有效地处理从pandas到Pytorch的表格数据集中的数千个特征
在实践中,传统的表格数据的形状为(batch_size, feat_1, feat_2,…feat_N),其中N是任意大的。当有数千个特征(例如,N>1000)时,很难知道Pytorch张量中的哪些列索引对应于哪个特征。以及如何为神经网络架构应用适当的Pytorch模块。
- 数据科学家通常使用
pandas DataFrame进行必要的数据探索、数据处理和特征工程,然后将其转换为Pytorch张量以构建Pytorch数据集。使用pandas的一些主要好处是它有一个简单的API。 - Pytorch模型要求输入数据类型为
torch.Tensor。但是,当我们将pandas DataFrame转换为Pytorch张量后,我们失去了能够轻松查找数据集中特征的能力。 - 如果我们想要得到
feature对应的数据gender,使用pandas我们会这样做df[‘gender’],但是对于Pytorch Tensor,我们必须计算列数来找到列索引:X[:,3]。 - 如果我们有数千个特征,而性别只是其中之一,我们可以清楚地看到它是无法做到的。
学习和实践存在差距:
- 网络资源以简单易懂的方式解释概念,对实际应用的重视不够。
- 专注于深度学习的学习资源往往聚焦于自然语言处理和计算机视觉。
结论:学习高级实践或技术的唯一方法是深入研究在线社区共享的原始Github代码或学习行业经验(由导师指导)。
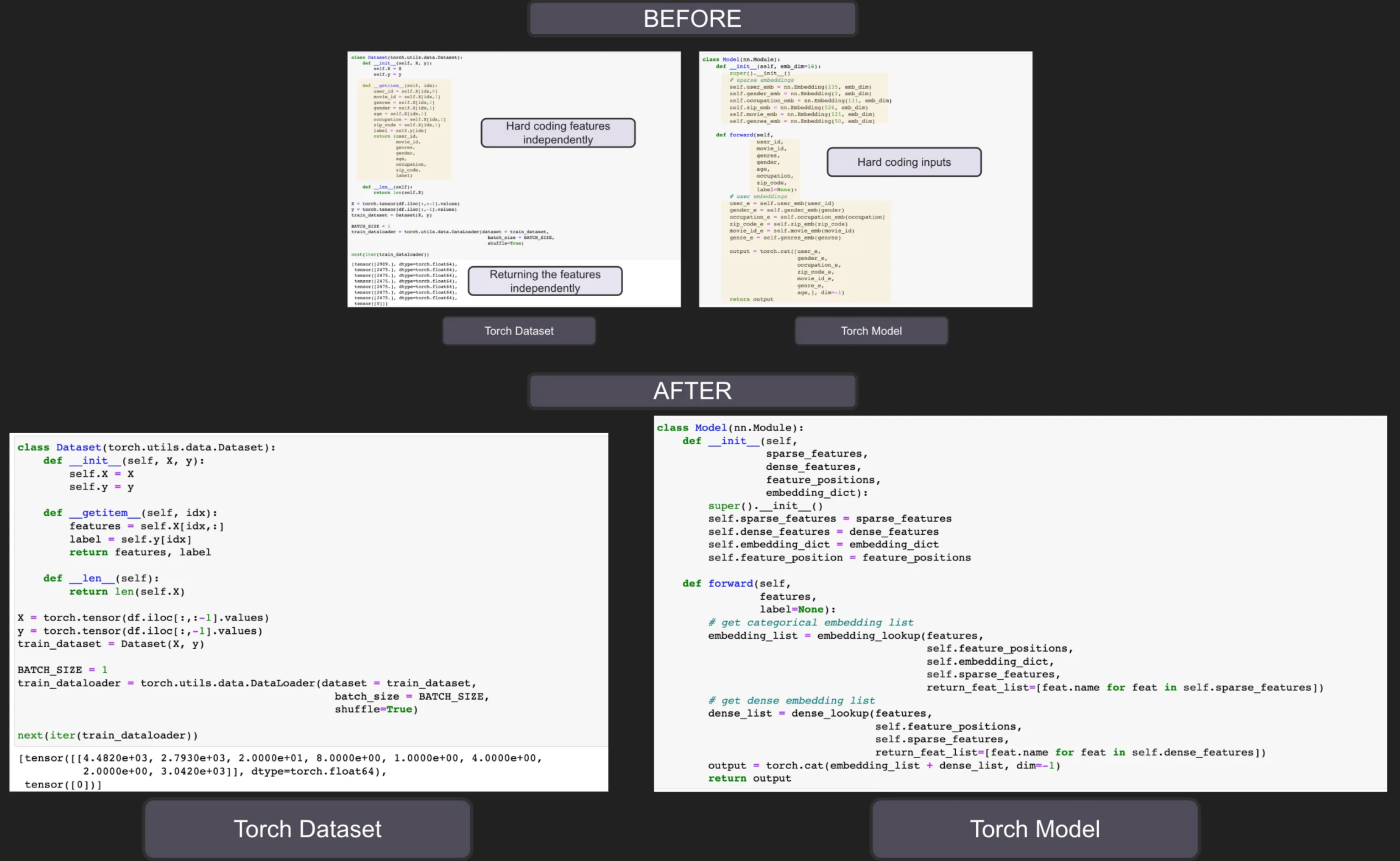
初学者处理从Pandas到PyTorch的数据
通常从在线学习资源中看到的内容,在将pandas DataFrame转换为Pytorch张量之后,他们下一步会告诉你是创建一个torch.utils.data.Dataset用于批量梯度下降,也是为了管理内存。最常见的方法是torch.utils.data.Dataset独立输出每个特征,然后我们用它来创建模型:
Torch Dataset:
1 | import pandas as pd |
Torch Model:
1 | class Model(nn.Module): |
- 我们目前只有
7个特征,代码看起来很长,而且要写很多重复的代码。试想一下,如果我们有1000个特征。我们是否要编写1000行代码只是为了获取torch数据集中的特征,并且我们是否要对1000个参数使用1000个实参? - 我们手动初始化
nn.Embedding每个分类特征的a,同时手动输入词汇量大小。如果我们有1000个分类特征,我们要写1000行吗? - 我们通常将这些输入特征连接成一个张量作为线性层的输入。我们是否要手动连接
1000个特征,从而有效地编写另外1000行重复代码?
经验丰富的数据科学家处理从Pandas到PyTorch的数据
他们观察到:
- 获取与自己想要的特征对应的
torch张量是一个烦人的过程。 - 创建嵌入是一个重复的过程
- 连接他们想要的特征是一个烦人的过程。
他们将利用Python数据结构来帮助他们有效地管理代码。
1.创建一个字典来存储所有词汇
- 当初始化分类特征的
nn.Embedding时,需要所有词汇量大小。 - 为了不手动跟踪每个分类特征的词汇大小,我们创建一个包含每个分类列的词汇大小的字典。
1 | def get_vocabularies(df: pd.DataFrame, categorical_columns: list): |
2.创建字典来存储嵌入维度
- 初始化
nn.Embedding时,我们需要嵌入维度。 - 通常,每个分类特征的嵌入维度是相同的,因此我们可以对多个分类特征执行
Pytorch操作。
1 | embedding_dim_dict = get_embedding_dim_dict(categorical_features, 6) |
3.创建一个类来存储分类特征元数据
- 现在我们有了词汇量大小字典和嵌入维度字典,我们创建一个数据类来存储分类特征的元数据。
