电影推荐(TensorFlow Ranking)
TensorFlow Ranking是一个开源库,用于开发可扩展的神经学习排名 (LTR) 模型。 排名模型通常用于搜索和推荐系统,但也已成功应用于各种领域,包括机器翻译、对话系统、SAT求解器、智能城市规划,甚至计算生物学。排名模型采用项目列表(网页、文档、产品、电影等)并以优化的顺序生成列表,例如最相关的项目位于顶部,最不相关的项目位于底部,通常应用于用户搜索:
该库支持LTR模型的标准逐点、成对和列表损失函数。它还支持广泛的排名指标,包括平均倒数排名(MRR)和标准化贴现累积增益(NDCG),因此您可以针对排名任务评估和比较这些方法。排名库还提供了由Google机器学习工程师研究、测试和构建的增强排名方法的函数。
TensorFlow Ranking库可帮助您构建可扩展的神经学习排名模型,使用最新研究中成熟的方法和技术对机器学习模型进行排名。排名模型采用相似项目的列表(例如网页),并生成这些项目的优化列表,例如最相关的页面与最不相关的页面。学习排序模型在搜索、问答、推荐系统和对话系统中都有应用。您可以使用此库通过Keras API加速为您的应用程序构建排名模型。排名库还提供工作流实用程序,使您可以更轻松地扩展模型实现,从而使用分布式处理策略有效地处理大型数据集。
BERT列表输入排序
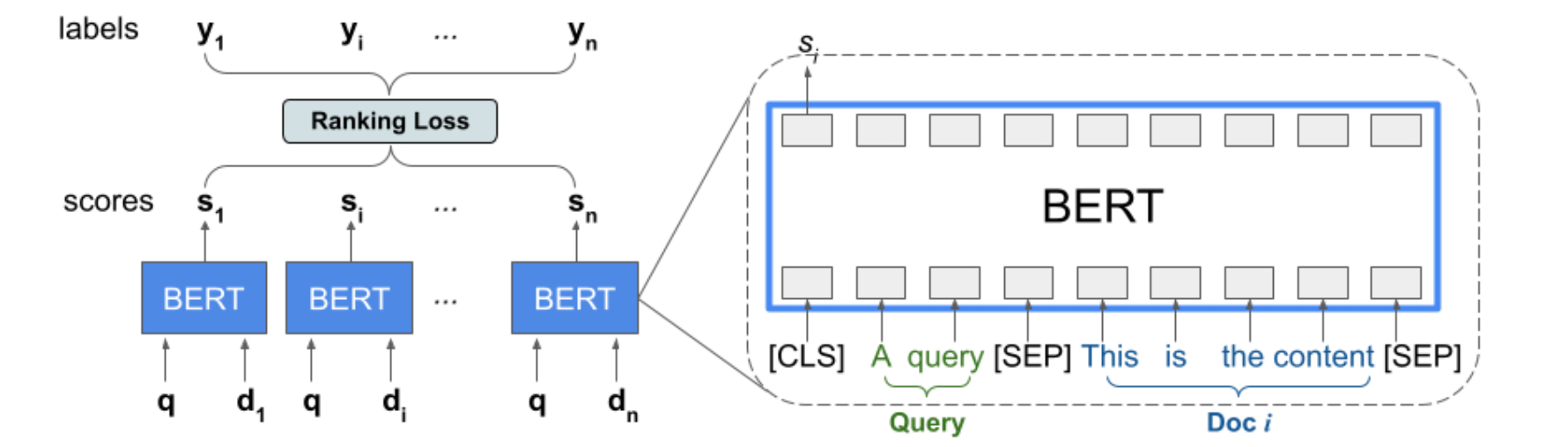
Ranking库提供了TFR-BERT的实现,这是一种将BERT与LTR建模结合起来的评分架构,以优化列表输入的排序。作为此方法的一个示例应用程序,请考虑一个查询和一个包含n个文档的列表,您希望根据该查询对这些文档进行排名。LTR模型不是<query, document>对学习独立的BERT表示,而是应用排名损失来联合学习BERT表示,从而最大化整个排名列表相对于真实标签的效果。下图说明了这个过程,首先,我们将包含n个文档的列表展平,以响应查询列表<query,document>元组进行排名。这些元组被输入到预先训练的语言模型(例如BERT)中,然后,将整个文档列表的汇总BERT输出与TF-Ranking中专门的排名损失之一联合微调。我们的经验表明,这种TFR-BERT架构可以显著提高预训练怨言的性能,尤其是在集成多个预训练语言模型时。我们的用户现在可以使用这个简单的示例开始使用TFR-BERT。
