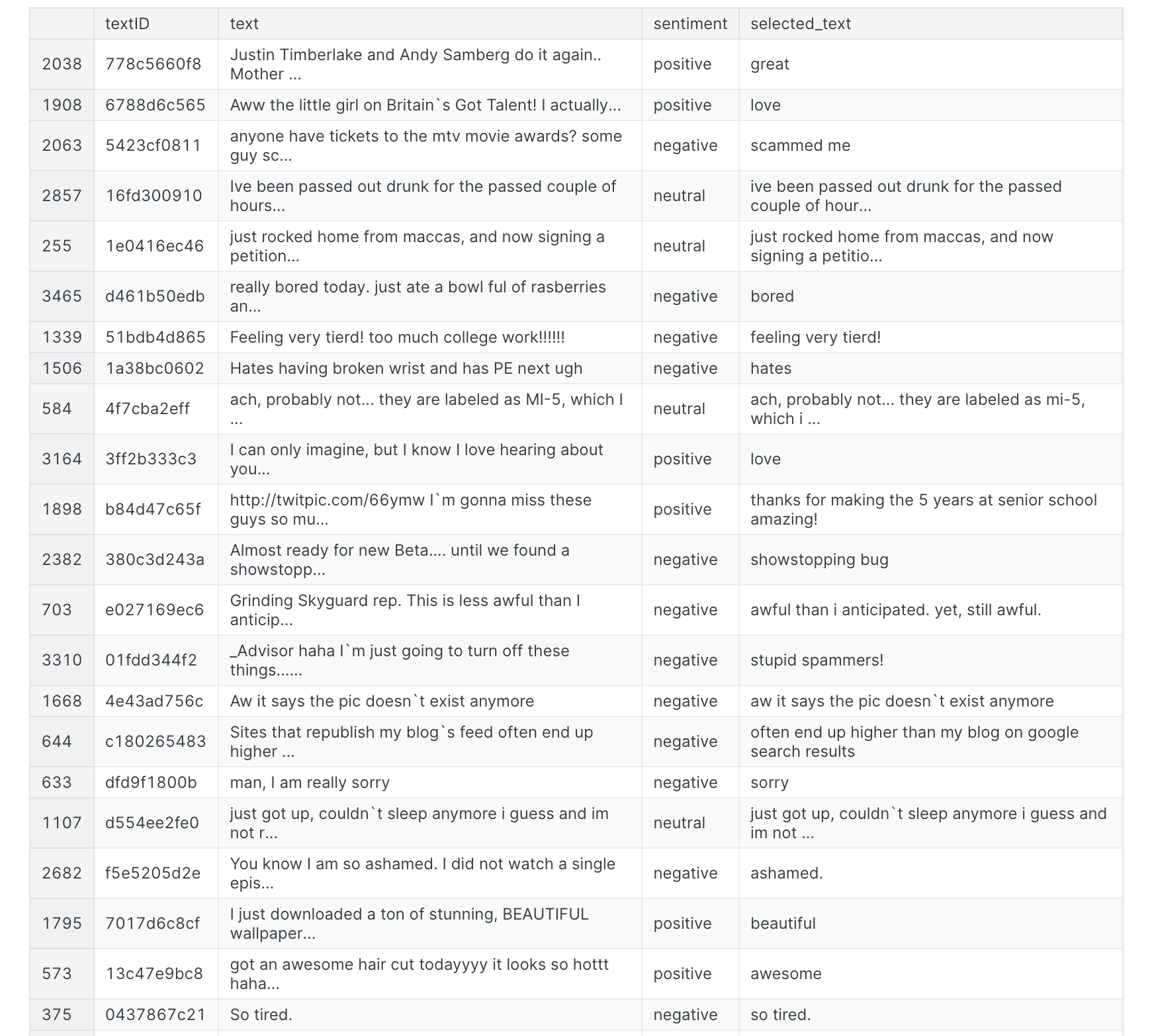
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
| jac = []; VER='v0'; DISPLAY=1
oof_start = np.zeros((input_ids.shape[0],MAX_LEN))
oof_end = np.zeros((input_ids.shape[0],MAX_LEN))
preds_start = np.zeros((input_ids_t.shape[0],MAX_LEN))
preds_end = np.zeros((input_ids_t.shape[0],MAX_LEN))
skf = StratifiedKFold(n_splits=5,shuffle=True,random_state=777)
for fold,(idxT,idxV) in enumerate(skf.split(input_ids,train.sentiment.values)):
print('#'*25)
print('### FOLD %i'%(fold+1))
print('#'*25)
K.clear_session()
model = build_model()
sv = tf.keras.callbacks.ModelCheckpoint(
'%s-roberta-%i.h5'%(VER,fold), monitor='val_loss', verbose=1, save_best_only=True,
save_weights_only=True, mode='auto', save_freq='epoch')
model.fit([input_ids[idxT,], attention_mask[idxT,], token_type_ids[idxT,]], [start_tokens[idxT,], end_tokens[idxT,]],
epochs=3, batch_size=32, verbose=DISPLAY, callbacks=[sv],
validation_data=([input_ids[idxV,],attention_mask[idxV,],token_type_ids[idxV,]],
[start_tokens[idxV,], end_tokens[idxV,]]))
print('Loading model...')
model.load_weights('%s-roberta-%i.h5'%(VER,fold))
print('Predicting OOF...')
oof_start[idxV,],oof_end[idxV,] = model.predict([input_ids[idxV,],attention_mask[idxV,],token_type_ids[idxV,]],verbose=DISPLAY)
print('Predicting Test...')
preds = model.predict([input_ids_t,attention_mask_t,token_type_ids_t],verbose=DISPLAY)
preds_start += preds[0]/skf.n_splits
preds_end += preds[1]/skf.n_splits
all = []
for k in idxV:
a = np.argmax(oof_start[k,])
b = np.argmax(oof_end[k,])
if a>b:
st = train.loc[k,'text']
else:
text1 = " "+" ".join(train.loc[k,'text'].split())
enc = tokenizer.encode(text1)
st = tokenizer.decode(enc.ids[a-1:b])
all.append(jaccard(st,train.loc[k,'selected_text']))
jac.append(np.mean(all))
print('>>>> FOLD %i Jaccard ='%(fold+1),np.mean(all))
print()
print('>>>> OVERALL 5Fold CV Jaccard =',np.mean(jac))
|