defcompute_loss(self, features, training=False): # We only pass the user id and timestamp features into the query model. This # is to ensure that the training inputs would have the same keys as the # query inputs. Otherwise the discrepancy in input structure would cause an # error when loading the query model after saving it. query_embeddings = self.query_model({"user_id": features["user_id"],"timestamp": features["timestamp"],}) movie_embeddings = self.candidate_model(features["movie_title"])
import os import pprint import tempfile from typing importDict, Text import numpy as np import tensorflow as tf import tensorflow_datasets as tfds import tensorflow_recommenders as tfrs
ratings = tfds.load('movielens/100k-ratings', split="train") movies = tfds.load('movielens/100k-movies', split="train")
# 重复构建词汇表并将数据拆分为训练集和测试集的准备工作: # Randomly shuffle data and split between train and test. tf.random.set_seed(42) shuffled = ratings.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
train = shuffled.take(80_000) test = shuffled.skip(80_000).take(20_000)
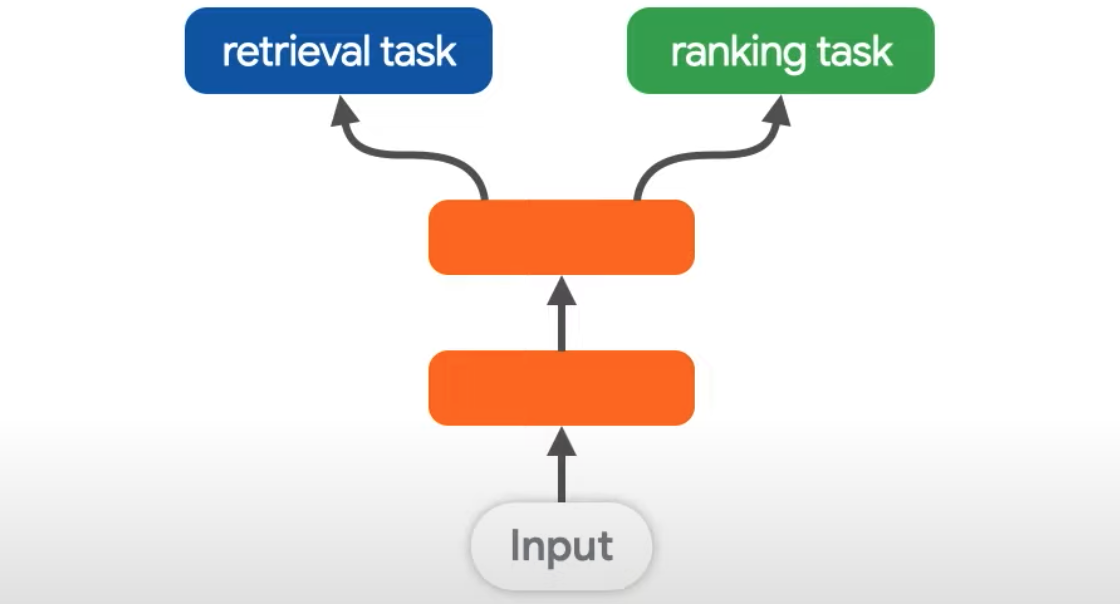
def__init__(self, rating_weight: float, retrieval_weight: float) -> None: # We take the loss weights in the constructor: this allows us to instantiate # several model objects with different loss weights. super().__init__()
# A small model to take in user and movie embeddings and predict ratings. # We can make this as complicated as we want as long as we output a scalar # as our prediction. self.rating_model = tf.keras.Sequential([ tf.keras.layers.Dense(256, activation="relu"), tf.keras.layers.Dense(128, activation="relu"), tf.keras.layers.Dense(1), ])
# The loss weights. self.rating_weight = rating_weight self.retrieval_weight = retrieval_weight
defcall(self, features: Dict[Text, tf.Tensor]) -> tf.Tensor: # We pick out the user features and pass them into the user model. user_embeddings = self.user_model(features["user_id"]) # And pick out the movie features and pass them into the movie model. movie_embeddings = self.movie_model(features["movie_title"])
return ( user_embeddings, movie_embeddings, # We apply the multi-layered rating model to a concatentation of # user and movie embeddings. self.rating_model( tf.concat([user_embeddings, movie_embeddings], axis=1) ), )
defcompute_loss(self, features: Dict[Text, tf.Tensor], training=False) -> tf.Tensor: ratings = features.pop("user_rating") user_embeddings, movie_embeddings, rating_predictions = self(features) # We compute the loss for each task. rating_loss = self.rating_task( labels=ratings, predictions=rating_predictions, ) retrieval_loss = self.retrieval_task(user_embeddings, movie_embeddings)
# And combine them using the loss weights. return (self.rating_weight * rating_loss + self.retrieval_weight * retrieval_loss)
评级专用模型
根据我们分配的权重,模型将对任务的不同平衡进行编码。让我们从一个只考虑评级的模型开始。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
model = MovielensModel(rating_weight=1.0, retrieval_weight=0.0) model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))