在传统的检索排名管道中,我们在检索阶段来过滤大量候选者。然后,仅将相关的候选者传递到排名阶段。需要检索阶段是因为候选池太大,如果你直接对所有项目进行排名,则需要花费太多的时间,并且你将受到延迟的影响。这就是为什么我们需要检索阶段来缩小项目的排名。但是,如果你一开始就没有很多项目,换句话说,如果你的排名阶段可以在延迟要求范围内对所有项目进行排名,该怎么办?还需要检索阶段吗?答案是否定的。在这种情况下你可以只进行排名而忽略检索。在工具方面 你可以使用:TensorFlow Recommenders进行逐点排名,也可以使用TensorFlow Ranking执行更复杂的排名。如果单独使用TensorFlow Ranking进行推荐,可以帮助你有效地对候选项目列表进行排名,并且在Google内部广泛使用。有了这个背景,我们来看看下面这个例子。我们使用MovieLens 100K数据集和TF-Ranking构建一个简单的两塔排名模型。我们可以使用这个模型根据给定用户的预测用户评分对电影进行排名和推荐。
可解释的排名学习
透明度和可解释性是在排名系统中部署LTR模型的重要因素,排名系统可参与确定贷款资格评估、广告定位或指导医疗决策等流程的结果。在这种情况下,每个特征对最终排名的贡献应该是可检查和可理解的,以确保结果的透明度、问责制和公平性。实现这一目标的一种可能方法是使用广义加性模型(GAM)——本质上是”可解释的机器学习模型“,由各个特征的平滑函数线性组成。虽然GAM在回归和分类任务上得到了广泛的研究,但如何将它们应用到排名环境中还不太清楚。例如,GAM可以直接应用于对列表中的每个单独项目进行建模,但对项目交互和这些项目排序的上下文进行建模是一个更具挑战性的研究问题。为此,我们开发了神经排序GAM——广义加性模型对排序问题的扩展。与标准GAM不同,神经排序GAM可以考虑排序项目的特征和上下文特征(例如,查询或用户配置文件),导出可解释的紧凑模型。这确保了不仅每个项目级特征的贡献是可解释的,而且上下文特征的贡献也是可解释的。例如,在下图中,使用神经排名GAM可以清楚地看出在给定用户设备的背景下距离、价格和相关性如何影响酒店的最终排名。神经排名GAM现在可作为TF-Ranking的一部分。
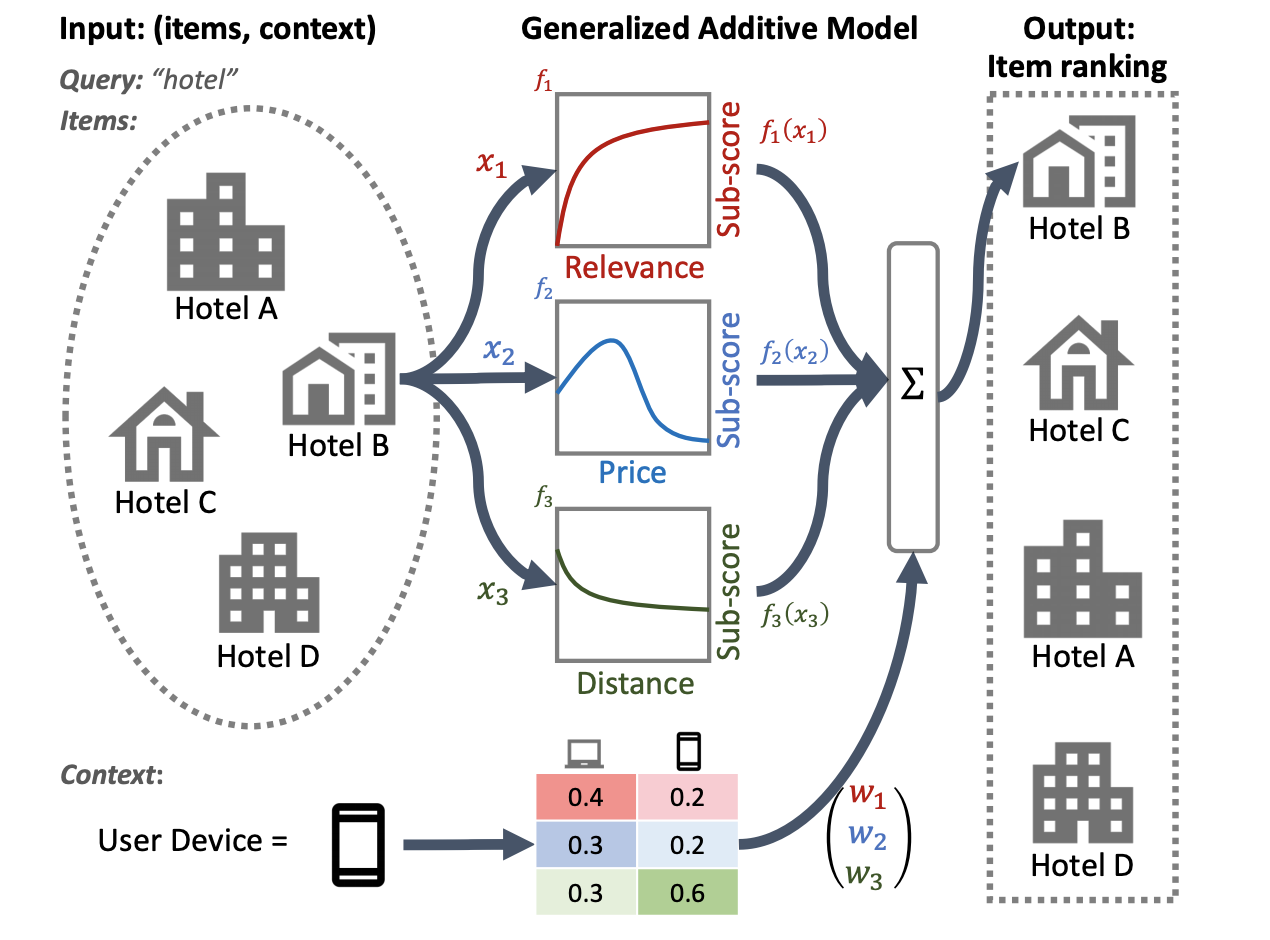
应用神经排序GAM进行本地搜索的示例。对于每个输入特征(例如价格、距离),子模型会生成可以检查的子分数,从而提供透明度。可以利用上下文特征(例如,用户设备类型)来导出子模型的重要性权重。
神经排序还是梯度提升?
虽然神经模型已在多个领域实现了最好的性能,但像LambdaMART这样的专门梯度增强决策树(GBDT)仍然是各种开放LTR数据集的基准。GBDT在开放数据集中的成功有几个原因。首先,由于神经模型的规模相对较小,因此很容易在这些数据集上过度拟合。其次,由于GBDT使用决策树划分其输入特征空间,因此它们自然对排名数据中数值范围的变化更具弹性,这些数据通常包含Zipfian或其他倾斜分布的特征。然而,GBDT在更现实的排名场景中确实有其局限性,这些场景通常结合了文本和数字特征。例如,GBDT不能直接应用于大型离散特征空间,例如原始文档文本。一般来说,它们的可扩展性也低于神经排序模型。
