卷积分类器(The Convolutional Classifier)
使用现代深度学习网络通过Keras构建图像分类器。
使用可重复使用的块设计您自己的自定义卷积网络。
了解视觉特征提取背后的基本思想。
掌握迁移学习的艺术来提升您的模型。
利用数据增强来扩展数据集。
介绍 将向您介绍计算机视觉的基本思想。我们的目标是了解神经网络如何充分“理解”自然图像,以解决人类视觉系统可以解决的同类问题。最擅长此任务的神经网络称为卷积神经网络(有时我们称为CNN)。卷积是一种数学运算,它赋予了CNN各层独特的结构。我们将把这些想法应用到图像分类问题上:给定一张图片,我们能否训练计算机告诉我们它是什么?您可能见过可以从照片中识别植物种类的应用程序。这就是图像分类器!最后,您将准备好继续学习更高级的应用程序,例如生成对抗网络和图像分割。
卷积分类器 用于图像分类的卷积网络由两部分组成:卷积基 和密集头 。
基础用于从图像中提取特征 。它主要由执行卷积运算的层组成,但通常也包括其他类型的层。头部用于确定图像的类别。它主要由致密层组成,但可能包括其他层,例如dropout。视觉特征是什么意思?特征可以是线条、颜色、纹理、形状、图案——或者一些复杂的组合。整个过程是这样的:
训练分类器 训练期间网络的目标是学习两件事:
从图像(基础)中提取哪些特征。
哪个类具有哪些特征(头)。
如今,卷积网络很少从头开始训练。更常见的是,我们重用预训练模型的基础。然后我们在预训练的基础上附加一个未经训练的头部。换句话说,我们重用网络中已经学会执行。1.提取特征,并附加一些新层来学习;2.分类的部分。
由于头部通常仅由几个致密层组成,因此可以从相对较少的数据创建非常准确的分类器。重用预训练模型是一种称为迁移学习的技术。它非常有效,以至于现在几乎每个图像分类器都会使用它。
举例 - 训练Convnet分类器 我们将创建分类器来尝试解决以下问题:这是汽车还是卡车的图片?我们的数据集大约有10,000张各种汽车的图片,大约一半是汽车,一半是卡车。
第1步 - 加载数据 下一个隐藏单元将导入一些库并设置我们的数据管道。我们有一个名为ds_train的训练分割和一个名为ds_valid的验证分割。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 import os, warningsimport matplotlib.pyplot as pltfrom matplotlib import gridspecimport numpy as npimport tensorflow as tffrom tensorflow.keras.preprocessing import image_dataset_from_directorydef set_seed (seed=31415 ): np.random.seed(seed) tf.random.set_seed(seed) os.environ['PYTHONHASHSEED' ] = str (seed) os.environ['TF_DETERMINISTIC_OPS' ] = '1' set_seed(31415 ) plt.rc('figure' , autolayout=True ) plt.rc('axes' , labelweight='bold' , labelsize='large' , titleweight='bold' , titlesize=18 , titlepad=10 ) plt.rc('image' , cmap='magma' ) warnings.filterwarnings("ignore" ) ds_train_ = image_dataset_from_directory( '../input/car-or-truck/train' , labels='inferred' , label_mode='binary' , image_size=[128 , 128 ], interpolation='nearest' , batch_size=64 , shuffle=True , ) ds_valid_ = image_dataset_from_directory( '../input/car-or-truck/valid' , labels='inferred' , label_mode='binary' , image_size=[128 , 128 ], interpolation='nearest' , batch_size=64 , shuffle=False , ) def convert_to_float (image, label ): image = tf.image.convert_image_dtype(image, dtype=tf.float32) return image, label AUTOTUNE = tf.data.experimental.AUTOTUNE ds_train = ( ds_train_ .map (convert_to_float) .cache() .prefetch(buffer_size=AUTOTUNE) ) ds_valid = ( ds_valid_ .map (convert_to_float) .cache() .prefetch(buffer_size=AUTOTUNE) )
让我们看一下训练集中的一些示例。
1 import matplotlib.pyplot as plt
第2步 - 定义预训练库 最常用的预训练数据集是ImageNet,这是一个包含多种自然图像的大型数据集。Keras在其应用程序模块中包含在ImageNet上预训练的各种模型。我们将使用的预训练模型称为VGG16。
1 2 3 4 pretrained_base = tf.keras.models.load_model( '../input/cv-course-models/cv-course-models/vgg16-pretrained-base' , ) pretrained_base.trainable = False
