import numpy as np # linear algebra import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv) from tqdm import tqdm from sklearn.model_selection import train_test_split import tensorflow as tf from keras.models import Sequential from keras.layers.recurrent import LSTM, GRU,SimpleRNN from keras.layers.core import Dense, Activation, Dropout from keras.layers.embeddings import Embedding from keras.layers.normalization import BatchNormalization from keras.utils import np_utils from sklearn import preprocessing, decomposition, model_selection, metrics, pipeline from keras.layers import GlobalMaxPooling1D, Conv1D, MaxPooling1D, Flatten, Bidirectional, SpatialDropout1D from keras.preprocessing import sequence, text from keras.callbacks import EarlyStopping
import matplotlib.pyplot as plt import seaborn as sns from plotly import graph_objs as go import plotly.express as px import plotly.figure_factory as ff
# Detect hardware, return appropriate distribution strategy try: # TPU detection. No parameters necessary if TPU_NAME environment variable is # set: this is always the case on Kaggle. tpu = tf.distribute.cluster_resolver.TPUClusterResolver() print('Running on TPU ', tpu.master()) except ValueError: tpu = None
if tpu: tf.config.experimental_connect_to_cluster(tpu) tf.tpu.experimental.initialize_tpu_system(tpu) strategy = tf.distribute.experimental.TPUStrategy(tpu) else: # Default distribution strategy in Tensorflow. Works on CPU and single GPU. strategy = tf.distribute.get_strategy()
#zero pad the sequences xtrain_pad = sequence.pad_sequences(xtrain_seq, maxlen=max_len) xvalid_pad = sequence.pad_sequences(xvalid_seq, maxlen=max_len)
word_index = token.word_index
with strategy.scope(): # A simpleRNN without any pretrained embeddings and one dense layer model = Sequential() model.add(Embedding(len(word_index) + 1, 300, input_length=max_len)) model.add(SimpleRNN(100)) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) model.summary()
embeddings_index = {} f = open('/kaggle/input/glove840b300dtxt/glove.840B.300d.txt','r',encoding='utf-8') for line in tqdm(f): values = line.split(' ') word = values[0] coefs = np.asarray([float(val) for val in values[1:]]) embeddings_index[word] = coefs f.close()
print('Found %s word vectors.' % len(embeddings_index))
# create an embedding matrix for the words we have in the dataset embedding_matrix = np.zeros((len(word_index) + 1, 300)) for word, i in tqdm(word_index.items()): embedding_vector = embeddings_index.get(word) if embedding_vector isnotNone: embedding_matrix[i] = embedding_vector
with strategy.scope(): # A simple LSTM with glove embeddings and one dense layer model = Sequential() model.add(Embedding(len(word_index) + 1,300,weights=[embedding_matrix],input_length=max_len,trainable=False))
