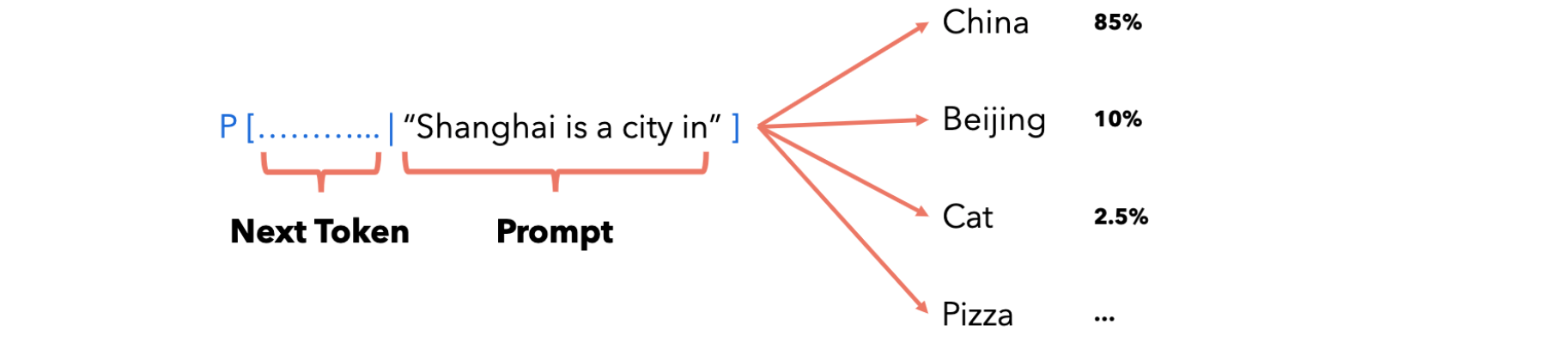
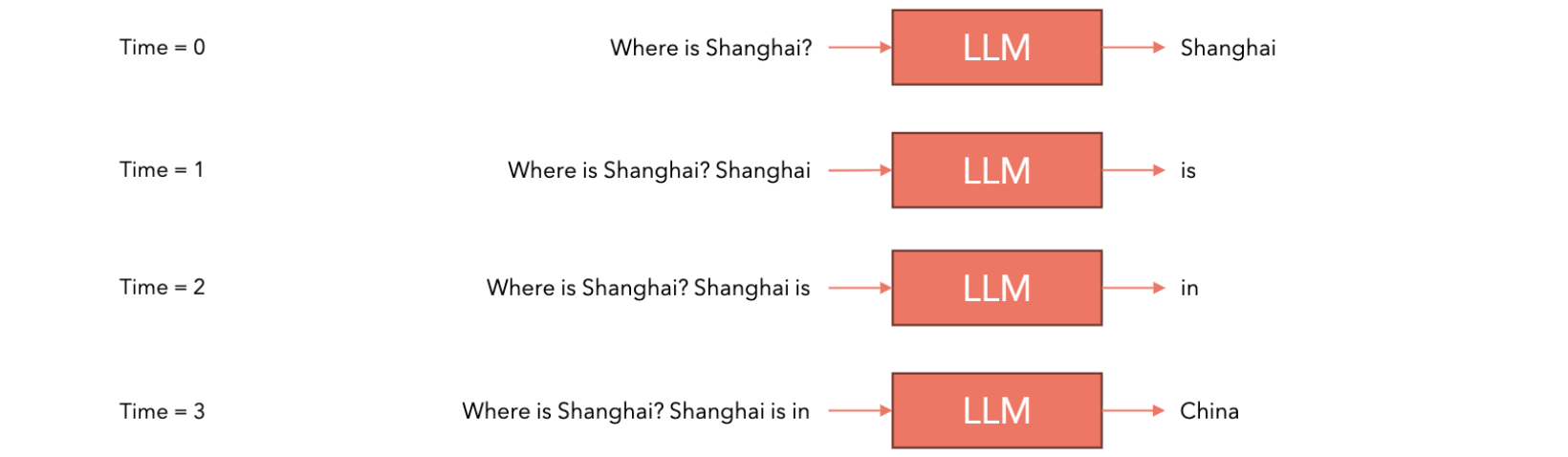
这里简化为:一个token是一个单词,在大多数语言模型中实际上并不是这样的,但用于解释它很有帮助。给定特定提示的情况下,下一个token是china、Beijing、Cat、Pizza的概率是85%、10%、2.5%、...,语言模型给了我们这些概率。我们如何使用语言模型来生成文本呢?首先我们会给出一个提示,如:“Where is Shanghai?”,我们把它提交给语言模型,语言模型会给出下一个单词或token的概率列表,假设我们选择概率分数最高的token,假设它是“Shanghai”,然后我们将其(token)放回到提示中:“Where is Shanghai? Shanghai”,再次交给语言模型,然后语言模型再次给出一个单词或token的概率列表,我们选择相关性最重要的一个。然后将其放回到提示后边,然后再次提交给语言模型等,直到完成了句子标记的结尾。这种情况下,这是一个特殊的token。
AI对齐
预训练模型不会教授语言模型:回复时要有礼貌、不使用任何攻击性语言、不使用任何种族主义式的表达等。因为语言模型只会根据其拥有的数据去执行,如果你提供了互联网上的数据,实际上语言模型会表现得非常糟糕。所以我们需要将语言模型与期望的动作保持一致。不希望语言模型使用任何攻击性的语言。这也是AI对齐的目标。
