NLP(初级)
介绍
过去几年深度学习取得显着进步的一个领域是自然语言处理(NLP)。计算机现在可以生成文本、自动从一种语言翻译成另一种语言、分析评论、标记句子中的单词等等。也许NLP最广泛的实际应用是分类——将文档自动分类到某个类别。例如,这可以用于:
- 情绪分析(例如,人们对您的产品有正面还是负面评价)。
- 作者识别(最有可能是哪个作者写了一些文档)。
- 法律发现(哪些文件属于审判范围)。
- 按主题组织文档。
- 对电子邮件进行分类。
- …以及更多!
分类模型还可以用于解决起初不合适的问题。在此,我们的任务是比较两个单词或短语,并根据它们是否相似以及它们所使用的专利类别对它们进行评分。得分为
1时,认为这两个输入具有相同含义,0表示含义完全不同。例如,减少和消除过程的得分为0.5,这意味着它们有些相似,但不完全相同。对于以下文本…:“TEXT1:减少;TEXT2:消除过程”…选择意义相似的类别:“不同;相似;相同”。我们如何通过将专利短语匹配问题视为分类任务,并以上面所示的方式来解决它。NLP数据集中的文档通常采用以下两种主要形式之一: - 较大的文档:每个文档一个文本文件,通常按类别组织到一个文件夹中。
- 较小的文档:CSV 文件中每行一个文档(或文档对,可选地包含元数据)。
创建一个DataFrame,它是一个命名列的表,有点像数据库表。要查看DataFrame的第一行和最后一行以及行数,只需输入其名称:
1 | import pandas as pd |
结果输出为:
1 | id anchor target context |
DataFrame最有用的功能之一是describe()方法。我们可以看到,在36473行中,有733个唯一的anchor、106个上下文和近30000个目标。有些anchors非常常见,例如“组件复合涂层”就出现了152次。我建议可以将模型的输入表示为“TEXT1:减少;TEXT2:消除过程”之类的内容。我们还需要为其添加上下文。在Pandas中,我们只使用+来连接,如下所示:
1 | df['input'] = 'TEXT1: ' + df.context + '; TEXT2: ' + df.target + '; ANC1: ' + df.anchor |