with strategy.scope(): # GRU with glove embeddings and two dense layers model = Sequential() model.add(Embedding(len(word_index) + 1, 300, weights=[embedding_matrix], input_length=max_len, trainable=False)) model.add(SpatialDropout1D(0.3)) model.add(GRU(300)) model.add(Dense(1, activation='sigmoid'))
# 创建Bi-Directional RNN with strategy.scope(): # A simple bidirectional LSTM with glove embeddings and one dense layer model = Sequential() model.add(Embedding(len(word_index) + 1, 300, weights=[embedding_matrix], input_length=max_len, trainable=False)) model.add(Bidirectional(LSTM(300, dropout=0.3, recurrent_dropout=0.3)))
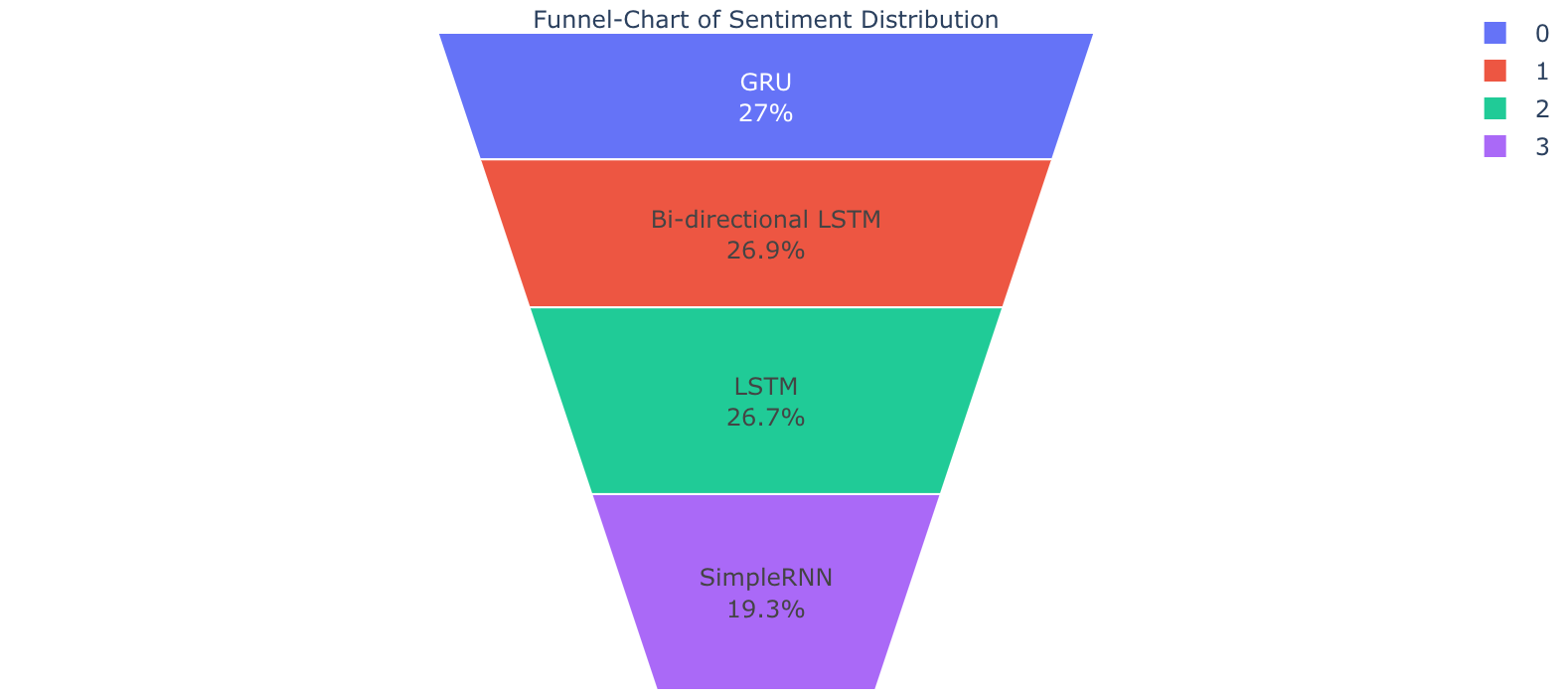
# Visualization of Results obtained from various Deep learning models results = pd.DataFrame(scores_model).sort_values(by='AUC_Score',ascending=False) results.style.background_gradient(cmap='Blues')
fig = go.Figure(go.Funnelarea( text =results.Model,values = results.AUC_Score,title = {"position": "top center", "text": "Funnel-Chart of Sentiment Distribution"} )) fig.show()
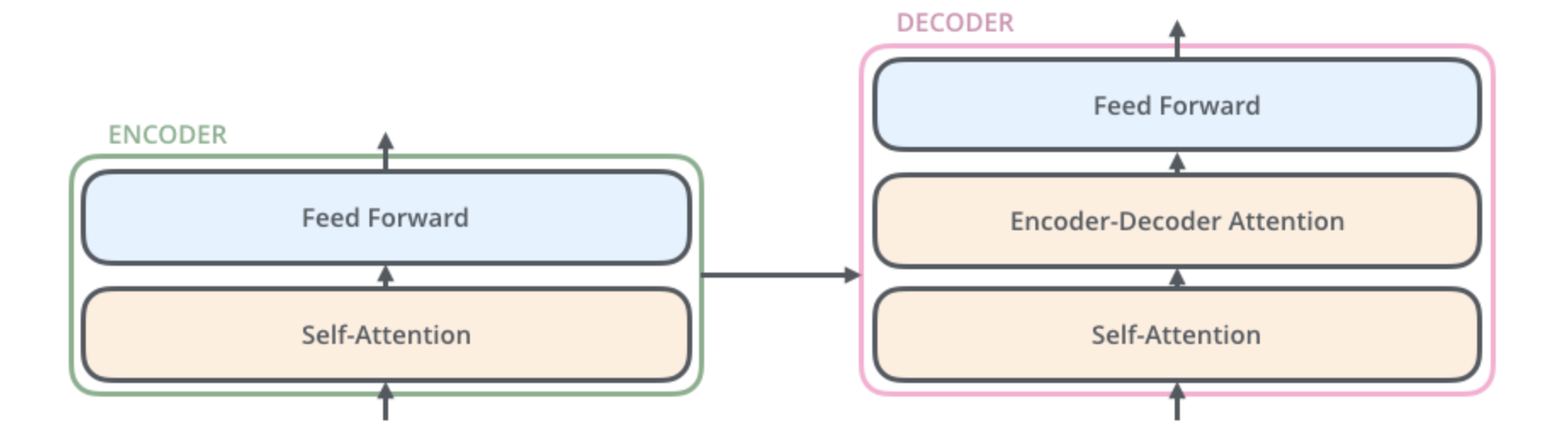
最后我们到达了学习曲线的终点,即将开始学习彻底改变NLP的技术,这也是最先进的NLP技术的原因。Google在论文《Attention is all you need》中介绍了Transformer。Transformer是由一个编码器、解码器组件以及他们之间的连接构成。编码组件有一堆编码器组成,解码器组件也是由相同数量的解码器组成。编码器分为两层:自注意力层、前馈神经网络。编码器与编码器的结构相同,但彼此不共享权重。编码器的输入首先流入自注意力层,该层帮助编码器在对特定单词进行编码时查看输入句子中的其他单词,自注意力层的输出被馈送到前馈神经网络,完全相同的前馈网络是相互独立的。解码器分为三层:自注意力层、Encoder-Decoder注意力层、前馈神经网络。Encoder-Decoder注意力层的作用是帮助解码器专注于输入的相关部分(类似于seq2seq模型中注意力的作用)。
import numpy as np import torch import torch.nn as nn import torch.nn.functional as F import math, copy, time from torch.autograd import Variable import matplotlib.pyplot as plt import seaborn seaborn.set_context(context="talk")
classEncoderDecoder(nn.Module): """ A standard Encoder-Decoder architecture. Base for this and many other models. """ def__init__(self, encoder, decoder, src_embed, tgt_embed, generator): super(EncoderDecoder, self).__init__() self.encoder = encoder self.decoder = decoder self.src_embed = src_embed self.tgt_embed = tgt_embed self.generator = generator defforward(self, src, tgt, src_mask, tgt_mask): "Take in and process masked src and target sequences." return self.decode(self.encode(src, src_mask), src_mask, tgt, tgt_mask) defencode(self, src, src_mask): return self.encoder(self.src_embed(src), src_mask) defdecode(self, memory, src_mask, tgt, tgt_mask): return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