- 我们用这个类来创建一个简单的“
API”,让我们了解分类特征,获取词汇量大小、名称、nn.Embedding()的嵌入维度。 - 我们将此类称为
SparseFeat,因为nn.Embedding本质上是一个查找表,就像One-Hot编码一样,它本质上是一个稀疏特征,因为one-hot编码的特征除了“1”就是“0”
1 |
|
4.将分类列的列表存储为SparseFeat
- 如果我们有
1,000个分类特征,那么我们只需要迭代整个列表即可。1
2
3
4
5
6
7
8sparse_features = [SparseFeat(name=cat,
vocabulary_size=vocab_sizes[cat],
embedding_dim=embedding_dim_dict) for cat in categorical_features]
# [SparseFeat(name='uid', vocabulary_size=3, embedding_dim={'uid': 6, 'ugender': 6, 'iid': 6, 'igenre': 6}, embedding_name='uid', group_name='default_group', dtype=torch.int64),
# SparseFeat(name='ugender', vocabulary_size=2, embedding_dim={'uid': 6, 'ugender': 6, 'iid': 6, 'igenre': 6}, embedding_name='ugender', group_name='default_group', dtype=torch.int64),
# SparseFeat(name='iid', vocabulary_size=4, embedding_dim={'uid': 6, 'ugender': 6, 'iid': 6, 'igenre': 6}, embedding_name='iid', group_name='default_group', dtype=torch.int64),
# SparseFeat(name='igenre', vocabulary_size=3, embedding_dim={'uid': 6, 'ugender': 6, 'iid': 6, 'igenre': 6}, embedding_name='igenre', group_name='default_group', dtype=torch.int64)]
5.同样,创建一个类来存储数据集的数值特征,并将数值特征列表存储为DenseFeat
- 处理完分类元数据后,我们还创建一个类来存储数字特征的元数据。
- 这也是为了制作一个简单的“
API”,让我们知道一个数字特征,它的名称是什么以及对应的维度(默认=1)1
2
3
4
5
6
7dense_feat = DenseFeat(name='score', dimension=1)
dense_feat
# DenseFeat(name='score', dimension=1, dtype=torch.float32)
# create list of numerical features
numerical_features = ['score']
dense_features = [DenseFeat(name=col, dimension=1) for col in numerical_features]
6.创建与分类或数值特征对应的 Pytorch 张量的开始和结束索引
- 请记住,将
pandas DataFrame转换为Pytorch数据集后,我们失去了能够通过名称轻松查找功能的优势。 - 为了帮助我们解决这个问题,我们创建了一个函数来告诉我们每个特征,
Pytorch张量中的开始和结束索引是什么。 - 如果我们没有元数据类,我们必须继续引用