安装 & 导入包
安装并导入TF-Ranking库:
1 | pip install -q tensorflow-ranking |
1 | from typing import Dict, Tuple |
读取数据
通过创建评级数据集和电影数据集来准备训练模型。使用user_id作为查询输入特征,movie_title作为文档输入特征,user_rating作为标签来训练排名模型。构建词汇表,将所有用户ID和所有电影标题转换为嵌入层的整数索引:
1 | gcs_utils._is_gcs_disabled = True |
ds_train中生成的user_id和movie_title张量的形状为[32, None],其中第二个维度在大多数情况下为100,但列表中分组的项目少于100个时的批次除外。因此使用了研究不规则张量的模型。
1 | # 我们再看一下处理后的特征和标签。 |
定义模型
继承tf.keras.Model并实现了call方法,构建排名模型:
1 | class MovieLensRankingModel(tf.keras.Model): |
创建模型,然后使用排名tfr.keras.losses和tfr.keras.metrics进行编译,这是TF-Ranking包的核心。此示例使用特定于排名的softmax损失,这是一种列表损失,旨在提升排名列表中的所有相关项目,以更好的机会超越不相关的项目。与多级分类问题中的softmax损失(其中只有一类为正类,其余为负类)相反,TF-Ranking库支持查询列表中的多个相关文档和非二元相关标签。对于排名指标,此示例使用特定的标准化折扣累积增益(NDCG)和平均倒数排名(MRR),它们计算具有位置折扣的排名查询列表的用户效用。有关排名指标的更多详细信息,审查评估措施离线指标。
1 | # Create the ranking model, trained with a ranking loss and evaluated with |
电影推荐结果显示为:
1 | Top 5 recommendations for user 42: |
结论
TF Recommenders和TF Ranking比较。TF Recommenders更专注于推荐系统,他包括专门为推荐器设计的工具和程序,例如检索和排名任务。TF Ranking专注于对项目进行排名,并且可以在推荐系统之外使用,例如文档搜索和问答。TF Recommenders和TF Ranking都是独立的库,但它们在推荐系统的排名阶段有交叉。如果您在进行文档搜索、问答等,只需使用TF Ranking;如果你正在构建推荐系统并需要检索阶段,请选择TF Recommenders;在推荐器中你可以选择其中任何一个。