classGenerator(nn.Module): "Define standard linear + softmax generation step." def__init__(self, d_model, vocab): super(Generator, self).__init__() self.proj = nn.Linear(d_model, vocab)
defclones(module, N): "Produce N identical layers." return nn.ModuleList([copy.deepcopy(module) for _ inrange(N)])
classEncoder(nn.Module): "Core encoder is a stack of N layers" def__init__(self, layer, N): super(Encoder, self).__init__() self.layers = clones(layer, N) self.norm = LayerNorm(layer.size) defforward(self, x, mask): "Pass the input (and mask) through each layer in turn." for layer in self.layers: x = layer(x, mask) return self.norm(x)
# 两个子层周围 采用残差连接, 然后进行层归一化。 classLayerNorm(nn.Module): "Construct a layernorm module (See citation for details)." def__init__(self, features, eps=1e-6): super(LayerNorm, self).__init__() self.a_2 = nn.Parameter(torch.ones(features)) self.b_2 = nn.Parameter(torch.zeros(features)) self.eps = eps
# 为了促进这些残差连接,模型中的所有子层以及嵌入层都会产生维度的输出。 classSublayerConnection(nn.Module): """ A residual connection followed by a layer norm. Note for code simplicity the norm is first as opposed to last. """ def__init__(self, size, dropout): super(SublayerConnection, self).__init__() self.norm = LayerNorm(size) self.dropout = nn.Dropout(dropout)
defforward(self, x, sublayer): "Apply residual connection to any sublayer with the same size." return x + self.dropout(sublayer(self.norm(x)))
# 每层有两个子层。第一个是多头自注意力机制,第二个是全连接前馈网络。 classEncoderLayer(nn.Module): "Encoder is made up of self-attn and feed forward (defined below)" def__init__(self, size, self_attn, feed_forward, dropout): super(EncoderLayer, self).__init__() self.self_attn = self_attn self.feed_forward = feed_forward self.sublayer = clones(SublayerConnection(size, dropout), 2) self.size = size
defmake_model(src_vocab, tgt_vocab, N=6, d_model=512, d_ff=2048, h=8, dropout=0.1): "Helper: Construct a model from hyperparameters." c = copy.deepcopy attn = MultiHeadedAttention(h, d_model) ff = PositionwiseFeedForward(d_model, d_ff, dropout) position = PositionalEncoding(d_model, dropout) model = EncoderDecoder( Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N), Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), N), nn.Sequential(Embeddings(d_model, src_vocab), c(position)), nn.Sequential(Embeddings(d_model, tgt_vocab), c(position)), Generator(d_model, tgt_vocab)) # This was important from their code. # Initialize parameters with Glorot / fan_avg. for p in model.parameters(): if p.dim() > 1: nn.init.xavier_uniform(p) return model
