数据可视化(Seaborn)
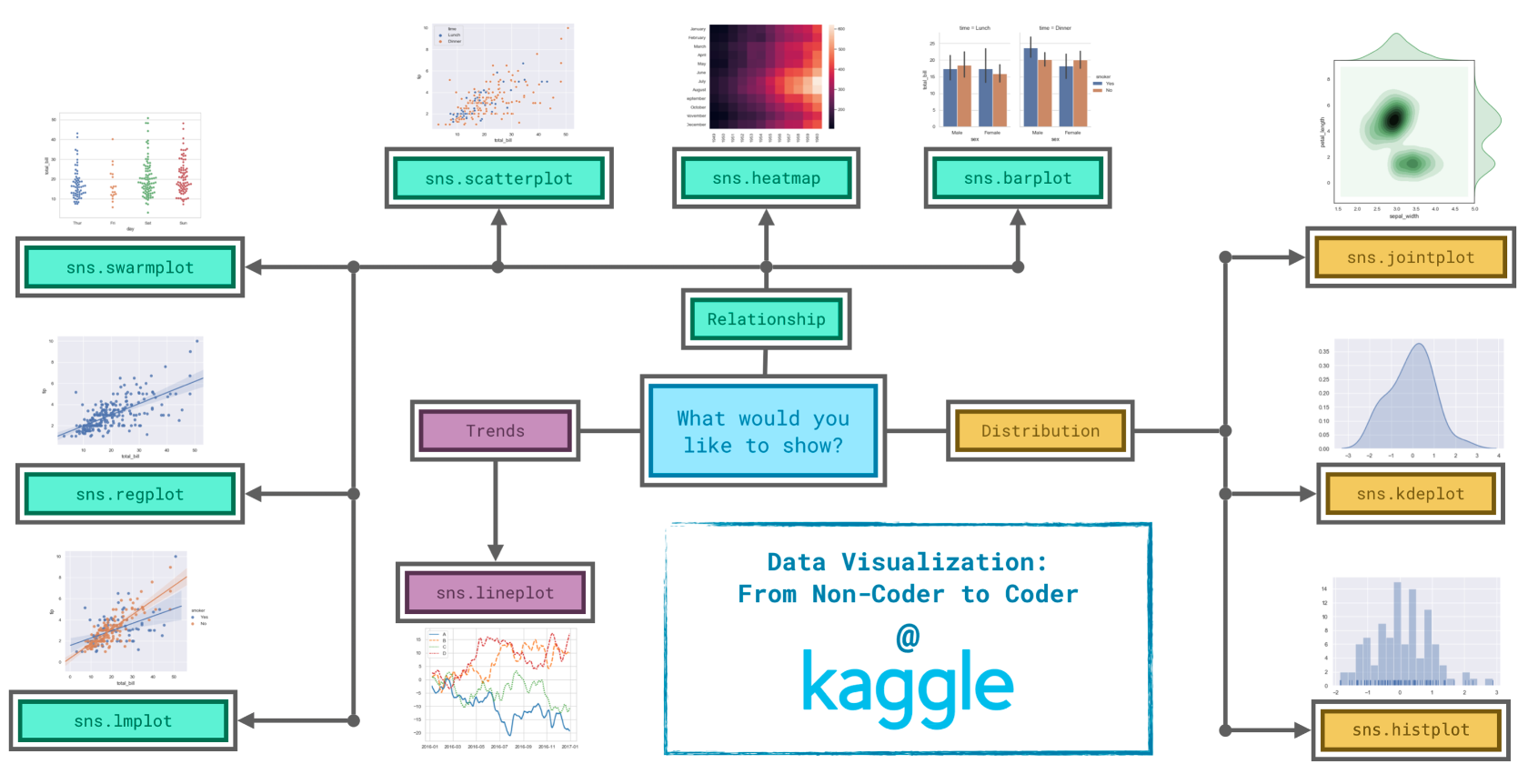
如何最好地讲述数据背后的故事并不总是那么容易,因此我们将图表类型分为三大类来帮助解决这一问题。
Trends(趋势):趋势被定义为变化的模式。sns.lineplot- 折线图最能显示一段时间内的趋势,并且可以使用多条线来显示多个组中的趋势。
Relationship(关系):您可以使用许多不同的图表类型来了解数据中变量之间的关系。sns.barplot- 条形图可用于比较不同组对应的数量。sns.heatmap- 热图可用于在数字表中查找颜色编码模式。sns.scatterplot- 散点图显示两个连续变量之间的关系;如果用颜色编码,我们还可以显示与第三个分类变量的关系。sns.regplot- 在散点图中包含回归线可以更轻松地查看两个变量之间的任何线性关系。sns.lmplot- 如果散点图包含多个颜色编码组,则此命令对于绘制多条回归线非常有用。sns.swarmplot- 分类散点图显示连续变量和分类变量之间的关系。
Distribution(分布):我们将分布可视化以显示我们期望在变量中看到的可能值以及它们的可能性。sns.histplot- 直方图显示单个数值变量的分布。sns.kdeplot-KDE图(或2D KDE图)显示单个数值变量(或两个数值变量)的估计平滑分布。sns.jointplot- 此命令对于同时显示2D KDE图和每个单独变量的相应KDE图。
1 | import pandas as pd |