KerasCV & KerasNLP 介绍
在深入了解KerasCV和KerasNLP之前,先向你介绍Keras的一个新功能:Keras Core。允许你在任意框架(TensorFlow、JAX和PyTorch)之上运行Keras代码。Keras组件,例如层、模型或指标,作为低级TensorFlow、JAX和PyTorch工作流程的一部分。
KerasCV & KerasNLP的后台环境变量设置:

1 | # Classify text |
了解最新模型以保持竞争力至关重要,与此同时,最先进的模型变得越来越复杂,通常需要昂贵的资源。KerasCV & KerasNLP可以帮助你完成许多机器学习任务。
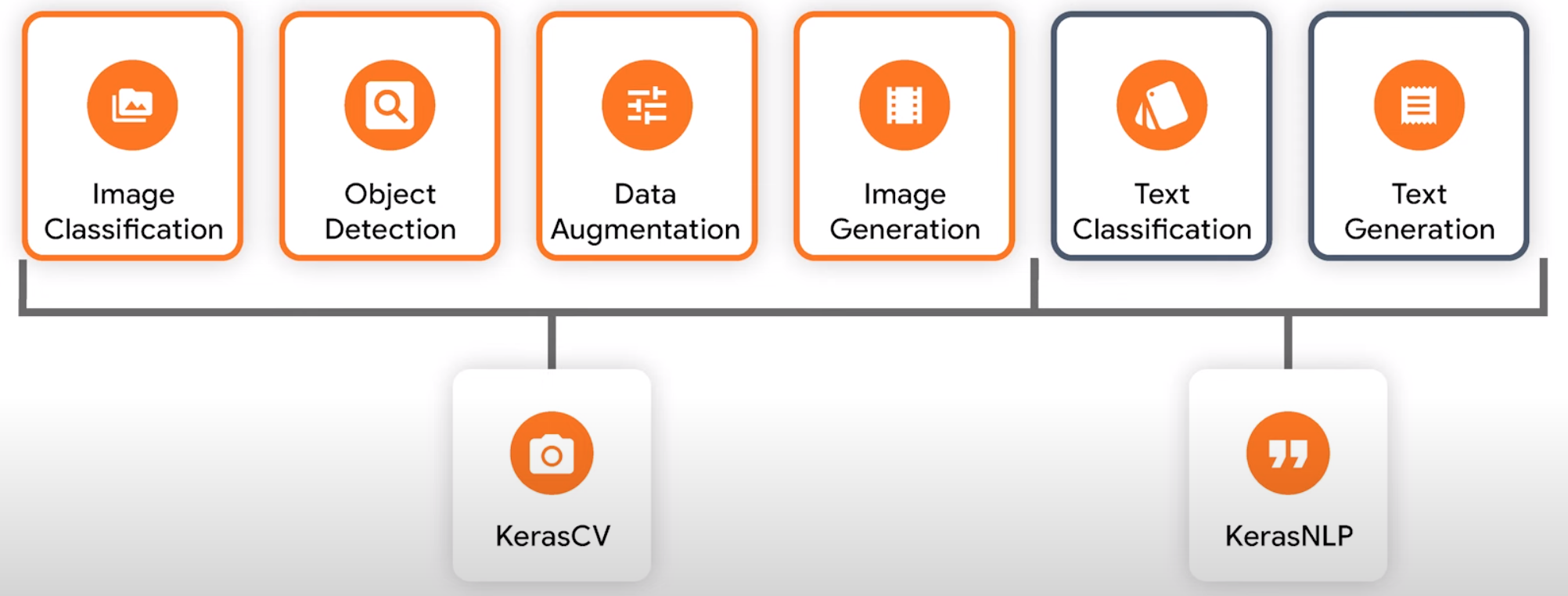
KerasCV & KerasNLP中最高级别的模型是任务,任务(如图像分类器)是一个Keras模型,由主干子模型解决特定问题所需特定任务的层组成。反过来,主干模型是一组重用层。通常在单独的任务上进行预训练,从输入数据中提取信息丰富的特征,从而大大减少在任务中获得有竞争力的性能所需的标记数据量和计算资源。
图像分类
在此示例中我们以ResNet架构为主干,在KerasCV和KerasNLP中加载具有预训练权重的模型,并使用带有预设名称的from_preset构造函数。在此示例中ResNet50 ImageNet是在ImageNet数据集上预训练50层ResNet模型。
1 | from eras_cv.models import {ResNetBackone, ImageClassifier,} |
创建主干模型之后,我们将其连同我们想要预测的类的数量一起传递给图像分类器构造函数,之后编译和拟合模型。
对象检测
KerasCV还支持对象检测,这是一项比图像分类更复杂的任务,因为该模型可以检测任意数量的对象,并且必须为每个对象预测一个类和一个边界框。尽管增加了复杂性,但使用RetinaNet架构创建对象检测模型与图像分类非常相似。我们再次使用from_preset构造函数选择预训练的ResNet50主干网络。主要区别在于需要在训练集中标记边界框并在任务构造函数中指定边界框格式之后。与其他Keras工作流程一样编译并拟合模型。
1 | from eras_cv.models import {ResNetBackone, RetinaNet} |
