# Selects random valid column defagent_random(obs, config): valid_moves = [col for col inrange(config.columns) if obs.board[col] == 0] return random.choice(valid_moves)
# Helper function for score_move: gets board at next step if agent drops piece in selected column defdrop_piece(grid, col, mark, config): next_grid = grid.copy() for row inrange(config.rows-1, -1, -1): if next_grid[row][col] == 0: break next_grid[row][col] = mark return next_grid
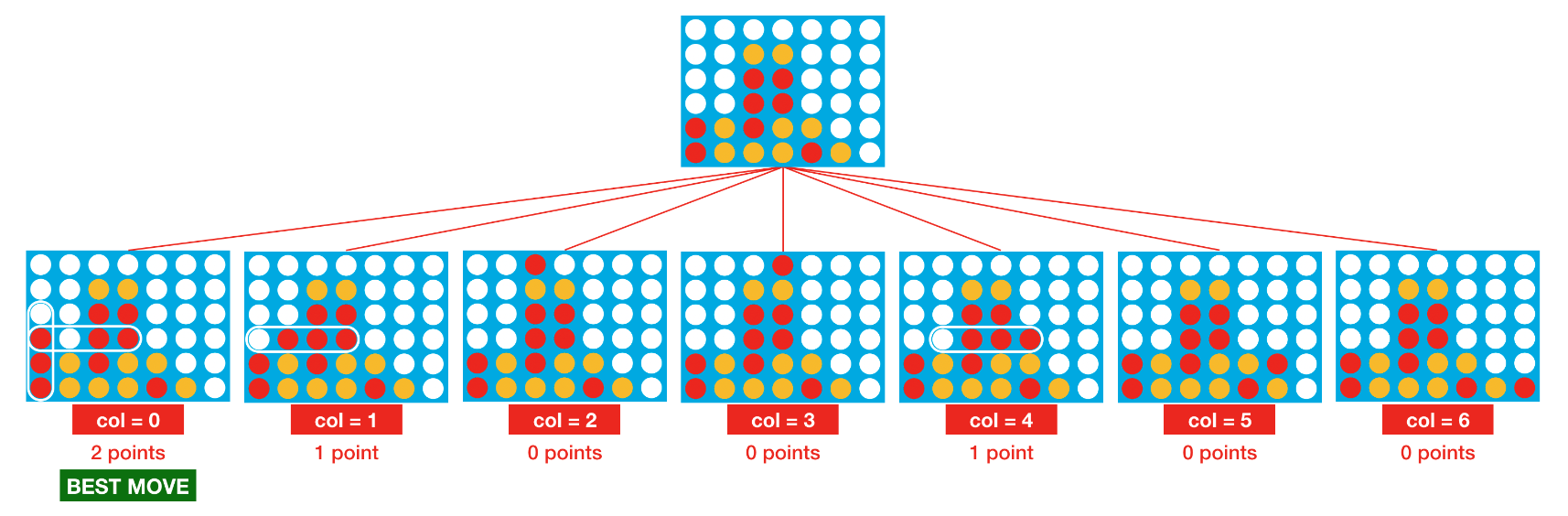
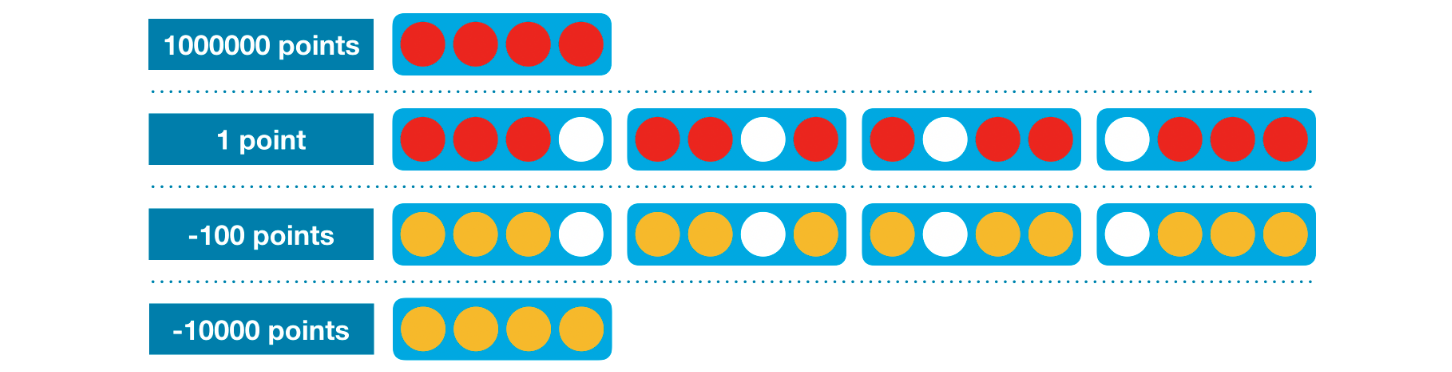
# Helper function for score_move: calculates value of heuristic for grid defget_heuristic(grid, mark, config): num_threes = count_windows(grid, 3, mark, config) num_fours = count_windows(grid, 4, mark, config) num_threes_opp = count_windows(grid, 3, mark%2+1, config) score = num_threes - 1e2*num_threes_opp + 1e6*num_fours return score
# Helper function for get_heuristic: checks if window satisfies heuristic conditions defcheck_window(window, num_discs, piece, config): return (window.count(piece) == num_discs and window.count(0) == config.inarow-num_discs) # Helper function for get_heuristic: counts number of windows satisfying specified heuristic conditions defcount_windows(grid, num_discs, piece, config): num_windows = 0 # horizontal for row inrange(config.rows): for col inrange(config.columns-(config.inarow-1)): window = list(grid[row, col:col+config.inarow]) if check_window(window, num_discs, piece, config): num_windows += 1 # vertical for row inrange(config.rows-(config.inarow-1)): for col inrange(config.columns): window = list(grid[row:row+config.inarow, col]) if check_window(window, num_discs, piece, config): num_windows += 1 # positive diagonal for row inrange(config.rows-(config.inarow-1)): for col inrange(config.columns-(config.inarow-1)): window = list(grid[range(row, row+config.inarow), range(col, col+config.inarow)]) if check_window(window, num_discs, piece, config): num_windows += 1 # negative diagonal for row inrange(config.inarow-1, config.rows): for col inrange(config.columns-(config.inarow-1)): window = list(grid[range(row, row-config.inarow, -1), range(col, col+config.inarow)]) if check_window(window, num_discs, piece, config): num_windows += 1 return num_windows
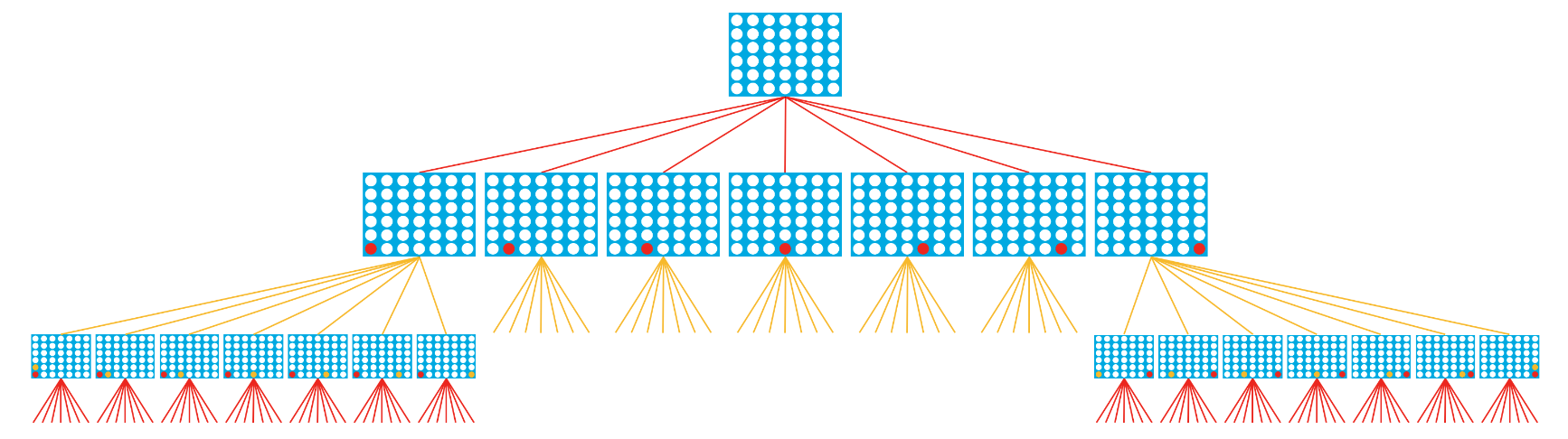
# The agent is always implemented as a Python function that accepts two arguments: obs and config defagent(obs, config): # Get list of valid moves valid_moves = [c for c inrange(config.columns) if obs.board[c] == 0] # Convert the board to a 2D grid grid = np.asarray(obs.board).reshape(config.rows, config.columns) # Use the heuristic to assign a score to each possible board in the next turn scores = dict(zip(valid_moves, [score_move(grid, col, obs.mark, config) for col in valid_moves])) # Get a list of columns (moves) that maximize the heuristic max_cols = [key for key in scores.keys() if scores[key] == max(scores.values())] # Select at random from the maximizing columns return random.choice(max_cols)
# Gets board at next step if agent drops piece in selected column defdrop_piece(grid, col, mark, config): next_grid = grid.copy() for row inrange(config.rows-1, -1, -1): if next_grid[row][col] == 0: break next_grid[row][col] = mark return next_grid
# Helper function for get_heuristic: checks if window satisfies heuristic conditions defcheck_window(window, num_discs, piece, config): return (window.count(piece) == num_discs and window.count(0) == config.inarow-num_discs) # Helper function for get_heuristic: counts number of windows satisfying specified heuristic conditions defcount_windows(grid, num_discs, piece, config): num_windows = 0 # horizontal for row inrange(config.rows): for col inrange(config.columns-(config.inarow-1)): window = list(grid[row, col:col+config.inarow]) if check_window(window, num_discs, piece, config): num_windows += 1 # vertical for row inrange(config.rows-(config.inarow-1)): for col inrange(config.columns): window = list(grid[row:row+config.inarow, col]) if check_window(window, num_discs, piece, config): num_windows += 1 # positive diagonal for row inrange(config.rows-(config.inarow-1)): for col inrange(config.columns-(config.inarow-1)): window = list(grid[range(row, row+config.inarow), range(col, col+config.inarow)]) if check_window(window, num_discs, piece, config): num_windows += 1 # negative diagonal for row inrange(config.inarow-1, config.rows): for col inrange(config.columns-(config.inarow-1)): window = list(grid[range(row, row-config.inarow, -1), range(col, col+config.inarow)]) if check_window(window, num_discs, piece, config): num_windows += 1 return num_windows
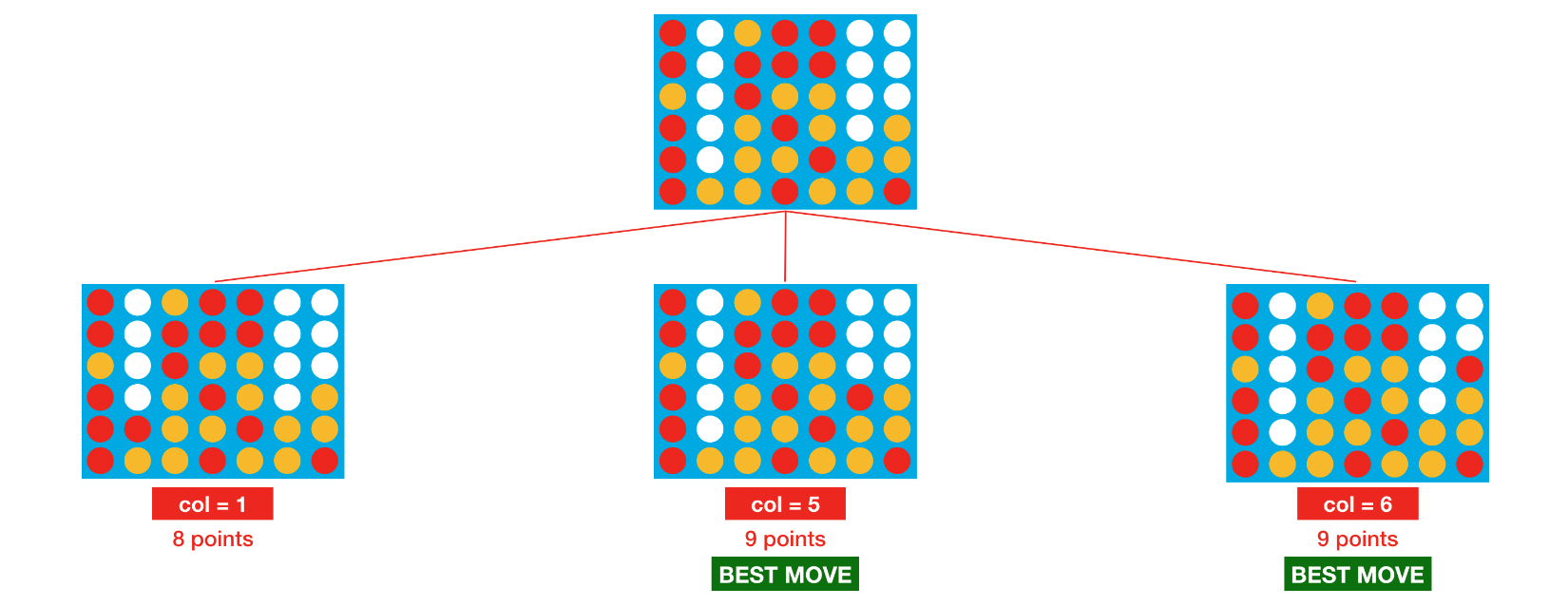
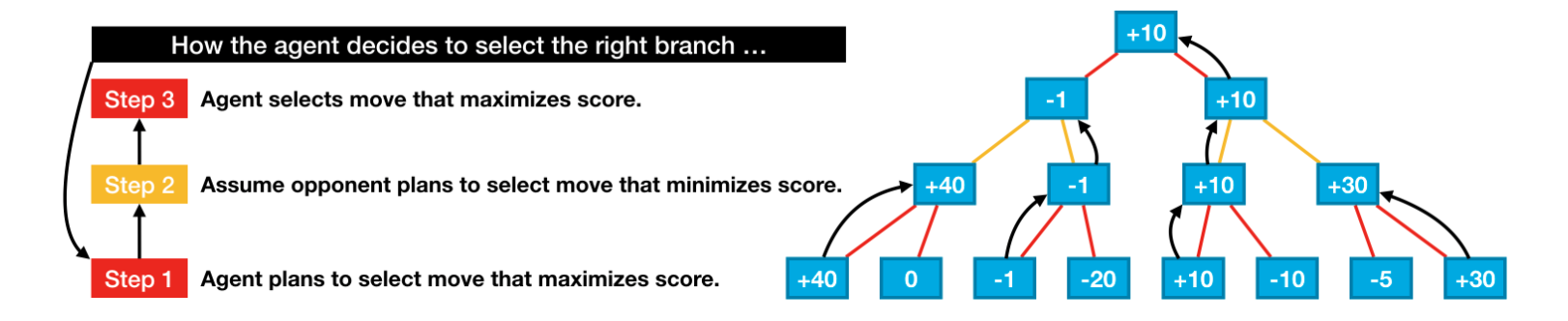
# Uses minimax to calculate value of dropping piece in selected column defscore_move(grid, col, mark, config, nsteps): next_grid = drop_piece(grid, col, mark, config) score = minimax(next_grid, nsteps-1, False, mark, config) return score
# Helper function for minimax: checks if agent or opponent has four in a row in the window defis_terminal_window(window, config): return window.count(1) == config.inarow or window.count(2) == config.inarow
# Helper function for minimax: checks if game has ended defis_terminal_node(grid, config): # Check for draw iflist(grid[0, :]).count(0) == 0: returnTrue # Check for win: horizontal, vertical, or diagonal # horizontal for row inrange(config.rows): for col inrange(config.columns-(config.inarow-1)): window = list(grid[row, col:col+config.inarow]) if is_terminal_window(window, config): returnTrue # vertical for row inrange(config.rows-(config.inarow-1)): for col inrange(config.columns): window = list(grid[row:row+config.inarow, col]) if is_terminal_window(window, config): returnTrue # positive diagonal for row inrange(config.rows-(config.inarow-1)): for