迁移学习(TensorFlow & Keras)
例如,我可能想要一个可以判断照片是在城市地区还是农村地区拍摄的模型,但我的原始模型不会将图像分为这两个特定类别。我可以为此特定目的从头开始构建一个新模型。但为了获得好的结果,我需要数千张带有城市和乡村标签的照片。一种称为迁移学习的方法可以用更少的数据给出良好的结果。迁移学习利用模型在解决一个问题时学到的知识(称为预训练模型,因为该模型已经在不同的数据集上进行了训练),并将其应用于新的应用程序中。
ImageNet是一个非常大的图像数据集,由来自数千个类别的超过1400万张图像组成。Keras在此提供了几个已在此数据集上进行预训练的模型。其中一种模型是ResNet。我们将向您展示如何使预训练的ResNet模型适应新任务,以预测图像是农村还是城市。您将使用此数据集。
背景
请记住,深度学习模型的早期层可以识别简单的形状。后面的层可以识别更复杂的视觉模式,例如道路、建筑物、窗户和开阔的田野。这些层将在我们的新应用程序中有用。
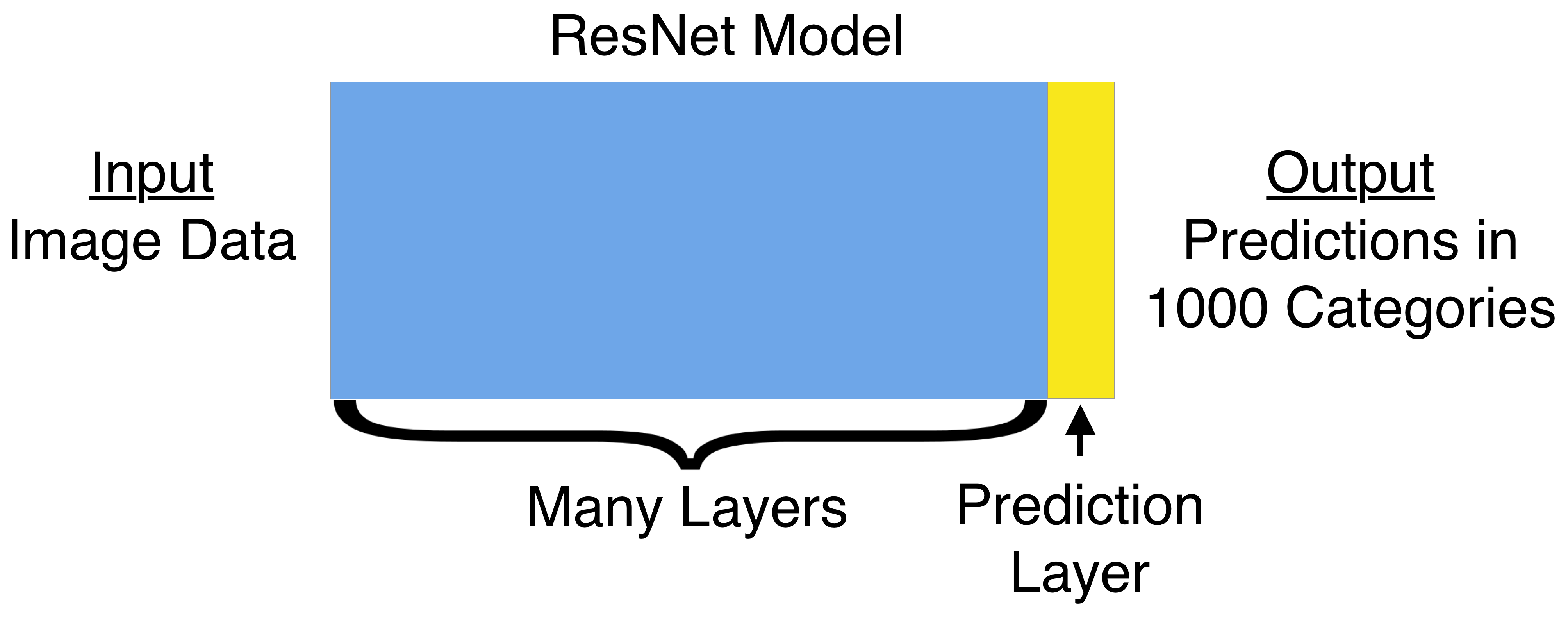
最后一层进行预测。我们将替换ResNet模型的最后一层。替换是具有两个节点的密集层。一个节点捕捉照片的城市化程度,另一个节点捕捉照片的乡村化程度。理论上,预测前最后一层的任何节点都可能告知其城市化程度。因此城市度量可以取决于该层中的所有节点。我们画出联系来表明这种可能的关系。出于同样的原因,每个节点的信息可能会影响我们对照片乡村程度的衡量。
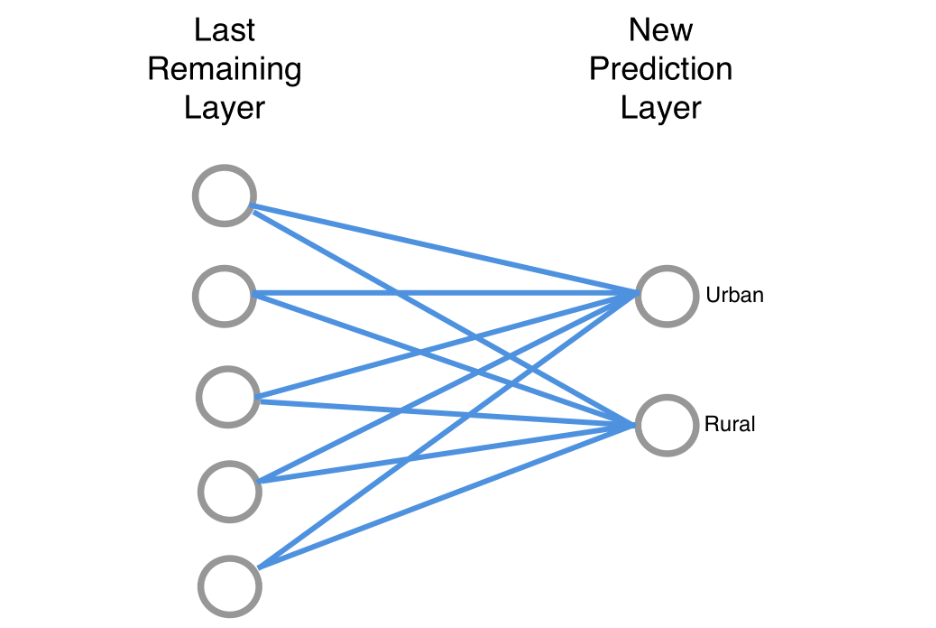