vocabulary_size字典和embedding_dim_dict。起始索引是包含的,而结束索引是排除的,类似于张量切片。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38categorical_features = ['uid', 'ugender', 'iid', 'igenre']
sparse_features = [SparseFeat(name=cat,
vocabulary_size=vocab_sizes[cat],
embedding_dim=embedding_dim_dict[cat]) for cat in categorical_features]
numerical_features = ['score']
# create list of numerical features
dense_features = [DenseFeat(name=col, dimension=1)
for col in numerical_features]
feature_columns = sparse_features + dense_features
def build_input_features(feature_columns):
features = OrderedDict()
start = 0
for feat in feature_columns:
if isinstance(feat, DenseFeat):
features[feat.name] = (start, start + feat.dimension)
start += feat.dimension
elif isinstance(feat, SparseFeat):
features[feat.name] = (start, start + 1)
start += 1
else:
raise TypeError('Invalid feature columns type, got', type(feat))
return features
feature_positions = build_input_features(feature_columns)
feature_positions
# OrderedDict([('uid', (0, 1)),
# ('ugender', (1, 2)),
# ('iid', (2, 3)),
# ('igenre', (3, 4)),
# ('score', (4, 5))])
7.基于pandasDataFrame构建Pytorch张量feature_columns
- 请注意上面代码中的
feature_columns= 稀疏特征+密集特征。这本质上意味着分类特征位于列表的左侧,数字列位于列表的右侧。 - 在上面的
build_input_features中,与分类或数值特征对应的Pytorch张量的开始和结束索引是根据feature_columns中的顺序创建的,这可能与pd.DataFrame中列的排列方式完全不同。 - 为了解决这个问题,我们根据
feature_columns中特征的顺序创建Pytorch张量。这确保了Pytorch张量的开始和结束索引对应于我们通过build_input_features创建的feature_positions。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23def build_torch_dataset(df: pd.DataFrame, feature_columns: List):
""" Create a torch tensor from the pandas dataframe according to the order of the features in feature_columns
Cannot just use torch.tensor(df.values) because for variable length columns, it contains a list.