我们可以使用常规的Python“点分”表示法来引用列,或者像字典一样访问它。要获取前几行,请使用head():
1 | df.input.head() |
结果输出为:
1 | 0 TEXT1: A47; TEXT2: abatement of pollution; ANC... |
Tokenization
当然,Transformers使用Dataset对象来存储以上数据集!我们可以像这样创建一个:
1 | from datasets import Dataset,DatasetDict |
但我们不能将文本直接传递到模型中。深度学习模型需要数字作为输入,所以我们需要做两件事:
- 标记化:将每个文本分割成单词(或者实际上,正如我们将看到的,分割成标记)。
- 数值化:将每个单词(或标记)转换为数字。
有关如何完成此操作的详细信息实际上取决于我们使用的特定模型。所以首先我们需要选择一个模型。有数千种可用模型,但几乎所有NLP问题的合理起点都是使用此模型(完成探索后,将“小”替换为“大”,以获得较慢但更准确的模型):
1 | model_nm = 'microsoft/deberta-v3-small' |
AutoTokenizer将创建适合给定模型的分词器。词汇表中添加了特殊标记,确保相关的词嵌入到微调或训练。下面是一个示例,说明分词器如何将文本拆分为“标记”(类似于单词,但可以是子单词片段,如下所示):
1 | tokz.tokenize("G'day folks, I'm Jeremy from fast.ai!") |
不常见的单词将被分割成碎片。新单词的开头由_表示。这是一个简单的函数,可以标记我们的输入:
1 | def tok_func(x): return tokz(x["input"]) |
要在数据集中的每一行并行运行此操作,请使用map。这会向我们的数据集添加一个名为input_ids的新item。
1 | row = tok_ds[0] |
那么,这些ID是什么?它们来自哪里?秘密在于标记生成器中有一个名为vocab的列表,其中包含每个的标记字符串的唯一整数。我们可以像这样查找它们,例如查找单词“of”的标记:265。
