特征工程实践之—房价预测
第1步 - 准备工作
导入和配置
我们将首先导入使用的包并设置一些笔记本默认值。
1 | import os |
数据预处理
在进行任何特征工程之前,我们需要对数据进行预处理,以使其成为适合分析的形式。我们在课程中使用的数据比比赛数据简单一些。对于艾姆斯竞赛数据集,我们需要:
- 从
CSV文件加载数据。 - 清理数据以修复任何错误或不一致。
- 对统计数据类型(数字、分类)进行编码。
- 估算任何缺失值。
加载数据
我们将把所有这些步骤包装在一个函数中,这将使您可以在需要时轻松获得新的数据帧。读取CSV文件后,我们将应用三个预处理步骤:清理、编码和插补,然后创建数据分割:一个 (df_train) 用于训练模型,另一个 (df_test) 用于进行预测。
1 | def load_data(): |
清理数据
该数据集中的一些分类特征在其类别中存在明显的拼写错误:
1 | data_dir = Path("../input/house-prices-advanced-regression-techniques/") |
结果输出为:
1 | array(['VinylSd', 'MetalSd', 'Wd Shng', 'HdBoard', 'Plywood', 'Wd Sdng', |
将它们与data_description.txt进行比较可以向我们展示哪些内容需要清理。我们将在这里解决几个问题,但您可能需要进一步评估这些数据。
1 | def clean(df): |
对统计数据类型进行编码
Pandas具有与标准统计类型(数值、分类等)相对应的Python类型。使用正确的类型对每个特征进行编码有助于确保我们使用的任何函数都适当地处理每个特征,并使我们更容易一致地应用转换。该隐藏单元定义了编码函数:
1 | # The numeric features are already encoded correctly (`float` for |
处理缺失值
现在处理缺失值将使特征工程进行得更加顺利。我们将缺失数值归为0,将缺失分类值归为“无”。您可能想尝试其他插补策略。特别是,您可以尝试创建“缺失值”指标:每当估算值时为1,否则为 0。
1 | def impute(df): |
加载数据
现在我们可以调用数据加载器并获取处理后的数据分割:
1 | df_train, df_test = load_data() |
如果您想查看它们包含的内容,请取消注释并运行此单元格。请注意,df_test缺少SalePrice值。(在插补步骤中NA被设为0。)
建立基线
最后,让我们建立一个基线分数来判断我们的特征工程。它将计算功能集的交叉验证RMSLE分数。我们的模型使用了XGBoost,但您可以想尝试其他模型。
1 | def score_dataset(X, y, model=XGBRegressor()): |
当我们想要尝试新的特征集时,我们可以随时重用这个评分函数。我们现在将在没有附加功能的处理数据上运行它并获得基线分数:
1 | X = df_train.copy() |
结果输出为:
1 | Baseline score: 0.14302 RMSLE |
这个基线分数可以帮助我们了解我们组装的某些特征是否实际上带来了任何改进。
第2步 - 特征有效分值
我们了解了如何使用互信息来计算某个特征的有效分值,让您了解该特征的潜力有多大。
1 | def make_mi_scores(X, y): |
让我们再次看看我们的特征得分:
1 | X = df_train.copy() |
结果输出为:
1 | OverallQual 0.571457 |
您可以看到,我们有许多信息丰富的特征,但也有一些特征似乎根本没有信息(至少其本身)。得分最高的特征通常会在特征开发过程中获得最大的回报,因此将精力集中在这些特征上可能是个好主意。 另一方面,对无信息特征的训练可能会导致过度拟合。因此,我们将完全放弃得分为0.0的特征:
1 | def drop_uninformative(df, mi_scores): |
删除它们确实会带来一定的性能提升:
1 | X = df_train.copy() |
结果输出为:
1 | 0.14274827027030276 |
稍后,我们会将drop_uninformative函数添加到我们的特征创建管道中。
第3步 - 创建特征
现在我们将开始开发我们的特征集。为了使我们的特征工程工作流程更加模块化,我们将定义一个函数,该函数将获取准备好的数据帧并将其通过转换管道传递以获得最终的特征集。它看起来像这样:
1 | def create_features(df): |
现在让我们继续定义一个转换,即分类特征的标签编码:
1 | def label_encode(df): |
当您使用像XGBoost这样的树集成时,标签编码适用于任何类型的分类特征,即使对于无序类别也是如此。如果您想尝试线性回归模型,您可能会想使用one-hot编码,特别是对于具有无序类别的特征。
使用 Pandas 创建特征
1 | def mathematical_transforms(df): |
以下是您可以探索其他的一些想法:
- 质量
Qual和条件Cond特征之间的相互作用。例如,OverallQual就是一个高分特征。您可以尝试将其与OverallCond结合起来,方法是将两者都转换为整数类型并取一个乘积。 - 面积特征的平方根。这会将平方英尺的单位转换为英尺。
- 数字特征的对数。如果某个特征具有偏态分布,则应用对数可以帮助将其标准化。
- 描述同一事物的数字特征和分类特征之间的相互作用。例如,您可以查看
BsmtQual和TotalBsmtSF之间的交互。 Neighborhood中的其他群体统计数据。我们做了GrLivArea的中位数。查看平均值、标准差或计数可能会很有趣。您还可以尝试将组统计数据与其他功能结合起来。也许GrLivArea和中位数的差异很重要?
k均值聚类
我们用来创建特征的第一个无监督算法是k均值聚类。我们看到,您可以使用聚类标签作为特征(包含 0、1、2、… 的列),也可以使用观测值到每个聚类的距离。我们看到这些特征有时如何有效地理清复杂的空间关系。
1 | cluster_features = [ |
主成分分析
PCA是我们用于特征创建的第二个无监督模型。我们看到了如何使用它来分解数据中的变分结构。PCA算法为我们提供了描述变化的每个组成部分的载荷,以及转换后的数据点的组成部分。负载可以建议要创建的特征以及我们可以直接用作特征的成分。
1 | def apply_pca(X, standardize=True): |
其他特征变化
1 | def pca_inspired(df): |
这些只是使用主要成分的几种方法。您还可以尝试使用一个或多个成分进行组合。需要注意的一件事是,PCA不会改变点之间的距离——它就像旋转一样。因此,使用全套成分进行聚类与使用原始特征进行聚类相同。相反,选择成分的一些子集,可能是方差最大或MI分数最高的成分。为了进一步分析,您可能需要查看数据集的相关矩阵:
1 | def corrplot(df, method="pearson", annot=True, **kwargs): |
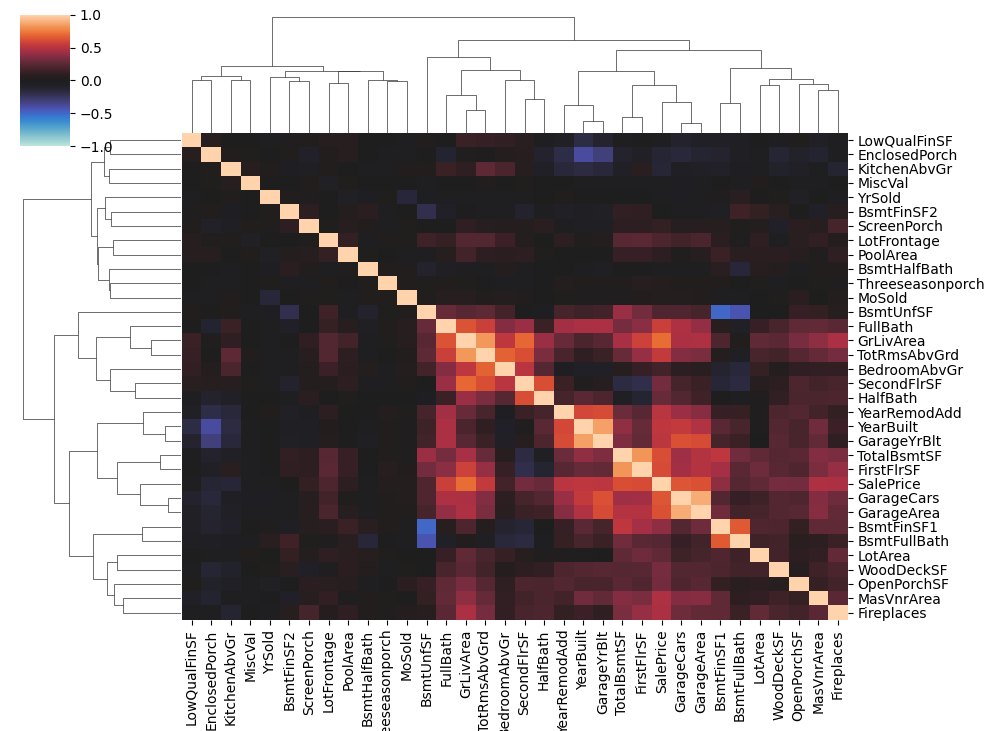
高度相关的特征组通常会产生有趣的负载。
PCA 应用 - 指示异常值
您应用了PCA来确定异常值的房屋,即房屋的值在其余数据中没有得到很好的体现。您看到爱德华兹附近有一组房屋的销售条件为“部分”,其价值特别极端。某些模型可以从指示这些异常值中受益,这就是下一个转换将要做的事情。
1 | def indicate_outliers(df): |
您还可以考虑将scikit-learn的sklearn.preprocessing模块中的某种强大的缩放器应用于外围值,尤其是GrLivArea中的值。这是一个说明其中一些的教程。另一种选择可能是使用 scikit-learn的异常值检测器之一创建“异常值分数”特征。
目标编码
需要单独的保留集来创建目标编码是相当浪费数据的。我们使用了25%的数据集来对单个特征(邮政编码)进行编码。我们根本没有使用那25%中其他特征的数据。然而,有一种方法可以使用目标编码,而不必使用保留的编码数据。 这基本上与交叉验证中使用的技巧相同:
- 将数据拆分为折叠,每个折叠都有数据集的两个分割。
- 在一个分割上训练编码器,但转换另一个分割的值。对所有分割重复此操作。
这样,训练和转换始终在独立的数据集上进行,就像使用保留集但不会浪费任何数据一样。 下面是一个包装器:
1 | class CrossFoldEncoder: |
像这样:
1 | encoder = CrossFoldEncoder(MEstimateEncoder, m=1) |
您可以将category_encoders库中的任何编码器转换为交叉折叠编码器。CatBoostEncoder值得尝试。 它与MEstimateEncoder类似,但使用一些技巧来更好地防止过度拟合。其平滑参数称为a而不是m。
创建最终的特征集
现在让我们将所有内容组合在一起。将转换放入单独的函数中可以更轻松地尝试各种组合。我发现那些未注释的结果给出了最好的结果。不过,您应该尝试自己的想法!修改任何这些转换或提出一些您自己的转换以添加到管道中。
1 | def create_features(df, df_test=None): |
结果输出为:
1 | 0.13863986787521657 |
第 4 步 - 超参数调整
在此阶段,您可能希望在创建最终提交之前使用XGBoost进行一些超参数调整:
1 | X_train = create_features(df_train) |
结果输出为:
1 | 0.12417177287599078 |
只需手动调整这些即可给您带来很好的结果。但是,您可能想尝试使用scikit-learn的自动超参数调整器之一。或者您可以探索更高级的调优库,例如Optuna或scikit-optimize。以下是将Optuna与XGBoost结合使用的方法:
1 | import optuna |
第 5 步 - 训练模型并创建提交
一旦您对此感到满意,就可以创建最终预测了:
- 从原始数据创建您的特征集
- 在训练数据上训练
XGBoost使用经过训练的模型从测试集中进行预测- 将预测保存到
CSV文件
1 | X_train, X_test = create_features(df_train, df_test) |