多层感知器(MLP) vs 科尔莫戈罗夫-阿诺德网络(KAN)(机器学习)
多层感知器(MLP)
多层感知器(MLP)是如何工作的?多层感知器(MLP)是由多个神经元层组成的神经网路,每个神经元层以前馈方式组织,这意味着一层的输出作为下一层的输入,通常在每一层,我们会放置一些非线性激活函数,例如RelU,在这种情况下,会形成一个非常简单的网络,如下图所示:
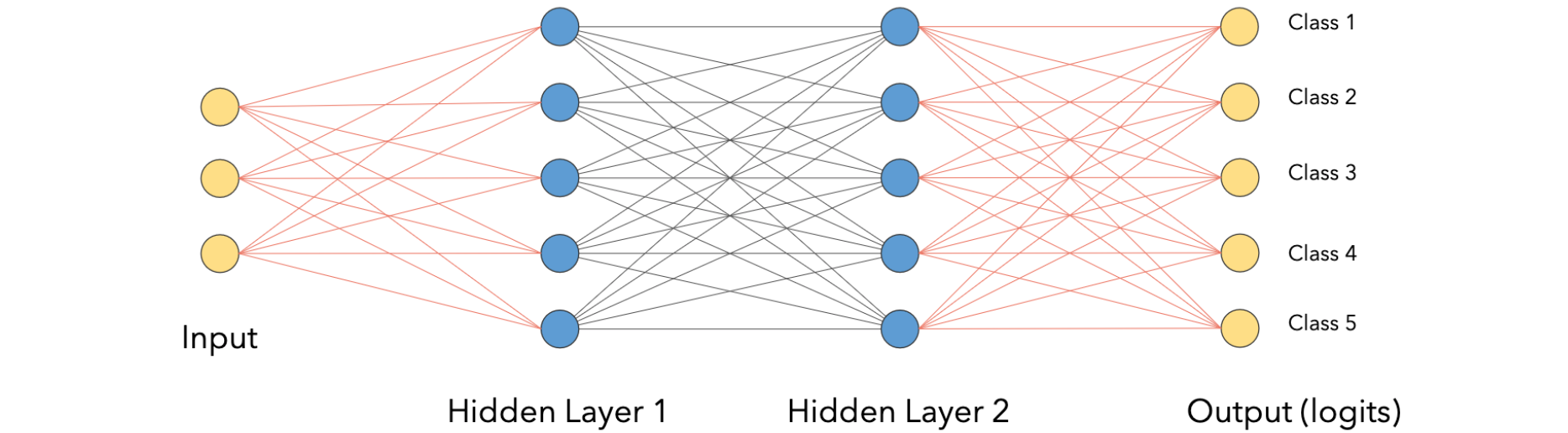
上图中有包含三个特征的输入向量,接下来有5个神经元组成的第一层,5个输出特征的网络,这里的网络采用5个特征作为输入,并产生5个输出特征,它们具有相同的结构,通常我们将激活函数放在各层中。让我们看看它在pytorch中是如何工作的:

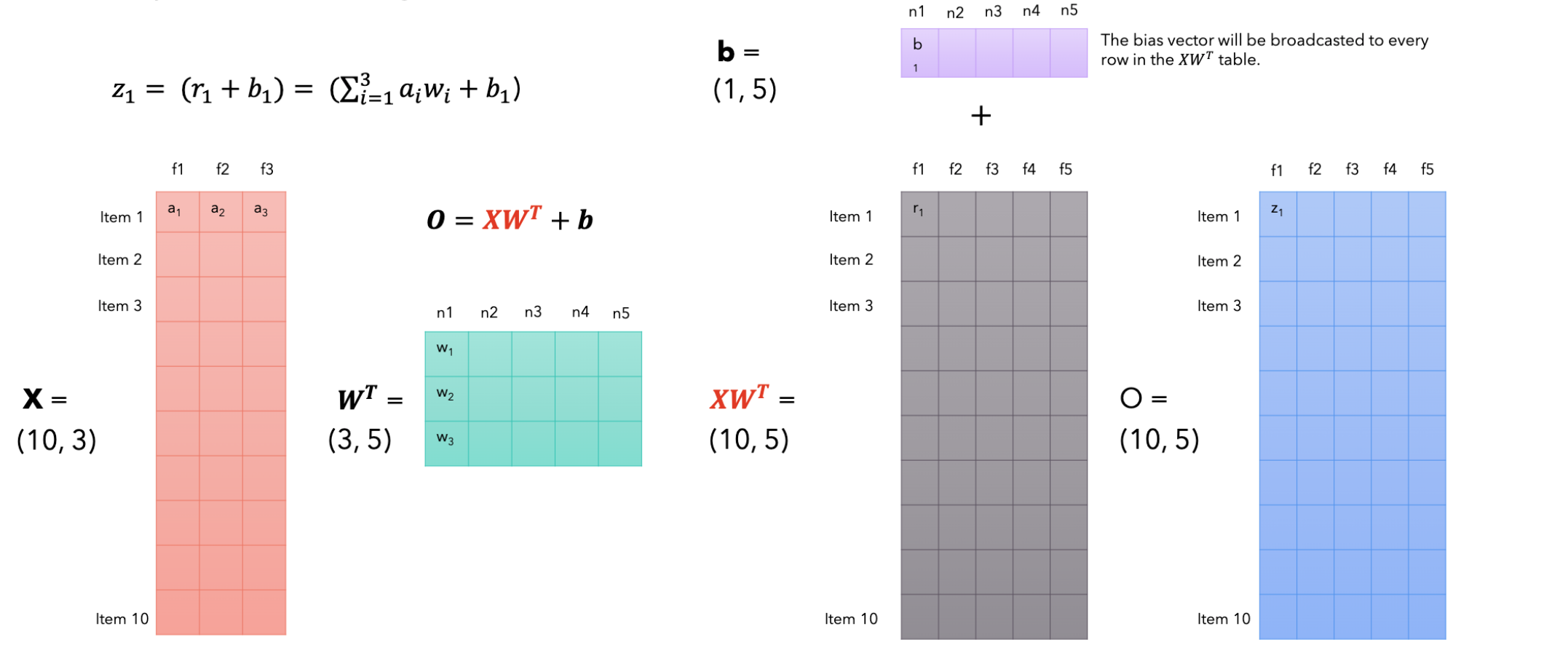
在文档中你将看到线性层执行这个非常简单的操作,它接受输入,你可以将其视为由特征组成的向量,或者你可以将其视为由许多项目组成的矩阵,每个项目都具有输入特征,让后我们将它乘以权重矩阵,我们它称之为10个输入,每个输入向量有3个特征组成,在这里称之为3个特征作为输入并产生5个输出特征,因此,权重矩阵转置后的权重矩阵将是10个项目,因为在输入中我们有10个项目(items),每个项目有5个特征,因为线性层从3个特征变为5个特征输出。第1个特征是由第一个项目与第1个神经元的点积生成的。这里的值是第2个输出第一项的特征是第一项的特征值乘以第2个神经元,因此第2个神经元的权重在执行此乘法之后负责该线性层中的一个输出特征,我们添加一个偏差项,在本例中是一个向量,每个神经元都有一个值,我们将它广播到这个矩阵。每个项目的每个输出特征将有一个附加项,即与该特定神经元相关的偏差,因此第一个神经元将添加第一个特征的值加上10个项目,每个项目有5个特征。线性层是从3变换到5。所以基本上它是每个项目的输入特征乘以相应的权重加上偏差。
为什么线性层需要激活函数?
