卷积神经网络 (CNN)(TensorFlow)
卷积神经网络(convolutional neural network,CNN)是一类强大的、为处理图像数据而设计的神经网络。基于卷积神经网络架构的模型在计算机视觉领域中已经占主导地位,当今几乎所有的图像识别、目标检测或语义分割相关的学术竞赛和商业应用都以这种方法为基础。
现代卷积神经网络的设计得益于生物学、群论和一系列的补充实验。卷积神经网络需要的参数少于全连接架构的网络,而且卷积也很容易用GPU并行计算。因此卷积神经网络除了能够高效地采样从而获得精确的模型,还能够高效地计算。久而久之,从业人员越来越多地使用卷积神经网络。即使在通常使用循环神经网络的一维序列结构任务上(例如音频、文本和时间序列分析),卷积神经网络也越来越受欢迎。通过对卷积神经网络一些巧妙的调整,也使它们在图结构数据和推荐系统中发挥作用。
从全连接层到卷积
不变性
- 平移不变性(
translation invariance):不管检测对象出现在图像中的哪个位置,神经网络的前面几层应该对相同的图像区域具有相似的反应,即为“平移不变性”。 - 局部性(
locality):神经网络的前面几层应该只探索输入图像中的局部区域,而不过度在意图像中相隔较远区域的关系,这就是“局部性”原则。最终,可以聚合这些局部特征,以在整个图像级别进行预测。
多层感知机的限制
首先,多层感知机的输入是二维图像
其中从
平移不变性
现在引用上述的第一个原则:平移不变性。这意味着检测对象的输入
这就是卷积(convolution),我们使用系数
局部性
现在引用上述的第二个原则:局部性。如上所述,为了收集用来训练参数
简而言之,这是一个卷积层(convolutional layer),而卷积神经网络是包含卷积层的一类特殊的神经网络。在深度学习研究社区中,convolution kernel)或者滤波器(filter),亦或简单地称之为该卷积层的权重,通常该权重是可学习的参数。当图像处理的局部区域很小时,卷积神经网络与多层感知机的训练差异可能是巨大的:以前,多层感知机可能需要数十亿个参数来表示网络中的一层,而现在卷积神经网络通常只需要几百个参数,而且不需要改变输入或隐藏表示的维数。参数大幅减少的代价是,我们的特征现在是平移不变的,并且当确定每个隐藏活性值时,每一层只包含局部的信息。以上所有的权重学习都将依赖于归纳偏置。当这种偏置与现实相符时,我们就能得到样本有效的模型,并且这些模型能很好地泛化到未知数据中。但如果偏置与现实不符时,比如当图像不满足平移不变时,我们的模型可能难以拟合我们的训练数据。
卷积
我们先简要回顾一下为什么上面的操作被称为卷积。在数学中,两个函数(比如
也就是说,卷积是当把一个函数“翻转”并移位
对于二维张量,则为
总结
图像的平移不变性使我们以相同的方式处理局部图像,而不在乎它的位置。局部性意味着计算相应的隐藏表示只需一小部分局部图像像素。在图像处理中,卷积层通常比全连接层需要更少的参数,但依旧获得高效用的模型。卷积神经网络(CNN)是一类特殊的神经网络,它可以包含多个卷积层。多个输入和输出通道使模型在每个空间位置可以获取图像的多方面特征。
图像卷积
我们解析了卷积层的原理,现在我们看看它的实际应用。
互相关运算