强化学习
强化学习(Reinforcement Learning, RL)是机器学习的一个重要分支,主要关注如何让智能体(agent)在与环境的交互中学习最优策略。智能体通过试错的方式,在环境中采取行动,获得奖励或惩罚,从而学习如何最大化长期累积奖励。举个简单的例子:
example_1 |
example_2 |
|---|---|
Agent:猫 |
Agent:语言模型 |
状态:猫在网格中的位置(x,y) |
状态:提示(输入的tokens) |
行为:在每个位置,猫可以移动到4个方向连接的单元格之一,如果移动无效,则单元格将不会移动并保持在同一位置。每次猫移动时,都会产生新的状态和奖励。 |
行为:哪个token被选为下一个 token |
| 奖励模式: 1.移至另一个空单元格将导致奖励 0。2.移向扫帚将导致奖励 -1。3.移向浴缸将导致奖励 -10,猫会晕倒(剧集结束)。猫会再次重生在初始位置。4.移向肉将导致奖励 +100 |
奖励模式:语言模型应该因产生“好的反应”而获得奖励,而不应该因产生“坏的反应”而获得任何奖励。 |
| 策略:策略规定代理如何在其所处的状态下选择要执行的操作: |
策略:对于语言模型来说,策略就是语言模型本身!因为它根据代理的当前状态模拟动作空间的概率: |
 |
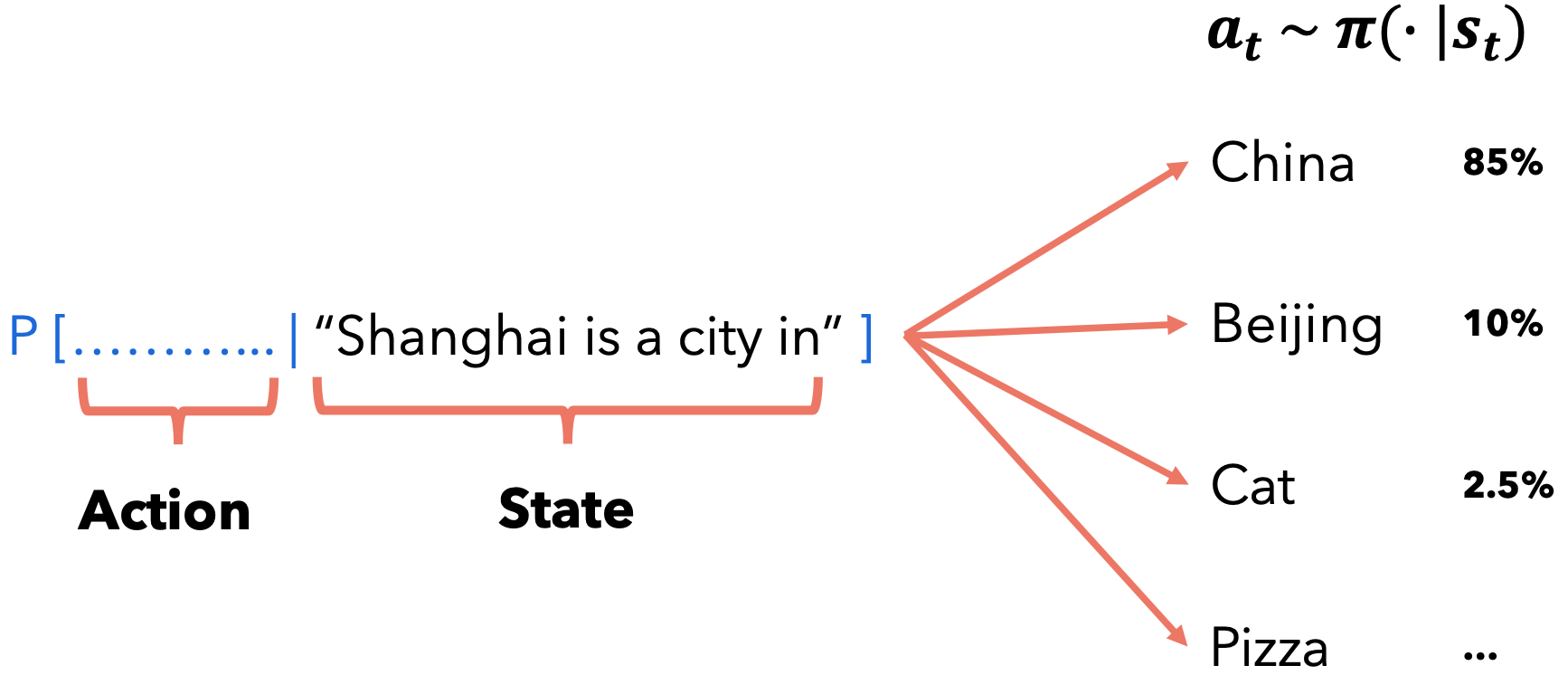 |
RL中的目标是选择一种策略,当代理按照该策略采取行动时,该策略可以最大化预期回报。
Bradley-Terry模型
为语言模型创建奖励模型并不容易,因为这需要我们创建一个提示和响应的数据集,并为每个答案分配一个普遍接受的“奖励”。想象一下,如果我们可以创建一个查询和答案的数据集,然后让人们选择他们喜欢的那个。这会容易得多!使用这样的数据集,我们可以训练一个模型来为给定的答案分配分数。让我们看看它是如何做到的。现在我们有了偏好数据集,我们需要找到一种方法将偏好转换为分数(奖励)。一种方法是使用Bradley-Terry模型对我们的偏好进行建模。
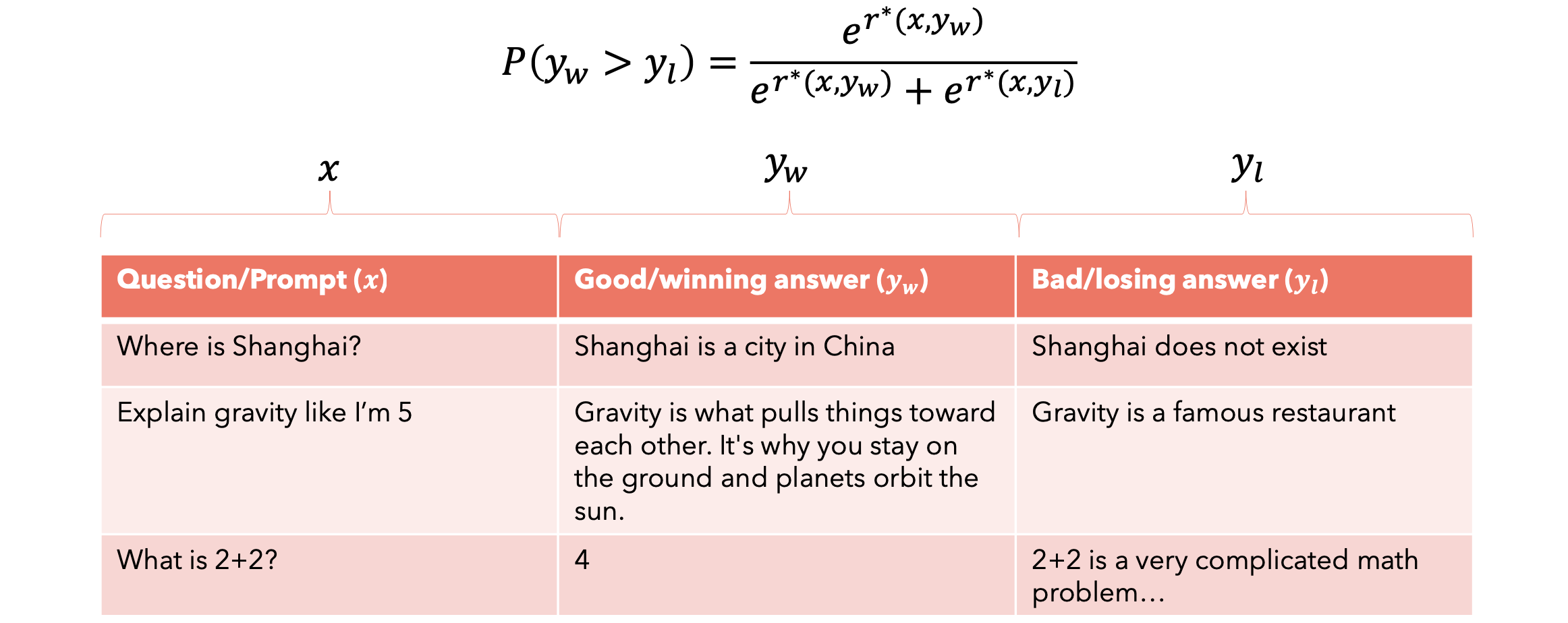
当然,我们希望最大化偏好模型正确排序我们答案的概率。一种方法是最大似然估计。使用MLE,我们可以估计奖励模型
推导奖励模型的损失函数
我们来推导一下奖励模型的损失函数,就是DPO论文中的公式。
我们的目标是将Bradley-Terry模型的表达式转换为sigmoid。

这给出了我们通常所熟知的奖励模型表达式。减号是因为我们想要最小化损失。