col inrange(config.columns-(config.inarow-1)): window = list(grid[range(row, row+config.inarow), range(col, col+config.inarow)]) if is_terminal_window(window, config): returnTrue # negative diagonal for row inrange(config.inarow-1, config.rows): for col inrange(config.columns-(config.inarow-1)): window = list(grid[range(row, row-config.inarow, -1), range(col, col+config.inarow)]) if is_terminal_window(window, config): returnTrue returnFalse
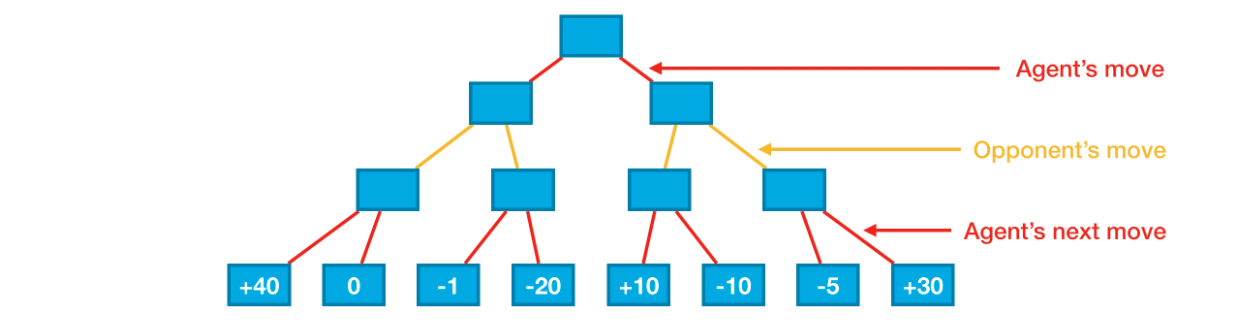
# Minimax implementation defminimax(node, depth, maximizingPlayer, mark, config): is_terminal = is_terminal_node(node, config) valid_moves = [c for c inrange(config.columns) if node[0][c] == 0] if depth == 0or is_terminal: return get_heuristic(node, mark, config) if maximizingPlayer: value = -np.Inf for col in valid_moves: child = drop_piece(node, col, mark, config) value = max(value, minimax(child, depth-1, False, mark, config)) return value else: value = np.Inf for col in valid_moves: child = drop_piece(node, col, mark%2+1, config) value = min(value, minimax(child, depth-1, True, mark, config)) return value
N_STEPS变量用于设置树的深度。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
# How deep to make the game tree: higher values take longer to run! N_STEPS = 3
defagent(obs, config): # Get list of valid moves valid_moves = [c for c inrange(config.columns) if obs.board[c] == 0] # Convert the board to a 2D grid grid = np.asarray(obs.board).reshape(config.rows, config.columns) # Use the heuristic to assign a score to each possible board in the next step scores = dict(zip(valid_moves, [score_move(grid, col, obs.mark, config, N_STEPS) for col in valid_moves])) # Get a list of columns (moves) that maximize the heuristic max_cols = [key for key in scores.keys() if scores[key] == max(scores.values())] # Select at random from the maximizing columns return random.choice(max_cols)
我们看到与随机代理的一轮游戏的结果。