严格来说,卷积层是个错误的叫法,因为它所表达的运算其实是互相关运算(cross-correlation),而不是卷积运算。首先,我们暂时忽略通道(第三维)这一情况,看看如何处理二维图像数据和隐藏表示。输入是高度为3、宽度为3的二维张量。卷积核的高度和宽度都是2,而卷积核窗口(或卷积窗口)的形状由内核的高度和宽度决定。

在二维互相关运算中,卷积窗口从输入张量的左上角开始,从左到右、从上到下滑动。当卷积窗口滑动到新一个位置时,包含在该窗口中的部分张量与卷积核张量进行按元素相乘,得到的张量再求和得到一个单一的标量值,由此我们得出了这一位置的输出张量值。在如上例子中,输出张量的四个元素由二维互相关运算得到,这个输出高度为2、宽度为2,如下所示:
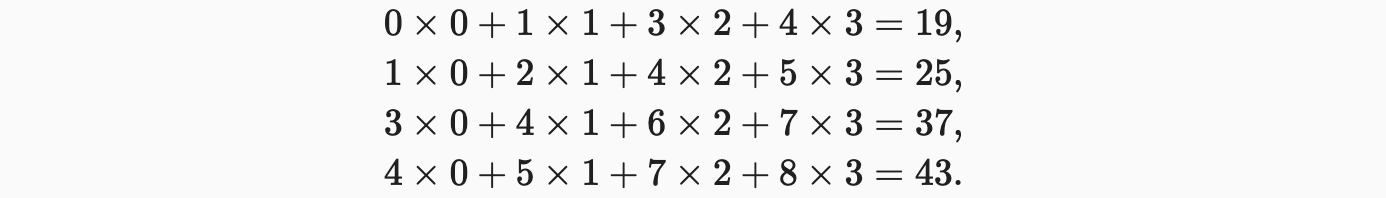
注意,输出大小略小于输入大小。这是因为卷积核的宽度和高度大于1,而卷积核只与图像中每个大小完全适合的位置进行互相关运算。所以输出大小等于输入大小
这是因为我们需要足够的空间在图像上“移动”卷积核。我们在corr2d函数中实现如上过程,该函数接受输入张量X和卷积核张量K,并返回输出张量Y。
1 | import tensorflow as tf |
卷积层
卷积层对输入和卷积核权重进行互相关运算,并在添加标量偏置之后产生输出。所以,卷积层中的两个被训练的参数是卷积核权重和标量偏置。就像我们之前随机初始化全连接层一样,在训练基于卷积层的模型时,我们也随机初始化卷积核权重。基于上面定义的corr2d函数实现二维卷积层。在__init__构造函数中,将weight和bias声明为两个模型参数。前向传播函数调用corr2d函数并添加偏置。
1 | class Conv2D(tf.keras.layers.Layer): |
高度和宽度分别为
图像中目标的边缘检测
如下是卷积层的一个简单应用:通过找到像素变化的位置,来检测图像中不同颜色的边缘。首先,我们构造一个0),其余像素为白色(1)。
1 | X = tf.Variable(tf.ones((6, 8))) |
卷积核
如果我们只需寻找黑白边缘,那么以上[1, -1]的边缘检测器足以。然而,当有了更复杂数值的卷积核,或者连续的卷积层时,我们不可能手动设计滤波器。那么我们是否可以学习由X生成Y的卷积核呢?现在让我们看看是否可以通过仅查看“输入-输出”对来学习由X生成Y的卷积核。我们先构造一个卷积层,并将其卷积核初始化为随机张量。接下来,在每次迭代中,我们比较Y与卷积层输出的平方误差,然后计算梯度来更新卷积核。为了简单起见,我们在此使用内置的二维卷积层,并忽略偏置。
1 | # 构造一个二维卷积层,它具有1个输出通道和形状为(1,2)的卷积核 |
你会发现,我们学习到的卷积核权重非常接近我们之前定义的卷积核K。
互相关和卷积
为了得到正式的卷积运算输出,我们需要执行之前定义的严格卷积运算,而不是互相关运算。幸运的是,它们差别不大,我们只需水平和垂直翻转二维卷积核张量,然后对输入张量执行互相关运算。
总结
二维卷积层的核心计算是二维互相关运算。最简单的形式是,对二维输入数据和卷积核执行互相关操作,然后添加一个偏置。我们可以设计一个卷积核来检测图像的边缘。我们可以从数据中学习卷积核的参数。学习卷积核时,无论用严格卷积运算或互相关运算,卷积层的输出不会受太大影响。当需要检测输入特征中更广区域时,我们可以构建一个更深的卷积网络。