我们这里有很多连接,我们将使用训练数据来确定哪些节点表明图像是城市的,哪些节点表明图像是农村的,哪些节点无关紧要。也就是说,我们将训练模型的最后一层。实际上,训练数据将是标记为农村或城市的照片。
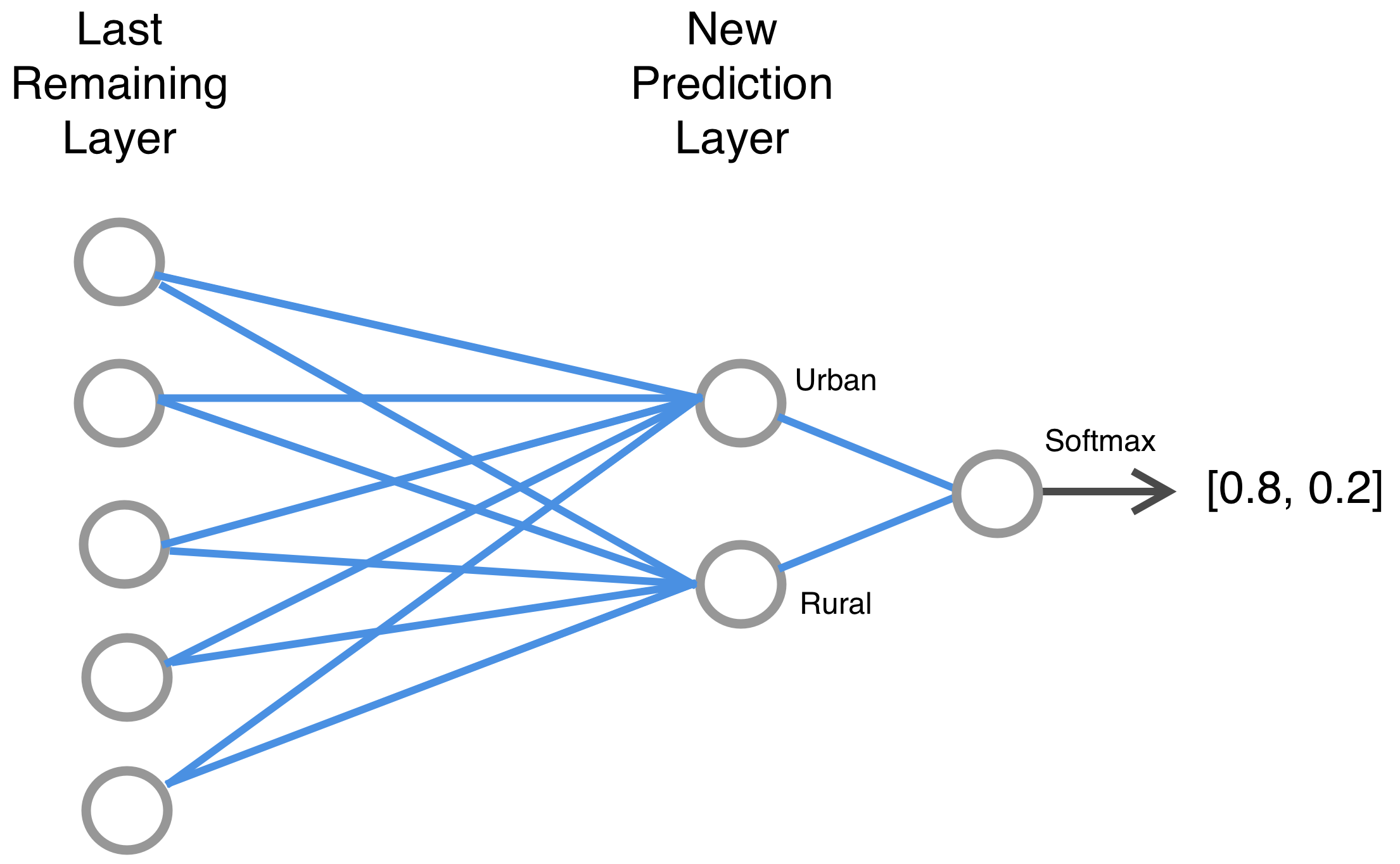
注意:当将某事物仅分为两类时,我们可以在输出处仅使用一个节点。在这种情况下,对照片城市化程度的预测也可以衡量它的乡村化程度。如果一张照片80%的可能性是城市,则20%的可能性是乡村。但我们在输出层保留了两个独立的节点。在输出层中为每个可能的类别使用单独的节点将有助于我们过渡到想要预测2个以上类别的情况。
Code
指定模型
在此应用程序中,我们将照片分为2个类别:城市和农村。我们将其保存为num_classes。接下来我们构建模型。我们建立了一个可以添加层的顺序模型。首先我们添加一个预训练的ResNet模型。创建ResNet模型时,我们编写了include_top=False。这就是我们指定要排除进行预测的ResNet模型的最后一层的方式。我们还将使用一个不包含该层权重的文件。参数 pooling='avg'表示如果在这一步结束时我们的张量中有额外的通道,我们希望通过取平均值将它们折叠为一维张量。现在我们有一个预训练的模型,可以创建您在图形中看到的图层。我们将添加一个密集层来进行预测。我们指定该层中的节点数量,在本例中是类的数量。然后我们应用softmax函数来生成概率。
最后,我们将告诉TensorFlow不要训练顺序模型的第一层,即ResNet50层。这是因为该模型已经使用ImageNet数据进行了预训练。
1 | # set random seed / make reproducible |
1 | Model: "sequential" |