Args:
df (pandas.DataFrame): dataframe containing the features
feature_columns (List)
Returns:
(torch.Tensor): pytorch tensor from df according to the order of feature_columns
"""
tensors = []
df = df.copy()
feature_length_names = []
for feat in feature_columns:
tensor = torch.tensor(df[feat.name].values, dtype=feat.dtype)
tensors.append(tensor.reshape(-1, 1))
return torch.concat(tensors, dim=1)
torch_df = build_torch_dataset(df, feature_columns)
torch_df
# tensor([[0.0000, 0.0000, 1.0000, 1.0000, 0.1000],
# [1.0000, 1.0000, 2.0000, 2.0000, 0.2000],
# [2.0000, 0.0000, 3.0000, 1.0000, 0.3000]])
8.创建一个函数来查找分类嵌入
- 我们首先创建一个字典,其中
key作为feature_name,value作为初始化的nn.Embedding。 - 我们创建函数,以便我们只能获得所选分类特征的嵌入。
- 在下面的示例中,您可以看到获取 [
‘uid’, ‘genre’] 的嵌入是多么容易,我们不必手动考虑‘uid’或‘genre’属于哪个位置索引。 - 如果我们有
1000个特征,只需将分类特征列表传递给return_feat_list。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54def build_embedding_dict(all_sparse_feature_columns, init_std=0.001):
embedding_dict = nn.ModuleDict(
{feat.name: nn.Embedding(feat.vocabulary_size,
feat.embedding_dim) for feat in all_sparse_feature_columns})
if init_std is not None:
for tensor in embedding_dict.values():
# nn.init is in_place
nn.init.normal_(tensor.weight, mean=0, std=init_std)
return embedding_dict
embedding_dict = build_embedding_dict(sparse_features)
embedding_dict
# ModuleDict(
# (uid): Embedding(3, 6)
# (ugender): Embedding(2, 6)
# (iid): Embedding(4, 6)
# (igenre): Embedding(3, 6)
# )
def embedding_lookup(X,
feature_positions,
embedding_dict,
sparse_feature_columns,
return_feat_list=()):
embeddings_list = []
for feat in sparse_feature_columns:
feat_name = feat.name
embedding_name = feat.embedding_name
if feat_name in return_feat_list or len(return_feat_list) == 0:
lookup_idx = feature_positions[feat_name]
input_tensor = X[:, lookup_idx[0]:lookup_idx[1]].long()
embedding = embedding_dict[embedding_name](input_tensor)
embeddings_list.append(embedding)
return embeddings_list
categorical_embeddings = embedding_lookup(torch_df,
feature_positions,
embedding_dict,
sparse_features,
return_feat_list=['uid', 'genre'])
categorical_embeddings
# [tensor([[[-9.1713e-04, 6.5061e-05, -8.2737e-04, -6.2794e-04, 3.2218e-04,
# -9.5998e-04]],
# [[-3.6192e-04, -7.2849e-04, -4.4335e-04, 5.4883e-04, -6.2344e-04,
# -5.5105e-04]],
# [[ 4.9634e-04, 2.3615e-04, -1.2853e-03, -2.9909e-04, 1.2274e-03,
# -2.2752e-04]]], grad_fn=<EmbeddingBackward0>)]
9.同样,创建一个函数来查找数值特征
- 在下面的示例中,您可以再次看到获取 [‘
score’] 的张量是多么容易,我们不必手动考虑‘score’属于哪个位置索引。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17def dense_lookup(X, feature_positions, dense_features, return_feat_list=()):
dense_list = []
for feat in dense_features:
feat_name = feat.name
lookup_idx = feature_positions[feat_name]
tensor = X[:, lookup_idx[0]:lookup_idx[1]]
dense_list.append(tensor)
return dense_list
dense_feats = dense_lookup(torch_df,
feature_positions,
dense_features,
return_feat_list=['score'])
dense_feats
# [tensor([[0.1000],
# [0.2000],
# [0.3000]])]
总结
更有经验的数据科学家将利用Python数据结构来使他/她的工作变得更轻松,当使用Pytorch处理数千个特征时,这些技能在现实世界中极其重要。