填充和步幅
卷积的输出形状取决于输入形状和卷积核的形状。还有什么因素会影响输出的大小呢?假设以下情景:有时,在应用了连续的卷积之后,我们最终得到的输出远小于输入大小。这是由于卷积核的宽度和高度通常大于1所导致的。比如,一个
填充
如上所述,在应用多层卷积时,我们常常丢失边缘像素。由于我们通常使用小卷积核,因此对于任何单个卷积,我们可能只会丢失几个像素。但随着我们应用许多连续卷积层,累积丢失的像素数就多了。解决这个问题的简单方法即为填充(padding):在输入图像的边界填充元素(通常填充元素是0)。例如,在下图中,我们将

通常,我们添加
这意味着输出的高度和宽度将分别增加1、3、5或7。选择奇数的好处是,保持空间维度的同时,我们可以在顶部和底部填充相同数量的行,在左侧和右侧填充相同数量的列。此外,使用奇数的核大小和填充大小也提供了书写上的便利。对于任何二维张量X,当满足:1.卷积核的大小是奇数;2.所有边的填充行数和列数相同;3.输出与输入具有相同高度和宽度则可以得出:输出Y[i, j]是通过以输入X[i, j]为中心,与卷积核进行互相关计算得到的。
比如,在下面的例子中,我们创建一个高度和宽度为3的二维卷积层,并在所有侧边填充1个像素。给定高度和宽度为8的输入,则输出的高度和宽度也是8。
1 | import tensorflow as tf |
步幅
在计算互相关时,卷积窗口从输入张量的左上角开始,向下、向右滑动。在前面的例子中,我们默认每次滑动一个元素。但是,有时候为了高效计算或是缩减采样次数,卷积窗口可以跳过中间位置,每次滑动多个元素。我们将每次滑动元素的数量称为步幅(stride)。到目前为止,我们只使用过高度或宽度为

通常,当垂直步幅为
如果我们设置了2,从而将输入的高度和宽度减半。
1 | conv2d = tf.keras.layers.Conv2D(1, kernel_size=3, padding='same', strides=2) |
为了简洁起见当输入高度和宽度两侧的填充数量分别为
总结
填充可以增加输出的高度和宽度。这常用来使输出与输入具有相同的高和宽。步幅可以减小输出的高和宽,例如输出的高和宽仅为输入的高和宽的
多输入多输出通道
多输入通道
当输入包含多个通道时,需要构造一个与输入数据具有相同输入通道数的卷积核,以便与输入数据进行互相关运算。假设输入的通道数为

为了加深理解,我们实现一下多输入通道互相关运算。简而言之,我们所做的就是对每个通道执行互相关操作,然后将结果相加。
1 | import tensorflow as tf |
多输出通道
到目前为止,不论有多少输入通道,我们还只有一个输出通道。在最流行的神经网络架构中,随着神经网络层数的加深,我们常会增加输出通道的维数,通过减少空间分辨率以获得更大的通道深度。直观地说,我们可以将每个通道看作对不同特征的响应。而现实可能更为复杂一些,因为每个通道不是独立学习的,而是为了共同使用而优化的。因此,多输出通道并不仅是学习多个单通道的检测器。用
1 | def corr2d_multi_in_out(X, K): |
下图展示了使用3个输入通道和2个输出通道的互相关计算。这里输入和输出具有相同的高度和宽度,输出中的每个元素都是从输入图像中同一位置的元素的线性组合。我们可以将

下面,我们使用全连接层实现
1 | def corr2d_multi_in_out_1x1(X, K): |
总结
多输入多输出通道可以用来扩展卷积层的模型。当以每像素为基础应用时,
汇聚层
汇聚层(pooling),它具有双重目的:降低卷积层对位置的敏感性,同时降低对空间降采样表示的敏感性。
最大汇聚层和平均汇聚层
与卷积层类似,汇聚层运算符由一个固定形状的窗口组成,该窗口根据其步幅大小在输入的所有区域上滑动,为固定形状窗口(有时称为汇聚窗口)遍历的每个位置计算一个输出。然而,不同于卷积层中的输入与卷积核之间的互相关计算,汇聚层不包含参数。相反,池运算是确定性的,我们通常计算汇聚窗口中所有元素的最大值或平均值。这些操作分别称为最大汇聚层(maximum pooling)和平均汇聚层(average pooling)。在这两种情况下,与互相关运算符一样,汇聚窗口从输入张量的左上角开始,从左往右、从上往下的在输入张量内滑动。在汇聚窗口到达的每个位置,它计算该窗口中输入子张量的最大值或平均值。计算最大值或平均值是取决于使用了最大汇聚层还是平均汇聚层。
 = 4")
上图中中的输出张量的高度为
汇聚窗口形状为X,汇聚层输出为Y。无论X[i, j]和X[i, j + 1]的值相同与否,或X[i, j + 1]和X[i, j + 2]的值相同与否,汇聚层始终输出Y[i, j] = 1。也就是说,使用
1 | import tensorflow as tf |
填充和步幅
与卷积层一样,汇聚层也可以改变输出形状。和以前一样,我们可以通过填充和步幅以获得所需的输出形状。下面,我们用深度学习框架中内置的二维最大汇聚层,来演示汇聚层中填充和步幅的使用。我们首先构造了一个输入张量X,它有四个维度,其中样本数和通道数都是1。请注意,Tensorflow采用“通道最后”(channels-last)语法,对其进行优化,(即Tensorflow中输入的最后维度是通道)。
1 | X = tf.reshape(tf.range(16, dtype=tf.float32), (1, 4, 4, 1)) |
默认情况下,深度学习框架中的步幅与汇聚窗口的大小相同。因此,如果我们使用形状为(3, 3)的汇聚窗口,那么默认情况下,我们得到的步幅形状为(3, 3)。
1 | pool2d = tf.keras.layers.MaxPool2D(pool_size=[3, 3]) |
多个通道
在处理多通道输入数据时,汇聚层在每个输入通道上单独运算,而不是像卷积层一样在通道上对输入进行汇总。这意味着汇聚层的输出通道数与输入通道数相同。下面,我们将在通道维度上连结张量1和X+1,以构建具有2个通道的输入。
1 | X = tf.concat([X, X + 1], 3) |
总结
对于给定输入元素,最大汇聚层会输出该窗口内的最大值,平均汇聚层会输出该窗口内的平均值。汇聚层的主要优点之一是减轻卷积层对位置的过度敏感。我们可以指定汇聚层的填充和步幅。使用最大汇聚层以及大于1的步幅,可减少空间维度(如高度和宽度)。汇聚层的输出通道数与输入通道数相同。
卷积神经网络(LeNet)
卷积神经网络(LeNet),它是最早发布的卷积神经网络之一,因其在计算机视觉任务中的高效性能而受到广泛关注。这个模型是由AT&T贝尔实验室的研究员Yann LeCun在1989年提出的(并以其命名),目的是识别图像中的手写数字。当时,Yann LeCun发表了第一篇通过反向传播成功训练卷积神经网络的研究,这项工作代表了十多年来神经网络研究开发的成果。当时,LeNet取得了与支持向量机(support vector machines)性能相媲美的成果,成为监督学习的主流方法。LeNet被广泛用于自动取款机(ATM)机中,帮助识别处理支票的数字。时至今日,一些自动取款机仍在运行Yann LeCun和他的同事Leon Bottou在上世纪90年代写的代码呢。
LeNet
总体来看,LeNet(LeNet-5)由两个部分组成:
- 卷积编码器:由两个卷积层组成;
- 全连接层密集块:由三个全连接层组成。
该架构如下图所示:

每个卷积块中的基本单元是一个卷积层、一个sigmoid激活函数和平均汇聚层。请注意,虽然ReLU和最大汇聚层更有效,但它们在20世纪90年代还没有出现。每个卷积层使用6个输出通道,而第二个卷积层有16个输出通道。每个2)通过空间下采样将维数减少4倍。卷积的输出形状由批量大小、通道数、高度、宽度决定。为了将卷积块的输出传递给稠密块,我们必须在小批量中展平每个样本。换言之,我们将这个四维输入转换成全连接层所期望的二维输入。这里的二维表示的第一个维度索引小批量中的样本,第二个维度给出每个样本的平面向量表示。LeNet的稠密块有三个全连接层,分别有120、84和10个输出。因为我们在执行分类任务,所以输出层的10维对应于最后输出结果的数量。通过下面的LeNet代码,可以看出用深度学习框架实现此类模型非常简单。我们只需要实例化一个Sequential块并将需要的层连接在一起。
1 | import tensorflow as tf |
我们对原始模型做了一点小改动,去掉了最后一层的高斯激活。除此之外,这个网络与最初的LeNet-5一致。下面,我们将一个大小为LeNet。通过在每一层打印输出的形状,我们可以检查模型,以确保其操作与我们期望的下图一致。

1 | X = tf.random.uniform((1, 28, 28, 1)) |
请注意,在整个卷积块中,与上一层相比,每一层特征的高度和宽度都减小了。 第一个卷积层使用2个像素的填充,来补偿4个像素。随着层叠的上升,通道的数量从输入时的1个,增加到第一个卷积层之后的6个,再到第二个卷积层之后的16个。同时,每个汇聚层的高度和宽度都减半。最后,每个全连接层减少维数,最终输出一个维数与结果分类数相匹配的输出。
模型训练
现在我们已经实现了LeNet,我们训练和评估LeNet-5模型。
1 | lr, num_epochs = 0.9, 10 |
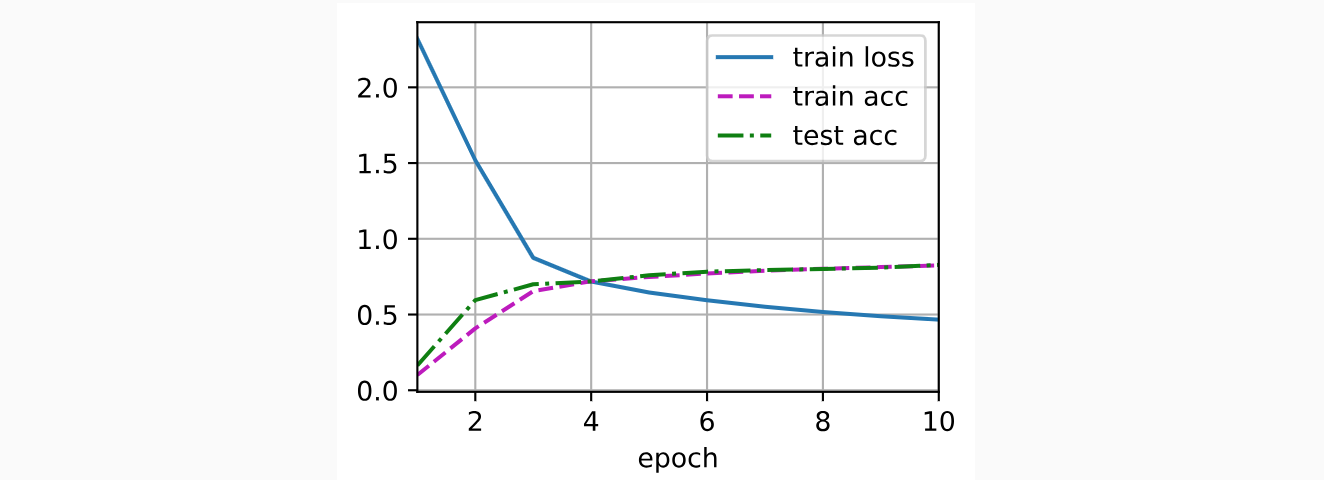
总结
卷积神经网络(CNN)是一类使用卷积层的网络。在卷积神经网络中,我们组合使用卷积层、非线性激活函数和汇聚层。为了构造高性能的卷积神经网络,我们通常对卷积层进行排列,逐渐降低其表示的空间分辨率,同时增加通道数。在传统的卷积神经网络中,卷积块编码得到的表征在输出之前需由一个或多个全连接层进行处理。LeNet是最早发布的卷积神经网络之一。