Kubernetes 高可用
Kubernetes 是一个分布式系统,容易出现多种故障。对于组织而言,拥有高度可用的 Kubernetes 对于提供良好的客户体验至关重要。如果发生意外中断,如果您的集群在一个或多个组件发生故障的情况下无法继续运行,则停机可能会导致收入损失、声誉问题等。
通过在 Kubernetes 中实施 HA,可以降低停机风险,集群上运行的应用程序和服务仍然可供用户访问,并且系统可以快速从故障中恢复,无需人工干预。在较高级别上,这可以通过部署控制平面组件的多个副本以及跨越多个可用区或区域的网络拓扑来实现。
Kubernetes 控制面节点的高可用性
Kubernetes 控制面节点具有以下核心组件:
API serverKube controller managerKube SchedulerCloud Controller Manager (Optional)
运行单个控制面节点可能会导致所有控制平面组件出现单点故障。要拥有高度可用的 Kubernetes 控制平面,您应该至少拥有三个 quoram 控制平面节点,并在所有三个节点之间复制控制平面组件。
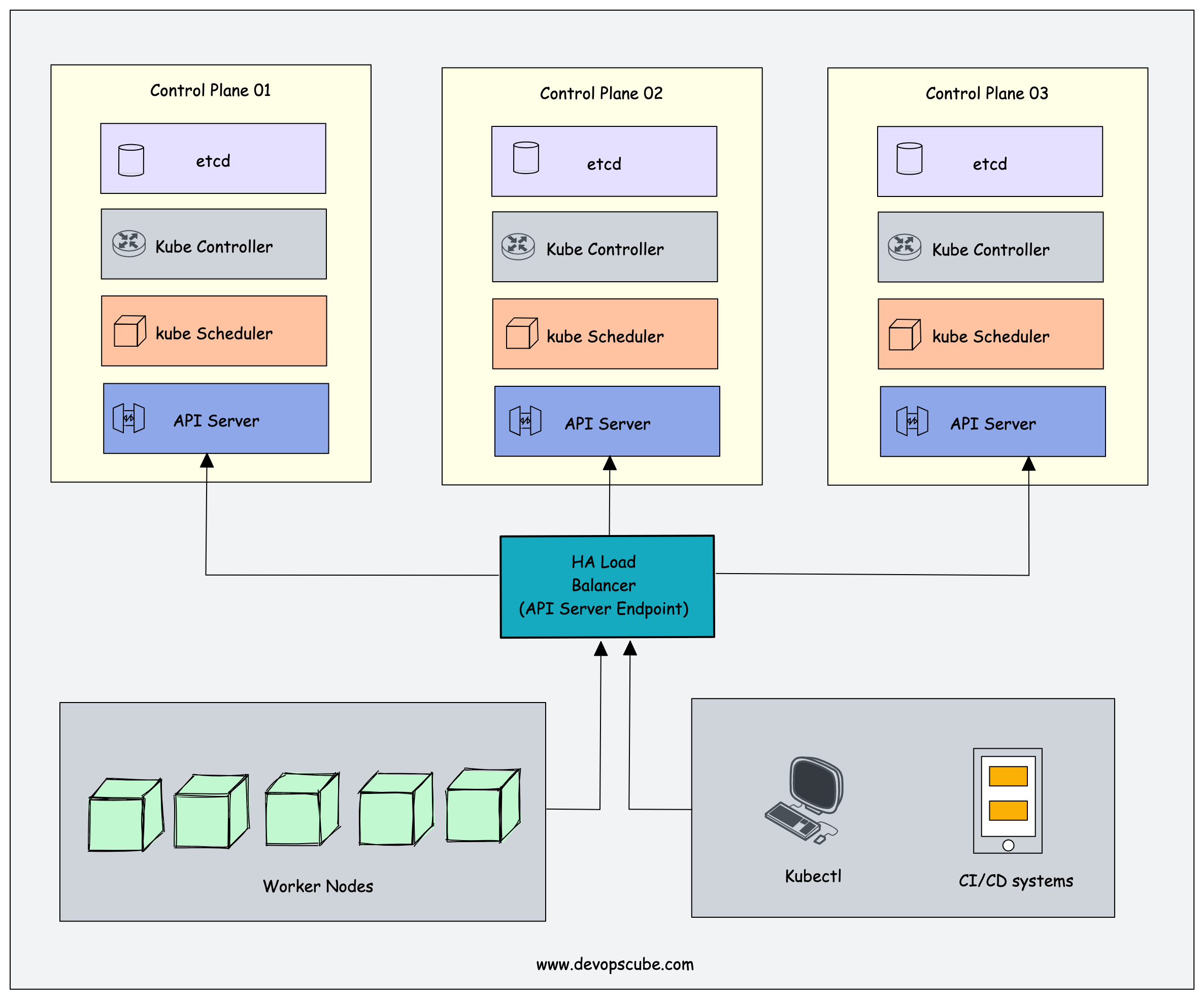
现在,了解每个控制平面组件在跨节点部署为多个副本时的性质非常重要。因为当部署为多个副本时,很少有组件会使用领导者选举。
etcd
当谈到etcd HA架构时,有两种模式。
- 堆叠式 etcd:etcd 与控制平面节点一起部署
- 外部etcd集群:运行专用节点的Etcd集群。该模型的优点是管理良好的备份和恢复选项。
为了具有容错能力,您应该拥有至少三节点的 etcd 集群。下表展示了etcd集群的容错能力。当涉及到生产部署时,定期备份 etcd非常重要。
API server
API 服务器是一个无状态应用程序,主要与 etcd 集群交互以存储和检索数据。这意味着 API 服务器的多个实例可以跨不同的控制平面节点运行。为了确保集群 API 始终可用,应该在 API 服务器副本之前放置一个负载均衡器。工作节点、最终用户和外部系统使用此负载均衡器端点与集群进行交互
Kube Scheduler