主要有以下几个原因:
- 引入非线性:非线性激活函数能够为神经网络引入非线性特性,使网络能够学习和表示复杂的非线性关系。如果没有非线性激活函数,多层神经网络就等同于单层线性网络,无法建模复杂的函数。
- 增强表达能力:非线性激活函数使神经网络能够近似任意复杂的函数。根据通用近似定理,具有非线性激活函数的前馈网络可以近似任何连续函数。
- 解决梯度消失问题:某些非线性激活函数(如
ReLU)可以帮助缓解深度网络中的梯度消失问题,使得深层网络更容易训练。 - 实现决策边界:非线性激活函数使得神经网络能够学习非线性决策边界,这对于解决复杂的分类问题至关重要。
- 映射到特定范围:某些激活函数(如
Sigmoid和Tanh)可以将输入映射到特定的范围,这对于某些任务(如概率预测)非常有用。 - 促进反向传播:非线性激活函数的可微性质使得反向传播算法能够有效地调整网络权重。
- 增加网络深度能力:使用非线性激活函数使得增加网络深度变得有意义,因为每一层都可以学习更复杂的特征表示。
总之,非线性激活函数是使神经网络能够学习复杂模式和关系的关键组成部分,它们使得神经网络成为强大的通用函数逼近器,能够解决各种复杂的机器学习任务。
数据拟合
想象以下我们正在创建一个2D游戏,其中我们有一个角色,想要通过由点组成来制作动画。当然,制作角色动画的方法是:用这些点并在它们之间画直线,这样就可以为角色设置动画。但看起来不太好,这个动作不太平滑,你可以看到这个角色在刚性运动。所以有一种更好的办法是制作一条弯曲的多项式曲线。它穿过这些点并生成更平滑的路径,这看起来更好。创建一条多项式,穿过这些点的线是弯曲的,如何做到这一点?当你有两个点时,你只能在它们之间画一条线,当你有三个点时,则意味着它们不再是直线,你可以画一条二次曲线,想抛物线一样;如果你有四个点,你需要一个3次方程来画一条穿过它们的多项式线。如何计算这条线的方程而正好穿过所有这些点?我们想象有4个点
我们创一个方程组,在该方程组中我们加一个条件,即该曲线必须从所有这些点上通过,一次我们通过代入来写出该曲线方程:
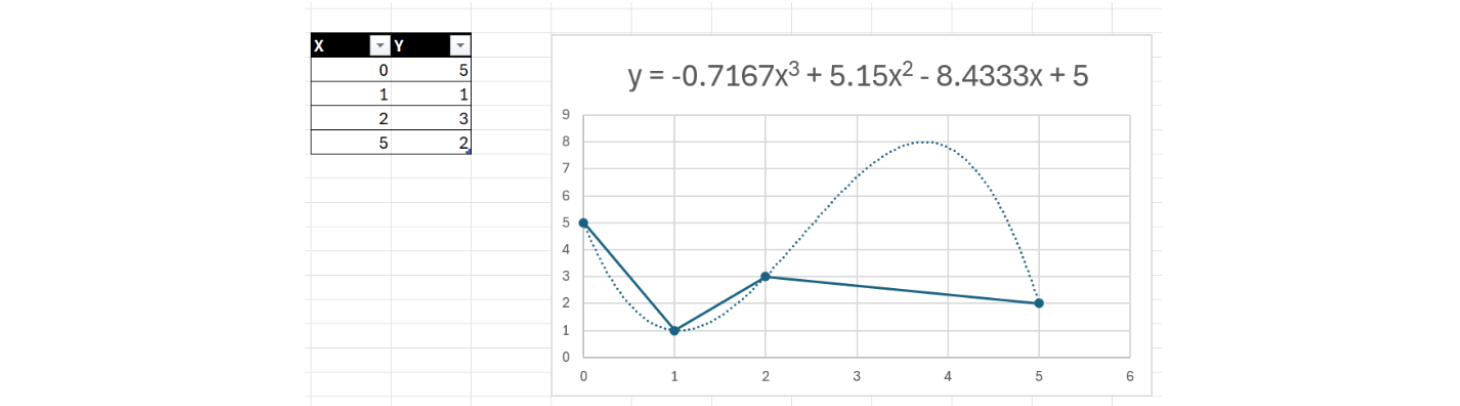
如果现在我们有数百个点并且我们想生成一条穿过它们的平滑曲线,我们可以这样做。但是会存在两个问题:1.我们需要求解非常复杂的方程组,随着点数的增加,这条多项式曲线会以越来越奇怪的方式呈现,我们需要一种方法来控制这条曲线的平滑度,并且不让它在极端情况下变得如此疯狂,在这里需要研究B曲线,看看它是如何工作的。
B样条曲线
B样条曲线是一条参数化的曲线,因为该差值曲线上的点坐标取决于一个称为
现在这条曲线是参数化,这也是你所看到的
我们有一个公式来计算B样条曲线的方程,而无需进行递归计算,我们一系列的点
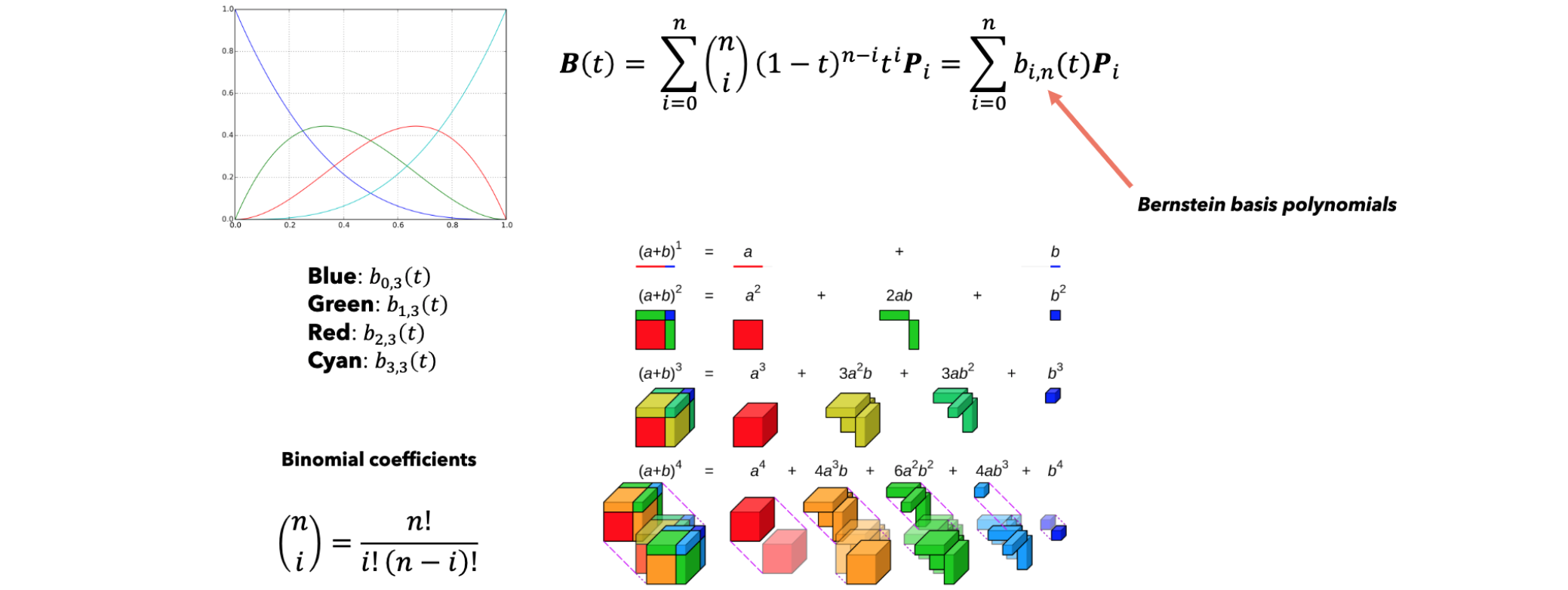
B样条曲线是通过控制点
在这,控制点被称为de Boor点,基函数
其中有
即
即
柯尔莫哥洛夫-阿诺德网络(KAN)
柯尔莫哥洛夫-阿诺德表示定理
在实分析和近似理论中,柯尔莫哥洛夫-阿诺德表示定理(或叠加定理)指出,每个多元连续函数
在这里,
假设有一个多元连续函数2个输入(5个隐藏层神经元的Kolmogorov Network。隐藏层神经元数量为
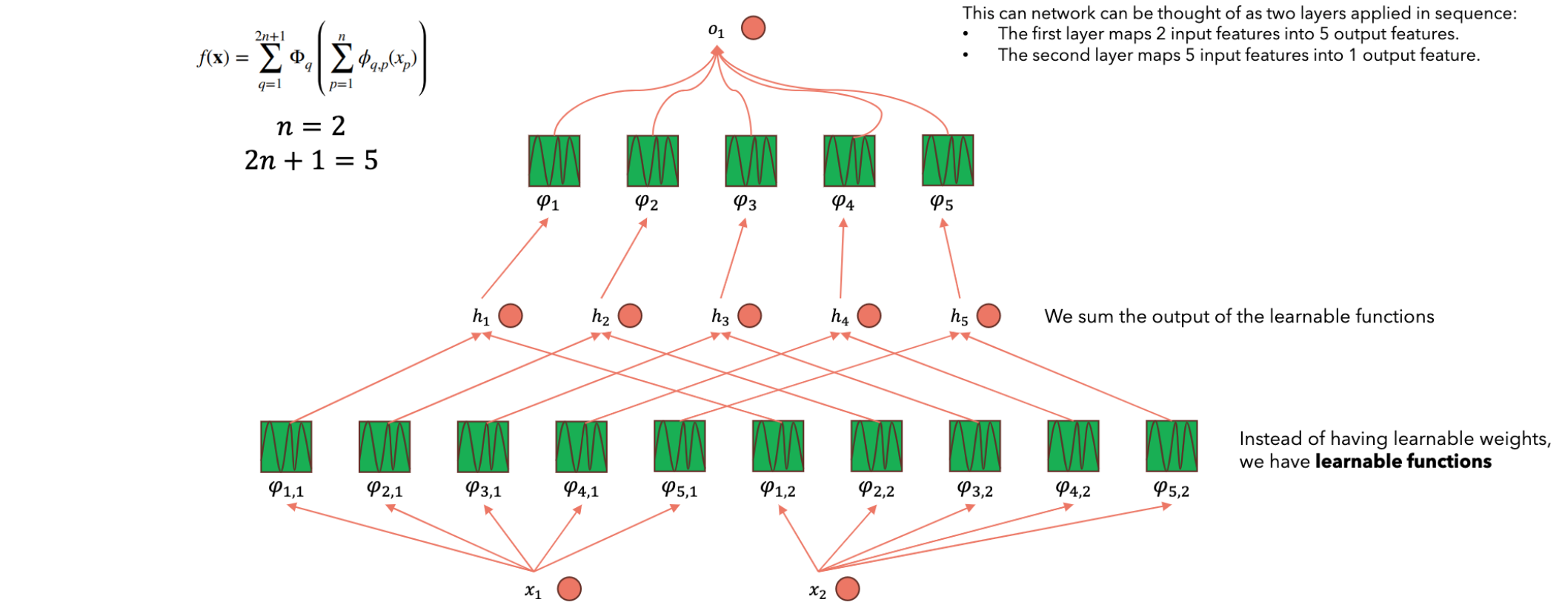
对于第一个神经元,它接收到两个branch的信号,分别是2-5个神经元也是如此,这是第一层神经元取值的计算方法。为了计算第二层神经元的结果,我们需要对第一层中的每个神经元构造一元函数(
MLP vs KAN
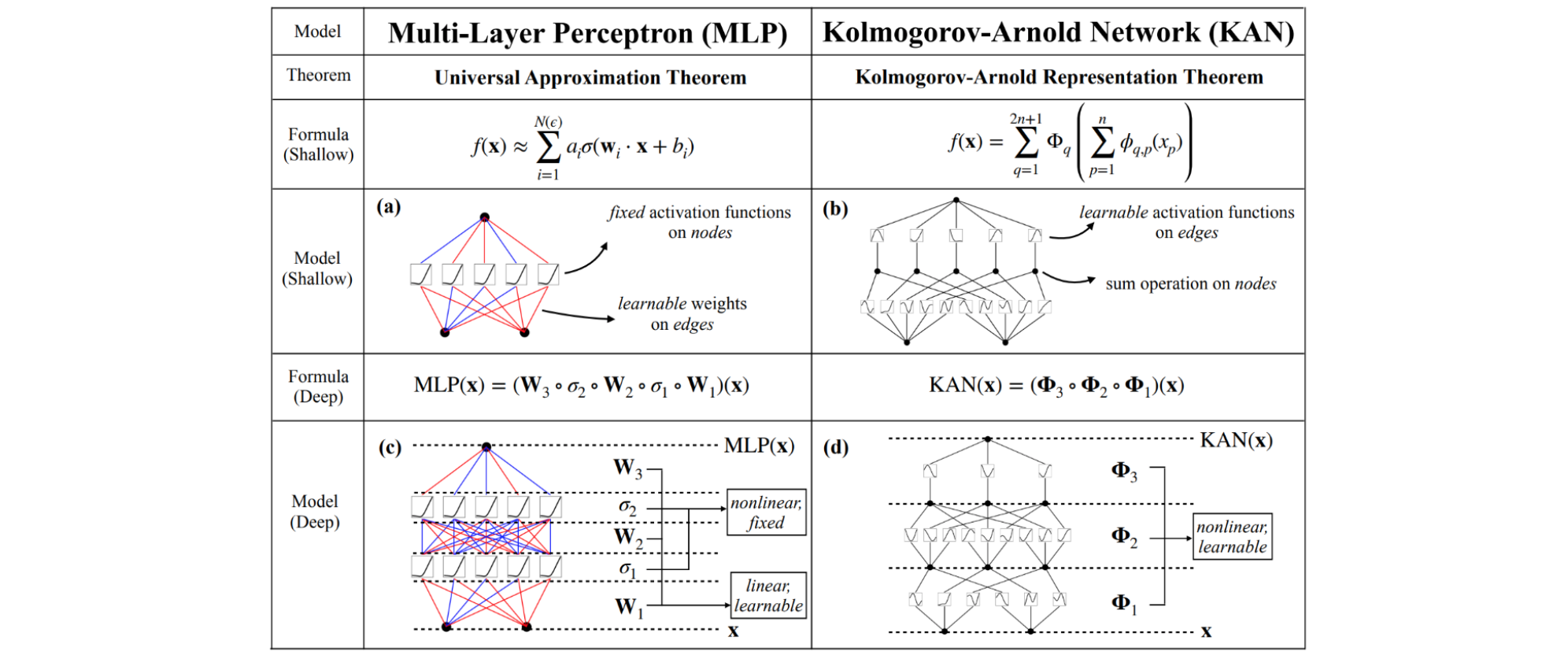
多层KAN实现


KAN参数数量
假设深度为KAN更有效,幸运的是,KAN通常比MLP需要更小的KAN网络只不过是一个样条近似。
KAN可解释性
上面我们提出了多种KAN简化技术。我们可以将这些简化选项视为可以点击的按钮。与这些按钮交互的用户可以决定接下来最有可能点击哪个按钮以使KAN更具可解释性。我们使用下面的示例来展示用户如何与KAN交互以获得最大程度可解释性的结果。

KAN代码实现
先安装必要的KAN库,如下:
1 | pip install pykan |
现在库已安装,让我们导入并定义模型:
1 | import matplotlib.pyplot as plt |
执行上面的代码块后,会生成以下输出:
1 | train loss: 5.77e-02 | test loss: 9.22e-02 | reg: 4.18e+01 : 100%|██| 20/20 [00:04<00:00, 4.23it/s] |
加入以下功能:
1 | lib = ['x', 'x^2', 'x^3', 'x^4', 'exp', 'log', 'sqrt', 'tanh', 'sin', 'abs'] |
因此,KAN在这里表现稍好一些,尽管差别不大。我们可以利用其他基准数据集来比较KAN和MLP,并更好地了解使用KAN模型的优势。
总结
KAN的优势:
- 效率:
KAN通常比MLP具有更高的参数效率。它们可以用更少的参数实现相当甚至更好的准确率。这在涉及回归和偏微分方程(PDE)的任务中尤为明显,在这些任务中KAN的表现明显优于MLP。 - 可解释性:由于使用了样条函数,
KAN的可解释性更好。与MLP中基于节点的固定激活相比,边缘上的激活函数可以更直观地可视化和理解。这使得KAN在科学应用中特别有用,因为理解模型的行为至关重要。 - 避免灾难性遗忘:
KAN已展现出避免灾难性遗忘的能力,这是神经网络中常见的问题,学习新信息可能会导致模型忘记之前学习的信息。这是由于基于样条函数的激活函数的局部可塑性,它只影响附近的样条函数系数,而不会影响远处的系数。
KAN的局限性:
- 训练速度慢:
KAN的训练速度通常比具有相同数量参数的MLP慢10倍左右。这种低效率被认为是一个工程问题,而不是根本限制,这表明未来还有优化的空间。 - 维数灾难:虽然
KAN中使用的样条函数对于低维函数来说是精确的,但由于维数灾难,它们对于高维函数来说却很困难。这是因为样条函数无法有效地利用组合结构,与MLP相比,这是一个重大限制。 - 泛化和现实设置:虽然
KAN在避免灾难性遗忘和可解释性方面已显示出良好的效果,但它们是否可以推广到更现实和更复杂的设置仍不清楚。

柯尔莫哥洛夫-阿诺德网络(KAN)是一种新型神经网络架构,有望突破传统多层感知器(MLP)的局限性。其效率、可解释性和对灾难性遗忘的适应能力使其成为特定应用中的有前途的替代方案。然而,在它们完全取代传统神经网络之前,还有许多挑战需要解决。