编译模型
编译命令告诉TensorFlow如何在训练期间更新网络最后一层的关系。我们有一个衡量损失或不准确性的方法,希望将其最小化。我们将其指定为categorical_crossentropy。如果您熟悉对数损失,这是同一事物的另一个术语。我们使用一种称为随机梯度下降(SGD)的算法来最小化分类交叉熵损失。我们要求代码报告准确性指标,即正确预测的比例。这比分类交叉熵分数更容易解释,因此最好将其打印出来并查看模型的表现。
1 | my_new_model.compile(optimizer='sgd', loss='categorical_crossentropy', metrics=['accuracy']) |
加载图像数据
我们的原始数据分为训练数据目录和验证数据目录。在每个目录中,我们都有一个用于城市图片的子目录,另一个用于乡村图片的子目录。TensorFlow提供了一个很棒的工具,用于处理按标签分组到目录中的图像。这是图像数据生成器。使用ImageDataGenerator有两个步骤。首先我们抽象地创建生成器对象。我们希望在每次读取图像时应用ResNet预处理函数。然后我们使用 flow_from_directory命令。我们告诉它数据在哪个目录中,我们想要什么大小的图像,一次读入多少图像(批量大小),然后我们告诉它我们正在将数据分类为不同的类别。我们做同样的事情来设置读取验证数据的方法。ImageDataGenerator在处理大型数据集时尤其有价值,因为我们不需要立即将整个数据集保存在内存中。但这里还好,数据集很小。 请注意,这些是生成器,这意味着我们需要迭代它们才能获取数据。
