机器学习模型 — 介绍
混合专家模型 Mixture of Experts (MoE)
混合专家模型(MoE)是一种机器学习技术,其中使用多个专家网络(学习者)将问题空间划分为同质区域。混合专家模型(MoE)的一个显著优势是它们能够在远少于稠密模型所需的计算资源下进行有效的预训练。这意味着在相同的计算预算条件下,可以显著扩大模型或数据集的规模。特别是在预训练阶段,与稠密模型相比,混合专家模型通常能够更快地达到相同的质量水平。
在Transformer模型的背景下,MoE主要由两个部分组成:
- 稀疏
MoE层:代替了传统的密集前馈网络(FFN)层。MoE层包含若干「专家」(如8个),每个专家都是一个独立的神经网络。这些专家通常是FFN,但它们也可以是更复杂的网络,甚至可以是MoE本身,形成一个层级结构的MoE。 - 一个门控网络/路由器:用于决定哪些
Token分配给哪个专家。例如,在下图中,「More」这个Token被分配给第二个专家,而「Parameters」这个Token被分配给第一个网络。值得注意的是,一个Token可以同时被分配给多个专家。如何高效地将Token分配给合适的专家,是使用MoE技术时需要考虑的关键问题之一。这个路由器由一系列可学习的参数构成,它与模型的其他部分一起进行预训练。![]()
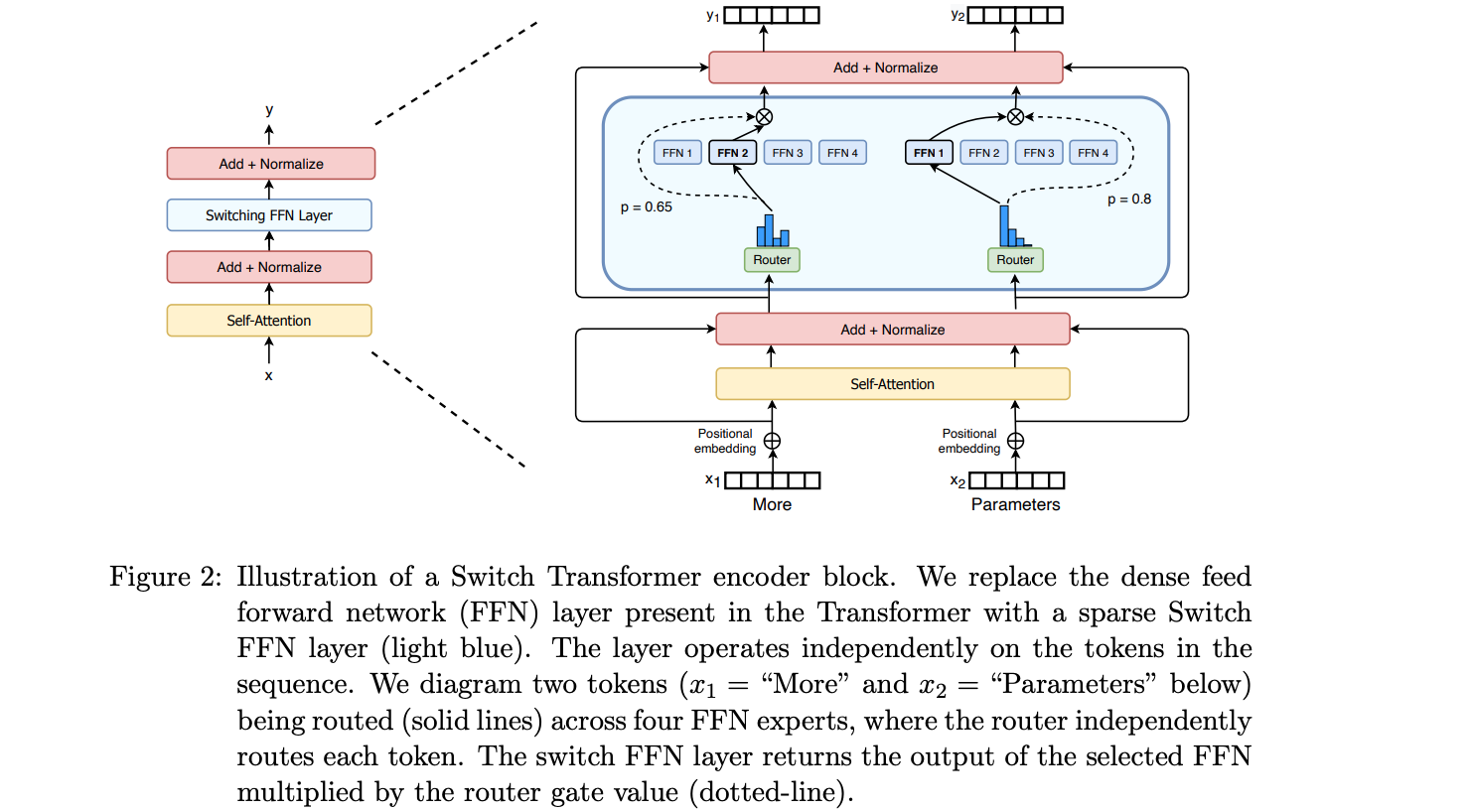
MoE(混合专家模型)的设计思路是:在Transformer模型中,将每一个FFN(前馈网络)层替换为MoE层,由一个门控网络和若干「专家」组成。
尽管混合专家模型(MoE)提供了若干显著优势,例如更高效的预训练和与稠密模型相比更快的推理速度,但它们也伴随着一些挑战:
- 训练挑战: 虽然
MoE能够实现更高效的计算预训练,但它们在微调阶段往往面临泛化能力不足的问题,长期以来易于引发过拟合现象。 - 推理挑战:
MoE模型虽然可能拥有大量参数,但在推理过程中只使用其中的一部分,这使得它们的推理速度快于具有相同数量参数的稠密模型。然而,这种模型需要将所有参数加载到内存中,因此对内存的需求非常高。以Mixtral 8x7B这样的MoE为例,需要足够的VRAM来容纳一个47B参数的稠密模型。之所以是47B而不是8 x 7B = 56B,是因为在MoE模型中,只有FFN层被视为独立的专家,而模型的其他参数是共享的。此外,假设每个令牌只使用两个专家,那么推理速度(以FLOPs计算) 类似于使用12B模型 (而不是14B模型),因为虽然它进行了2x7B的矩阵乘法计算,但某些层是共享的。