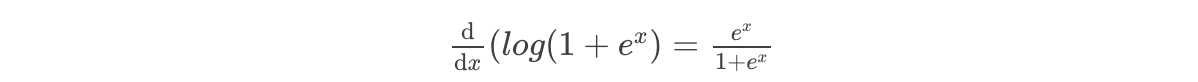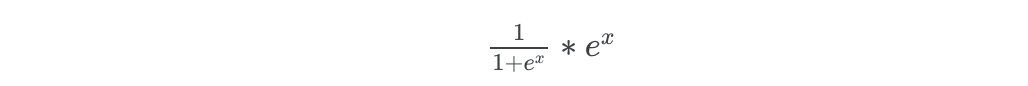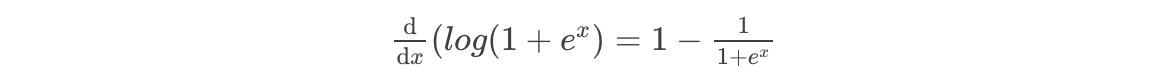import time import numpy as np import jax import jax.numpy as jnp from jax import random from jax import make_jaxpr from jax import vmap, pmap, jit from jax import grad, value_and_grad from jax.test_util import check_grads
# Modified product function. Explicity stopping the # flow of the gradients through `y` defproduct_stop_grad(x, y): z = x * jax.lax.stop_gradient(y) return z
# Differentiating wrt y. This should return 0 grad(product_stop_grad, argnums=1)(x, y)
# Check if we can compute the gradients for a single example grads_single_example = grad(activate)(0.5) print("Gradient for a single input x=0.5: ", grads_single_example)
# Now we will generate a batch of random inputs, and will pass # those inputs to our activate function. And we will also try to # calculate the grads on the same batch in the same way as above # Always use the PRNG key = random.PRNGKey(1234) x = random.normal(key=key, shape=(5,)) activations = activate(x)
print("\nTrying to compute gradients on a batch") print("Input shape: ", x.shape) print("Output shape: ", activations.shape)
try: grads_batch = grad(activate)(x) print("Gradients for the batch: ", grads_batch) except Exception as ex: print(type(ex).__name__, ex)
结果输出为:
1 2 3 4 5
Gradient for a single input x=0.5: 0.7864477 Trying to compute gradients on a batch Input shape: (5,) Output shape: (5,) TypeError Gradient only defined for scalar-output functions. Output had shape: (5,).
那么解决办法是什么呢?vmap和pmap是几乎所有问题的解决方案,让我们看看它的实际效果:
1 2 3 4
grads_batch = vmap(grad(activate))(x) print("Gradients for the batch: ", grads_batch)
# Gradients for the batch: [0.48228705 0.45585024 0.99329686 0.0953269 0.8153717 ]
try: check_grads(jitted_grads_batch, (x,), order=1) print("Gradient match with gradient calculated using finite differences") except Exception as ex: print(type(ex).__name__, ex)
# Gradient match with gradient calculated using finite differences
print("First order derivative: ", grad(activate)(x)) print("Second order derivative: ", grad(grad(activate))(x)) print("Third order derivative: ", grad(grad(grad(activate)))(x))
# First order derivative: 0.7864477 # Second order derivative: -0.726862 # Third order derivative: -0.5652091
# An example of a mathematical operation in your workflow deflog1pexp(x): """Implements log(1 + exp(x))""" return jnp.log(1. + jnp.exp(x))
# This works fine print("Gradients for a small value of x: ", grad(log1pexp)(5.0))
# But what about for very large values of x for which the # exponent operation will explode print("Gradients for a large value of x: ", grad(log1pexp)(500.0))
@log1pexp.defjvp deflog1pexp_jvp(primals, tangents): """Tells JAX to differentiate the function in the way we want.""" x, = primals x_dot, = tangents ans = log1pexp(x) # This is where we define the correct way to compute gradients ans_dot = (1 - 1/(1 + jnp.exp(x))) * x_dot return ans, ans_dot
# Let's now compute the gradients for large values print("Gradients for a small value of x: ", grad(log1pexp)(500.0))
# What about the Jaxpr? make_jaxpr(grad(log1pexp))(500.0)
# Gradients for a small value of x: 1.0 # { lambda ; a. # let _ = custom_jvp_call_jaxpr[ fun_jaxpr={ lambda ; a. # let b = exp a # c = add b 1.0 # d = log c # in (d,) } # jvp_jaxpr_thunk=<function _memoize.<locals>.memoized at 0x7f79cc3f2dd0> # num_consts=0 ] a # b = exp a # c = add b 1.0 # d = div 1.0 c # e = sub 1.0 d # f = mul e 1.0 # in (f,) }