查看上面的输入ID,我们确实看到265。最后,我们需要准备标签。Transformers始终假设标签都有列名称标签,但在我们的数据集中,它当前是得分。因此,我们需要将其重命名:
1 | tok_ds = tok_ds.rename_columns({'score':'labels'}) |
现在我们已经准备好了令牌和标签,我们需要创建验证集。
测试和验证集
您可能已经注意到我们的目录包含另一个文件。
1 | eval_df = pd.read_csv(path/'test.csv') |
输出结果:
1 | id anchor target context |
这是测试集。机器学习中最重要的想法可能是拥有单独的训练、验证和测试数据集。
验证集
为了解释动机,让我们从简单的开始,想象我们正在尝试拟合一个模型,关系是x的二次方:
1 | def f(x): return -3*x**2 + 2*x + 20 |
matplotlib没有提供可视化函数的方法,因此我们将自己编写一些代码来执行此操作:
1 | import numpy as np, matplotlib.pyplot as plt |
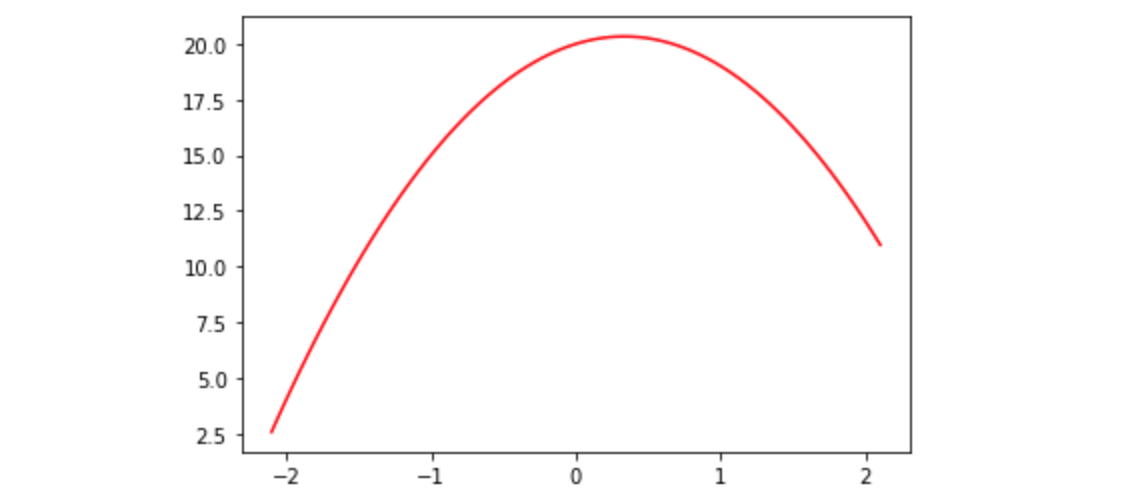
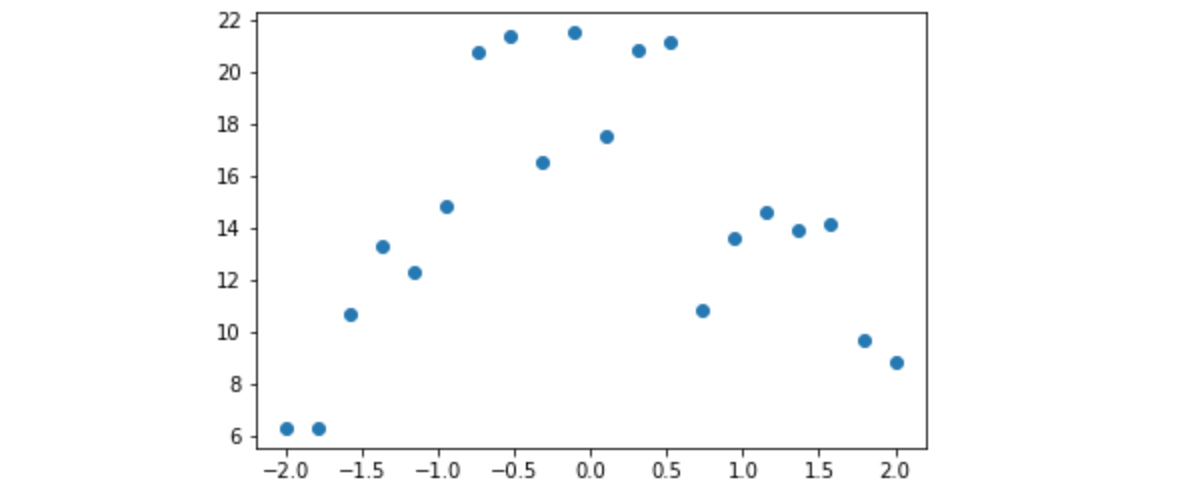
也许我们在某个事件之前和之后测量了物体离地面的高度。测量结果会存在一些随机误差。我们可以使用numpy的随机数生成器来模拟它。
1 | from numpy.random import normal,seed,uniform |
这是一个函数add_noise,它向数组添加一些随机变化。让我们用它来模拟一些随时间均匀分布的测量值。
现在让我们看看如果我们对这些预测拟合不足或过度拟合会发生什么。为此,我们将创建一个拟合某个次数多项式的函数(例如,直线为1次,二次为2次,三次为3次,等等)。
1 | from sklearn.linear_model import LinearRegression |
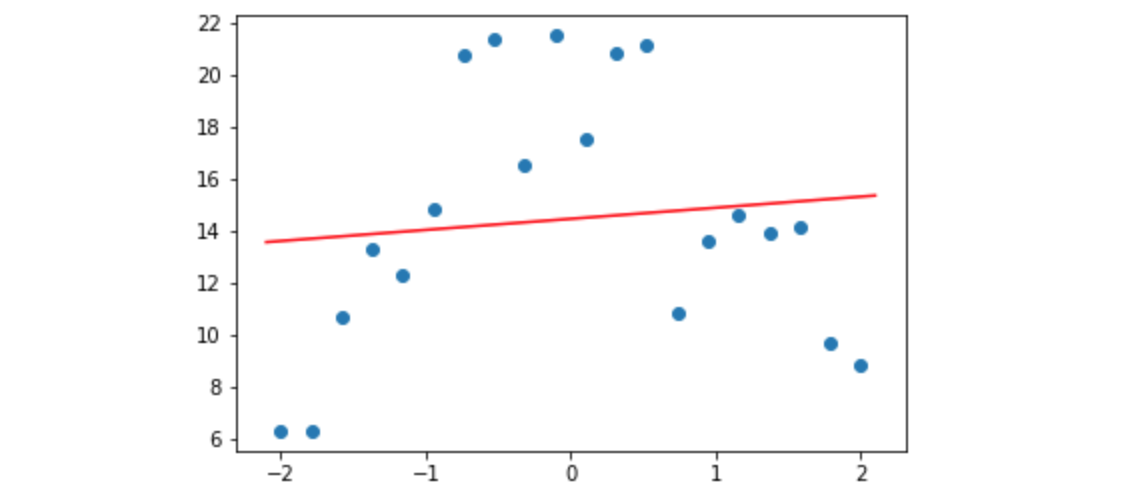
正如您所看到的,红线(我们拟合的线)上的点根本不是很接近。这是欠拟合的——我们的函数没有足够的细节来匹配我们的数据。如果我们将10次多项式拟合到我们的测量结果会发生什么?