# Small example model. tmp_model = make_model(10, 10, 2)
# Loading Dependencies import os import transformers import tensorflow as tf from tensorflow.keras.layers import Dense, Input from tensorflow.keras.optimizers import Adam from tensorflow.keras.models import Model from tensorflow.keras.callbacks import ModelCheckpoint from kaggle_datasets import KaggleDatasets from tokenizers import BertWordPieceTokenizer
# LOADING THE DATA train1 = pd.read_csv("/kaggle/input/jigsaw-multilingual-toxic-comment-classification/jigsaw-toxic-comment-train.csv") valid = pd.read_csv('/kaggle/input/jigsaw-multilingual-toxic-comment-classification/validation.csv') test = pd.read_csv('/kaggle/input/jigsaw-multilingual-toxic-comment-classification/test.csv') sub = pd.read_csv('/kaggle/input/jigsaw-multilingual-toxic-comment-classification/sample_submission.csv')
deffast_encode(texts, tokenizer, chunk_size=256, maxlen=512): """ Encoder for encoding the text into sequence of integers for BERT Input """ tokenizer.enable_truncation(max_length=maxlen) tokenizer.enable_padding(max_length=maxlen) all_ids = [] for i in tqdm(range(0, len(texts), chunk_size)): text_chunk = texts[i:i+chunk_size].tolist() encs = tokenizer.encode_batch(text_chunk) all_ids.extend([enc.ids for enc in encs]) return np.array(all_ids)
#IMP DATA FOR CONFIG AUTO = tf.data.experimental.AUTOTUNE # Configuration EPOCHS = 3 BATCH_SIZE = 16 * strategy.num_replicas_in_sync MAX_LEN = 192
# Tokenization # First load the real tokenizer tokenizer = transformers.DistilBertTokenizer.from_pretrained('distilbert-base-multilingual-cased') # Save the loaded tokenizer locally tokenizer.save_pretrained('.') # Reload it with the huggingface tokenizers library fast_tokenizer = BertWordPieceTokenizer('vocab.txt', lowercase=False) fast_tokenizer
defbuild_model(transformer, max_len=512): """ function for training the BERT model """ input_word_ids = Input(shape=(max_len,), dtype=tf.int32, name="input_word_ids") sequence_output = transformer(input_word_ids)[0] cls_token = sequence_output[:, 0, :] out = Dense(1, activation='sigmoid')(cls_token) model = Model(inputs=input_word_ids, outputs=out) model.compile(Adam(lr=1e-5), loss='binary_crossentropy', metrics=['accuracy']) return model
# 开始训练 with strategy.scope(): transformer_layer = ( transformers.TFDistilBertModel .from_pretrained('distilbert-base-multilingual-cased') ) model = build_model(transformer_layer, max_len=MAX_LEN) model.summary()