第3步 - 连接头部 接下来,我们连接分类器头。对于此示例,我们将使用隐藏单元层(第一个Dense层),然后使用一个层将输出转换为1类卡车的概率分数。Flatten层将基础的二维输出转换为头部所需的一维输入。
1 2 3 4 5 6 7 8 9 from tensorflow import kerasfrom tensorflow.keras import layersmodel = keras.Sequential([ pretrained_base, layers.Flatten(), layers.Dense(6 , activation='relu' ), layers.Dense(1 , activation='sigmoid' ), ])
第4步 - 训练 最后,让我们训练模型。由于这是一个二分类问题,我们将使用交叉熵和准确性的二进制版本。adam优化器通常表现良好,因此我们也选择它。
1 2 3 4 5 6 7 8 9 10 11 12 model.compile ( optimizer='adam' , loss='binary_crossentropy' , metrics=['binary_accuracy' ], ) history = model.fit( ds_train, validation_data=ds_valid, epochs=30 , verbose=0 , )
训练神经网络时,检查损失图和度量图始终是个好主意。历史对象在字典history.history中包含此信息。我们可以使用Pandas将此字典转换为数据框,并使用内置方法将其绘制出来。
1 2 3 4 5 import pandas as pdhistory_frame = pd.DataFrame(history.history) history_frame.loc[:, ['loss' , 'val_loss' ]].plot() history_frame.loc[:, ['binary_accuracy' , 'val_binary_accuracy' ]].plot()
结论 我们了解了卷积网络分类器的结构:在执行特征提取的基础之上充当分类器的头部 。本质上,头部是一个普通的分类器。对于特征,它使用基础提取的那些特征。这是卷积分类器背后的基本思想:我们可以将执行特征工程的单元附加到分类器本身。这是深度神经网络相对于传统机器学习模型的一大优势:给定正确的网络结构,深度神经网络可以学习如何设计解决问题所需的特征。
卷积 & ReLU激活函数(Convolution & ReLU) 介绍 我们看到卷积分类器有两部分:卷积基础 和密集层头部 。我们了解到,卷积基础 的工作是从图像中提取视觉特征,然后头部将使用这些特征对图像进行分类。我们接下来将学习在卷积图像分类器的基础上找到的两种最重要的层类型。这些是具有ReLU激活的卷积层 和最大池化层 。如何通过将这些层组合成执行特征提取的块来设计自己的卷积网络。
特征提取 在详细介绍卷积之前,我们先讨论一下网络中这些层的用途。我们将了解如何使用这三种操作(卷积 、ReLU 和最大池化 )来实现特征提取 的过程。
过滤 图像的特定特征(卷积)。检测 滤波图像中的该特征 (ReLU)。压缩 图像以增强特征(最大池化)。
下图说明了此过程。您可以看到这三个操作如何能够隔离原始图像的某些特定特征。
通常,网络将对单个图像并行执行多次提取。在现代卷积网络中,基础的最后一层产生1000多个独特的视觉特征并不罕见。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import numpy as npfrom itertools import productdef show_kernel (kernel, label=True , digits=None , text_size=28 ): kernel = np.array(kernel) if digits is not None : kernel = kernel.round (digits) cmap = plt.get_cmap('Blues_r' ) plt.imshow(kernel, cmap=cmap) rows, cols = kernel.shape thresh = (kernel.max ()+kernel.min ())/2 if label: for i, j in product(range (rows), range (cols)): val = kernel[i, j] color = cmap(0 ) if val > thresh else cmap(255 ) plt.text(j, i, val, color=color, size=text_size, horizontalalignment='center' , verticalalignment='center' ) plt.xticks([]) plt.yticks([])
卷积过滤 卷积层执行过滤步骤。您可以在Keras模型中定义一个卷积层,如下所示:
1 2 3 4 5 6 7 8 import tensorflow as tfimport kerasfrom keras import layers, callbacksmodel = keras.Sequential([ layers.Conv2D(filters=64 , kernel_size=3 ), ])
我们可以通过查看这些参数与层的权重和激活的关系来理解这些参数。
权重(Weights) 卷积网络在训练期间学习的权重主要包含在其卷积层中。这些权重我们称为内核 。我们可以将它们表示为小数组:内核通过扫描图像并生成像素值的加权和来进行操作。通过这种方式,内核的作用有点像偏振透镜,强调或弱化某些信息模式。