数据增强
数据增强(Data Augmentation)是最大限度提高计算机视觉任务准确性所必须的关键预处理步骤。为了避免过度拟合训练集的光照、裁剪和其他特殊性,旋转噪声甚至将原始图像混合在一起增加训练目标的鲁棒性非常重要,这里边包括了用于旋转的RandomFlip、用于强度扰动的随机增强(RandomAugment)、用于创建合成图像的CutMix和MixUp等等。只需将您所需的增强层组合到Keras模型中,并在训练模型之前映射你的数据集即可。
1 | from keras_cv.layers import {CutMix, MixUp, RandomAugment, RandomFlip} |
图像生成
文本到图像模型(例如稳定扩散)提供了简单接口,可以根据文本提示生成新颖的图片。使用所需的输出,并提示生成多个输出图片。文本反转是一种通过示例教授稳定扩散模型。提示 -> 提示是一种将提示修改为稳定扩散同时保持图像视觉一致的方法。
1 | from eras_cv.models import {StableDiffusion} |
文本分类
让我们首先训练情感分析分类器,来预测电影评论是正面还是负面。我们使用from_preset构造函数实例化BERT分类器任务模型。与KerasCV的区别之一是KerasNLP任务模型(如BERT分类器)默认包含预处理,在训练和服务时传递原始字符串而不必担心使用正确的标记化和打包方法。因此,最好在任务模型上调用from_preset,而不是传递显示主干。这将自动为你提供一个匹配的于处理器类,它将标记并填充输入。该骨干网络已经过千兆字节文本数据的预训练,以理解上下文中单词的含义,并从我们标记的示例中提取更多信息。
1 | from keras_nlp.models import {BertClassifier} |
在根据IMDB的情感标记电影评论数据集微调我们的模型后,我们可以预测两条新电影评论的情感,获得积极情绪的概率为99.6%。
文本生成
微调文本生成模型,就像分类一样简单,只需传递你希望模型,模仿的文本数据集,预处理就会自动处理。因果LM是一种任务模型,他在给定所有前面的标记的情况下预测输入序列的每个标记,这是训练生成文本模型的规范方法,可以根据用户提示预测新的标记。在此示例中,我们使用from_preset构造函数加载预训练的GPT-2模型。与其他Keras工作流程一样编译并拟合模型。因果任务附带一个生成方法,允许你指定提示和最大输出长度来生成新文本。