1 | plot_poly(10) |
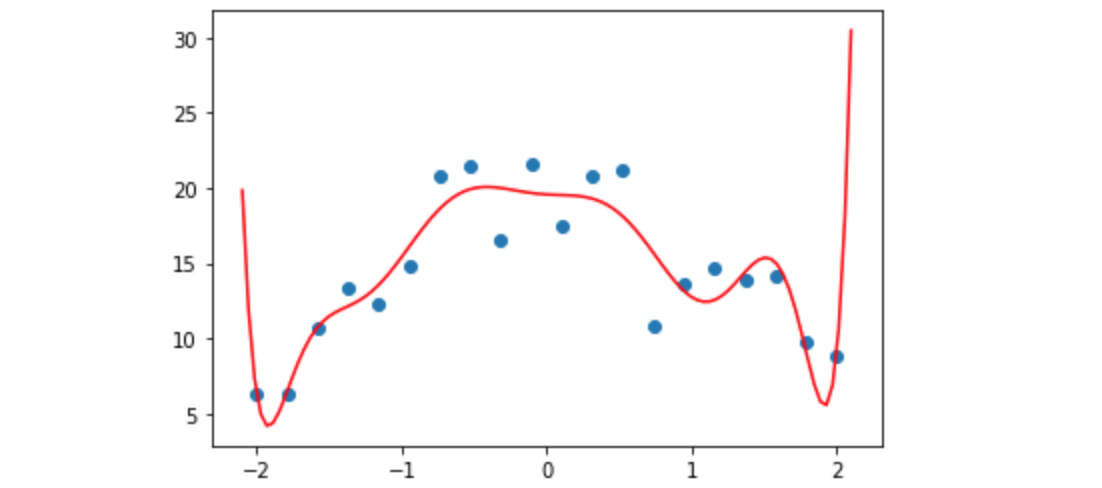
好吧,现在它更适合我们的数据,但它看起来并不能很好地预测我们测量以外的点——尤其是那些较早或较晚时间段的点。这是过度拟合——有太多细节使得模型符合我们的观点,但不符合我们真正关心的基本过程。让我们尝试使用2次多项式,并将其与我们的“真实”函数(蓝色)进行比较:
1 | plot_poly(2) |
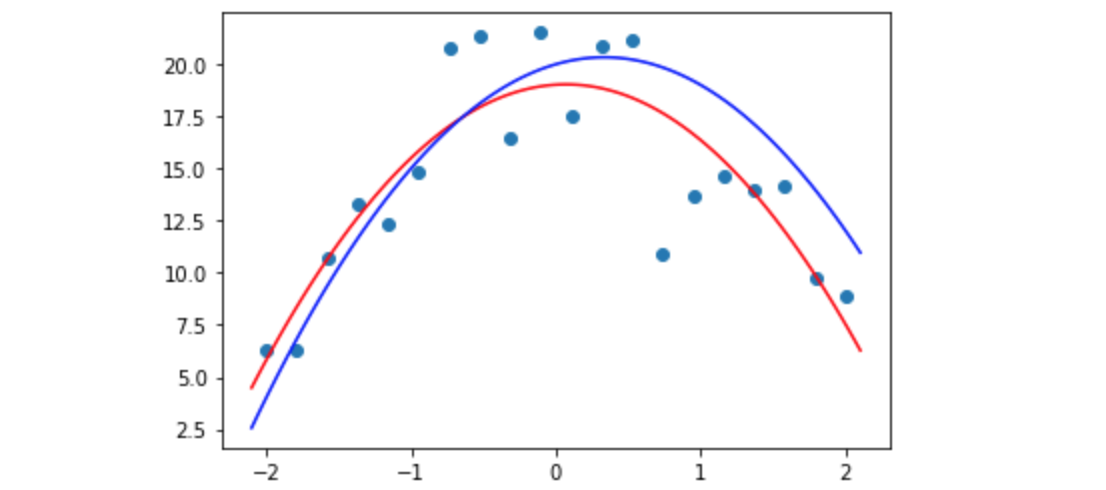
那么,我们如何识别我们的模型是欠拟合、过度拟合还是“恰到好处”呢?我们使用验证集。 这是我们在训练中“保留”的一组数据——根本不让我们的模型看到它。如果您使用fastai库,如果您没有验证集,它会自动为您创建一个验证集,并且始终使用验证集报告指标(模型准确性的测量)。验证集仅用于查看我们的性能表现。 它永远不会用作训练模型的输入。Transformers使用 DatasetDict来保存训练集和验证集。要创建一个包含25%的验证集数据和75%的训练集数据的数据集,请使用train_test_split:
1 | dds = tok_ds.train_test_split(0.25, seed=42) |
正如你在上面看到的,这里的验证集称为测试而不是验证,所以要小心!在实践中,像我们在这里使用的随机分割可能不是一个好主意:“导致开发结果与生产结果之间脱节的最可能的罪魁祸首之一是验证集选择不当(或者更糟糕的是,根本没有验证集)。根据数据的性质,选择验证集是最重要的一步。虽然sklearn提供了train_test_split方法,但该方法采用数据的随机子集,这对于许多现实问题来说是一个糟糕的选择。”