1 2 3 4 5 6 7 8 9 10
from kaggle_environments import make, evaluate
# Create the game environment env = make("connectx")
# Two random agents play one game round env.run([agent, "random"])
# Show the game env.render(mode="ipython")
我们会检查它的平均表现。
1 2 3 4 5 6 7 8 9 10 11 12 13
defget_win_percentages(agent1, agent2, n_rounds=100): # Use default Connect Four setup config = {'rows': 6, 'columns': 7, 'inarow': 4} # Agent 1 goes first (roughly) half the time outcomes = evaluate("connectx", [agent1, agent2], config, [], n_rounds//2) # Agent 2 goes first (roughly) half the time outcomes += [[b,a] for [a,b] in evaluate("connectx", [agent2, agent1], config, [], n_rounds-n_rounds//2)] print("Agent 1 Win Percentage:", np.round(outcomes.count([1,-1])/len(outcomes), 2)) print("Agent 2 Win Percentage:", np.round(outcomes.count([-1,1])/len(outcomes), 2)) print("Number of Invalid Plays by Agent 1:", outcomes.count([None, 0])) print("Number of Invalid Plays by Agent 2:", outcomes.count([0, None]))
import random import numpy as np import pandas as pd import matplotlib.pyplot as plt import gym from kaggle_environments import make, evaluate from gym import spaces
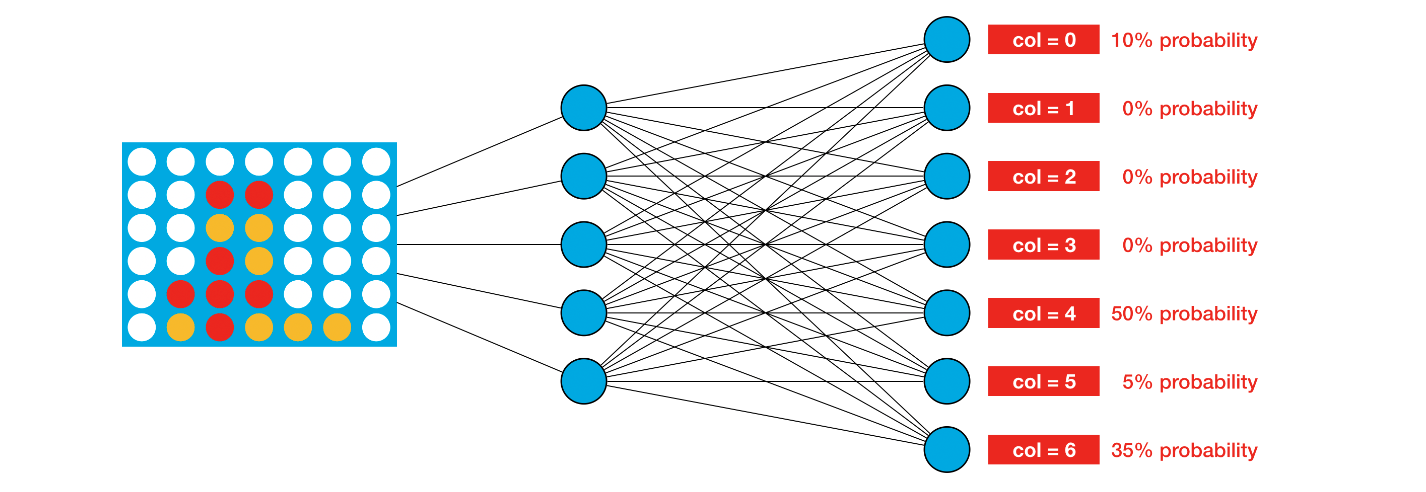
classConnectFourGym(gym.Env): def__init__(self, agent2="random"): ks_env = make("connectx", debug=True) self.env = ks_env.train([None, agent2]) self.rows = ks_env.configuration.rows self.columns = ks_env.configuration.columns # Learn about spaces here: http://gym.openai.com/docs/#spaces self.action_space = spaces.Discrete(self.columns) self.observation_space = spaces.Box(low=0, high=2, shape=(1,self.rows,self.columns), dtype=int) # Tuple corresponding to the min and max possible rewards self.reward_range = (-10, 1) # StableBaselines throws error if these are not defined self.spec = None self.metadata = None defreset(self): self.obs = self.env.reset() return np.array(self.obs['board']).reshape(1,self.rows,self.columns) defchange_reward(self, old_reward, done): if