1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
| preprocess_fun = tf.keras.applications.densenet.preprocess_input
train_datagen = ImageDataGenerator(horizontal_flip=True,
width_shift_range=0.1,
height_shift_range=0.05,
rescale = 1./255,
validation_split = 0.2,
preprocessing_function=preprocess_fun
)
test_datagen = ImageDataGenerator(rescale = 1./255,
validation_split = 0.2,
preprocessing_function=preprocess_fun)
train_generator = train_datagen.flow_from_directory(directory = train_dir,
target_size = (IMG_HEIGHT ,IMG_WIDTH),
batch_size = BATCH_SIZE,
shuffle = True ,
color_mode = "rgb",
class_mode = "categorical",
subset = "training",
seed = 12
)
validation_generator = test_datagen.flow_from_directory(directory = train_dir,
target_size = (IMG_HEIGHT ,IMG_WIDTH),
batch_size = BATCH_SIZE,
shuffle = True ,
color_mode = "rgb",
class_mode = "categorical",
subset = "validation",
seed = 12
)
test_generator = test_datagen.flow_from_directory(directory = test_dir,
target_size = (IMG_HEIGHT ,IMG_WIDTH),
batch_size = BATCH_SIZE,
shuffle = False ,
color_mode = "rgb",
class_mode = "categorical",
seed = 12
)
def display_one_image(image, title, subplot, color):
plt.subplot(subplot)
plt.axis('off')
plt.imshow(image)
plt.title(title, fontsize=16)
def display_nine_images(images, titles, title_colors=None):
subplot = 331
plt.figure(figsize=(13,13))
for i in range(9):
color = 'black' if title_colors is None else title_colors[i]
display_one_image(images[i], titles[i], 331+i, color)
plt.tight_layout()
plt.subplots_adjust(wspace=0.1, hspace=0.1)
plt.show()
def image_title(label, prediction):
class_idx = np.argmax(label, axis=-1)
prediction_idx = np.argmax(prediction, axis=-1)
if class_idx == prediction_idx:
return f'{CLASS_LABELS[prediction_idx]} [correct]', 'black'
else:
return f'{CLASS_LABELS[prediction_idx]} [incorrect, should be {CLASS_LABELS[class_idx]}]', 'red'
def get_titles(images, labels, model):
predictions = model.predict(images)
titles, colors = [], []
for label, prediction in zip(classes, predictions):
title, color = image_title(label, prediction)
titles.append(title)
colors.append(color)
return titles, colors
img_datagen = ImageDataGenerator(rescale = 1./255)
img_generator = img_datagen.flow_from_directory(directory = train_dir,
target_size = (IMG_HEIGHT ,IMG_WIDTH),
batch_size = BATCH_SIZE,
shuffle = True ,
color_mode = "rgb",
class_mode = "categorical",
seed = 12
)
clear_output()
images, classes = next(img_generator)
class_idxs = np.argmax(classes, axis=-1)
labels = [CLASS_LABELS[idx] for idx in class_idxs]
display_nine_images(images, labels)
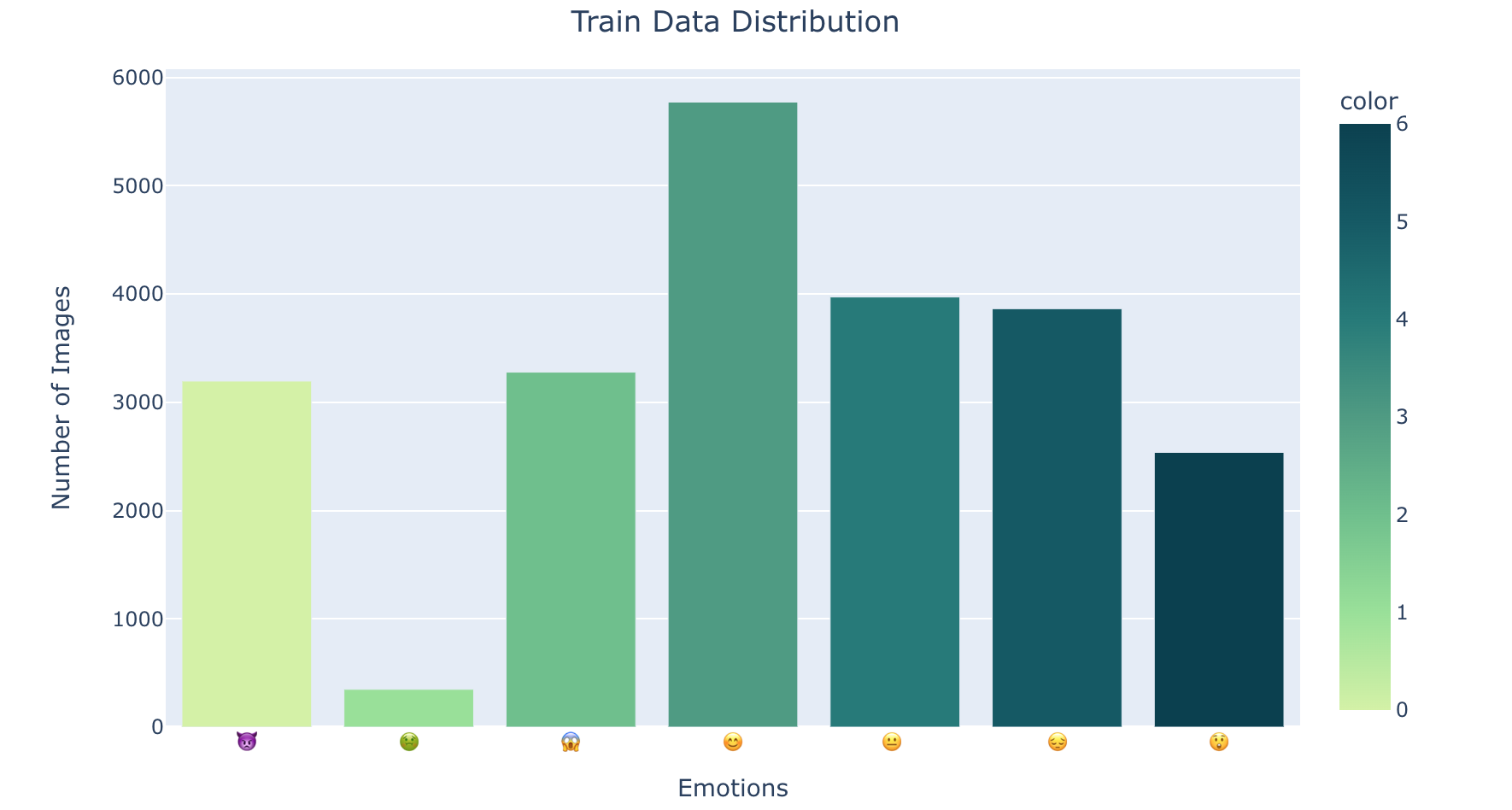
fig = px.bar(x = CLASS_LABELS_EMOJIS,
y = [list(train_generator.classes).count(i) for i in np.unique(train_generator.classes)] ,
color = np.unique(train_generator.classes) ,
color_continuous_scale="Emrld")
fig.update_xaxes(title="Emotions")
fig.update_yaxes(title = "Number of Images")
fig.update_layout(showlegend = True,
title = {
'text': 'Train Data Distribution ',
'y':0.95,
'x':0.5,
'xanchor': 'center',
'yanchor': 'top'})
fig.show()
|