测试集
“测试集”——它是用来做什么的?测试集是训练中保留的另一个数据集。但它也被排除在报告指标之外!仅在完成整个训练过程(包括尝试不同的模型、训练方法、数据处理等)后才会检查模型在测试集上的准确性。您会发现,当您尝试所有这些不同的事情时,为了了解它们对验证集指标的影响,您可能会意外地发现一些完全巧合地改善验证集指标的事情,但在实践中并没有更好。如果有足够的时间和实验,您会发现这些巧合的改进。意味着您过度拟合了验证集!这就是我们保留测试集的原因。我们将使用eval作为测试集的名称,以避免与上面创建的测试数据集混淆。
1 | eval_df['input'] = 'TEXT1: ' + eval_df.context + '; TEXT2: ' + eval_df.target + '; ANC1: ' + eval_df.anchor |
指标和相关性
当我们训练模型时,我们会对最大化或最小化一个或多个指标感兴趣。希望这些测量值能够代表我们的模型。从本质上讲,当前大多数人工智能方法的作用是优化指标。优化指标的做法对于人工智能来说并不新鲜,也不是独一无二的,但人工智能在这方面特别有效。理解这一点很重要,因为人工智能会加剧优化指标的任何风险。虽然指标在适当的地方可能有用,但如果不加思考地应用它们就会产生危害。一些最可怕的算法失控实例都是由于过度强调指标造成的。让我们看一些使用加州住房数据集的示例,其中显示“加州各地区的房屋价值中位数,以数十万美元表示”。该数据集由优秀的 scikit-learn库提供,该库是深度学习之外使用最广泛的机器学习库。
