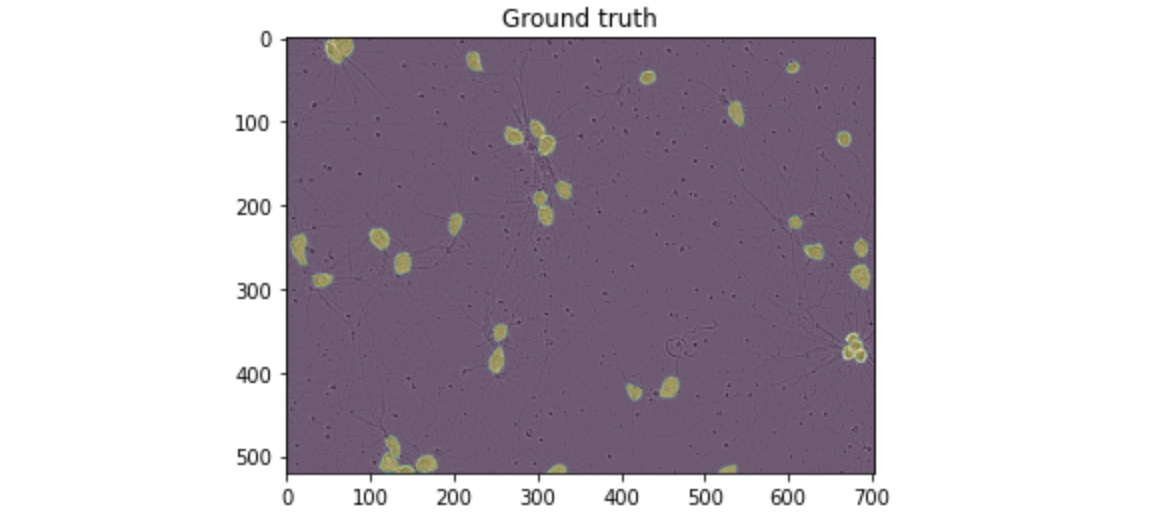
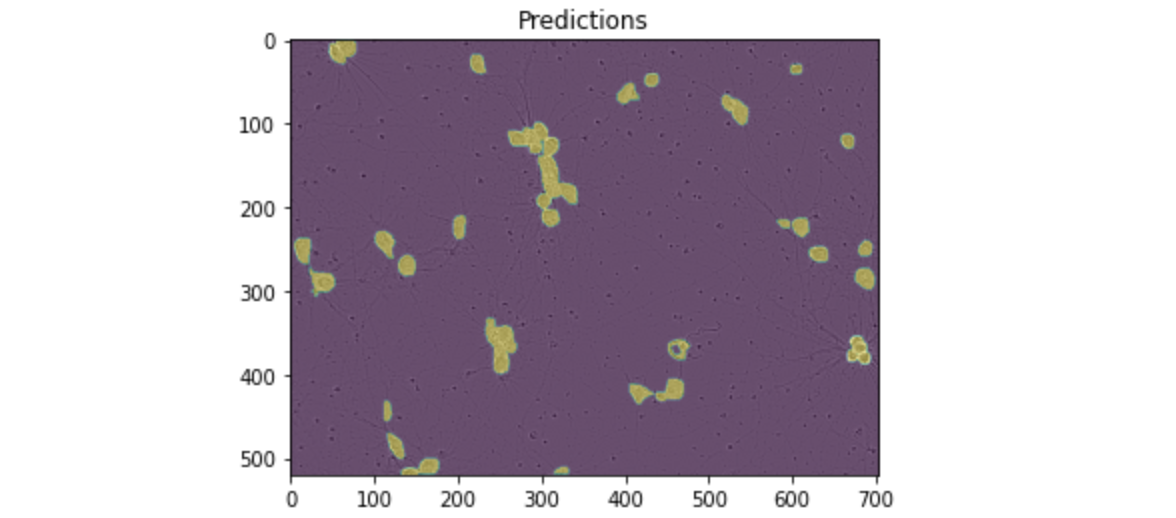
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
|
class Compose:
def __init__(self, transforms):
self.transforms = transforms
def __call__(self, image, target):
for t in self.transforms:
image, target = t(image, target)
return image, target
class VerticalFlip:
def __init__(self, prob):
self.prob = prob
def __call__(self, image, target):
if random.random() < self.prob:
height, width = image.shape[-2:]
image = image.flip(-2)
bbox = target["boxes"]
bbox[:, [1, 3]] = height - bbox[:, [3, 1]]
target["boxes"] = bbox
target["masks"] = target["masks"].flip(-2)
return image, target
class HorizontalFlip:
def __init__(self, prob):
self.prob = prob
def __call__(self, image, target):
if random.random() < self.prob:
height, width = image.shape[-2:]
image = image.flip(-1)
bbox = target["boxes"]
bbox[:, [0, 2]] = width - bbox[:, [2, 0]]
target["boxes"] = bbox
target["masks"] = target["masks"].flip(-1)
return image, target
class Normalize:
def __call__(self, image, target):
image = F.normalize(image, RESNET_MEAN, RESNET_STD)
return image, target
class ToTensor:
def __call__(self, image, target):
image = F.to_tensor(image)
return image, target
def get_transform(train):
transforms = [ToTensor()]
if NORMALIZE:
transforms.append(Normalize())
if train:
transforms.append(HorizontalFlip(0.5))
transforms.append(VerticalFlip(0.5))
return Compose(transforms)
def rle_decode(mask_rle, shape, color=1):
'''
mask_rle: run-length as string formated (start length)
shape: (height,width) of array to return
Returns numpy array, 1 - mask, 0 - background
'''
s = mask_rle.split()
starts, lengths = [np.asarray(x, dtype=int) for x in (s[0:][::2], s[1:][::2])]
starts -= 1
ends = starts + lengths
img = np.zeros(shape[0] * shape[1], dtype=np.float32)
for lo, hi in zip(starts, ends):
img[lo : hi] = color
return img.reshape(shape)
class CellDataset(Dataset):
def __init__(self, image_dir, df, transforms=None, resize=False):
self.transforms = transforms
self.image_dir = image_dir
self.df = df
self.should_resize = resize is not False
if self.should_resize:
self.height = int(HEIGHT * resize)
self.width = int(WIDTH * resize)