RLHF目标函数
我们的目标是解决以下约束优化问题:我们希望找到一种策略,使用该策略时获得的奖励最大化,同时我们希望该策略与原始未优化策略的表现不会有太大差异。添加此约束是为了避免所谓的“reward hacking”:语言模型(策略)可能只是选择获得高奖励的token序列,但可能完全是胡言乱语。人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)的目标函数是一个关键组成部分,用于指导模型的优化过程。
优化问题
最大化一个函数的意思是找到一个或多个变量的所有值,使得该函数取得最大值。这同样适用于最小值问题。例如,如果我们有一个非常简单的函数,如下所示:
简单的抛物线问题是一个无约束优化问题。在RLHF的情况下,我们有一个约束优化问题,这意味着我们希望最大化奖励,但同时我们希望KL散度很小。
为什么不直接在这个目标函数上运行梯度下降?结果是不能!因为变量𝑦是使用各种策略(贪婪、波束搜索、top-k等)从语言模型本身采样的。这个采样过程是不可微的。这就是我们被迫使用PPO等RL算法的原因。
最优策略
约束优化问题的解如下。它是DPO论文中的公式(4)。
其中
因此,如果可以访问最佳策略,我们可以使用它来获得奖励函数。如果我们将奖励函数的表达式代入Bradley-Terry模型的表达式中会怎么样?