1 | from tensorflow.keras.applications.resnet50 import preprocess_input |
拟合模型
现在我们拟合模型。训练数据来自train_generator,验证数据来自validation_generator。 由于我们有72个训练图像并一次读取12个图像,因此我们在单个epoch中使用6个步骤 (steps_per_epoch=6)。同样,我们有20个验证图像,并使用一个验证步骤,因为我们在一步中读取了所有20个图像 (validation_steps=1)。随着模型训练的运行,我们将看到损失函数和准确性的进度更新。它更新了致密层中的连接,即模型对城市照片和乡村照片的印象。完成后,78%的训练数据都是正确的。然后它检查验证数据。90%的都答对了。我应该提到,这是一个非常小的数据集,您应该对依赖如此少量数据的验证分数犹豫不决。我们从小型数据集开始,这样您就可以通过可以快速训练的模型获得一些经验。
1 | my_new_model.fit( |
即使训练数据集很小,这个准确度分数也非常好。我们用72张照片进行训练。您可以轻松地在手机上拍摄那么多照片,并构建一个非常准确的模型来区分几乎所有您关心的东西。
训练结果
在此阶段,打印的验证准确性可能明显优于训练准确性。一开始这可能会令人困惑。发生这种情况是因为随着网络的改进,训练精度是在多个点计算的(卷积中的数字正在更新以使模型更准确)。当模型看到第一张训练图像时,网络不准确,因为权重尚未经过太多训练/改进。 这些第一次训练结果被平均到上面的度量中。模型遍历所有数据后计算验证损失和准确性度量。因此,在计算这些分数时,网络已经经过充分训练。这在实践中并不是一个严重的问题,我们往往不用担心。