网络中的网络 (NiN)(TensorFlow)
LeNet、AlexNet和VGG都有一个共同的设计模式:通过一系列的卷积层与汇聚层来提取空间结构特征;然后通过全连接层对特征的表征进行处理。AlexNet和VGG对LeNet的改进主要在于如何扩大和加深这两个模块。或者,可以想象在这个过程的早期使用全连接层。然而,如果使用了全连接层,可能会完全放弃表征的空间结构。网络中的网络(NiN)提供了一个非常简单的解决方案:在每个像素的通道上分别使用多层感知机。
NiN块
回想一下,卷积层的输入和输出由四维张量组成,张量的每个轴分别对应样本、通道、高度和宽度。另外,全连接层的输入和输出通常是分别对应于样本和特征的二维张量。NiN的想法是在每个像素位置(针对每个高度和宽度)应用一个全连接层。如果我们将权重连接到每个空间位置,我们可以将其视为feature)。
下图说明了VGG和NiN及它们的块之间主要架构差异。NiN块以一个普通卷积层开始,后面是两个ReLU激活函数的逐像素全连接层。第一层的卷积窗口形状通常由用户设置。随后的卷积窗口形状固定为

NiN模型
最初的NiN网络是在AlexNet后不久提出的,显然从中得到了一些启示。NiN使用窗口形状为AlexNet中的相同。每个NiN块后有一个最大汇聚层,汇聚窗口形状为2。NiN和AlexNet之间的一个显著区别是NiN完全取消了全连接层。相反,NiN使用一个NiN块,其输出通道数等于标签类别的数量。最后放一个全局平均汇聚层(global average pooling layer),生成一个对数几率(logits)。NiN设计的一个优点是,它显著减少了模型所需参数的数量。然而,在实践中,这种设计有时会增加训练模型的时间。
1 | import tensorflow as tf |
结果输出为:
1 | Sequential output shape: (1, 54, 54, 96) |
训练模型
和以前一样,我们使用Fashion-MNIST来训练模型。训练NiN与训练AlexNet、VGG时相似。
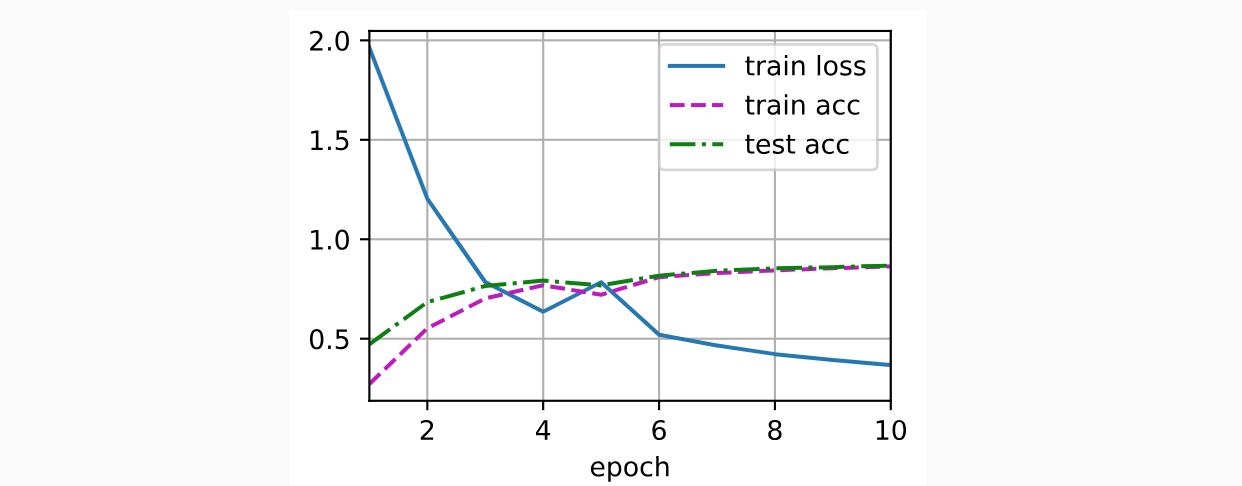
总结
NiN块使用由一个卷积层和多个NiN去除了容易造成过拟合的全连接层,将它们替换为全局平均汇聚层(即在所有位置上进行求和)。该汇聚层通道数量为所需的输出数量(例如,Fashion-MNIST的输出为10)。移除全连接层可减少过拟合,同时显著减少NiN的参数。NiN的设计影响了许多后续卷积神经网络的设计。