内核定义卷积层如何连接到后续层。上面的内核将输出中的每个神经元连接到输入中的九个神经元。通过使用kernel_size设置内核的尺寸,您可以告诉卷积网络以何种方式形成这些连接。大多数情况下,内核将具有奇数维度-例如kernel_size=(3, 3)或(5, 5)-因此单个像素位于中心,但这不是必需的。卷积层中的内核决定了它创建的特征类型。在训练过程中,卷积网络尝试解决分类问题所需的特征。这意味着找到其内核的最佳值。
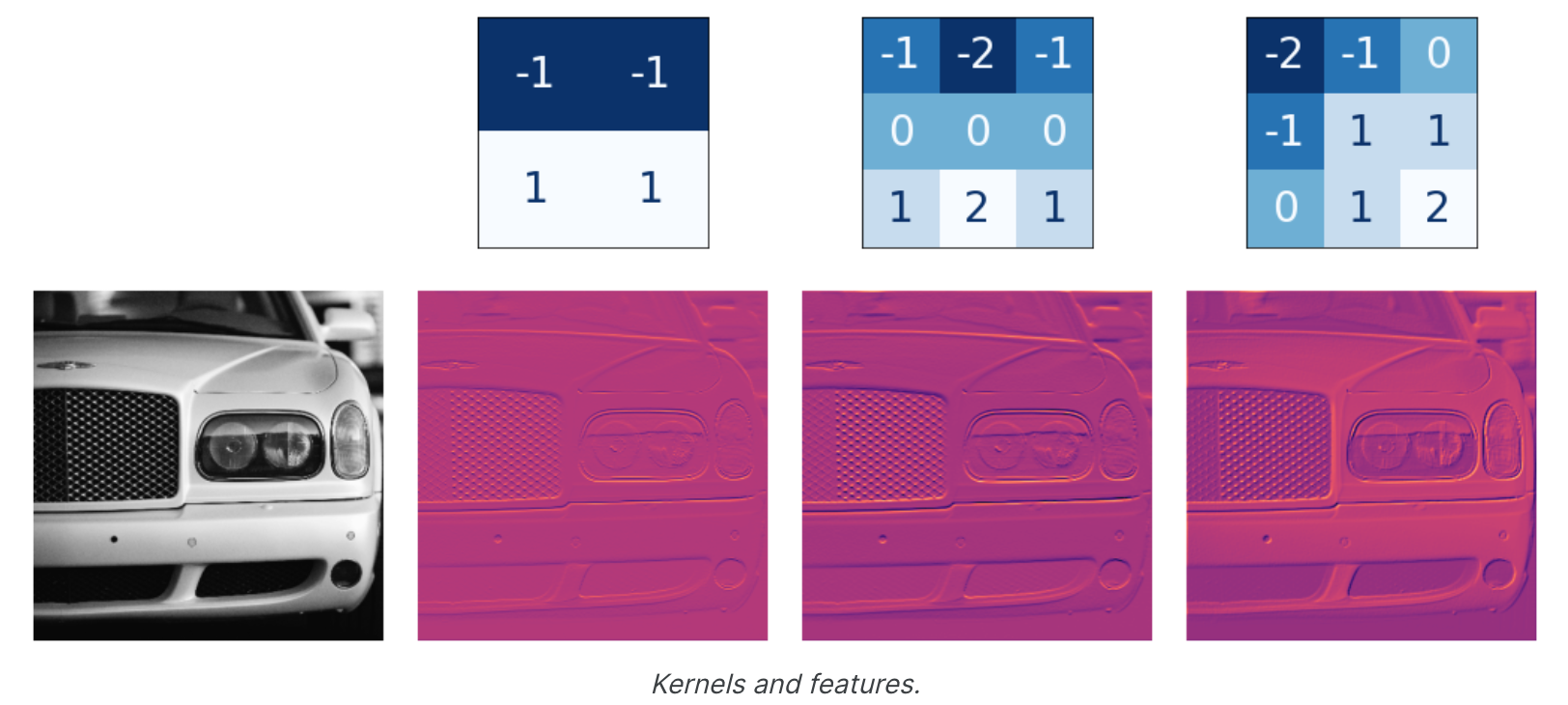
激活(Activations) 网络中的激活我们称为特征图 。它们是我们对图像应用滤镜时的结果;它们包含内核提取的视觉特征。以下是一些内核及其生成的特征图。
从内核中的数字模式,您可以看出它创建的特征图的类型。一般来说,卷积在其输入中强调的内容将与内核中正数的形状相匹配。上面的左侧和中间的内核都会过滤水平形状。使用过滤器参数,您可以告诉卷积层您希望它创建多少个特征图作为输出。
使用ReLU进行检测 过滤后,特征图通过激活函数 。整流器函数 如下图:
连接有整流器的神经元称为整流线性单元 。因此,我们也可以将整流函数称为ReLU激活函数 ,或者称为ReLU函数。ReLU激活可以在其自己的激活层中定义,但大多数情况下您只需将其包含为Conv2D的激活函数。
1 2 3 4 model = keras.Sequential([ layers.Conv2D(filters=64 , kernel_size=3 , activation='relu' ) ])
您可以将激活函数视为根据某种重要性度量对像素值进行评分。ReLU激活表明负值并不重要,因此将它们设置为0。这是ReLU应用了上面的特征图。请注意它如何成功隔离特征。
与其他激活函数一样,ReLU函数是非线性的。本质上,这意味着网络中所有层的总效果与仅将效果加在一起所获得的效果不同——这与仅使用单个层所能实现的效果相同。非线性确保特征在深入网络时以有趣的方式组合。
举例 - 应用卷积和ReLU 在这个例子中,我们将自己进行提取,以更好地理解卷积网络在“幕后”所做的事情。这是我们将在本示例中使用的图像:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import tensorflow as tfimport matplotlib.pyplot as pltplt.rc('figure' , autolayout=True ) plt.rc('axes' , labelweight='bold' , labelsize='large' , titleweight='bold' , titlesize=18 , titlepad=10 ) plt.rc('image' , cmap='magma' ) image_path = '../input/computer-vision-resources/car_feature.jpg' image = tf.io.read_file(image_path) image = tf.io.decode_jpeg(image) plt.figure(figsize=(6 , 6 )) plt.imshow(tf.squeeze(image), cmap='gray' ) plt.axis('off' ) plt.show();
对于过滤步骤,我们将定义一个内核,然后将其与卷积一起应用。本例中的内核是“边缘检测 ”内核。您可以使用tf.constant定义它,就像在Numpy中使用np.array定义数组一样。这将创建TensorFlow使用的张量。
1 2 3 4 5 6 7 8 9 10 import tensorflow as tfkernel = tf.constant([ [-1 , -1 , -1 ], [-1 , 8 , -1 ], [-1 , -1 , -1 ], ]) plt.figure(figsize=(3 , 3 )) show_kernel(kernel)
TensorFlow在其tf.nn模块中包含神经网络执行的许多常见操作。我们将使用的两个是conv2d和relu。这些只是Keras层的函数版本。下一个隐藏单元会进行一些重新格式化,以使内容与TensorFlow兼容。
1 2 3 4 5 image = tf.image.convert_image_dtype(image, dtype=tf.float32) image = tf.expand_dims(image, axis=0 ) kernel = tf.reshape(kernel, [*kernel.shape, 1 , 1 ]) kernel = tf.cast(kernel, dtype=tf.float32)
现在让我们应用我们的内核,看看会发生什么。
1 2 3 4 5 6 7 8 9 10 11 12 image_filter = tf.nn.conv2d( input =image, filters=kernel, strides=1 , padding='SAME' , ) plt.figure(figsize=(6 , 6 )) plt.imshow(tf.squeeze(image_filter)) plt.axis('off' ) plt.show()
接下来是使用ReLU函数的检测步骤。该函数比卷积简单得多,因为它不需要设置任何参数。
1 2 3 4 5 6 image_detect = tf.nn.relu(image_filter) plt.figure(figsize=(6 , 6 )) plt.imshow(tf.squeeze(image_detect)) plt.axis('off' ) plt.show()
现在我们已经创建了一个特征图!像这样的图像是大脑用来解决分类问题的。我们可以想象,某些特征可能更具有汽车特征,而其他功能则更具有卡车特征。训练期间卷积网络的任务是创建可以找到这些特征的内核。