当您运行 kube 调度程序的多个实例时,它遵循领导者选举方法。这是因为,schedler 组件涉及 pod 调度活动,并且一次只有一个实例可以做出决策。因此,当您运行调度程序的多个副本时,一个实例将被选为领导者,其他实例将被标记为追随者。
这确保了始终有一个活动的调度程序来做出调度决策,并避免冲突和不一致。如果是领导者,追随者将被选举为领导者并接管所有调度决策。这样,您就拥有了具有一致调度的高度可用的调度程序。
Kube controller manager
Kuber 控制器管理器也遵循相同的领导者选举方法。从许多副本中,选出一个控制器管理器,并将领导者和其他人标记为追随者。领导者控制器负责控制集群的状态。
Cloud Controller Manager
云控制器管理器 (CCM) 是一个 Kubernetes 组件,它运行与云提供商特定的 API 交互的控制器,以管理负载均衡器、持久卷和路由等资源。就像调度程序和 kube-controller 一样,CCM 也使用领导者选举来确保一次只有一个活动副本做出决策并与云提供商 API 进行交互。
Kubernetes 工作节点的高可用性
为了获得工作节点高可用性,您需要运行应用程序所需的多个工作节点。当存在 pod 扩展活动或节点故障时,其他工作节点上应该有足够的容量来调度 pod。在云平台上,您可以使用自动缩放来缩放工作节点。因此,当存在扩展活动或资源需求时,工作节点可以扩展到所需的容量。
Kubernetes 集群可用性测量
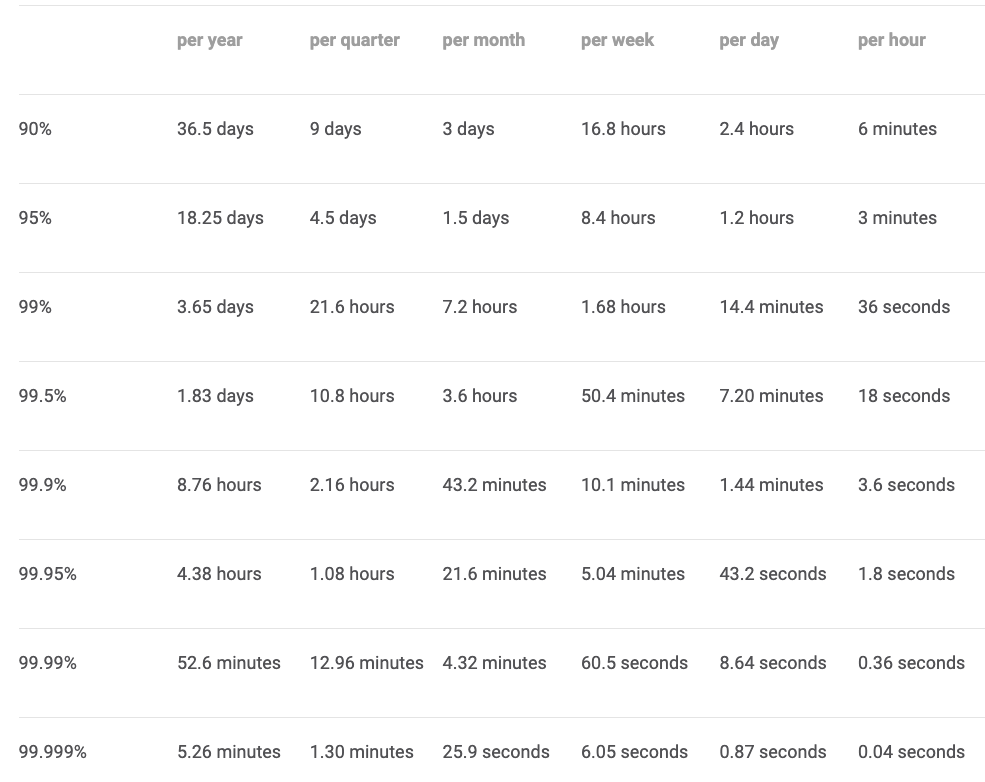
假设没有计划停机时间,下表来自Google SRE 书籍,显示了根据不同可用性级别允许的停机时间的计算。每个组织都会有用于集群可用性的 SLO。如果您使用管理服务,服务提供商将制定与 SLO 一致的 SLA。
如果 Kubernetes 集群中的 DNS 服务失败会发生什么?
如果像 Core DNS 这样的 DNS 服务出现故障,可能会对集群中运行的应用程序的可用性和功能产生重大影响。它可能会破坏服务发现、外部访问、负载平衡、监控和日志记录以及滚动更新,从而导致应用程序故障、错误和中断。
控制平面故障期间会发生什么?
即使控制平面发生故障,工作节点上现有的工作负载也会继续处理请求。但是,如果出现节点故障,Pod 调度活动或任何类型的更新活动都不会发生。