1 | from keras_nlp.models import {GPT2CausalLM} |
自定义预处理
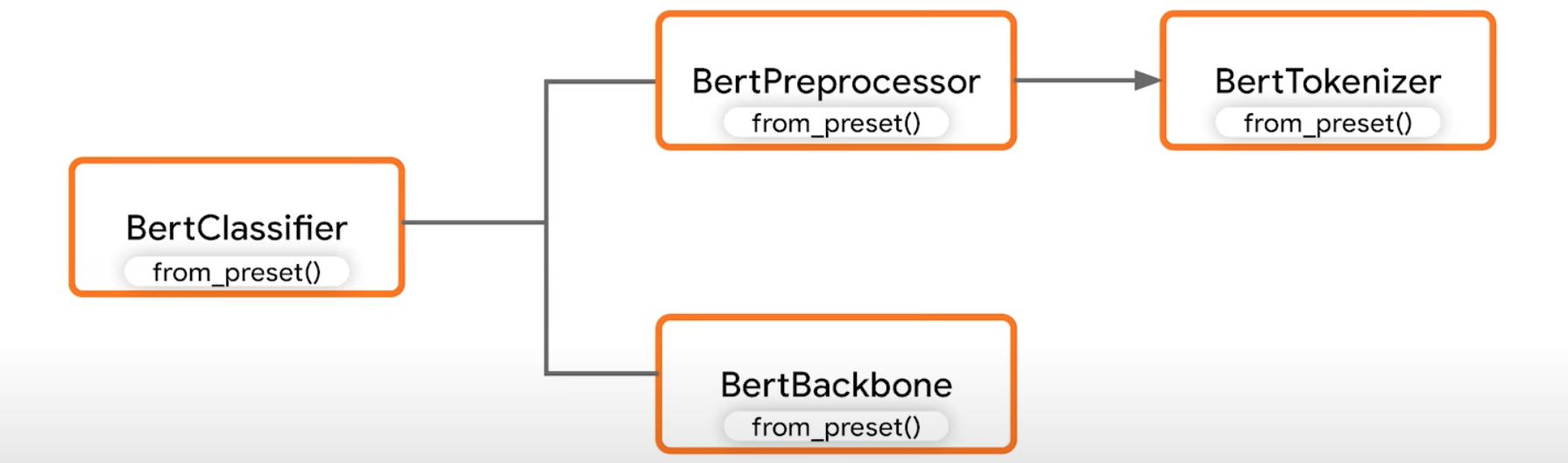
我们从一组较低级别的模块构建最高级别的API来实现这一目标。例如,假设你的数据集包含相对较短的文本段,并且训练需要多次遍历数据。在这种情况下,BERT分类器中的构建预处理器可能不太适合你,因为他将所有序列填充到了512个标记并在每个训练周期中重新计算预处理。对于这种情况从头开始主干、BERT预处理器和BERT分词器类构建而成,每个类都有自己的预设方法,要访问预处理器目录只需使用与分类器相同的预设名称以及你想要指定的任何自定义参数(例如较短的序列),然后你可以自己应用预处理。在此示例中,包含了缓存,在每个时期都不会重新计算标记。为了避免在工作流程中调用预处理器两次,只需要在人物构造函数中设置为None即可。与其他Keras工作流程一样编译并拟合模型。
1 | from keras_nlp.models import {BertClassifier, BertPreprocessor} |
如果需要更多灵活性,则使用Keras函数式API:
1 | from keras_nlp.models import {TokenAndPositionEmbedding, TransformerEncoder} |
创建新模型的第一步是声明输入张量。在本例中,我们的输入是令牌ID的可变长度序列,然后,我们将此序列传入到嵌入层学习每个标记ID和序列位置的唯一向量表示,并返回序列中每个标记的总和。然后我们将嵌入输出传递到一堆可配置的Transformer编码器层,该编码器层将一系列多头注意力和前馈层应用于输入。该堆栈的输出使我们最终的序列表示。为了让令牌序列生成单个分类输出,常见的做法是在每个序列的开头放置一个占位符令牌,并将该令牌的表示作为输入传递到前馈层,该前馈层具有与要预测的类相同数量的输出。与任何Keras模型一样我们将特征输入和输出传递给构造函数以获取模型实例。与其他Keras工作流程一样编译并拟合模型。