Pathway
Pathway
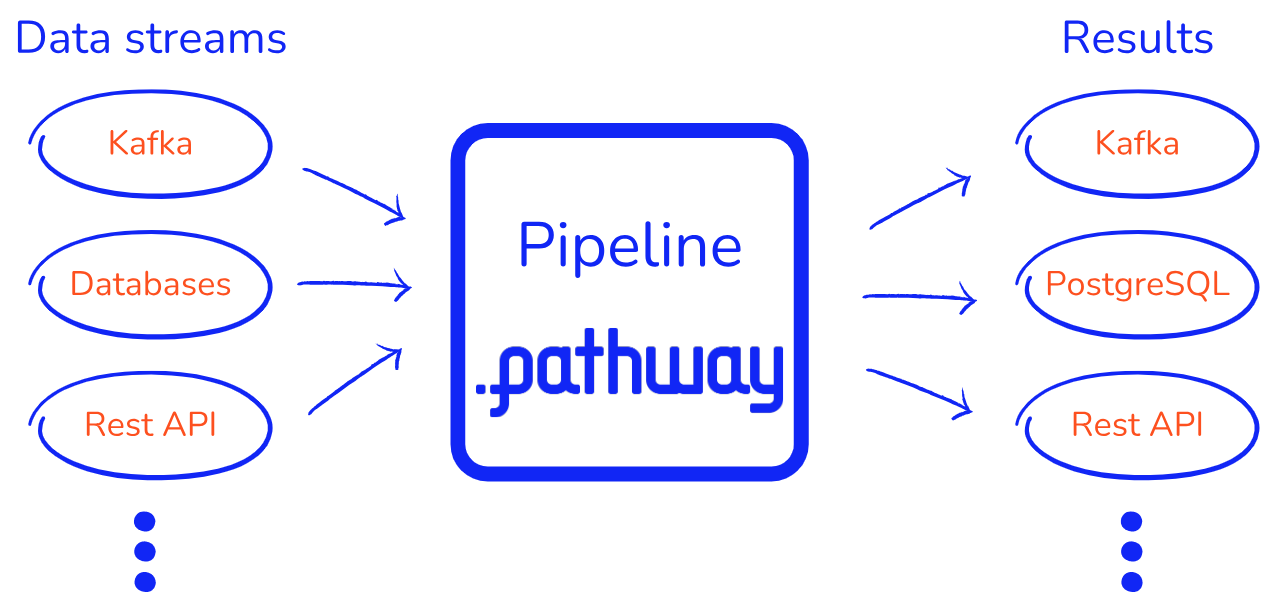
Pathway 的设计初衷是为面临实时数据源(需要对新数据做出快速反应)的Python开发人员和ML/AI工程师提供救星(或至少节省时间)。尽管如此,Pathway仍然是一个强大的工具,可以用于很多事情。如果您想在Python中进行流处理、构建AI数据管道,或者如果您正在寻找下一个Python数据处理框架。Pathway允许您轻松开发可处理实时数据源和不断变化的数据的数据转换管道和机器学习应用程序。您可以从使用本地Python安装开始,然后在您喜欢的IDE或笔记本中工作。这样,您就可以用静态数据样本进行数据实验,尝试数据源连接。一旦对测试实施感到满意,就可以在生产中使用相同的管道来获取实时数据。
Pathway的引擎为批处理和流数据提供一致的输出。您可以在同一代码逻辑中组合实时数据和历史数据,使用多个数据源,包括API、类似 Kafka 的事件代理、数据库和文件。
Pathway的强大之处:
- 实时处理各种数据:
Pathway支持从文件、数据库、传感器、社交媒体等各种来源读取数据,并能够实时处理数据流。 - 轻松构建实时应用:
Pathway提供了一个简单易用的API。 - 高性能、可扩展:
Pathway采用高性能的底层框架,能够轻松应对海量数据处理需求。它还支持分布式部署,可以满足各种规模的应用场景。 - 开源免费:
Pathway是一个完全开源的项目,你可以免费使用它,并根据自己的需求进行二次开发。
Pathway在AI领域的应用:Pathway拥有强大的实时数据处理能力,使其在AI领域拥有广泛的应用场景,包括:
- 实时推荐系统:
Pathway可以根据用户行为实时推荐商品或内容,提高用户体验。 - 实时欺诈检测:
Pathway可以实时分析交易数据,快速识别欺诈行为。 - 实时异常监测:
Pathway可以实时检测数据流,快速发现异常情况。 - 强化学习:
Pathway可以用于训练强化学习模型,让模型在实时环境中不断学习和改进。
使用Pathway构建实时推荐系统:
- 使用
Pathway从数据库中读取用户数据,并将其转换为实时数据流。 - 使用机器学习算法训练推荐模型。
- 使用
Pathway将推荐模型部署到生产环境并实时为用户推荐商品。
导入Pathway
要使用Pathway,需要导入它。
1 | $ pip install -U pathway |
Pathway可在MacOS和Linux上使用。 Windows目前不支持Pathway。 Windows用户可能希望使用适用于Linux的Windows子系统(WSL)、docker或VM。
连接到你的数据
在构建管道之前,你需要使用“输入连接器”连接到数据源,输入连接器将传入数据存储在Pathway表中。要连接到数据源,您需要指定传入数据的模式。假设我们的数据只有一个由整数组成的字段“值”:
1 | value |
现在,您需要使用输入连接器将数据连接到Pathway表。为了简单起见并避免设置数据源,让我们使用pw.demo库来生成人工数据源:
1 | import pathway as pw |
pw.demo.range_stream函数将生成一个带有单列“value”的简单数据流,其值范围从0开始,每秒递增。实际上,您应该使用输入连接器,例如pw.io.csv连接器,它连接到存储在给定目录中的CSV文件。
创建的管道
现在您有了数据,您可以根据需要对其进行处理!连接、时间窗口、过滤…。为了简单起见,我们从一个简单的求和开始:
1 | import pathway as pw |
sum_table包含带有单个条目的单列总和,该条目是表input_table中所有值的总和。当新值添加到input_table时,Pathway会自动更新该值。
输出你的结果
现在您的管道已完成并且所有计算均已准备就绪,您现在需要指定如何处理返回的结果。 Pathway使用输出连接器将数据输出到Pathway外部。让我们使用pw.io.csv连接器将结果输出到新的 CSV文件中。
1 | import pathway as pw |
运行您的管道
现在一切都已准备就绪,您可以轻松运行,同时让Pathway处理更新。要启动对流数据的计算,您需要添加pw.run():
1 | import pathway as pw |
不要忘记使用pw.run()运行计算,否则将构建管道,但不会摄取任何数据:将不会进行计算。使用pw.run(),将启动计算。 输入数据流中的每次更新都会自动触发整个管道的更新。 Pathway将轮询新的更新,计算将永远运行,直到进程被终止。Pathway提供了一种静态模式,可以在模拟“批处理”模式下工作,在该模式下操作静态和有限的数据。 主要优点之一是能够使用整个数据触发计算,并在不使用输出连接器的情况下打印结果,这要归功于pw.debug.compute_and_print。注意:流式传输和静态模式都不是交互式的,因为管道先构建一次,然后再摄取数据。