old_reward == 1: # The agent won the game return1 elif done: # The opponent won the game return -1 else: # Reward 1/42 return1/(self.rows*self.columns) defstep(self, action): # Check if agent's move is valid is_valid = (self.obs['board'][int(action)] == 0) if is_valid: # Play the move self.obs, old_reward, done, _ = self.env.step(int(action)) reward = self.change_reward(old_reward, done) else: # End the game and penalize agent reward, done, _ = -10, True, {} return np.array(self.obs['board']).reshape(1,self.rows,self.columns), reward, done, _
defagent1(obs, config): # Use the best model to select a column col, _ = model.predict(np.array(obs['board']).reshape(1, 6,7)) # Check if selected column is valid is_valid = (obs['board'][int(col)] == 0) # If not valid, select random move. if is_valid: returnint(col) else: return random.choice([col for col inrange(config.columns) if obs.board[int(col)] == 0])
在下一个代码单元中,我们看到与随机代理的一轮游戏的结果。
1 2 3 4 5 6 7 8
# Create the game environment env = make("connectx")
# Two random agents play one game round env.run([agent1, "random"])
# Show the game env.render(mode="ipython")
并且,我们计算它相对于随机代理的平均表现。
1 2 3 4 5 6 7 8 9 10 11 12 13
defget_win_percentages(agent1, agent2, n_rounds=100): # Use default Connect Four setup config = {'rows': 6, 'columns': 7, 'inarow': 4} # Agent 1 goes first (roughly) half the time outcomes = evaluate("connectx", [agent1, agent2], config, [], n_rounds//2) # Agent 2 goes first (roughly) half the time outcomes += [[b,a] for [a,b] in evaluate("connectx", [agent2, agent1], config, [], n_rounds-n_rounds//2)] print("Agent 1 Win Percentage:", np.round(outcomes.count([1,-1])/len(outcomes), 2)) print("Agent 2 Win Percentage:", np.round(outcomes.count([-1,1])/len(outcomes), 2)) print("Number of Invalid Plays by Agent 1:", outcomes.count([None, 0])) print("Number of Invalid Plays by Agent 2:", outcomes.count([0, None]))