要学习最大化选择Bradley-Terry模型,我们只需要最大化上面的表达式或最小化下面的负表达式:
因此,我们不是优化奖励函数,而是优化最优策略(该策略取决于上面公式中的最优奖励函数)。
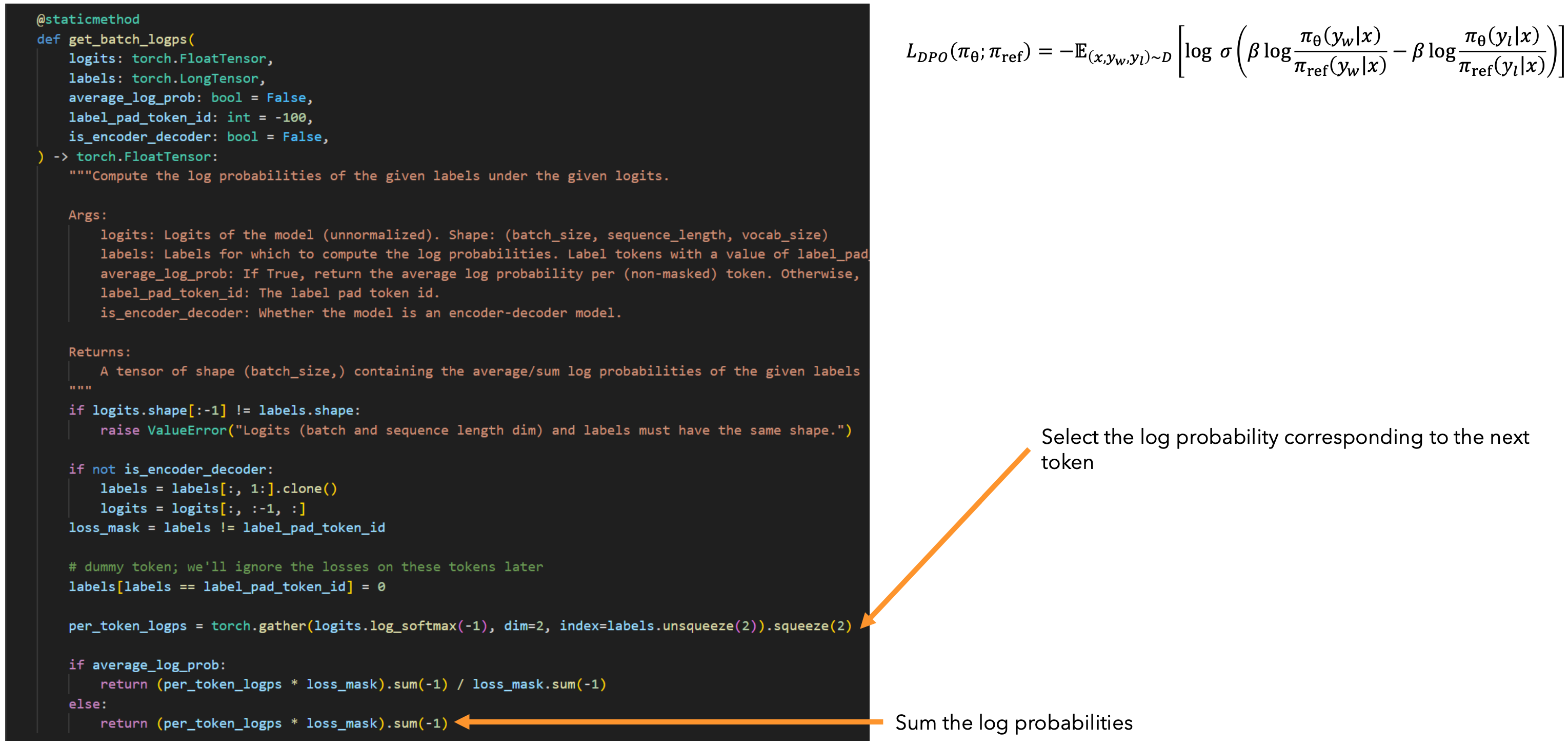
对数概率
为了评估损失,我们需要计算表达式中的对数概率。我们如何计算对数概率?