结论 我们看到了卷积网络用于执行特征提取的前两个步骤:使用Conv2D层进行过滤并使用relu激活进行检测。
最大池化(Maximum Pooling) 介绍 我们开始讨论卷积网络中的基础 如何执行特征提取。我们了解了此过程中的前两个操作如何在具有relu激活的Conv2D层中发生。在本课中,我们将了解此序列中的第三个(也是最后一个)操作:使用最大池进行压缩 ,这在Keras中由MaxPool2D层完成。
使用最大池化进行压缩 在我们之前的模型中添加压缩步骤,将得到:
1 2 3 4 5 6 7 8 from tensorflow import kerasfrom tensorflow.keras import layersmodel = keras.Sequential([ layers.Conv2D(filters=64 , kernel_size=3 ), layers.MaxPool2D(pool_size=2 ), ])
MaxPool2D层与Conv2D层非常相似,不同之处在于它使用简单的最大值函数而不是内核,其中pool_size参数类似于kernel_size。然而,MaxPool2D层不像其内核中的卷积层那样具有任何可训练权重。请记住,**MaxPool2D是压缩步骤**。
注意 ,应用ReLU函数(检测)后,特征图最终会出现大量“死区 ”,即仅包含0的大区域(图像中的黑色区域)。必须在整个网络中携带这些0激活会增加模型的大小,而不会添加太多有用的信息。相反,我们希望压缩特征图仅保留最有用的部分——特征本身 。这实际上就是最大池化的作用 。最大池化采用原始特征图中的激活补丁 ,并将其替换为该补丁中的最大激活值。
在ReLU激活后应用时,它具有“强化 ”特征的效果。池化步骤将活动像素的比例增加到零像素 。
举例 - 应用最大池化 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 import tensorflow as tfimport matplotlib.pyplot as pltimport warningsplt.rc('figure' , autolayout=True ) plt.rc('axes' , labelweight='bold' , labelsize='large' , titleweight='bold' , titlesize=18 , titlepad=10 ) plt.rc('image' , cmap='magma' ) warnings.filterwarnings("ignore" ) image_path = '../input/computer-vision-resources/car_feature.jpg' image = tf.io.read_file(image_path) image = tf.io.decode_jpeg(image) kernel = tf.constant([ [-1 , -1 , -1 ], [-1 , 8 , -1 ], [-1 , -1 , -1 ], ], dtype=tf.float32) image = tf.image.convert_image_dtype(image, dtype=tf.float32) image = tf.expand_dims(image, axis=0 ) kernel = tf.reshape(kernel, [*kernel.shape, 1 , 1 ]) image_filter = tf.nn.conv2d( input =image, filters=kernel, strides=1 , padding='SAME' ) image_detect = tf.nn.relu(image_filter) plt.figure(figsize=(12 , 6 )) plt.subplot(131 ) plt.imshow(tf.squeeze(image), cmap='gray' ) plt.axis('off' ) plt.title('Input' ) plt.subplot(132 ) plt.imshow(tf.squeeze(image_filter)) plt.axis('off' ) plt.title('Filter' ) plt.subplot(133 ) plt.imshow(tf.squeeze(image_detect)) plt.axis('off' ) plt.title('Detect' ) plt.show();
我们将使用tf.nn中的另一个函数tf.nn.pool来应用池化步骤。这是一个Python函数,与模型构建时使用的MaxPool2D层执行相同的操作,但作为一个简单的函数,更容易直接使用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import tensorflow as tfimage_condense = tf.nn.pool( input =image_detect, window_shape=(2 , 2 ), pooling_type='MAX' , strides=(2 , 2 ), padding='SAME' , ) plt.figure(figsize=(6 , 6 )) plt.imshow(tf.squeeze(image_condense)) plt.axis('off' ) plt.show();
很酷!希望您能够看到池化步骤如何通过压缩最活跃像素周围的图像来增强特征 。
平移不变性(Translation Invariance) 我们称零像素“不重要”。这是否意味着它们根本不携带任何信息?事实上,零像素携带位置信息。空白区域仍将特征定位在图像内。当MaxPool2D删除其中一些像素时,它会删除特征图中的一些位置信息。这赋予了卷积网络一种称为平移不变性的属性。这意味着具有最大池化的卷积网络往往不会根据特征在图像中的位置来区分特征。(“平移 ”是一个数学词,指的是在不旋转某物或改变其形状或大小的情况下改变某物的位置。)观察当我们重复将最大池化应用于以下特征图时会发生什么。