1 | from sklearn.datasets import fetch_california_housing |
结果输出为:

我们可以通过调用np.corrcoef来查看该数据集中每个列组合的所有相关系数:
1 | np.set_printoptions(precision=2, suppress=True) |
我们将创建这个小函数,以便在给定一对变量的情况下返回我们需要的单个数字:
1 | def corr(x,y): return np.corrcoef(x,y)[0][1] |
现在我们将使用这个函数看一些相关性的例子(函数的细节并不重要):
1 | def show_corr(df, a, b): |
我们来看看收入和房价的相关性:
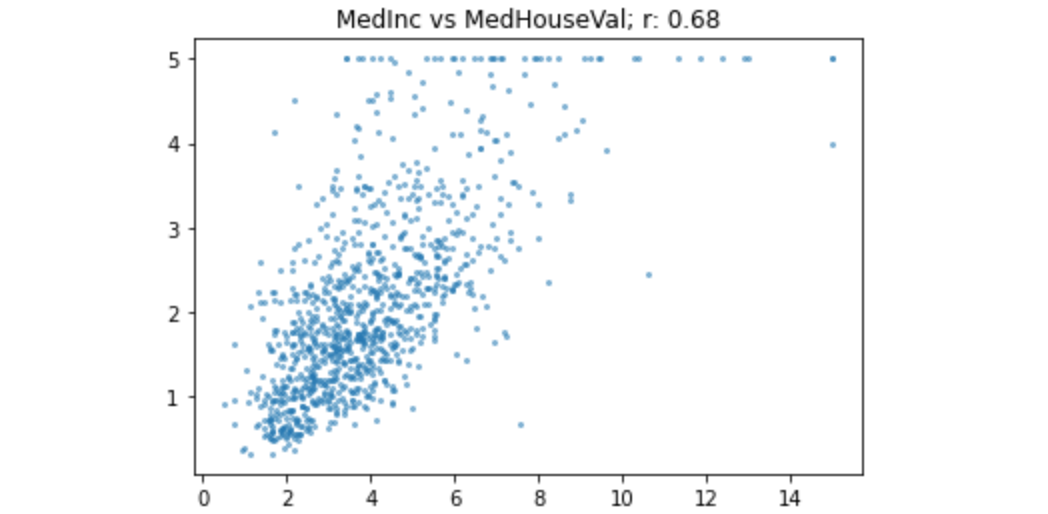
这就是0.68的相关性。这是一种相当密切的关系,但仍然存在很多差异。(顺便说一句,这也说明了为什么查看数据如此重要-我们可以在该图中清楚地看到,500,000美元以上的房价似乎已被截断至该最大值)。
1 | show_corr(housing, 'MedInc', 'AveRooms') |
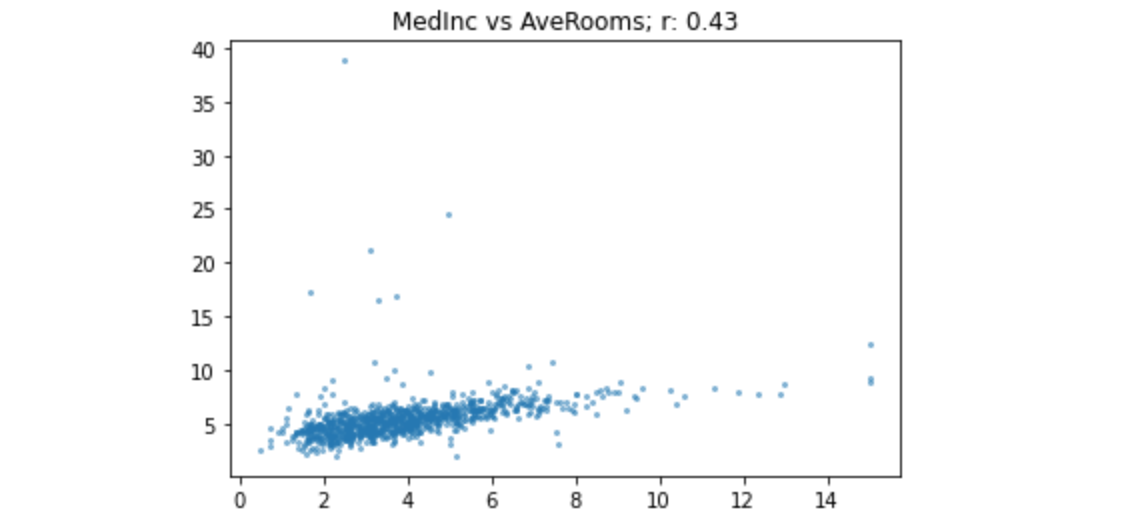