例如,
1 | dpo_trainer = DPOTrainer( |
每个隐藏状态编码器仅包含有关先前token的信息,因为我们在自注意力期间应用了因果掩码,将线性投影应用于所有隐藏状态,为所有位置生成logits。接下来使用token对应的对数概率。
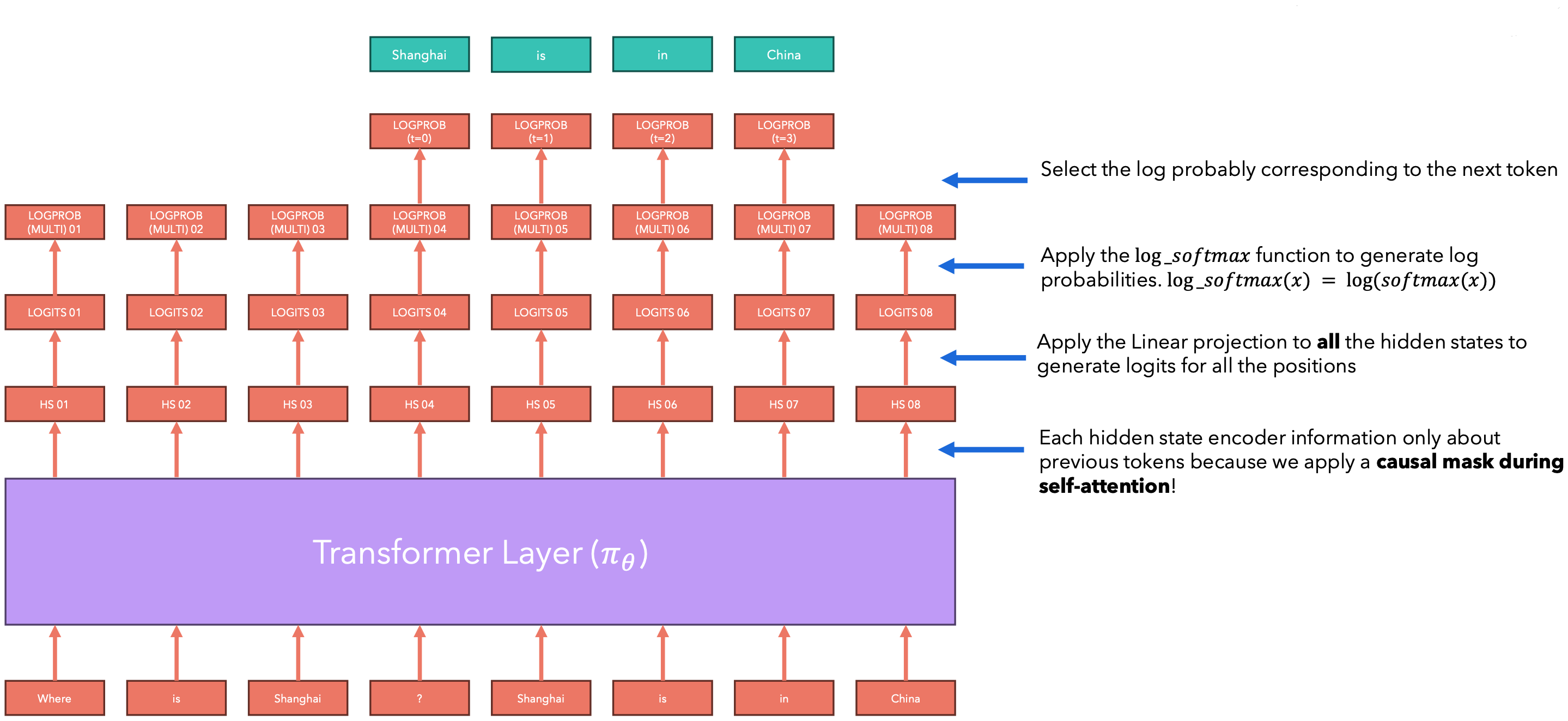
对数概率计算实现: