残差网络 (ResNet)(TensorFlow)
随着我们设计越来越深的网络,深刻理解“新添加的层如何提升神经网络的性能”变得至关重要。更重要的是设计网络的能力,在这种网络中,添加层会使网络更具表现力,为了取得质的突破,我们需要一些数学基础知识。
函数类
首先,假设有一类特定的神经网络架构
那么怎样得到更近似真正non-nested function)类,较复杂的函数类并不总是向“真”函数nested function)类
的函数类不能保证更接近真函数)。这种现象在嵌套函数类中不会发生。")
因此,只有当较复杂的函数类包含较小的函数类时,我们才能确保提高它们的性能。对于深度神经网络,如果我们能将新添加的层训练成恒等映射(identity function)ResNet)。它在2015年的ImageNet图像识别挑战赛夺魁,并深刻影响了后来的深度神经网络的设计。残差网络的核心思想是:每个附加层都应该更容易地包含原始函数作为其元素之一。于是,残差块(residual blocks)便诞生了,这个设计对如何建立深层神经网络产生了深远的影响。凭借它,ResNet赢得了2015年ImageNet大规模视觉识别挑战赛。
残差块
让我们聚焦于神经网络局部:如下图所示,假设我们的原始输入为0,那么ResNet的基础架构–残差块(residual block)。在残差块中,输入可通过跨层数据线路更快地向前传播。
和一个残差块(右图)")
ResNet沿用了VGG完整的2个有相同输出通道数的ReLU激活函数。然后我们通过跨层数据通路,跳过这2个卷积运算,将输入直接加在最后的ReLU激活函数前。这样的设计要求2个卷积层的输出与输入形状一样,从而使它们可以相加。如果想改变通道数,就需要引入一个额外的use_1x1conv=False时,应用ReLU非线性函数之前,将输入添加到输出。另一种是当use_1x1conv=True时,添加通过

ResNet模型
ResNet的前两层跟之前介绍的GoogLeNet中的一样:在输出通道数为64、步幅为2的2的ResNet每个卷积层后增加了批量规范化层。GoogLeNet在后面接了4个由Inception块组成的模块。ResNet则使用4个由残差块组成的模块,每个模块使用若干个同样输出通道数的残差块。第一个模块的通道数同输入通道数一致。由于之前已经使用了步幅为2的最大汇聚层,所以无须减小高和宽。之后的每个模块在第一个残差块里将上一个模块的通道数翻倍,并将高和宽减半。
1 | import tensorflow as tf |
结果输出为:
1 | Conv2D output shape: (1, 112, 112, 64) |
每个模块有4个卷积层(不包括恒等映射的18层。因此,这种模型通常被称为ResNet-18。通过配置不同的通道数和模块里的残差块数可以得到不同的ResNet模型,例如更深的含152层的ResNet-152。虽然ResNet的主体架构跟GoogLeNet类似,但ResNet架构更简单,修改也更方便。这些因素都导致了ResNet迅速被广泛使用。下图描述了完整的ResNet-18。

在训练ResNet之前,让我们观察一下ResNet中不同模块的输入形状是如何变化的。在之前所有架构中,分辨率降低,通道数量增加,直到全局平均汇聚层聚集所有特征。
训练模型
同之前一样,我们在Fashion-MNIST数据集上训练ResNet。
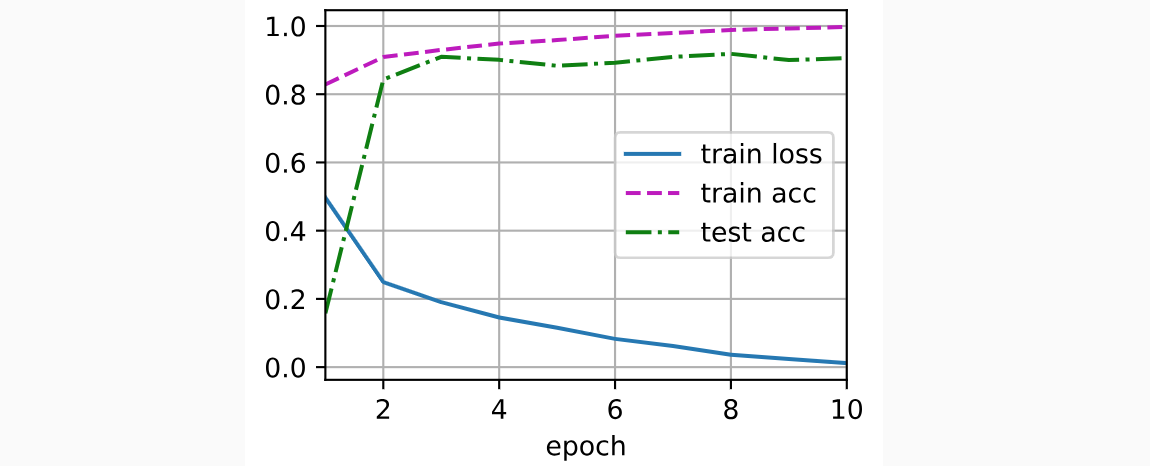
总结
学习嵌套函数(nested function)是训练神经网络的理想情况。在深层神经网络中,学习另一层作为恒等映射(identity function)较容易(尽管这是一个极端情况)。残差映射可以更容易地学习同一函数,例如将权重层中的参数近似为零。利用残差块(residual blocks)可以训练出一个有效的深层神经网络:输入可以通过层间的残余连接更快地向前传播。残差网络(ResNet)对随后的深层神经网络设计产生了深远影响。