该关系看起来与前面的示例类似,但r远低于收入与估值情况。这是为什么?原因是存在很多异常值——AveRooms的值远远超出平均值。r对异常值非常敏感。如果数据中存在异常值,那么它们之间的关系将主导指标。在这种情况下,房间数量非常多的房屋往往不会那么有价值,因此r会比原本的情况有所减少。让我们删除异常值并重试:
1 | subset = housing[housing.AveRooms<15] |
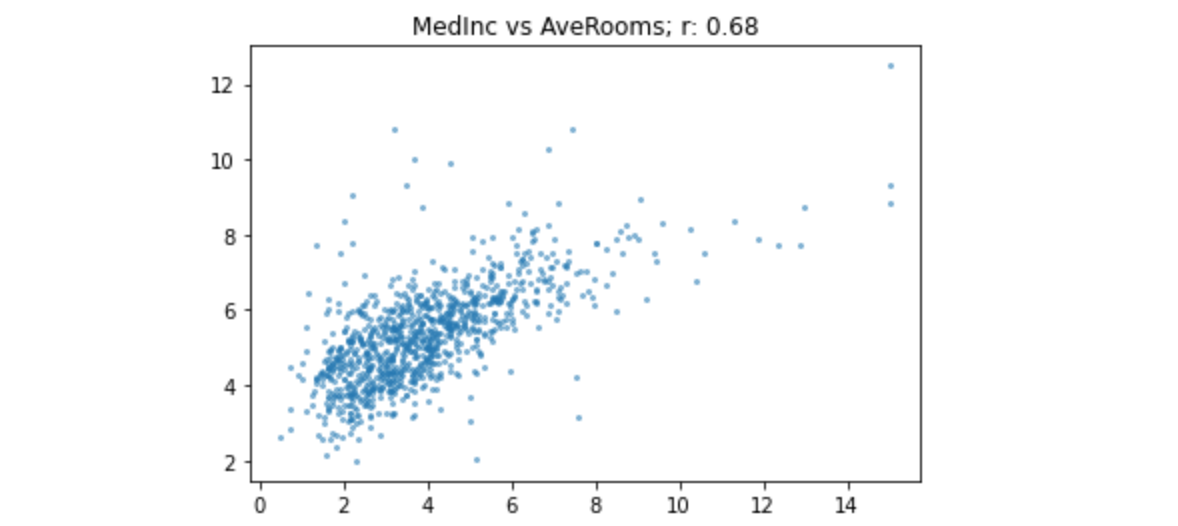
正如我们所预期的,现在的相关性与我们的第一次比较非常相似。这是在子集上使用AveRooms的另一个关系:
1 | show_corr(subset, 'MedHouseVal', 'AveRooms') |
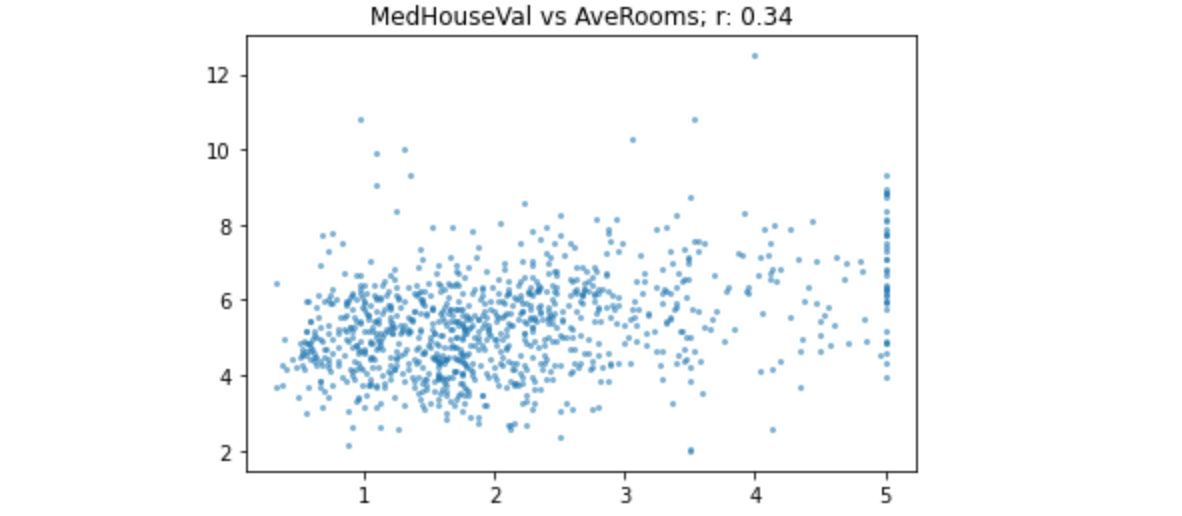
在r为0.34的这个值上,关系变得相当弱。
1 | show_corr(subset, 'HouseAge', 'AveRooms') |
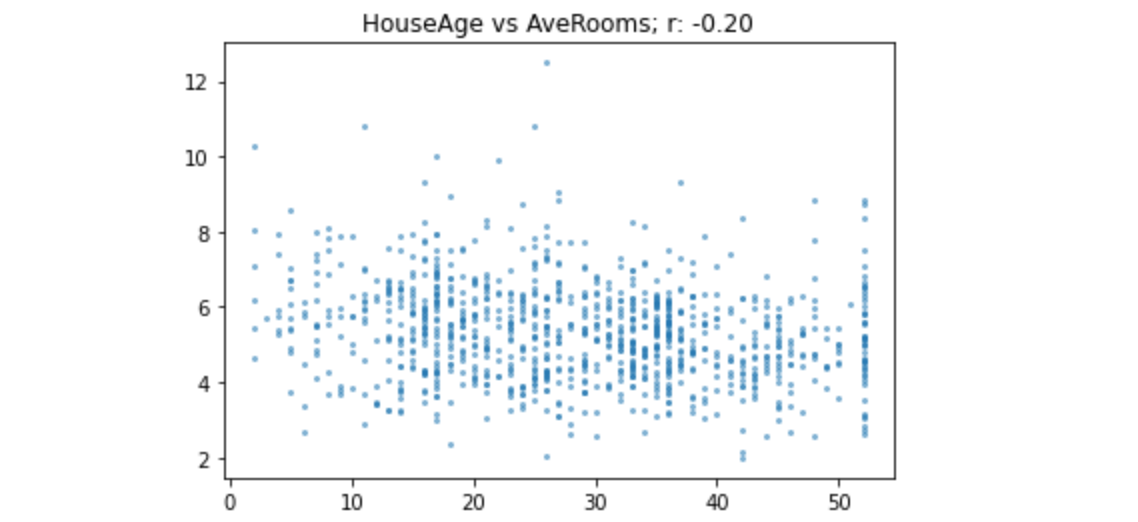
正如您在此处看到的,-0.2的相关性显示出非常弱的负趋势。我们现在已经看到了各种相关系数级别的示例,因此希望您能够很好地理解该指标的含义。Transformers希望指标以字典形式返回,因为这样训练器就知道要使用什么标签,所以让我们创建一个函数来执行此操作:
1 | def corr_d(eval_pred): return {'pearson': corr(*eval_pred)} |
训练