else:
self.height = HEIGHT
self.width = WIDTH
self.image_info = collections.defaultdict(dict)
temp_df = self.df.groupby('id')['annotation'].agg(lambda x: list(x)).reset_index()
for index, row in temp_df.iterrows():
self.image_info[index] = {
'image_id': row['id'],
'image_path': os.path.join(self.image_dir, row['id'] + '.png'),
'annotations': row["annotation"]
}
def get_box(self, a_mask):
''' Get the bounding box of a given mask '''
pos = np.where(a_mask)
xmin = np.min(pos[1])
xmax = np.max(pos[1])
ymin = np.min(pos[0])
ymax = np.max(pos[0])
return [xmin, ymin, xmax, ymax]
def __getitem__(self, idx):
''' Get the image and the target'''
img_path = self.image_info[idx]["image_path"]
img = Image.open(img_path).convert("RGB")
if self.should_resize:
img = img.resize((self.width, self.height), resample=Image.BILINEAR)
info = self.image_info[idx]
n_objects = len(info['annotations'])
masks = np.zeros((len(info['annotations']), self.height, self.width), dtype=np.uint8)
boxes = []
for i, annotation in enumerate(info['annotations']):
a_mask = rle_decode(annotation, (HEIGHT, WIDTH))
a_mask = Image.fromarray(a_mask)
if self.should_resize:
a_mask = a_mask.resize((self.width, self.height), resample=Image.BILINEAR)
a_mask = np.array(a_mask) > 0
masks[i, :, :] = a_mask
boxes.append(self.get_box(a_mask))
labels = [1 for _ in range(n_objects)]
boxes = torch.as_tensor(boxes, dtype=torch.float32)
labels = torch.as_tensor(labels, dtype=torch.int64)
masks = torch.as_tensor(masks, dtype=torch.uint8)
image_id = torch.tensor([idx])
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])
iscrowd = torch.zeros((n_objects,), dtype=torch.int64)
target = {
'boxes': boxes,
'labels': labels,
'masks': masks,
'image_id': image_id,
'area': area,
'iscrowd': iscrowd
}
if self.transforms is not None:
img, target = self.transforms(img, target)
return img, target
def __len__(self):
return len(self.image_info)
df_train = pd.read_csv(TRAIN_CSV, nrows=5000 if TEST else None)
ds_train = CellDataset(TRAIN_PATH, df_train, resize=False, transforms=get_transform(train=True))
dl_train = DataLoader(ds_train, batch_size=BATCH_SIZE, shuffle=True, num_workers=2, collate_fn=lambda x: tuple(zip(*x)))
|