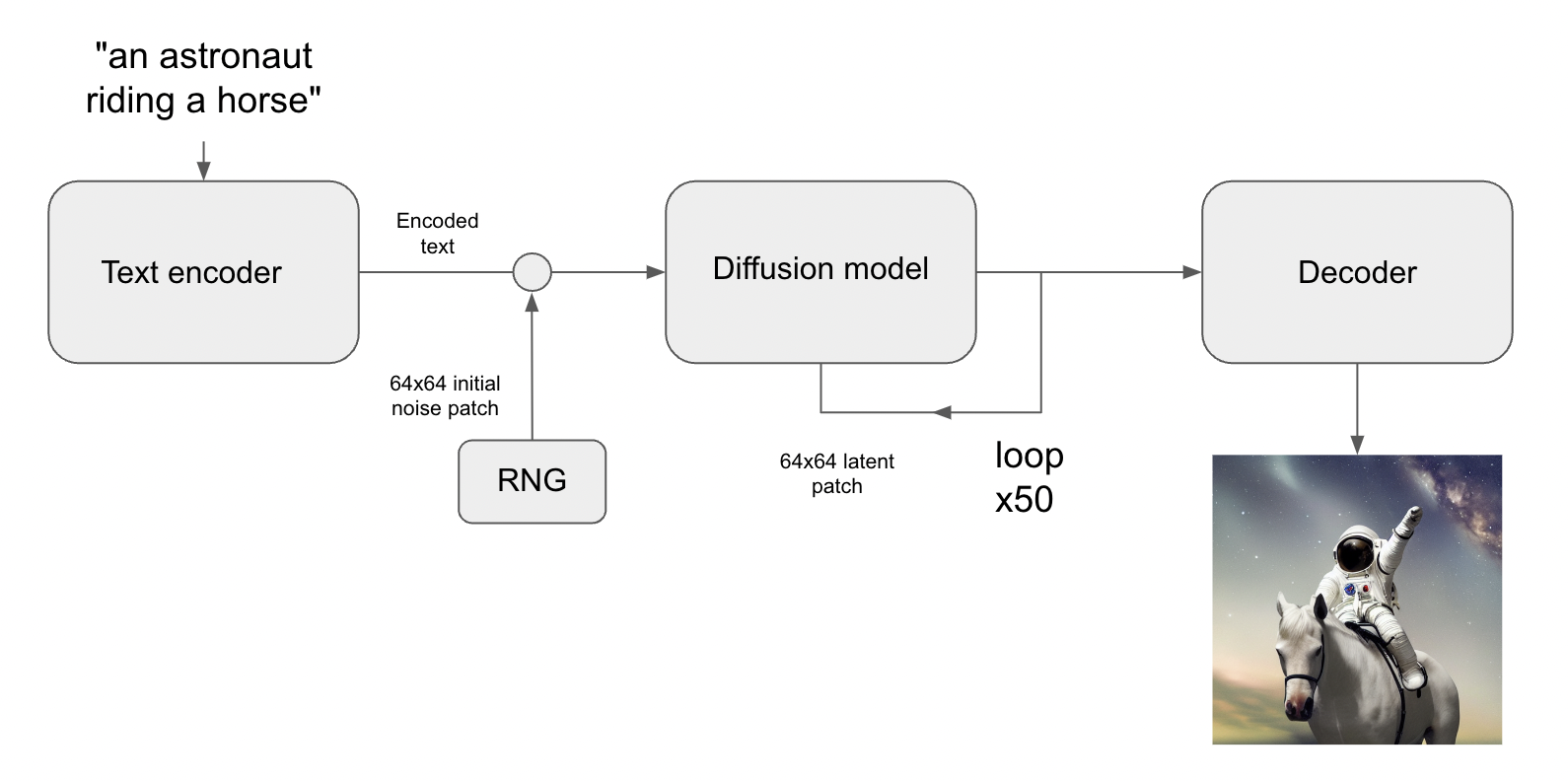
import time import keras_cv import keras import matplotlib.pyplot as plt
# 首先,我们构建一个模型 model = keras_cv.models.StableDiffusion(img_width=512, img_height=512, jit_compile=False)
# 接下来,我们给它一个提示: images = model.text_to_image("photograph of an astronaut riding a horse", batch_size=3) defplot_images(images): plt.figure(figsize=(20, 20)) for i inrange(len(images)): ax = plt.subplot(1, len(images), i + 1) plt.imshow(images[i]) plt.axis("off")
plot_images(images)
# 但这并不是该模型所能做的全部。让我们尝试一个更复杂的提示: images = model.text_to_image( "cute magical flying dog, fantasy art, " "golden color, high quality, highly detailed, elegant, sharp focus, " "concept art, character concepts, digital painting, mystery, adventure", batch_size=3, ) plot_images(images)
# Set back to the default for benchmarking purposes. keras.mixed_precision.set_global_policy("float32") model = keras_cv.models.StableDiffusion(jit_compile=True)
start = time.time() # Before we benchmark the model, we run inference once to make sure the TensorFlow # graph has already been traced. images = model.text_to_image("A cute otter in a rainbow whirlpool holding shells, watercolor",batch_size=3,) end = time.time()
benchmark_result.append(["XLA", end - start]) plot_images(images)
keras.mixed_precision.set_global_policy("mixed_float16") model = keras_cv.models.StableDiffusion(jit_compile=True)
start = time.time() images = model.text_to_image( "A mysterious dark stranger visits the great pyramids of egypt, " "high quality, highly detailed, elegant, sharp focus, " "concept art, character concepts, digital painting", batch_size=3, ) end = time.time() benchmark_result.append(["XLA + Mixed Precision", end - start]) plot_images(images)