要在Transformers中训练模型,我们需要引入transformers包,我们选择适合的GPU的批量大小和少量的epoch,以便我们可以快速运行实验。最重要的超参数是学习率。fastai 提供了一个学习率查找器来帮助您解决这个问题,但Transformers没有,所以您只能反复试验。这个想法是找到尽可能大的值,但这不会导致训练失败。Transformers使用 TrainingArguments类来设置参数。对于不同的型号,您可能需要更改上述3个参数。我们现在可以创建我们的模型和Trainer,它是一个将数据和模型结合在一起的类(就像fastai中的 Learner一样):
1 | from transformers import TrainingArguments,Trainer |
让我们训练模型吧。
1 | trainer.train() |
结果输出为:
1 | Epoch Training Loss Validation Loss Pearson |
需要注意的是表中的“Pearson”值。 正如您所看到的,它正在增加,并且已经超过0.8。让我们对测试集进行一些预测:
1 | preds = trainer.predict(eval_ds).predictions.astype(float) |
请注意:我们的一些预测是<0或>1。再次体现了记住实际查看数据的价值。让我们修复这些越界预测:
1 | preds = np.clip(preds, 0, 1) |
现在我们准备创建提交文件。如果您在笔记本中保存CSV,您将可以选择稍后提交。
1 | import datasets |