经过反复池化后,原始图像中的两个点变得无法区分。换句话说,池化会破坏它们的一些位置信息。由于网络无法再在特征图中区分它们,因此它也无法在原始图像中区分它们:它已经变得对位置差异具有不变性。事实上,池化仅在网络中的小距离上产生平移不变性,就像图像中的两个点一样。开始时相距甚远的特征在合并后仍将保持明显;仅丢失一些位置信息,但不是全部。
这种特征位置微小差异的不变性对于图像分类器来说是一个很好的特性。仅仅由于视角或取景的差异,相同类型的特征可能位于原始图像的不同部分,但我们仍然希望分类器能够识别它们是相同的。由于这种不变性内置于网络中,因此我们可以使用更少的数据进行训练:我们不再需要教它忽略这种差异。这使得卷积网络比只有密集层的网络具有更大的效率优势。
结论 我们学习了特征提取的最后一步:使用MaxPool2D进行压缩。
滑动窗口(The Sliding Window) 介绍 我们学习了从图像中进行特征提取的三种操作:
带卷积层的滤波器。
使用ReLU激活进行检测。
使用最大池化层进行压缩。
卷积和池化操作有一个共同的特点:它们都是在滑动窗口上执行的 。对于卷积,这个“窗口”由内核的尺寸(参数kernel_size)给出。对于池化,它是池化窗口,由pool_size给出。
还有两个影响卷积层和池化层的附加参数——窗口的步幅以及是否在图像边缘使用填充 。strides参数表示窗口每一步应移动多远,padding参数描述我们如何处理输入边缘的像素。有了这两个参数,定义两层就变成了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 import numpy as npfrom itertools import productfrom skimage import draw, transformfrom tensorflow import kerasfrom tensorflow.keras import layersdef circle (size, val=None , r_shrink=0 ): circle = np.zeros([size[0 ]+1 , size[1 ]+1 ]) rr, cc = draw.circle_perimeter( size[0 ]//2 , size[1 ]//2 , radius=size[0 ]//2 - r_shrink, shape=[size[0 ]+1 , size[1 ]+1 ], ) if val is None : circle[rr, cc] = np.random.uniform(size=circle.shape)[rr, cc] else : circle[rr, cc] = val circle = transform.resize(circle, size, order=0 ) return circle def show_kernel (kernel, label=True , digits=None , text_size=28 ): kernel = np.array(kernel) if digits is not None : kernel = kernel.round (digits) cmap = plt.get_cmap('Blues_r' ) plt.imshow(kernel, cmap=cmap) rows, cols = kernel.shape thresh = (kernel.max ()+kernel.min ())/2 if label: for i, j in product(range (rows), range (cols)): val = kernel[i, j] color = cmap(0 ) if val > thresh else cmap(255 ) plt.text(j, i, val, color=color, size=text_size, horizontalalignment='center' , verticalalignment='center' ) plt.xticks([]) plt.yticks([]) def show_extraction (image, kernel, conv_stride=1 , conv_padding='valid' , activation='relu' , pool_size=2 , pool_stride=2 , pool_padding='same' , figsize=(10 , 10 subplot_shape=(2 , 2 ops=['Input' , 'Filter' , 'Detect' , 'Condense' ], gamma=1.0 ): model = tf.keras.Sequential([ tf.keras.layers.Conv2D( filters=1 , kernel_size=kernel.shape, strides=conv_stride, padding=conv_padding, use_bias=False , input_shape=image.shape, ), tf.keras.layers.Activation(activation), tf.keras.layers.MaxPool2D( pool_size=pool_size, strides=pool_stride, padding=pool_padding, ), ]) layer_filter, layer_detect, layer_condense = model.layers kernel = tf.reshape(kernel, [*kernel.shape, 1 , 1 ]) layer_filter.set_weights([kernel]) image = tf.expand_dims(image, axis=0 ) image = tf.image.convert_image_dtype(image, dtype=tf.float32) image_filter = layer_filter(image) image_detect = layer_detect(image_filter) image_condense = layer_condense(image_detect) images = {} if 'Input' in ops: images.update({'Input' : (image, 1.0 )}) if 'Filter' in ops: images.update({'Filter' : (image_filter, 1.0 )}) if 'Detect' in ops: images.update({'Detect' : (image_detect, gamma)}) if 'Condense' in ops: images.update({'Condense' : (image_condense, gamma)}) plt.figure(figsize=figsize) for i, title in enumerate (ops): image, gamma = images[title] plt.subplot(*subplot_shape, i+1 ) plt.imshow(tf.image.adjust_gamma(tf.squeeze(image), gamma)) plt.axis('off' ) plt.title(title) model = keras.Sequential([ layers.Conv2D(filters=64 , kernel_size=3 , strides=1 , padding='same' , activation='relu' ), layers.MaxPool2D(pool_size=2 , strides=1 , padding='same' ) ])
Stride 窗口每一步移动的距离称为步幅 。我们需要指定图像两个维度的步幅:一种用于从左到右移动,一种用于从上到下移动。该动画显示strides=(2, 2),每步移动2个像素。
步幅 有什么作用?每当任一方向的步幅大于1时,滑动窗口都会在每一步跳过输入中的一些像素。因为我们希望使用高质量的特征进行分类,所以卷积层通常具有步长=(1, 1)。增加步幅意味着我们会错过摘要中潜在的有价值的信息。然而,最大池化层的步幅值几乎总是大于1,如(2, 2)或(3, 3),但不能大于窗口本身。最后需要注意的是,当两个方向的步幅值相同时,只需设置该数字即可;例如,您可以使用strides=2来代替strides=(2, 2)进行参数设置。
Padding 在执行滑动窗口计算时,存在一个问题:在输入的边界处做什么。完全留在输入图像内部意味着窗口永远不会像输入中的每个其他像素一样正好位于这些边界像素上方。由于我们没有以完全相同的方式对待所有像素,是否会出现问题?卷积对这些边界值的作用由其填充参数决定。在TensorFlow中,您有两种选择:padding='same'或padding='valid'。每一个都需要权衡。当我们设置 padding='valid'时,卷积窗口将完全保留在输入内部。缺点是输出会缩小(丢失像素),并且对于较大的内核,缩小得更多。这将限制网络可以包含的层数,特别是当输入尺寸较小时。另一种方法是使用padding='same'。这里的技巧是在输入的边界周围填充0,使用足够的0使输出的大小与输入的大小相同。然而,这可以具有削弱边界处像素的影响的效果。下面的动画显示了具有“相同”填充的滑动窗口。
我们一直在研究的VGG模型对其所有卷积层使用相同的填充。大多数现代卷积网络都会使用两者的某种组合。
举例 - 探索滑动窗口 为了更好地理解滑动窗口参数的影响,它可以帮助观察低分辨率图像上的特征提取,以便我们可以看到各个像素。让我们看一个简单的圆。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import tensorflow as tfimport matplotlib.pyplot as pltplt.rc('figure' , autolayout=True ) plt.rc('axes' , labelweight='bold' , labelsize='large' , titleweight='bold' , titlesize=18 , titlepad=10 ) plt.rc('image' , cmap='magma' ) image = circle([64 , 64 ], val=1.0 , r_shrink=3 ) image = tf.reshape(image, [*image.shape, 1 ]) kernel = tf.constant( [[-1 , -2 , -1 ], [0 , 0 , 0 ], [1 , 2 , 1 ]], ) show_kernel(kernel)
VGG架构相当简单。它使用步幅为1的卷积、最大池化2 × 2窗口和步幅为2。我们在Visiontools程序脚本中包含了一个函数,该函数将向我们显示所有步骤。
1 2 3 4 5 6 7 8 9 10 11 show_extraction( image, kernel, conv_stride=1 , pool_size=2 , pool_stride=2 , subplot_shape=(1 , 4 ), figsize=(14 , 6 ), )
这效果非常好!内核被设计用来检测水平线,我们可以看到在生成的特征图中,输入的更多水平部分最终具有最大的激活。如果我们将卷积的步长改为3会发生什么?
1 2 3 4 5 6 7 8 9 10 11 show_extraction( image, kernel, conv_stride=3 , pool_size=2 , pool_stride=2 , subplot_shape=(1 , 4 ), figsize=(14 , 6 ), )
这似乎降低了提取的特征的质量。我们的输入圆相当“精细”,只有1像素宽。步长为3的卷积太粗糙,无法从中生成良好的特征图。有时,模型会在其初始层中使用步幅较大的卷积。这通常也会与更大的内核结合使用。例如,ResNet50模型使用7×7第一层步幅为2的内核。这似乎加速了大规模特征的生成,而无需牺牲输入中的太多信息。
结论 我们研究了卷积和池化 共有的特征计算:滑动窗口和影响其在这些层中行为的参数 。 这种窗口计算风格贡献了卷积网络的大部分特征,并且是其功能的重要组成部分。
定制卷积网络 我们了解了卷积网络如何通过三个操作来执行特征提取:过滤、检测和压缩 。单轮特征提取只能从图像中提取相对简单的特征,例如简单的线条或对比度。这些对于解决大多数分类问题来说太简单了。相反,卷积网络将一遍又一遍地重复这种提取,以便特征随着它们深入网络而变得更加复杂和精致。
卷积块(Convolutional Blocks) 它通过将它们传递到执行提取的长卷积块链来实现这一点。
这些卷积块是Conv2D和MaxPool2D层的堆栈。
每个块代表一轮提取,通过组合这些块,卷积网络可以组合和重新组合生成的特征,对它们进行增长和整形,以更好地适应当前的问题。现代卷积网络的深层结构使得这种复杂的特征工程成为可能,并在很大程度上保证了它们的卓越性能。
举例 - 设计一个 Convnet 让我们看看如何定义能够设计复杂特征的深度卷积网络 。在此例子中,我们将创建一个Keras序列模型,然后在我们的Cars数据集上对其进行训练。
第1步 - 加载数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 import os, warningsimport matplotlib.pyplot as pltfrom matplotlib import gridspecimport numpy as npimport tensorflow as tffrom tensorflow.keras.preprocessing import image_dataset_from_directorydef set_seed (seed=31415 ): np.random.seed(seed) tf.random.set_seed(seed) os.environ['PYTHONHASHSEED' ] = str (seed) os.environ['TF_DETERMINISTIC_OPS' ] = '1' set_seed() plt.rc('figure' , autolayout=True ) plt.rc('axes' , labelweight='bold' , labelsize='large' , titleweight='bold' , titlesize=18 , titlepad=10 ) plt.rc('image' , cmap='magma' ) warnings.filterwarnings("ignore" ) ds_train_ = image_dataset_from_directory( '../input/car-or-truck/train' , labels='inferred' , label_mode='binary' , image_size=[128 , 128 ], interpolation='nearest' , batch_size=64 , shuffle=True , ) ds_valid_ = image_dataset_from_directory( '../input/car-or-truck/valid' , labels='inferred' , label_mode='binary' , image_size=[128 , 128 ], interpolation='nearest' , batch_size=64 , shuffle=False , ) def convert_to_float (image, label ): image = tf.image.convert_image_dtype(image, dtype=tf.float32) return image, label AUTOTUNE = tf.data.experimental.AUTOTUNE ds_train = ( ds_train_ .map (convert_to_float) .cache() .prefetch(buffer_size=AUTOTUNE) ) ds_valid = ( ds_valid_ .map (convert_to_float) .cache() .prefetch(buffer_size=AUTOTUNE) )
第2步 - 定义模型 这是我们将使用的模型的图表:
现在我们将定义模型。了解我们的模型如何由三个Conv2D和MaxPool2D层块(基础层)和后面的Dense层头组成。只需填写适当的参数,我们就可以或多或少地将该图直接转换为Keras序列模型。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from tensorflow import kerasfrom tensorflow.keras import layersmodel = keras.Sequential([ layers.Conv2D(filters=32 , kernel_size=5 , activation="relu" , padding='same' , input_shape=[128 , 128 , 3 ]), layers.MaxPool2D(), layers.Conv2D(filters=64 , kernel_size=3 , activation="relu" , padding='same' ), layers.MaxPool2D(), layers.Conv2D(filters=128 , kernel_size=3 , activation="relu" , padding='same' ), layers.MaxPool2D(), layers.Flatten(), layers.Dense(units=6 , activation="relu" ), layers.Dense(units=1 , activation="sigmoid" ), ]) model.summary()
结果输出为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 Model: "sequential" _________________________________________________________________ Layer (type ) Output Shape Param ================================================================= conv2d (Conv2D) (None, 128, 128, 32) 2432 max_pooling2d (MaxPooling2D (None, 64, 64, 32) 0 ) conv2d_1 (Conv2D) (None, 64, 64, 64) 18496 max_pooling2d_1 (MaxPooling (None, 32, 32, 64) 0 2D) conv2d_2 (Conv2D) (None, 32, 32, 128) 73856 max_pooling2d_2 (MaxPooling (None, 16, 16, 128) 0 2D) flatten (Flatten) (None, 32768) 0 dense (Dense) (None, 6) 196614 dense_1 (Dense) (None, 1) 7 ================================================================= Total params: 291,405 Trainable params: 291,405 Non-trainable params: 0 _________________________________________________________________
请注意 ,在此定义中,滤波器的数量如何逐块加倍:32、64、128。这是一种常见模式。由于MaxPool2D层正在减小特征图的大小,因此我们可以增加创建的数量。
第3步 - 训练 我们可以训练该模型:使用优化器以及适合二元分类的损失和指标对其进行编译。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import pandas as pdmodel.compile ( optimizer=tf.keras.optimizers.Adam(epsilon=0.01 ), loss='binary_crossentropy' , metrics=['binary_accuracy' ] ) history = model.fit( ds_train, validation_data=ds_valid, epochs=40 , verbose=0 , ) history_frame = pd.DataFrame(history.history) history_frame.loc[:, ['loss' , 'val_loss' ]].plot() history_frame.loc[:, ['binary_accuracy' , 'val_binary_accuracy' ]].plot()
该模型比VGG16模型小得多——只有3个卷积层,而VGG16有16个。尽管如此,它还是能够很好地拟合这个数据集。我们仍然可以通过添加更多的卷积层来改进这个简单的模型,希望创建更好地适应数据集的特征。这就是我们将在练习中尝试的内容。
结论 您了解了如何构建由许多卷积块 组成并能够进行复杂特征工程的自定义卷积网络 。
数据增强(Data Augmentation) 介绍 现在您已经学习了卷积分类器的基础知识。接下来,您将学习一个可以增强图像分类器的技巧:它称为数据增强 。
假数据的用途 提高机器学习模型性能的最佳方法是使用更多数据对其进行训练。模型学习的例子越多,它就越能够识别图像中哪些差异重要,哪些差异不重要。更多数据有助于模型更好地泛化。获取更多数据的一种简单方法是使用已有的数据。如果我们能够以保留类别的方式转换数据集中的图像,我们就可以教我们的分类器忽略这些类型的转换。例如,无论汽车在照片中朝左还是朝右,都不会改变它是汽车而不是卡车的事实。因此,如果我们用翻转图像来增强训练数据,我们的分类器将了解到“左或右”是它应该忽略的差异。这就是数据增强背后的整个想法:添加一些看起来相当像真实数据的额外假数据,你的分类器将会得到改进 。
使用数据增强 通常,在扩充数据集时会使用多种转换。这些可能包括旋转图像、调整颜色或对比度、扭曲图像或许多其他通常组合应用的操作。以下是单个图像可能被转换的不同方式的示例。
数据增强 通常是在线完成的,这意味着图像被输入网络进行训练。回想一下,训练通常是在小批量数据上完成的。这就是使用数据增强时一批16张图像的样子。
每次在训练过程中使用图像时,都会应用新的随机变换。这样,模型看到的东西总是与之前看到的有所不同。训练数据中的这种额外差异有助于模型处理新数据。但重要的是要记住,并非所有转换都对给定问题有用。最重要的是,无论您使用什么转换,都不应该混淆这些类。例如,如果您正在训练数字识别器,旋转图像会混淆“9”和“6”。最后,寻找良好增强的最佳方法与大多数机器学习问题相同。
第1步 - 加载数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 import os, warningsimport matplotlib.pyplot as pltfrom matplotlib import gridspecimport numpy as npimport tensorflow as tffrom tensorflow.keras.preprocessing import image_dataset_from_directorydef set_seed (seed=31415 ): np.random.seed(seed) tf.random.set_seed(seed) os.environ['PYTHONHASHSEED' ] = str (seed) set_seed() plt.rc('figure' , autolayout=True ) plt.rc('axes' , labelweight='bold' , labelsize='large' , titleweight='bold' , titlesize=18 , titlepad=10 ) plt.rc('image' , cmap='magma' ) warnings.filterwarnings("ignore" ) ds_train_ = image_dataset_from_directory( '../input/car-or-truck/train' , labels='inferred' , label_mode='binary' , image_size=[128 , 128 ], interpolation='nearest' , batch_size=64 , shuffle=True , ) ds_valid_ = image_dataset_from_directory( '../input/car-or-truck/valid' , labels='inferred' , label_mode='binary' , image_size=[128 , 128 ], interpolation='nearest' , batch_size=64 , shuffle=False , ) def convert_to_float (image, label ): image = tf.image.convert_image_dtype(image, dtype=tf.float32) return image, label AUTOTUNE = tf.data.experimental.AUTOTUNE ds_train = ( ds_train_ .map (convert_to_float) .cache() .prefetch(buffer_size=AUTOTUNE) ) ds_valid = ( ds_valid_ .map (convert_to_float) .cache() .prefetch(buffer_size=AUTOTUNE) )
第2步 - 定义模型 为了说明增强的效果,我们只需添加几个简单的转换。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from tensorflow import kerasfrom tensorflow.keras import layersfrom tensorflow.keras.layers.experimental import preprocessingpretrained_base = tf.keras.models.load_model( '../input/cv-course-models/cv-course-models/vgg16-pretrained-base' , ) pretrained_base.trainable = False model = keras.Sequential([ preprocessing.RandomFlip('horizontal' ), preprocessing.RandomContrast(0.5 ), pretrained_base, layers.Flatten(), layers.Dense(6 , activation='relu' ), layers.Dense(1 , activation='sigmoid' ), ])
第3步 - 训练和评估 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import pandas as pdmodel.compile ( optimizer='adam' , loss='binary_crossentropy' , metrics=['binary_accuracy' ], ) history = model.fit( ds_train, validation_data=ds_valid, epochs=30 , verbose=0 , ) history_frame = pd.DataFrame(history.history) history_frame.loc[:, ['loss' , 'val_loss' ]].plot() history_frame.loc[:, ['binary_accuracy' , 'val_binary_accuracy' ]].plot();
训练和验证曲线很快就出现了分歧,这表明它可以从一些正则化中受益 。该模型的学习曲线能够保持更紧密的联系,并且我们在验证损失和准确性方面取得了一些适度的改进。这表明数据集确实受益于增强。